在網存儲系統研究綜述
2023-11-24 05:26:00李俊儒舒繼武
計算機研究與發展 2023年11期
關鍵詞:系統
汪 慶 李俊儒 舒繼武
(清華大學計算機科學與技術系 北京 100084)
(q-wang18@mails.tsinghua.edu.cn)
傳統的存儲系統以CPU 為中心,CPU 處理所有的存儲邏輯.然而,在如今的后摩爾時代,通用CPU的處理能力難以提升,這極大限制了傳統存儲系統的性能上限.與此同時,傳統存儲系統面臨來自上層應用和下層I/O 硬件的前所未有的壓力.一方面,全球的數據量持續增長,尤其是需要實時處理的數據:據國際數據公司預測,2025 年實時性數據將達到50 ZB[1].另一方面,I/O 硬件的性能也大幅提升:高速網卡的帶寬已經超過100 Gbps,如雙端口ConnectX-6 網卡的聚合帶寬有400 Gbps[2];基于NVMe(non-volatile memory express)協議的閃存盤能提供百萬級的IOPS(input/output operations per second).當傳統存儲系統嘗試利用這些高速I/O 硬件來實時處理海量數據時,CPU 不可避免地成為了系統瓶頸,導致I/O 硬件資源難以被充分發揮.
近些年來,以可編程交換機和智能網卡為代表的可編程網絡設備在數據中心逐漸普及,這為緩解CPU 瓶頸、構建以數據為中心的在網存儲系統(innetwork storage systems)帶來了新的機遇.可編程交換機與智能網卡支持用戶自定義數據處理與轉發過程,且具有天生的位置優勢:可編程交換機是存儲服務器之間的數據交換中樞,而智能網卡是存儲服務器的出入口.在網存儲系統將存儲功能分工至可編程交換機或智能網卡上,在網絡通路上處理與存儲數據,因此既能夠充分發揮現代網絡硬件低延遲、高帶寬的優勢,又能夠減少數據的移動開銷.學術界和工業界近些年設計了大量的在網存儲系統,從不同角度加速存儲任務,獲得顯著的性能提升.
本文對在網存儲系統進行綜述,主要貢獻有3 個方面:
1)從可編程網絡設備的硬件特性出發,總結了構建高性能在網存儲系統面臨的兩大挑戰:網絡硬件和存儲軟件如何高效分工,以及在網存儲系統如何容錯.此外,歸納了在硬件和軟件層次針對這些挑戰的現有解決方法.
2)根據可編程網絡設備執行的任務,對現有的在網系統進行分類,包括在網數據緩存系統、在網數據協調系統、在網數據調度系統以及在網數據聚合系統.針對每類在網存儲系統,以具體例子分析其對應的設計難點以及軟件技術.
3)對在網存儲系統進行了展望,指出了研究人員未來需要著重對交換機與網卡協同、多租戶、安全以及自動卸載4 個方向進行深入探索,才能使得在網存儲系統被廣泛部署.
1 背景介紹
在網存儲系統目前主要使用可編程交換機與智能網卡進行存儲功能的加速,下面分別介紹它們的硬件結構以及性能特征.
1.1 可編程交換機
與功能固定的傳統交換機不同,可編程交換機支持用戶自定義網絡協議以及網絡包的轉發邏輯.現有的商用可編程交換機大多基于可重配置匹配表(reconfigurable match table,RMT)的硬件架構[3],如圖1所示.在RMT 架構下,可編程交換機具有多條入口流水線(ingress pipeline)和出口流水線(egress pipeline);每條流水線包含多個階段(stage).網絡包首先進入某個入口流水線,按照階段順序被交換機硬件部件處理,然后被轉發至某個出口流水線,最后從對應的交換機端口流出.RMT 架構的核心可編程部件是動作-匹配表(match action table),它定義了當網絡包滿足什么格式時(match 字段),對網絡包做何種操作(action 字段):比如,用戶可創建基于IP 地址的轉發表,根據網絡包的IP 地址字段進行網絡包內容的修改以及路由.此外,RMT 架構還支持有狀態的數據存儲;具體地,交換機具有數十MB 的SRAM 空間,用戶能夠通過定義長度固定的寄存器數組(register array)來使用這些SRAM 空間,并在處理網絡包的過程中對寄存器數組進行讀寫.
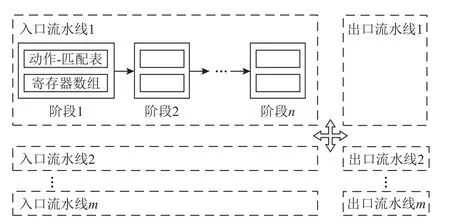
Fig.1 Hardware architecture of RMT programmable switch圖1 RMT 可編程交換機的硬件架構
可編程交換機擁有高帶寬、低延遲的性能特征.相比于服務器網卡,可編程交換機的聚合帶寬能高出1 個數量級:以英特爾公司的Barefoot Tofino 系列可編程交換機[4]為例,第1 代Tofino 芯片聚合帶寬可達到6.4 Tbps,支持100 Gbps 的網絡端口;最新一代Tofino 3 芯片聚合帶寬可達25.6 Tbps,支持400 Gbps的網絡端口.可編程交換機能夠線速(line rate)轉發網絡包,因此其流水線內處理邏輯的復雜度具有上限,比如不支持循環操作.
1.2 智能網卡
智能網卡是具有可編程芯片的網卡,用戶可自定義網絡包的處理過程,并可靈活地卸載通用CPU的任務.按照數據通路模式,智能網卡可以被分為onpath 和off-path 這2 類:在on-path 智能網卡中,可編程芯片位于網絡包收發路徑上,即每個網絡包都需要經過可編程芯片處理;而在off-path 智能網卡中,可編程芯片在網絡包收發路徑之外,存在額外的交換部件來控制網絡包是否被送往可編程芯片.onpath 智能網卡由于數據通路更短,網絡包處理延遲比off-path 智能網低;然而,on-path 網卡通常更難以編程.
現有智能網卡配備的可編程芯片主要分為4 種:ARM CPU、網絡處理器(network processor,NP)、專用集成電路(application specific integrated circuit,ASIC)以及現場可編程門陣列(field-programmable gate array,FPGA),它們在性能、易用性和表達能力方面各有優劣,如表1 所示.

Table 1 Comparison Among Four Types of SmartNICs表1 4 種智能網卡的對比
具體而言,基于ARM CPU 的智能網卡表達能力強且易于編程,這是因為ARM CPU 是通用處理器,且可以直接利用現有的工具鏈生態(如編程語言和編譯器).但ARM CPU 的性能比較差,針對網絡包的處理能力遠不如相同頻率下的x86 架構CPU;例如,英偉達BlueField 2 智能網卡[5]具有8 顆ARMv8 A72 CPU 核心,運行頻率為2.0 GHz.根據我們的測試,當運行基于RDMA 的用戶態測試程序,發送/接收尺寸為64 B 的網絡包時,使用這8 顆ARM 核心處理網絡包的吞吐量只有8 顆2.2 GHz 英特爾Xeon CPU 核心的1/2.基于NP 的智能網卡包含大量專為網絡處理設計的可編程網絡處理核心,相比于ARM CPU,它的網絡處理延遲更低且并發度更高:比如Netronome的Agilio CX 網卡[6]具有60 個NP 核心,并且每個NP核心上能同時運行8 個獨立的硬件線程.盡管性能很高,基于NP 的智能網卡編程難度要高于ARM CPU,且某些處理邏輯無法表達.基于ASIC 的智能網卡通過高速芯片進行網絡處理,同時針對網絡、存儲、虛擬化等任務提供一定程度的可編程接口;例如英偉達ConnectX 系列智能網卡[7]支持上層應用自定義網絡流表規則.基于FPGA 的智能網卡直接使用FPGA處理網絡包,FPGA 性能高且表達能力強,但FPGA編程門檻比較高,典型的代表有英偉達的Innova 智能網卡[8]系列.更多關于智能網卡的介紹可參見文獻[9].值得注意的是,相比于文獻[9],本文側重智能網卡和可編程交換機在存儲系統中的應用與加速.
