基于多級(jí)殘差注意力的X-ray圖像超分辨率重建
2023-11-02 12:36:14張建波劉佳琦
計(jì)算機(jī)應(yīng)用與軟件 2023年10期
張建波 楊 璐 劉佳琦 張 禎
1(天津理工大學(xué)天津市先進(jìn)機(jī)電系統(tǒng)設(shè)計(jì)與智能控制重點(diǎn)實(shí)驗(yàn)室 天津 300384)
2(機(jī)電工程國(guó)家級(jí)實(shí)驗(yàn)教學(xué)示范中心(天津理工大學(xué)) 天津 300384)
3(天津醫(yī)科大學(xué)總醫(yī)院重癥醫(yī)學(xué)科 天津 300052)
0 引 言
醫(yī)學(xué)影像作為臨床醫(yī)學(xué)中發(fā)展最迅速的學(xué)科之一,從最初的X-ray到CT、MRI、CR等,醫(yī)學(xué)影像設(shè)備及技術(shù)在不斷地更新?lián)Q代。由于我國(guó)醫(yī)療資源分布不均衡,多數(shù)基層醫(yī)院及鄉(xiāng)鎮(zhèn)醫(yī)院只具備X-ray影像設(shè)備,通常情況下均使用X-ray來完成日常體檢以及各種肺部疾病的前期檢查。但是在X-ray圖像采集過程中,受到成像設(shè)備以及成像參數(shù)(輻射量)的影響,獲取的圖像分辨率往往有限。通過更新硬件設(shè)備來提升圖像分辨率不僅成本高、難度大,而且實(shí)用性不強(qiáng)。而超分辨率重建技術(shù)可以有效提升圖像質(zhì)量,使醫(yī)生能夠更清晰地觀察到相關(guān)病灶的細(xì)節(jié)信息,為相應(yīng)的診斷及診療方案的制定提供便利。
超分辨率重建技術(shù)[1-3]旨在通過一幅或者多幅低分辨率的圖像恢復(fù)出高分辨率圖像[4-6],在醫(yī)學(xué)影像、視頻復(fù)原、軍事偵察等多個(gè)領(lǐng)域已得到了廣泛的應(yīng)用。現(xiàn)有超分辨率方法主要分為基于插值[7]、基于重建[8]和基于學(xué)習(xí)[9]的方法。最常見的基于插值的超分辨率重建方法包括雙線性插值和雙三次線性插值,但經(jīng)過插值獲得的超分辨率圖像往往過于平滑,容易在邊緣處理上因丟失高頻信息而出現(xiàn)細(xì)節(jié)模糊以及鋸齒問題。基于重建的方法通常利用多幀圖像及先驗(yàn)知識(shí)約束解空間進(jìn)而完成圖像的超分辨率重建,相對(duì)于插值方法的重建效果有一定改善,但是對(duì)配準(zhǔn)算法和先驗(yàn)知識(shí)依賴性過高。通過學(xué)習(xí)高低分辨率圖像之間非線性映射關(guān)系完成圖像重建是目前主流的基于學(xué)習(xí)的重建方法,常見方法有Yang等[10]提出的稀疏編碼方法、Chang等[11]提出的鄰域嵌入法、Timofte等[12]提出的鄰域回歸法(ANR)等。Dong等[13]首次利用卷積構(gòu)造出包含特征提取、非線性映射、重建模塊的卷積神經(jīng)網(wǎng)絡(luò)SRCNN實(shí)現(xiàn)高效的圖像的超分辨率重建,其計(jì)算復(fù)雜度低,且能夠在保證高質(zhì)量圖像的同時(shí)完成圖像快速重建。自SRCNN提出后,基于CNN的圖像超分辨率算法逐漸成為主流圖像重建方法。隨著神經(jīng)網(wǎng)絡(luò)的不斷深入研究,學(xué)者們陸續(xù)提出了FSRCNN[14]、VDSR[15]、D-DBPN[16]等超分辨率重建算法,并在自然圖像超分辨率重建上取得了較好的效果。
