環境感知的自適應深度強化學習路由算法
2023-12-04 11:12:52侯詩琪
計算機工程與設計 2023年11期
李 婧,侯詩琪
(上海電力大學 計算機科學與技術學院,上海 201306)
0 引 言
路由選擇是網絡數據傳輸的關鍵技術[1],優化路由選擇協議有助于提升網絡服務質量。在大流量頻繁的傳輸場景中,網絡負載的波動性對傳統路由選擇協議提出了新挑戰[2]。傳統路由協議基于啟發式規則或基于數據驅動。基于啟發式規則的傳統路由選擇協議,例如開放最短路徑優先協議(open shortest path first,OSPF)不能根據傳輸節點和鏈路的狀態動態調整路由策略,并從歷史決策中習得經驗,避免遇到類似場景時再次做出不當決策。基于數據驅動的協議包括基于深度學習的協議和基于強化學習(rei-nforcement learning,RL)的協議。前者訓練成本和部署成本高,在負載大幅波動的環境中無法一如既往地保障網絡吞吐量;后者未能根據負載波動自適應調整參數,且廣泛使用簡單的ε-greedy策略,在訓練初期,動作探索具有一定盲目性[3],波動的負載不僅延長了訓練時間,而且使訓練初期的網絡吞吐量很低。此外,現有模型經驗回放效率不高,很多優質經驗未被采樣就被拋棄,模型收斂速度仍有提升空間[4]。
為應對上述挑戰,提出了基于環境感知的自適應深度強化學習路由算法,利用平均損失函數值調節探索和利用的程度,采用有限度探索和優先經驗回放機制加速訓練。仿真結果表明,該算法可保障并提升模型相對收斂前后的網絡吞吐量,并顯著縮短訓練時間。
1 相關工作
路由選擇可看作一類序列決策任務。對此類問題,比起基于深度學習的路由選擇算法,強化學習更關注動作的長期收益,在與環境的交互中智能體可學得更優策略。
Boyan最先利用強化學習優化路由選擇并提出了Q-routing[5],旨在為數據分組的傳輸選擇時延最短的路徑以避免擁塞。Daniel等提出了基于Q-routing和啟發式規則相結合的擁塞感知路由算法QCAR[6],可感知網絡環境變化動態調整下一跳選擇,通過自適應避免擁塞,提高數據分組傳輸率,縮短端到端延遲。但模型對擁塞的判斷過于依賴啟發式規則。Kavalerov等提出了基于模糊邏輯的FQLRP[7],根據每個節點的剩余能量以及路由過程中一組節點的能量分布,決定下一跳。黃慶東等提出了低時延全回波Q路由算法AQFE-M[8],使用雙曲正切算子根據不同網絡情況調節學習率,減少了數據平均遞交時間,降低路由間的振蕩,提高了數據分組的投遞率。邵天竺等提出一種路由抖動抑制的智能路由選擇算法FSR[9],在提升轉發性能的同時,縮短路由收斂時間,提升網絡整體轉發性能。沙鑫磊等提出一種雙學習率自適應的Q路由算法DALRQ-routing[10],可根據網絡延遲調整學習率,減少輪詢操作造成的延遲抖動,加速算法收斂,提升網絡穩定性。
盡管上述基于Q-routing的各類改進算法在提升網絡性能和模型性能方面均取得了重要成果,但在網絡優化問題中,智能體的動作空間和狀態空間往往具有連續性,迫使Q表急劇增大,一方面,查表操作嚴重影響算法性能,另一方面,對Q表的存儲和查找任務也消耗著網絡設備寶貴的內存和計算資源。
