基于YOLOv5-Eff 網絡的織物疵點檢測算法
2023-12-19 01:55:16石玉文林富生宋志峰余聯慶
棉紡織技術 2023年12期
石玉文 林富生 宋志峰 余聯慶
(1.武漢紡織大學,湖北武漢,430200;2.三維紡織湖北省工程研究中心,湖北武漢,430200;3.湖北省數字化紡織裝備重點實驗室,湖北武漢,430200)
目前,從織物疵點目標檢測的實現技術來分,可分為傳統的機器視覺識別方法和深度學習兩大類。傳統的機器視覺疵點識別方法主要依賴于顏色或亮度、紋理等表層可辨特征,同時對于燈光或檢測背景要求苛刻,因此檢測局限性較大,算法性能存在諸多不穩定因素,這就會導致算法的檢測準確率低、小目標漏檢等問題,同時對于不同背景、不同種類織物的泛化能力較弱。隨著工業智能化快速發展,利用人工智能技術[1-3]迅速準確地完成對織物疵點的自動識別,已經成為智能裝配領域研究的熱點。
近年來,隨著深度學習技術的快速發展,上述問題得到一定程度的解決。羅俊麗等[4]提出將YOLOv5 的特征金字塔網絡模塊替換為雙向特征金字塔網絡來增強算法對不同尺度特征提取的泛化能力;蔡兆信等[5]提出改進Faster RCNN 網絡的RPN 結構,融合多層不同尺度特征圖,增加了圖像細節提取的能力;黃漢林等[6]提出了以MobileNet 網絡結構代替SSD 算法中的特征提取部分的方法,提高了SSD 算法的運行效率;李楊等[7]提出了一種基于深度信念網絡的織物疵點檢測方法,用改進的受限玻爾茲曼機模型對深度信念網絡進行訓練,完成模型識別參數的構建,完成了在復雜環境下織物疵點檢測的任務;胡越杰等[8]提出了用ResDCN 替代YOLO 網絡中的殘差單元來增強網絡模型的特征提取能力,使得YOLOv5 網絡的準確率提高了4.99 個百分點。
盡管許多學者已經提出了各種不同的織物疵點檢測方法,并取得了一定的成果,但仍存在兩個主要問題。首先,由于織物疵點的類型多樣并且分布不均勻,導致檢測難度增大;其次,織物疵點通常為小目標且形狀多變,使得識別較為困難。本研究提出了一種改進的YOLOv5 織物疵點檢測算法,即YOLOv5-Eff。在算法中引入了改進的EfficientNet[9]模塊來替換原有的特征提取網絡,同時結合了Swish 動態激活函數來優化模型,設計了ACmix 注意力模塊,使得網絡能夠捕獲更多疵點的特征信息以提高對小目標疵點的敏感度。
1 YOLOv5 網絡結構
在現有的目標檢測算法中,YOLOv5 因其速度高和準確率較高等特點而得到廣泛應用。YOLOv5 目標檢測模型如圖1 所示。在輸入端,采用了mosaic 數據增強方式,將包含目標的4 張圖片拼接成1 張圖片。這樣新的圖片中包含了4 種具有相同背景的目標,大大豐富了被檢測物體的背景,加快了圖片的讀取速度,并且增強了網絡的魯棒性。在特征提取部分,引入了Focus 結構,將原始的512×512×3 輸入圖像切片后生成256×256×12 特征圖,在不丟失任何信息的情況下獲得了兩倍的下采樣特征圖。特征融合部分結合了路 徑 聚 合 網 絡(PAN)[10]和 特 征 金 字 塔 網 絡(FPN)[11]。FPN 網絡從頂部向下傳遞并與主干特征提取網絡的特征圖進行融合,傳遞深層次的語義信息。PAN 網絡從底部向上傳遞目標位置信息。這種方式更利于模型學習目標特征,減少了底層特征信息的丟失,并增強了模型對小目標的敏感度。
