基于文本融合特征的突發(fā)事件子話(huà)題聚類(lèi)研究
2023-10-31 09:39:16蘆子涵鄭中團(tuán)
智能計(jì)算機(jī)與應(yīng)用 2023年10期
蘆子涵, 鄭中團(tuán)
(上海工程技術(shù)大學(xué) 數(shù)理與統(tǒng)計(jì)學(xué)院, 上海 201600)
0 引 言
話(huà)題檢測(cè)與追蹤(Topic Detection and Tracking,TDT) 是美國(guó)國(guó)防高級(jí)研究計(jì)劃局(Defense Advanced Research Projects Agency,DARPA)于1996年開(kāi)展的語(yǔ)言信息研究項(xiàng)目[1],曾在評(píng)測(cè)會(huì)議上對(duì)話(huà)題等相關(guān)要素進(jìn)行了定義,認(rèn)為話(huà)題是由一個(gè)種子事件或活動(dòng),和全部與之直接關(guān)聯(lián)的后續(xù)事件和活動(dòng)構(gòu)成[2]。 而在國(guó)內(nèi),曾有學(xué)者定義子話(huà)題為話(huà)題內(nèi)一組相關(guān)事件的集合,是話(huà)題內(nèi)所有事件集合的一個(gè)子集[3]。 近年來(lái),突發(fā)事件時(shí)有發(fā)生。 譬如2022 年“3·20”東航航班墜機(jī)等事故災(zāi)難事件、2022 年6 月河北唐山打人等社會(huì)安全事件、2021 年“7·20”河南特大暴雨等自然災(zāi)害事件與至今仍時(shí)有發(fā)生的2020 年新冠肺炎疫情等公共衛(wèi)生事件。與此同時(shí),隨著網(wǎng)民規(guī)模的擴(kuò)大與社交平臺(tái)的普及,像新浪微博這樣傳播范圍廣、普及率高的社交網(wǎng)絡(luò)平臺(tái)逐漸成為突發(fā)事件的曝光口。 社會(huì)大眾可自由地在網(wǎng)絡(luò)平臺(tái)上發(fā)表自身對(duì)突發(fā)事件的看法或評(píng)論,從而形成網(wǎng)絡(luò)輿情。 由于突發(fā)事件具有不確定性、危害性等特點(diǎn)[4],通常會(huì)給社會(huì)大眾帶來(lái)負(fù)面的心理沖擊。 如若不能針對(duì)性地根據(jù)社會(huì)大眾對(duì)于某一突發(fā)事件所關(guān)注的不同子話(huà)題來(lái)引導(dǎo)積極的輿論走向,并建立輿情治理機(jī)制,則會(huì)放大社會(huì)大眾的負(fù)面情緒,引起不必要的激進(jìn)言論,甚至?xí)?duì)政府機(jī)構(gòu)造成不良影響。 現(xiàn)有研究大多基于事件這一粒度進(jìn)行話(huà)題聚類(lèi),而忽略了同一事件下不同側(cè)面的更細(xì)粒度子話(huà)題的研究。 因此,如何有效地挖掘某一事件中的潛在子話(huà)題,逐漸成為了新興研究熱點(diǎn),也對(duì)輿情管控相關(guān)部門(mén)實(shí)現(xiàn)輿情精準(zhǔn)化管控具有重要現(xiàn)實(shí)意義。
本文針對(duì)以往話(huà)題聚類(lèi)大多基于事件這一層次,而忽略了同一事件下更細(xì)粒度子話(huà)題的研究,且文本特征表示上缺乏上下文語(yǔ)義信息的缺陷,提出一種基于LDA 文檔-主題分布與Doc2Vec 句向量融合的文本表示方法與文本相似度計(jì)算方法,最后通過(guò)Single-Pass 增量聚類(lèi)算法實(shí)現(xiàn)同一突發(fā)事件下子話(huà)題聚類(lèi)。
