引入通道注意力機制的目標檢測算法
2023-12-25 03:25:04許維義
電腦知識與技術 2023年31期
許維義



摘要:針對目標檢測模型在提高檢測精度的同時會帶來更高模型復雜度這一不足,該文提出了一種改進的YOLOv4模型。該模型將通道注意力機制ECA模塊加入特征提取網絡之中,構建了一個新的YOLOv4模型。通過在PASCAL VOC數據集上的實驗表明:該算法在不增加模型大小的前提下提高了檢測精度,相比YOLOv4算法在PASCAL VOC 2007測試集上的平均精確度均值@0.5提升了最高3.56mAP,達到了最高83.42mAP,能夠解決目標檢測性能和模型復雜度之間的矛盾,并提高了檢測精度。
關鍵詞:目標檢測;YOLOv4算法;通道注意力機制;解耦頭
中圖分類號:TP391? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2023)31-0048-03
開放科學(資源服務)標識碼(OSID)
目標檢測作為計算機視覺領域的重要分支,在實時監(jiān)控、信息檢索、交通物流等領域都發(fā)揮著重要的作用,一直受到眾多學者的關注和研究。目標檢測任務作為圖像處理領域的經典任務之一,由目標定位和目標分類兩部分組成。其中目標定位任務主要輸出目標在圖片上的位置,輸出的數據形式一般為目標中心及目標區(qū)域的長寬或目標在圖片上的四個端點的坐標信息;而目標分類負責判斷圖片中是否有需要檢測的目標出現,其輸出數據的形式包括類別的編碼以及目標屬于該類別的概率。目標檢測任務的應用范圍非常廣泛,如人臉檢測、智能交通、安全系統檢測和醫(yī)療方面檢測。
從像素級分析的傳統目標檢測時代到特征級分析的深度學習型目標檢測時代,目標檢測技術在無數研究人員的努力下得到了長足發(fā)展,并逐漸走向成熟。但由于應用領域的不同、應用場景的不同、目標大小和目標類別的不同、任務類型的不同和樣本數目的不同,目標檢測仍然面對著提高應用靈活性和任務適應性等挑戰(zhàn)。
如Girshick R等人[1]將區(qū)域提議與CNN相結合,提出的R-CNN揭示了豐富的圖像特征層次結構,提高了檢測的精度。Girshick R等人[2]提出的Fast R-CNN是在R-CNN的基礎上引入SPPnets,在對整個圖像進行歸一化后,候選區(qū)域的特征不再是在卷積層中進行提取,而是通過在尾部的池化層中加入需要檢測區(qū)域的坐標位置來提取所需要的特征。Liu W等人[3]介紹了SSD,SSD的創(chuàng)新是對目標的檢測加入了多尺度特征圖,能夠提高檢測的精確度。Ren S等人[4]通過讓RPN和Fast R-CNN共同使用卷積特征來整合成一個網絡,能夠有效地提高檢測速度和綜合性能。Rashwan A等人[5]介紹了矩陣網(xNet) ,一個尺度和縱橫比感知架構的目標檢測,能夠增強基于關鍵點的對象檢測,且使用一半參數的同時降低訓練時間到原來的1/3。針對上述問題,本文提出了一種改進的YOLOv4模型[6],能夠在不增加模型大小的前提下,提高模型的檢測精度。該算法將有效通道注意力模塊ECA引入特征提取網絡中,通過分析插入位置的不同而導致的模型性能的差異來選取最優(yōu)插入區(qū)域,并對YOLOv4原模型的SPP[7]進行不同尺度的對比優(yōu)化。為解決YOLOv4檢測頭部耦合問題,使用解耦檢測頭代替了原本的耦合檢測頭,進而提升檢測的效果。
1 背景知識
1.1 YOLOv4模型
YOLO[8-10]作為一系列的目標檢測模型,已廣泛應用于各個行業(yè),如交通違章檢測、行人檢測、商品檢測等領域。其中,YOLOv4作為一種單階段目標檢測算法,首先是通過骨干網絡進行目標的關鍵信息提取,再經過頸部網絡對骨干網絡提取的信息進行融合,最后使用檢測頭部對融合的信息進行分類和回歸。YOLOv4借鑒CSPNet結構并融入Darknet53中,使骨干網絡性能得到大幅提升。頸部網絡也稱加強特征提取網絡,YOLOv4采用了SPP模塊和PANet網絡作為頸部網絡,增強了對特征圖的提取能力。YOLOv4的頭部結構與YOLOv3相同,依舊采用三尺度輸出,用于對不同尺寸大小的目標進行檢測。
自2018年YOLOv3年提出的兩年后,在Redmon聲明放棄更新YOLO算法后,Alexey等人扛起了YOLO系列更新的大旗,在2020年4月提出了YOLOv4版本。YOLOv4在YOLOv3的模型基礎上使用了空間金字塔池化和路徑聚合網絡組合的特征融合方式,并將原骨干網絡Darknet53換成了CSPDarknet53,CSPDarknet53是在Darknet53的基礎上加了CSPNet。CSPNet的特點是充分利用跨層信息,使用CSPaNet結構將輸入特征圖分成兩個部分,然后通過跨層連接來結合這兩部分的信息,這樣可以在減少計算復雜度的同時提高網絡的感受野和特征表達能力。
