概念漂移下的系統(tǒng)日志在線(xiàn)異常檢測(cè)模型
2023-11-02 12:37:20呂宗平梁婷婷顧兆軍劉春波
計(jì)算機(jī)應(yīng)用與軟件 2023年10期
呂宗平 梁婷婷,2 顧兆軍 劉春波 王 雙 王 志
1(中國(guó)民航大學(xué)信息安全測(cè)評(píng)中心 天津 300300)
2(中國(guó)民航大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院 天津 300300)
3(南開(kāi)大學(xué)人工智能學(xué)院 天津 300071)
0 引 言
系統(tǒng)日志是由監(jiān)控系統(tǒng)基于程序代碼預(yù)設(shè)條件下自動(dòng)產(chǎn)生的富含大量描述系統(tǒng)(如分布式系統(tǒng)、操作系統(tǒng))狀態(tài)信息的事件集合[1],能夠如實(shí)地記錄所有信息系統(tǒng)的系統(tǒng)狀態(tài)和行為[2]。在這些大型分布式系統(tǒng)中產(chǎn)生的日志大多數(shù)情況下可以看作動(dòng)態(tài)達(dá)到的流式數(shù)據(jù)。與傳統(tǒng)數(shù)據(jù)相比,這類(lèi)日志數(shù)據(jù)具有動(dòng)態(tài)性、無(wú)序性、無(wú)限性、突發(fā)性和體積大等特點(diǎn)。首先,大批量的日志數(shù)據(jù)源源不斷地涌入,將這些日志數(shù)據(jù)完全存儲(chǔ)下來(lái)幾乎不可能;其次,數(shù)據(jù)具有時(shí)間屬性,帶有表示事件發(fā)生的時(shí)刻的時(shí)間戳信息;最后,樣本分布、樣本的特征可能隨時(shí)間變化,呈現(xiàn)動(dòng)態(tài)變化的特點(diǎn)[3]。傳統(tǒng)中通過(guò)手工檢查是不切實(shí)際的,目前,針對(duì)自動(dòng)日志解析,學(xué)術(shù)界和工業(yè)提出了許多數(shù)據(jù)驅(qū)動(dòng)方法,包括頻繁模式挖掘(SLCT,及其擴(kuò)展的聚類(lèi)方法LogCluster)、迭代分區(qū)(IPLoM)、層次聚類(lèi)(LKE)、最長(zhǎng)公共子序列計(jì)算(Spell)和解析樹(shù)(Drain)等[4]。網(wǎng)絡(luò)日志分析對(duì)網(wǎng)絡(luò)安全管理具有重要意義,但現(xiàn)有的網(wǎng)絡(luò)日志分析系統(tǒng)具有無(wú)法處理海量日志數(shù)據(jù)、采用離線(xiàn)模式和處理時(shí)延較長(zhǎng)等弊端[5]。結(jié)合自動(dòng)日志解析實(shí)現(xiàn)一個(gè)高效且實(shí)時(shí)的基于系統(tǒng)日志的異常檢測(cè)算法具有重要的理論意義和實(shí)際應(yīng)用價(jià)值。
然而,由于動(dòng)態(tài)變化和非平穩(wěn)環(huán)境中發(fā)生的概念漂移或模型老化,動(dòng)態(tài)生成的日志會(huì)導(dǎo)致傳統(tǒng)異常檢測(cè)算法的性能?chē)?yán)重下降[6]。已有的基于離線(xiàn)學(xué)習(xí)的日志異常檢測(cè)模型如支持向量機(jī)、邏輯回歸、決策樹(shù)[7]和模糊核聚類(lèi)[8]等,概念不隨新的日志數(shù)據(jù)的分布而改變,這些算法無(wú)法完全正確地識(shí)別異常事件,因此會(huì)做出模糊的決策。所以,基于離線(xiàn)學(xué)習(xí)的日志異常檢測(cè)算法面臨著概念漂移問(wèn)題,在系統(tǒng)劇烈變化的環(huán)境下表現(xiàn)為性能降低。在面對(duì)動(dòng)態(tài)中產(chǎn)生的概念漂移問(wèn)題時(shí),大多算法選擇重訓(xùn)練(Retrain)來(lái)解決。Retrain是一種模擬增量學(xué)習(xí)的機(jī)器學(xué)習(xí)算法,每當(dāng)有新的數(shù)據(jù)出現(xiàn)時(shí),Retrain就丟棄以前的模型,將新的數(shù)據(jù)與以前的數(shù)據(jù)合并,并在這個(gè)數(shù)據(jù)上學(xué)習(xí)新的模型。但是Retrain沒(méi)有考慮同一類(lèi)日志的差異或日志之間的不一致性,沒(méi)有能夠根據(jù)數(shù)據(jù)分布變化或新日志與以前日志的關(guān)系隨著時(shí)間動(dòng)態(tài)更新以往經(jīng)驗(yàn)的機(jī)制。同時(shí),由于數(shù)據(jù)集不斷增大,Retrain需要一個(gè)相當(dāng)大的訓(xùn)練集來(lái)代表所有可能的正常行為,這需要日志完整地下載和識(shí)別標(biāo)注,從日志產(chǎn)生到檢測(cè)結(jié)束具有較大的時(shí)間跨度,不能及時(shí)地檢測(cè)出系統(tǒng)異常,對(duì)系統(tǒng)內(nèi)存資源的消耗非常大。
