一種考慮隱私保護的深度強化學習任務分配模型
2023-11-24 05:25:54楊明川朱敬華李元婧奚赫然
計算機研究與發展 2023年11期
楊明川 朱敬華,2 李元婧 奚赫然,2
1(黑龍江大學計算機科學與技術學院 哈爾濱 150006)
2(數據庫與并行計算重點實驗室(黑龍江大學)哈爾濱 150006)
(mrvincenty@163.com)
移動群智感知(mobile crowdsensing,MCS)是Ganti等人[1]提出的,是一種在用戶或社區之間感知和共享數據的新方法.Guo 等人[2]給MCS 更為明確的定義:“MCS 是一種新的感知范式,使普通公民能夠貢獻從移動設備感知或生成的數據,聚合和融合云中的數據,用于人群智能提取和以人為中心的服務交付.”[3]隨著高性能的便攜式移動設備與高速智能網絡的普及,移動群智感知技術快速發展并深入到智慧醫療、交通流量預測以及智慧城市等各個領域,需要采集處理的數據集也日漸龐大,MCS 系統需要大量用戶的參與和貢獻[4],如何在數量龐大的參與者中選擇合適的參與者完成給定的感知計算任務,且最大化平臺和用戶的收益顯得格外重要.任務分配系統主要由3 部分組成:平臺(任務發布者)、工人(用戶,攜帶移動智能設備負責采集感知數據)和任務(如收集某地區的空氣質量數據、監測某路段的交通流量等).如圖1 所示,任務由平臺基于一定的收益計算機制分配給工人,然后工人利用移動智能設備到指定任務點進行相關感知數據的收集并上傳到平臺獲取相應報酬.一方面,考慮到任務的時效性以及預算,任務應當被合理地分配給合適的工人,保證任務分配合理化的同時盡可能最大化平臺總收益;另一方面,工人上傳信息時通常無法避免暴露自身位置等隱私信息.因此,在MCS 系統中,合理的任務分配機制與工人信息的隱私保護問題尤為重要.傳統的任務分配算法,如螞蟻算法、貪婪算法,適合于小規模數據集,應用于工人與任務信息固定的靜態系統,但實際問題中工人與任務的位置、狀態信息會不斷改變,因此,深度學習被越來越多的研究者引入到這樣的動態系統中來解決相應的動態規劃問題.
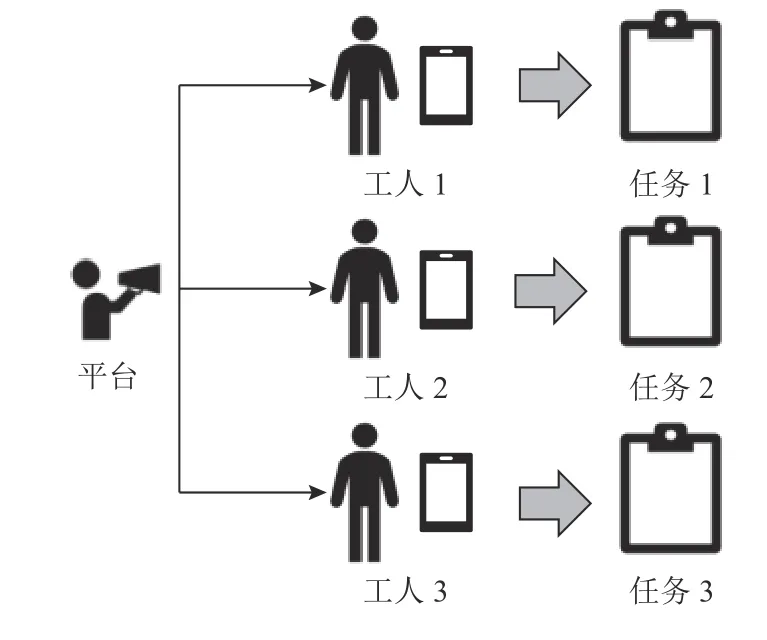
Fig.1 Diagram of MCS task assignment system圖1 MCS 任務分配系統圖示
深度強化學習(deep reinforcement learning,DRL)可以基于過去的經驗,通過智能體選擇動作與環境交互并獲得相應的狀態和回報[5],在每次進行決策的過程中,智能體的策略選擇的概率分布不斷調整,最終達到最優的全局策略.因此在動態的MCS 問題中,DRL 往往能發揮更好的性能.在DRL 的眾多方法中,DQN(deep Q-network)[6]和 A3C(asynchronous advantage actor-critic)[7]可以表現出良好性能,但僅限在離散的動作空間中;DDPG(deep deterministic policy gradient)[8]是一種離線的、確定性的方法,相對不適合需要實時控制解決方案的動態場景;TRPO(trust region policy optimization)[9]采用信任區域方法,其性能優于許多隨機在線策略梯度方法,更適合于需要更多探索的場景;PPO(proximal policy optimization)[10]是一種無模型的、基于策略的、基于梯度的強化學習方法,它在連續控制問題的表現極其優異,并具有TRPO 的相應優點且實現復雜性要低得多.本文的算法采用了PPO 框架,該框架可以更好地適配離散型和連續型的狀態/動作集合,甚至在復合型的狀態/動作集合的表現也較為良好,并且相對于其他的DRL方法,PPO 的表現也較為優異,具有更快的收斂性.