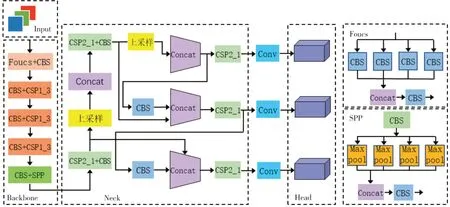
圖1 YOLOv5 網絡結構
2 YOLOv5 模型改進
2.1 嵌入Swish 激活函數
本研究采用兩種激活函數,在保持原有YOLOv5 網絡Neck 層和Head 層SiLU 激活函數的基礎上引入改進版Swish 激活函數。傳統的YOLOv5 網絡結構使用的是SiLU 激活函數,與RELU[12]激活函數類似,都屬于靜態函數,對所有輸入數據都執行相同操作,并產生大量的冗余數據。在輸入負值越大的情況下,其對結果的影響逐漸增加。為了避免負樣本對訓練精度的過大影響,引入可學習參數β的Swish 激活函數,如式(1)所示。
與LeakyReLU[13]激活函數相比,Swish 函數在負無窮方向上更加平滑,在保持有負樣本輸入的前提下,減弱了其對整個網絡的影響。這樣不僅允許信息更深入地傳播到網絡中,同時也提高了網絡的效率。
2.2 設計ACmix 注意力模塊
在執行注意力機制時,卷積注意力模塊優先處理輸入與輸出之間的交互關系,而自注意力模塊則著重于輸入間的內部關聯。本研究受CoAt-Net[14]網絡的啟發,融合自注意力和卷積注意力的優勢,設計ACmix 注意力模塊,旨在提高網絡對微小目標的敏感度。ACmix 注意力模塊如圖2所示。
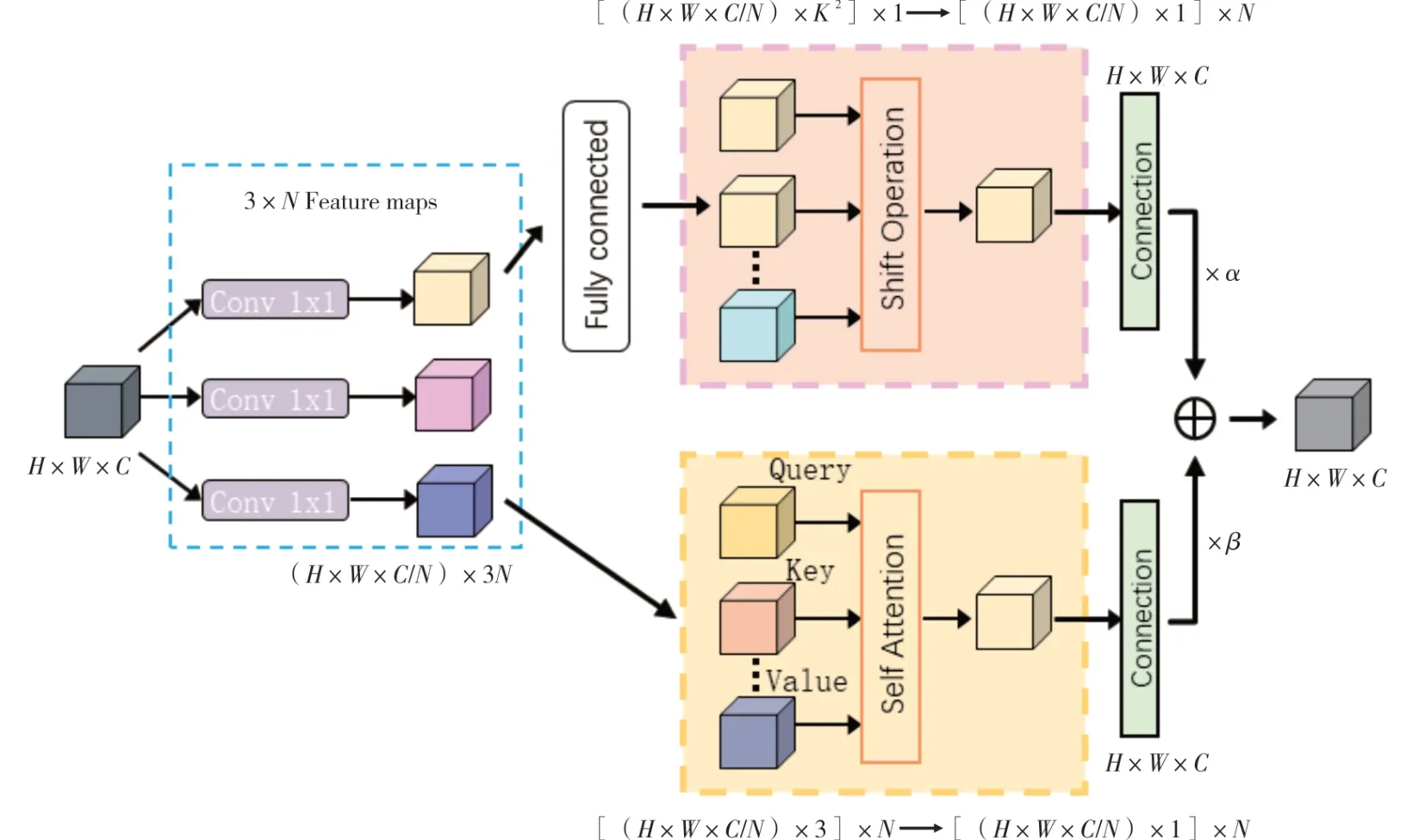
圖2 ACmix 注意力模塊
ACmix 注意力模塊由卷積注意力和自注意力兩個模塊并行構建,原理如下。先將H×W×C的特征通過3 個1×1×C的卷積進行映射,分割為N個部分,得到3×N個尺寸為H×W×C/N的子特征。在上半部分(以K為內核的卷積路徑),網絡如同傳統的卷積注意力模塊,從局部感受野中抽取信息,子特征通過3N×K2N的全連接層,對生成的特征進行位移、融合和卷積處理,從而得到H×W×C/N的特征,共N組。而在下半部分(自注意路徑),網絡在全局信息的考量下,同時關注關鍵區域。3N個子特征對應的3 個H×W×C/N尺寸的特征圖各自充當查詢、鍵和值的功能,嚴格遵從傳統的多頭自注意力模型。通過位移、聚合和卷積處理后,得到H×W×C的特征。接著,兩條路徑的輸出經過Concat 操作,其強度由兩個可學習的標量控制,如公式(2)所示。
式中:Fout指代路徑的最終輸出;Fatt指代自注意力分支的輸出;Fconv代表卷積注意力分支的輸出;參數α和β的值均設為1。兩個分支的輸出在合并之后,全局特征與局部特征得到了平衡的考慮,從而增強網絡對微小目標的識別能力。
2.3 網絡結構的改進
YOLOv5 的特征抽取網絡主要基于CSPDarknet 結構,該框架在輸入圖像上進行下采樣處理,這可能導致小目標的信息遺失,因此對于小尺寸疵點的檢測YOLOv5 可能表現出一些局限性。此外,YOLOv5 的特征抽取網絡采用了深度卷積層設計,使得感受野逐步擴大。然而,這樣的擴大感受野可能會使得目標檢測算法對目標的局部精細特征敏感性降低,特別是對于具有精細紋理特征的目標。
