基于LightGBM的LoRa室外指紋定位算法
2023-11-02 13:05:32張子凡龐成鑫冉浦東刁志峰
計算機(jī)應(yīng)用與軟件 2023年10期
關(guān)鍵詞:模型
張子凡 龐成鑫* 冉浦東 范 磊 刁志峰 張 軍
1(上海電力大學(xué)電子與信息工程學(xué)院 上海 201306)
2(同濟(jì)大學(xué)設(shè)計創(chuàng)意學(xué)院 上海 200092)
3(國家電網(wǎng)南瑞南京控制系統(tǒng)有限公司 江蘇 南京 210000)
0 引 言
物聯(lián)網(wǎng)技術(shù)的發(fā)展,在諸如物流檢測、生產(chǎn)監(jiān)控、河道檢測等領(lǐng)域內(nèi)產(chǎn)生了越來越多基于物聯(lián)網(wǎng)應(yīng)用的位置信息服務(wù)。LoRaWAN是低功耗廣域網(wǎng)(LPWAN)技術(shù)之一。它由Semtech開發(fā),是在Sub—GHz免許可頻段中使用最廣泛的LPWAN技術(shù)之一,具有低成本、低功耗和較長距離通信的優(yōu)點[1]。在學(xué)校校區(qū)和工業(yè)園區(qū)這樣若干平方公里的區(qū)域進(jìn)行企業(yè)級組網(wǎng)較為合適。例如學(xué)校和廠區(qū)中的貨物推車經(jīng)常在各個時段被不同的人員推到不同的地點,這通常導(dǎo)致重要的公有財產(chǎn)在使用的時候反而難以找到甚至導(dǎo)致推車的損壞及丟失。
為了解決這個問題,可以使用具有LoRaWAN技術(shù)的智能推車。智能推車既可對自身進(jìn)行定位幫助后勤人員尋找、使用和統(tǒng)計,又可從低功耗方面受益,因為沒有人希望找到并頻繁更換相當(dāng)數(shù)量智能推車的電池。
如今,國內(nèi)外學(xué)者在嘗試各種方法在LoRaWAN中實現(xiàn)精確定位。在較為廣闊的地段單純使用接收信號強(qiáng)度(Received Signal Strength Indicate,RSSI)模型,其原理是使用基站接收到的信號強(qiáng)度計算出信號的傳播損耗,再將其以理論與經(jīng)驗?zāi)P娃D(zhuǎn)化為距離,通過多個基站的重疊覆蓋范圍運(yùn)用樸素貝葉斯原理計算出節(jié)點的最大概率位置。計算估計位置時,誤差約為1 000~2 000 m[2]。Ha等[3]針對這個問題提出了使用指紋定位輔助ToA的定位系統(tǒng),利用LoRa信號在空間中的傳播時間來計算信號發(fā)射端與接收端的距離。其方法特點是比較少的基站數(shù)目同樣能夠進(jìn)行定位,但是這種算法在空曠地帶的精度很高而在城市范圍內(nèi)則精度欠佳(200 m左右)。Fargas等[4]使用TDoA方法來估計物體在農(nóng)村地區(qū)的位置。通過研究人員進(jìn)行的實驗驗證結(jié)果,但是該算法定位誤差在某些情況下超過1 km,誤差較大。即使在一些情況下將定位誤差縮小到100 m左右,但是算法框架中數(shù)據(jù)包的發(fā)送數(shù)量卻超過10 000,并且算法總處理時間較長。還有不少研究針對室內(nèi)定位和室外小范圍定位取得了不錯的定位精度[5-7],但是在基站與終端距離更遠(yuǎn)、地理環(huán)境更復(fù)雜、干擾更多樣的環(huán)境下精度還是不理想。
