面向計算機科學領域的專業實體識別
2023-12-12 04:26:20張仰森李尚美胡昌秀成琪昊
重慶理工大學學報(自然科學) 2023年11期
陳 祥,張仰森,2,李尚美,胡昌秀,成琪昊
(1.北京信息科技大學 智能信息處理研究所, 北京 100101;2.國家經濟安全預警工程北京實驗室, 北京 100044)
0 引言
命名實體識別是自然語言處理領域中的一項基礎任務,也是開展智能問答、關系抽取、機器翻譯等研究任務的基礎環節。對于實體本身而言,區別于傳統命名實體,領域專業實體是具有領域表征作用的某一領域特有的命名實體。隨著建設網絡強國戰略的提出,計算機科學領域相關技術在人們日常生活中發揮著越來越重要的作用。研究領域的發展與科研活動的開展息息相關,面向計算機科學領域,精準識別領域的專業實體,對科研活動的展開具有技術層面的輔助作用,如為科研項目、學術論文的評審專家推薦提供技術支持。
實現計算機科學領域的科技項目或學術論文的評審專家推薦,關鍵因素在于盡可能滿足專家自身的研究領域與文檔涉及的研究領域相匹配的條件。而研究領域信息通常以專業實體的形式表現出來,計算機科學領域的專業實體通常包含在科研專家的學術論文中,同時學術論文的摘要是一篇論文的精華,其高度概括了論文的主要內容。專業實體包含多種類別,其中一類是專家研究領域實體,因此從學術論文的摘要中提取專業實體,是獲取專家研究領域信息的關鍵,以此表征專家的學術研究領域,為后續的評審專家推薦奠定基礎。為此,實現對計算機科學領域專業實體的識別具有非常重要的現實意義。
1 相關工作
目前,有關命名實體識別任務的研究大致可以分為2類:一類是針對人名、地名、機構名、時間表達式等傳統的命名實體進行識別[1-4];另一類是針對某一特定領域的專業實體進行識別,目前研究較多的特定領域主要包括生物醫學[5-7]、軍事領域[8-9]等。針對命名實體識別的實現方法可分為基于規則和詞典的方法、基于統計機器學習的方法以及基于深度學習的方法。近年來,基于深度學習的方法取得的成果較為顯著。馮艷紅等[10]提出一種基于BLSTM的神經網絡結構的命名實體識別方法,結合基于上下文的詞向量和基于字的詞向量,有效地利用了文本中命名實體的上下文信息以及組成實體的前綴、后綴和領域信息;李博等[5]提出了一種完全基于注意力機制的Transformer-CRF命名實體識別模型,解決了輸入和輸出序列對模型識別效果的限制問題;唐國強等[6]采用雙向門控循環網絡、多頭注意力機制和條件隨機場相容和的方式,進行實體識別,有效地利用了未標注數據并實現了對文本自身特征進行深入地捕捉;單義棟等[8]以字詞向量同時作為模型的輸入,利用注意力機制獲取特征向量,同時采用維特比算法解碼,標注命名實體標簽;車金立等[9]基于Bi-GRU-CRF命名實體識別模型,引入軍事詞語中的詞位信息,提出了一種融合詞位字向量的命名實體識別方法。王月等[11]使用BERT預訓練語言模型,同時引入注意力機制改進BiLSTM-CRF模型,完成命名實體識別任務。語言模型保存了較完整的語義信息,從而提高了模型特征抽取能力。李健龍等[12]基于無監督學習的方式訓練軍事領域語料進行詞語向量表示,采用融入注意力機制的雙向LSTM遞歸神經網絡模型完成軍事領域命名實體識別任務;曹春萍等[13]面向醫學領域,提出了一種卷積神經網絡-雙向長短期記憶網絡-條件隨機場相結合的實體識別模型,利用多種尺度卷積核的CNN對識別效果進行改善。
近年來,隨著RoBERTa預訓練模型的提出,越來越多的學者開始著手于此模型的研究與應用,并以此模型為基礎進行命名實體識別任務的研究。張云秋[14]提出了一種基于RoBERTa-wwm動態融合的實體識別模型,提升了對電子病歷實體的識別效果。Yin等[15]提出一種基于RoBERTa-wwm的細粒度中文命名實體識別模型,并在公開的CLUENER2020數據集中取得較好的效果。Cui等[16]將RoBERTa模型與卷積注意力機制相融合,以此融合模型開展中文命名實體識別的研究,通過實驗驗證了該模型的有效性。
綜上所述,關于命名實體識別任務的研究正如火如荼地進行著,也取得了顯著的成果。然而,目前關于計算機科學領域專業實體的識別任務研究較少,考慮以實現評審專家推薦為最終目的開展此方面研究,通過構建的專業實體識別模型獲取專家研究領域的相關信息,對專家進行表征。利用RoBERTa-wwm-BiLSTM-CRF模型對計算機科學領域的學術論文中的專業實體進行識別,通過RoBERTa-wwm預訓練模型獲取輸入文本的字符語義向量,并將其輸送下游BiLSTM-CRF模型中實現對專業實體的識別,提升獲取計算機科學領域專業實體的有效性和準確性。
2 專業實體識別
面向計算機科學領域專業實體識別的研究方案分為以下2個步驟:專家論文摘要數據的獲取與預處理以及專業實體識別模型的構建。
2.1 專家論文摘要數據的獲取與預處理
2.1.1摘要數據獲取
由于專業實體識別方法是面向中文文本領域的,且中國知網(CNKI)平臺中收錄了大量學術專家的科研論文,論文內容中涉及的專家研究領域信息較為廣泛,同時其行文用詞具有很高的權威性和可信度,因此利用網絡爬蟲工具,爬取中國知網平臺的專家論文摘要數據作為實驗數據集。在爬取專家的論文摘要數據之前,通過人工的方式從全國各大高校官網中手動地獲取一些專家基本信息數據。同時結合實驗室已有專家基本信息數據,對兩部分專家基本信息數據進行先融合再去除重復、無效數據的處理,最終得到專家基本信息數據表,表中主要包括專家姓名、專家所在高校單位名稱等字段。
中國知網平臺的高級檢索功能給使用者提供了一種能準確查找某位專家論文數據的方法。基于已有的專家基本信息數據表,結合中國知網平臺高級檢索頁面所具備的根據作者名和作者單位進行聯合查找的功能,利用網絡爬蟲技術,對表中的每位專家在知網平臺中收錄的論文摘要進行爬取,如圖1所示。同時,為了盡量避免由于同一所高校中存在專家重名現象而導致獲取到的論文摘要與計算機科學領域無關的情況,在爬取論文信息時,以論文所屬的分類號為依據對不屬于計算機科學領域的摘要文本進行過濾。參考《中國圖書館分類法》中的中國圖書分類號信息,爬取論文分類號屬于TP18(人工智能理論)、TP24(機器人技術)、TP3(計算技術、計算機技術)的論文摘要文本,過濾其他不包含上述分類號的摘要文本,以此保證摘要數據的可用性。
由于專家撰寫論文所標注的單位信息不一定同高校名稱完全一致,例如:清華大學丁**副教授在論文中標注的單位信息有“清華大學軟件學院”“清華大學北京信息科學與技術國家研究中心”等,并不是“清華大學”,因此在高級檢索頁面中設置模糊匹配的方式對作者單位進行篩選,以保證爬取的專家論文摘要數據充足而全面。
Selenium WebDriver是開源API集合,可以用于自動測試Web應用程序,并可以在大多數Web瀏覽器上運行,在爬蟲中也有很好的應用。 selenium工具具有簡單方便、易于實現、隱匿性強的優點[17]。基于上述說明,設計了基于selenium工具的網絡爬蟲框架,如圖2所示。

