基于分子生成模型的SOS1抑制劑衍生物設計
2023-12-18 18:13:49成凱陽胡晨駿胡孔法
計算機時代 2023年11期
成凱陽 胡晨駿 胡孔法


關鍵詞:數據增強;強化學習;虛擬篩選;多樣性
中圖分類號:TP399 文獻標識碼A 文章編號:1006-8228(2023)11-94-06
0 引言
在傳統的藥物設計中,藥化專家通過實驗及高通量篩選(High Throughput Screening,HTS)[1]從而發現具有潛在活性的化合物。然而僅通過實驗方法篩選藥物,耗時耗力,以計算機輔助藥物設計(Computer-Aided Drug Design,CADD)[2]或通過AI 算法設計更多類藥化合物已成為藥物研究的重要內容。
近年來,以分子生成模型為代表的藥物設計方法為先導化合物發現和優化提供了新途徑。如AMABILINO等人提出的遞歸神經網絡(Recurrent Neural Network,RNN)運用遷移學習方法擴展化合物庫[3],但也存在一些問題,即當時間步長較大或循環網絡層數較深時,RNN 在采樣分子時可能會出現梯度消失或梯度爆炸的情況,導致模型生成有效分子數量較少。此外,Bagal 等人提出的Transformer 模型[4]使用了自注意力機制,具有處理長序列的能力和并行計算的優勢。但在生成過程中,通常使用固定的采樣策略生成序列,這可能導致生成的分子缺乏多樣性。
由于激酶靶點的成藥性高,本文選擇SOS1 靶點進行設計與研究[5]。通過設計SOS1 抑制劑的衍生物希望發現潛在能抑制SOS1 活性的藥物,從而抑制腫瘤細胞的生長和擴散。因此,本文提出一種結合RNN與Transformer 的R-T 算法來設計分子,該方法避免了單獨使用RNN 所存在的梯度消失的問題。通過減少模型的復雜度,可以實現更快的訓練收斂速度,相較于Transformer 可以生成更多樣化的分子序列。此外,進一步運用SMILES 枚舉的數據增強方法擴充數據集以生成更多樣化的分子結構。最后用SOS1 抑制劑對R-T 模型進行微調,并以MRTX0902 為例來設計其衍生物,從而為激酶抑制劑的研究和開發提供新的思路和方法。
1 生成模型相關工作
在分子生成領域中,Blaschke 等人提出的變分自編碼器(Variational Autoencoders,VAE)架構[6],該方法通過對編碼器的隱空間進行優化,并加入正態分布的噪聲以及懲罰,以減少重構誤差的方式生成與多巴胺受體(DDR2)化合物屬性分布近似的化合物。實驗證明,基于隱空間優化的方法在指導化合物優化目標屬性方面具有顯著效果。
此外,Segler 等人[7]首次利用RNN 模型運用于分子生成并證明了該方法的可靠性,先是利用大規模的生物活性數據對RNN 模型進行預訓練,然后根據PPARγ 靶標的活性化合物對模型做進一步的微調從而設計靶向PPARγ 的化合物。Kim 等人提出的Transformer 模型[8]在生成分子的有效性及新穎性上相較于RNN 更有優勢,由于其多頭注意力機制及并行計算的能力使得在少量訓練輪次即可達到收斂狀態。同時,相關研究發現,通過對SMILES 枚舉的方法可以較好地實現生成分子的多樣性[9]。因此本文運用數據增強方法,先對Transformer 模型做預訓練,并將其采樣的分子通過調整RNN 模型參數來生成更多樣化的化學結構。
2 數據收集及預處理