2 在網存儲系統的設計挑戰
可編程交換機與智能網卡為存儲系統的設計帶來了巨大機遇,但同時構建高性能的在網絡存儲系統也面臨著諸多挑戰,其中最主要的有:1)網絡硬件和存儲軟件如何高效分工;2)在網存儲系統如何容錯.下面依次闡述.
2.1 網絡硬件和存儲軟件的分工
可編程網絡設備的表達能力受限,不如通用CPU.首先,它們的計算能力受限,以可編程交換機為例,為了保證線速,用戶能夠定義的操作步驟有限,不支持循環和浮點數計算,而且所有的操作必須要被表達成動作-匹配表的模式;此外,在可編程交換機中,具有依賴的操作必須被擺放在不同的流水線階段中,而流水線的總階段數有限,這進一步限制了用戶能夠表達的邏輯.其次,可編程網絡設備的可用內存小:可編程交換機只具有數十MB 左右的SRAM,而智能網卡的內存空間也一般不超過16 GB;此外,在可編程交換機中,SRAM 在不同流水線和不同階段之間無法被共享,導致內存空間無法被充分利用.
但另一方面,存儲系統具有大量復雜邏輯.比如存儲系統中的分布式協議(如共識協議、分布式提交協議)需要服務器之間進行多次網絡消息的交互,流程復雜;存儲系統中的崩潰一致性機制需要對存儲介質進行多個步驟的更新操作,保證系統在崩潰之后能夠恢復到一致性的狀態.此外,存儲系統使用大量內存空間維護狀態,比如文件系統需要幾十GB 甚至更大空間的頁緩存用于加速文件訪問性能.如何緩解受限的可編程網絡設備表達能力與復雜的存儲系統邏輯之間的矛盾,進行網絡硬件和存儲軟件之間高效分工是在網存儲系統面臨的一大挑戰.
目前的研究工作主要通過存儲軟件抽象和網絡硬件擴展2 個方面應對這一挑戰.在存儲軟件抽象方面,考慮到可編程網絡設備的資源受限,現有研究工作通常不會將存儲系統的所有功能全部卸載至可編程網絡設備上,而是對存儲系統功能進行細粒度地抽象劃分,將加速效果最佳的部分實現在可編程網絡設備中,而其他部分仍由存儲軟件實現.比如,分布式共享內存系統Concordia[10]將并發控制(讀寫鎖的管理)卸載至可編程交換機,與此相關的元數據所占空間較小但對系統性能影響大.
在網絡硬件擴展方面,存在一系列研究工作提升可編程網絡設備的表達能力,可具體分為3 類,如表2 所示.

Table 2 Summary of Switch Expressiveness Optimizations表2 交換機表達能力優化方案總結
為了提高可編程交換機的內存利用率,思科公司的研究者對RMT 架構進行擴展,提出了解耦的可重配置匹配表(disaggregated reconfigurable match table)架構[11],將內存從交換機流水線移動至中心化的資源池中,使得不同的流水線階段可以共享內存資源;進一步地,普渡大學的研究者提出MP5 可編程交換機架構[12],允許用戶邏輯能夠同時利用多個流水線中的內存資源;此外,卡內基梅隆大學的研究者提出TEA 架構[13],支持可編程交換機通過RDMA 網絡協議訪問服務器集群中的DRAM 資源,以擴充數據存儲空間.為了提高可編程交換機的計算能力,伊利諾伊大學厄巴納-香檳分校的研究者提出一種適用于交換機高效處理的浮點數表示方法FPISA[14],并為此擴展了RMT 架構.為了擴充可編程交換機的執行語義,麻省理工學院的研究者提出網絡包事務(packet transactions)的抽象[15],為可編程交換機中的部分執行邏輯片段提供原子性保證.
2.2 在網存儲系統的容錯
在網存儲系統引入了可編程網絡設備,這不可避免地擴大了系統的故障域(failure domain).具體而言,在傳統存儲系統中,系統狀態僅存儲在服務器內存和外存中;而對于在網存儲系統,除了服務器內存和外存,系統狀態還會存留在智能網卡的DRAM 和可編程交換機的SRAM 中.當網卡和交換機發生崩潰時,它們存儲的數據將會丟失,如何讓系統容忍這種新型故障是在網存儲系統的另一大設計挑戰.
目前的研究工作主要從軟件設計和硬件支持2方面應對這一挑戰.在軟件設計方面,現有在網存儲系統盡量只在可編程網絡設備中存儲軟狀態(soft state),即可以從別處(如后端服務器)恢復的狀態.例如,NetCache[16]在可編程交換機中緩存熱點的鍵值數據,而這些數據均在后端分布式鍵值服務器中有最新的版本,因此可編程交換機的崩潰不會導致任何鍵值數據的丟失;R2P2[17]在可編程交換機中維護每臺服務器的隊列長度信息,該信息丟失后可以通過詢問服務器來重構.
在硬件支持方面,主要的相關研究工作有弗吉尼亞大學提出的PMNet[18]和卡內基梅隆大學提出的RedPlane[19].PMNet 將持久性內存用于可編程網絡設備,以替代智能網卡的DRAM 和可編程交換機的SRAM;因此,可編程網絡設備可以通過持久性地存儲數據來容忍掉電等異常事件.此外,PMNet 設計了一種新型的數據更新協議,如圖2 所示:當可編程交換機收到客戶端發送的數據更新請求時,將內容記錄在交換機的持久性日志區,然后便可提前返回完成消息給客戶端,而服務器異步地處理數據更新請求;通過該協議,客戶端的請求延遲可以減半.RedPlane 則采用數據復制的方式進行可編程網絡設備的容錯:在RedPlane 系統中,當可編程交換機需要修改內存狀態時,它會生成包含修改數據的復制請求,并發送至多臺服務器;這些服務器將修改數據存儲到本地的DRAM 中,以此容忍可編程交換機的崩潰.
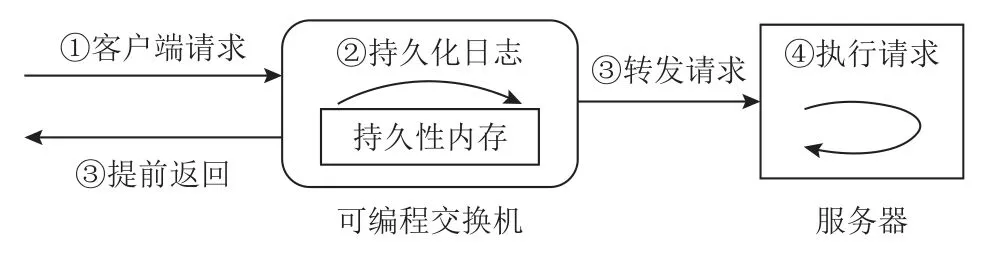
Fig.2 Data update protocol of PMNet圖2 PMNet 的數據更新協議
3 在網存儲系統的分類與研究進展
基于可編程網絡設備的在網存儲系統支持在數據傳輸路徑上執行存儲任務,顛覆了傳統以CPU 為核心的存儲系統架構思想.根據可編程網絡設備執行的任務,我們將在網存儲系統分為4 類:在網數據緩存系統、在網數據協調系統、在網數據調度系統以及在網數據聚合系統.本節將依次介紹這4 類在網存儲系統,并詳細分析典型的系統實例.表3 對這4類系統在多方面進行了對比.