圖2 基于selenium工具的爬蟲框架
2.1.2摘要數據預處理
基于中國知網平臺的文獻知網節頁面內容簡潔性的特點,通過上述爬蟲框架爬取的數據中不包含廣告、不相關信息等噪聲數據。經觀察,在爬取的論文摘要數據中不同摘要的文本長度不盡相同,甚至存在2條摘要的文本字數相差幾百的情況。這就可能導致后續對文本向量化處理時需要過多地“補0”,從而影響整體的實驗效果。因此,在進行預處理時,以摘要文本的“。”或者“.”為分隔符,對摘要進行切分,以句子作為后續數據標注和文本向量化的基本單位。
2.2 專業實體識別模型的構建
2.2.1RoBERTa-wwm-ext-large預訓練模型
基于遷移學習的思想,預訓練模型最開始是在圖像領域提出的,且獲得了良好的效果,近年被廣泛應用到自然語言處理各項任務中。目前,BERT模型是使用較為廣泛的一種預訓練語言模型,其于2018年10月由Google AI研究院提出[14]。BERT預訓練模型一經問世,就因其在不同NLP任務中都取得了較為突出的成果而備受廣大NLP學者的關注。基礎的BERT模型基于默認的12層Transformer Encoder對輸入進行編碼,同時創造性地使用MLM(masked language modeling)和NSP(next sentence prediction)2種方式對模型進行訓練,使得BERT模型具有理解長序列上下文關系的能力和強大的表征能力。
近年來,對于基礎BERT模型的改進研究也層出不窮,實驗所使用的RoBERTa-wwm-ext-large預訓練模型是由哈工大訊飛聯合實驗室發布的改進模型。相比于基礎BERT的模型,RoBERTa模型的改進之處在于具有更多的模型參數、更大的Batch Size、更充足的訓練數據,同時在模型訓練過程中去除NSP任務。RaBERTa模型采用動態掩碼的方式代替靜態掩碼,通過復制原始語料,每一份語料隨機選擇15%的Token,對其按照[mask]、replace、keep分別為80%、10%、10%的占比方式進行mask處理,增強模型的表征能力。
RoBERTa預訓練模型結構如圖3所示。RoBERTa的輸入為每一個Token對應的表征,而每一個Token表征由Token Embeddings、Segment Embeddings、Position Embeddings 3部分組成,如圖4所示。在將Token表征送入RoBERTa模型之前,在輸入序列之前添加[CLS]標簽,為RoBERTa最后一個Transformer層的輸出所用,同時使用[SEP]標簽對輸入的句子進行分割。輸入的Token表征經Transformer Encoder層和動態掩碼MLM層后得到相應的輸出。C為[CLS]標簽對應最后一個Transformer的輸出,Ti(i=1,…,N)則代表其他Token對應最后一個Transformer的輸出。在命名實體識別(named entity recognition,NER)任務中,只把部分內容作為下游神經網絡的輸入。