為了解決這些問題,本研究在特征提取階段引入了優化后的EfficientNet 網絡結構作為YOLOv5 的檢測網絡。EfficientNet 的基礎卷積模塊稱為移動倒置瓶頸卷積(MBConv)模塊,包含1×1 升維卷積層(Conv)、批量歸一化(BN)、隨機失活(Dropout)、深度卷積(DWConv)、1×1 降維卷積層(Conv)以及殘差連接等,結構如圖3所示。

圖3 MBConv 結構
本研究選用EfficientNet B1 進行改進作為特征提取網絡,通過融入ACmix 注意力機制來彌補YOLOv5 在特征抽取細節方面的不足。假設輸入圖像的維度為H×W×C,首先,通過全局平均池化和全連接層將其轉換為1×1×C的形狀,然后將其與原始圖像進行逐元素乘法,以賦予每個通道相應的權重,因此通過嵌入ACmix 注意力機制,使得網絡可以了解到更多疵點的特征信息。此外,EfficientNet B1 網 絡的MBConv 模 塊 中 在兩個完整的連接層之間增加了Swish 激活函數,以加快算法的收斂速度,改進MBConv 結構如圖4 所示。本研究改進的YOLOv5 網絡結構如圖5所示。

圖4 改進MBConv 結構

圖5 改進的YOLOv5 網絡結構
3 試驗材料與方法
3.1 數據集
本研究樣本來自于阿里云天池數據集和江蘇某紡織企業,融合兩個數據集構成一個包含1 780張540 pixel×450 pixel 彩色圖像的數據集。針對疵點數據量少的問題,本研究采取數據翻轉、數據旋轉、數據縮放和增加顏色4 種處理的方法對織物疵點數據集進行擴容處理,以增加樣本數量,擴充后的數據集共7 120 張。在擴充后根據疵點的長度面積以及出現的頻率,將織物疵點分為2個大類6個小類,缺紗、斷紗、錯紗為線類疵點;污漬、磨花、結頭為點類疵點。本試驗按照9∶1 劃分訓練集和驗證集。
3.2 試驗環境及參數設定
本研究試驗環境為64 位Win10 操作系統,NVIDIA GeForce RTX3080 顯 卡,CPU 為Inter(R)Core(TM)i7-7700。編程語言為Python,深度學習框架為Pytorch。
為了保證模型訓練的精度,防止訓練過程中過擬合的現象發生,訓練時采用YOLOv5 原始網絡提供的預訓練權重來訓練本研究網絡,以加快網絡的收斂速度。在訓練過程中采用標簽平滑技術,將整個訓練過程分為兩個階段。第一階段采用凍結訓練的方式,將學習率設置為0.001,批處理大小為6,并進行10 個epoch 的訓練。第二階段進行解凍訓練,使用了SGD(隨機梯度下降)[15]方法,以防止模型陷入局部最優解。此外采用了余弦學習率衰減方法,將最大學習率改為0.01,最小學習率改為0.000 1,批處理大小設置為3。
3.3 評價指標
為量化改進YOLOv5 模型對小目標疵點和復雜背景下檢測的優越性,本研究采用3 個常用的目標檢測評價指標:精確率(P)、召回率(R)和平均精度均值(mAP)。
4 結果與分析
4.1 消融試驗
選 用EfficientNet B1、ACmix、Swish 方法 分別作為獨立的變量模塊,在相同的環境及訓練技巧的前提下,研究各個模塊在YOLOv5 網絡的改進效果。表1 為消融試驗結果。

表1 消融試驗