為了減少在線(xiàn)中概念漂移對(duì)日志異常檢測(cè)算法的產(chǎn)生的影響,本文提出了一種能夠基于置信度動(dòng)態(tài)增量更新的在線(xiàn)日志異常檢測(cè)模型(COP)。首先根據(jù)時(shí)間順序模擬了Hadoop分布式文件系統(tǒng)HDFS日志生成環(huán)境。之后提出用于計(jì)算統(tǒng)計(jì)值p值的一致性度量模塊,在此基礎(chǔ)上設(shè)置一個(gè)基于置信度的校準(zhǔn)集,在滑動(dòng)窗口步長(zhǎng)范圍內(nèi)的日志數(shù)據(jù)將根據(jù)校準(zhǔn)集得到可靠的標(biāo)簽。僅訓(xùn)練一次數(shù)據(jù)時(shí),數(shù)據(jù)的傳遞就變得相當(dāng)重要。COP根據(jù)時(shí)間的推移不斷將可信的日志數(shù)據(jù)、一致得分反饋到這個(gè)校準(zhǔn)集,根據(jù)p值更新校準(zhǔn)集。這個(gè)校準(zhǔn)集將作為之前日志的概要來(lái)計(jì)算后續(xù)滑動(dòng)窗口中日志數(shù)據(jù)檢測(cè)的依據(jù)以計(jì)算p值。經(jīng)實(shí)驗(yàn)驗(yàn)證,本文提出的COP異常檢測(cè)算法能夠達(dá)到與重訓(xùn)練異常檢測(cè)算法相當(dāng)?shù)男阅軝z測(cè)結(jié)果,平均檢測(cè)時(shí)間為181.417秒,大大降低了檢測(cè)時(shí)間。
1 概念漂移
根據(jù)應(yīng)用場(chǎng)景的不同可以將異常檢測(cè)分為離線(xiàn)異常檢測(cè)(又稱(chēng)為批處理)和在線(xiàn)異常檢測(cè)。在線(xiàn)異常檢測(cè)顧名思義即為結(jié)合在線(xiàn)學(xué)習(xí)的異常檢測(cè)方法也被稱(chēng)為增量學(xué)習(xí)或適應(yīng)性學(xué)習(xí),是指對(duì)一定順序下接收數(shù)據(jù),每接收一個(gè)數(shù)據(jù),模型會(huì)對(duì)它進(jìn)行檢測(cè)并對(duì)當(dāng)前模型進(jìn)行更新,然后處理下一個(gè)數(shù)據(jù)。基于在線(xiàn)學(xué)習(xí)的異常檢測(cè)方法滿(mǎn)足一些實(shí)時(shí)性要求較高的日志分析系統(tǒng)需求。針對(duì)流數(shù)據(jù)的在線(xiàn)異常檢測(cè)算法通常在PCA[9]、隔離森林[10]等基礎(chǔ)上使用梯度增量算法對(duì)損失進(jìn)行優(yōu)化,或者與LSTM[11-12]等深度學(xué)習(xí)結(jié)合。但是深度學(xué)習(xí)訓(xùn)練和檢測(cè)過(guò)程耗時(shí)長(zhǎng),不適用于在線(xiàn)中需要快速響應(yīng)的環(huán)境中。這些異常檢測(cè)方法都可以得到不錯(cuò)的實(shí)驗(yàn)效果,但隨著時(shí)間的推移,面對(duì)爆炸式涌現(xiàn)且多變的數(shù)據(jù),建立一個(gè)持續(xù)且不會(huì)退化的能夠?qū)崟r(shí)學(xué)習(xí)的模型仍然存在困難。
概念漂移問(wèn)題通常是指輸入數(shù)據(jù)和目標(biāo)變量隨時(shí)間變化的關(guān)系。數(shù)據(jù)分布的變化使得基于數(shù)據(jù)的舊模型與基于新數(shù)據(jù)的不一致,有必要對(duì)模型進(jìn)行定期更新[13]。在動(dòng)態(tài)變化的環(huán)境中,非平穩(wěn)的數(shù)據(jù)的基礎(chǔ)分布可能會(huì)隨著時(shí)間的推移而動(dòng)態(tài)變化,如圖1所示。概念漂移設(shè)置中的一般假設(shè)是變化意外地發(fā)生并且是不可預(yù)測(cè)的,盡管在某些特定的現(xiàn)實(shí)世界情況下,可以提前知道與特定環(huán)境事件的發(fā)生相關(guān)的變化,但是針對(duì)漂移的一般情況的解決方案需要針對(duì)特定情況的解決方案。在時(shí)間序列演變過(guò)程中需要能夠根據(jù)高層特征的變化作出自適應(yīng)的調(diào)整,獲得對(duì)新生成類(lèi)別的鑒別。