雖然深度學(xué)習(xí)與超分辨率的結(jié)合在自然圖像上獲得了良好的重建效果[17],但是在語(yǔ)義簡(jiǎn)單且結(jié)構(gòu)較為固定的肺部X-ray醫(yī)學(xué)圖像重建上仍存在特征提取時(shí)大量高頻信息的丟失導(dǎo)致的重建圖像邊緣不清晰以及細(xì)節(jié)模糊等問題。針對(duì)上述問題,提出一種基于多級(jí)殘差通道注意力的X-ray圖像超分辨率重建方法。主要貢獻(xiàn)歸納如下:
(1) 提出一種超分辨率重建方法MRAN(Multistage Residual Attention Network)。以殘差神經(jīng)網(wǎng)絡(luò)為基礎(chǔ)框架,去除原殘差塊中批歸一化層并嵌入通道注意力機(jī)制,構(gòu)造模型基本塊,自適應(yīng)地校正各信道的特征響應(yīng),強(qiáng)化肺部器官圖像的紋理細(xì)節(jié)特征;利用多級(jí)殘差學(xué)習(xí)逐步簡(jiǎn)化信息流,加速網(wǎng)絡(luò)訓(xùn)練;設(shè)計(jì)多尺度融合模塊進(jìn)行特征提取,進(jìn)而獲取圖像更加完整的結(jié)構(gòu)信息;使用Bicubic生成圖像與亞像素卷積圖像融合,彌補(bǔ)信息提取時(shí)造成的特征損失,完成最終圖像的超分辨率重建。
(2) 將提出的MRAN應(yīng)用于肺部X-ray圖像的超分辨率重建,實(shí)驗(yàn)結(jié)果表明,該方法取得了更高的PSNR和SSIM值,并且重建出的肺部圖像邊緣清晰、紋理豐富,更接近真實(shí)圖像。
1 相關(guān)工作
1.1 殘差學(xué)習(xí)
隨著CNN的不斷發(fā)展,學(xué)者們發(fā)現(xiàn)網(wǎng)絡(luò)層次是影響網(wǎng)絡(luò)性能的重要因素之一,網(wǎng)絡(luò)的深度越深,模型的性能就會(huì)越好。因此學(xué)者們對(duì)于網(wǎng)絡(luò)的設(shè)計(jì)更趨向于不斷加深網(wǎng)絡(luò)層次,以獲取更高的評(píng)價(jià)指標(biāo)值。這不僅加大了網(wǎng)絡(luò)計(jì)算量和內(nèi)存開銷,還帶來了梯度消失以及模型退化等問題。針對(duì)上述問題,He等[18]提出了ResNet模型,并且在模型中提出了殘差學(xué)習(xí)的思想,通過添加跳躍連接(Skip Connection)的方式,保證信息實(shí)現(xiàn)更好的回傳,加快網(wǎng)絡(luò)的收斂速度。殘差學(xué)習(xí)結(jié)構(gòu)如圖1所示。

圖1 殘差學(xué)習(xí)結(jié)構(gòu)