圖4 Token表征構成圖
wwm(whole word masking)表示對語料的詞進行mask處理,而BERT模型的mask處理則是針對字而言的,RoBERTa-wwm在一定程度上提高了模型的學習能力。
實驗使用的RoBERTa-wwm-ext-large是支持中文的RoBERTa-like BERT模型,采用全詞遮罩wwm技術,直接采用最大長度512進行訓練,預訓練數據集包括中文維基百科、百科、新聞、問答等,該模型集成了RoBERTa模型和BERT-wwm模型的優點,具有較好的可用性。
2.2.2BiLSTM-CRF模型
隨著近些年深度學習技術不斷發展與成熟,越來越來多深度學習模型被應用于實際的NLP任務中。循環神經網絡(recurrent neural network,RNN)就是一種典型的深度學習模型,其可以處理時間序列信息,通過“記憶”將序列前后信息關聯起來。但是在RNN模型訓練的過程中容易產生梯度消失和梯度爆炸的問題,從而導致RNN無法很好地學習到時序數據的長期依賴關系。而長短時記憶網絡(long short-term memory,LSTM)引入“門”機制,通過控制特征的流通和損失解決RNN模型存在的問題。單個LSTM單元如圖5所示。

圖5 LSTM單元結構圖
LSTM通過“忘記門”ft、“更新門”it、“輸出門”ot實現對信息的選擇記憶,過濾噪聲信息,減輕記憶負擔。LSTM內部的前向傳播公式如下:
(1)
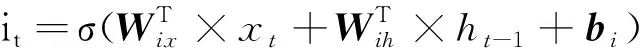
(2)

(3)

(4)
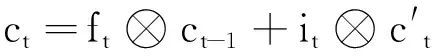
(5)
ht=ot?tanh(ct)
(6)

(7)