本文提出基于LightGBM的指紋定位算法進(jìn)行室外定位。通過在學(xué)校整個校區(qū)內(nèi)的實驗估算了在類似大小中應(yīng)用本文算法得出的定位準(zhǔn)確性和算法實時性。
1 定位算法
考慮到并非所有應(yīng)用都需要在整個LoRa的最大有效范圍內(nèi)定位,本文專注于一片廠區(qū)或者校園大小的區(qū)域,本文采用機(jī)器學(xué)習(xí)融合指紋定位的算法實現(xiàn)LoRa的室外定位。離線階段包括指紋庫的構(gòu)建以及LightGBM算法的參數(shù)訓(xùn)練。
1.1 指紋定位原理及指紋庫的創(chuàng)建
當(dāng)在空間范圍內(nèi)安置數(shù)目大于三個、位置較分散的網(wǎng)關(guān)后,區(qū)域內(nèi)終端與網(wǎng)關(guān)通信將在各個基站分別多組產(chǎn)生各自的RSSI值(rssigw1,rssigw2,…,rssigwn)。空間中干擾眾多,城市環(huán)境的高樓會嚴(yán)重影響附近被遮擋的樣本點。因此需要對數(shù)據(jù)進(jìn)行預(yù)處理。
本文的數(shù)據(jù)預(yù)處理分為三個部分,按照先后順序第一是對采集樣本中的空缺值進(jìn)行填補(bǔ)。實際使用網(wǎng)關(guān)的性能會存在差異。例如唐周益丹等[5]的論文中使用了靈敏度為-90 dBm的網(wǎng)關(guān),不能識別接收功率小于-90 dBm的LoRa信號,導(dǎo)致其難以接收長距離或是復(fù)雜環(huán)境下的終端信號。本文中實驗使用的中興ZTE-IWG200網(wǎng)關(guān)靈敏度為-140 dBm,對于實際信號強(qiáng)度弱于-140 dBm的信號沒有分辨能力。這個靈敏度已經(jīng)相當(dāng)高了,因此我們將某樣本點可能出現(xiàn)的RSSI空缺值由-140 dBm代替,也不會對結(jié)果產(chǎn)生較大影響。第二步是針對噪聲和環(huán)境的復(fù)雜性對同一地點的多組信號采用中值濾波。最后為了提高模型的泛化能力和收斂速度,將數(shù)據(jù)作歸一化處理。
數(shù)據(jù)在經(jīng)過預(yù)處理之后將構(gòu)成一組大于三維的向量,再附上某地本身的二維地理位置(xi,yi)便是指紋(rssigw1,rssigw2,…,rssigwn,xi,yi)。通過一定數(shù)量[8]的指紋可以構(gòu)建好離線指紋庫。表1展示了帶4個基站、共n個樣本點的指紋數(shù)據(jù)庫。