1 相關(guān)研究
目前,在話(huà)題挖掘領(lǐng)域,多以基于概率主題模型的話(huà)題發(fā)現(xiàn)、基于文本特征表示的話(huà)題聚類(lèi)兩種為主要途徑與方法。 概率主題模型是對(duì)文本中隱含主題的一種非監(jiān)督建模方法,其認(rèn)為一篇文檔中的每個(gè)詞都是通過(guò)以一定概率選擇某個(gè)主題,并從這個(gè)主題中以一定概率選擇某個(gè)詞的方式得到的。 早期,為解決TF-IDF 文本模型的缺陷,利用奇異值分解將高維共現(xiàn)矩陣映射到低維潛在語(yǔ)義空間的潛在語(yǔ)義分析模型(Latent Semantic Analysis,LSA)被提出。 因其計(jì)算復(fù)雜度高且缺乏概率基礎(chǔ),Hofmann[5]在1999 年將LSA 的思想引入到概率模型中,提出概率潛在語(yǔ)義分析模型(Probabilistic Latent Semantic Analysis,PLSA)。 2003 年,Blei 等[6]基于貝葉斯思想,認(rèn)為文檔-主題概率分布是服從狄利克雷概率分布的隨機(jī)變量,提出了潛在狄利克雷模型(Latent Dirichlet Allocation,LDA)。 在話(huà)題挖掘領(lǐng)域,LDA 主題模型也成為目前最為成熟的概率主題模型。 由于概率主題模型以詞袋模型為基礎(chǔ),通常忽略了單詞與單詞之間的語(yǔ)義信息,導(dǎo)致語(yǔ)義缺失、主題可解釋性差等問(wèn)題。 基于此,趙林靜等[7]通過(guò)HowNet 常識(shí)知識(shí)庫(kù)計(jì)算單詞間的語(yǔ)義相似度,來(lái)調(diào)整LDA 主題模型中的超參數(shù)β, 提出SS-LDA 模型以提高主題挖掘的精度。 居亞亞等[8]為解決LDA 主題模型語(yǔ)義連貫性較差等問(wèn)題,在LDA框架下引入GRU 模型加入單詞—單詞和文檔—單詞語(yǔ)義相似度來(lái)引導(dǎo)建模,提出了SDS-TM 模型。閆盛楓[9]利用詞嵌入技術(shù)進(jìn)行語(yǔ)義向量編碼,以此來(lái)合并同語(yǔ)義信息主題詞并調(diào)整主題詞分布及權(quán)重,增強(qiáng)了主題模型的語(yǔ)義表達(dá)性。 也有學(xué)者通過(guò)優(yōu)化LDA 主題建模結(jié)果實(shí)現(xiàn)子話(huà)題的挖掘。 如:周楠等[10]基于PLSA 模型得到每個(gè)子話(huà)題下不同的詞頻分布,通過(guò)相似子話(huà)題合并、子話(huà)題更新優(yōu)化主題建模結(jié)果,解決了傳統(tǒng)方法的子話(huà)題區(qū)分度差等缺陷。 夏麗華等[11]將概率主題模型融合詞共現(xiàn)關(guān)系,提出GPLSA 方法對(duì)原始子話(huà)題進(jìn)行合并與更新,解決了描述同一產(chǎn)品的文檔十分相似,難以保證子話(huà)題差異性的問(wèn)題。