LSTM往往關注的是上文所傳遞的信息,從而忽略了當前輸入的下文信息,這在一些NLP任務中存在著一定的局限性,如NER任務。為了充分考慮上下文信息對模型輸出結果的影響,相關學者設計了將一個輸入序列同時連接前向LSTM層和后向LSTM層的BiLSTM深度學習模型。BiLSTM模型將2層網絡的隱含層連接起來,共同傳遞至輸出層進行結果預測。
BiLSTM模型只選擇標簽分數最高的一類標簽作為輸出,沒有考慮到標簽與標簽之間的內聯系和依賴關系,很可能輸出不符合常理的無效標簽序列,因此單獨的BiLSTM模型在NER任務中往往不能取得很好的效果,通常需結合CRF算法共同使用。CRF是一種序列標注算法,在最終輸出預測標簽之前自動學習并添加標簽的約束條件,考慮標簽與標簽之間的關聯性,提高模型輸出標簽序列的有效性。
CRF接受如X=(x1,x2,…,xn)的輸入序列,得到如Y=(y1,y2,…,yn)的輸出序列,在NER任務中得到輸出結果為模型預測標簽序列。輸出序列得分的計算公式如下:
(8)
式中:S表示得分;Ayi,yi+1表示從yi到yi+1的轉移概率矩陣;Pi,yi表示softmax函數在第i個位置輸出yi的概率。在輸入序列為X的條件下,預測序列Y的softmax歸一化概率計算公式如下:
(9)
式中:P(Y|X)表示在X條件下輸出Y的概率;Y′表 示所有標簽集合;y′表示真實標簽。型損失值loss通過如下公式進行計算:
(10)
最后,計算得到最優標簽序列:
y*=arg max(S(X,y′))
(11)
2.2.3模型整體框架
采用RoBERTa-wwm-BiLSTM-CRF聯合模型對計算機科學領域的專業實體識別任務進行分析研究,優化BERT預訓練模型的語義表征能力,模型框架如圖6所示。
將專家論文摘要文本以字為單位進行切分并添加索引,隨后將切分后的索引格式文本序列輸入RoBERTa-wwm層,獲取RoBERTa-wwm層輸出的每個位置表示。之后,將各層文本表示信息輸入BiLSTM模型,對序列特征信息進行初步獲取。最后,利用CRF層處理得到最后的預測序列表示。綜上步驟,完成對計算機科學領域專業實體的識別任務。
3 模型驗證及實驗結果分析
3.1 實驗數據集
以爬蟲獲取的論文摘要數據作為實驗數據,采用《計算機科學技術百科全書》中的學科名詞及經人工校對后的論文關鍵詞作為標注詞,對摘要數據中的計算機領域專業名詞進行人工標注。由于目前暫未出現計算機科學領域專業實體的公開數據集,因此以自行標注的數據完成模型的訓練與測評。實體采用“BIO”標注方式,“B”表示實體詞的開始位置,“I”表示實體詞的中部位置,“O”表示非實體詞部分。通過對論文摘要中出現的專業名詞進行分析,人為地將專業名詞實體分為3類,分別是科研方向實體(表述計算機科學領域專家研究方向的專業名詞實體,如人工智能)、概念名稱實體(表述計算機科學領域某種概念的專業名詞實體,如魯棒性)、技術名稱實體(表明進行學術研究所用技術的專業名詞實體,如BERT)。由此,所使用的數據集對應的標簽集合為:{O、B-sde、I-sde、B-coe、B-tce、I-tce}。其中,sde代表科研方向實體,coe代表概念名稱實體,tce代表技術名稱實體。
實驗數據集*為6 512篇計算機科學領域專家學術論文摘要,并將數據集劃分為訓練集與測試集。其中,訓練集中共5 000篇論文摘要文本,共25 635條句子;測試集中共1 512篇論文摘要文本,共6 278條句子。實體種類與具體數量如表1所示。

表1 數據實體種類與數量
3.2 評測標準
采用實體識別精確率(Precision)、實體識別召回率(Recall)、實體識別F1值(F1-Score)3個指標來進行專業實體識別模型的評價,具體計算公式如表2所示。

表2 評價指標
其中,P為模型識別專業實體的精確率,R為模型識別專業實體的召回率,TP表示正確識別實體的數量,FP表示錯誤識別實體的數量,FN表示未能被識別實體的數量。
3.3 實驗及結果分析
為了驗證模型的有效性,設置了不同命名實體識別模型在同一數據集有關識別效果的對比實驗。實驗所用環境及模型相關參數分別如表3、表4所示。