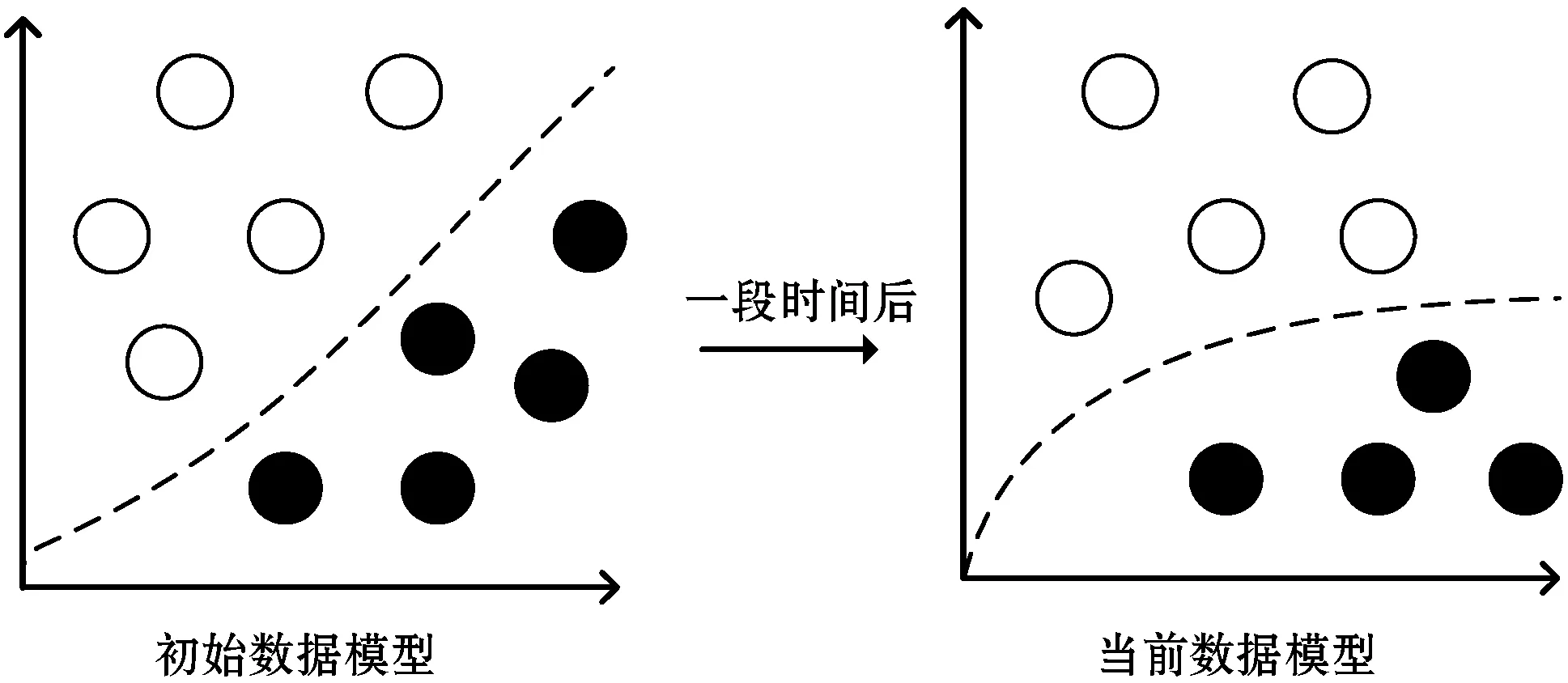
圖1 經(jīng)過(guò)一段時(shí)間后數(shù)據(jù)發(fā)生概念漂移現(xiàn)象
應(yīng)對(duì)概念漂移的方法可以分為全局替換方法和局部替換方法。全局模型中的自適應(yīng)方法,比如邏輯回歸模型,需要模型的完全重構(gòu),這是對(duì)漂移最根本的反應(yīng)。刪除一個(gè)完整的模型,從頭開(kāi)始一個(gè)新的模型,比如本文中作為對(duì)比實(shí)驗(yàn)的邏輯回歸Retrain。但是許多情況下更改只發(fā)生在數(shù)據(jù)空間的某些區(qū)域,所以可以通過(guò)調(diào)整模型的某些部分,結(jié)合統(tǒng)計(jì)學(xué)習(xí)一致性度量的方法,抵抗在線(xiàn)異常檢測(cè)中存在的概念漂移。已有的基于自適應(yīng)微簇的任意形狀進(jìn)化數(shù)據(jù)流聚類(lèi)算法,設(shè)計(jì)遞歸的微簇半徑更新機(jī)制,自適應(yīng)地搜索微簇半徑的局部最優(yōu)值[14]。
當(dāng)給定算法的原始分?jǐn)?shù)作為一致性度量的決策標(biāo)準(zhǔn)時(shí),需要認(rèn)識(shí)到傳統(tǒng)算法通常使用固定閾值判斷標(biāo)簽。從原始分?jǐn)?shù)建立的閾值缺乏選擇背景和意義。將原始分?jǐn)?shù)與p值相結(jié)合可以提供清晰明了的統(tǒng)計(jì)意義。p值能夠以標(biāo)準(zhǔn)化的范圍(0~1)量化地觀察到漂移,而不需要考慮底層基礎(chǔ)算法[15]。
2 實(shí)驗(yàn)?zāi)P?/h2>2.1 模型框架
如圖2所示,實(shí)驗(yàn)?zāi)P涂傮w上主要包括日志預(yù)處理、一致性度量和在線(xiàn)一致性增量檢測(cè)三個(gè)步驟。在線(xiàn)學(xué)習(xí)模型基于時(shí)間的推移,使用滑動(dòng)窗口存儲(chǔ)固定數(shù)量的最近的日志數(shù)據(jù)。首先將窗口內(nèi)的原始非結(jié)構(gòu)化日志文本轉(zhuǎn)變?yōu)榻Y(jié)構(gòu)化日志;再通過(guò)特征提取轉(zhuǎn)化為一致性度量模塊可接收的輸入數(shù)據(jù);接下來(lái)使用一致性度量映射出的一致性得分計(jì)算p值,并進(jìn)行一致性預(yù)測(cè)以及校準(zhǔn)集的更新。

圖2 模型框架
2.2 日志預(yù)處理
日志預(yù)處理部分包括日志解析和特征提取兩個(gè)步驟。原始的非結(jié)構(gòu)化日志文本由時(shí)間戳和日志文本組成,不能直接輸入在線(xiàn)學(xué)習(xí)模型進(jìn)行異常檢測(cè)。在通過(guò)日志解析成結(jié)構(gòu)化日志之后,使用特征提取的方法轉(zhuǎn)換為特征矩陣,用于后續(xù)的異常檢測(cè)。
圖3詳細(xì)說(shuō)明了日志預(yù)處理中日志解析和特征提取的步驟。如1.1節(jié)中提到的,日志解析的目的是將原始的非結(jié)構(gòu)化日志文本數(shù)據(jù)轉(zhuǎn)化為結(jié)構(gòu)化的常量與變量的對(duì)應(yīng)關(guān)系模板。在日志解析后,進(jìn)一步將日志事件編碼為特征向量,進(jìn)而形成特征矩陣,以便應(yīng)用在基于日志的異常檢測(cè)算法中。特性提取將使用會(huì)話(huà)窗口技術(shù)來(lái)計(jì)算日志事件出現(xiàn)的次數(shù),并形成一個(gè)特征矩陣。

圖3 原始日志轉(zhuǎn)換為結(jié)構(gòu)日志
2.3 一小時(shí)日志數(shù)據(jù)分析