同時,考慮到工人在與平臺進行數據交互時往往會暴露自己的移動軌跡信息,因而本文采用本地差分隱私在工人與平臺的交互中進行隱私保護.差分隱私的概念最早由Dwork[11]提出,建立在嚴格的數學理論基礎上,對隱私保護提供了量化的評估方法和嚴謹的數學證明.本文方法在平臺與工人的信息交互中,利用本地差分隱私的方法,對其位置信息加入隨機噪聲,最大限度地保護工人的隱私信息.
本文是面向MCS 任務分配問題,使用DRL 與差分隱私方法在保護隱私的前提下獲得優化的任務分配策略.將動態環境下的任務分配問題定義為一個基于離散型數據集來進行動態規劃的優化問題,并使用基于DRL 的算法來解決動態環境下的任務分配問題.具體來說,在每次迭代開始時,該算法觀察了之前迭代中平臺的分配策略、平臺收益、工人收益、現有任務信息以及工人信息.根據觀察結果,由基于DRL 的算法來決定工人分配到的任務以及任務的順序,在此過程中利用差分隱私來對工人相關隱私信息做了模糊化處理.本文的目標是最大化平臺的總收益和工人收益,被定義為工人收益與平臺總收益的聯合約束問題,此外還考慮了隱私保護的相關問題.本文的主要貢獻總結為4 個方面:
1)將MCS 動態場景下的任務分配問題建模為一個多目標優化問題,并證明為NP-hard 問題.充分考慮了在MCS 的任務分配問題中,工人與任務狀態信息不斷變化的動態系統,以及工人與平臺進行數據交互的隱私保護的必要性.
2)提出基于DRL 的PPO 方法求解該優化問題.相比于傳統方法,DRL 在中大型數據集的MCS 問題中表現性能良好、收斂性好,能更快達到最優解,同時考慮了真實的MCS 中工人和任務的動態性,利用DRL 方法更適用于解決此類動態的、非確定性的MCS 問題.
3)提出基于差分隱私的任務分配方法.在工人的智能移動設備與中央服務器交互中利用本地差分隱私的方法,對工人的位置信息加入隨機噪聲,模糊化工人位置信息,進而解決中央服務器收集工人信息時存在的隱私泄露問題.
4)通過實驗評估本文方法的有效性和高性能.通過模擬數據集的實驗,對比了傳統方法與現有方法,驗證了本文的模型具有穩定性能,且收斂效果較好;此外還進行了消融實驗,證明了加入隱私保護方法的有效性.
1 相關工作
1.1 傳統任務分配方法
Cheung 等人[12]研究了時間敏感和位置依賴的感知任務的分配問題.考慮到具有不同初始位置、移動成本和速度以及聲譽級別的異構用戶,提出了一種貪婪算法來計算該問題的近似解.該算法要求每個用戶專注于自己的收益,并向用戶提供一個異步的分布式算法來計算用戶的移動性計劃.該算法的設計目標是最大化用戶收益,但無法適用于工人狀態信息變化的動態系統.在文獻[13]中,Li 等人提出了基于蟻群算法ACO(ant colony optimization)的啟發式多任務調度算法來確定任務調度策略,對工人福利的計算模型進行理論分析,利用基于ACO 的啟發式多任務調度算法來確定任務調度策略,以最大限度地提高工人的利益.但該方法同樣僅適用于靜態系統,對于動態系統,越來越多的研究者傾向于基于DRL 的算法[14-15].
1.2 基于DRL 的算法
2013 年谷歌的DeepMind 團隊發表了利用強化學習玩Atari 游戲的文章[16],DRL 開始炙手可熱,相關算法被更多的研究者引入到各個領域.Kim 等人[17]將DRL 的方法應用于無人機的任務分配問題上,用基于Q 值的深度強化學習算法 DQN 來實現快速策略收斂,從而有可能適用于更大規模的系統,進而解決難以量化的由隨機環境引起的無人機移動性的隨機性問題.Tao 等人[18]使用雙深度Q 網絡(double deep Q-network,DDQN)來解決任務分配問題,作為一個具有時間窗的路徑規劃問題,考慮了感知任務的位置依賴性和時間敏感性,以及工人在最大旅行距離方面的資源限制.在文獻[19]中,Patel 等人針對聯邦環境下計算資源分配問題,提出了一個旨在使系統總成本最小化的優化問題,并將其定義為訓練時間和能量消耗的加權和.考慮到非線性約束的難度和網絡質量的不穩定,該團隊設計了一種基于DRL的經驗驅動算法,該算法可以在不了解網絡質量的情況下收斂到接近最優解.