聚類(lèi)是一種十分重要的非監(jiān)督學(xué)習(xí)技術(shù),其任務(wù)是按照某種標(biāo)準(zhǔn)或數(shù)據(jù)的內(nèi)在性質(zhì)及規(guī)律實(shí)現(xiàn)樣本的聚類(lèi)[12]。 在話(huà)題挖掘領(lǐng)域,話(huà)題聚類(lèi)基于文本的特征表示或文本間的相似度,將目標(biāo)文檔分為若干個(gè)簇,使得每個(gè)簇內(nèi)文本間的相似度盡可能高,不同簇間文本的相似度盡可能低。 因而,眾多研究者基于文本特征表示或文本相似度進(jìn)行話(huà)題發(fā)現(xiàn)。 史劍虹等[13]利用隱主題模型挖掘微博內(nèi)容中隱含主題—文檔分布作為文本特征表示,并基于K-means++聚類(lèi)實(shí)現(xiàn)話(huà)題發(fā)現(xiàn)。 顏端武等[14]針對(duì)微博文本高維稀疏與上下文語(yǔ)義缺失等問(wèn)題,以L(fǎng)DA 文檔—主題分布特征和加權(quán)Word2Vec 詞向量特征構(gòu)建文本融合特征,并通過(guò)K-means 聚類(lèi)實(shí)現(xiàn)主題聚類(lèi)。肖巧翔等[15]提出一種基于Word2Vec 擴(kuò)充文本和LDA 主題模型的Web 服務(wù)聚類(lèi)方法,將短文本主題建模轉(zhuǎn)化為長(zhǎng)文本主題建模,進(jìn)而通過(guò)K-means 算法更準(zhǔn)確地實(shí)現(xiàn)了服務(wù)內(nèi)容主題聚類(lèi)。 趙愛(ài)華等[16]針對(duì)子話(huà)題間文本相似度高的特點(diǎn),引入主題特征詞相關(guān)性分析,提出一種改進(jìn)的文本相似度計(jì)算方法,并基于Single-Pass 增量聚類(lèi)實(shí)現(xiàn)新聞話(huà)題子話(huà)題挖掘。 李湘東等[17]針對(duì)LDA 建模結(jié)果較泛化的缺陷,將LDA 建模結(jié)果主題—特征詞分布作為文本較粗粒度的特征,將TF-IDF 向量作為文本較細(xì)粒度的特征來(lái)融合表示文檔,采用知網(wǎng)語(yǔ)義詞典得到文本相似度,通過(guò)Single-Pass 聚類(lèi)實(shí)現(xiàn)國(guó)內(nèi)各地時(shí)事新聞子話(huà)題劃分。
綜上,子話(huà)題挖掘多以L(fǎng)DA 主題模型建模、LDA 主題模型建模結(jié)果優(yōu)化、基于文本特征表示的話(huà)題聚類(lèi)為主要方法。 其中,對(duì)于評(píng)論短文本LDA主題模型具有文本向量高維稀疏、缺乏上下文語(yǔ)義信息等缺陷;改進(jìn)的LDA 主題模型以引入外部知識(shí)庫(kù)來(lái)修改超參數(shù)β來(lái)引導(dǎo)建模,通用性低且計(jì)算復(fù)雜度高。 基于文本特征表示的話(huà)題聚類(lèi)多以事件為層次進(jìn)行主題發(fā)現(xiàn),而忽略了同一事件下更細(xì)粒度、更深層次的子話(huà)題聚類(lèi)研究。 基于此,本文提出一種基于LDA 文檔-主題分布與Doc2Vec 句向量融合的文本特征表示方法與文本相似度計(jì)算方法,通過(guò)Single-Pass 增量聚類(lèi)算法實(shí)現(xiàn)同一突發(fā)事件下子話(huà)題聚類(lèi)。 一方面,上述文本融合特征不僅通過(guò)LDA 文檔—主題分布提取了全局主題信息,同時(shí)也通過(guò)句向量的構(gòu)建提取了局部上下文語(yǔ)義信息以補(bǔ)充LDA 主題模型語(yǔ)義信息的缺乏。 另一方面,不同于大多話(huà)題所基于的事件層次,針對(duì)同一事件下子話(huà)題相似度高、區(qū)分度低的問(wèn)題,本文給出了一種同一事件下更細(xì)粒度、更深層次的子話(huà)題聚類(lèi)方法。
2 預(yù)備知識(shí)
2.1 LDA 主題模型