殘差學(xué)習(xí)將原先學(xué)習(xí)恒等映射φ(x)=x的任務(wù)轉(zhuǎn)化為學(xué)習(xí)輸入與輸出之間的殘差F(x)。相對(duì)于擬合恒等變化關(guān)系,擬合殘差更加容易,這可以使學(xué)習(xí)任務(wù)變得更加輕松。在網(wǎng)絡(luò)的反向傳播中,通過添加跳躍連接使得各網(wǎng)絡(luò)層之間梯度信息能夠更好地傳遞,有效地緩解了梯度消失和網(wǎng)絡(luò)退化問題。本文將進(jìn)一步改進(jìn)原始?xì)埐顗K,以殘差學(xué)習(xí)方式簡(jiǎn)化學(xué)習(xí)過程,并以多級(jí)嵌套方式逐步添加跳躍連接,進(jìn)一步簡(jiǎn)化信息流,加速網(wǎng)絡(luò)的收斂速度。
1.2 通道注意力機(jī)制
近年來,由于注意力機(jī)制在建模全局依賴關(guān)系[19]以及降低無關(guān)圖像域特征信息[20]方面表現(xiàn)出的良好性能,被廣泛用于深度神經(jīng)網(wǎng)絡(luò)之中。通道注意力機(jī)制通過使用不同的激勵(lì)權(quán)重對(duì)各個(gè)通道進(jìn)行激勵(lì),使網(wǎng)絡(luò)更加關(guān)注于高頻信道特征,達(dá)到加速網(wǎng)絡(luò)收斂和提升網(wǎng)絡(luò)性能的目的。Hu等[21]提出的SENet表明在神經(jīng)網(wǎng)絡(luò)中,不同通道的卷積核所提取到的特征圖是不同的,其對(duì)于超分辨率重建中恢復(fù)高頻細(xì)節(jié)信息的重要程度也是不一樣的。若在網(wǎng)絡(luò)中同等處理各信道特征,會(huì)導(dǎo)致網(wǎng)絡(luò)在處理高低頻信息時(shí)缺乏靈活性,難以充分利用上下文信息進(jìn)行有效的特征學(xué)習(xí)。
如圖2所示,通道注意力機(jī)制主要由擠壓、激勵(lì)、注意力三部分組成。該模塊首先對(duì)輸入圖像進(jìn)行全局平均池化,完成各通道像素值的壓縮,獲取逐通道統(tǒng)計(jì)z∈RC,然后通過兩個(gè)卷積層學(xué)習(xí)各個(gè)通道的激勵(lì)權(quán)重,最后將激勵(lì)權(quán)重與各通道像素進(jìn)行Hadamard乘積實(shí)現(xiàn)對(duì)不同特征通道的調(diào)節(jié),得到最終輸出。具體實(shí)現(xiàn)如下:

圖2 通道注意力機(jī)制
(1)
S=σ(W2δ(W1z))
(2)
Uc=Sc×Uc
(3)
式中:zc為z的第c個(gè)元素;Hsq表示特征壓縮操作;uc(i,j)為特征圖的第c個(gè)通道(i,j)位置的像素值;σ和δ分別表示Sigmoid和ReLU激活函數(shù);W1和W2分別為激勵(lì)權(quán)重。網(wǎng)絡(luò)通過通道注意機(jī)制自適應(yīng)的校正各個(gè)信道的特征響應(yīng),強(qiáng)化高頻信息通道,利于超分辨率圖像邊緣細(xì)節(jié)的重建。對(duì)于肺部X-ray圖像而言,其紋理細(xì)節(jié)特征對(duì)疾病的分類診斷尤為重要,因此本文將通道注意力機(jī)制嵌入到殘差塊中構(gòu)成網(wǎng)絡(luò)基本塊,在保證強(qiáng)化高頻信道特征的同時(shí),加速網(wǎng)絡(luò)收斂,進(jìn)一步提高網(wǎng)絡(luò)的性能。
2 方法設(shè)計(jì)