表1 指紋數(shù)據(jù)庫
最后的在線階段使用未知位置的指紋經(jīng)過數(shù)據(jù)預(yù)處理后作為離線算法輸入,最終算法模型計算出相應(yīng)的位置輸出,整個過程如圖1所示。

圖1 LoRa指紋定位過程
1.2 LightGBM算法
LightGBM是微軟于2016年開源發(fā)布的一種基于決策樹的梯度提升算法[9],其具有支持并行處理、訓(xùn)練速度快、準(zhǔn)確率高、內(nèi)存占用量小的特點,是基于梯度提升樹算法的優(yōu)化版本,目前在Kaggle等各種比賽上取得了很好的成績[10]。
介紹LightGBM前,首先要介紹梯度提升(Gradient Boosting)[11]。集成學(xué)習(xí)中的提升方法(Boosting)通過將若干個弱分類器通過組合,構(gòu)造出一個強(qiáng)分類器[12]。在此之上,梯度提升的核心思想通過計算負(fù)梯度近似計算殘差來逐步提升模型,它采用決策樹作為基分類器。
當(dāng)定義初始值f0(x)=0后,之后的第n步迭代的模型可以表示為:
fn(x)=fn-1(x)+T(x;Θn)
(1)
式中:fn-1(x)是當(dāng)前模型;T(x;Θn)所代表的殘差為模型優(yōu)化的關(guān)鍵參數(shù)。下一個基分類器的Θn可以通過式(2)確定。
(2)
梯度提升使用了模型負(fù)梯度值近似計算T(x;Θn),從而使之后的每次迭代減少了整體的損失函數(shù)值。當(dāng)訓(xùn)練第i個樣本時,該處的負(fù)梯度近似值為:
(3)
通過近似擬合來優(yōu)化損失函數(shù),在每次迭代中減少損失函數(shù)的值并形成新的基學(xué)習(xí)器,通過之前每次迭代產(chǎn)生的基學(xué)習(xí)器線性相加,最后可以得到強(qiáng)學(xué)習(xí)器。
LightGBM作為梯度提升算法的一種,最重要的是改進(jìn)采用了直方圖(Histogram)算法和帶有深度限制的按葉子生長(leaf-wise)算法。
直方圖算法通過把連續(xù)的浮點型特征離散化成K個整數(shù),從而構(gòu)造出一個寬度為K的直方圖。遍歷數(shù)據(jù)時,根據(jù)離散化后的值作為索引在直方圖中累積統(tǒng)計量,當(dāng)遍歷一次數(shù)據(jù)后,直方圖累積了需要的統(tǒng)計量,然后從直方圖的離散值中,遍歷出最優(yōu)的分割點。對比精確分割,雖然有一定準(zhǔn)確度降低。但由于弱分類器對準(zhǔn)確度要求不高,因此這種方法在梯度提升框架下影響不大且可以有效防止過擬合。
傳統(tǒng)的樹生長策略使用層生長(level-wise)策略,但很多葉子的分裂增益較低,沒有生長的必要。因此LightGBM使用葉子生長(leaf-wise)策略:每次從當(dāng)前所有葉子中具有最大delta loss的節(jié)點來生長,這種生長方式需要配合參數(shù)最大深度限制(max_depth)以及葉子數(shù)(number_leaves)使用,在保證高效的同時又限制了樹過深或者葉子過多,防止模型出現(xiàn)過擬合。改進(jìn)策略如圖2所示。

圖2 LightGBM樹生長策略改進(jìn)
1.3 基于LightGBM的LoRa指紋算法
將指紋庫訓(xùn)練數(shù)據(jù)(rssigw1,rssigw2,…,rssigwn)當(dāng)作特征輸入,以地理位置信息(xn,yn)作為標(biāo)簽輸出,使用LGBMRegressor做監(jiān)督學(xué)習(xí),通過K折交叉驗證(K-Fold Cross Validation)調(diào)參就訓(xùn)練出該區(qū)域的算法模型。K折交叉驗證是將總體樣本集分成k份,分別使用其中的(k-1)份作為訓(xùn)練集,剩下的1份作為交叉驗證集,最后取每次的平均誤差來評估這個模型。
最適合判斷平面地理位置信息準(zhǔn)確率的損失函數(shù)是歐氏距離,因此算法采用RMSE作為損失函數(shù),其公式定義如式(4)所示。
(4)
式中:f(Xi)表示i點處的算法預(yù)測值(xi,yi),而Yi代表真實的地理位置(xi,yi)。
值得注意的是,平面位置信息是二維數(shù)據(jù)。但是包括XGBoost、LightGBM在內(nèi),相當(dāng)多的深度學(xué)習(xí)流行算法使用回歸樹作為基分類器,導(dǎo)致其無法進(jìn)行多輸入多輸出(MIMO)。因此,本文使用多輸出回歸器(MultiOutputRegressor)對LGBMRegressor進(jìn)行包裝組合從而使得算法框架能夠訓(xùn)練并輸出多維標(biāo)簽,整個算法框架的流程如圖3所示。

圖3 算法框架流程
2 實驗及結(jié)果分析
本文于上海電力大學(xué)浦東校區(qū)內(nèi)部設(shè)置了約800 m×500 m的實驗區(qū)域,區(qū)域內(nèi)包括樓宇、人員、車輛等其他各種障礙物,對其他的場地也具有一定代表性。選取學(xué)校靠近邊角的4棟樓樓頂上安裝了ZTE-IWG200的LoRa網(wǎng)關(guān)如圖4所示。