使用最開(kāi)始的一個(gè)小時(shí)的日志數(shù)據(jù)建立模型,根據(jù)置信度分布估計(jì)顯著性水平。例如,圖4(a)為所有正常日志數(shù)據(jù)出現(xiàn)次數(shù)與p值的關(guān)系,正常的日志數(shù)據(jù)置信度大多集中在0.901 013 25。圖4(b)中異常數(shù)據(jù)p值大多接近于0,但大部分集中在0.000 141 713至0.027 634 096之間。這說(shuō)明正常日志數(shù)據(jù)與異常日志數(shù)據(jù)很大程度上區(qū)別度很高。保存一小時(shí)內(nèi)的數(shù)據(jù)集中所有的正常數(shù)據(jù)組成校準(zhǔn)集,作為接下來(lái)在線(xiàn)一致性預(yù)測(cè)的經(jīng)驗(yàn)。

(a) 正常日志數(shù)據(jù)
2.4 一致性度量
一致性度量方法指測(cè)量樣本和已知標(biāo)簽數(shù)據(jù)集之間的一致性程度的方法,給出的結(jié)果是一致性得分,代表了樣本與待測(cè)數(shù)據(jù)集之間的一致性程度[16]。檢測(cè)系統(tǒng)的模型匹配算法可以看作是一致性度量方法,其計(jì)算結(jié)果可以作為一致性得分。
經(jīng)過(guò)日志預(yù)處理之后得到特征矩陣,輸入一致性度量函數(shù)中得到一致性得分。選取邏輯回歸算法作為實(shí)值得分函數(shù)計(jì)算得分。邏輯回歸具有實(shí)施簡(jiǎn)單、建模高效的優(yōu)點(diǎn),它的計(jì)算量小、存儲(chǔ)資源占用低,可以在大數(shù)據(jù)場(chǎng)景中使用。邏輯回歸通過(guò)計(jì)算被測(cè)樣本異常概率的方式進(jìn)行分類(lèi)。例如,當(dāng)設(shè)置0表示正常,1表示異常,設(shè)置檢測(cè)固定閾值為0.5。當(dāng)邏輯回歸檢測(cè)出的概率小于閾值時(shí),那么數(shù)據(jù)標(biāo)簽設(shè)置0;如果邏輯回歸檢測(cè)出的概率大于閾值時(shí),那么數(shù)據(jù)標(biāo)簽為設(shè)置1。傳統(tǒng)閾值不能動(dòng)態(tài)適應(yīng)概念漂移,本文提出的異常檢測(cè)日志的一致性得分將反饋到相應(yīng)的分?jǐn)?shù)集,作為后續(xù)檢測(cè)的已有經(jīng)驗(yàn)來(lái)應(yīng)對(duì)不斷動(dòng)態(tài)變化的數(shù)據(jù)產(chǎn)生環(huán)境。
對(duì)于日志樣本l*,訓(xùn)練日志數(shù)據(jù)集D以及在訓(xùn)練集中相同標(biāo)簽的數(shù)據(jù)序列L,根據(jù)一致性度量方法得到的實(shí)值得分函數(shù)A計(jì)算一致性得分a,得分a表示當(dāng)前新的日志樣本與之前日志數(shù)據(jù)的一致性程度。在本文中實(shí)值得分函數(shù)A由邏輯回歸算法給出,得到的是被測(cè)樣本異常的概率,其計(jì)算式為:
a(l*)=AD(L,l*)
(1)
式中:滑動(dòng)窗口內(nèi)數(shù)據(jù)序列L,某時(shí)刻日志數(shù)據(jù)li,在預(yù)先已經(jīng)獲得的數(shù)據(jù)集序列D中提取出來(lái)的所有正常數(shù)據(jù)組成的校準(zhǔn)集Cali∈{c1,c2,…,ci},通過(guò)實(shí)值得分函數(shù)可以得到當(dāng)前數(shù)據(jù)的預(yù)測(cè)得分,如式(2)所示。
ai=AD(Cali,li)
(2)
2.5 在線(xiàn)一致性增量檢測(cè)
通過(guò)得分計(jì)算p值來(lái)評(píng)估新的日志樣本與之前的日志樣本的相似性,式(3)為p值的計(jì)算過(guò)程。通過(guò)計(jì)算當(dāng)前得分與校準(zhǔn)集中得分的百分位。統(tǒng)計(jì)校準(zhǔn)集中所有大于ai的日志個(gè)數(shù)并除以總樣本個(gè)數(shù)n。
(3)
使用p值建立一個(gè)新的檢測(cè)記錄分?jǐn)?shù)的數(shù)據(jù)和前面的正常分?jǐn)?shù)之間的聯(lián)系,這將避免算法造成的錯(cuò)誤決定從而能夠忽略?xún)?nèi)部細(xì)節(jié)和實(shí)現(xiàn)算法的影響。
為了能夠使用盡量少的數(shù)據(jù)來(lái)獲得盡量好的性能,不重復(fù)訓(xùn)練異常檢測(cè)模型,通過(guò)結(jié)合置信度動(dòng)態(tài)更新訓(xùn)練中得到的校準(zhǔn)集來(lái)對(duì)抗在線(xiàn)中的概念漂移。根據(jù)式(4),顯著性水平ε將會(huì)給出一個(gè)過(guò)濾后的檢測(cè)集,通過(guò)一致性預(yù)測(cè)給出置信度conf。