以神經擬合代替Q表更新為核心思想的深度強化學習(deep q network,DQN)[11]為上述問題提供了解決方案。Jalil等提出了基于深度強化學習和優先經驗回放[12](perio-rity experience replay,PER)的路由選擇DQR[13],其獎勵函數可對時延和吞吐量等服務質量(quality of service,QoS)指標進行優化,降低延遲的同時最大化帶寬。高飛飛等提出了基于集中式部署的SDMT-DQN和DOMT-DQN[14],旨在提升數據抵達率,降低擁塞概率。周鵬等使用部分可觀察馬爾可夫決策模型對環境建模,把模擬退火算法的思想引入貪心函數ε。可實現網絡資源的合理分發[15]。曹茜等提出一種基于高獎勵值和時序差分誤差的優先經驗回放算法HVPER[16],一定程度上提升了模型訓練效率,加快了模型相對收斂速度。張宇超等提出了基于模型融合的深度強化學習多最優路由路由通用方案[17],增加了路由策略靈活性。
基于DQN及其各類改進算法解決了Q-routing的瓶頸問題,但存在的共性問題是智能體在探索階段網絡性能較差,未能權衡好探索和利用的關系;在負載變化頻繁的網絡環境中,模型自適應性還有待提高。
2 問題描述
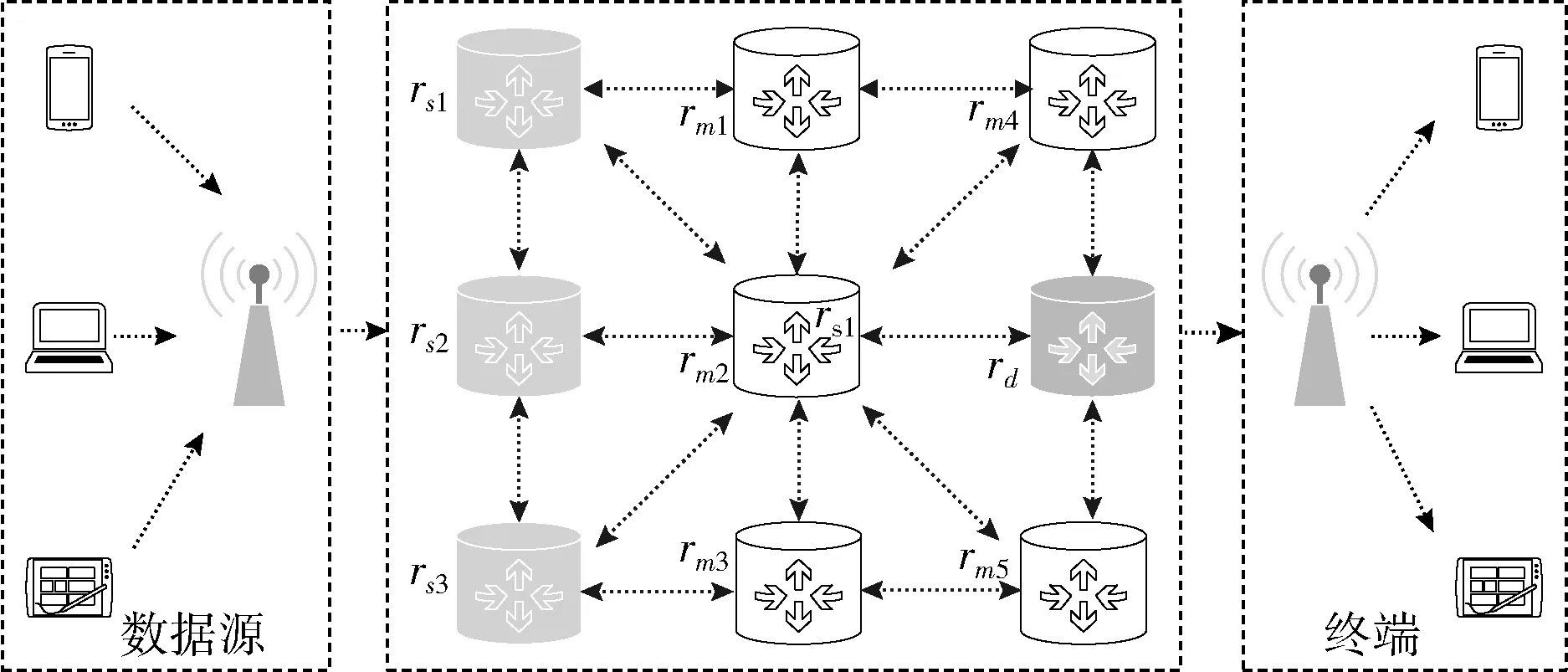
圖1 網狀網絡拓撲結構
=Ns+Nm+Nd
(1)
該拓撲結構可表示為有向圖G=(V,E ),V表各個路由器結點,E代表各路由器的連接關系,E滿足E={(i,j)|(i,j)∈V×V,i≠j}。
網絡架構采用集中式控制的軟件定義網絡(software defined networking,SDN)[18],包括數據層、控制層、應用層。圖1所示的路由器位于數據層,僅執行轉發操作。控制層提供應用程序和數據層之間的通信接口,路由策略計算、轉發規則更新等依賴控制層的控制器。每時隙控制器與路由器進行通信收集傳輸任務信息并存儲至任務隊列QT。假設每個時隙內,數據分組可從一個路由器傳輸到下一個路由器或是被丟棄,任務隊列中所有待處理任務均可被處理。
對于從源路由器rs轉發的數據分組,需為其生成一條轉發路徑,通過目的路由器rd送達終端,并使網絡吞吐量最大。
3 DQNPES詳細設計
DQNPES(deep q network with priority experience replay and self-adaptability)總體架構如圖2所示,采用了深度強化學習(deep q network,DQN)[19]思想。DQNPES包括兩個實體:一是環境實體;二是智能體(agent)。

圖2 DQNPES架構
3.1 環 境
路由選擇問題具有馬爾可夫性[20]。控制器與路由器通信獲取當前網絡狀態,并計算下一跳,路由器根據控制器的策略轉發分組,網絡狀態隨之改變。路由選擇問題的當前狀態是過去狀態的匯總。
由于網絡拓撲結構動態變化,且各路由器并行轉發分組,智能體所觀測的狀態是片面的。針對此問題,使用部分可觀測馬爾可夫決策模型構建智能體(partially observable Markov decision processes,POMDP)[21]。POMDP可表示為M=(S,A,P,R)。S為網絡狀態集合,為無限集,S={s0,s1,…,st,…};A為當前節點合法下一跳集合,為有限集,A={a0,a1,…,an};P為狀態轉移概率函數,P(s′|s,a) 表示在狀態s下執行動作a轉移至s′的概率。R為路由器執行轉發操作后網絡環境的獎勵反饋。R(s,a,s′) 表示狀態s下執行動作a到達狀態s′時的獎勵。