首先從ChEMBL 數據庫[10]中下載70 萬條SMILES格式的分子,數據預處理流程如圖1A 所示,首先過濾掉同位素及相同結構的分子,并進一步移除PAINS 結構以及不滿足于類藥五原則的分子,最終得到50112個分子。其中類藥五原則為Lipinski[11]等人提出的篩選類藥分子的五條基本法則。此外,微調數據集為ChEMBL 中現有對SOS1 靶標有pIC50 值的1329 個分子,并從中篩選掉多羥基、重原子數量大于40 及pIC50小于4.5,最終得到222 個分子(圖1B)。
3 模型改進方法
3.1 R-T 算法流程
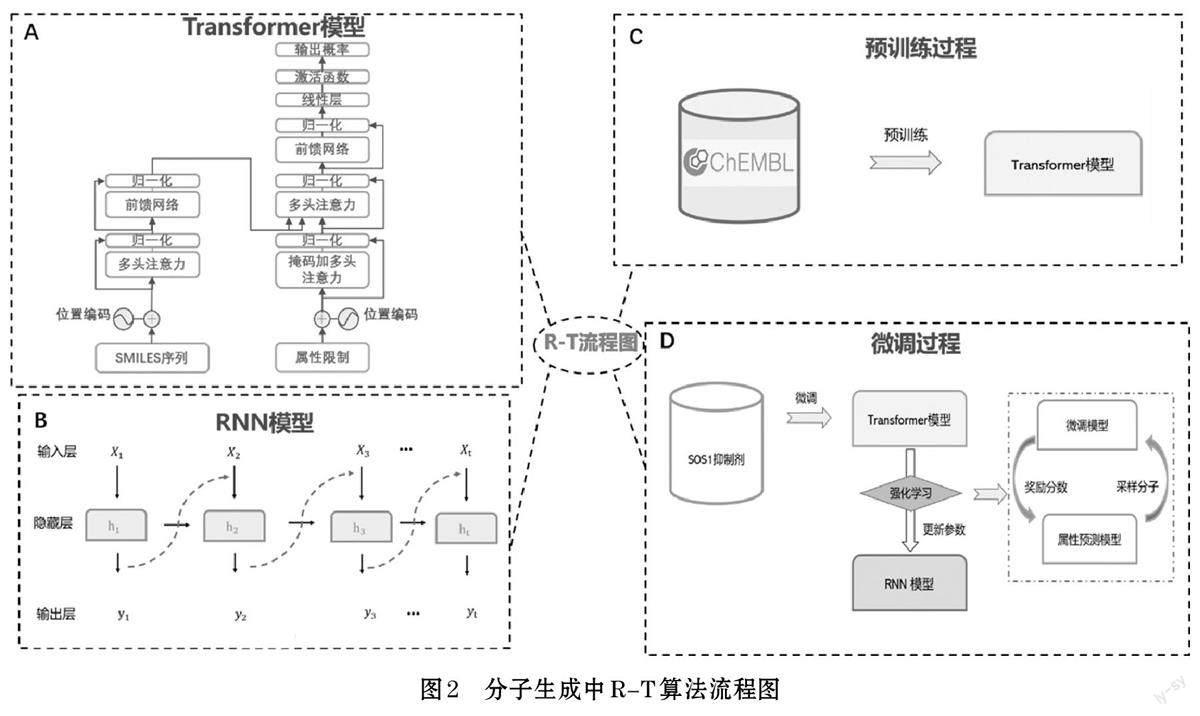
本文所用的R-T算法框架如圖2所示,Transformer模型及RNN 模型如圖2A 和圖2B 所示,其中RNN 模型由輸入層,隱藏層及輸出層所組成。Transformer 模塊是由編碼塊以及解碼塊堆疊而成。每個編碼塊包含一個多頭注意力層和一個前饋網絡(feed forwardnetwork,FFN)。在解碼塊中有三個子層,分別是掩碼加自注意力子層、多頭編碼器-解碼器注意力子層和前饋網絡子層。其中多頭自注意力可以捕捉到全局的依賴關系,通過位置編碼使得模型能夠關注輸入SMILES 序列中每個字符的位置信息,并將相關信息傳遞給后續的層。
首先,本文用預處理后的數據集對Transformer 模型進行預訓練(圖2C),并用SOS1抑制劑來對Transformer模型進行微調,從而使R-T 學習這批分子的屬性分布。其次,根據強化學習方法將Transformer 對RNN模型進行蒸餾,從而指導RNN 模型采樣分子,并不斷迭代來更新模型參數,使得在較少的訓練輪次下采樣出期望屬性的分子(圖2D)。
分子相似性表示為基于拓撲指紋和谷本相似性方法指紋計算分子之間的相似性,即將分子轉化(編碼)為比特位串,若存在該子結構則該位為1,否則為0。本文選用兩個分子表示向量之間的Tanimoto 距離來表示兩個分子間的相似性分數。
此外,本實驗選擇了MOSES 提供的評價指標[15]來評價生成分子的屬性分布。包括logP(the octanolwaterpartition coefficient, 脂水分配系數),SAscore(Synthetic Accessibility Score,合成可及性),用來評價合成的難易,該指標范圍在1 到10 區間內,越低越易于合成。
4.2 實驗設置
本文采用Colab pro Tesla V100(32G),為了防止訓練時產生過擬合,引入了早停機制,即當驗證集的損失在20 個epoch 不下降就停止訓練,具體參數如表1 所示。
4.3 具體實驗過程
4.3.1 模型訓練的損失曲線
本文設置預訓練輪數為120 次,由圖3 可知,我們可視化了R-T 模型在訓練集和驗證集的損失曲線。第100 個輪次損失值降低到0.06,并保持20 個輪次不變,至此預訓練過程結束。
4.3.2 預訓練模型比較
為了比較R-T 方法在分子生成中的優勢,分別對RNN、Transformer 及Blaschke 等人提出的VAE 模型進行預訓練,在訓練完畢后,對上述三種方法隨機采樣10000 個分子來比較生成分子的質量。如表2 所示,可以發現,R-T 模型的四個指標都在0.9 以上,且在多樣性、唯一性、新穎性指標中,R-T 相較于僅使用單一模型上效果更好。具體而言,在多樣性指標中,相較于排名第二的Transformer 增長了0.053,而在合法性指標中也僅次于最優值0.016。由此可見,R-T 模型生成的分子質量相較于上述方法有競爭性的優勢。
4.3.3 數據增強方法比較
