基于深度生成模型的聚合查詢區間估計方法
2023-11-18 03:33:04薛曉東周云亮
計算機工程 2023年11期
房 俊,薛曉東,周云亮
(1.北方工業大學 信息學院,北京 100144;2.大規模流數據集成與分析技術北京市重點實驗室,北京 100144)
0 概述
當前,用戶希望通過對大數據的分析處理來發掘潛藏在數據間的關系,以獲得更多有價值的信息。但是,由于數據量大的特性,傳統的精確査詢方法難以滿足用戶在訪問效率上的需求。此外,部分用戶所提出的分析需求可以理解為目的性不夠明確的探索式査詢,其特點是用戶對結果準確性的要求并非十分嚴格,更在意查詢速度是否足夠快。近似查詢處理(Approximate Query Processing,AQP)技術通常以遠小于精確查詢的查詢代價為用戶提供近似答案,往往允許用戶在準確性和查詢執行速度之間進行權衡。在數據探索式和可視化分析等應用中,這種權衡不僅可以接受,而且通常是有必要的。
目前,已經有不少學者對AQP 相關技術進行了研究,不同的方法在查詢準確性、響應時間、空間預算和所支持的查詢[1-2]之間進行了不同的權衡,要綜合考慮這些方面來達成一個令人滿意的方法仍然是一個挑戰。基于抽樣的AQP 是應用最廣泛的近似查詢處理方法之一,主要分為離線抽樣和在線抽樣兩種。離線抽樣意味著在查詢開始執行之前創建樣本。均勻抽樣以等概率選擇每個數據作為樣本,雖然做法簡單,但是在面對查詢答案涉及多個值的分組查詢時,隨機抽樣的方法很難為所有組提供足夠準確的估計。分層抽樣[3-4]是提高抽樣精度的一種方法,它以不同的概率從每一組中進行抽樣,但是分層抽樣通常依賴于一些先驗知識,如樣本分布等。在線抽樣[1]是在查詢出現后動態創建樣本,可以為給定的查詢謂詞選擇足夠的樣本,從而提高精度。但是,在線抽樣的缺點也很明顯,查詢時抽樣意味著需要經常訪問原始數據集,會導致較高的查詢時延,這在交互分析中是不可接受的[5]。
隨著人工智能技術的發展,模型驅動的AQP 方法近年來受到了更多的關注,研究人員將數據查詢處理和優化技術與人工智能中的機器學習、深度學習等技術相融合[6],取得了一定的研究成果:一類研究通過生成模型來生成數據樣本,再基于樣本進行近似查詢處理,相比于抽樣方法,其生成樣本速度較快,且在查詢準確性、普適性上具有一定優勢;另一類研究直接使用機器學習模型快速預測查詢結果,這類近似查詢方法雖然可以取得令人滿意的時間性能,但是查詢結果的誤差評價缺乏理論保障。
現有的模型驅動方法多數以一個估計值來回答查詢,從數理統計的角度來講,這種點估計的方法產生的結果總是會存在誤差,在面向某些不穩定的生成模型[如生成對抗網絡(Generative Adversarial Network,GAN)模型[7]]時,這種問題尤為明顯。區間估計可以在一定程度上判斷總體估計量的取值范圍,相應地會提高精度。不僅如此,在一些數據分析的實際業務場景中,研究人員對于某個總體估計量的取值范圍更感興趣,相比于單一值的點估計,采用置信區間作為返回值可以獲得更多的數據分布特征。