基于EEMD 近似熵與神經(jīng)網(wǎng)絡(luò)的管道故障識別研究
2023-12-12 14:58:48楊磊
中國設(shè)備工程 2023年23期
楊磊
(昆明工業(yè)職業(yè)技術(shù)學院,云南 昆明 650302)
基金項目:本文系2022 年度云南省教育廳科學研究基金項目“基于管道協(xié)同創(chuàng)新中心校企共研的VMD 樣本熵集成學習管道泄漏故障識別研究”(2022J1431 )研究成果。
運輸管道運行環(huán)境復雜多變,當管道發(fā)生故障時,故障信號很難收集和識別。因此,本文提出采用通過模擬實驗獲取不同類型的3 類信號:金屬棒敲擊、砂紙和斷鉛3 種聲發(fā)射聲源信號。對獲得的實驗數(shù)據(jù)進行EEMD分解,并求取近似熵作為特征向量,應用BP 和PNN 進行信號識別,對比基于EEMD 近似熵和BP 故障識別和基于EEMD 近似熵和PNN 故障識別的識別率。
1 EEMD 基本理論
由Huang 等提出了經(jīng)驗模態(tài)分解(Empirical Mode Decomposition,EMD)是一種自適應信號分解方法。EMD 方法不需要選擇基函數(shù),根據(jù)信號特征自適應地將其分解為一組固有模態(tài)函數(shù)分量,在非平穩(wěn)、非線性信號處理領(lǐng)域得到了廣泛的應用。由于其對信號的間歇性等復雜問題存模態(tài)混疊問題,致使信號分解結(jié)果失真,在復雜的信號處理場合受到了限制。為了克服EMD 存在的缺點,Wu 和Huang 提出了一種新的添加噪聲的EEMD 方法—聚合經(jīng)驗模態(tài)分 解(Ensemble Empirical Mode Decomposition,EEMD),EEMD 在改善模態(tài)混疊方面取得了較大進展。
EEMD 分解方法的具體步驟如圖1。

圖1 EEMD 方法算法流程圖
2 近似熵特征向量提取
近似熵(A p p r o x i m a t e Entropy ApEn)指的是由Pincus 根據(jù)k 氏熵的定義將近似熵函數(shù)定義為相似性的向量,相對原始化的信號,隨機化的信號衍生的一系列信號具有更高的熵值,即使原始隨機信號可能代表在多個不同時空空間尺度上具有相關(guān)性結(jié)構(gòu)的復雜動力學信息輸出。但是,這種產(chǎn)生原始衍生信號的技術(shù)旨在徹底打破衍生信號間的復雜聯(lián)系,從而大大降低了原始衍生信號過程中的復雜信息量。近似熵計算原理如圖2 所示。

圖2 近似熵原理圖
近似熵的算法表述如下:
(1)設(shè)存在一個以等時間間隔采樣獲得的m 維向量x(i);
(2) 計 算 向 量x(i)與 其 他 向 量的距離;
(3)給定閾值r(r>0),r一般為0.2,對每個ci統(tǒng)計dij<r的數(shù)目;并計算出總數(shù)(N-M)與數(shù)目的比值,記作即:
得到近似熵估計值,并記作:
滿足:
假設(shè)有n個樣本,第i樣本所計算出來的近似熵特征為:
所有樣本所計算出來的近似熵共同構(gòu)成了近似熵特征矩陣:
近似熵特征矩陣:
3 BP 神經(jīng)網(wǎng)絡(luò)
3.1 BP 網(wǎng)絡(luò)結(jié)構(gòu)和模型
1986 年由Rumelhart 和McCelland 為首的科學家小組提出BP(Back Propagation)神經(jīng)網(wǎng)絡(luò),BP 神經(jīng)網(wǎng)絡(luò)需要進行學習和存儲輸入-輸出關(guān)系,當通過不斷的訓練,調(diào)整不同的參數(shù)后,得到合適的訓練函數(shù)和參數(shù)后,形成高識別率的運算模式,這時再輸入測試信號,將得到最終所需要的識別效果。
