基于雙通道混合神經網絡的房顫風險預測模型
2023-11-18 03:33:06柯博文陳艷紅
計算機工程 2023年11期
柯博文,楊 湘,陳艷紅
(1.武漢科技大學 計算機科學與技術學院,武漢 430065;2.國家新聞出版署富媒體數字出版內容組織與知識服務重點實驗室,北京 100038;3.武漢亞洲心臟病醫院 心血管內科,武漢 430022)
0 概述
心房顫動是心血管疾病中常見的慢性心律失常[1],隨著年齡增長,患病率逐漸上升。房顫具有隱秘性,患者在病發前不會出現任何明顯的身體異常,但病發時容易致命[2]。因此,針對心房顫動的早期篩查和風險預測工作是非常有必要的。
心電圖(Electrocardiogram,ECG)是一種常用的心房顫動診斷手段,但具有普適性的電子健康病歷(Electronic Health Records,EHR)更適合用于心房顫動的早期篩查工作[3]。EHR 直接反應了患者一段時間內的身體健康狀況,其中涵蓋了患者一段時間內做過的診斷、檢查檢驗、用藥等信息。不同于心電圖,EHR 來源于患者的日常治療過程,是一種較易獲取的數據。
受益于近些年來深度學習的發展,卷積神經網絡(Convolution Neural Network,CNN)[4-5]和循環神經網絡(Recurrent Neural Network,RNN)[6-7]被廣泛應用于疾病風險預測任務。CNN 是一個能夠提取數據中的局部特征,并不斷匯聚以反映數據整體特征的深度神經網絡,在圖像處理[8]、語音識別[9]等領域表現理想。EHR 涵蓋了非常多的醫療事件,醫療事件之間的多依賴關系使得數據的全局特征更為重要,而CNN 無法完全提取到數據的全局特征。
除了EHR 的數據特性以外,在實際臨床診斷過程中,房顫的發生也受到其他醫學指標的影響。臨床醫學[10]與早期的分析方法[11]已經證實,高血壓、甲狀腺功能異常等指標會直接導致房顫發生,因此重點關注這些特定指標是非常有必要的。
為了克服上述挑戰,本文提出因素風險-注意神經網絡(Factor Risk-Attention Neural Network,FRANN),FR-ANN 的一個通道通過引入注意力機制來提取數據的全局特征,另一個通道對一些重要的醫療事件獨立進行特征提取,解決CNN 無法有效提取到數據全局特征的問題。根據患者近幾次就診記錄,預測患者半年內是否有患病風險,并采用專用通道提取單個醫療事件的變化特征,捕捉醫療事件對結果的直接影響。在MIT 的公共數據集MIMIC-Ⅲ[12]和武漢亞洲心臟病醫院提供的私有數據集上驗證FR-ANN 在房顫風險預測工作中的有效性。
1 相關研究
在現代醫學領域,基于EHR 的房顫早期篩查技術對于降低疾病致死率具有重要意義,它能夠幫助醫生預防疾病的發生。EHR 數據包含大量的醫療事件,主要由醫療診斷和檢查檢驗構成。特征提取是疾病預測工作中最重要的一步,它將經過特征工程的數據輸入到模型中,模型通過手動或自動的方式提取特征,最后預測結果。