1.3 差分隱私
在文獻[11]中,差分隱私的概念被Dwork 首次提出,該文章通過嚴謹的數學證明,可以保證數據變化時用戶隱私不受攻擊者所知的背景知識的影響.之后Dwork 對原有差分隱私的概念進行改進,提出本地化差分隱私[20],將信息的隱私處理工作轉移到用戶端,對差分隱私進行量化,每個用戶單獨對敏感數據進行處理,使得隱私保護更為徹底.Chen 等人[21]將本地差分隱私應用于位置數據保護,通過對位置數據加入拉普拉斯噪聲,實現對位置數據的隱私保護.Wang 等人[22]提出了一種基于差分隱私以及Hilbert曲線的位置保護方法,將位置映射到一維空間中,通過拉普拉斯噪聲對位置信息進行擾動,將處理后的位置信息發送給平臺來實現位置信息保護.
2 問題定義
假設在該系統中有n個攜帶智能移動設備的工人W={w1,w2,…,wn},m個任務V={v1,v2,…,vm}.進而工人的智能移動設備可用Dev={Dev1,Dev2,…,Devn}表示,并定義第i個工人由表示,第j個任務由表示,其中(xi,yi)和(xj,yj)表示坐標,Pwi是第i個工人該時刻所有任務的開銷集合,是該工人當前被分配到的任務隊列,表示第j個任務所需時間,表示該任務的獎勵,表示完成該任務平臺可獲取的收益.該系統是動態的,即工人與任務狀態位置信息不斷改變,在不同時刻下工人完成已有任務后會有“閑置狀態”,此時需要在每次迭代時將“閑置”的工人重新放入在“待分配”工人的隊列里,同時每個工人可接受的任務也是有限的,這需要根據工人的報酬以及任務對于工人的收益進行約束,例如距離較遠的任務的開銷大于收益則不會分配給工人,進而間接限制了工人所接受任務的數量,這就避免了任務分配不均的問題.
工人完成任務是有時效性的,因此在每個工人與任務里加入了時間戳,記錄工人完成任務的時間,并標注出每個任務的完成時間限制.此外,考慮到工人開銷的差異性,即任務對于每個工人的開銷應該是不一樣的,因而加入了笛卡兒坐標系,為每個工人和任務設置了位置坐標,每個工人依據距離和自己未完成的任務量計算任務開銷.例如對于第i個工人,計算第m個任務開銷時,距離越遠,任務開銷越大,自身未完成任務量(加權后的任務數量)越多,任務開銷越大,反之亦然.這里,定義第i個工人對于第j個任務的開銷為:
其中θi表示該工人的完成任務所需總時間,ξ表示第i個工人到第j個任務點的歐氏距離權重,α為時間權重,這里體現出了每個工人的任務開銷的差異性.
可定義第i個工人的收益以及平臺總收益為
其中ri表示第i個工人的收益,Rp表示此時平臺總收益,Vout表示此時所有被分配出去的任務集合.
最終,將這一個基于離散型數據集的動態策略優化問題定義為
其中式(5)代表最大化平臺總收益同時也要最大化當前第i個工人的收益,λ1與λ2為兩者的收益權重,在式(6)中的約束代表第i個工人完成第j個任務時的報酬要保證不小于最小值Pmin,且Pmin是一個大于0 的常量.
從式(3)(4)中可以看出平臺總收益與工人的收益是負相關的,而在本文的問題中,更希望兩者都能達到最大化,因此采用聯合優化方式,通過調節權重值來平衡雙方利益,實現雙方的納什均衡.
由上述的問題定義可證明MCS 的任務分配問題是一個NP-hard 問題.首先假設一個特殊情況,即只有一個工人,任務集合不變.然后,該工人有一個設定的最大旅行距離,且支付給工人的報酬設置為0.最后,平臺的總利潤等于該工人完成任務的報酬,這也映射到定向運動問題,且該問題已被證明為NP-hard問題[23],則可推論本文的問題同樣是NP-hard 問題.
3 系統模型及算法
3.1 系統模型概述
本文的系統模型如圖2 所示,任務發布者在模型中作為中央服務器,每個工人的智能移動設備可看作分布式的小型處理器.在整個系統中,中央服務器與各個工人的移動設備在隱私保護的環境中進行信息交互.首先,每個工人智能移動設備將相關信息經過差分隱私的處理后傳至中央服務器.之后,中央服務器獲取該時刻全局的工人與任務的狀態信息,經過基于DRL 的動態策略優化算法,制定相應的分配策略,最終傳給各工人智能移動設備.同時在交互過程中,中央服務器中采用PPO 的算法進行訓練并決策,在每輪訓練時考慮了系統的動態性與差異性問題,即不同工人對于相同的任務會受到距離以及未完成的任務量影響,進而每個任務對不同工人的開銷應是不一樣的,且在每輪迭代時可能會產生完成了當前任務的“空閑”工人,在模型定義中考慮了以上問題,在每輪迭代會動態更新全局信息,最終得到全局最優的策略.