本文設(shè)計(jì)的X-ray圖像超分辨率重建網(wǎng)絡(luò)MRAN主要由三部分構(gòu)成:特征提取模塊、基于特征融合的通道注意力信息提取模塊、重建模塊。網(wǎng)絡(luò)的整體架構(gòu)如圖3所示。

圖3 MRAN網(wǎng)絡(luò)整體結(jié)構(gòu)
2.1 特征提取模塊
特征提取模塊用于從ILR中提取特征,該模塊由雙層3×3卷積構(gòu)成,特征維度均為64。ILR為原始輸入,由IHR經(jīng)圖像退化得到,特征F-1、F0的提取過程通過式(4)-式(5)實(shí)現(xiàn)。
F-1=Hconv(ILR)=σ(W-1×ILR+B-1)
(4)
F0=Hconv(F-1)=σ(W0×F-1+B0)
(5)
式中:W表示權(quán)重矩陣;B表示偏置項(xiàng);σ表示非線性ReLU激活函數(shù)。相較于SRResnet以及EDSR等模型使用單層卷積完成特征提取,雙層卷積提取的特征更加精細(xì),能較好地抑制卷積層在進(jìn)行特征提取時(shí)特征的丟失問題。
2.2 基于特征融合的通道注意力信息提取模塊
信息提取模塊將對(duì)特征提取模塊傳入的特征圖進(jìn)行深度特征提取和殘差信息學(xué)習(xí),該模塊由多尺度特征融合模塊和多級(jí)殘差注意力基本塊構(gòu)成,FLF的提取過程由式(6)實(shí)現(xiàn)。
FLF=HDF(F0)
(6)
式中:F0為特征提取塊提取到的特征;HDF為信息提取操作。經(jīng)過信息提取模塊進(jìn)行信息充分提取后,獲取的信息FLF經(jīng)過全局殘差學(xué)習(xí)得到特征FGF,FGF將用于最終高分辨率圖像的重建。
2.2.1多尺度特征融合模塊
在深層提取圖像特征的過程中,各種特征信息往往是不同尺度的,但目前多數(shù)網(wǎng)絡(luò)都是用單一卷積核來實(shí)現(xiàn)特征提取,這往往會(huì)導(dǎo)致信息提取過程中結(jié)構(gòu)信息的缺失。本文對(duì)Inception結(jié)構(gòu)[22]進(jìn)行改進(jìn),使用不同大小的卷積核通過并行路徑完成特征提取后進(jìn)行特征融合,以此來獲取圖像更加完整的結(jié)構(gòu)信息。本文設(shè)計(jì)的多尺度特征融合模塊如圖4所示。
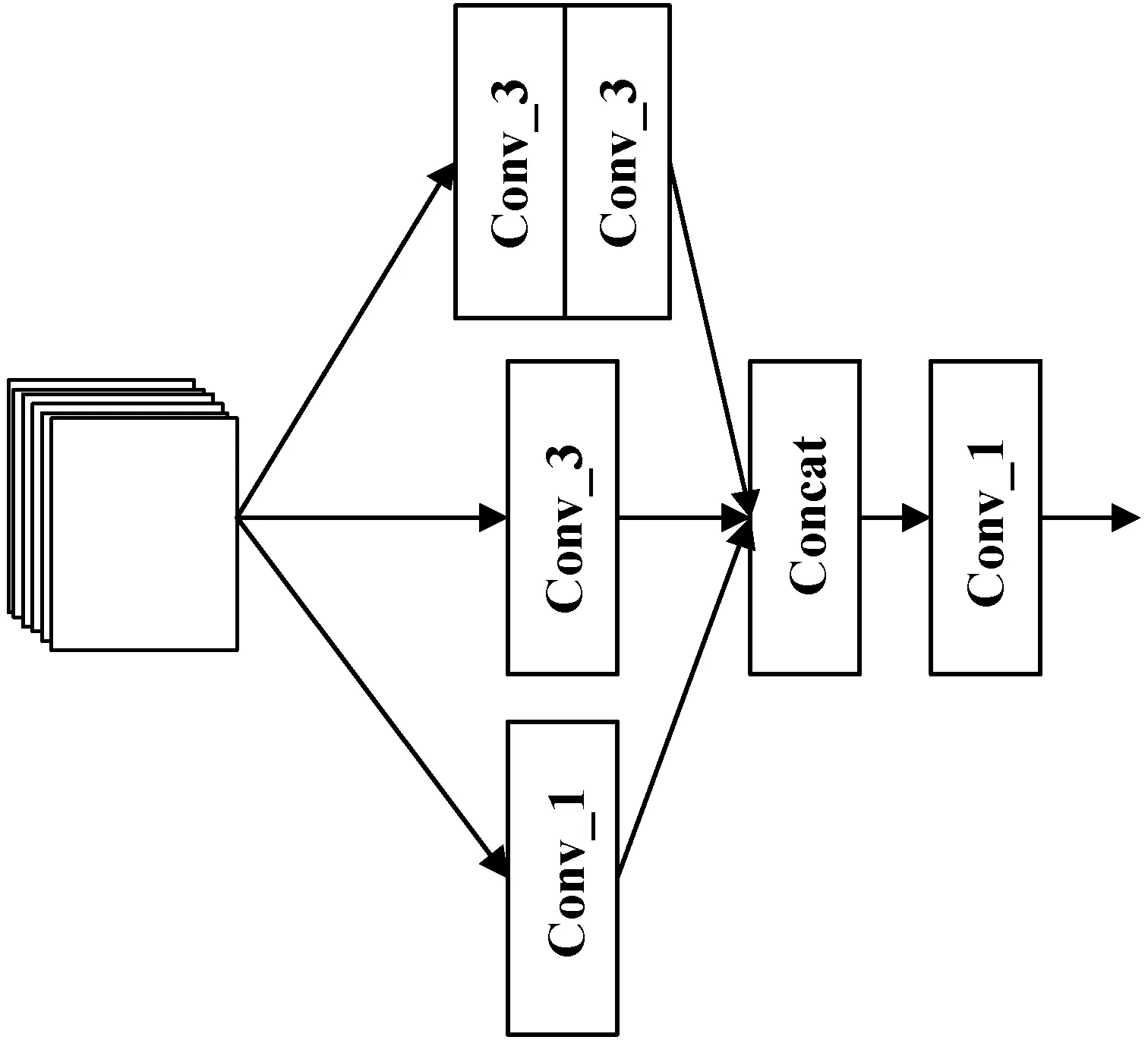
圖4 多尺度信息融合模塊
在多尺度信息融合模塊中,對(duì)于上層輸出的特征,通過三種不同的卷積路線進(jìn)行特征提取,其中以兩個(gè)3×3卷積核替代5×5卷積核,在保證感受野相同的前提下,減少模型參數(shù)量。各卷積路線的輸出特征維數(shù)分別為32、48、32,然后使用concat層進(jìn)行特征信息融合。concat層按通道維度對(duì)各卷積路線的輸出特征進(jìn)行疊加,例如上述三條卷積路線共包含112個(gè)卷積層,則經(jīng)過concat層后的輸出可由式(7)獲得。
(7)
式中:W表示權(quán)重矩陣;B表示偏置項(xiàng);σ表示非線性ReLU激活函數(shù),經(jīng)過拼接后輸出的特征圖通道維數(shù)變?yōu)?12維。最后,在保持concat層所有特征的前提下,使用1×1卷積核完成特征降維,從而縮減多尺度特征圖的數(shù)量,進(jìn)一步減少網(wǎng)絡(luò)的參數(shù)數(shù)量。
