一種優化空天地一體化網絡吞吐量算法
2023-11-28 01:02:24杜丹冰
彈箭與制導學報 2023年5期
關鍵詞:用戶
杜丹冰
(長春師范大學教育學院,吉林 長春 130032)
0 引言
為了滿足全球全面的三維覆蓋和在將來隨時隨地訪問的長期需求,空天地一體化網絡已成為當今世界的重要研究方向。在空天地一體化網絡[1]中,無人機(unmanned aerial vehicles, UAV)[2]作為空中基站(base stations, BS),為地面用戶提供視距(line-of-sight, LoS)通信鏈路,提高蜂窩網絡對地面用戶覆蓋率和網絡吞吐量。
然而,基于UAV-協助的通信系統面對諸多挑戰。例如,UAV的移動和位置對通信系統性的影響。此外,由于頻譜資源稀缺,如何有效管理UAV的頻譜資源也是空天地一體化網絡的關鍵。文獻[3]討論了頻譜資源的分配問題,并提出基于連續凸優化技術的UAV軌跡和功率分配策略[4]。
除了頻譜資源分配問題外,回程鏈路的連通也是空天地一體化網絡必須考慮的問題之一。文獻[5]采用宏基站提供回程鏈路通信,并通過優化UAV的二維軌跡最大化吞吐量。文獻[6]討論了基于衛星-UAV網絡的資源分配問題,并采用單近地軌道(low earth orbit, LEO)衛星為UAV提供回程鏈路。然而,該策略并沒有優化UAV的位置。
為此,針對空天地一體化網絡,文中提出基于強化學習的鏈路優化(reinforcement learning-based link optimization, RLLO)算法。RLLO算法通過優化衛星-基站和基站-用戶間資源分配,資源管理和UAV的軌跡,提高系統吞吐量。具體而言,先建立目標問題,再利用強化學習求解。仿真結果表明,文中所提出的RLLO算法有效地提升了吞吐量和地面用戶端的可達速率。
1 系統模型
1.1 網絡拓撲
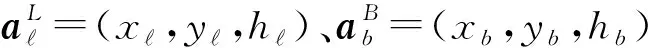
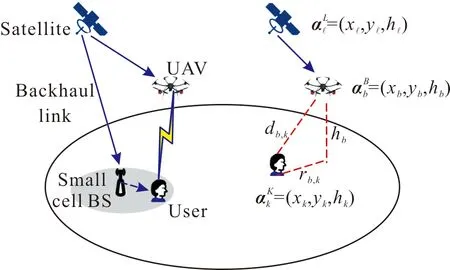
圖1 系統模型Fig.1 System Model
以rb,k表示用戶k與基站b間的平面距離(二維距離),以db,k表示用戶k與基站b間的三維距離。
以二值變量Kb(t)表示在時刻t的用戶k是否與基站b∈B關聯,其中B=S∪U,時刻t的時長為Ts,且t∈{1,2,…,N},其中N為總時刻數。若Kb(t)=1,則表示它們關聯;否則,Kb(t)=0。
此外,時長Ts足夠小,致使每個UAV在一個時隙內的位置不變。假定所有通信是在毫米波段完成,并且不考慮衛星對用戶接入鏈路的干擾。
1.2 回程鏈路
在衛星的回程鏈路中,衛星均勻分布在環形軌道,并且在y軸移動方向上的高度H固定[7]。衛星在軌道平面內的軌道速度為[8]:
(1)
式中:G,M分別為地球的萬有引力常數、質量;R表示地球的半徑。軌道周期為:
(2)
假定回程鏈路的總帶寬為wBCK。將wBCK等間隔地劃分為L個帶寬。每個衛星與每個BS間鏈路為視距鏈路(line-of-sight, LoS)[7]。因此,衛星與基站b間的自由空間的路徑衰耗為:
L(t)=32.45+20lgfc+20lg(d(t))
(3)
式中:d(t)為衛星與基站b間在時刻t的距離。
依據香農公式[6],衛星給基站b提供的速率:
(4)
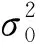
(5)
式中:G,Gb,G分別為衛星的發射天線增益,基站b的接收天線增益;為基站b離衛星的最大距離[9]:
(6)
式中:rb,o為基站b離地球中心的距離;rb,L為基站b離衛星的最短距離。
1.3 接入鏈路
用戶依隨機游走移動模型進行移動。在時刻t,用戶k∈K在速度范圍[Vmin,Vmax]內隨機移動。
以Q表示接入鏈路的可用信道集,wACC表示可用的帶寬。將總帶寬wACC劃分為Q個正交信道。
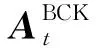
依據香農公式,基站b為用戶k提供的最大速率可表示為:
(7)
式中:γb,k(t)為與基站b關聯的用戶k端的信干擾比,其定義為:
(8)
式中:pb(t)為基站b的傳輸功率;gb,k(t)為基站b與用戶k的信道增益;b′∈B/b;ρb(t)為在時刻t基站b的負載[10]:
(9)
式中:?k為數據包達到率;ζk為用戶k的數據包尺寸的均值。
為了簡化表述,令ρb(t)=fb(ρ(t)),且ρ(t)=ρ1(t),…,ρB(t)。因此,將式(9)改寫為[11]:
ρ(t)=f(ρ(t))
(10)
式中:f(ρ(t))=(f1(ρ(t)),…,fB(ρ(t)))。
利用標準干擾函數迭代求解式(10)得到[11]:
ρm=min(f(ρm-1),1)
(11)
式中:ρm為第m次迭代后的輸出,其中m∈{1,2,…,Mt};Mt為總的迭代次數。
依據文獻[12],用戶k與基站b間鏈路呈LoS鏈路的概率可表示為:
(12)

(13)
式中:(xb(t),yb(t))為時刻t的基站b的位置;(xk(t),yk(t))為時刻t的用戶k的位置。
因此,時刻t基站b與用戶k間信道增益為:
(14)
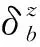
(15)
2 RLLO算法
2.1 目標問題
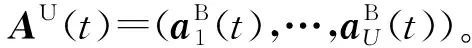
(16)