例如,將基于隨機抽樣方法得到的樣本數據[{“id”:1;“pm25”:129},{“id”:2;“pm25”:138},{“id”:3;“pm25”:140},{“id”:4;“pm25”:90}]記為表T,針對查詢“select avg(pm25)from T”(實際值是98.61),其點估計結果是124.25,使用區間估計方法Bootstrap[1]的計算 結果 是[104.2-7.04,104.2+7.04](置信度是90%),可以看出區間估計方法的估計值更接近實際值。
以中心極限定理及Bootstrap 方法為代表的相關技術為基于抽樣的近似查詢結果提供了誤差范圍保障。GAN 模型可快速生成多個樣本,但是這些樣本不滿足中心極限定理的前提要求,一個猜想是是否可以通過多個樣本查詢結果來生成一個相對可靠的區間結果?此時,多個樣本查詢可能帶來更大的查詢時延,這也是Bootstrap 方法很少實際應用于AQP系統的主要原因。本文認為,當前分布式處理技術飛速發展,將相關技術引入AQP 系統中,有助于緩解上述性能問題。基于該思路,本文提出一種基于深度生成模型的聚合查詢區間估計方法,目的是為給定查詢生成足夠樣本以提高估計精度。首先利用深度生成模型學習數據分布特征,然后利用訓練好的模型快速生成多個樣本,隨后通過基于抽樣的AQP 方法為給定的查詢任務計算估計值,最后計算相應的置信區間并返回給用戶。
1 相關工作
近似查詢處理的主要目標是高效地找到與精確答案接近的近似答案,多年來一直是數據管理領域研究的熱點問題。基于抽樣的AQP 方法由于效率和普遍性方面的優勢而得到廣泛的研究和應用。基于少量樣本的查詢響應速度很快,但是降低了準確性。很多研究人員都在尋找合適的樣本,以期在不降低查詢速度的情況下提高查詢精度。隨機抽樣的查詢方法的主要缺點是查詢精度會隨著聚合屬性值方差的增大而降低,即隨機抽樣不能為具有高傾斜分布的數據集提供足夠準確的估計。分層抽樣是解決這一問題的一種方法,分層抽樣雖然可以提高精度,但是通常需要一些有關數據分布的知識。國會抽樣[3]是一種經典的分層抽樣方法,其將每個組在總體中所占的頻數作為依據,把原始數據分為若干組,在總體樣本量確定的情況下,在不同組中利用隨機抽樣方法得到一定量的分樣本,最后由分樣本組成總體樣本。CVOPT[4]是一種新的分層抽樣方法,它根據變異系數分配各組的樣本量。在線抽樣[8-9]是AQP 的另一種方式,它以不斷迭代的方式獲得更多的樣本,以提高估計精度,但是在線抽樣需要在查詢時抽取樣本,會造成較高的查詢時延。
有一些預計算的方法在執行查詢之前根據查詢工作負載計算直方圖[10]、小波[11]、數據立方體等概要,從而快速獲取聚合查詢結果,但是這些方法不能支持通用的查詢。此外,還有一些將抽樣與預計算相融合的AQP 技術,如文獻[12]提出了聯合基于預計算的數據立方體和基于抽樣的AQP 的AQP++技術,從而估計查詢結果。