主題模型是一種用來(lái)發(fā)現(xiàn)一系列文檔中隱含主題的無(wú)監(jiān)督統(tǒng)計(jì)模型,認(rèn)為一篇文檔中的每個(gè)詞都是以一定概率而選擇某個(gè)主題,并從該主題中以一定概率而選擇某個(gè)詞所生成的。 如圖1 所示,LDA主題模型是2003 年被Blei 等人[6]提出的文檔—主題—單詞的三層貝葉斯主題模型。 該模型以詞袋模型為基礎(chǔ),認(rèn)為一篇文檔是由詞所組成的集合,而詞與詞之間沒(méi)有語(yǔ)義聯(lián)系與順序。 其能夠?qū)⒁黄臋n表示為隱含主題的多項(xiàng)分布,即該文檔屬于每個(gè)主題的概率;將主題表示為詞集上的多項(xiàng)分布,即該主題下各個(gè)詞出現(xiàn)的概率。 與其他概率主題模型不同的是,LDA 主題模型基于貝葉斯思想,認(rèn)為文檔—主題分布θd的先驗(yàn)分布為Dirichlet 分布,即θd =。 主題—詞分布βk的先驗(yàn)分布為Dirichlet 分布,即βk =。

圖1 LDA 主題模型Fig.1 LDA topic model
在LDA 主題模型中,通常使用Gibbs 采樣算法[18]來(lái)進(jìn)行求解。α,η作為已知的先驗(yàn)輸入,目標(biāo)是得到各個(gè)zd,n、wd,n對(duì)應(yīng)的整體文檔—主題分布與主題—詞分布。
2.2 Doc2Vec 模型
為表達(dá)整條文本評(píng)論或整篇文檔的特征,常將由Word2Vec 得到的詞向量進(jìn)行向量拼接,此方法導(dǎo)致信息損失較大,得到的新向量不能涵蓋豐富語(yǔ)義信息內(nèi)容[19];或?qū)⒂蒞ord2Vec 得到的詞向量進(jìn)行平均求和,但此方法未考慮到詞與詞之間的語(yǔ)序信息,一定程度上忽略了文本上下文語(yǔ)義信息。Mikolov 等 人[20]在Word2Vec 的 基 礎(chǔ) 上 提 出 了Doc2Vec 模型, 以期構(gòu)建文檔的向量化表示。Word2Vec 模型本質(zhì)上一個(gè)具有輸入層、隱藏層、輸出層的三層神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),其包含CBOW(Continue Bag of Words)與Skip-Gram 兩種學(xué)習(xí)模型。 CBOW模型根據(jù)所輸入的目標(biāo)詞上下文單詞的One-Hot向量表示來(lái)輸出對(duì)目標(biāo)詞的預(yù)測(cè),而Skip-Gram 則是輸入當(dāng)前詞來(lái)預(yù)測(cè)上下文詞。
與Word2Vec 不同的是,Doc2Vec 模型在訓(xùn)練過(guò)程中增加了段落向量Paragraph id,進(jìn)而可以結(jié)合上下文詞訓(xùn)練文本,從而得到句向量和文本向量[21]。在Doc2Vec 模型中,段落向量與單詞一樣首先將被映射成一個(gè)句向量Paragraph Vector,其次將段落向量與上下文詞語(yǔ)所映射成的向量累加或拼接起來(lái),作為輸出層的輸入。 由于Paragraph Vector 在同一個(gè)文檔的每一次訓(xùn)練中是共享的,因此隨著文檔每次滑動(dòng)窗口取上下文單詞訓(xùn)練的過(guò)程中,Paragraph Vector 作為輸入層向量的一部分每次都將被訓(xùn)練,向量所儲(chǔ)存的段落信息將會(huì)越來(lái)越準(zhǔn)確。 Doc2Vec模型同樣包含PV-DM(Distributed Memory)與PVDBOW(Distributed Bag of Words)兩種學(xué)習(xí)模型。 本文擬采用PV-DM 模型,如圖2 所示。 PV-DM 模型根據(jù)所輸入目標(biāo)詞的上下文單詞來(lái)預(yù)測(cè)目標(biāo)詞,而PV-DBOW 則是輸入當(dāng)前詞來(lái)預(yù)測(cè)上下文詞。