Table 3 Comparison of Four Types of In-Network Storage Systems表3 4 種在網存儲系統的對比
3.1 在網數據緩存系統
在網數據緩存系統利用可編程交換機和智能網卡的內存空間,在網絡上進行數據的緩存或存儲,以提供高吞吐量、低延遲的數據訪問.本節將著重介紹基于可編程交換機的NetCache[16]系統,以及基于智能網卡的KV-Direct[20]系統.
NetCache 由約翰霍普金斯大學提出,用于解決傳統分布式內存鍵值系統的負載不均衡問題.分布式內存鍵值系統將鍵值數據以某種規則分散在多臺服務器的內存中,具有較好的水平擴展能力.然而,現實世界中的負載往往是傾斜的,即少量熱點的鍵值對(key-value pairs)會被頻繁地訪問,這會導致整個分布式內存鍵值系統負載不均衡:某些服務器承受了大量的請求,處于過載狀態;而其他服務器處理的請求較少,處于空閑狀態.負載不均衡嚴重影響系統性能:過載的服務器限制了整個系統的總吞吐量,并導致對熱點鍵值對的訪問會經歷較高的延遲.為此,NetCache 利用可編程交換機緩存熱點鍵值對,用于過濾對應的讀請求,使得后臺服務器處于負載均衡的狀態.
圖3 展示了NetCache 的架構.NetCache 系統由4個組件構成:1)存儲服務器,將鍵值數據存儲在DRAM中;2)客戶端服務器,用于發送鍵值請求,包括查詢(Get)、更新(Put)和刪除(Del);3)可編程交換機,緩存熱點鍵值對以服務Get 操作,并進行熱點鍵值數據的統計;4)交換機控制器,用于向交換機中添加或刪除鍵值對.后端存儲服務器、可編程交換機以及交換機控制器位于同一個機架中,因此所有的客戶端請求均會流經該交換機.
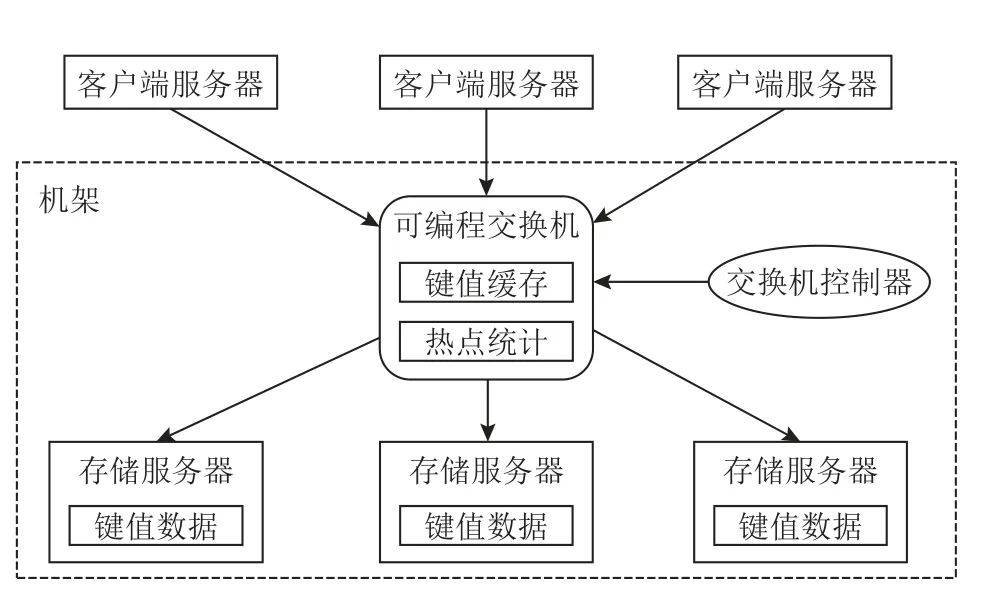
Fig.3 Architecture of NetCache圖3 NetCache 的架構
在NetCache 系統中,交換機與后端存儲服務器協同處理客戶端請求.當交換機接收到客戶端發送的Get 請求時,會先查詢本地的鍵值緩存;若緩存命中,則將對應的值返回給客戶端;若不命中,Get 請求會被路由至請求中指定的存儲服務器,然后存儲服務器查詢本地DRAM,返回對應的值至客戶端.
當交換機接收到客戶端發送的Put 或Del 請求時,也會查詢本地緩存;若緩存命中,則將該鍵值對標記為無效,確保未來的Get 操作不會讀到過期的數據.然后,請求會被路由至對應的存儲服務器,存儲服務器更新或刪除對應鍵值對,并回復客戶端.同時,若該鍵值對屬于交換機的緩存,存儲服務器會異步地發送更新請求至交換機,交換機更新緩存中的該鍵值對內容,并標記為有效.
NetCache 通過動作-匹配表和寄存器數組在交換機中構建了鍵值對的緩存結構.具體地,NetCache 維護了一張查詢表,每個條目對應一個鍵值對:其中的match 字段是鍵,action 部分會產生出一份位圖結構和下標.位圖結構用于定位值被存儲在哪些流水線階段的寄存器數組中,下標用于定位值在寄存器數組中的哪個元素中.通過這種組織方式,NetCache 可以支持變長的值;但對于鍵,由于其存儲在match 字段中,只能是定長的.由于交換機SRAM 空間有限,NetCache 緩存在交換機中的鍵值對數量很少(64 000);但這已經能達到良好的負載均衡效果,這得益于之前的研究結論[24]:在傾斜的負載下,只需要將N× lbN份最頻繁被訪問的鍵值對緩存住,就能夠保證后端的負載均衡,其中N是后端存儲服務器的數目.
NetCache 也將熱點統計功能實現在交換機中.具體地,NetCache 利用寄存器數組構建了一個計數器數組和一個計數-最小略圖(count-min sketch)[25].其中計數器數組用于統計每份被緩存的鍵值對的訪問次數;計數-最小略圖用于近似統計未被緩存的鍵值對的訪問次數.當某一鍵值對的訪問次數到達某一閾值時,交換機將其報告給交換機控制器.交換機控制器向交換機的查詢表中插入對應的條目.為防止交換機將某一熱點鍵值對重復地向控制器報告,NetCache 在交換機中構建了一個布隆過濾器[26],用于近似記錄哪些鍵值對已向控制器報告.
得益于交換機的極高聚合帶寬,NetCache 在Get操作密集的傾斜負載下能提高系統吞吐量1 個數量級.但NetCache 只支持單個機架,具有擴展性問題;后續工作DistCache[27]通過獨立緩存分配和2 次隨機選擇策略將NetCache 擴展到大規模集群.此外,除了負載均衡場景,研究者們設計了高可靠的鍵值存儲系統NetChain[28].NetChain 通過鏈式復制協議(Chain Replication Protocol)[29]將每份鍵值對存儲在多臺交換機的SRAM 上,存儲方式與NetCache 類似.表4 對NetCache,DistCache,NetChain 這3 個基于可編程交換機的緩存系統進行了總結對比.
KV-Direct 系統由微軟研究院提出,它將內存鍵值系統的功能卸載至基于FPGA 的智能網卡上.隨著網絡帶寬的持續提升,服務器端CPU 變成鍵值系統的主要性能瓶頸:從吞吐量上看,單個CPU 核心處理鍵值操作的上限低于8 MOPS;從延遲上看,CPU 的軟件調度和排隊經常導致較大的延遲波動.因此,KV-Direct的目標是通過高性能FPGA 智能網卡完全消除鍵值訪問路徑上的服務器CPU 的介入.在KV-Direct 中,鍵值數據被存儲在CPU 的DRAM 中,智能網卡通過DMA操作訪問CPU DRAM.KV-Direct 重新設計了高效的索引結構、執行引擎以及緩存機制,以充分釋放FPGA 的硬件性能.