在早期的疾病預測任務研究中,許多研究人員通過邏輯回歸、決策樹、隨機森林、貝葉斯網絡等機器學習算法從EHR 中提取與患者相關的特征[13]。機器學習算法能夠結合臨床醫學知識,幫助研究人員重建疾病的潛在機制,構建符合任務特點的框架。但這些方法建立在手動特征提取的模式之上,需要加入大量的醫學專業知識以及專家輔助完成特征提取工作,這將會限制實際應用的適用性。
隨著計算機性能逐漸提升,更多的研究偏向于使用深度學習方法對EHR 數據進行建模。在醫學領域,深度學習的自動特征提取模式使其使用范圍非常廣泛,它不需要手動加入醫學專業知識。CNN是疾病風險預測任務中最常用的深度神經網絡結構之一[14],能夠提取到EHR 中的局部特征,通過增加模型深度的方式建立醫療事件之間的聯系,其池化層能夠對特征進行壓縮與下采樣,以擴大感知視野。LANDI 等[15]使用CNN 提取醫療事件的時間特征,并預測最終結果。文獻[16]使用基于CNN 的方法預測心力衰竭的患病風險。CNN 擅于捕獲數據的局部特征,然而EHR 的全局特征使CNN 方法的分類效果與醫療事件序列的排列規則具有緊密聯系。值得注意的是,FRDLS 通過多種分析方法計算每個醫療事件的得分,根據得分從高到低重新排列醫療事件序列。通過不同的分析方法得到多種排列規則,并對多種排列規則的數據同時進行建模,分析排列規則對結果的影響,提供幾種性能較優的排列方式。
RNN[17-19]同樣適用于疾病風險預測任務。RNN善于通過鏈式的方式將多個醫療事件聯系起來,使前后醫療事件之間的時間關系顯而易見。文獻[20]將時間1 到t的醫療代碼序列輸入Bi-LSTM 模型中,從而預測第t+1 次的醫療代碼。雙向LSTM 很好地保留了前t次醫療代碼之間的時序關系,以此推斷出第t+1 次的結果。XU 等[21]將醫療 事件按 時間排 序輸入到LSTM 中,提取醫療事件之間的時間特征。RNN 對于數據的時序關系是非常敏感的,但是將EHR 數據鏈式排列時,并不能直接斷定前后兩個醫療事件存在潛在多依賴關系。雖然LSTM 加入了“門”機制,但是每個單元的計算過程依然依賴于上一個單元,這可能會加入原本不存在的潛在關系。
近年來,隨著自然語言處理的發展,注意力(Attention)機制[22]開始被普及。注意力機制并行計算的特點降低了其性能消耗。在注意力機制的特征提取過程中,每個醫療事件的特征提取過程相對獨立,但在提取過程中醫療事件之間又相互依賴,清晰的界限能夠很好地解決數據存在多依賴關系帶來的全局特征問題。文獻[23]引入Attention 機制提取每個醫療事件對結果的貢獻,然后通過一個3 層的多層感知機(Multilayer Perceptron,MLP)得到預測結果。在MLP 之前加入注意力機制,相當于先進行一次特征提取,能夠降低模型的資源消耗,提高計算效率。文獻[24]基于LSTM 結構在醫療事件和就診記錄兩個級別分別加入注意力機制預測哮喘疾病的風險。TSANN 加入的兩層注意力機制能夠分析單次就診與單個事件在各自維度內的權重,并提供就診和醫療事件兩個維度的事后可解釋性。文獻[25]通過構造多尺度的注意力機制的方式對單次就診進行建模,然后將多尺度信息匯集,減少序列長度。多尺度注意力機制可以理解為多個局部注意力機制,這種方式可以定制化地獲取數據不同尺度的特征,貼合任務特性。
