基于物體顯著性自監督學習的片煙雜物檢測方法
2023-12-21 07:48:22王小飛李東方李玉珩陳傳通
煙草科技 2023年12期
王小飛,李東方,李玉珩,陳傳通
1.秦皇島煙草機械有限責任公司,河北省秦皇島市經濟技術開發區龍海道67號 066000
2.山東中煙工業有限責任公司濟南卷煙廠,濟南市歷城區科航路2006號 250100
片煙原料中經常混有金屬、石塊、麻繩、紙片、蟲繭、泡沫等雜物,這些雜物若混入煙絲卷制成卷煙,在煙支燃燒時會產生異味,影響卷煙感官質量,增加加工質量風險。因此,片煙雜物檢測和剔除是卷煙制絲生產中的重要工序之一,其作用在于防止金屬和石塊等重質雜物對后續工序設備造成損壞,避免泡沫等輕質雜物以及麻繩和蟲繭等異物影響卷煙質量。目前煙草行業常用的雜物檢測及剔除方法主要有風選法、激光法和圖像識別法[1]。風選法利用異物與片煙或煙絲懸浮速度不同剔除重質雜物,但無法有效剔除與煙絲質量相近的異物。激光法根據片煙和異物對激光反射、吸收特性的不同進行雜物識別,但該設備生產成本較高,不利于推廣應用[1-2]。圖像識別法分為傳統法和基于深度學習方法。李陽萱[3]利用顏色特征對煙草異物圖像進行檢測,異物剔除率達到99%;莊珍珍[4]采用區域生長邊緣檢測方法對煙葉圖像進行分割,取得較好的背景分離效果;邵素琳[5]通過梯度直方圖和灰度共生矩陣提取片煙的關鍵點和描述符,進而提取片煙的顏色及紋理特征識別片煙類別。傳統的圖像識別法剔除雜物效果較好,但需要人工進行參數調節,且魯棒性較差,容易受環境噪聲的影響。隨著深度學習方法的發展,吳亞成[6]將卷積神經網絡嵌入到顏色分類器,提高特征提取性能,煙葉除雜精度得到顯著提升。李亞召等[7-8]提出一種基于卷積神經網絡的霉變煙葉識別方法,通過構建卷積神經網絡模型學習正常煙葉和霉變煙葉的特征,再利用收斂后的模型推理并篩選正常煙葉與霉變煙葉,識別準確率可達96.12%。但在實際應用中由于片煙運動容易造成雜物被遮擋,仍然存在正常片煙被誤判為雜物、雜物漏檢等問題。而采用深度學習方法利用訓練得到的深度神經網絡對圖像進行顯著性目標檢測(Salient Object Detection,SOD)[8],可有效提升檢測準確度。顯著性目標檢測可以看作是一個圖像分割問題,即將圖像中的顯著性目標區域從背景中分割出來[9]。顯著性目標檢測目前廣泛應用于計算機視覺任務中[10-11],如對高分辨率衛星圖像進行基于無監督特征學習的場景分類[12];將無監督學習轉化為多實例學習,實現圖像目標定位和分類[13];構建測試視覺問答模型性能的數據集[14]等。近年來,顯著性目標檢測在煙草行業也有大量應用,楊威等[15]基于U-Net和超像素分割對煙株進行自動提取,平均準確度達到93.42%。