近年來,機器學習方法被廣泛應用于數據處理和數據分析領域,有一些新的AQP 方法采用了機器學習技術。DBEst[13]是一種基于模型預測的AQP方法,它根據數據樣本建立概率密度模型和回歸模型,然后使用模型來直接回答查詢。但是,對于分組查詢,DBEst 需要為每個分組都構建一個模型,這將大幅增加模型訓練和存儲成本。文獻[14]對DBEst 進行拓展,基于單詞嵌入模型與神經網絡的混合架構,使用輕量級模型降低了內存的占用率。LAQP[15]是一個融合基于抽樣的AQP、預計算方法和機器學習的AQP 方法,其通過一個小的離線樣本來獲得較高精度的查詢估計值。使用機器學習方法來獲得近似查詢結果的主要問題是目前還無法像基于抽樣的AQP 方法那樣提供誤差保障。
還有一些基于模型樣本的查詢方法致力于使用深度生成模型來學習數據分布,通過模型生成樣本然后回答查詢。文獻[16-17]提出一種使用深度生成模型學習數據分布并通過訓練好的模型來生成樣本以近似回答查詢的方法,雖然該方法減少了查詢延遲,但是仍然會受到抽樣誤差的影響。文獻[18]訓練一個基于工作負載的模型,該模型捕獲數據的聯合概率分布并反映其關鍵特征,也支持直接更新,即模型可以識別數據庫上的操作類型,無需重新訓練模型。
在大多數抽樣估計方法中,置信區間被廣泛用于評價近似查詢的估計結果[19],通常根據用戶給定的置信度計算一個相應的置信區間。如果數據集的數據分布是已知的,或者有一個足夠大的樣本來得到數據分布,則上述過程轉變為一個經典的統計問題——參數估計。以計算一個正態分布上的某一屬性均值為例,如果已知正態分布的方差,則可以很容易地使用高斯分布模型N(μ,σ2)來計算置信區間。如果方差是未知的,可以將其形式化為T 分布。如果數據分布是未知的,則可以通過Bootstrap 和Closed-form Estimate[20]兩種方 法。Bootstrap 旨在獲得多個樣本,對于每個樣本S,可以計算出一個估計值,由這些值組成的分布可用于估計總體聚合結果的值。Bootstrap 對數據分布沒有限制,適用于大多數查詢,但是大多數Bootstrap 方法需要數千次重采樣,而重采樣過程非常耗時,因此Bootstrap 在實際應用中很受限制。Closed-form Estimate 方法以正態分布N(θ(S),σ2)來近似抽樣分布,并通過樣本的特殊封閉函數Var(S)估計方差σ2,利用中心極限定理可以證明這種近似的合理性。然而,Closed-form Estimate 方法只能適用于COUNT、SUM、AVG 這類比較容易計算方差的查詢。
2 方法介紹
如圖1 所示,本文基于深度生成模型的聚合查詢區間估計方法主要分為3 個階段:利用預處理后的數據訓練深度生成模型,經過多次迭代訓練后得到可靠的數據生成模型;基于該模型生成多個數據樣本,等待用戶查詢;用戶查詢到來后在不同樣本上分別執行查詢,將全部查詢結果匯總,根據用戶給定的置信水平計算相應的查詢結果置信區間并返回給用戶。