2.2.2基于殘差注意力機(jī)制的基本塊
基礎(chǔ)塊是網(wǎng)絡(luò)架構(gòu)中的基本組成單元,也是圖像超分辨率重建任務(wù)中重要的非線性特征映射模塊,它直接影響圖像的重建效果。本文以殘差網(wǎng)絡(luò)為基礎(chǔ)實(shí)現(xiàn)網(wǎng)絡(luò)架構(gòu)搭建,刪減原殘差塊中影響高頻信息表達(dá)的批歸一化層,嵌入利于高頻信息提取的注意力機(jī)制模塊,完成模型基本塊RCAB(Residual Channel Attention Block)的構(gòu)建。模型基本塊RCAB如圖5所示。

圖5 基本塊RCAB
RCAB基本塊中將上層輸入使用兩個(gè)連續(xù)的3×3卷積核進(jìn)行特征信息提取后,輸入到通道注意力模塊中,對(duì)各個(gè)通道進(jìn)行不同的權(quán)重激勵(lì),獲取特征Fd,LF。基礎(chǔ)塊通過通道注意力機(jī)制使網(wǎng)絡(luò)強(qiáng)化高頻信道特征,有利于圖像細(xì)節(jié)的重建。使用殘差結(jié)構(gòu)完成實(shí)現(xiàn)Fd,LF與Fd-1的連接以獲取輸出Fd,進(jìn)一步改善信息流,提升了網(wǎng)絡(luò)表達(dá)能力。Fd獲取過程由式(8)實(shí)現(xiàn)。
Fd=Fd-1+Fd,LF
(8)
如圖3中虛線框所示,將6個(gè)RCAB基本塊以多級(jí)嵌套方式進(jìn)行殘差連接,構(gòu)成一個(gè)中級(jí)殘差注意力模塊。每個(gè)RCAB基本塊的輸出都將作為后續(xù)基本塊的輸入,并且后續(xù)RCAB基本塊通過多級(jí)殘差連接實(shí)現(xiàn)圖像特征的復(fù)用,在每個(gè)中級(jí)殘差注意力模塊末端添加卷積層,進(jìn)一步實(shí)現(xiàn)各級(jí)特征融合后的特征整合。網(wǎng)絡(luò)中共設(shè)置了10個(gè)中級(jí)模塊,每個(gè)中級(jí)塊的輸出將通過跳躍連接進(jìn)行有效前傳,使得所有塊的輸出都得到充分利用。
考慮到輸入圖像與輸出圖像具有較高的相似性,引入全局殘差學(xué)習(xí)來解決網(wǎng)絡(luò)難以收斂問題。各個(gè)中級(jí)模塊的輸出特征最終融合后使用卷積層進(jìn)行特征整合,并與全局特征進(jìn)行殘差學(xué)習(xí),減少網(wǎng)絡(luò)冗余,進(jìn)而獲得用于最終重建的特征FGF。
2.3 重建模塊
重建模塊利用網(wǎng)絡(luò)學(xué)習(xí)到的各層次特征,重建生成最終的高分辨率圖像ISR。首先,使用Upsampler模塊實(shí)現(xiàn)低分辨率到高分辨率的非線性映射,完成高分辨率圖像Frec1的獲取。本文的Upsampler模塊是由亞像素卷積和3×3卷積層構(gòu)成,通過從低分辨率到高分辨率的非線性映射實(shí)現(xiàn)圖像超分辨率的重建。網(wǎng)絡(luò)在進(jìn)行特征學(xué)習(xí)時(shí)不可避免地存在一定程度上的特征損失。為彌補(bǔ)該損失,本文采用雙三次線性插值方法對(duì)原始圖片進(jìn)行插值,生成高分辨率圖像Frec2。最后,將所獲得的兩幅圖片進(jìn)行像素加法,獲得最終的輸出ISR。