表3 實驗環境

表4 模型主要參數
在訓練過程中,設置預訓練模型微調學習率的大小為5×10-5,在下游模型中設置學習速率的大小為1×10-3。
實驗選取了BiLSTM-CRF模型、BERT-BiLSTM-CRF模型、BERT-wwm-BiLSTM-CRF模型作為對照模型,同所提優化模型進行比較。其中,BiLSTM-CRF模型屬于經典的NER模型,后續的拓展模型大多在其基礎上進行改進與優化,此模型沒有使用預訓練模型,采用靜態詞向量的方式進行訓練。BERT-BiLSTM-CRF模型在BiLSTM-CRF模型引入預訓練模型獲得包含語義信息的字符向量,再同下游模型連接完成命名實體識別的任務。在一些研究中,該模型取得了不錯的效果。BERT-wwm-BiLSTM-CRF模型在BERT模型字符級掩碼的基礎上提出詞語級掩碼的概念,并通過詞語掩碼的方式訓練模型,實現了對模型的進一步優化。文本模型在BERT模型的基礎上,使用RoBERTa預訓練模型獲取字符向量,此預訓練模型憑借動態掩碼的訓練方式以及更豐富的訓練參數和語料,同時結合了wwm機制的優點,進一步提高了模型的泛化能力。通過對比實驗,得到了基于實驗數據集各模型對專業實體的識別效果,實驗結果如表5所示。
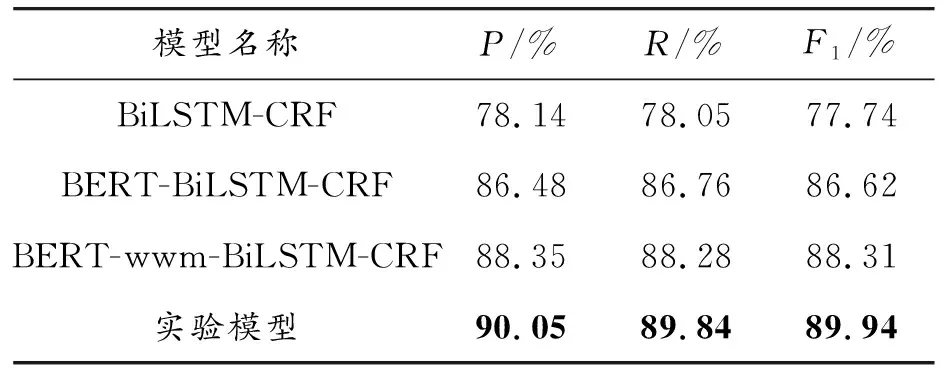
表5 各模型在實驗數據集上的專業實體識別情況
實驗結果表明,在自主標注的數據集上,加入BERT預訓練模型后對專業實體的識別效果相較于傳統的BiLSTM-CRF模型而言具有較為明顯的提升,F1值提高了8.88%。在BERT模型中融入wwm機制后,其識別的精確率、召回率、F1值均有所提升,說明模型獲取文本語義信息的能力有所增強,體現了wwm機制的有效性。從具體數值看,相較于BERT-BiLSTM-CRF模型,BERT-wwm-BiLSTM-CRF模型識別的準確率提升1.87%、召回率提升1.52%、F1值提升1.69%,引入wwm機制有助于下游任務的效果提升。
為了驗證動態掩碼機制在提高模型識別效果方面的有效性,實驗中用此模型(RoBERTa-wwm-BiLSTM-CRF)與BERT-wwm-BiLSTM-CRF模型進行對比實驗。從表5可以看出,文本模型在識別精確率、召回率、F1值3項指標上均有所提升,具體分別提升了1.70%、1.56%、1.63%,說明了RoBERTa 動態掩碼機制的有效性。實驗模型在BERT模型的基礎上,將動態掩碼與詞語級掩碼機制相結合,在一定程度上使得預訓練模型的輸出結果具有更豐富的語義表示,提高了模型的泛化能力,可更好地為下游任務服務,有助于提高識別專業實體的效果。
4 結論
面向計算機科學領域,針對專業實體識別任務構建了一種RoBERTa-wwm-BiLSTM-CRF的聯合模型,對模型的有效性在自主標注的數據集上進行了實驗驗證。同時,在實驗中設置3個對照模型與實驗模型相對比,得到如下結論:
1) BERT預訓練模型的引入使得在NER任務的上游獲得了字符級的語義表示,將其送入 BiLSTM-CRF模型后在一定程度上提高了對專業實體識別的效果。
2) wwm機制的引入提高了預訓練模型的泛化能力,相較于字符級掩碼策略,wwm機制在NER任務上具有更好的實際效果和使用價值。
3) RoBERTa的動態掩碼策略提高了模型適應掩碼策略的能力和模型學習能力,將RoBERTa的動態掩碼策略與wwm方式結合,能獲取更豐富的語義表示,在連接下游的BiLSTM-CRF基礎模型后,總體上提升了對專業實體的識別準確性,在對比實驗中取得了最好的效果。
此外,實驗數據集存在不同實體類別數量的不均衡問題。例如技術名稱實體數量較其他2類偏少,也在一定程度上導致了對該類實體識別效果劣于其他2類實體的結果。未來的工作中需要針對上述問題提出進一步的改進策略,處理數據不均衡的問題,提升對計算機科學領域專業實體的識別效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