目前絕大多數的研究都是基于深度學習進行的,這得益于自動特征提取模式。對于疾病風險預測任務來說,深度學習有很多方法可以使用,但選擇符合數據與疾病特性的方法才是解決問題的關鍵。總的來說,CNN 適用于提取數據的局部關系,以局部特征反映全局特征;RNN 的結構優勢使得它善于提取數據的時序性特征;注意力機制使用較少的參數提取數據的全局特征,并挖掘數據之間的潛在依賴關系。
以上方法均在考慮如何解決數據特性,除此之外,疾病帶來的特性同樣重要。年齡較大是最有可能直接導致房顫發生的因素之一,但更深層次的原因是患有多種其他疾病導致心房顫動發生的概率上升,心房顫動的并發性需要引起重視。現有的臨床醫學知識已經可以篩選出一部分與心房顫動相關性較高的醫療事件,例如高血壓、甲狀腺功能等,獨立捕獲這些醫療事件對心房顫動的預測非常必要。
2 心房顫動風險預測模型
心房顫動的疾病風險預測工作可以看作是一個二分類任務,即是否患有心房顫動。本文將患有房顫的樣本分為陽性樣本(正樣本),未患有房顫的樣本分為陰性樣本(負樣本)。本節將描述FR-ANN 的模型結構,并介紹FR-ANN 中的每個模塊。
2.1 數據表示
本文數據集以病人為單位,用X代表每個病人。每個病人的EHR 數據可構成一個二維矩陣,如式(1)所示:
其中:ci表示病人的第i次就診記錄,每次就診記錄中包含多個醫療事件,即ci=[si,1,si,2,…,si,m],si,m表示病人的第i次就診記錄中的第m個醫療事件。
本文模型將從時間序列特征分析通道和單指標特征分析通道兩個不同的通道進行分析,它們的輸入由原始EHR 矩陣切割得到。圖1 所示為數據切割的過程。EHR 矩陣縱向切割得到多個醫療事件向量,即Sj代表由第j個醫療事件在多次就診記錄中的表現構成的向量,本文根據醫學專業知識從m個醫療事件中篩選出100 多個對房顫影響較大的醫療事件(表1 給出了部分篩選出的醫療事件),將這些篩選后的醫療事件作為最終得到的Sj=[s1,j,s2,j,…,sn,j],j?[1,m]醫療事 件向量序列MR=[S1,S2,…,Sm]。由EHR 矩陣橫向切割將得到多個就診記錄向量,即ci=[si,1,si,2,…,si,m],i?[1,n],ci代表第i次就診記錄,多個就診記錄向量構成最終的就診記錄向量序列VR=[c1,c2,…,cn]。數據切割過程只是把病人的EHR 矩陣轉換成了兩種形式,它們依然是同源的數據。

表1 部分篩選出的醫療事件(用于單指標特征分析通道)Table 1 Selected medical events(for single indicator characteristic analysis channel)

圖1 數據切割過程Fig.1 Process of data cutting
2.2 模型結構