圖1 近似查詢方法執行過程Fig.1 The execution process of approximate query method
2.1 CWGAN-GP 模型訓練
在模型訓練階段,本文使用深度生成模型CWGAN-GP 來生成樣本,CWGAN-GP 是WGANGP[21]和條件生成對抗網絡(Conditional Generative Adversarial Network,CGAN)[22]的組合網絡。
GAN 模型的核心思想是用訓練神經網絡來代替對似然函數的求解,利用生成器和判別器之間的對抗學習來不斷優化模型的參數,利用這種方法規避求解似然函數的問題。但是,GAN 模型還存在一些問題,如模型難以訓練等。WGAN(Wasserstein GAN)[23]從原理上說明了GAN 模型存在的缺陷,提出用Wasserstein 距離替代KL 散度和JS 散度,優化了生成器和判別器的目標函數,因此,在很大程度上緩解了原始GAN 模型存在的一些問題。但是,WGAN 在訓練過程中常會出現收斂速度慢、梯度爆炸等現象。WGAN-GP 將判別器的梯度作為正則項加入判別器的目標函數中,該正則項通過梯度懲罰使判別器梯度在充分訓練后穩定在Lipschitz 常數附近。經過優化,WGAN-GP 幾乎不再出現梯度消失或梯度爆炸的問題,在很大程度上提高了模型收斂速度。CGAN 模型是GAN 模型的擴展,它向GAN的生成器和判別器添加條件設置,可以在給定條件下生成相應的數據。
CWGAN-GP 模型訓練過程如圖2 所示,將真實數據x及其對應的標簽y提供給模型,訓練生成器G和判別器D。首先固定G,訓練D,這是一個二分類問題,即給定一個樣本,訓練D 判斷其是真樣本還是由G 生成的假樣本;之后固定D,訓練G,給G 一個隨機輸入,損失函數是D 的輸出結果,根據損失函數對G 的參數進行更新。重復上述2 個過程,經過多次訓練后,生成器與判別器達到納什均衡就停止,此時生成器可以為給定的標簽生成一個與真實樣本x相似的樣本x′。
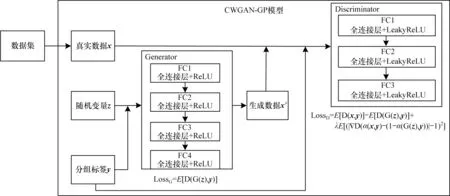
圖2 CWGAN-GP 模型訓練過程Fig.2 Training process of CWGAN-GP model
在模型訓練前需要標記數據,為使模型能夠為給定的組生成樣本,本文用組屬性值來標記數據,編碼的分組屬性值將被視為訓練數據的標簽。一些研究人員[16-17]使用One-Hot 編碼方法來實現,假設屬性A有3 個取值{A1,A2,A3},One-Hot 編碼為A1=001,A2=010,A3=100。如果屬性域取值較多,這種方法會導致2 個主要問題:編碼后的向量可能非常稀疏,導致性能較差[24];提高了模型學習的參數量,增加了模型的訓練時間。針對這些問題,本文使用Binary-Encoding來降低編碼維度,同時使得編碼后的向量更加稠密。上述例子使用Binary-Encoding編碼后,只需要二維向量(「lb 3?=2),編碼結果為A1=00,A2=01,A3=10。