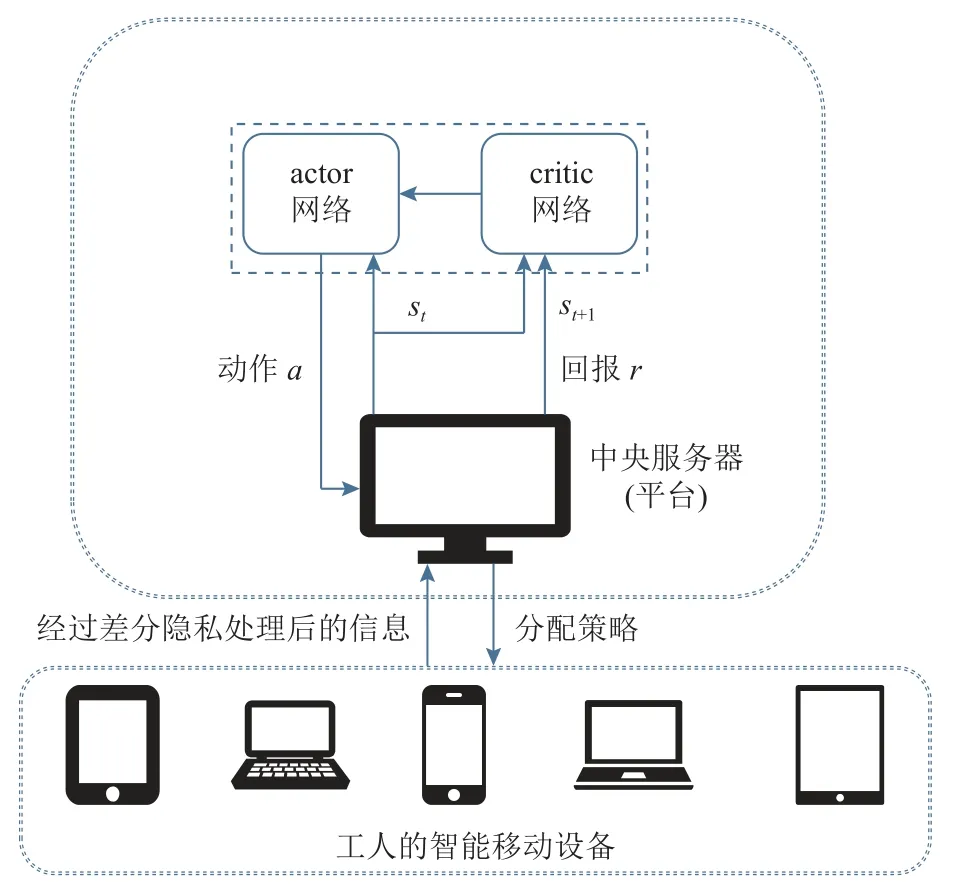
Fig.2 Illustration of the system model圖2 系統模型圖示
3.2 PPO 模型
中央服務器中應用了基于DRL 的動態策略優化算法PPO 進行決策推演.傳統的PPO 算法源于A-C網絡[24]的思想,如圖3 所示,該算法由actor 網絡和critic 網絡構成,每一次迭代時,actor 網絡會根據一定的動作決策概率分布進行動作選擇,并與環境進行交互,獲得該時刻的狀態和相應的回報,此時critic 網絡將根據動作、狀態和回報的集合計算相應的收益函數(有時是TD-error,用于評價actor 網絡的動作),并傳給actor 網絡和環境,actor 網絡基于此調整動作的決策概率分布,并進行下一步動作選擇,最終獲得最優策略.
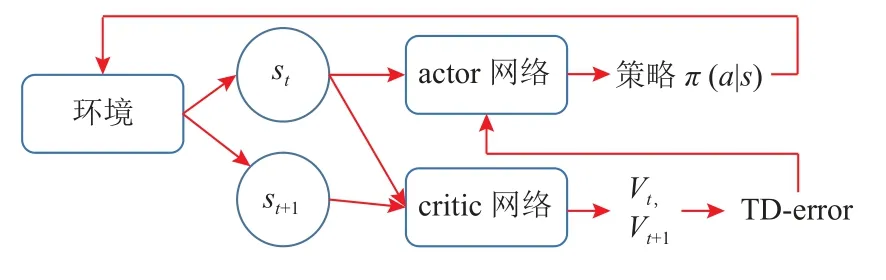
Fig.3 Block diagram of A-C network圖3 A-C 網絡的框架圖
在本文的算法中,將傳統PPO 框架做了調整,即在收益函數的定義上采用了雙約束.動作空間、狀態空間以及回報約束定義為:
1)動作空間.動作集中包含了工人與任務的匹配信息,并采用2 維向量表來表示,其中定義第i個工人在第k次迭代時被分配的任務集合為同時,每個工人設備中將存儲任務分配記錄以及任務完成順序.每次迭代時由中央服務器決策進行分配,中央服務器依據上一輪交互所得到的全局信息(工人和任務數量、工人報酬、任務收益等),計算平臺總收益,并進行匹配.其定義為
2)狀態空間.狀態集合中,記錄了工人與任務的相關信息(工人的任務時序、各任務的收益、雇傭工人的開銷、可用工人數量和剩余任務數量等),這里由第k個狀態可用工人集合Wk與可用任務集合Vk來表示.每次迭代開始,每個工人根據中央服務器傳遞的數據,計算各個任務對于自己的開銷與收益,并于中央服務器進行交互,更新此時的本地信息以及中央服務器的全局信息.綜上所述,將狀態集合定義為
3)回報約束.參照式(5)的聯合約束,力求保證平臺收益最大化的同時,盡可能增加工人的累積收益.將該問題視為平臺與工人間非合作性競爭的納什均衡問題.將平臺總收益的計算定義為平臺整體收益減去所有工人開銷,而單個工人的收益定義為工人獲得報酬減去完成任務的開銷.回報約束中的平臺總收益的優先級高于單個工人優先級,此處根據收益權重進行調整.這里回報約束定義為
其中Wout為已分配任務的工人集合,Wk為未分配的任務集合.