圖2 所示為FR-ANN 的模型結構。
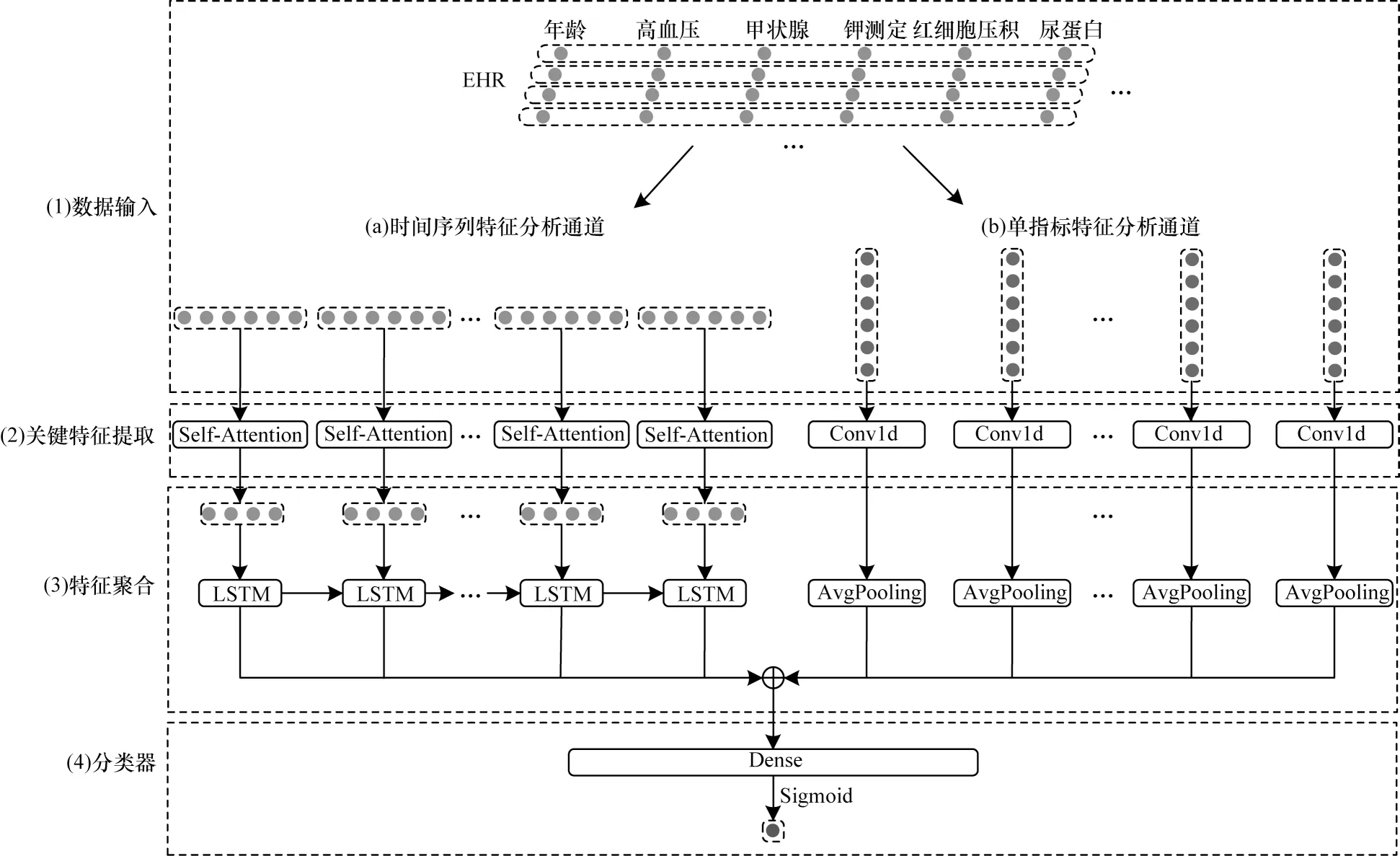
圖2 FR-ANN 模型結構Fig.2 Structure of FR-ANN model
由圖2 可知,FR-ANN 模型將就診記錄向量序列VR輸入到時間序列特征分析通道,將醫療事件向量序列MR輸入到單指標特征分析通道。
單指標特征分析通道會對醫療事件向量序列MR中的每個醫療事件向量獨立分析,以提取每個醫療事件在多次就診中不同表現的綜合特征,并匯總得到所有醫療事件的綜合變化特征coutput;時間序列特征分析通道會先對VR中的每條就診記錄向量單獨進行特征提取與注意力分析,并將多條就診記錄向量的特征匯總輸入到一個LSTM 中,根據前幾次的就診記錄得到下一次的預測狀態信息hn。分類器模塊把2 個通道的輸出拼接,通過多個全連接層與一個Sigmoid 分類器得到最終預測結果。具體的計算過程如下:
其中:W1?Rr×(4+4m)、W2?Rs×r、b1?Rr×1、b2?Rs×1是全連接層的參數矩陣;yD是全連接層的計算結果;y是yD通過Sigmoid 函數得到的最終預測結果。
數據樣本比例不平衡是醫療數據的通病,本文使用的數據同樣存在此類問題。為了與醫學臨床過程保持一致,本文在模型方法上做出一些優化,而不是直接增加正樣本的占比。在損失函數的選擇上,本文使用了Focal Loss[26]代替常用的二值交叉熵損失函數作為FR-ANN 的損失函數。這是因為Focal Loss 的出現就是為了解決訓練集正負樣本極度不平衡的問題。損失函數的計算過程如下:
其中:y為標簽值為模型預測值;α和γ是超參數,α用于調和正負樣本比例,γ負責緩解易分類樣本(負樣本)的影響。實驗過程中使用的超參數均設置為Focal Loss 推薦的值,即α=0.25、γ=2。
2.3 時間序列特征分析通道
EHR 數據中的潛在關系可分為兩種形式:單個就診記錄形成的時間片內和多個就診記錄之間。在單個時間片內,各個醫療事件的指標綜合反映了患者一段時間內的身體狀況;在多個就診記錄之間,每個就診記錄根據時間順序排列。分級提取兩種潛在特征是有必要的。首先,本文基于注意力機制提取每個時間片內醫療事件之間的多依賴潛在特征,然后再使用LSTM 提取多個就診記錄之間的時序特征,最后將提取到的特征輸入到分類器中。
2.3.1 基于注意力機制的片內特征提取
在時間序列特征分析通道中,本文拿到患者單次就診 記錄向 量ci=[si,1,si,2,…,si,m],i?[1,n]。CNN在特征提取工作中,由于卷積核大小的限制,一般通過增加模型深度的方法達到提取與距離較遠的單元之間的潛在關系的目的。而注意力機制由于并行計算的優勢,可以獨立考慮醫療事件與其他事件之間的潛在關系,不會受到距離與其他因素的影響。并且注意力機制計算得到的注意力分布體現了單個醫療事件在整體上的權重,增強了模型的可解釋性。所以本文在FR-ANN 中引入注意力機制,代替時間序列特征分析通道中的常規卷積方法。