在索引結構方面,KV-Direct 構建了高效的鏈式哈希索引.索引由固定數目的哈希桶構成;每個桶中存有若干哈希槽;哈希槽主要包含鍵值對的地址.當插入新的鍵值對時,若對應的哈希桶滿了,網卡則會分配新的哈希桶鏈接至原有哈希桶尾部,形成鏈式結構.由于智能網卡與CPU DRAM 之間為PCIe 連接,帶寬有限,且存在幾百納秒的延遲,該鏈式哈希索引做出了3 個設計以減少DMA 次數:1)每個哈希槽中內嵌了鍵的部分哈希值,在查詢鍵值對時,網卡會首先進行比對,當不匹配時,則不需要讀取CPU DRAM中的鍵值對.2)尺寸較小的鍵值對(如10 B)直接被存儲在哈希桶中,避免了一次DMA 訪問.3)KVDirect 為尺寸較大的鍵值對和哈希桶設計了專門的分配器;分配器的主要邏輯運行在CPU 上,但分配器中的空閑空間元數據被緩存在網卡里,因此,大部分的空間分配和釋放無需網卡執行DMA 操作.
在執行引擎方面,KV-Direct 通過亂序執行保證系統在并發語義正確的同時達到極致的吞吐量.具體地,網卡在FPGA 中維護了保留站(reservation station),用于追蹤所有正在執行的鍵值操作.保留站將哈希沖突的鍵值操作集合維護成隊列結構,網卡按隊列順序執行這些操作,以保證并發執行的正確性.這種基于哈希沖突的方式避免了保留站進行鍵的比較,極大節省了FPGA 上的物理資源;但會引入偽沖突,即某些鍵不同的鍵值操作會被序列化執行.此外,保留站會緩存鍵值操作產生的最新值,用于支持數據轉發(data forwarding),提高執行效率和減少DMA 操作次數.
在緩存機制方面,KV-Direct 將部分數據緩存在智能網卡中的DRAM 空間(網卡DRAM).由于網卡DRAM 的帶寬較低(十幾GBps),傳統的緩存方法會導致整個系統性能受限于網卡DRAM 帶寬.為此,KV-Direct 設計了負載調度器,保證系統能夠同時利用網卡DRAM 和PCIe 的帶寬.具體地,整個CPU DRAM空間被劃分成可緩存部分和不可緩存部分.對可緩存部分的訪問會執行緩存邏輯,即相關數據會被緩存在網卡DRAM 中,當緩存命中時會消耗網卡DRAM帶寬但保存了PCIe 帶寬.對于不可緩存部分,網卡對其所有訪問需要DMA 操作,只消耗PCIe 帶寬.通過調整2 部分CPU DRAM 空間的比例,KV-Direct 使得整個系統可利用的帶寬最大.KV-Direct 系統使用一張網卡就能達到180 MOPS 的吞吐率,并且尾延遲低于10 μs;同時,相比于基于CPU 的鍵值系統,KV-Direct僅使用1/3 的功耗.KV-Direct 的不足也很明顯:未考慮分布式場景以及系統容錯.
除了KV-Direct,復旦大學還提出了基于智能網卡卸載的分布式內存鍵值系統SKV[30],其利用智能網卡中的ARM CPU 執行系統的錯誤檢測和副本操作.
3.2 在網數據協調系統
分布式存儲系統由多臺存儲服務器構成,并運行分布式協議進行服務器之間的協調(比如分布式緩存一致性與分布式事務).傳統的分布式協調方式消耗大量網絡流量和服務器CPU 資源,效率低下.而在網數據協調系統將分布式協議卸載至可編程網絡設備上;得益于可編程交換機和智能網卡在網絡路徑上的優勢,在網數據協調系統能夠極大地提高分布式存儲系統的性能.本節將著重介紹分布式緩存一致性和分布式事務處理相關的研究工作.
1)分布式緩存一致性
分布式共享內存系統Concordia[10]由清華大學提出,利用可編程交換機加速緩存一致性協議.基于高速網絡(如RDMA)的分布式共享內存系統能支持圖計算等大規模內存計算應用.盡管目前網絡帶寬很高(如100 Gbps),但仍低于本地內存的訪問,且網絡延遲遠高于內存延遲.因此,在分布式共享內存系統中,為了減少數據的遠程訪問,每臺服務器一般具有本地緩存.如何保證不同服務器緩存之間的一致性是個極具挑戰的問題,而現有的緩存一致性協議需要服務器之間進行昂貴的分布式協調,極大地降低了系統在數據共享時的性能:基于目錄的緩存一致性協議引入多次網絡往返,且當熱點數據存在時,服務器會成為系統瓶頸;基于廣播的緩存一致性協議會導致網絡和CPU 資源的消耗,這是由于每次緩存一致性請求需要被廣播到所有的服務器處理.Concordia利用可編程交換機在網絡中樞上的位置優勢,設計了高效的在網分布式緩存一致性協議.圖4 展示了其架構.
Concordia 是機架級別的分布式共享內存系統,主要由內存節點和可編程交換機2 個組件構成.內存節點是普通的服務器,它們將自己的DRAM 空間分為了2 部分:全局共享內存以及本地緩存.所有內存節點的全局共享內存一起構成了全局地址空間,可以被共享讀寫;內存節點的本地緩存用于緩存最近訪問的全局內存,由此減少網絡訪問開銷.可編程交換機記錄了緩存塊的信息,并執行緩存一致性邏輯.具體地,如圖4 所示,針對每份緩存塊,可編程交換機通過寄存器數組記錄了相關元數據,包括:①緩存塊的標簽(tag),即對應的全局內存地址的高位,用于唯一標識該緩存塊和索引其他的元數據;②讀寫鎖,用于序列化沖突的緩存一致性請求,比如2 個內存節點對同一份緩存塊進行寫操作;③狀態,用于描述該緩存塊所處的狀態,如未共享的(unshared)、共享的(shared)或者被修改的(modified);④節點列表,即持有該緩存塊的內存節點的集合.利用這些元數據,Concordia 在交換機中高效地處理緩存一致性請求.
這里通過一個例子描述Concordia 系統中的緩存一致性請求執行流程.標簽為0x12b 的緩存塊的元數據如圖4 所示,它的狀態為共享的,被內存節點1 和節點3 緩存在本地;此外,讀寫鎖字段為空,代表當前不存在針對該緩存塊的一致性操作.當節點2 需要寫該緩存塊對應的全局地址時,會發現本地緩存缺失,因此產生一個寫缺失(write miss)請求發送至可編程交換機;該請求中會捎帶標簽0x12b.當可編程交換機接收到該請求時,首先通過標簽查詢到該緩存塊的其他元數據.然后,可編程交換機嘗試獲得對應的寫鎖,若失敗,則返回錯誤消息給節點2,節點2將進行請求重試.若持鎖成功,可編程交換機根據請求類型(即write miss)和緩存塊狀態(即shared)做出相應的動作,在這個例子中就是將一致性請求多播至節點列表對應的服務器(即內存節點1 和節點3).當內存節點1 和節點3 收到一致性請求時,會將本地持有的緩存塊無效化,然后發送回復給節點2.此外,其中1 個節點(節點1 或者節點3)會將該緩存塊的內容也發送至節點2,這由交換機隨機挑選.當節點2 收到所有的回復時,將緩存塊數據存放在本地緩存中,便可繼續進行對全局地址空間的讀寫操作.節點2 會發送異步的解鎖請求給交換機,請求中會捎帶標簽0x12b.當交換機接收到該解鎖請求時,則會釋放該緩存塊的鎖,并修改對應元數據:狀態修改為modified,節點列表修改為{2}.從該例子可以看出,Concordia 的在網緩存一致性協議在數據讀寫的關鍵路徑上只需1 次網絡往返,且不會像廣播協議一樣引入額外的網絡和CPU 資源的消耗.