式中:Pb為基站b的可用傳輸功率集;條件第1行對基站b的傳輸功率和信道進行約束;條件第2行對基站負載進行約束,使基站的負載率不高于1;條件第3行、條件第4行對基站關聯的衛星數進行約束,使每個基站至少關聯到一個且只有一個衛星;條件第5行、條件第6行對用戶關聯的基站數進行約束,使每個用戶至少關聯到一個且只有一個基站。
為了能有效地求解式(16)所示的目標問題,將該目標問題分解成兩個子問題:1)回程鏈路的基站與衛星間的關聯問題(以下簡稱第一子問題);2)接入鏈路中用戶與基站的關聯,資源管理和UAV軌跡的設計的聯合問題。
可表述為:
(17)
由式(17)可知,每個基站選擇離自己具有最強的信號強度的衛星為自己服務。
2.2 基于增強學習的目標問題求解
提升接入鏈路的吞吐量是設計RLLO算法的主要目的。RLLO算法通過優化基站的傳輸功率和信道以及UAV的軌跡,最大化接入鏈路的吞吐量。由于窮盡搜索算法求解聯合問題的計算量過大,RLLO算法引用強化學習算法求解。強化學習算法能夠通過觀察、獎勵和動作來學習對輸入的正確反饋。
在強化學習算法中,基站扮演玩家,即將基站集B作為玩家集;值得注意的是,基站包含微基站SBS和無人機UAV。UAV作為空中飛行基站,如圖2所示。

圖2 強化學習框架Fig.2 Reinforcement learning structure
由于SBS和UAV的特性不同,它們采取不同的動作。具體而言,對于編號為s的SBS,用as,i表示其動作,由SBS的傳輸功率和信道兩項信息構成,即as,i=(ps,qs),其中i∈{1,2,…,AS}。而AS=Ps×Q,且ps∈Ps,qs∈Q分別表示s的傳輸功率和信道。
對于編號為u的UAV,令zu和Zu分別表示其移動方向和移動方向集,即Zu={up,down,left,right,forward,backward,static}。用au,i表示其動作,由傳輸功率,信道和移動方向三項信息構成,即au,i=(pu,qu,zu),其中i∈{1,2,…,AU},且pu∈Pu,qu∈Q,zu∈Zu。
此外,利用式(18)計算選擇編號為u的UAV作為空中基站b的獎懲函數:
(18)
式中:Cmax為歸一化因子。
2.3 基于多臂老虎機問題的強化學習
強化學習算法通過不斷獲取周邊環境的反饋來達到學習目的,即強化學習算法根據當前環境進行判斷,并選擇相應的動作措施,從而迫使環境狀態發生改變,環境的改變帶來潛在的“獎賞值”。再將獎賞值反饋算法,進而達到學習目的。
一般而言,在多步動作之后,才能觀察到強化學習任務的最終獎賞。考慮最簡單的情形:最大化單步獎賞。即在當前時刻,在所有能采取的動作集合中,選擇能使獎賞最大的動作。多臂老虎機問題(multi-armed bandits problem, MAB)是強化學習任務對應的理論模型。MAB就是如何在有限時間內,獲取最大化搖臂機的累計獎賞的理論算法。