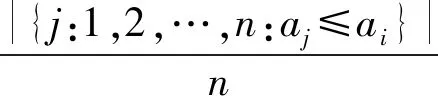
(4)
當(dāng)置信度越高,則意味著更高的可信度。當(dāng)ε=0.02時(shí),conf=0.98,則有98%的可信度得到以下結(jié)論:當(dāng)某條日志樣本數(shù)據(jù)的p值小于顯著性水平0.02時(shí),那么該條日志樣本數(shù)據(jù)有低于0.02的概率與校準(zhǔn)集的不一致程度相同或者更不一致。換句話(huà)說(shuō)我們有小于0.02的把握相信該條數(shù)據(jù)不是異常的。
如算法1中所示,隨著時(shí)間的推移更新校準(zhǔn)集。將新檢測(cè)出的正常的一致性得分和置信度反饋給原有的校準(zhǔn)集,并通過(guò)簡(jiǎn)單隨機(jī)抽樣的方法更新原有校準(zhǔn)集,防止校準(zhǔn)集隨著時(shí)間的推移不斷擴(kuò)大造成內(nèi)存不足,消耗p值計(jì)算時(shí)間。與Retrain相比,大大減少了對(duì)數(shù)據(jù)存儲(chǔ)空間的要求,提升了時(shí)間效率。利用能夠測(cè)量日志之間的p值,建立新日志與前日志之間連接的反饋機(jī)制的在線(xiàn)異常檢測(cè)。
算法1增量更新校準(zhǔn)集。
輸入:滑動(dòng)窗口中數(shù)據(jù)集Xn;日志校準(zhǔn)集Xcali;顯著性水平ε。
輸出:檢測(cè)后對(duì)應(yīng)窗口中日志數(shù)據(jù)的標(biāo)簽y_pred;更新后的校準(zhǔn)集Xcali。
1. aXn=A(Xn);
2. aCali=A(Xcali);
3. p=P(aXn,aCali);
4.ifp>ε:
5. y_pred_N=N with Conf;
6.else:
7. y_pred_A=A with Conf;
8. 增加aXnTo aCali;
9. 抽樣aCali
10.returny_pred,aCali
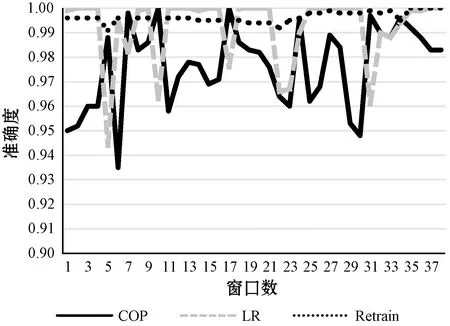
傳統(tǒng)一致性預(yù)測(cè)的時(shí)間復(fù)雜度主要來(lái)源于建模和檢測(cè)兩個(gè)部分。當(dāng)計(jì)算一個(gè)新的日志數(shù)據(jù)樣本相對(duì)于訓(xùn)練集的p值為例,檢測(cè)的時(shí)間較短可以忽略不計(jì)。假設(shè)建模的時(shí)間復(fù)雜度為On,訓(xùn)練集大小為n,計(jì)算單個(gè)樣本的p值時(shí)需要得到n+1個(gè)數(shù)據(jù)樣本的一致性得分,所以計(jì)算一個(gè)新樣本相對(duì)于一個(gè)標(biāo)簽的p值的算法復(fù)雜度為(n+1)×On。但由于COP中建模由一小時(shí)內(nèi)的校準(zhǔn)集(大小為m,m< 由于預(yù)處理是通過(guò)正則匹配快速解析日志文本,所造成的時(shí)間耗損較低,訓(xùn)練過(guò)程所使用的日志數(shù)據(jù)量較小,避免了因?yàn)橛?xùn)練而造成的較大的時(shí)延。綜上所述,COP能夠滿(mǎn)足在線(xiàn)檢測(cè)的要求。 所有實(shí)驗(yàn)運(yùn)行在64位Windows 10操作系統(tǒng)上(工作站處理器為i7-6700,3.4 GHz,內(nèi)存16.0 GB),Python 3.7編程環(huán)境。 系統(tǒng)日志數(shù)據(jù)集[6]采用香港中文大學(xué)的Hadoop分布式文件系統(tǒng)日志數(shù)據(jù)集HDFS進(jìn)行模擬在線(xiàn)環(huán)境。該數(shù)據(jù)集共1.58 GB,11 197 705個(gè)原始日志,復(fù)雜且能夠模擬一個(gè)動(dòng)態(tài)環(huán)境[2]。此數(shù)據(jù)集共近39小時(shí)原始日志數(shù)據(jù)。模擬在線(xiàn)環(huán)境時(shí),取第一個(gè)小時(shí)內(nèi)所有原始數(shù)據(jù)(OneHou-HDFS)進(jìn)行日志分析,通過(guò)專(zhuān)家領(lǐng)域?qū)<沂謩?dòng)標(biāo)記,共188 723條日志,特征提取后生成14 771條日志序列,其中異常數(shù)據(jù)659條,正常數(shù)據(jù)14 112條。系統(tǒng)異常包括對(duì)文件存儲(chǔ)塊的增加,移動(dòng)和刪除操作異常,如表1所示。 