在PPO 模型的訓練過程中,critic 網絡根據回報rk以及動作/狀態集合{a,s}計算其Value值以及優勢函數Ak,進而對于下一次actor 網絡中動作選擇的策略π進行調整,相關定義為:
其中第k輪迭代時的價值函數為Valueπ(sk),γ為折扣率,為狀態轉換概率,Ak為此時的優勢函數,λ為優勢函數權重,最終損失函數可用Loss表示.
3.3 本地差分隱私
這里引入地理不可區分性的概念,即存在2 個位置點x和x′∈X,Z是X通過映射機制D的輸出結果,若D滿足地理不可區分性,則對所有歐幾里得距離d(x,x′) ≤r,其中r為該映射機制保護的范圍,報告位置點z∈Z,則有
式(14)(15)輸入為x和x′ 時,根據該映射機制D的查詢函數D(x)(z),將得到相同輸出z的概率.位置信息中應用差分隱私是為了使真實位置點信息與其近似位置點信息擁有地理不可區分性,從而達到隱私保護的目的.
本文采用本地差分隱私的算法.首先,工人的移動設備定位當前位置信息(xreal,yreal).其次,根據當前位置坐標劃定模糊位置范圍,該范圍是一個以R為模糊半徑的圓形區域.在該范圍內指定ε∈R2,根據機制D確定候選的位置坐標集合,并根據拉普拉斯機制隨機噪聲,敏感度設為Δf,該噪聲服從(0,Δf/ε)的拉普拉斯分布.最后在候選坐標集合中隨機選取模糊化后的位置坐標(x,y),并作為位置信息上傳至平臺.
3.4 基于PPO 的任務分配算法
基于A-C 網絡的思想,利用PPO 模型訓練并學習任務分配策略,該方法與本文的問題非常匹配,并已成功地應用于許多其他領域.在DRL 的眾多策略優化方法中,PPO 在易于實現樣本復雜性和易于調優之間取得了平衡,以最小化目標函數進行計算和更新,同時確保與以前策略的偏差相對較小.因此,在本文算法中的策略優化過程采用了PPO 算法.
在本文的模型里包括了一個歷史策略緩沖區Cache、策略π、actor 網絡與critic 網絡,在算法1 中展示了該模型算法的偽代碼.首先,初始化PPO 框架,隨機賦予actor 網絡與critic 網絡的相關參數相應的初始值θa和θv,將θa作為初始的策略參數(行①).隨后迭代開始,最大迭代次數為K(行②).在環境中獲取當前的可用工人集合Wk以及可用任務集合Vk的信息,其中工人的位置信息根據本地差分隱私已做模糊化處理,最終得到第k次迭代的狀態(行③~⑧).然后,基于狀態sk根據當前策略在actor 網絡中進行動作選擇(行⑨),將此時的動作集合ak輸入到環境中計算相應的回報rk以及下一輪的狀態集合sk+1(行⑩).critic 網絡中計算Ak以及Valuek,并將集合{sk+1,sk,ak,rk,Ak,Valuek}存儲到歷史策略緩沖區Cache中(行?~?).當Cache裝滿時計算偏導數,并基于根據梯度上升策略更新策略參數θa(行?~?).在從Cache中學習信息后,actor 網絡的新參數θa分配給策略進行下一次采樣.同時,歷史策略緩沖區被清空(行?).
算法1.基于PPO 的動態策略優化算法.
4 實驗
4.1 實驗參數設置
本文選用Gowalla 和TaskMe 這2 個數據集進行模擬實驗,從中提取部分數據的位置以及時間信息,并將添加在一定范圍內隨機生成的數據作為任務獎勵等其他信息,最終生成擁有2 000 個任務和1 000個工人的模擬數據集合.其中,每個任務的獎勵設置在8~20 的范圍內并按照N~(12,4)的正態分布進行隨機生成,任務的時間則設置在10~60 的范圍內隨機生成.最后,根據實驗的不同要求,選用該數據集中部分任務以及工人的數據信息在一個200×200 的正方形傳感區域空間內進行模擬實驗.