對于每一個就診記錄ci,本文都將接入一個獨立的注意力層。注意力機制的計算過程可以簡寫為:
其中:ci表示病人第i次就診記錄;ai表示ci計算得到的注意力權重是可訓練參數矩陣;Dk表示ci的維度m,即醫療事件的個數。
2.3.2 基于LSTM 的時序特征提取
AATTs=[a1,a2,…,an]是多個自注意力層的輸出構成的注意力權重序列,at對應患者的第t次就診記錄。多次就診記錄之間存在的時序關系反映了患者在一段時間內的身體變化趨勢。LSTM 既能夠捕捉多次就診記錄之間的時序關系,又可以保留每個就診記錄內的潛在關系。所以本文把LSTM 放在自注意力層之后,用于提取多個就診之間的時序特征。
整個LSTM 模塊由一層LSTM 構成,具有n個隱藏層單元。LSTM 模塊的結構圖如圖3 所示。對于LSTM 的每個單元而言,它的輸入由一個自注意力層的輸出at得到,AATTs通過LSTM 層得到多個隱藏層狀態h1,h2,…,hn,本文取最后一個狀態hn作為LSTM 層的輸出。LSTM 每個單元中的計算過程如下:
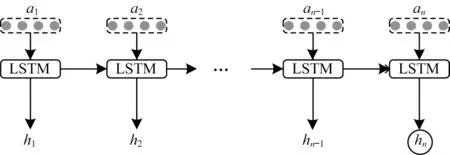
圖3 LSTM 模塊的結構Fig.3 Structure of LSTM module
其中:第t次的輸入at和第t-1 次的隱藏狀態ht-1的拼接得到[ht-1,at],構成每個單元的輸入;在保留隱藏狀態過程中,主要起作用的是記憶門和輸出門ot;?表示逐元素相乘。
2.4 單指標特征分析通道
醫學臨床知識能夠篩選出與心房顫動相關性較大的醫療事件,本文專門在單指標特征分析通道上獨立提取每個篩選得到的醫療事件在多個時間片之間的變化趨勢,加強對結果的預測能力。本文通過CNN 提取單個醫療事件在多次就診中的變化特征,將多個醫療事件的變化特征拼接得到的綜合變化特征coutput輸入到分類器中,由分類器拼接特征并預測結果。
房顫是一種慢性疾病,它與許多疾病關系密切。現代臨床醫學已經證實,高血壓、心動過速等癥狀會直接導致房顫的發生。第2.1 節已經篩選出部分相關性較大的醫療事件作為此通道的輸入。因為患者的就診次數在4 次左右,所以CNN 的卷積核可以輕松地幫助本文模型捕捉到單個醫療事件在較低跨度上的變化特征。由于房顫的治療過程較為漫長,因此更早的記錄產生的影響會逐漸減弱。所以本文把卷積核的大小設置為1×2,以關注單個醫療事件前后兩次就診之間的變化趨勢。
在得到單個醫療事件的變化曲線之后,本文還需要對特征進行收斂。平均池化層(Average Pooling Layer)和最大 池化層(Maximum Pooling Layer)是兩種常用的池化手段,前者保留信息的平均值,后者保留信息的最大值。對于單個醫療事件的變化特征而言,平均值能夠權衡醫療事件在每一次就診時的表現,而最大值只記錄了極端情況。結合實際情況,平均池化層更適用于收斂單個醫療事件的變化特征。
單指標特征分析通道的模塊結構如圖4 所示。對于每個醫療事件向量Sj,都將經過3 個卷積層和1 個平均池化層,卷積層的通道數均為16,卷積核大小均為2×1,平均池化層的卷積核均為16×1。計算過程如下:
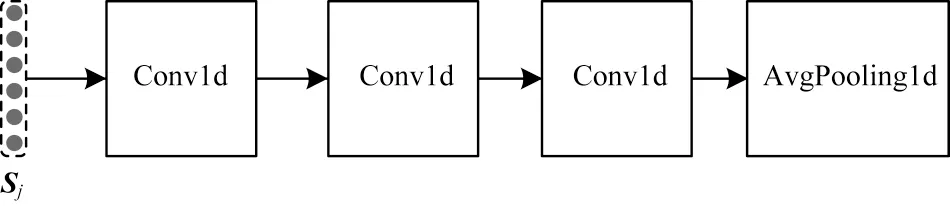
圖4 單指標特征分析通道的模塊結構Fig.4 Module structure of single index feature analysis channel
對于每個醫療事件ei都有輸出Aj,將所有的輸出拼接得到序列coutput=[A1,A2,…,Am]。
3 實驗結果與分析
3.1 研究的數據
本研究使用的數據來源于武漢亞洲心臟病醫院房顫中心的私有數據庫和MIT 的公開數據庫MIMIC-Ⅲ。私有數據集經過武漢亞洲心臟病醫院倫理委員會批準,所有數據都經過去標識化處理,即去除了所有可能跟患者個人隱私相關的信息。
本文從數據庫中收集病人的診斷數據、檢查檢驗數據和人口學數據,將其組合得到患者的電子病歷信息。對于各種醫療事件,來自亞心的私有數據庫保留頻率不小于1 000 次的事件,最終篩選出480 種診斷、檢查檢驗等項目;而MIMIC-Ⅲ數據庫保留了頻率不小于5 000 次的事件,最終篩選出241 種診斷、檢查檢驗等項目。本文統計了所有病人的就診次數,最終確定將患者的前4 次就診記錄作為實驗用數據,以預測患者半年內是否會發生房顫。
3.2 實驗環境
本文涉及的所有代碼均基于Python3.8.3 完成。機器學習模型通過sklearn 實現,深度學習模型基于Keras2.4.3 實現。在深度學習模型中,自動學習的參數使用Adam 優化器自動更新,初始學習率為0.001,訓練20 個輪次。所有模型均采用批量大小為1 024的小批量訓練方式。深度學習模型使用Dropout 和L1、L2 正則化防止過擬合問題。在訓練開始前將數據集隨機打亂,再以6∶2∶2 的比例區分訓練集、驗證集和測試集。在每個輪次過程中,模型利用訓練集來訓練模型,使用驗證集驗證模型訓練后的結果并自動調整可訓練參數。在所有輪次訓練完成后,使用測試集測試模型的最終性能,并計算評價指標。
3.3 評價指標
在疾病預測任務中,如何評判模型的性能非常重要。在實驗過程中,本文使用了4 種評價指標:精確率(P)、召回率(R)、F1 值(F1)以及AUC 曲線。計算式如下:
其中:精確率指的是預測為患病的結果中實際患病的占比;召回率指的是對于實際患病的樣本中,預測正確(預測為患病)的比例;精確率體現了模型對樣本整體預測的準確性;召回率體現了對患病群體判斷的準確性;F1 值兼顧了精確率和召回率,是一種綜合性能指標;AUC 代表模型區分陽性樣本和陰性樣本的能力,數值越高,表示模型的分辨能力越強。
3.4 基線模型
為了驗證模型性能,本文選取了幾種機器學習算法以及基于EHR 數據并應用在疾病風險預測任務上的深度學習模型,和本文提出的FR-ANN 模型進行比較。本文所選用的機器學習算法包括邏輯回歸(Logistic Regression,LR)和隨機森林(Random Forest,RF)。深度學習模型分別是基于MLP 與注意力機制 的MLP_Attention[23]、基 于CNN 的FRDLS[16]和基于LSTM 與注意力機制的TSANN[24]。