BP 神經(jīng)網(wǎng)絡(luò)包含3 層結(jié)構(gòu)。所建立的BP 神經(jīng)網(wǎng)絡(luò)各層神經(jīng)元個數(shù)隨著樣本類別個數(shù)和輸入樣本的維度不同也會相應改變。樣本的維度決定了輸入層神經(jīng)元的個數(shù),同時,因本文是設(shè)置3 種故障識別,所以輸出層神經(jīng)元的個數(shù)決定了樣本分類個數(shù)為3 類。
3.2 BP 神經(jīng)網(wǎng)絡(luò)學習流程
BP 神經(jīng)網(wǎng)絡(luò)算法的學習步驟如圖3。
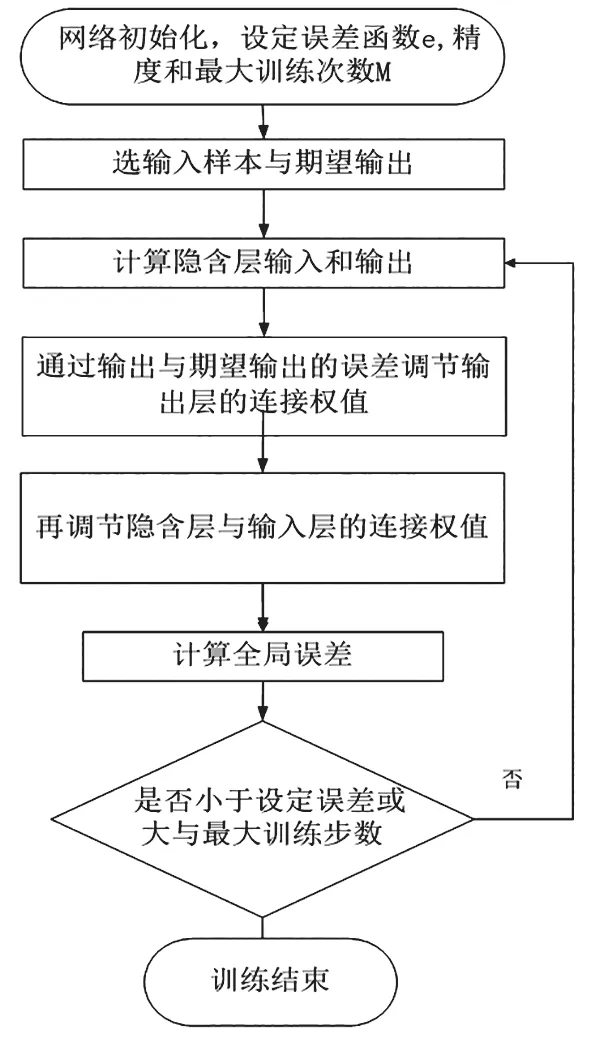
圖3 BP 神經(jīng)網(wǎng)絡(luò)算法過程
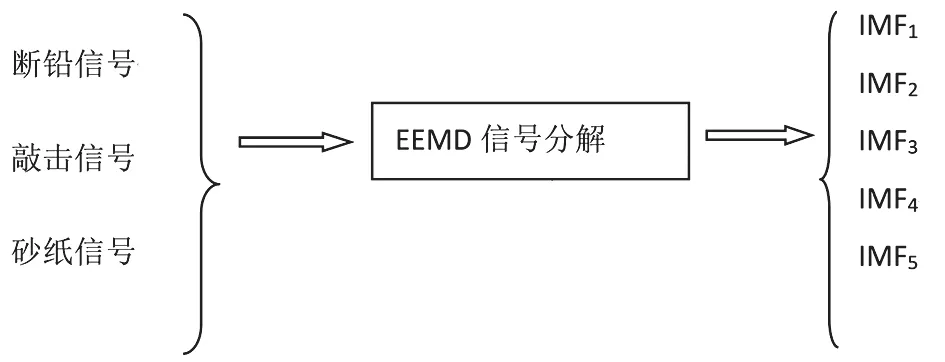
圖4 斷鉛、敲擊、砂紙3 種信號經(jīng)EEMD 分解的IMF 分量
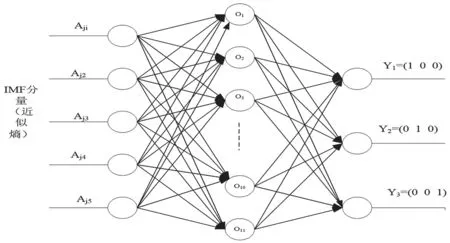
圖5 BP 神經(jīng)網(wǎng)絡(luò)的具體結(jié)構(gòu)
4 故障仿真
基于EEMD 近似熵和BP、PNN 故障識別步驟如下。
(1)采集斷鉛、敲擊、砂紙3 種故障信號。
(2)用EEMD 方法對采集的信號進行分解,之后數(shù)據(jù)求取近似熵并進行歸一化處理。
(3)選取一定數(shù)量的訓練樣本進行程序測試,然后再輸入測試樣本,分別用BP 和PNN 網(wǎng)絡(luò)進行識別,得出實驗結(jié)果,比較不同神經(jīng)網(wǎng)絡(luò)的識別率。
4.1 信號處理和特征向量求取
經(jīng)EEMD 分解后斷鉛、敲擊、砂紙信號分解出來的IMF 分量,除了第一個為原始信號分量,前5 個IMF 分量包含故障信號的主要信息,又因為EEMD 方法對相應故障分量進行分解后,分解出的分量比較多,經(jīng)過比較分析后取EEMD分解得到的前6個IMF分量來提取特征值,第一列的分量跟原始信號分量相同,所以我們?nèi)〉诙械姆至孔鳛镮MF1 分量。
4.2 基于EEMD 近似熵和BP 故障識別
BP 網(wǎng)絡(luò)包括輸入層、隱含層和輸出層,而輸入層的個數(shù)由輸入數(shù)據(jù)的維數(shù)決定,所以對于每個樣本特征向量維數(shù)為都5,故障類別為3 類。
近似熵為特征向量,BP 神經(jīng)網(wǎng)絡(luò)訓練與測試過程:每種信號共有60 組近似熵樣本,每種故障隨機選出40組向量,3 種共120 組作為訓練樣本;每種故障隨機選出20 組特征向量,3 種共60 組作為測試樣本,設(shè)置BP 神經(jīng)網(wǎng)絡(luò)參數(shù)為:訓練次數(shù)為1000,訓練目標為0.01,學習速率為0.1。
設(shè)定訓練樣本為輸入量X,用BP 網(wǎng)絡(luò)進行訓練,比較實際輸出Y與期望輸出iY的差值大小,若差值大于設(shè)定值,則網(wǎng)絡(luò)會自動調(diào)整連接權(quán)值Wih、Whj和閾值,最終使輸出達到或接近期望值,此時,BP 網(wǎng)絡(luò)就是實驗所需要的測試網(wǎng)絡(luò)。