首先,設置了不同的工人與任務數量下損失函數的對比實驗,目的是驗證工人與任務數量對損失函數的收斂性的影響.在一個200×200 的正方形傳感區域空間內,分別測試了80 個任務和5 個工人、300個任務和15 個工人、800 個任務和30 個工人這3 種不同情境下的損失函數.其次,與現有的傳統方法(貪婪算法、螞蟻算法)以及其他DRL 方法(DDQN)針對收斂速度、最大收益以及任務覆蓋率的對比實驗.該部分將螞蟻算法中螞蟻數、迭代次數和隨機選擇的概率分別設置為10,30 000,0.1,對于基于DDQN的算法將其重播內存容量設為10 000 次,迭代次數設為30 000 次,隨機選擇的概率從0.9 開始,然后逐漸衰減到0.1.最后,通過消融實驗來驗證隱私保護的有效性.在該實驗中將本文算法與DDQN 的算法以及去除掉差分隱私時的算法進行比較,實驗設置參數與對比實驗相同.
4.2 模型損失
本節進行了不同工人數量以及任務數量的模擬實驗,圖4(a)中迭代次數在100 次以內,大約在第70次時達到收斂;圖4(b)中模型在迭代次數約120 次時達到收斂;圖4(c)中在迭代280 次時達到收斂.可以看出,該算法收斂效果主要受到工人與任務的數量影響,隨著其數量的增多,收斂速度將變慢.
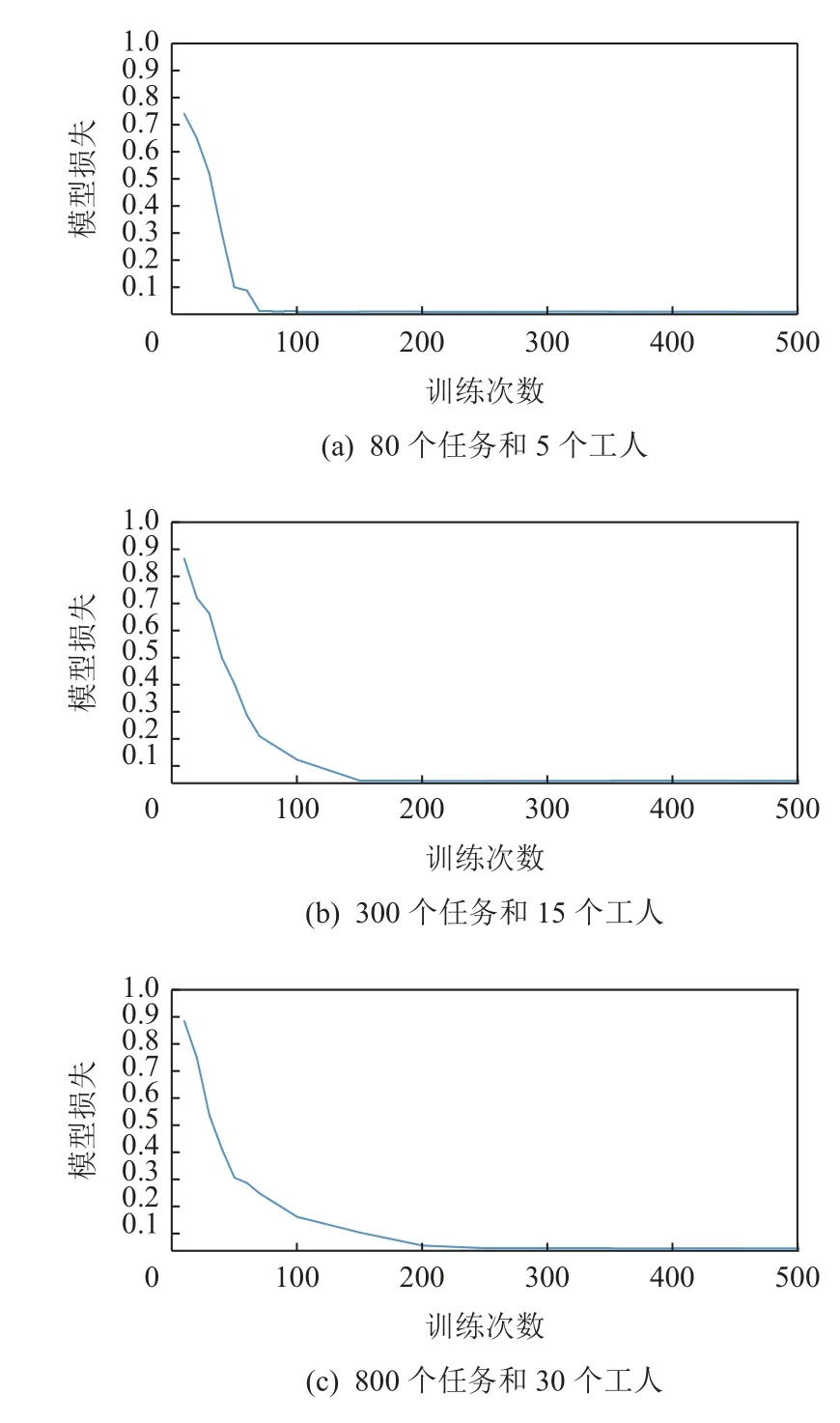
Fig.4 System loss for different numbers of tasks and workers圖4 任務與工人不同數量下的系統損失
4.3 對比實驗
本節實驗不僅針對傳統MCS 任務分配方法(即螞蟻算法和貪婪算法的對比),而且加入了同為基于DRL 的任務分配算法(即基于DDQN 的算法),在任務覆蓋率、性能、收斂性以及最大收益上做了相應對比實驗.在圖5 中,可以看到基于DDQN 以及基于PPO 的2 種DRL 算法在系統平均開銷的收斂情況,結果表示基于DDQN 的算法雖然可以比本文算法能更快收斂,但本文算法可以達到更小的平均系統開銷.圖6 展示了4 種算法的平臺收益情況,貪婪算法和蟻群算法由于是靜態的算法,因而不需要多輪迭代,但其平臺收益與基于DRL 的算法相比差距甚遠;而基于DDQN 的算法同樣有更快的收斂性,但本文的基于PPO 的算法可以最終達到最大收益.