2.2 多樣本生成
如圖3 所示,基于大規模并行處理(Massively Parallel Processing,MPP)[25-26]架構快速生成多份樣本,該架構包括Master和Segment兩類服務器節點。

圖3 基于MPP 的多樣本生成與近似聚合查詢Fig.3 Multi sample generation and approximate aggregation query based on MPP
Master 節點主要負責:
1)將第2.1 節的CWGAN-GP 生成模型復制到Segment 節點的模型存儲庫
2)維護聚合查詢的生成模型映射元數據
3)接收Client的多樣本生成請求(qPattern,n,m),其中,n為生成的樣本份數,m為每份樣本的數據量。形成分布式生成樣本的任務請求(mID,ni,m)并分配給Segment 節點,其中,mID 是qPattern 對應的模型主鍵,ni是第i個Segment節點需要生成的樣本個數,ni根據Segment節點數量采用均衡策略生成。
Segment 節點主要負責:
1)接收并存儲數據生成模型。
2)接收Master節點的生成樣本請求(mID,ni,m),使用相應的CWGAN-GP 生成模型生成樣本。
為了能夠有效利用物理資源,每個多核Segment節點可并行執行多個任務實例。在每個Segment 節點上開啟多個進程,并行生成樣本,之后將樣本放到Segment 節點的樣本內存區域。
分組查詢的結果涉及多個值,隨機抽樣方法很難為所有組提供足夠準確的估計。為提高準確性,本文選擇用分層抽樣的方法獲取每份樣本,算法1描述了使用生成器G 生成樣本的過程。根據數據集中各分組屬性在總體中所占的比例來計算樣本中每組的個 數NSamplesize。Random(z,NSamplesize)表示產 生NSamplesize個隨機噪聲,將其作為模型的輸入。Repeat(Binary-Encoding(i),NSamplesize)表示重復得到NSamplesize個經過Binary-Encoding 編碼的標簽數據,作為模型的輸入。
算法1模型生成樣本的過程
2.3 聚合查詢區間估計
聚合查詢區間估計階段仍然基于圖3 的MPP 架構來完成。由Master 節點將聚合查詢任務并行分發到各個Segment 處理節點,每個處理節點開啟多個進程,每個進程負責完成一個查詢子任務,生成一個近似查詢結果,并回傳給Master 節點。在每個節點都完成查詢任務后,Master 節點將n個近似查詢結果匯總并計算得到最終的結果。借助中心極限定理,以正態近似的方式來計算置信區間,最終得置信區間為其中:Mean(S)表示n份樣本集上聚合結果的均值;Var(S)是聚合結果的方差;a是用戶給定的置信水平為分位數。
3 實驗驗證
3.1 實驗環境