2020年11月,CSPNet的作者Chien-Yao Wang與Alexey等人在YOLO系列繼續(xù)擴展,從影響模型擴展的幾個不同因素出發(fā),基于CSP方法的YOLOv4對象檢測神經網絡,可向上和向下擴展,適用于小型和大型網絡,同時保持最佳速度和精度。Scaled-YOLOv4是一種Network Scaling網絡擴展方法,它不僅針對深度、寬度、分辨率進行調整,同時可以調整網絡結果,并提出了兩種分別適合于高端GPU的YOLOv4-large和低端GPU的YOLOv4-tiny。
YOLOv4-large是為云GPU設計的,主要目的是實現高精度的目標檢測,是一種完全csp化的模型YOLOv4-P5,并將其擴展到YOLOv4-P6和YOLOv4-P7。
1.2 注意力機制
通道注意力機制是指在多個通道中,通過調節(jié)每個通道的權重來實現注意力分配。例如,在圖像識別任務中,每個通道對應的是不同的顏色、紋理、形狀等特征,通過調節(jié)每個通道的權重,可以更好地捕捉重要的特征,從而提高識別準確率,因此對提高目標檢測網絡模型的性能方面有著重要的作用。但是,現在大多數方法為了提高模型的檢測性能,往往采用十分復雜的注意力模塊,這使得模型的復雜性大大增加,而本文使用的有效通道注意力模塊ECA在提升模型檢測精度的同時并沒有增加模型的大小。
擠壓和激發(fā)模塊驗證了通過建模可以重新預測各個通道,使獲取的通道信息更加關鍵,但是遺漏了位置的信息。卷積注意模塊雖然添加了空間注意力模塊,但是通過卷積來獲取位置信息,而卷積只能捕獲局部位置關系,不能夠對長范圍關系進行卷積。協調注意力模塊捕獲了跨通道的方向感知和位置感知的信息,可以讓模型對目標區(qū)域的定位更加精準,但使用的參數太多。
本文使用的有效通道注意力模塊與提高檢測精度的同時會帶來更高模型復雜度的模塊不同,ECA模塊在提高檢測精度的同時參數量并沒有太大變化。ECA模塊通過避免渠道維度縮減,同時以極其輕量級的方式捕捉跨渠道互動,用來學習有效的渠道注意力,可以使模型對通道內信息的提取更敏感、更關鍵。
2 改進的YOLOv4算法
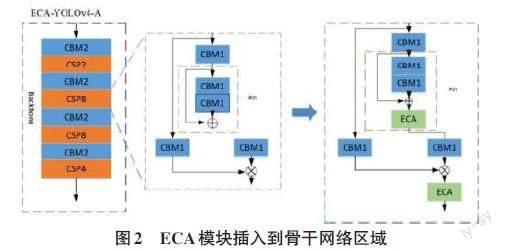
作為一種即插即用的注意力模塊,ECA可以添加到YOLOv4網絡中的任何地方,但不同的插入位置也會導致模型預測性能的差異。本文對在YOLOv4網絡模型中的不同位置插入ECA模塊所帶來的差異進行研究。根據 YOLOv4 網絡模型的結構,可分別在 YOLOv4的Backbone骨干網絡、Neck頸部和Head檢測頭部3個部分插入ECA注意力模塊。由于ECA模塊是加強對不同通道中的特征信息提取,所以可以在上述3部分中的每個特征融合區(qū)域中插入ECA模塊,ECA模塊的具體插入位置如圖2所示。
根據YOLOv4 網絡模型的結構,可在YOLOv4的Backbone骨干網絡部分插入ECA注意力模塊。由于ECA模塊是加強對不同通道中的特征信息提取,所以可以在特征融合區(qū)域中插入ECA模塊。
3 實驗與結果分析
3.1 數據集和訓練參數
本實驗采用VOC2007+2012公共數據集,該數據集的主要層級結構為4個大類,共包含20個小類,共有27088張圖片。訓練集、驗證集和測試集的比例為7∶2∶1。其中,訓練集圖片有18 962張,驗證集有5 418張,測試集有2 708張。訓練過程的初始學習率為0.001,每25次迭代后學習率下降到原來的0.1倍,動量為0.9,衰減系數為0.000 5,Batchsize設為4,設置訓練的Epochs為180次。
實驗將VOC2007數據集中的圖像標簽修改為YOLO模型所需的pascalvoc標簽,訓練集是voc07train+val和 VOC12的train+val,驗證集/測試集是voc2007test。由于顯存較低的原因,本實驗將原圖片608×608尺寸調整為416×416大小。
3.2 對比試驗及結果分析
為了驗證所提出的網絡模型在檢測精度上的有效性,從不同方面將筆者的方法與現有方法進行了對比和分析。