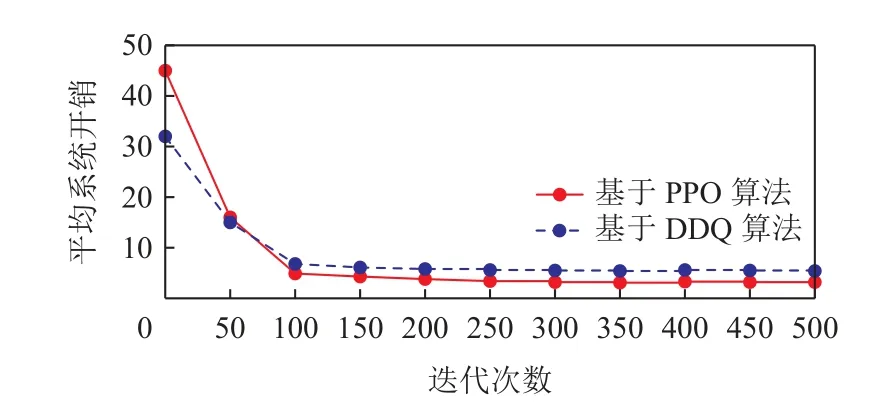
Fig.5 Comparison of average system costs圖5 平均系統開銷的比較
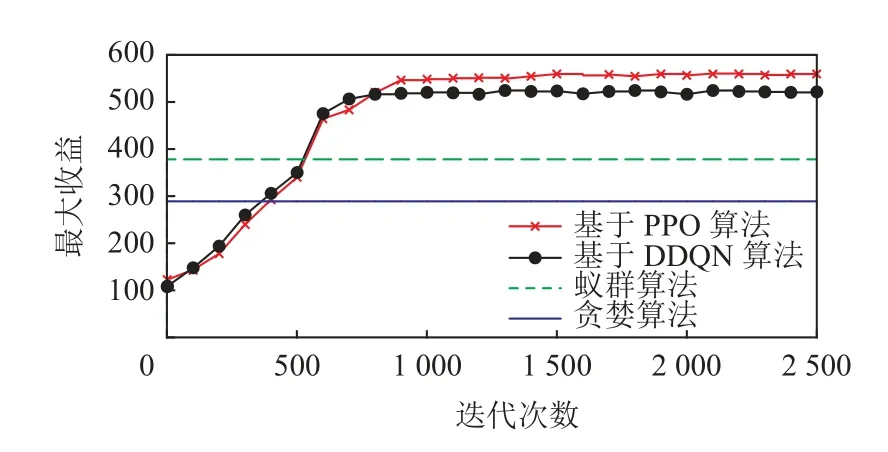
Fig.6 Comparison of maximum profits圖6 最大收益的比較
首先引入任務覆蓋率的概念:當一個任務在其可接受的時間范圍內被分配出去且完成,則可稱為該任務被覆蓋.因此任務覆蓋率可被定義為被分配掉的任務數與總任務數的比值.如表1 所示,在平臺最大利潤和任務覆蓋率上,基于DDQN 和PPO 的2種DRL 算法均遠高于貪婪算法和蟻群算法等傳統方法,且基于PPO 算法比基于DDQN 的算法表現更為優異.圖7~9 展示了4 種算法在平均開銷、總開銷以及工人平均收益上的對比,結果表明本文的基于PPO 算法均優于其他算法,而貪婪算法表現最差.