對于阿司匹林(Aspirin)藥物分子而言,雖然以不同的原子作為起點出發遍歷分子圖得到不一樣的SMILES,但是最終的分子圖是一樣的(圖4)。
為了驗證不同的數據增強方法是否可以改善R-T模型生成分子的多樣性,首先根據SMILES 枚舉算法將預訓練數據集中的每個分子都分別枚舉五次和十次,并與不采用數據增強方法構成的訓練集來分別訓練R-T 模型。預訓練結束后,再從三個模型中分別采樣了1000 個分子。首先為每個分子提取了其1024 位的分子指紋向量。隨后,使用t-SNE 算法對分子表征進行降維,并通過可視化展示來展現他們的化學空間分布。如圖5 所示,基于枚舉十次的方法訓練出的RT模型采樣得到的新穎結構基本上覆蓋了前兩種采樣方法得到的化學空間,且覆蓋面積更廣,可見該方法生成的分子較上述方法更多樣化。
4.3.4 MRTX0902 分子衍生物設計
MRTX0902 是目前已報道的口服SOS1 抑制劑,有助于阻斷異常的細胞增殖和轉移過程[16]。本研究以它為例通過強化學習方法來設計其衍生物[17]。具體而言,首先設置生成分子與MRTX0902 相似性分數之間的閾值為0.5,模型在生成的過程中會將相似性評分值大于0.5 的給予一個較高的獎勵值,并將滿足條件的分子保留下來,直到數量達到設定值則停止迭代。與之類比,從Specs 數據庫[18]中搜索與MRTX0902 相似度大于0.5 的分子。并且根據搜索時間、搜索數量、分子多樣性及可合成性來比較R-T 方法相較于搜索化合物庫的顯著優勢[19]。本研究首先從Specs 中隨機采樣50000、100000、150000 個分子來作為基準比較。Specs 庫的搜索時間為遍歷整個化合物庫所需時間,R-T 的搜索時間為生成滿足數量的分子所需時間,在這里設定生成分子的數量為10000。結果如表3 所示,R-T 方法在時間略遜色于上述三種篩選方法的情況下,能夠生成數量、多樣性遠超基于Specs 庫的搜索方法,且可合成性分數更低,可見該方法的優勢。此外,如圖6 所示,還可視化了R-T 方法生成的四個與MRTX0902 相似度較高的化合物,其中紅框標記的化合物出現于Reaxy 數據庫中,可見該方法生成分子的合理性及可靠性,有助于擴展現有的化合物庫,彌補虛擬篩選化合物庫[20]多樣性不足的問題。
4.4 實驗總結
改進的R-T 算法使用強化學習方法來設計SOS1 抑制劑的衍生物,改善了傳統虛擬篩選方法中篩選與SOS1抑制劑結構相似且新穎的化合物數量不足的問題。實驗結果表明,相較于僅使用單一模型的情況下,R-T算法在生成分子的唯一性、合法性、新穎性和多樣性方面具有明顯的優勢。此外,相較于未使用SMILES枚舉的數據增強方法,通過對預訓練集進行數據增強可以使得生成的化合物具有更高的多樣性。同時,在設計MRTX0902 小分子衍生物時,R-T 模型可以快速生成數量更多、更多樣化且易于合成的結構,從而更好地填補現有化合物庫所涉及的化學空間不足的問題。
5 結束語
本文采用強化學習方法,來設計SOS1 抑制劑的衍生物。首先通過海量分子對Transformer 模型進行訓練,再調整RNN 模型的參數從而生成更多樣的化合物。實驗數據顯示,改進的R-T 算法性能相較于單獨使用一種模型生成分子的質量明顯更優。此外還比較了使用數據增強擴充訓練集的方法設計分子的優勢,表明該增強方法的有效性。進一步,與虛擬篩選的相似性搜索策略相比,發現改進的R-T 算法在生成分子的多樣性和數量方面較有優勢。總之,該方法為藥物化學專家進行先導化合物的優化提供了便利。未來的研究,將繼續探索在不同的激酶數據集上設計和優化小分子衍生物的能力。