2.4 損失函數(shù)
在MRAN模型訓(xùn)練中,優(yōu)化網(wǎng)絡(luò)的損失函數(shù)是整個(gè)網(wǎng)絡(luò)模型的調(diào)度中心。本文采用均方誤差(MSE)作為衡量模型輸出的ISR與真實(shí)圖像IHR之間差異的損失函數(shù)[23],如式(9)所示。
(9)
式中:L(θ)代表均方誤差損失;F(Yi;θ)和Xi分別代表重建后的高分辨率圖像ISR和原始高分辨率圖像IHR;n代表訓(xùn)練樣本總數(shù)目。在網(wǎng)絡(luò)訓(xùn)練中,通過不斷計(jì)算ISR和IHR之間差異,持續(xù)更新各層網(wǎng)絡(luò)參數(shù)θ=(W1,W2,…,B1,B2,B3,…),最終獲取最佳的網(wǎng)絡(luò)參數(shù)模型。
3 實(shí)驗(yàn)分析與結(jié)果
本文使用Ubuntu系統(tǒng),并在該系統(tǒng)下利用PyTorch框架進(jìn)行模型搭建。服務(wù)器配置為NVIDA RTX 2080 Ti×2,軟件配置為Cuda 9.2。在網(wǎng)絡(luò)訓(xùn)練中,設(shè)置batch_size為8,初始學(xué)習(xí)率為1E-4,采用Adam算法[24]作為模型優(yōu)化算法,設(shè)置每200個(gè)epoch時(shí)將學(xué)習(xí)率減半,保證模型在逐步迭代中達(dá)到最優(yōu)。
3.1 數(shù)據(jù)集
使用兩種不同的數(shù)據(jù)集進(jìn)行實(shí)驗(yàn)仿真。第一種是美國(guó)蒙哥馬利縣公開的Montgomery County X-ray Set數(shù)據(jù)集,從中選取120幅紋理豐富、清晰度高的X-ray圖像作為訓(xùn)練集的HR圖像,使用圖像退化獲取LR-HR圖像對(duì)用于網(wǎng)絡(luò)訓(xùn)練,將剩余的18幅圖像作為測(cè)試集,用于模型重建效果的測(cè)試。第二種是由NIH發(fā)布的Chest X-ray14數(shù)據(jù)集,包含十四種常見肺部疾病的X-ray圖像,共計(jì)112 120幅。從中隨機(jī)選取520幅圖像,并以不同分辨率的圖像對(duì)各個(gè)模型的重建效果進(jìn)行測(cè)試,以此來充分驗(yàn)證模型的魯棒性與泛化能力。
在模型訓(xùn)練中,為防止因訓(xùn)練數(shù)據(jù)集圖像較少可能帶來的模型過擬合問題,采用三種方法對(duì)訓(xùn)練集進(jìn)行數(shù)據(jù)增強(qiáng):(1) 圖像旋轉(zhuǎn),旋轉(zhuǎn)角度為90°、270°;(2) 圖像翻轉(zhuǎn),將圖像進(jìn)行上下翻轉(zhuǎn)和左右翻轉(zhuǎn);(3) 圖片縮放,縮放比例為0.9、0.7。
3.2 量化指標(biāo)
本文采用峰值信噪比(PSNR)和結(jié)構(gòu)相似度(SSIM)作為量化指標(biāo),來客觀衡量各圖像超分辨率方法的重建性能。其中,PSNR是一種最常見的基于像素間誤差靈敏度的圖像客觀評(píng)價(jià)指標(biāo)[25]。而SSIM將失真建模為亮度、對(duì)比度、結(jié)構(gòu)的組合,進(jìn)而客觀衡量ISR和IHR的相似度。本文采用這兩種指標(biāo)(式(11)-式(12))在YCbCr顏色空間的Y通道上評(píng)估模型重建圖像的質(zhì)量。