試驗結(jié)果,BP 網(wǎng)絡(luò)斷鉛信號的識別率為75%,識別率居中;敲擊故障的識別率為85%,識別率較高;砂紙信號的識別率為65%,識別率最低。基于EEMD 近似熵和BP 神經(jīng)網(wǎng)絡(luò)對斷鉛、砂紙、敲擊的識別率高低分別為:敲擊>斷鉛>砂紙。
4.3 基于EEMD 近似熵和PNN 故障識別
為了進行對比,我們用PNN 來做聲發(fā)射故障識別。概率神經(jīng)網(wǎng)絡(luò)(Probabilistic Neural Network,PNN)最早是由D.F.Speeht 博士在1989 年首先正式提出,是優(yōu)徑向自由基神經(jīng)網(wǎng)絡(luò)的一個重要分支,屬于徑向前饋神經(jīng)網(wǎng)絡(luò)的一種。它具有以下幾大點;學習程序過程簡單、訓練過程速度快;準確分類,容錯性好等。從技術(shù)本質(zhì)上看,它只是屬于一種有嚴格監(jiān)督的新型分類器,基于貝葉斯最小風險準則。PNN 的層次模型,由輸入層、模式層、求和層、輸出層共4 層組成。
由于每個樣本中特征向量維數(shù)為5,故障信號為3類,因此本章中PNN 神經(jīng)網(wǎng)絡(luò)的輸入層采用5 個神經(jīng)單元,分別對應輸入的特征向量為Aj1,Aj2,…,Aj5;PNN 網(wǎng)絡(luò)的輸出層為3 個輸出神經(jīng)單元,分別對應輸出的特征向量為數(shù)據(jù)斷鉛Y1、數(shù)據(jù)敲擊Y2、數(shù)據(jù)砂紙Y3。
以近似熵為特征向量,PNN 概率神經(jīng)網(wǎng)絡(luò)訓練與測試過程:每種信號共有60 組近似熵特征向量,每種故障隨機選出40 組向量,三種共120 組做為訓練樣本;每種故障隨機選出20 組特征向量,三種共60 組作為測試樣本。
通過試驗發(fā)現(xiàn),對于60 組測試樣本,對于斷鉛故障信號識別率為PNN 網(wǎng)絡(luò)識別結(jié)果60%,較相同條件下BP 識別率(75%)有所降低;敲擊故障信號識別率為85%,與相同條件下BP 識別率(85%)相同;砂紙故障信號識別率為70%,較相同條件下BP 識別率(65%)有所提高。綜合識別率為,PNN 故障信號識別率(71.67%)低于BP 故障信號識別率(75%)。
5 結(jié)語
因此,基于EEMD 近似熵和BP 網(wǎng)絡(luò)故障識別和基于EEMD 近似熵和PNN 網(wǎng)絡(luò)故障識別方法進行故障信號識別。BP 神經(jīng)網(wǎng)絡(luò)對故障信號識別率都高于PNN 概率神經(jīng)網(wǎng)絡(luò),由此,將對后續(xù)進一步的研究提供一定的技術(shù)保障,在故障信號識別中,也將不斷探索更高識別率的神經(jīng)網(wǎng)絡(luò)形式。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
中國生殖健康(2019年3期)2019-02-01 06:12:26
汽車維護與修理(2016年10期)2016-07-10 08:17:41
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
汽車維修與保養(yǎng)(2015年12期)2015-04-18 07:51:49
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
汽車維修與保養(yǎng)(2015年2期)2015-04-17 01:30:34