在MAB問題中,賭徒對應玩家;手臂對應動作。每位賭徒從手臂動作集中選擇一個手臂,然后再觀察所選手臂的獎勵。為了獲取基站最優的動作,采用上限置信區間(upper confidence bound, UCB)算法求解MAB問題。UCB考慮的是每個手臂獎賞的置信區間的上界。
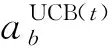
(19)
3 性能分析
3.1 仿真參數
在1 000 m×1 000 m區域內均勻分布用戶和基站。系統的仿真參數如表1所示。除最大傳輸率為24 dBm外,基站的其他相關參數如表2所示。

表1 系統仿真參數Table 1 System parameter
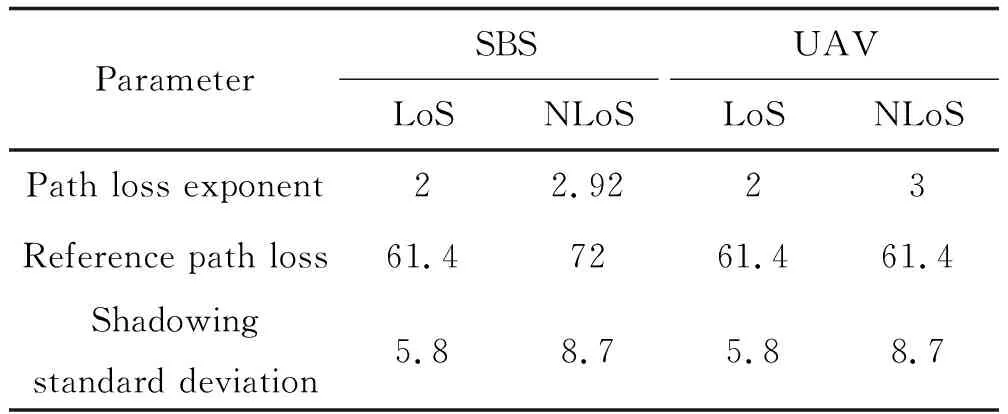
表2 基站的相關參數Table 2 BS parameter
為了更好地分析RLLO算法的性能,選擇兩個基準算法進行比較:隨機選擇(Random)和基于Q學習(Q-Learning)算法。Random算法表示每個基站以等概率隨機選擇其動作;Q-Learning算法表示基站通過Q-Learning學習選擇其傳輸功率和信道。同時,UAV隨機地選擇其移動方向。
3.2 微基站的平均吞吐量
首先,分析UAV數對接入鏈路中的微基站的平均吞吐量的影響,設用戶數為300,如圖3所示。由圖3可知,當UAV數從0增加至2,微基站的平均吞吐量也隨之增加。但是當UAV數大于2后,微基站的平均吞吐量就隨之下降。原因在于:最初UAV數的增加,UAV扮演空中基站并分擔了微基站的負載,致使微基站的平均負載下降。因此,每個微基站的平均吞吐量就隨之上升。
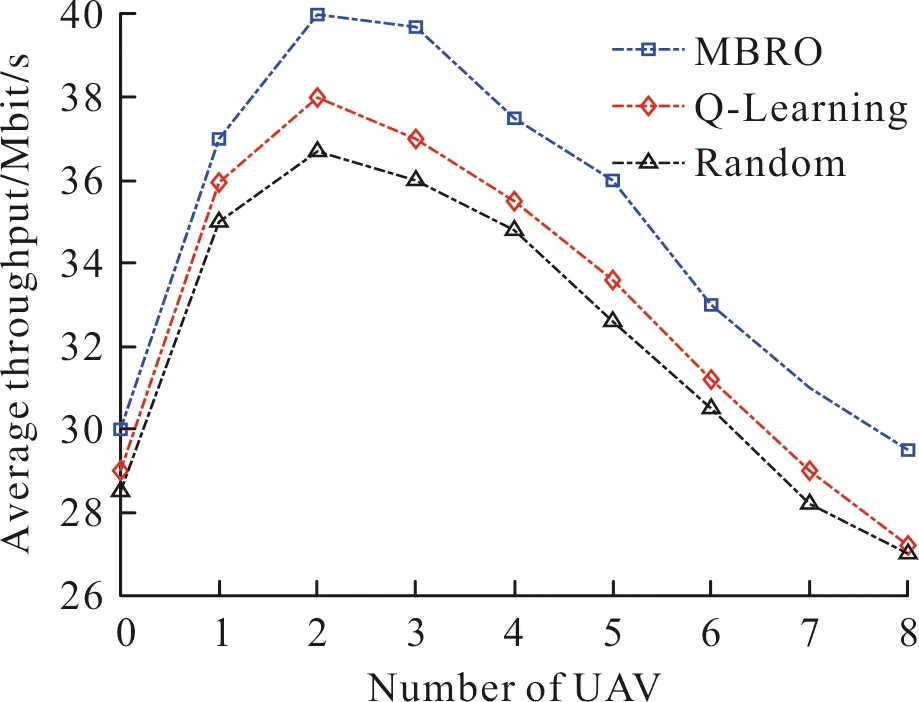
圖3 基站的平均吞吐量Fig.3 Average throughput of BS
但當UAV數增加到一定數量時,UAV分擔的負載更多。由于用戶數固定,每個微基站的平均負載下降,最終導致吞吐量下降。此外,相比于Random和Q-Learning算法,RLLO算法有效地提升了吞吐量。
3.3 用戶的平均速率
分析接入鏈路中用戶的平均速率,設用戶數為300,UAV數為1~8,如圖4所示。由圖4可知,用戶的平均速率隨UAV數的增加而增加。原因在于:UAV數越多,每個UAV為用戶分擔的負載越少,分配的帶寬越寬,速率就越高。相比于Random算法和Q-Learning算法,提出的RLLO算法有效提升用戶的平均速率。這歸功于:RLLO算法通過分配帶寬、傳輸功率的調整,最大化了用戶的平均速率。
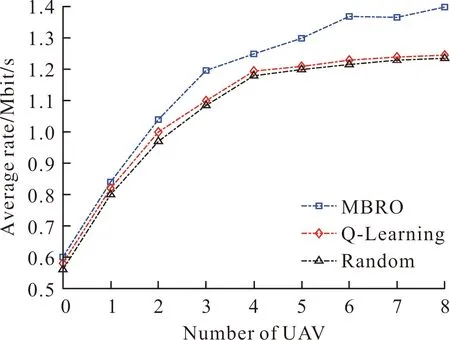