鐘宇等[16]提出一種基于殘差神經網絡的煙絲類型識別方法,能夠有效識別葉絲、梗絲、膨脹葉絲、再造煙葉絲等煙絲類型,相比基于卷積神經網絡的識別方法,識別率、泛化能力與魯棒性均有提升。洪金華等[17]采用自監督的k-means++聚類方法對煙蟲圖像自動生成YOLOv3模型的錨點框,提高了對煙蟲位置、煙絲和煙末的識別能力。自監督學習是一種具有特殊監督形式的非監督學習方法[18],由自監督任務而非預設先驗知識誘發,其算法能夠自主學習檢測到的顯著物體之間的相互關系,并通過自動適應雜物與正常物體的分界點來確定真實雜物。為此,采用深度學習顯著性目標檢測與傳統特征聚類相結合的方法,提出一種片煙雜物檢測方法,并采用狀態累積的方法對一定時間內多幀序列的檢測結果進行像素分析,以期提高片煙雜物檢測精度,實現片煙生產流程全自動化檢測。
1 材料與方法
1.1 樣品
片煙樣品為濟南卷煙廠制絲車間2023年1—4月生產的片煙產品,包含多個批次。
1.2 數據集構建
所使用數據均為濟南卷煙廠細支卷煙智能生產線監控視頻數據。將視頻數據進行圖像提取、篩選、標注得到訓練數據,數據標注過程見圖1。其中,雜物區域標記為白色,灰度值為255;其他背景區域標記為黑色,灰度值為0。對原始圖像進行處理得到12 000 張標注圖像,按照7∶2∶1 的比例將其劃分為訓練集、驗證集和測試集。

圖1 數據標注過程Fig.1 Data labeling procedure
1.3 模型構建
1.3.1 片煙雜物的顯著性目標檢測
顯著性目標檢測分為稀疏檢測法和密集檢測法[19],本文中采用的是基于編-解碼結構的密集檢測法,其顯著性目標檢測網絡為嵌套的兩級U型結構,所嵌套的模塊稱為殘差U 型塊[20](ReSidual U-blocks,RSU)。由于RSU 中混合了不同大小的感受野,故能夠從不同尺度獲取更多信息。此外,RSU還使用了池化操作,在增加整個模型深度的情況下不會增大計算成本。圖2是一個深度為7的RSU,其結構包含上采樣和下采樣兩個階段,各有5層網絡,每層網絡包含卷積層、批歸一化層和激活層。其中,H、W、C分別代表輸入和輸出的高、寬和通道數,M表示每層輸入輸出通道數的度量,3×3為卷積層的卷積核大小,d表示擴張卷積的擴張率[21]。

圖2 殘差U型塊結構Fig.2 Structure of ReSidual U-blocks
顯著性目標檢測網絡架構如圖3所示,采用全卷積神經網絡[22]架構,每個藍色方塊為一個RSU,每個RSU包含兩層不改變輸入高、寬的卷積層,下采樣網絡層數由高到低依次為5,4,3,2,1,0 層。圖3 中向下箭頭表示下采樣,向上箭頭表示上采樣,向右的細箭頭表示跳躍連接,就是將兩個相同高、寬的特征在通道維度上進行串聯操作。顯著性目標檢測網絡采用嵌套的U 型結構,能夠有效提取每一階段的多尺度特征以及聚集階段的多層次特征。
