基于SVM算法的垃圾焚燒爐排爐參數(shù)預(yù)測(cè)研究
2024-01-02 00:00:00劉燕
中國(guó)新技術(shù)新產(chǎn)品
2024年24期
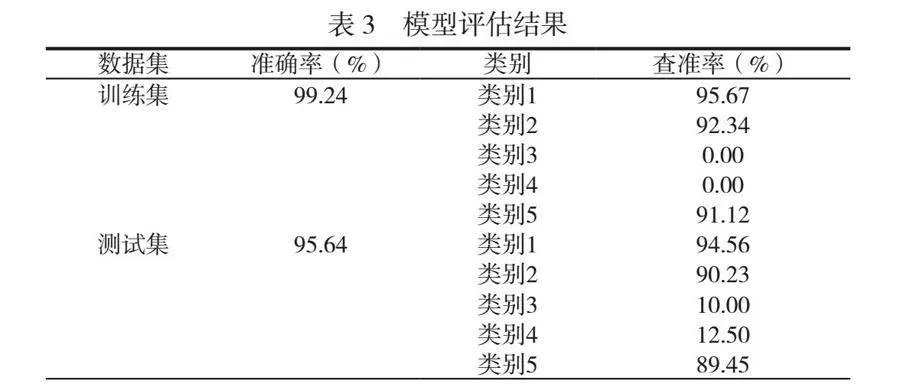
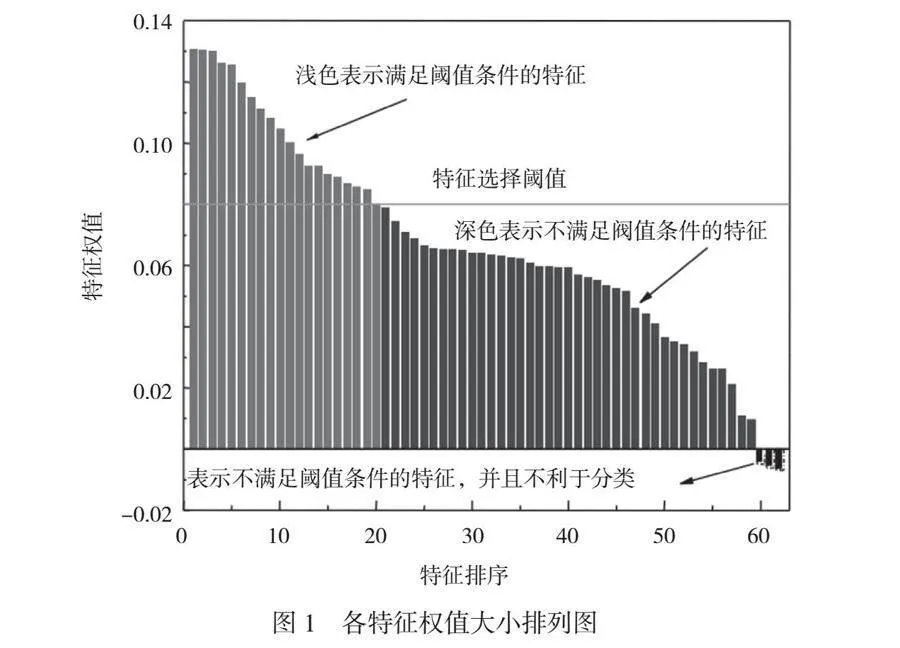
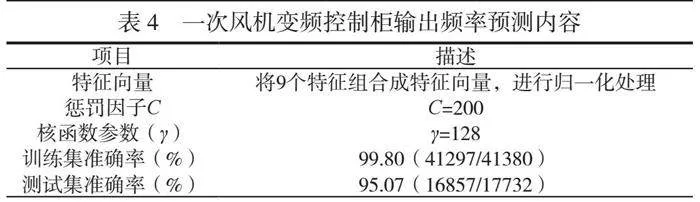

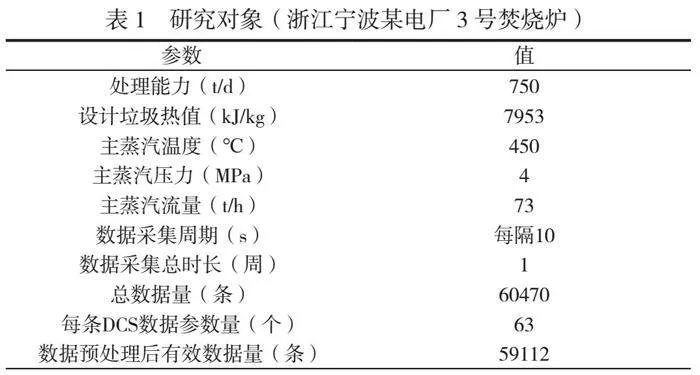
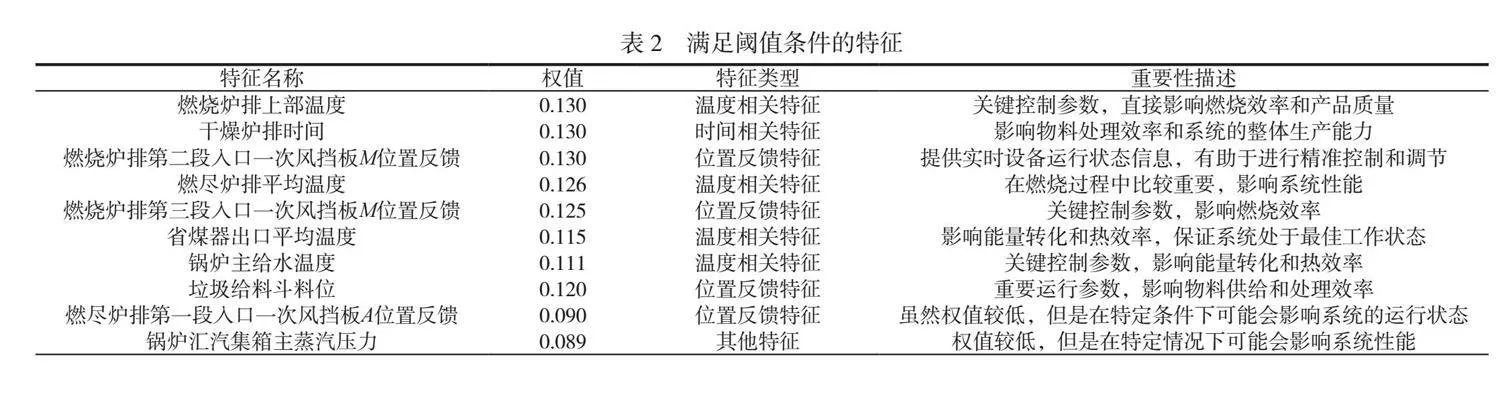
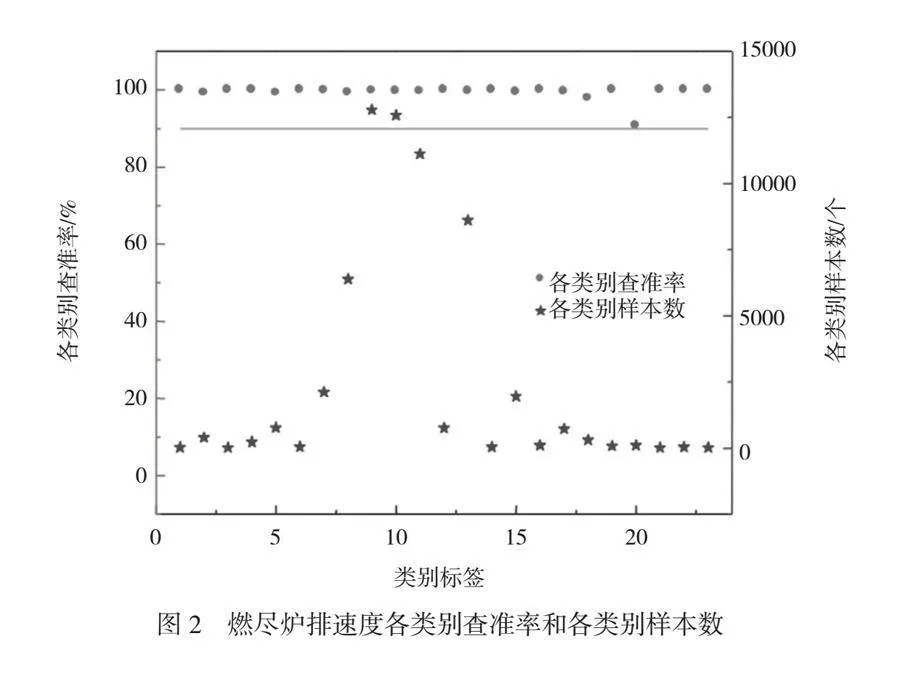
摘 要:本文對(duì)浙江寧波某電廠3號(hào)焚燒爐的排爐運(yùn)行參數(shù)進(jìn)行了預(yù)測(cè),采用支持向量機(jī)(SVM)算法對(duì)垃圾焚燒爐排爐速度進(jìn)行建模與分析。