為了解決可編程交換機內存空間小的問題,Concordia 提出動態地將緩存塊的一致性管理權限在交換機與內存節點之間遷移.具體地,交換機只管理活躍緩存塊的緩存一致性;對于很少觸發緩存一致性協議的緩存塊,它們的一致性由內存節點管理退化成傳統的基于目錄的協議.為了保證遷移過程中整個系統的并發正確性,Concordia 設計了細粒度的遷移協議,每次遷移只會阻塞對一份緩存塊的訪問.
除了Concordia,還有一些研究工作也利用可編程交換機保證不同服務器的數據之間的一致性.華盛頓大學提出了分布式對象系統Pegasus[31]以解決負載不均衡問題;與NetCache 使用緩存的方式不同,Pegasus 將熱點的對象復制至多臺服務器,以均攤相應的訪問.在Pegasus 系統中,可編程交換機記錄熱點對象所在的服務器列表,當發生寫請求時更新列表,以保證后續的讀操作能獲得最新數據.此外,耶魯大學提出的Mind[32]系統針對的是分離式內存場景,即多個計算節點訪問遠程內存池,并將數據緩存至本地.Mind 利用可編程交換機保證不同計算節點的緩存之間處于一致的狀態.此外,約翰霍普金斯大學提出NetLock[33],通過交換機實現高性能的鎖管理器,用于上層應用保證數據一致性.NetLock 將鎖資源存儲在交換機的內存中,因此相比于傳統基于服務器的設計,能夠提高吞吐量1 個數量級;NetLock 在交換機中為鎖請求維護了隊列結構,以保證能夠公平地服務沖突的鎖請求,降低上層應用的尾延遲.表5對上述在網緩存一致性系統進行了總結對比.

Table 5 Comparison of In-Network Cache Coherence Systems表5 在網緩存一致性系統對比
2)分布式事務處理
分布式事務系統將數據劃分在不同服務器中,并通過分布式并發控制和提交協議提供事務語義.這些協議存在很高的協調開銷,包括網絡通信、CPU 排隊等,而這些開銷位于事務提交的關鍵路徑上,會導致高延遲和高沖突,嚴重降低系統性能.因此,研究人員利用可編程網絡設備的處理能力和得天獨厚的位置卸載事務系統中的協調操作,減少網絡往返和CPU 消耗.本節介紹基于可編程交換機的Eris[34]和SwitchTx[21]系統,以及基于智能網卡的Xenic[35]系統.
華盛頓大學提出了基于在網排序的分布式事務系統Eris[34],通過將序號向量生成器卸載到可編程交換機中,為無依賴事務(independent transactions)[36]指定序號向量,僅需1 次網絡通信即可完成無依賴事務,因此顯著減少了分布式事務的協調開銷.在Eris系統中,數據被分散至多個數據分區,每個數據分區由多臺存儲數據副本的存儲服務器組成.序號向量中的1 個序號對應1 個數據分區.圖5 展示了Eris 系統中無依賴事務的提交流程:
在Eris 系統中,客戶端將事務請求發送給可編程交換機,可編程交換機根據事務涉及的數據分區為其生成序號向量,同時將事務請求廣播至所有涉及到的數據分區;數據分區中的存儲服務器按照序號順序執行請求.交換機生成的序號向量為無依賴事務建立一個可線性化的執行順序,而不需要額外的網絡協調.為支持通用事務(比如讀寫集未知),Eris 將其分解為多個無依賴事務.Eris 存在著擴展性受限的問題:當系統規模擴大時中心化的序號向量生成器會成為性能瓶頸,限制系統的總吞吐量.
清華大學提出了可擴展的在網分布式事務系統SwitchTx[21],將分布式事務協調過程抽象為多次“收集-分發”操作的組合,并將這些操作卸載到集群中的多個可編程交換機中.相較于Eris 系統,SwitchTx 系統避免了單點瓶頸問題.圖6 展示了SwitchTx 系統的組件構成以及事務處理流程.
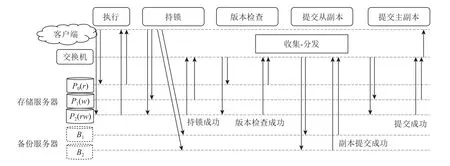
Fig.6 Transaction processing workflow of SwitchTx圖6 SwitchTx 的事務處理流程
SwitchTx 系統由4 個組件構成:①客戶端服務器,用于發起事務并完成事務的執行;②存儲服務器,將數據存儲在DRAM 中并維護數據的版本和鎖信息;③備份服務器,存儲數據的備份以提供系統容錯能力;④可編程交換機,完成事務提交過程多個存儲服務器和備份服務器之間的協調.
SwitchTx 系統將樂觀并發控制協議[37]和主從備份副本協議的協調任務卸載到交換機.SwitchTx 中的事務提交可以分為5 個階段,包括執行階段、持鎖階段、版本檢查階段、提交從副本階段以及提交主副本階段.這些階段是依次進行的,其中的協調任務是同步來自當前階段的參與者的結果,并使事務進入下一個階段.SwitchTx 通過在交換機中設計“收集-分發”原語完成協調任務,即通過“收集”步驟統計當前階段的執行結果,通過“分發”步驟使事務進入下一階段.以從持鎖階段到版本檢查階段的協調任務為例,當交換機收集到所有寫參與者的包含持鎖成功信息的網絡包,它將向所有讀參與者廣播版本檢查的請求.
SwitchTx 將“收集-分發”原語擴展到多個交換機,這得益于SwitchTx 中的協調是去中心化的,即不同的事務可以使用不同的交換機來執行“收集-分發”操作.具體地,SwitchTx 為每個事務選擇一組交換機來執行“收集-分發”操作,多個交換機和服務器構成樹形的拓撲結構,其中最高層交換機為樹的根,其余交換機為中間節點,存儲服務器、備份服務器和客戶端為葉子節點.在“收集”步驟中,非根交換機從其子節點(交換機或服務器)收集消息,并將結果發送到其父節點.當根節點交換機收集到足夠數目的消息時,則開始執行“分發”步驟,即將請求廣播給對應事務階段的參與者.在“分發”步驟中,消息沿著樹結構從根節點多播到葉子節點.
SwitchTx 只需在可編程交換機中為每個“收集-分發”操作實現一個計數器,即用寄存器數組記錄“收集”步驟中已收集到的網絡包數量,因此對交換機存儲空間的占用小.當可編程交換機接收到網絡包時,根據其包頭中標記的事務編號取出對應的計數器,增加計數器數值并與網絡包攜帶的閾值信息對比.若計數器數值小于閾值,交換機丟棄網絡包;若計數器數值等于閾值,交換機開始“分發”步驟,并重置計數器.其中計數器以事務編號為索引存儲在哈希表中.