(10)
(11)
(12)
式中:MSE代表均方誤差;H和W分別代表圖像的高和寬;μ和σ分別代表兩幅圖像的均值與方差。PSNR與SSIM可以客觀反映出重建圖像相對(duì)于原始圖像的失真程度,其數(shù)值越大,表明失真越小。通過計(jì)算各個(gè)模型在同一測(cè)試集上的平均評(píng)價(jià)指標(biāo)值,可以客觀地衡量各網(wǎng)絡(luò)模型的超分辨率重建性能。
3.3 實(shí)驗(yàn)對(duì)比
為更好地評(píng)估網(wǎng)絡(luò)性能,在同一臺(tái)服務(wù)器上使用×2的拉伸倍數(shù),將本文設(shè)計(jì)的MRAN網(wǎng)絡(luò)與Bicubic、SRCNN、VDSR、LapSRN四種超分辨率重建方法進(jìn)行比較。SRCNN具有三層卷積層網(wǎng)絡(luò)結(jié)構(gòu),以雙三次線性插值圖像作為網(wǎng)絡(luò)輸入;VDSR在結(jié)合殘差學(xué)習(xí)思想基礎(chǔ)上,將網(wǎng)絡(luò)層次增加至20層;LapSRN模型在網(wǎng)絡(luò)中融入了拉普拉斯金字塔模型的思想,以搭建的24層網(wǎng)絡(luò)實(shí)現(xiàn)圖像的超分辨率重建。在對(duì)比實(shí)驗(yàn)的實(shí)現(xiàn)過程中,使用MATLAB interp2函數(shù)實(shí)現(xiàn)Bicubic方法,其余對(duì)比模型均根據(jù)相關(guān)作者的開源代碼實(shí)現(xiàn)。
本文提出的MRAN模型相對(duì)于SRCNN以及VDSR等算法具有更深的網(wǎng)絡(luò)層次,模型的復(fù)雜度更高。在少量增加模型參數(shù)的同時(shí),使得模型性能得到較大的改善。MRAN模型可以實(shí)現(xiàn)端到端的模型訓(xùn)練,完成圖像的快速重建,完全滿足醫(yī)學(xué)圖像超分辨率重建對(duì)速度的要求。圖6展示了網(wǎng)絡(luò)訓(xùn)練過程中各模型的量化指標(biāo)增長(zhǎng)曲線,MRAN模型在逐步迭代訓(xùn)練過程中,能夠在最短的時(shí)間內(nèi)實(shí)現(xiàn)模型收斂,并且獲得了更高的PSNR量化指標(biāo)值。

圖6 各模型的PSNR值隨迭代次數(shù)增長(zhǎng)曲線
表1展示了各模型在不同測(cè)試數(shù)據(jù)集上的平均量化指標(biāo)值。可以看出,傳統(tǒng)方法Bicubic重建出的超分辨率圖像的評(píng)價(jià)指標(biāo)值最低,而其余對(duì)比模型較于Bicubic都有了不同程度的提高。值得注意的是,本文提出的MRAN模型在PSNR和SSIM兩個(gè)量化指標(biāo)上,均超過了幾種對(duì)比的超分辨率模型。充分說明,MRAN模型性能相較于其他模型有了一定的提升。

表1 不同測(cè)試集上各模型的平均量化指標(biāo)值