本文實驗中的查詢任務是在集群上完成的,集群由6 臺同配置服務器組成,配置如表1 所示。其中,1 臺服務器用于模型訓練及Master 節點,其余5 臺服務器作為Segment 節點用于樣本生成和查詢處理。為了充分利用物理資源,每個多核Segment節點可并行執行多個任務實例,在本次實驗中,每臺服務器設置16 個進程。

表1 實驗環境Table 1 Experimental environment
3.2 實驗數據
本文分別在如下2 個數據集上進行實驗:
1)PM2.5[13]數據集,包含了美國駐北京大使館的pm25 數據信息,同時還包括了北京首都國際機場的氣象數據,共43 824 條數據。在對PM2.5 數據集的聚合查詢中,聚合值屬性是“pm25”,且每個謂詞只涉及一個屬性“PREC”,其余部分屬性如表2所示。

表2 PM2.5 數據Table 2 PM2.5 data
2)ROAD[16]數據集,這是一個為道路網絡添加海拔信息而建造的數據集,共包含434 874 條數據。ROAD 數據集 有“Longitude”“Latitude”和“Elevation”3 個屬性。本文在ROAD 數據集上添加一個按組排列的屬性“GroupID”,并將“Latitude”的取值范圍劃分為10 個相等的子范圍,每條數據添加的組屬性值是其所屬子范圍的索引。修改后的數據集有4 個屬性,如表3 所示。
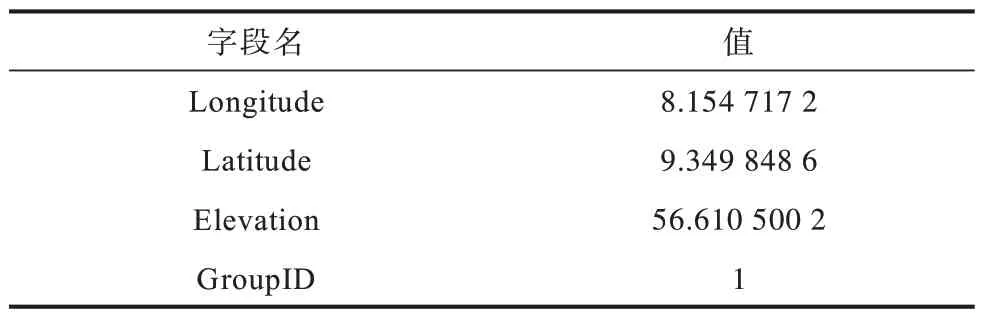
表3 ROAD 數據Table 3 ROAD data
本文實驗用到的查詢包括帶謂詞的查詢以及分組查詢,聚合函數有COUNT、AVG。部分查詢語句如表4 所示。

表4 查詢語句Table 4 Query statements
3.3 評價指標
本文采用置信區間的覆蓋率(Confidence Interval Coverage,CIC)來衡量查詢估計的準確性。CIC 是利用本文方法計算置信區間后統計給定查詢的實際值落在置信區間中的比例,計算公式如下:
其中:Result 是在原始數據集上執行查詢的結果集;truei表示第i組的真實聚合值,是集合Result 中的元素;Interval 為計算的置信區間;d(x,y)是一個判別函數,若實際值x落在置信區間y中,則取值為1,否則取值為0。
為了對比不同置信區間的計算結果,將CIC 進行歸一化,即計算CIC 與相應置信度a的比值,如式(2)所示:
3.4 結果分析
本文生成模型CWGAN-GP 的生成器有4 個全連接的隱藏層,每層中神經元的數量分別為512、256、128、64 個。判別器有3 個全連接的隱藏層,每層中神經元的數量分別為512、256、128 個。將優化器設置為RMSprop,設置RMSprop 的參數為(lr=0.000 05,rho=0.95)。在計算置信區間時,增加每份樣本集的數量會對計算結果產生影響,但同時也需要考慮性能,在本節實驗中會比較不同樣本集數量下的結果,從而選擇合適的取值。設置抽樣輪次r=103,實驗結果均為經過多次實驗后所得。