此外,華盛頓大學提出了分布式事務系統Xenic[35],利用基于ARM CPU 的on-path 智能網卡進行2 方面的卸載:事務的協調任務以及數據并發索引.具體地,Xenic 在客戶端網卡存儲事務的臨時狀態,完成事務協調任務,減少協調過程中的通信時延.Xenic 的服務端網卡利用網卡內存存儲熱點數據以及鎖信息,消除遠程數據訪問的PCIe 開銷;同時利用智能網卡的ARM CPU 處理復雜數據訪問,以減少服務端CPU開銷.Xenic 設計了智能網卡內存與主機內存協同的Robin hood 哈希索引結構[38],減少網卡處理遠程數據訪問請求時的DMA 次數.事務執行過程中的副本操作也完全由網卡執行,這進一步降低了主機CPU的消耗.除了事務系統,一些分布式文件系統也將副本操作卸載至智能網卡:比如LineFS[39]將包括數據副本的文件系統后臺操作卸載至基于ARM CPU 的off-path 智能網卡,由此釋放客戶端的CPU 資源,減少文件系統與計算任務之間的干擾.表6 對上述在網分布式事務系統進行了總結對比.

Table 6 Comparison of In-Network Transaction Systems表6 在網事務系統對比
3.3 在網數據調度系統
分布式存儲系統的服務器數目不斷增加,且每臺服務器中的CPU 核心數目也在持續增長.這些趨勢導致了2 個關鍵問題:多CPU 核心并發處理請求容易產生資源沖突;服務器或CPU 核心之間存在負載不均衡.在網數據調度系統利用可編程交換機和智能網卡的中心化位置優勢,在網絡上進行數據訪問請求的調度,旨在減少多核并發的資源競爭開銷,或保證服務器以及CPU 核心之間的負載均衡.本節將著重介紹針對多核并發的AlNiCo 系統[22],以及針對負載均衡的R2P2 系統[17].
1)針對多核并發的在網數據調度系統
在單機內存事務存儲系統中,系統接收來自網絡的事務請求并將它們分派給工作線程.由于事務請求包括對多份數據的讀/寫操作,工作線程需要使用并發控制協議來執行事務,以保證事務的隔離性.但是,當存在沖突的2 個事務并發執行時,事務會被中止或阻塞.中止會導致事務重試,阻塞可能會級聯阻塞更多事務,中止和阻塞均會導致系統性能下降.因此事務系統需要通過合理的調度模塊將沖突的事務調度到相同的工作線程,來最小化并發事務之間的沖突.現有基于軟件的調度算法包括靜態數據劃分和基于圖劃分,靜態數據劃分無法處理動態負載,而基于圖劃分的方法需要對請求做批處理,即積攢大量請求后處理,引入額外的延遲.
清華大學提出了在網事務請求調度系統AlNiCo,將智能網卡與事務軟件協同設計,利用智能網卡低延遲地執行調度算法,并通過軟件反饋機制根據負載變化更新調度算法.圖7 展示了AlNiCo 的整體架構:客戶端通過網絡連接到服務端的智能網卡并發送事務請求;智能網卡上的FPGA 執行調度算法選擇合適的工作線程分發請求;工作線程在執行事務請求的同時統計負載信息,用于定期更新調度算法的參數.
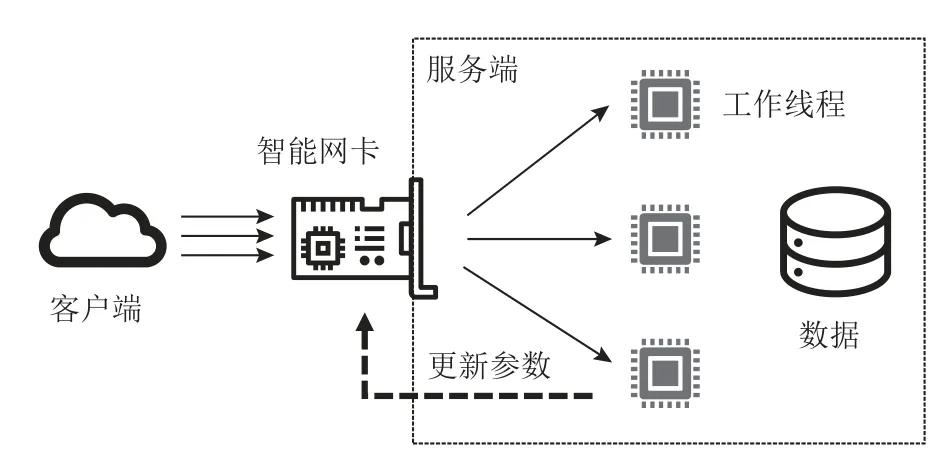
Fig.7 Architecture of AlNiCo圖7 AlNiCo 的架構
AlNiCo 將調度信息分為3 種類型:1)請求信息,即請求訪問的數據和對應的訪問方式(讀或寫);2)工作線程信息,即每個工作線程上正在執行或將要執行的事務;3)全局狀態信息,包括數據熱點等工作負載特征.AlNiCo 系統將這3 種調度信息編碼為向量,并將調度算法設計為向量計算,以此來充分發揮網卡上FPGA 的計算加速能力.具體地,AlNiCo 系統用特征向量表示請求信息,向量中每個特征代表一個數據分區是否被訪問和如何被訪問(讀/寫);工作線程信息用該線程正在執行/排隊的事務的特征向量的合集表示;AlNiCo 將數據熱點信息表示為特征向量中每個特征的權重.基于上述編碼方法,AlNiCo 設計了沖突感知的調度算法,利用FPGA 高效地比較事務的特征向量與工作線程的特征向量之間的相似程度(越相似則代表兩者沖突越大),為事務選擇最可能產生沖突的工作線程.
AlNiCo 在Mellanox Innova-2 網卡[7]上實現了通用的可調度的遠程過程調用(remote procedure call,RPC)框架.Innova-2 是一款基于FPGA 的off-path 智能網卡.AlNiCo 的RPC 框架不僅可以用于實現事務請求調度算法,而且可以用于其他基于請求內容調度的應用場景.圖8 展示了AlNiCo 系統的RPC 框架:
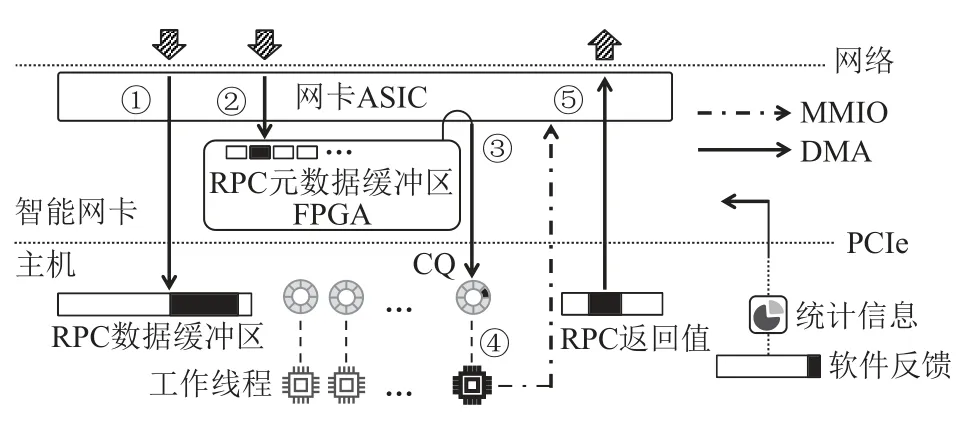
Fig.8 RPC framework of AlNiCo圖8 AlNiCo 的RPC 框架
該框架通過RDMA 實現服務端與客戶端之間的通信,以及通過DMA 和MMIO 實現FPGA 與主機之間的通信.AlNiCo 為每個RPC 請求添加固定格式的元數據,客戶端可以根據調度需求將請求信息編碼到元數據,在AlNiCo 系統的事務調度中,元數據為事務特征向量.該RPC 框架采用元數據與數據分離的設計,其在服務器主機內存上維護數據緩沖區,在FPGA 上維護元數據緩沖區.RPC 的處理流程為:客戶端同時發起2 個單邊RDMA 寫請求分別將RPC 數據(①)和RPC 元數據(②)發送到它們各自的緩沖區.FPGA 上的調度模塊輪詢元數據緩沖區,以確定新請求的到達,之后調度模塊會執行調度算法選擇一個工作線程.在做出調度決策之后,調度模塊通過DMA 操作向工作線程的接收完成隊列(CQ)添加條目(③),來通知被選定的工作線程.CQ 中的條目僅包含RPC 數據的地址,而不包括RPC 的元數據.由于RDMA 寫操作是保證順序的,因此當工作線程讀取到新的CQ 條目(④)后,可以從RPC 數據緩沖區獲得完整的RPC 數據.最后,工作線程執行事務請求,并通過RDMA 寫操作(⑤)回復客戶端.此外,CPU 向智能網卡暴露了FPGA 可讀的配置緩沖區,軟件可以將調度器的新配置寫入緩沖區,FPGA 上的調度器定期讀取配置并更新.