為更加直觀地說明各模型的超分辨率重建效果,使用各個(gè)模型對(duì)Montgomery County X-ray Set數(shù)據(jù)集中同一圖像進(jìn)行超分辨率重建,重建效果如圖7所示。可以看出,圖7(b)的重建效果最為模糊,而圖7(c)雖然在一定程度上提升了模型的清晰度,但是邊緣輪廓仍然不清晰,對(duì)于圖像細(xì)節(jié)的重建效果不佳。圖7(d)和圖7(e)分別為VDSR和LapSRN兩種算法重建出的高分辨率圖像,其整體重建效果較為清晰,在邊緣細(xì)節(jié)上也展現(xiàn)了良好的連續(xù)性,但是可能出現(xiàn)棋盤格子偽影現(xiàn)象。圖像的超分辨率重建效果不佳,很大程度上是由于圖像重建過程中對(duì)高頻信息利用不足導(dǎo)致的。本文提出的MRAN算法模型能有效地提取LR空間中更多的有用特征,增強(qiáng)網(wǎng)絡(luò)對(duì)高頻信道的關(guān)注度,進(jìn)而實(shí)現(xiàn)更好的重建效果。圖7(f)是MRAN模型重建出的高分辨率圖像,優(yōu)于其他網(wǎng)絡(luò)的重建圖像,具有清晰的邊緣和紋理細(xì)節(jié),更加逼近真實(shí)的高分辨率圖像。
圖8和圖9展示了各個(gè)模型在Chest X-ray14測(cè)試集上的重建效果。可以看出,本文提出的MRAN模型在不同像素的圖像上獲得了與Montgomery County X-ray Set測(cè)試集相近的重建效果。并且,重建效果均優(yōu)于其他模型,更加接近真實(shí)的高分辨率圖像,充分證明MRAN模型具有較高的魯棒性和泛化能力。

(a) Original (b) Bicubic (c) SRCNN

(a) Original (b) Bicubic (c) SRCNN
4 結(jié) 語(yǔ)
本文提出一種基于多級(jí)殘差注意力的X-ray圖像超分辨率算法模型MRAN。通過使用注意力機(jī)制來改進(jìn)原始?xì)埐顗K,構(gòu)建模型基本塊RCAB,在優(yōu)化模型收斂的同時(shí),使網(wǎng)絡(luò)更加關(guān)注充滿邊緣細(xì)節(jié)的高頻信道特征,進(jìn)一步提升網(wǎng)絡(luò)對(duì)于圖像邊緣細(xì)節(jié)的重建效果;使用多尺度特征融合模塊,將不同卷積核提取的多尺度特征進(jìn)行融合,更好地實(shí)現(xiàn)圖像結(jié)構(gòu)信息的完整提取;以多級(jí)嵌套方式進(jìn)行殘差學(xué)習(xí),并使用卷積層對(duì)各基本塊輸出進(jìn)行特征調(diào)和,加速網(wǎng)絡(luò)收斂,進(jìn)一步提升網(wǎng)絡(luò)性能;將亞像素卷積圖像和Bicubic生成圖像進(jìn)行融合,彌補(bǔ)特征提取過程中的特征損失,最終完成圖像的超分辨率重建。實(shí)驗(yàn)證明,本文設(shè)計(jì)的模型在PSNR和SSIM上都有較大程度的提升,且重建出的圖像細(xì)節(jié)更加清晰豐富,能夠更好地幫助醫(yī)生發(fā)現(xiàn)病變部位,從而提升診斷準(zhǔn)確率。在未來的工作中,將針對(duì)圖像的多尺度超分辨率重建進(jìn)行研究。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