3.4.1 深度生成模型的抽樣效率
本次實驗基于ROAD 數據集,比較利用模型生成樣本和利用隨機抽樣方法生成樣本所耗費的時間。為了比較不同數據規模下的抽樣效率,首先利用ROAD 數據集 生成大 小依次 為1×106、10×106、50×106、100×106、200×106的5 個實驗數據集,再分別從這5 個實驗數據集中利用隨機抽樣方法抽取1 000 個數據作為生成樣本,實驗結果如圖4 所示。從圖4 可以看出,利用模型生成樣本所需的時間小于隨機抽樣方法,且前者所需的時間與數據集大小無關。隨機抽樣方法的抽樣時間與數據集大小呈線性相關,隨著數據集的增大而不斷增加。可見,利用模型生成樣本的方法對于大數據集將更加有效。
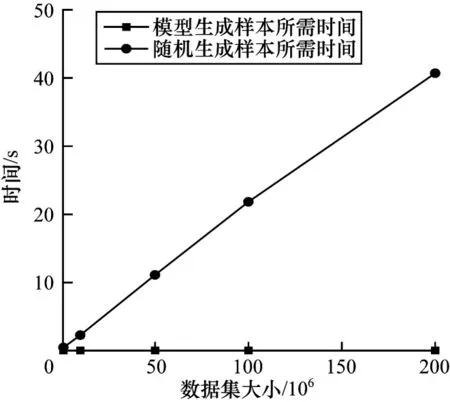
圖4 數據集大小對抽樣時間的影響Fig.4 The impact of dataset size on sampling time
3.4.2 深度生成模型的抽樣效果
本次實驗將在ROAD 和PM2.5 數據集上分別對生成樣本和隨機樣本的分布進行可視化。從每個數據集中選擇1 000 個隨機樣本,同樣地,利用模型也生成1 000 個樣本。為了更加準確地表示數據集的數據分布,以分層抽樣的方法獲得隨機樣本,即根據數據集中不同分組中的元組數量來分配樣本集中這一分組的數量。圖5 分別顯示了在2 個數據集中隨機樣本和生成樣本的分布情況。從圖5 可以看出,生成樣本和真實樣本的分布在視覺上比較相似,即由模型生成的樣本數據比較接近數據集中的真實數據,因此,可以由模型生成的樣本來代替從數據集中抽樣獲得的樣本。

圖5 樣本分布對比Fig.5 Sample distribution comparison
3.4.3 置信區間的覆蓋率
通過改變查詢謂詞范圍生成查詢數量分別為100、200、300、400、500 個的任務集。利用本文方法計算置信度分別為80%、85%、90%、95%的置信區間,在2 個數據集上對比計算所得歸一化的置信區間覆蓋率(NCIC),結果如圖6 所示。由圖6 可知,由本文方法得到的查詢結果計算的NCIC 均可達85%以上,其中有48.25%的任務集計算的NCIC 在95%以上,這表明區間估計結果具有較高的精度,而且在不同數據集、面對不同查詢任務時均有較好的表現,可移植性高。

圖6 歸一化的置信區間覆蓋率對比Fig.6 Comparison of NCIC
3.4.4 查詢時間對比
將本文方法與第1 節中提到的幾種常見查詢方法進行對比,包括隨機抽樣的查詢方法、基于模型樣本的查詢方法、基于模型預測的查詢方法,分析各方法執行查詢所需的時間。其中,基于模型樣本與基于隨機抽樣的查詢方法的時間相同,因此沒有列出基于模型樣本的方法的結果。在PM2.5 數據集上,生成抽樣比分別為5%、10%、15%、20%、25%、30%的樣本,對比執行查詢所需的時間,在接下來的實驗中,未加特別說明時均計算置信度為90%的置信區間,實驗結果如圖7 所示。由圖7 可知,本文方法在查詢時間上開銷大于基準方法,主要原因是本文方法涉及在多份樣本上執行查詢,之后還需要匯總查詢結果生成區間結果,這一過程比較耗時,但從整體來看,秒級時間開銷對于常規應用還是能夠接受的。