3.1.1 狀態
各路由器緩沖區情況以及數據分組狀態均會影響智能體決策。每時刻的狀態st表示為st=[Dt,Lt],其中Dt=[D1,t,D1,t,…,D],Di,t表示t時刻第i個路由器緩沖區的數據總量;Lt表示每時刻數據分組的位置,是長度為的one-hot編碼變體,Lt=[L1,t,L2,t,…,L],Li,t∈{-1,0,1}。數據分組不可被分割,因此每時刻有且僅有一個Li,t為1或-1。Li,t為1,表示t時刻數據分組在第i個路由器中;Li,t為-1,表示t時刻數據分組在第i個路由器被丟棄。
3.1.2 動作
對于路由選擇問題,動作是指從分組當前所在路由器選擇一個路由器ri作為下一跳。
3.1.3 狀態轉移概率
POMDP的求解目標是確定策略π(s),即為每個可能的狀態s指定動作。由于動作選擇具有不確定性,用狀態轉移概率P(s′|s,a) 來描述。狀態轉移概率與當前狀態和動作選擇策略有關。
3.1.4 獎勵函數
為尋找最優策略,需定義每時刻智能體可從環境獲得的獎勵R(s,a,s′)。為減少丟包,降低擁塞程度,提高吞吐量,R(s,a,s′) 包含因數據分組被丟棄的懲罰性獎勵以及被正常轉發時的即時獎勵,如式(2)所示。
智能體在以下情況獲得懲罰性獎勵,且任務傳輸終止:①當下一跳路由器的緩沖區無法存儲數據分組時,路由器負載過大;②當下一跳不是當前節點的鄰居節點,動作非法;
智能體在以下情況獲得即時獎勵:①數據分組每被轉發一次需要消耗資源,智能體獲得負向獎勵Rhop;②當下一跳是目的路由器,智能體獲得正向獎勵Rarrive。設置正向獎勵有助于加速模型收斂
(2)
Ro=Rhop+φRarrive,φ∈{0,1}
(3)
僅用每個時刻的獎勵評估策略是片面的。當前狀態蘊含了已執行動作產生的影響。因此,最近的獎勵應被重視,在未來,這一獎勵也應被考慮到。引入Gπ(s)來記錄POMDP累計獎勵
Gπ(s)=R0+γR1+γ2R2+…+γtRt+…=

(4)
其中,γ為折扣因子,表示當前獎勵在未來重要程度,會隨時間衰減,γ∈[0,1]。Gπ(s)隨動作的隨機性而變化,但Gπ(s)的期望值為定值。為評估π(s),引入狀態價值函數Vπ(s) 和狀態動作價值函數Qπ(s,a) (下文稱Q值),定義如下
Vπ(s)=π(Gπ(s))=
∑s′P(s′|s,a)[R(s,a,s′)+γVπ(s′)]
(5)
Qπ(s,a)=∑s′P(s′|s,a)[R(s,a,s′)+γVπ(s′)]
(6)
Vπ(s) 與Qπ(s,a) 相輔相成。Vπ(s) 由從狀態s0到達狀態st的所有狀態動作價值表征,Qπ(s,a),由后續狀態st的動作價值表征。通過價值迭代,可求得最優策略π(s)
(7)
3.2 智能體
在對環境建模的基礎上,設計了基于值的強化學習框架,即智能體(下稱模型)。智能體的兩大任務是在線動作決策和離線學習。為加速智能體學習,提升網絡吞吐量,本文針對動作決策和離線學習進行了優化。
3.2.1 模型結構
智能體包含兩個結構完全一致的神經網絡eval_network和target_network。