圖4 網(wǎng)關(guān)3位置及移動測試終端
該網(wǎng)關(guān)在擴(kuò)頻因子固定為12的情況下靈敏度≤-140 dBm,保證了測試區(qū)域室外LoRa信號全覆蓋不斷流。測試人員通過手持ZTE-T20移動測試終端獲得測試區(qū)域內(nèi)各個樣本點的RSSI值。
LoRa通信終端參數(shù)設(shè)置如表2所示。

表2 通信終端參數(shù)設(shè)置
實驗總共設(shè)置了樣本點300個。這些點涵蓋了停車場、樓宇附近、田徑場、室外籃球場、人行道等各種位置,對校園室外環(huán)境有充分的代表性。根據(jù)訓(xùn)練集和測試集的樣本比例,我們設(shè)置了270個訓(xùn)練點以及30個測試點,樣本的劃分由train_test_split分配。圖5所示范圍為實驗區(qū)域、樣本點選取及其中一種劃分方法的示意。其中標(biāo)數(shù)字點位為LoRa網(wǎng)關(guān),其他實心點位為訓(xùn)練點或測試點。

圖5 實驗區(qū)域示意圖
在每一個測試點位,我們都將終端放于地面上測試,保證天線垂直向上。終端設(shè)置為每隔30 s與網(wǎng)關(guān)通信1次,在每點進(jìn)行5次采集方便進(jìn)行數(shù)據(jù)處理。為了保證參數(shù)的一致性,我們關(guān)閉了終端自適應(yīng)功能(ADR)以確保擴(kuò)頻因子(SF)數(shù)值穩(wěn)定為12。
為了方便分析和比較定位準(zhǔn)確度和實時性,本文引入了其他常用的三種算法模型。它們分別為kNN、BP神經(jīng)網(wǎng)絡(luò)、XGBoost各自的回歸模型。在二維平面上kNN通過計算測試樣本與訓(xùn)練樣本的歐氏距離,找出與測試樣本距離最接近的k個訓(xùn)練樣本,輸出訓(xùn)練樣本的平均位置。其特點就是原理簡單高效。對比實驗中kNN中的k值根據(jù)經(jīng)驗和Lemic等[8]的研究設(shè)置為4;BP神經(jīng)網(wǎng)絡(luò)是利用誤差反向傳播算法訓(xùn)練的多層前饋神經(jīng)網(wǎng)絡(luò),作為目前應(yīng)用最廣泛的神經(jīng)網(wǎng)絡(luò)模型,其特點是極強(qiáng)的泛化能力和適應(yīng)能力,在本實驗中BP神經(jīng)網(wǎng)絡(luò)原生支持多維向量輸出。對比實驗中BP神經(jīng)網(wǎng)絡(luò)設(shè)置中間層為4層;XGBoost同LightGBM一樣是梯度提升樹模型的改進(jìn)版本,相比傳統(tǒng)梯度提升樹,它將損失函數(shù)從平方損失推廣到二階可導(dǎo)的損失同時加入了L2正則化項,其影響力已經(jīng)被許多機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘的比賽所廣泛認(rèn)可[13]。
上面的四種算法的對比測試一共分為10組,每組測試都采用train_test_split的方法將300組樣本分別按照test_size等于0.1的分法分為270個訓(xùn)練集合和30個測試集。為確保每組四個算法間訓(xùn)練集測試集樣本相同并且組與組之間不同,我們在不同組之間使用了不同的random_state種子使劃分方法不一,測試結(jié)果如圖6所示。
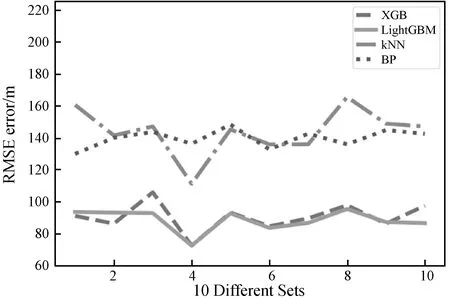
圖6 四種算法誤差結(jié)果對比
統(tǒng)計各個算法在10組樣本上誤差平均值如表3所示。