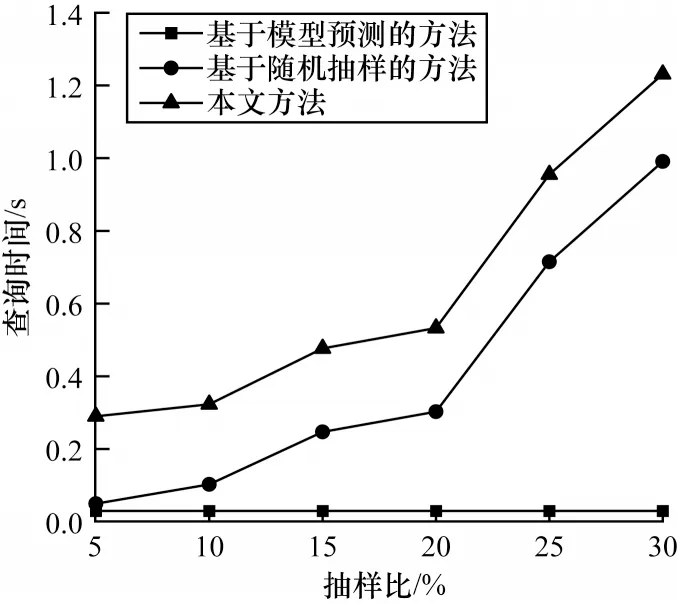
圖7 查詢時間對比Fig.7 Query time comparison
3.4.5 樣本量對查詢結果的影響
設置300 個聚合函數為COUNT 的查詢來比較不同樣本量對查詢結果的影響。本文主要考慮執行查詢所需時間和置信區間的覆蓋率CIC,結果如圖8所示。
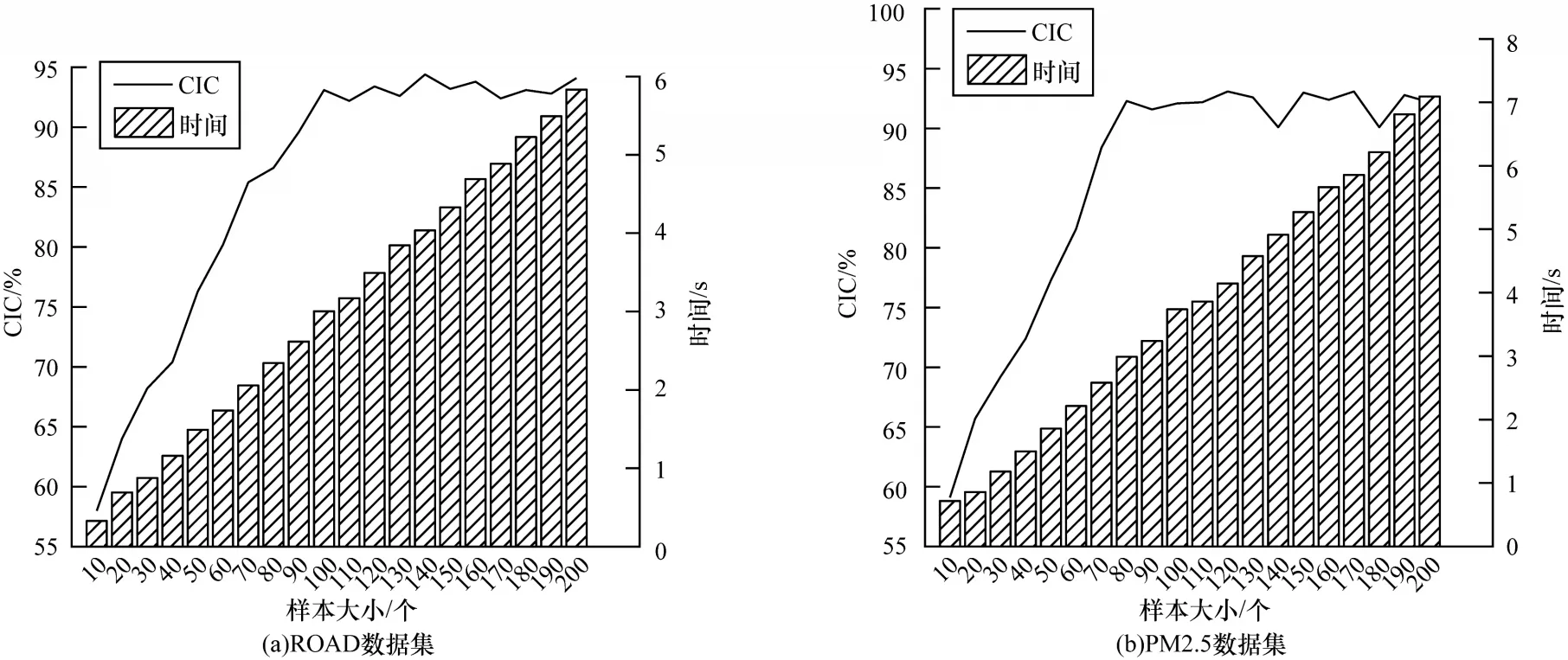
圖8 樣本量對查詢結果的影響Fig.8 The impact of sample size on query results
由圖8 可以看出,隨著樣本量的增加,查詢的執行時間不斷增加,而置信區間的覆蓋率增長率逐漸減少,即曲線逐漸變得平穩。綜合比較來看,對于ROAD 數據集,本文選擇樣本量n=100,對于PM2.5數據集,選擇n=80。
3.4.6 查詢選擇性對查詢結果的影響
在ROAD 和PM2.5 數據集上分別測試查詢選擇性對查詢結果的影響,設置300 個聚合函數為COUNT 且選擇性低于0.03 的查詢,對比隨機樣本與生成樣本的置信區間覆蓋率,結果如圖9 所示。

圖9 查詢選擇性對結果的影響Fig.9 The impact of query selectivity on results
從圖9 可以看出,對于隨機樣本和生成樣本,置信區間覆蓋率都隨著查詢選擇性的增加而增加,并且基于生成樣本的估計更加準確。其原因是:與從整個數據集中選擇的隨機樣本相比,生成樣本所包含的滿足查詢謂詞的樣本比例更高。本實驗中的查詢是低選擇性的查詢,這意味著從整個數據集中選擇的大多數樣本不滿足查詢謂詞,只有一小部分樣本對估計有貢獻,這導致隨機樣本的精度較低。由于生成模型可以靈活地生成某些子范圍的樣本,因此可以獲得更多的樣本,有助于提高估計精度。
4 結束語
本文提出一種基于深度生成模型的聚合查詢區間估計方法。該方法在不訪問原始數據集的條件下,利用CWGAN-GP 模型為給定的查詢并行生成多個近似樣本,通過多個樣本查詢結果聚合生成相對可靠的區間查詢結果。實驗結果表明,相比于常見的點估計近似查詢方法,該方法不僅提高了近似查詢估計的精度,也能夠降低查詢誤差。此外,該方法還可以根據不同的優化目標與多種抽樣方法相結合。雖然本文方法取得了較好的結果,但是生成大量的樣本客觀上也增加了時間開銷,因此,下一步將繼續優化抽樣以及查詢過程,減少時間開銷。此外,根據查詢結果日志來判斷生成樣本的質量,有選擇性地替換部分樣本集,進一步提高查詢精度,也是今后的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