為了突出YOLOv4-ours模型在檢測性能上的優(yōu)勢,本文選用三個注意力機制模塊分別插入YOLOv4網絡中,分別是SE模塊、CBAM模塊、CA模塊,再加上原本的YOLOv4網絡與改進后的YOLOv4-ours模型進行對比。ECA模塊是在SE模塊的基礎上,把SE中使用全連接層FC學習通道注意信息,改為1×1卷積學習通道注意信息。與FC相比,1×1卷積只有較小的參數量,這樣可以避免在學習通道注意力信息時通道維度減縮,且降低了參數量。而CBAM模塊雖然也是輕量級的注意力模塊,但它將通道與空間注意力機制進行結合,不可避免地增加了模型大小。與EC模塊相比,CBAM在特征提取后加了一個并行的最大池化層,雖然提取到的高層特征更加豐富,但池化而導致信息的丟失也更多。并且在通道注意力機制之后,CBAM模塊添加了一個多層感知機來提高識別率和分類速度,但訓練速度較低,尤其是對于目標檢測這類巨大量的訓練集。
為了突出YOLOv4-ours模型在精度上的優(yōu)勢,本文使用YOLO-V3、improved-YOLO-V3、YOLOv4、Fast-R-CNN4種模型在PASCAL VOC 2007上對比我們的模型。筆者使用文中提出的性能評價指標來評估這些方法的性能。從結果可以看出,在閾值為0.5即mAP@0.5時,YOLOv4-ours在目標檢測精度上相較YOLOv4算法表現更好,相較其他算法模型在PASCAL VOC 2007數據集上也表現出了最高的檢測精度83.42%,證明了該網絡模型具有較好的目標檢測性能。
4 結論
針對目標檢測模型在提高檢測精度的同時會帶來更高模型復雜度這一不足,本文提出了一種改進的YOLOv4模型,該算法將有效通道注意力模塊ECA引入特征提取網絡中,進而構建一個新的YOLOv4模型,在不增加模型大小的前提下,提高了模型的檢測精度。根據實驗表明,相比YOLOv4算法在PASCAL VOC 2007測試集上的mAP@0.5提升了最高3.56mAP,在PASCAL VOC 2007測試集上達到了最高83.42mAP@0.5,且較其他算法模型也表現出了最高的性能,證明了模型在解決目標檢測性能和模型復雜度之間矛盾的優(yōu)越性。
參考文獻:
[1] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.ACM,2014:580-587.
[2] GIRSHICK R.Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago,Chile.IEEE,2015:1440-1448.
[3] LIU W,ANGUELOV D,ERHAN D,et al.SSD:single shot MultiBox detector[J].Computer Vision – ECCV 2016,2016.
[4] REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[5] RASHWAN A,KALRA A,POUPART P.Matrix nets:a new deep architecture for object detection[C]//2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW).Seoul,Korea (South).IEEE,2019:2025-2028.
[6] BOCHKOVSKIY A,WANG C Y,LIAO H Y M.YOLOv4:optimal speed and accuracy of object detection[EB/OL].[2022-10-22].2020:arXiv:2004.10934.https://arxiv.org/abs/2004.10934.pdf.
[7] HE K M,ZHANG X Y,REN S Q,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].Computer Vision-ECCV 2014,2014.
[8] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas,NV,USA.IEEE,2016:779-788.
[9] REDMON J,FARHADI A.YOLO9000:better,faster,stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu,HI,USA.IEEE,2017:6517-6525.
[10] REDMON J,FARHADI A.YOLOv3:an incremental improvement[EB/OL].2018:arXiv:1804.02767.https://arxiv.org/abs/1804.02767.pdf.
【通聯編輯:代影】