表3 各算法RMSE誤差平均值 單位:m
其中LightGBM在最好的第4組平均定位精度為72.33 m,在最差的第8組平均精度為95.25 m,10組總共平均精度為90.29 m。
同時,針對指紋定位可能存在的線下指紋數(shù)量大、訓(xùn)練復(fù)雜耗時、線上定位對實時性要求高的特點,我們利用循環(huán)結(jié)構(gòu)模擬了線上同時100個終端請求位置計算的訓(xùn)練時間以及線下一次數(shù)據(jù)集的訓(xùn)練時間。公平起見,四個算法統(tǒng)一使用CPU版本。平臺CPU為Intel Core i7-9750H處理器,操作系統(tǒng)為Windows 10 64位家庭版。
線下訓(xùn)練四種算法的平均訓(xùn)練時間如表4所示。

表4 算法平均訓(xùn)練時間 單位:ms
可以清楚地看出kNN訓(xùn)練效率遠(yuǎn)超另外三種算法。而LightGBM與其他算法相比效率提高了不少,但還是在一個數(shù)量級。
線上定位時間如圖7所示。

圖7 四種算法計算時間對比
通過上面的數(shù)據(jù)我們可以清楚地發(fā)現(xiàn)此算法的位置誤差,相比kNN和BP神經(jīng)網(wǎng)絡(luò),分別縮小了37.2%和35.3%,相比XGBoost縮小了2.4%,相差不大。而根據(jù)圖7的線上定位時間數(shù)據(jù),在實時位置計算上該算法相較于XGBoost效率提升了350%,與BP神經(jīng)網(wǎng)絡(luò)相差不大,遜于kNN。
綜合上述結(jié)果,基于LightGBM的LoRa室外定位是有效的,在較為準(zhǔn)確地預(yù)計實際地點的同時通過采用直方圖算法,與XGBoost相比效率得到了很大的提高。因此兼顧了優(yōu)秀的實時性。尤其考慮到LightGBM原生支持并行計算并且有更高的內(nèi)存使用效率,將來對有更多樣本數(shù)據(jù)的訓(xùn)練相比XGBoost,線下訓(xùn)練的效率和線上定位的實時性會更加明顯。
3 結(jié) 語
隨著低功耗物聯(lián)網(wǎng)的發(fā)展,應(yīng)用LoRa或者ZETA、SigFox、NB-IoT的服務(wù)也會越來越多,同時對終端定位的需求越發(fā)強(qiáng)烈。本文針對LoRa使用傳統(tǒng)RSSI傳播模型在室外定位結(jié)果較為不準(zhǔn)確的情況,提出基于LightGBM的LoRa室外指紋定位算法,在整片校園環(huán)境中精確度達(dá)到了90 m左右,相比傳統(tǒng)定位方法準(zhǔn)確度有提高的同時提高了計算效率。下一步可以通過以下幾個方面來對進(jìn)一步優(yōu)化:(1) 空間中的定位需求可能不是相等的,一些熱門位置應(yīng)該分配更多樣本點進(jìn)行訓(xùn)練和測試;(2) 樣本點數(shù)量相對Wi-Fi這種協(xié)議較少,尚不能發(fā)揮機(jī)器學(xué)習(xí)甚至深度學(xué)習(xí)的潛力;(3) 實驗定位設(shè)備統(tǒng)一且規(guī)格較高,質(zhì)量稍差的標(biāo)簽可能不具備本實驗路測設(shè)備的發(fā)射功率從而影響基站RSSI的獲取。而這些缺陷也是本文后續(xù)工作的重點研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