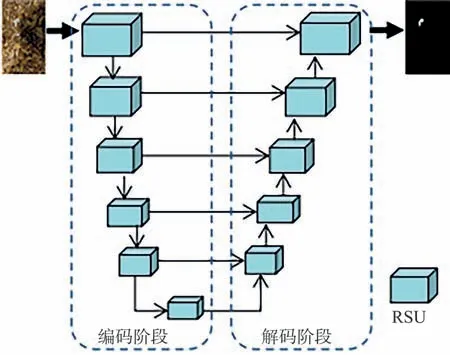
圖3 顯著性目標檢測網絡架構Fig.3 Structure of salient object detection network
因整個顯著性目標檢測網絡架構建立在RSU上,未使用任何經過預訓練的、適應于圖像分類的骨干網絡。因此,構建的顯著性目標檢測網絡模型(以下簡稱兩級U-Net模型)性能靈活且適應性強。兩級U-Net 模型輸入為三通道的RGB 圖像,輸出為相同分辨率的單通道顯著性圖像。在訓練過程中采用預訓練與監督學習方式對網絡參數進行優化,其損失函數為二值交叉熵:
式中:PS(r,c)和PG(r,c)分別代表高、寬為H、W的圖像坐標點(r,c)的模型預測值和真實值。
1.3.2 片煙雜物的自監督聚類
采用自監督學習方法可以自適應地學習顯著性物體之間的分界線。首先提取檢測到的顯著性物體的特征(圖4a),再采用傳統的K 均值聚類方法進行聚類分析。利用兩級U-Net 模型對輸入的片煙圖像進行檢測,能夠獲得圖像中各類雜物的顯著性目標檢測結果。如圖4b所示,黑色區域代表背景,白色區域代表所檢測的雜物,其形狀面積與雜物大小和類別相關。根據模型的輸出結果,按照白色區域對原始圖像進行分割,可獲得雜物的目標區域圖像(圖4c),提取這些目標區域的特征即可對雜物進行分類識別。

圖4 顯著性目標檢測及雜物矩形框生成過程Fig.4 Process of salient object detection and foreign matter rectangle box generation
利用模型的編碼器進行目標區域特征提取,編碼器由圖3 左邊虛線框內編碼階段各RSU 組成,其輸入大小為1 px×64 px×64 px×3 px。因雜物大小存在差異,目標區域尺寸也各不相同。因此,在將目標區域輸入到編碼器前需要對不同目標區域進行尺寸歸一化,使其滿足編碼器輸入要求。編碼器輸出的1×10×10×512維度的特征圖經過變形得到1×51 200維度的特征向量,對圖像上n個顯著性目標對應的特征向量進行堆疊可得到n×51 200維度的聚類特征矩陣。對特征矩陣進行聚類,k個類別的聚類輸出結果為0~(k-1)個標簽,每種標簽對應一種類別。根據緊湊度選擇前m個類別對應目標區域為雜物,其余標記為正常物體。聚類過程中,選取1 200個包含橡膠、塑料、尼龍、碎紙片、泡沫等雜物的矩形框進行特征提取,獲得1 200×51 200 維度的聚類特征矩陣并進行聚類。
1.3.3 片煙雜物的狀態判斷