在動作決策時,eval_network輸入層為當前網絡狀態,輸出層為每個動作的Q值,作為智能體下一跳選擇的參考。對于每一次決策,智能體將經驗以狀態轉移元組 (st,a,Rt+1,st+1) 的形式存入經驗回放池。
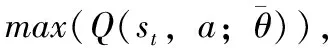
s′t=argtan(st)×2÷π
(8)
(9)
Loss(θ)=[(target_Q-Q(st,at;θ))2]
(10)

3.2.2 動作選擇
下一跳的選擇基于有限探索機制和改進的自適應ε-greedy機制,ε是權衡動作選擇策略的因子。智能體訓練初期,廣泛的探索可提升獲得更優解的概率[3]。但盲目探索不利于提升訓練初期的網絡吞吐量,影響用戶體驗。針對這一矛盾,引入了有限度探索機制。動作選擇算法如算法1所示。智能體以ε的概率選擇具有最大狀態價值函數值的動作,以1-ε的概率從當前節點的鄰居中優先選擇滿足緩沖區閾值條件的動作a。若這樣的動作不存在,則隨機選取當前節點的一個鄰居作為下一跳。有限探索為智能體的學習積累了更多優質經驗,有助于智能體更快學到良好的策略。
算法1:下一跳選擇
輸入:網絡拓撲G、網絡狀態s、送達的目的節點dst
輸出:下一跳動作a
(1) 從狀態s中提取數據分組當前位置i
(2) 隨機生成一個0到1的數m
(3)ifm≤εdo

(5)returna
(6)else:
(7)forneighborinneighborsofrido
(8)ifneighbor的緩存大小+分組數據量 <閾值do
(9)a=neighbor
(10)returna
(11)endfor
(12)else:
(13) 從ri的鄰居中隨機選擇一個返回
由于損失函數值可以反映預估Q值和實際Q值的差距,進而反應智能體的學習程度。自適應的ε有利于智能體在與環境交互過程中形成更多有價值的經驗。損失函數值較大時,表明智能體尚未學習充分,未能有效應對網絡負載變化,這時需要加大探索,利用有限探索機制積累優質經驗;當損失函數值較小時,表明神經網絡已相對收斂,智能體已能應對網絡負載變化,這時依據當前行為策略挑選出來的大多數動作對于最優策略的學習是有利的,智能體對環境的探索程度可適當降低。ε更新方法如式(11)。在訓練初期,為智能體設置一個較小的初值ε0,并保持一段時間(即Tstate1),隨后,ε隨著智能體多次訓練的平均損失函數值更新,若更新過程中ε超過閾值時,將ε重新調整為閾值εmax。
對ε的改進不僅提高了智能體對環境的自適應程度,也降低了智能體對啟發式規則的依賴
(11)
3.2.3 優先經驗回放

(12)
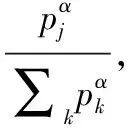
由于有偏采樣引入了偏差,為保證有偏采樣學到的策略與均勻采樣的策略相同,使用重要性抽樣權重wj(下稱isweight)糾正偏差。考慮到穩定性,使用最大權重值進行歸一化。β為退火因子,在學習結束時β將從初始值退火到1,與α共同作用以校正偏差。n為采樣數
wj=(n·p(j))-β/maxiwi=
(n·p(j))-β/maxi(n·p(i))-β=
(p(j))-β/maxi(p(i))-β=(p(j)/minip(i))-β
(13)
綜上,DQNPES偽代碼如算法2所示。在動作決策階段,控制層為每一個傳輸任務做出下一跳決策,并把指令分發給響應路由器進行分組轉發。并將經驗和優先級存入經驗回放池。在學習階段,優先級權重按照經驗采樣數分段后隨機選取,并選取該權重對應的經驗,依照式(13)計算重要性抽樣權重。