2)針對負載均衡的在網數據調度系統
遠程過程調用RPC 框架被廣泛應用在數據中心的存儲系統中,是實現系統服務等級目標(service level objective,SLO)的核心組件.隨著系統規模的擴大,RPC 框架為保證可擴展性,需通過調度保證多節點之間以及節點內多核之間的負載均衡;同時,現代數據中心的存儲系統如內存緩存的服務延遲僅為數百微秒,這就要求負載均衡調度本身具有極低延遲.
瑞士聯邦理工學院提出R2P2[17],它是基于可編程交換機的負載均衡RPC 框架.該框架使用JBSQ(joinbounded-shortest-queue)負載均衡策略;JBSQ 的調度質量接近單隊列模型,且實際擴展性更好.R2P2 在交換機中為每個服務器維護有限深度的隊列,深度通常取2 或3,代表該服務器未執行完的RPC 請求數目.圖9 展示了R2P2 的系統架構和RPC 處理流程.
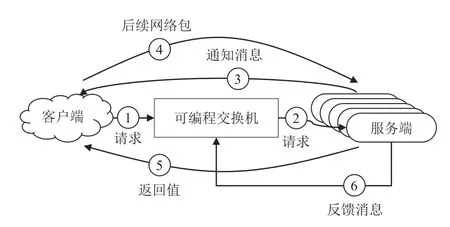
Fig.9 Architecture of R2P2圖9 R2P2 的架構
R2P2 通過以下階段處理RPC 請求:①客戶端向交換機發送RPC 請求,若RPC 請求的尺寸較大,由多個網絡包構成,則只需要發送1 個網絡包,并攜帶客戶端的信息以及該RPC 請求的唯一標識符;②可編程交換機讀取服務器的隊列信息,若存在某些服務器的隊列空閑,則選擇隊列最短的作為目標服務器,并將該RPC 請求轉發給它和并更新隊列信息;若所有服務器隊列都滿了,交換機則循環該RPC 請求,直到存在空閑隊列;③如果RPC 請求由多個網絡包構成,則目標服務器將發送通知消息至客戶端;④客戶端在收到通知消息后,將RPC 請求的剩余部分發送到該目標服務器,該過程完全繞過交換機中的調度邏輯;⑤目標服務器執行完RPC 請求后,將處理結果返回給客戶端;⑥服務器向交換機發送反饋消息,通知自身當前的狀態,包括隊列空閑狀況和可用性等.
由于可編程交換機的流水線硬件架構的限制,R2P2 設計了多輪的方式選擇最短的隊列.具體地,在隊列最大深度為n的系統設置下,每個RPC 請求第1 次經過交換機時,交換機進行第1 輪操作,尋找隊列長度小于等于0 的服務器(隊列長度信息被存儲在可編程交換機的寄存器數組中),若找到則確定了目標服務器;否則,該RPC 請求會再次被重新送回交換機流水線,進行第2 輪操作,尋找隊列長度小于等于1 的服務器;以此類推,若在第n輪操作時依舊找不到隊列長度小于等于n-1的服務器時,則說明所有的服務器隊列均已滿,該RPC 請求將在交換機內循環,直到存在某個服務器的隊列長度小于n.
除了R2P2 之外,約翰霍普金斯大學還提出了Rack-Sched[40],這是結合服務器之間調度和CPU 核心之間調度的統一調度框架,專為機架級別的應用設計.服務器之間的調度由可編程交換機實現:交換機為RPC 請求選擇目的服務器以達到服務器之間的負載均衡,與R2P2 不同,RackSched 采用樹狀歸約算法選擇最短隊列從而避免網絡包在交換機內的重新傳輸.此外,可編程交換機追蹤每臺服務器上的實時負載.CPU 核心之間調度通過中心化的調度線程來實現,借鑒了單機調度系統Shinjuku[41].
上述R2P2 和RackSched 系統雖然支持在服務器之間進行負載均衡調度,但忽略了數據一致性,即在存儲系統中,某些數據的最新版本只存儲在某些服務器中,因此交換機無法對相關RPC 請求進行任意調度.Harmonia[42]和FLAIR[43]這2 個系統利用可編程交換支持保證數據一致性的請求調度.具體地,它們針對的場景是副本協議,1 份數據通過共識協議被冗余地存儲在不同服務器(包括1 個主副本服務器以及多個從副本服務器),交換機將客戶端的讀請求高效地調度至具有最新版本數據的服務器上.這里的主要設計難點在于交換機如何與共識協議結合,識別哪些服務器具有讀請求所需的最新數據.Harmonia在可編程交換機中維護了細粒度哈希表,用于實時記錄哪些數據存在并發的寫請求,對于這些數據的讀請求只能被路由至主副本,對于其余數據的讀操作可被調度至任一從副本.FLAIR 將整個數據范圍切分成大量的分區,在交換機中記錄每個分區的穩定狀態:當某個分區存在進行中的寫請求時,則被標記成不穩定,對應的讀請求只能被路由至主副本;對于穩定分區的讀請求能以負載均衡的方式被調度至某一從副本.表7 對本節涉及的在網數據調度系統進行了總結對比.
3.4 在網數據聚合系統
在網數據聚合系統主要利用可編程交換機帶寬極高且位于網絡中樞的特點,在交換機內進行數據處理,以提高存儲系統的性能.本節主要介紹基于可編程交換機的糾刪碼系統NetEC[23].
NetEC 由清華大學提出,其可利用可編程交換機加速糾刪碼系統的數據重構性能.相比于副本機制,糾刪碼在保證相同數據可靠性的同時能夠大幅度降低存儲空間的使用.例如,在廣泛使用的里德-所羅門碼(RS 碼)[44]中,針對k份原始數據塊,能夠計算出r份校驗塊;這k份原始數據塊能夠通過這k+r份中的任意k份重構出來,因此最多能夠容忍r個錯誤.糾刪碼的主要缺陷是數據重構性能低下.假設分布式存儲系統使用RS(k,r)編碼,當某臺服務器崩潰后,恢復丟失的任何一份數據塊需要從k臺其他服務器讀取相應的數據塊,然后進行向量點積計算重構.此時,整個系統的重構速度受限于接收端網卡帶寬:假設網卡帶寬為B,恢復大小為M的數據需要的時間為k×M/B.NetEC 的基本思想是在交換機上完成糾刪碼的重構過程,由此克服接收端網卡的帶寬瓶頸并消除CPU 的計算開銷.圖10 展示了其架構.