表1 數(shù)據(jù)集時(shí)間信息 在2.3節(jié)中可以觀察到當(dāng)傳統(tǒng)檢測(cè)算法在面對(duì)概念漂移問(wèn)題時(shí)會(huì)存在顯著的性能下降,使模型無(wú)法做出準(zhǔn)確的決策。本文通過(guò)p值動(dòng)態(tài)更新校準(zhǔn)集的方式在線(xiàn)檢測(cè)系統(tǒng)日志,能夠成功抵抗在線(xiàn)檢測(cè)中的概念漂移,達(dá)到Retrain時(shí)的性能水平。 本文中使用準(zhǔn)確度(Accuracy)、精確度(Precision)、召回率(Recall)和F-Score對(duì)在線(xiàn)模型進(jìn)行性能上的評(píng)估,通過(guò)檢測(cè)時(shí)長(zhǎng)評(píng)估模型的檢測(cè)速度。 本文通過(guò)混淆矩陣中TP、TN、FP和FN,根據(jù)式(5)-式(7)計(jì)算準(zhǔn)確度、精確度和召回率。 (5) (6) (7) 精確度的提高說(shuō)明誤報(bào)率較低,正常日志極少被錯(cuò)誤地檢測(cè)為異常日志;召回率的提高說(shuō)明漏報(bào)率較低,異常日志極少被錯(cuò)誤地檢測(cè)為正常日志。 加權(quán)調(diào)和平均數(shù)F-Score對(duì)是基于精確度和召回率定義的,是對(duì)精確度、召回率的一種權(quán)衡,定義為: (8) 式中:β為參數(shù),當(dāng)β=1時(shí),稱(chēng)為F1,此時(shí)認(rèn)為精確度與召回率同等重要;當(dāng)β<1時(shí),則認(rèn)為精確度比召回率重要;當(dāng)β>1時(shí),則認(rèn)為精確度不如召回率重要,此時(shí)另β=2得到F2。精確度和召回率評(píng)估時(shí),理想情況下做到兩個(gè)指標(biāo)都高當(dāng)然最好,但在實(shí)際中需要根據(jù)具體情況做出取舍,例如異常檢測(cè)時(shí),由于檢測(cè)出對(duì)系統(tǒng)不利的異常更加重要,所以在保證精確度的條件下,盡量提升召回率。 如第1節(jié)中提到的,在給定的數(shù)據(jù)流上檢測(cè)時(shí),可以考慮分類(lèi)精度的變化,如準(zhǔn)確度、召回率和F-Score,來(lái)觀察概念漂移問(wèn)題。在基于系統(tǒng)日志的異常檢測(cè)中,實(shí)時(shí)到達(dá)的日志數(shù)據(jù)樣本引起的概念漂移反映在算法的召回率和精確度的降低上。在解決在線(xiàn)異常檢測(cè)中的概念漂移之前,本文將數(shù)據(jù)集模擬為一個(gè)動(dòng)態(tài)環(huán)境,使用訓(xùn)練集擬合的模型檢測(cè)了測(cè)試集日志數(shù)據(jù),使用邏輯回歸作為異常檢測(cè)函數(shù)時(shí)的異常檢測(cè)結(jié)果。 如圖5所示,在面對(duì)概念漂移問(wèn)題時(shí),數(shù)據(jù)集的召回率最多會(huì)降低60%以上,意味著更少的異常被檢測(cè)出來(lái),精確度、F-Score也都出現(xiàn)了不同程度的降低。該算法無(wú)法在急劇變化的環(huán)境下及時(shí)地做出準(zhǔn)確的決策。概念漂移的出現(xiàn)意味著惡意行為模式已經(jīng)開(kāi)始發(fā)生遷移,在實(shí)際生產(chǎn)環(huán)境中,概念漂移問(wèn)題是無(wú)法完全避免和修復(fù)的,但是,可以在最大程度上對(duì)概念漂移做出適應(yīng),限制概念漂移的范圍。 圖5 傳統(tǒng)檢測(cè)算法在HDFS數(shù)據(jù)集上的評(píng)估結(jié)果 設(shè)置邏輯回歸(Logistic Regression,LR)異常檢測(cè)和Retrain實(shí)驗(yàn)作為對(duì)比實(shí)驗(yàn)。僅使用邏輯回歸算法訓(xùn)練全部日志數(shù)據(jù)集中第一小時(shí)內(nèi)的數(shù)據(jù)并建模。之后每一個(gè)窗口內(nèi)的日志數(shù)據(jù)都使用這個(gè)模型進(jìn)行異常檢測(cè)。很明顯,LR模型的檢測(cè)來(lái)源僅為一小時(shí)的日志數(shù)據(jù),沒(méi)有抵抗概念漂移的能力。如圖6所示,LR的精確度平均為0.921。