3.5 實驗結果
實驗分別在來自武漢亞洲心臟病醫院的私有數據庫(簡稱亞心數據庫)和MIT 的公開數據庫MIMIC-Ⅲ中進行。基線模型與FR-ANN 模型的性能評分如表2、表3 所示。
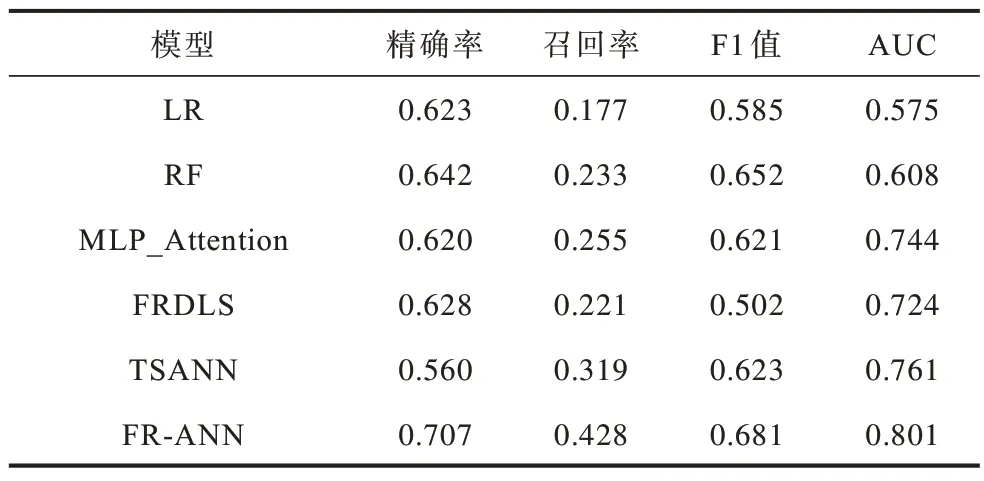
表2 對比模型評分表(亞心數據庫)Table 2 Scoring table of comparison model(Yaxin database)
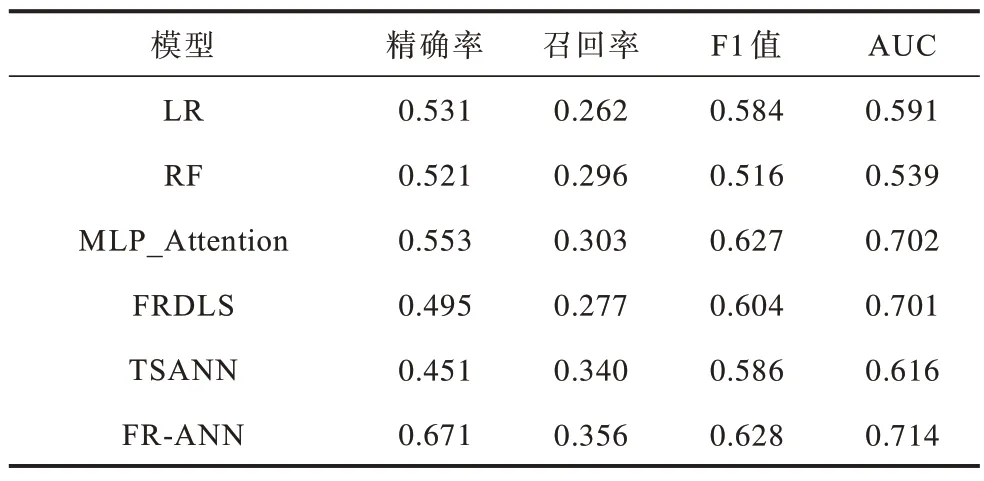
表3 對比模型評分表(MIMIC-Ⅲ數據庫)Table 3 Scoring table of comparison model(MIMIC-Ⅲ database)
在基于私有數據集的實驗中,MLP_Attention 和FRDLS 的AUC 分別為0.744 和0.724。多層感知機是一種全連接的神經網絡,雖然MLP 增加了參數數量,但它的性能優于FRDLS 模型,而TSANN 模型的召回率要優于前兩者,這歸功于注意力機制準確地注意到了醫療事件之間的多依賴關系,捕捉到了數據中的潛在知識。FR-ANN 模型的時間序列特征分析通道完成了醫療事件之間的多依賴關系與就診記錄之間時序關系的特征提取工作;單指標特征分析通道通過提取每個醫療事件的變化特征,增加FR-ANN 模型對重要醫療事件的關注度,兩者結合使得FR-ANN模型的各項指標均優于幾種基線模型。
3.6 消融實驗
首先,本文在消融實驗中以僅使用時間序列特征分析通道和僅使用單指標特征分析通道兩種模式預測患者的心房顫動風險,并與FR-ANN 模型進行比較,以分析單個通道對FR-ANN 模型的貢獻。其次,本文還將FR-ANN 模型的時間序列特征分析通道中的注意力層替換成卷積層,分析兩種不同模塊給FR-ANN 模型帶來的影響。消融實驗均在亞心數據庫上進行。
圖5 為消融實驗評分圖。圖5(a)展示了兩種模式以及FR-ANN 的性能評分。僅使用單個通道時,各項性能指標讀數有所下降,兩個通道的差異主要體現在精確率和召回率上。時間序列特征分析通道的召回率有所提升,這歸功于注意力機制能在全局范圍內提取醫療事件之間的潛在關系。單指標特征分析通道的精確率較高,這是因為此通道的輸入均是經過醫學專業知識鑒定的、與房顫疾病相關性較大的醫療事件,使得單指標特征分析通道能夠直接聚焦于疾病相關性較大的醫療事件,排除了其他醫療事件的干擾。
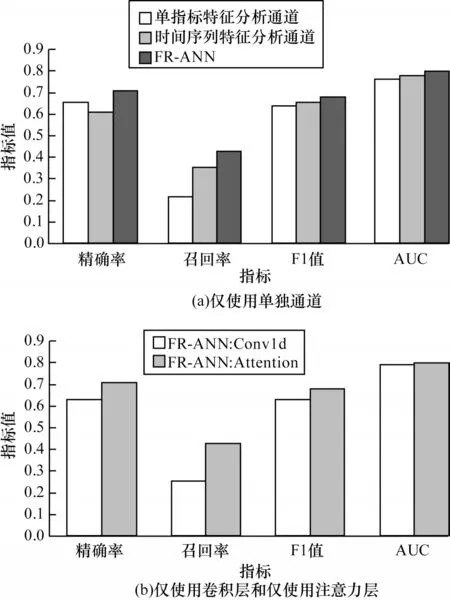
圖5 消融實驗評分圖Fig.5 Rating chart of ablation experiment
從性能與功能上看,FR-ANN 模型中的兩個通道各自承擔了不同的職責。時間序列特征分析通道采用多層級的特征提取方法,在醫療事件層級提取醫療事件之間的多依賴關系,在就診記錄層級提取就診記錄之間的時序特征。單指標特征分析通道針對每個輸入的醫療事件獨立分析,并且輸入的醫療事件由醫學臨床知識篩選得到,能夠加強模型的可解釋性。