為避免因片煙運動導致雜物被遮擋而影響檢測精度,需要對獲取的目標雜物進一步分析。首先對已判斷為雜物的目標區域進行篩查,利用矩形框預測為雜物的概率及其相互之間的重疊比率(IoU,Intersection over Union)去除冗余框;再計算篩選后每個矩形框的中心位置,并統計此后一段時間內的雜物狀態。具體步驟為:計算當前幀圖像中目標區域(矩形框)的中心位置,根據中心位置的個數建立位置數組和狀態數組,并將當前幀的位置寫入位置數組作為第一個元素,同時將對應的狀態數組狀態值置為1。計算下一幀圖像中矩形框的中心位置,并與存儲在位置數組中的上一幀中心位置進行對比,可能有3種情況:①矩形框的中心位置與上一幀的中心位置距離小于閾值,此時將矩形框的中心位置寫入位置數組并將對應的狀態數組狀態值置為1。②矩形框的中心位置與上一幀的任意中心位置距離均大于閾值,此時新建一個位置數組和狀態數組,并將矩形框中心位置寫入位置數組,同時將對應的狀態數組狀態值置為1。③某個位置數組在下一幀圖像中沒有矩形框與之相匹配,此時根據位置數組中上一幀的中心位置以及片煙運動情況,構建一個虛擬位置寫入位置數組,同時將對應的狀態數組狀態值置為0。
經過一定時間序列t后再次對雜物進行判斷。當狀態累積值小于閾值時物體被認為是誤檢雜物,刪除其對應的位置數組和狀態數組;當狀態累積值大于閾值時,對位置數組的存儲位置進行直線擬合。如果擬合誤差大于閾值,則認為此位置數組對應雜物為誤檢雜物,刪除其對應的位置數組和狀態數組;如果擬合誤差小于閾值,則認為此位置數組對應雜物為真實雜物,輸出雜物報警并刪除其對應的位置數組和狀態數組。如圖5所示,圖像中的物體先經過顯著性目標檢測和聚類分析后確定為雜物,再經過在一定時間序列t的狀態累積后判斷是否為真實雜物,然后對新檢測雜物與已檢測到雜物進行重疊比較,剔除重復檢測的雜物。
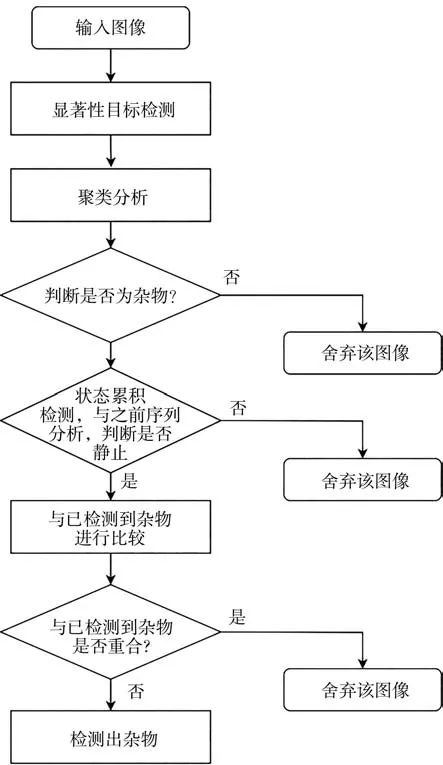
圖5 雜物檢測算法流程圖Fig.5 Flow chart of foreign matter detection algorithm
1.4 模型評估
1.4.1 顯著性目標檢測網絡模型評估
使用平均IoU 和平均絕對誤差(Mean Absolute Error,MAE)評價顯著性目標檢測網絡模型的性能,選擇顯著性目標檢測網絡BASNet[23]和U-Net[24]作為對比。MAE計算公式為:
1.4.2 聚類效果評估
在標注的數據集上對比不同參數下聚類結果對雜物檢測精度的影響,并以此為標準選取標簽m值。采用F1 分數[25]評價聚類效果,F1 分數越高,說明檢測模型性能越穩定。由文獻[26]可知,雜物聚類類別數k=10情況下,m取值范圍為1~9。F1分數計算公式為:
式中:P和R分別代表雜物檢測的精準率和召回率,%;F1分數用于評價m值對雜物檢測效果的影響。
1.5 模型訓練