由表1 可看出,選用EfficientNet B1、ACmix、Swish 單個模塊均能達到預期的效果,將EfficientNet B1 作為檢測頭后模型的精確率P、召回率R、平均精度均值mAP相比原始YOLOv5 算法分別提升了1.56 個百分點、1.04 個百分點、0.57個百分點;加入ACmix 后模型的P、R、mAP相比原始YOLOv5 算法分別提升了2.43 個百分點、0.86 個百分點、0.66 個百分點,說明加入注意力機制后,模型加強了疵點目標區域檢測,增加了模型對疵點目標的準確率。加入Swish 激活函數后mAP相比原始YOLOv5 提升了2.64 個百分點,也表明Swish 在引入了較少的參數情況下有效地提升了模型性能。
4.2 模型對比試驗
為驗證本研究算法的實用性和先進性,在同一試驗環境下對比了YOLOv5、SSD、Faster RCNN和EfficientNet B1 4 種模型,結果如表2 所示。

表2 不同模型的試驗結果對比
由表2 可知,與EfficientNet B1、SSD 算法相比,本研究算法mAP值分別提高了5.08 個百分點、6.81 個百分點。Faster RCNN、YOLOv5 網絡雖然P、R均達到了90%以上,但和本研究算法相比仍有一定差距。綜合衡量不同的檢測算法,本研究算法在無明顯影響檢測速度的前提下,具有較大的優勢圖6 展示了5 種算法在同一環境下分別進行疵點識別的部分檢測結果。可以看出,Efficient-Net B1 網絡雖可以檢測到較小疵點以及多個疵點目標,但對于疵點區域的定位精度不高,容易造成較高的錯誤率。SSD 網絡對于檢測環境要求較高,容易受到燈光影響,所以對于線類疵點和小疵點這種與圖片背景對比度不高的疵點容易漏檢。Faster RCNN 網絡在檢測單一疵點時可表現出良好的檢測效果,但受錨框固定的參數影響不能完全適應多個疵點目標,降低了模型檢測效果。YOLOv5 網絡算法對于小疵點目標不夠敏感,并且在多個疵點同時出現時定位不準。本研究算法在織物疵點檢測方面有顯著效果,特別是在疵點分類和檢測準確率方面,相比于原始YOLOv5 算法,雖犧牲了1.6 ms 的檢測時間,但解決了網絡對小疵點不敏感、多目標定位不準的問題,滿足了工業要求。

圖6 模型檢測對比試驗
5 結論
本研究提出了一種基于改進后的YOLOv5織物疵點檢測算法,通過將原網絡的檢測頭替換為EfficientNet B1 來增強特征提取能力;將注意力機制ACmix 模型嵌入YOLOv5 模型中,顯著提高了模型在多種場景下的疵點檢測性能;使用Si-LU 和Swish 兩種激活函數,使得預測框回歸更精準,并提高網絡的魯棒性;在疵點目標檢測這一單一場景下,過濾了分類損失,提高了網絡的抗干擾能力;為了降低過擬合風險,采用了幾何變換等數據增強技術;采用了余弦學習率衰減法和隨機梯度下降法,以防止模型陷入局部最優解并確保模型精確收斂。試驗結果表明:本研究模型在對小目標的提取能力和精確率方面取得了顯著提升。本研究算法的P、R和mAP值分別為96.47%、97.18%和81.33%,相比于原始YOLOv5,本研究算法的P、R和mAP分別提升了4.33 個百分點、2.11 個百分點和4.32 個百分點,可滿足實際部署中小目標和檢測的實時性等需求。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