圖5(b)展示了FR-ANN 模型的時間序列特征分析通道中,使用CNN 或者使用注意力機制兩種情況下的性能差異。由實驗結果可看出,引入注意力機制主要提升了召回率。相較于CNN,注意力機制的優勢在于全局性,這使得它能夠兼顧所有醫療事件之間的潛在關系。實驗結果表明,使用注意力機制的FR-ANN:Attention 的各項指標均優于FR-ANN:Conv1d。
3.7 結果分析
在臨床治療過程中,醫生往往需要結合多項指標綜合分析才能給出治療方案。常見的診斷依據包含高血壓、冠心病等與心臟、血液相關的疾病,也包括鉀測定、血糖、血清總蛋白等檢查檢驗指標。而FR-ANN 模型在訓練過程中會自動學習這些模式,本文引入的注意力機制通過分析醫療事件之間的潛在依賴關系,得到每個醫療事件在整個集合中的注意力權重,權重越高表示它越可能導致房顫發生。圖6 所示為在亞心數據庫中FR-ANN 的注意力層輸出的注意力分布結果。
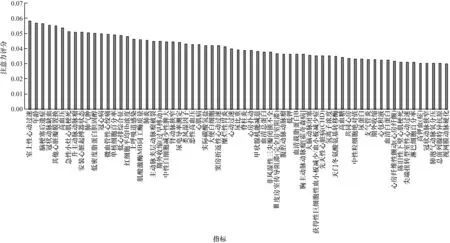
圖6 FR-ANN 自注意力層輸出的注意力分布Fig.6 Attention distribution outputing by FR-ANN self attention level
在注意力評分超過0.03 的醫療事件中,多數指標是與心血管疾病相關的,例如心包積液、心房撲動、冠心病、高血壓、膽固醇等指標,這些指標均預示著人體健康狀況異常,提高心房顫動發生的概率。
由圖6 可知,心房顫動與其他心血管類疾病具有非常大的關聯性,同時也受到高血糖、高血壓等其他疾病的影響。并且當蛋白膽固醇、血清蛋白等常規檢查檢驗指標異常時,也需要結合其他指標綜合考慮心房顫動的風險。注意力分布得到的信息與臨床診斷結果較為接近,注意力機制不僅注意到了高血壓、高血糖等相關性較大的醫療事件,而且能發現一些常規檢查檢驗指標對房顫的影響,例如紅細胞濃度、鉀測定、血清蛋白等。
圖6 的注意力分布的結果表明,以上對注意力權重的分析結論與臨床醫學知識相吻合,能夠為臨床診斷提供建議。
4 結束語
基于EHR 的心房顫動風險預測有助于更早地預防心房顫動。本文提出一種新的基于深度學習的模型FR-ANN,模型結構充分考慮了目前EHR 存在的問題以及心房顫動的隱蔽性等疾病特性。實驗結果表明:FR-ANN 模型對多項醫療事件的篩選工作提升了模型的召回率;注意力機制的引入能夠代替卷積層完成特征提取工作,提升了模型的計算性能,注意力機制的事后可解釋性為臨床診斷提供了解決方案。但目前模型只考慮了醫療事件的變化趨勢,沒有考慮單個醫療事件的時間間隔因素,例如,持續30 天與持續300 天的高血壓所反映的癥狀嚴重性是不同的。因此下一步將在數據中融入時間信息以刻畫癥狀的嚴重性程度,并改善模型,提升模型的可解釋性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