算法2:DQNPES
輸入:網絡拓撲、網絡狀態
(1) 初始化任務隊列,模型參數
(2)forepisode = 1,2,…,Mdo
(3)forT = 1,2,…,50do
(4) 數據源生成數據,并把傳送任務添加到隊列
(5) 控制器獲取各路由器狀態
(6)fortask = 1,2,…,N (N為隊列任務數目)do
(7) 根據分組送達的目的地選取相應智能體
(8) 獲取網絡狀態,輸入到eval_network
(9) eval_network按照算法1選擇動作
(10)endfor
(11) 為隊列中所有分組執行轉發操作
(12) 初始化經驗優先級為1或最大優先權重值,并存入經驗回放池
(13)ifT %5 ==0do
(14) 隨機選取優先級,從經驗池中隨機選取經驗j~p(j)
(15) 依據式 (13) 計算重要性抽樣權重isweight
(16) 根據式 (9) 計算target_Q值
(17) 根據式 (10) 計算損失函數,用梯度下降法更新參數
(18) 計算δj=target_Q-Q(st,at;θ) 并更新經驗優先級
(19) 根據式 (11) 更新ε
(21)endfor
(22)endfor
4 實驗仿真與結果分析
4.1 實驗設計
4.1.1 實驗環境
仿真環境基于Networkx[22]。假設源路由器和目的路由器可及時將接收到的數據分組轉發,緩沖區大小無限制,其余路由器緩沖區設為40 MB。數據源產生的數據分組數目符合泊松分布[23]。每時隙數據源生成的數據總量由概率參數ρ控制。數據源有ρ的概率產生大的數據分組,1-ρ的概率生成較小的數據分組。實驗設定部署了不同模型的網絡環境在每時隙生成的數據分組數目和數據量保持一致。
DQNPES的神經網絡部分采用 Keras實現[24],根據目的路由器的數目,確定需要訓練的神經網絡個數。每個神經網絡輸入層、輸出層的神經元個數分別是2和。模型神經網絡參數一致。
4.1.2 實驗模型
為評估算法性能,實驗選取以下算法:
OSPF:網絡中的各路由器通過泛洪法獲取整個區域的拓撲結構,到各節點最優路徑通過Dijkstra方法計算。
QCAR[6]:考慮兩跳的擁塞狀態,采用隨機選取不擁擠節點和選取具有最大Q值的節點相結合的方式決定最佳下一跳,將流量分配到多條路徑。
DOMT-DQN[14]:算法依照目的節點個數確定神經網絡的個數。每個神經網絡基于Nature DQN[19](下稱DQN)根據目的節點選擇對應DQN產生下一跳。
DQNP[12]:在DQN的基礎上引入優先經驗回放機制。
HVPER[16]:算法中經驗回放優先級的定義結合了TD error與獎勵,優先考慮具有高獎勵值和高時間差分誤差的經驗。
DQNPE:在DQNP基礎上引入自適應ε。
4.1.3 實驗思路
(1)為驗證加入自適應ε能有效權衡探索和利用,加速訓練,將DQNPES與以下模型變體對比:
DQNE:在DQN基礎上引入自適應ε。
DQNC:采用線性遞增的方式調整ε,更新方式如式(14)所示
(14)
DQN:在整個訓練過程中,ε保持不變。
(2)為驗證正向經驗積累對于網絡吞吐量的提升程度,將DQNPES與表1所示的模型變體作對比。