對(duì)原始DCS數(shù)據(jù)進(jìn)行清洗和標(biāo)準(zhǔn)化處理,以消除噪聲和異常值,提高了模型的收斂速度和性能。通過ReliefF算法評(píng)估特征與分類標(biāo)簽間的相關(guān)性,篩選出59個(gè)與燃燒爐排速度相關(guān)的特征,構(gòu)建新的特征集,從而降低模型復(fù)雜性,并提高可解釋性。結(jié)果表明,本文構(gòu)建的模型在垃圾焚燒爐排爐參數(shù)預(yù)測(cè)中表現(xiàn)出色,具備良好的學(xué)習(xí)能力和泛化能力,為實(shí)際操作提供了重要的決策支持。本文研究為垃圾焚燒爐的優(yōu)化運(yùn)行和管理提供了理論依據(jù)和實(shí)踐參考。
關(guān)鍵詞:支持向量機(jī);垃圾焚燒爐;排爐參數(shù)預(yù)測(cè)
中圖分類號(hào):TK 16 " " " 文獻(xiàn)標(biāo)志碼:A
隨著城市化進(jìn)程加快,垃圾處理問題日益凸顯。垃圾焚燒是一種有效的垃圾處理方式,已被廣泛應(yīng)用于各地的垃圾管理中。垃圾焚燒爐的運(yùn)行效率和排放控制直接影響環(huán)境保護(hù)和資源利用,因此,優(yōu)化焚燒爐的運(yùn)行參數(shù)、提高其處理能力和安全性成為研究的重點(diǎn)[1]。在垃圾焚燒過程中,排爐參數(shù)的準(zhǔn)確預(yù)測(cè)對(duì)提高焚燒效率、降低能耗并減少有害氣體排放至關(guān)重要。傳統(tǒng)的排爐參數(shù)預(yù)測(cè)方法基于經(jīng)驗(yàn)和規(guī)則,難以適應(yīng)復(fù)雜的運(yùn)行環(huán)境和多變的垃圾成分。隨著數(shù)據(jù)采集技術(shù)進(jìn)步,焚燒爐運(yùn)行中產(chǎn)生的大量實(shí)時(shí)數(shù)據(jù)為應(yīng)用現(xiàn)代數(shù)據(jù)分析技術(shù)提供了基礎(chǔ)[2]。支持向量機(jī)(SVM)是一種強(qiáng)大的機(jī)器學(xué)習(xí)算法,具有優(yōu)秀的分類和回歸能力,已被廣泛應(yīng)用于各類工程領(lǐng)域。……
登錄APP查看全文