實驗過程分為模型訓練和推理兩部分。其中,訓練環境用于訓練顯著性目標檢測網絡,主要算法流程在推理環境中實現。在訓練環境中,操作系統為Ubuntu16.04.6,采用2 塊GeForce RTX 2080Ti 顯卡,約20 GB內存,訓練框架為TensorFlow1.4。在實際檢測環境中,操作系統為Ubuntu16.04.6/Windows10,GPU為8 GB顯存的GeForce RTX 2080。訓練后模型采用TensorRT 框架進行推理優化部署,TensorRT 是NVIDIA公司開發的高性能GPU推理C++庫,具有高吞吐量、低延遲和低占用設備內存等優點,可有效提高深度學習模型在推理時的檢測速度,實現算法快速高效部署。
所訓練的兩級U-Net 模型輸入高、寬為320 px×320 px,輸入批次為24,初始化參數值為預訓練好的參數。采用Adam 方式優化參數,初始學習率為0.008,以指數衰減方式每8 000 步衰減1 次。首先凍結特征提取階段的網絡參數,在迭代10 000 步時開放所有網絡參數,繼續訓練至35 000 步。訓練損失函數值Loss 和步數Step變化曲線見圖6。訓練樣本的真實值為二值圖像,預測顯著圖的像素值在(0,1)范圍,0表示背景,1表示目標物體。
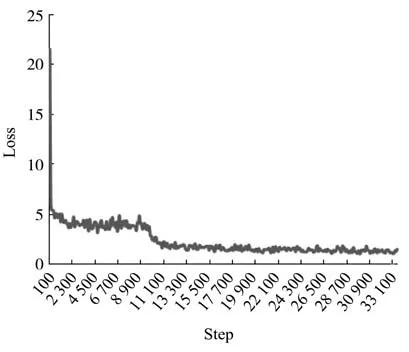
圖6 Loss-Step訓練曲線Fig.6 Loss-Step training curve
2 結果與分析
2.1 模型評估效果
將兩級U-Net 模型與U-Net 和BASNet 兩種模型的檢測性能進行對比,結果見表1。可見,兩級U-Net 模型的檢測精度均優于BASNet和U-Net。在實際檢測推理部署時,由于采用了高性能優化的TensorRT 框架,兩級U-Net 模型的檢測速度明顯優于BASNet和U-Net。由圖7可見,兩級U-Net模型的預測結果準確性顯著高于BASNet 和U-Net,其邊緣也更加精確。
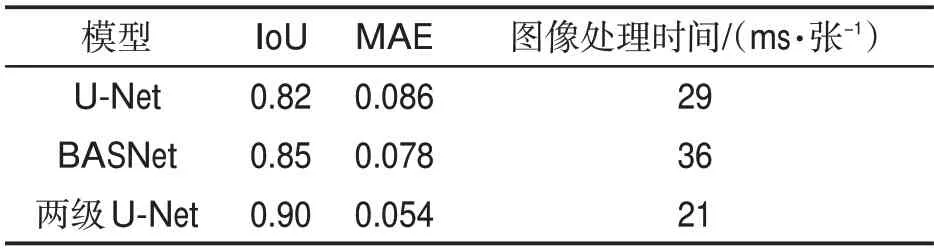
表1 不同顯著性目標檢測模型輸出結果Tab.1 Output results of different salient object detection models

圖7 不同模型顯著性目標檢測可視化結果Fig.7 Visualization results of salient object detection
2.2 聚類結果對檢測性能的影響
圖8 為不同m值下聚類結果對雜物檢測精度的影響。可見,m=5 時檢測精度最高;當m值較小時,聚類算法容易將部分與正常物體接近的雜物聚類為正常物體,故F1 分數較低;當m>5 時,隨著m值增大,聚類算法容易將部分正常物體聚類為雜物,故F1分數迅速降低。根據聚類結果的緊湊度可得標簽0~4 分別對應橡膠、塑料、尼龍、碎紙片、泡沫雜物,標簽5~(k-1)對應正常物體。
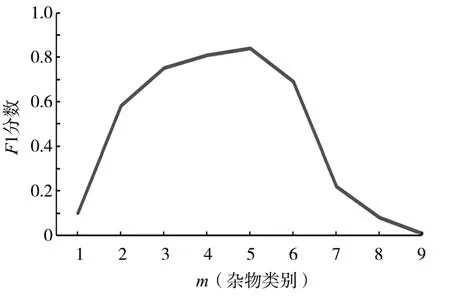