Table 1 Comparison of Maximum Profit and Coverage Ratio表1 最大利潤與覆蓋率的對比
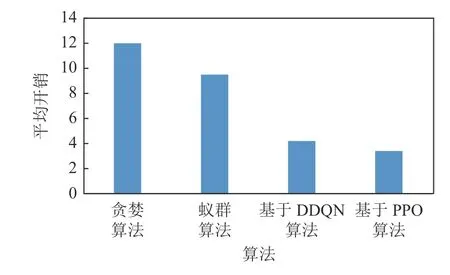
Fig.7 Comparison of average costs圖7 平均開銷的對比
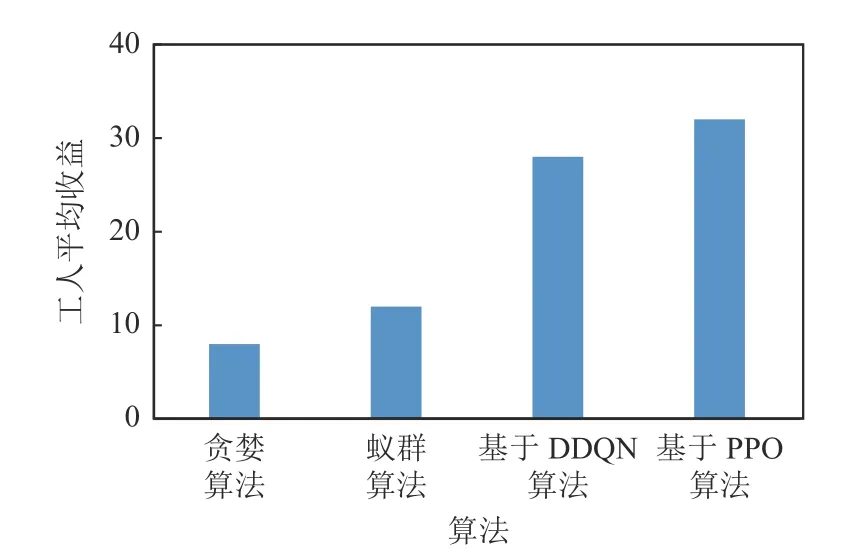
Fig.9 Comparison of average revenue of workers圖9 工人平均收益的對比
4.4 消融實驗
如圖10 所示,本文針對差分隱私的有效性做了消融實驗,實驗中對比了有差分隱私的性能以及沒有差分隱私的性能,并與基于DDQN 的算法模型進行對比.實驗結果表明,去除差分隱私性能會有更好的效果,是因為模糊化的位置信息影響了模型的計算性能,但加入差分隱私的方法可以在不損失過多性能的前提下保護工人信息的隱私.此外,為了驗證該算法的性能隨差分隱私保護程度的變化,消融實驗中加入了不同的隱私保護機制覆蓋范圍下的算法性能的對比實驗,如圖11 所示,其中r表示本文3.3節所提到的差分隱私機制的保護范圍,當保護范圍越大時,則需保證該范圍的地理不可區分性,故保護程度越高.由此可見,隨著保護范圍的增加算法性能所受影響較大,需選擇合適的保護強度,實現在保護隱私的前提下保證算法性能.
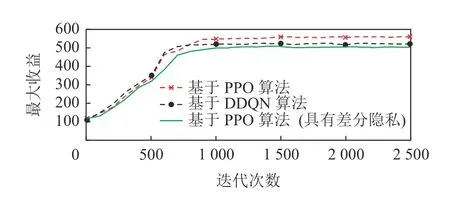
Fig.10 Ablation experiment圖10 消融實驗
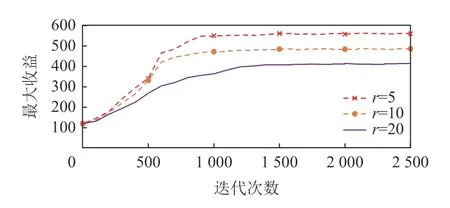
Fig.11 Comparison under different protection levels圖11 不同保護程度下的對比
5 結論與展望
在本文中,針對MCS 的感知任務分配問題,在工人與任務的位置、狀態信息不斷改變的動態系統中,考慮了任務分配機制的合理性與工人信息的隱私保護等問題,將其定義為一個基于離散型數據集來進行動態規劃的優化問題,并利用差分隱私和深度強化學習的相關算法及模型去解決該問題.將PPO 模型作為決策模型訓練和學習,在每次迭代中,考慮當前狀態下的每個工人開銷的差異性以及完成任務的時序性等因素,利用聯合約束,在保證平臺收益最大化的同時,盡可能增加工人的累積收益,在這樣的動態系統中不斷優化分配策略.此外,還在工人的移動設備與中央服務器的交互中加入了差分隱私的方法來保證工人的隱私.實驗結果也證明了本文方法的有效性.
在未來的工作中,將探索更多隱私保護的策略,并且在保證隱私的同時進一步提升模型的性能.此外,也考慮在該模型中加入數據預測的機制,在收集處理感知數據的同時,基于歷史經驗數據進行某一范圍內的數據預測,提升模型整體效率.
作者貢獻聲明:楊明川負責實驗及相關研究工作,并完成論文撰寫;朱敬華提出算法思路,設計論文整體框架;李元婧負責數據分析并協助撰寫論文;奚赫然提出修改意見并修改論文.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
時代英語·高三(2014年5期)2014-08-26 02:49:51