LR的時(shí)間復(fù)雜度主要為初次建模時(shí)間Om,由于COP計(jì)算p值與更新校準(zhǔn)集的時(shí)間復(fù)雜度較低,與LR的之間整體性能相差不多,所以本次對(duì)比實(shí)驗(yàn)中沒(méi)有展示LR與COP的時(shí)間開(kāi)銷(xiāo)對(duì)比結(jié)果。 圖6 COP、LR和Retrain的實(shí)驗(yàn)性能 Retrain中隨著時(shí)間的推移,每新接收一個(gè)窗口的日志數(shù)據(jù)塊,都需要將之前已經(jīng)存儲(chǔ)的所有日志數(shù)據(jù)合并,將之作為訓(xùn)練集。根據(jù)訓(xùn)練集數(shù)據(jù)擬合邏輯回歸模型之后,對(duì)當(dāng)前窗口內(nèi)的日志數(shù)據(jù)序列檢測(cè)異常。Retrain是一種模擬增量學(xué)習(xí)的批處理方法,顯而易見(jiàn)的優(yōu)點(diǎn)是能夠訓(xùn)練過(guò)去所有的已有知識(shí)形成新的模型,如圖6(c)中所示,Retrain平均準(zhǔn)確度在三種算法中最高,達(dá)到0.996。但是其他檢測(cè)結(jié)果表現(xiàn)較差,Retrain并不能高效地抵抗概念漂移的出現(xiàn)。新的概念漂移發(fā)生點(diǎn)可能會(huì)淹沒(méi)在舊的知識(shí)里,對(duì)于概念漂移反應(yīng)較慢。同時(shí)它對(duì)時(shí)間和空間消耗也比較大,平均時(shí)間損耗為687.143 s。計(jì)算過(guò)程需要當(dāng)前時(shí)間節(jié)點(diǎn)之前的全部的數(shù)據(jù)下載存儲(chǔ)。LR只能依靠最開(kāi)始的模型來(lái)預(yù)測(cè),導(dǎo)致它的精確度和準(zhǔn)確度較三者中最低。而COP模型可以通過(guò)訓(xùn)練少部分的知識(shí),根據(jù)置信度更新校準(zhǔn)集的方式達(dá)到和Retrain相近的性能結(jié)果,平均精確度、平均召回率以及平均F-Score為均為三者最高水平。同時(shí)COP在時(shí)間上表現(xiàn)優(yōu)越,大大降低了檢測(cè)時(shí)間。 根據(jù)2.3節(jié)中對(duì)前一小時(shí)的數(shù)據(jù)分析,發(fā)現(xiàn)異常類(lèi)日志數(shù)據(jù)的p值集中在0.000 141 713~0.027 634 096之間。所以實(shí)驗(yàn)中將顯著性水平可以選擇設(shè)置為0.002左右。顯著性水平與最終決策相關(guān),若將ε設(shè)置高于0.02,那么會(huì)有更多正常事件被誤判為異常事件。在更新校準(zhǔn)集的時(shí)候,校準(zhǔn)集中所代表正常的p值會(huì)越來(lái)越少,可以判斷為正常事件的置信度會(huì)越來(lái)越高,初期表現(xiàn)在檢測(cè)精度的降低和召回率以及F-Score的提升上。但是隨著時(shí)間的推移,越來(lái)越多的正常事件會(huì)被判斷為異常事件,導(dǎo)致完全拋棄了過(guò)去的模式,到第5個(gè)窗口時(shí)就已經(jīng)幾乎完全檢測(cè)不到正常日志序列,檢測(cè)精確度僅為0.024,這種現(xiàn)象被稱(chēng)為災(zāi)難性的遺忘。但是也不能將ε設(shè)置過(guò)低,當(dāng)ε=0.000 2時(shí),幾乎不會(huì)有任何異常被檢測(cè)出來(lái),從第一個(gè)窗口開(kāi)始異常樣本數(shù)量只有6個(gè),隨著時(shí)間的推移,異常樣本接近于零。具體檢測(cè)性能表現(xiàn)為精確度的提升以及召回率和F-Score的降低。 本次實(shí)驗(yàn)中將顯著性水平設(shè)置ε=0.002。圖7表示COP、LR和Retrain在準(zhǔn)確度、精確度、召回率和F-Score的對(duì)比實(shí)驗(yàn)結(jié)果。COP的整體性能與LR和Retrain的實(shí)驗(yàn)相比相對(duì)平穩(wěn)。如圖7(a)中所示,Retrain由于數(shù)據(jù)量大,模型的準(zhǔn)確度表現(xiàn)與COP模型相比趨向平穩(wěn),COP與LR模型檢測(cè)準(zhǔn)確度隨著時(shí)間的推移存在波動(dòng)。圖7(b)中Retrain在22個(gè)窗口之前均低于LR與COP的精確度,但是從第22個(gè)窗口開(kāi)始,之后的窗口隨著時(shí)間推移經(jīng)驗(yàn)積累到一定程度之后模型擬合越來(lái)越精準(zhǔn),Retrain的精確度開(kāi)始回升之后穩(wěn)定在0.97左右。