圖8 不同m值對雜物檢測效果的影響Fig.8 Influence of different m values on effectiveness of foreign matter detection
2.3 雜物檢測結果
以生產過程中的一段測試視頻為例,將訓練好的模型轉換為TensorRT 框架的引擎文件進行部署,設置當一個疑似雜物連續出現4幀時確認是雜物,檢測結果見圖9。可見,在第1幀時已檢測出疑似雜物(顯示綠色框),直到第4幀時被判定為真實雜物(顯示紅色框)并提示異常信息。

圖9 片煙雜物顯著性目標檢測可視化結果Fig.9 Visualization results of detection foreign matters in tobacco strips
2.4 雜物識別率測試
測試樣本包含生產中常見雜物尼龍、碎紙片、泡沫、橡膠和塑料各160塊。人工在正常片煙中混入各類雜物,挑選8組不同雜物數量的測試樣本,采用兩級U-Net 模型分別對8 組樣本進行識別,結果見表2。可見,8 組中雜物識別率最低為92.2%,最高為100%,平均識別率為96.6%,漏檢率均低于8%。表明兩級U-Net模型能夠對各類雜物進行準確檢測,且魯棒性較高。
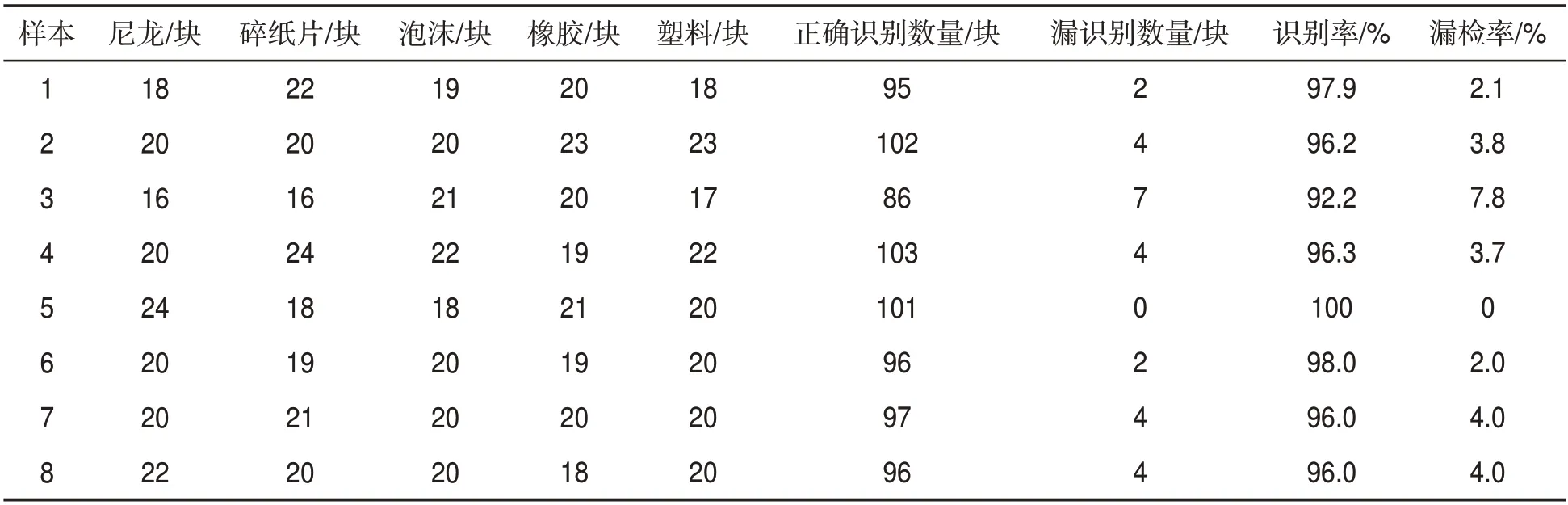
表2 片煙雜物識別測試結果Tab.2 Detection results of foreign matter identification
由表3 可見,因橡膠與片煙顏色差別較大,在測試過程中識別率達到100%;泡沫面積較大,混入片煙后形態明顯,識別率達到98.1%;碎紙片與塑料面積較小,識別率均為95.6%;而尼龍形態細長,與片煙較為相似,識別率較低,為93.8%。
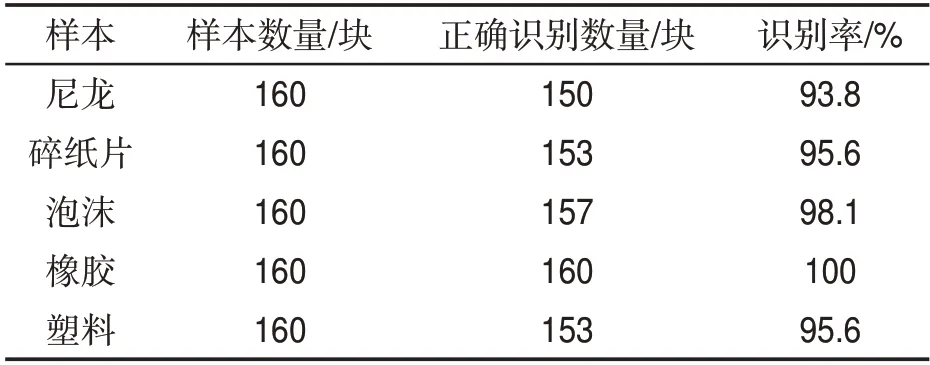
表3 不同類別雜物識別率Tab.3 Identification rates of foreign matters of different kinds
3 結論
提出了一種基于物體顯著性自監督學習的片煙雜物檢測方法。先檢測出片煙圖像中的顯著性目標,再對檢測目標進行聚類分析并剔除正常物體;然后采用基于時間序列的狀態累積檢測方法確定檢測雜物的真實度,提高雜物檢測的穩定性。結果表明:兩級U-Net 模型的平均IoU 和MAE 分別為0.90 和0.054,均優于對比的BASNet 和U-Net 模型;片煙雜物平均識別率達到96.6%;采用TensorRT 框架進行部署,圖像處理時間為21 ms/張,可以滿足現場檢測實時性要求,為實現片煙生產全自動化雜物分類識別提供支撐。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