表1 模型變體
(3)為驗證有限探索和自適應ε改進共同對網絡吞吐量、數據送達率等指標的提升程度,調整ρ大小,比較DQNPES、HVPER、DQN、QCAR、OSPF對上述指標的影響。各算法所在環境ρ保持一致。每時隙數據源生成數據完全相同。
4.2 結果分析
為清晰呈現實驗結果,繪圖時進行了平滑處理。
(1)圖3展示了訓練輪次與網絡吞吐量、數據送達率、損失函數值、數據分組平均路徑長度的關系。根據圖3(a)和圖3(b),在訓練初期,DQNPES使網絡吞吐量、數據送達率高于其它算法所在環境,DQNE次之。這驗證了引入自適應ε機制的有效性。在訓練初期,智能體需要進行大量的探索來嘗試更多的選擇,以學習更優策略。根據圖3(c),DQNPES在達到相對收斂后,平均路徑長度略長于其它算法,但對吞吐量的提升顯著,這反映了路由選擇策略的靈活性,分組沿著負載較小的方向傳輸,反而可以更快到達。圖3(d)反映了各個算法的收斂速度。在自適應ε機制的作用下,DQNPES最先達到相對收斂,DQNE次之,驗證了自適應ε機制加速模型收斂方面的有效性。
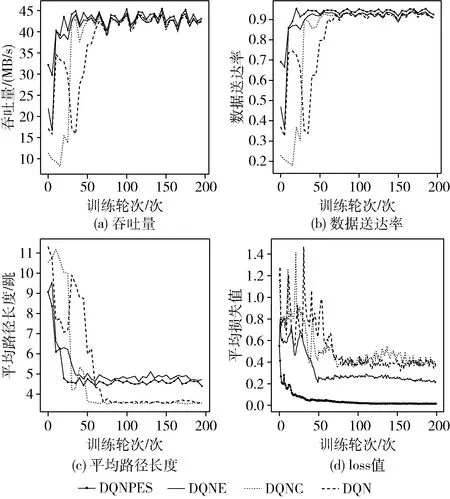
圖3 網絡性能與訓練輪次
(2)正向經驗積累對吞吐量提升的驗證
根據圖4,4個算法使網絡吞吐量在訓練50輪時就達到了相對穩定的狀態。與上一實驗中未引入優先經驗回放機制的算法相比,優先經驗回放機制在提升模型收斂速度方面具有優勢。盡管訓練初期,DQNPES的表現略遜色于HVPER,由于對動作探索范圍有所約束,其波動遠小于DQNPE和DQNP,在后期,DQNPES所在環境網絡吞吐量和數據送達率最高,驗證正向經驗的積累有助于提升網絡吞吐量。

圖4 網絡性能比較
(3)算法有效性驗證
圖5是ρ=0.4時各算法所在環境吞吐量和數據送達率隨訓練輪次的變化情況。DQNPES使數據送達率,吞吐量均達到了最高,且在訓練初期,性能也優于除QCAR之外的算法。在訓練后期,DQNPES表現優于其它算法。這驗證了引入自適應ε和有限探索機制的深度強化學習算法的有效性。

圖5 ρ=0.4時的網絡性能與訓練輪次關系
表2記錄了各算法在訓練100輪之后所在環境平均吞吐量和平均數據送達率隨ρ變化的情況。當ρ從0.2增加至0.8時,數據源每時隙產生的數據總量遞減,各算法平均吞吐量也因此呈遞減趨勢,但DQNPES的平均吞吐量始終高于其它算法。ρ為0.2時,網絡負載總體水平最大,丟包情況最為嚴重,但DQNPES仍使送達率保持在93%,算法優勢最為顯著。這驗證DQNPES所做改進提高了網絡數據傳送能力。

表2 ρ與模型
5 結束語
為提升負載變化頻繁的傳輸場景的網絡吞吐量,提出一種基于SDN架構的具有環境感知的自適應深度強化學習路由算法DQNPES。與基準算法相比,該算法可根據平均損失動態調整ε-greedy策略,并通過有限度動作探索積累正向經驗,避免了網絡出現大規模擁塞,結合優先經驗回放機制,加速了智能體學習,降低了訓練成本。實驗驗證正向經驗的積累對于提升網絡吞吐量的有效性。DQNPES可在大流量、負載波動頻繁的情況下保障并顯著提升從智能體訓練初期到相對收斂的網絡吞吐量和數據傳輸率。
猜你喜歡
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