圖4 UAVs數對用戶的平均速率的影響Fig.4 Average rate versus the number of UAVs
圖5給出用戶數對用戶的平均速率的影響,設用戶數為50~400,UAV數為4。由圖5可知,用戶數的增加,導致用戶的平均速率下降。原因在于:每個微基站可獲取的資源一定,當用戶數增加,每個微基站的負載就隨之增加。最終,導致用戶端的信干比下降。
圖5 用戶數對用戶的平均速率的影響Fig.5 Average rate versus the number of users
3.4 鏈路中斷的用戶數
下面分析鏈路發生中斷的用戶數,設用戶數為50~400,UAV數為4。如圖6所示。
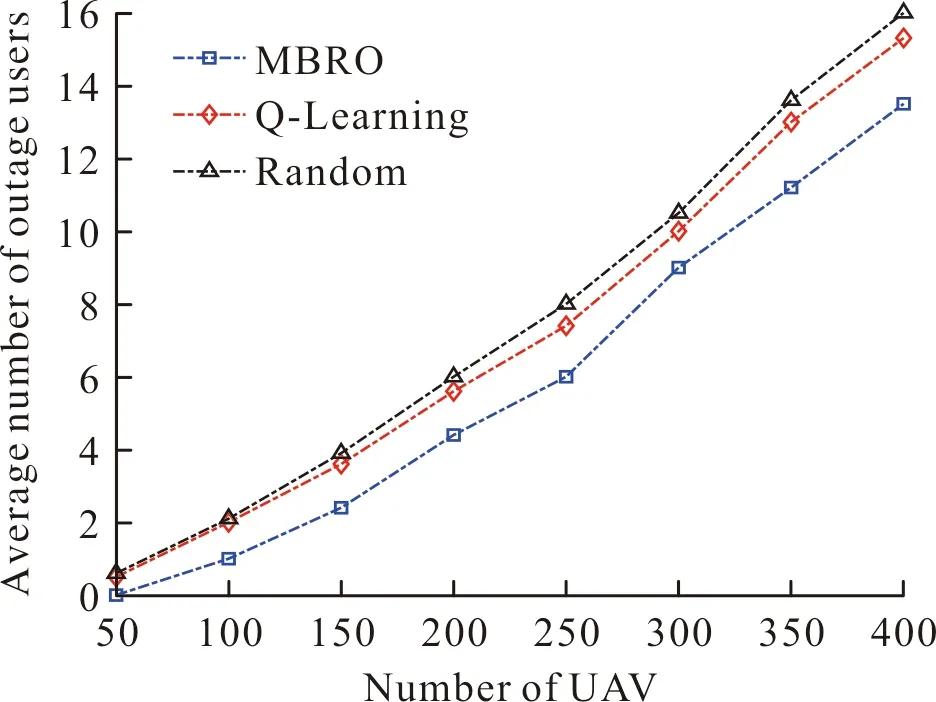
圖6 鏈路中斷的用戶數Fig.6 Average number of outage users versus the number of users
由圖6可知,鏈路中斷的用戶數隨用戶數的增加而上升。原因在于:用戶數越多,網絡資源競爭越激烈,導致更多鏈路發生中斷。相比于Random算法和Q-Learning算法,RLLO算法減少了發生鏈路中斷的用戶數。這說明RLLO算法有效分配了網絡資源,為用戶提供了穩定的數據傳輸鏈路。
3.5 算法的運算性能
分析RLLO算法、Q-Learning算法和Random算法的運算性能,利用運行時間評估其運算性能。運行時間越短,算法復雜度越低,運算性能越優。
表3為RLLO算法、Q-Learning算法和Random算法的運行時間。運行時間取獨立運行次數為20時的平均值。

表3 運行時間Table 3 Runtime
由表3可知,RLLO算法與Q-Learning算法的運行時間相近,且RLLO算法的運行時間略高于Q-Learning算法。RLLO算法和Q-Learning算法均采用強化學習算法,但由于Q-Learning算法采用隨機方式設定UAV移動方向,并沒有優化。因此Q-Learning算法的運行時間低于RLLO算法。此外,由于Random算法只以隨機方式選擇動作,并沒有利用算法優化選擇動作的過程,復雜度低,運行時間最短。
4 結論
文中通過聯合優化回程鏈路和接入鏈路的資源,提高了空天地一體化網絡的吞吐量。RLLO算法假定LEO衛星提供回程鏈接,而微基站和UAV為地面用戶提供服務。為了使基站能夠學習到最優的策略,RLLO算法采用強化學習,并利用基于MAB算法優化UAV的三維軌跡和基站的資源分配。仿真結果表明,相比于Random和Q-Learning算法,RLLO算法提高了網絡吞吐量和用戶端的速率。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