在圖10 中的例子里,交換機根據服務器B1,B2,B3中的數據進行糾刪碼的重構,重構的結果被存儲在服務器A中.B1,B2,B3將數據塊發送至可編程交換機,可編程交換機主要完成2 項任務:1)針對每個字(word),即圖10 中的xi,進行伽羅華域的乘法,將其乘以常數ai;2)將來自不同服務器的乘法結果進行求和,獲得重構的結果a1x1+a2x2+a3x3.由于交換機的硬件限制,NetEC 對這2 項任務進行了精心設計.由于交換機不支持乘法運算,NetEC 將乘法運算過程轉換為查表和加法.具體地,在NetEC 中,每個word 為16 b,對于16 b 的每個數字,可編程交換機預先存儲了對數查詢表和指數查詢表.因此,對于xi和ai相乘,交換機先通過查詢對數查詢表獲得lb(xi)的值,而lb(ai)的值是預先知道的;然后,將l b(xi)和lb(ai)相加,獲得lb(ai xi);最后,通過查詢指數查詢表,獲得ai xi的值.對于求和操作,NetEC 設計了求和緩存結構,對于每個word,分配初始值為0 的緩存區,當計算完ai xi后,交換機將ai xi與現有緩存區的值相加并更新緩存區.同時,交換機維護了位圖,用于記錄來自哪些服務器的word 已經完成了乘法和求和.若所有服務器的word 都已被處理,最后的重構結果將被發送至服務器A.為了防止不同發送端的數據傳輸不同步導致交換機內求和緩存結構空間占用過大,NetEC 復用了TCP 協議棧的功能,保證重構過程中發送端服務器在交換機中暫存的求和結果不超過TCP 接收窗口的大小.NetEC 被集成進HDFS[45]中,相比于原有糾刪重構方法,提升重構速度最高達9 倍,且完全消除了重構過程的CPU 開銷.
除了糾刪碼場景,利用可編程交換機進行數據聚合還能夠加速分布式機器學習訓練系統.微軟研究院提出了SwitchML[46]系統,將機器學習訓練過程中的模型參數聚合卸載至可編程交換機.針對可編程交換機不支持浮點數計算的問題,SwitchML 設計了服務器與交換機協同設計的方法:服務器將需要聚合的浮點參數進行量化,轉換成定點數,因此交換機只需要進行定點數的聚合.此外,清華大學提出了ATP系統[47],利用多臺交換機協同加速機器學習的訓練任務,且能高效支持多個訓練任務共同運行的多租戶場景;沙特阿拉伯阿卜杜拉國王科技大學提出了針對稀疏訓練任務的數據聚合系統OmniReduce[48],并將部分聚合算法卸載至可編程交換機;其他工作如iSwitch[49]和Flare[50]設計了加速數據聚合的定制化交換機硬件架構,其中iSwitch 采用了FPGA 硬件,Flare 采用了PsPIN[51]硬件.此外,Flare 進一步支持用戶自定義聚合操作處理的數據類型.表8 對上述在網數據聚合系統進行了對比總結.
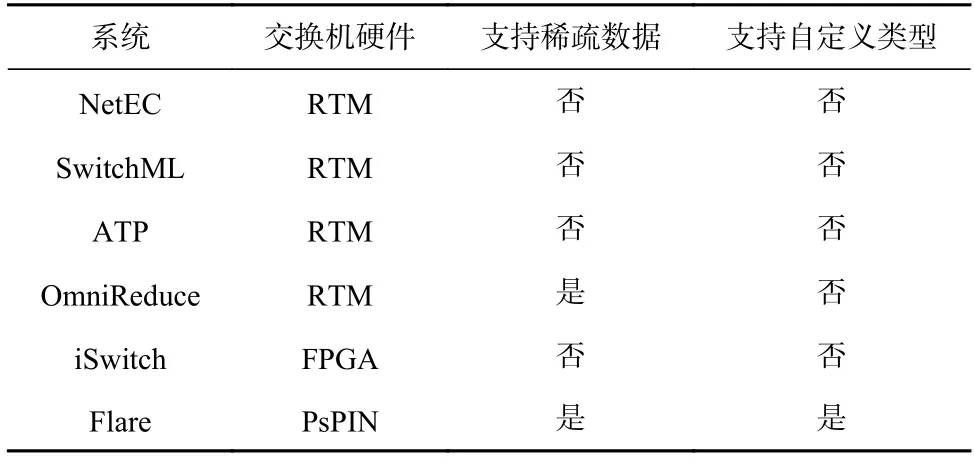
Table 8 Comparison of In-Network Data Aggregation Systems表8 在網數據聚合系統對比
4 總結與展望
本文首先從可編程網絡硬件(包括可編程交換機和智能網卡)的特性出發,展開分析了構建在網存儲系統面臨的挑戰,并對現有研究工作詳細地分類與剖析.現有研究工作利用可編程網絡硬件對存儲系統的不同模塊進行加速,包括數據緩存、協調、調度以及聚合,能夠顯著提高存儲系統的性能.然而,研究人員仍然需要在4 個方面進行深入探索,才能讓在網存儲系統廣泛普及到數據中心和超算中心.
1)交換機與網卡協同.現有的在網存儲系統大多孤立地使用可編程交換機或者智能網卡,無法做到全方位的存儲功能卸載.而未來的在網存儲系統應該是全編程的:可編程交換機和智能網卡協同工作、互相補充.其中可編程交換機執行服務器之間的任務,智能網卡執行服務器內部的任務.例如,對于在網緩存系統,可利用交換機緩存全局最熱的數據,而利用智能網卡緩存服務器中較熱的數據,以達到整體性能的最優.當交換機與網卡協同設計時,存儲系統的故障域將進一步擴大,這需要引入新的高效容錯機制.
2)多租戶.當在網存儲系統被部署至云環境時,需高效地支持多租戶,即多租戶之間要進行資源的共享和隔離.具體地,多個租戶需分時復用可編程交換機和智能網卡的計算、內存資源;同時,當出現資源競爭時,多個租戶之間需達到較好的性能隔離,不會相互影響.支持多租戶需要編譯器和網絡硬件體系結構的共同支持,為不同租戶卸載的存儲功能高效分配可編程網絡設備的硬件資源.例如,對于在網數據聚合系統,該如何分配可編程交換機的內存空間和帶寬,以滿足多個租戶的服務等級目標.目前,已有少量研究工作利用智能網卡進行了存儲虛擬化的探索,例如芝加哥大學提出的LeapIO 系統[52].在多租戶環境下,在網存儲系統的容錯將變得愈發復雜,需考慮某個在網存儲系統的失效不會影響其他租戶系統的可用性.
3)安全.目前越來越多的網絡數據為了安全考慮被加密,此時就需要可編程交換機和智能網卡能夠高效地處理加密的數據.在存儲系統軟件設計方面,我們需要首先分析清楚哪些數據需加密,比如用戶請求;哪些無需加密,比如存儲系統的元數據.在網絡硬件設計方面,需要讓交換機和網卡支持同態加密,在加密的網絡數據上進行處理和計算.
4)自動卸載.從頭構建可商用的高可靠在網存儲系統極其困難,需要大量的工程代碼和測試驗證.如果能夠將現有成熟的存儲系統如Memcached[53],Ceph[54]中的某些模塊自動卸載至可編程交換機和智能網卡,就能既利用現有的系統代碼,又能享受到可編程網絡設備帶來的性能紅利.這需要研究自動卸載技術,自動分析現有存儲系統代碼并將某些模塊自動卸載至可編程網絡設備.這里面存在諸多技術挑戰,比如如何識別對哪些模塊的卸載會帶來性能收益,如何保證部分模塊被卸載后整體系統功能上依舊正確.
作者貢獻聲明:汪慶負責文獻的搜集整理、論文整體架構的設計和論文主要內容的撰寫;李俊儒負責論文部分內容的撰寫;舒繼武負責論文結構的討論和修改.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