LR的檢測(cè)精確度最低為0.453,這意味著在第22個(gè)窗口中出現(xiàn)了模型判斷模糊的正常日志數(shù)據(jù),發(fā)生了概念漂移。一直不變的LR模型將這些處于邊界上的正常數(shù)據(jù)誤報(bào)為異常數(shù)據(jù),導(dǎo)致準(zhǔn)確度降低。但是由于COP設(shè)置動(dòng)態(tài)反饋的校準(zhǔn)集能夠保持新的知識(shí)不斷更新,抵抗了窗口中發(fā)生的概念漂移,將精確度提升至0.79。圖7(c)中COP模型召回率相對(duì)LR和Retrain來(lái)講較穩(wěn)定。LR在第7個(gè)窗口中召回率相較之前有所降低,出現(xiàn)將異常的數(shù)據(jù)判斷為正常數(shù)據(jù)的情況。本文提出的COP模型能夠通過(guò)控制顯著性水平區(qū)分正常數(shù)據(jù)和異常數(shù)據(jù),減少了漏報(bào)數(shù)量,提升了召回率。圖7(d)和(e)表示精確度與召回率的綜合結(jié)果F-Score,COP整體表現(xiàn)相對(duì)LR和Retrain較好。圖7(f)中,在檢測(cè)時(shí)間上,Retrain的平均時(shí)間損耗687.144 s,是COP模型的近四倍,COP模型大大提升了時(shí)間效率。 (a) 三種算法準(zhǔn)確度對(duì)比 針對(duì)目前大型在線(xiàn)系統(tǒng)自動(dòng)化異常檢測(cè)的需求,本文提出了一個(gè)能夠根據(jù)置信度在線(xiàn)增量更新的系統(tǒng)日志異常檢測(cè)模型。它將當(dāng)前的日志數(shù)據(jù)與之前的日志數(shù)據(jù)聯(lián)系起來(lái),有效地緩解動(dòng)態(tài)環(huán)境中概念漂移的問(wèn)題。通過(guò)Hadoop分布式文件系統(tǒng)HDFS日志數(shù)據(jù)按照時(shí)間順序模擬實(shí)時(shí)動(dòng)態(tài)的日志生成環(huán)境,COP模型可以高效地檢測(cè)數(shù)據(jù)集中的異常,得到與重訓(xùn)練在精確度、召回率等相近的檢測(cè)結(jié)果,并降低檢測(cè)時(shí)間。 但是顯著性水平的選擇很大地影響了檢測(cè)精確度和召回率。如何更加準(zhǔn)確地選擇合適的顯著性水平來(lái)增加模型的魯棒性,將成為接下來(lái)需要研究的問(wèn)題。未來(lái)的工作可以進(jìn)一步使用無(wú)監(jiān)督機(jī)器學(xué)習(xí)算法以及深度學(xué)習(xí)算法,同時(shí)測(cè)試更多數(shù)據(jù)集來(lái)擬合更多復(fù)雜環(huán)境下的異常檢測(cè),從而達(dá)到不依賴(lài)數(shù)據(jù)標(biāo)記完成分布式系統(tǒng)和平臺(tái)背景下的在線(xiàn)日志異常檢測(cè)的目的。3 算法實(shí)現(xiàn)
3.1 實(shí)驗(yàn)環(huán)境
3.2 實(shí)驗(yàn)室數(shù)據(jù)集

3.3 評(píng)估指標(biāo)
3.4 概念漂移識(shí)別
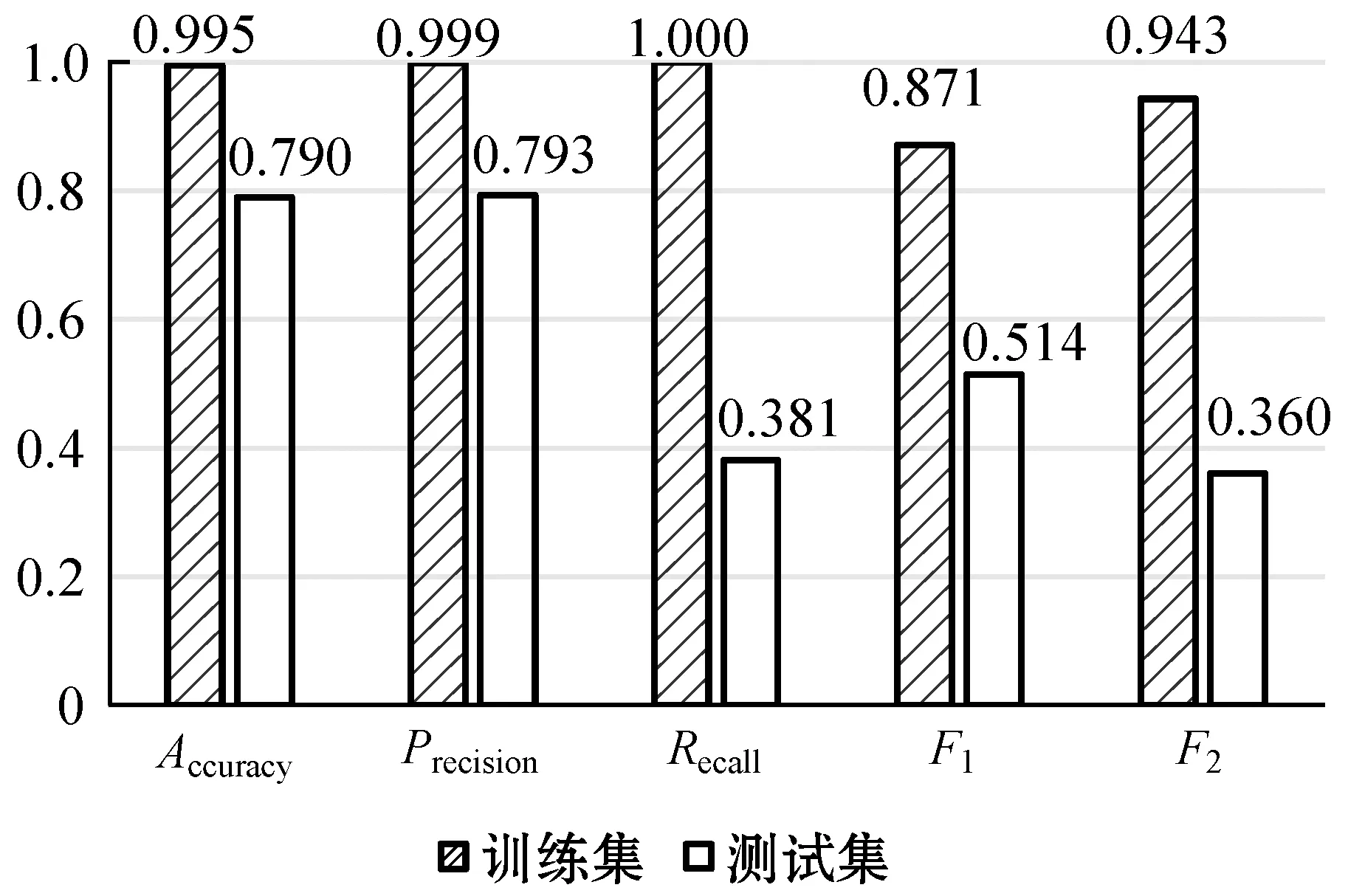
3.5 實(shí)驗(yàn)結(jié)果分析
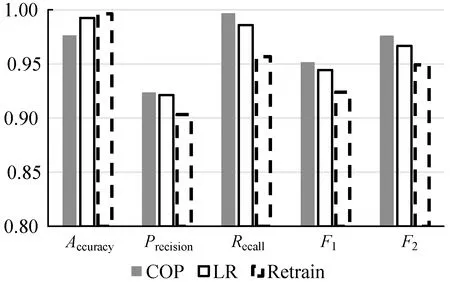
4 結(jié) 語(yǔ)
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
現(xiàn)代裝飾(2022年1期)2022-04-19 13:47:32
教學(xué)考試(高考物理)(2021年5期)2021-11-08 10:31:22
中醫(yī)眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
山東煤炭科技(2020年1期)2020-03-06 06:43:28
現(xiàn)代裝飾(2020年2期)2020-03-03 13:37:44
中學(xué)生數(shù)理化·高一版(2018年9期)2018-10-09 06:46:48
中學(xué)生數(shù)理化·高一版(2017年9期)2017-12-19 12:15:14
燕山大學(xué)學(xué)報(bào)(2015年4期)2015-12-25 02:19:49
高考金刊·理科版(2012年3期)2012-01-01 00:00:00