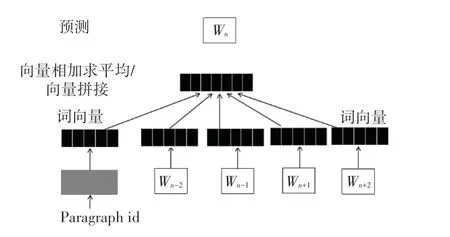
圖2 Doc2Vec 模型Fig.2 The model of Doc2vec
3 基于文本主題與語(yǔ)義融合特征的子話(huà)題聚類(lèi)
3.1 思路與流程
本文針對(duì)同一突發(fā)事件下子話(huà)題具有相似度高而區(qū)分度低的特點(diǎn),同時(shí)考慮到LDA 主題模型以詞袋模型為基礎(chǔ),其構(gòu)建的單一主題特征常忽略文本語(yǔ)義信息的問(wèn)題,重點(diǎn)構(gòu)建基于文本主題特征與文本語(yǔ)義特征的文本融合特征向量,并對(duì)上述兩種不同特征的文本相似度進(jìn)行線(xiàn)性結(jié)合,從而通過(guò)Single-Pass 增量聚類(lèi)實(shí)現(xiàn)突發(fā)事件下子話(huà)題聚類(lèi)。首先,以新浪微博平臺(tái)為數(shù)據(jù)來(lái)源,爬取突發(fā)事件評(píng)論文本構(gòu)建語(yǔ)料庫(kù),并對(duì)數(shù)據(jù)進(jìn)行清洗、分詞、去停用詞等預(yù)處理;其次,在全局主題層面通過(guò)LDA 主題模型提取文檔—主題分布以表達(dá)文本主題特征,在局部語(yǔ)義層面通過(guò)Doc2Vec 模型提取文檔句向量以表達(dá)文本語(yǔ)義特征,從而構(gòu)建文本融合特征;然后將基于KL 距離與余弦相似度線(xiàn)性結(jié)合計(jì)算融合特征相似度,以度量文本相似度;最后通過(guò)Single-Pass 增量聚類(lèi)實(shí)現(xiàn)子話(huà)題聚類(lèi)。 具體流程如圖3 所示。

圖3 研究思路與流程Fig.3 Research process
3.2 文本融合特征的構(gòu)建
假設(shè)預(yù)處理后的突發(fā)事件評(píng)論文本語(yǔ)料庫(kù)D ={d1,d2,…,dn},其中n為語(yǔ)料庫(kù)中評(píng)論文本的數(shù)目。 首先,通過(guò)LDA 主題模型提取文本主題特征。LDA 主題模型所提取的主題信息為T(mén) ={t1,t2,…,tk},K為主題個(gè)數(shù),通常由人為自主設(shè)定,本文將采用困惑度這一指標(biāo)來(lái)確定最優(yōu)主題個(gè)數(shù)。 本文采用Gibbs 采樣算法求解LDA 主題模型,在初始時(shí)刻為每個(gè)單詞隨機(jī)地賦予主題,其次,對(duì)于每個(gè)文本d中的每個(gè)詞,通過(guò)Gibbs 采樣公式獲取其所對(duì)應(yīng)的主題。 Gibbs 采樣公式如式(1)所示:
其中,n(dk)表示在第d個(gè)文本中第k個(gè)主題詞的個(gè)數(shù),n(kv)表示第k個(gè)主題中第v個(gè)詞的個(gè)數(shù)。
重復(fù)上述采樣過(guò)程直至Gibbs 采樣收斂,即可得到所有詞的采樣主題。通過(guò)統(tǒng)計(jì)每個(gè)文本d對(duì)應(yīng)詞的主題計(jì)數(shù), 每個(gè)文本d可表示為θd ={(t1,θt1) ,(t2,θt2) ,…,(tk,θtk)} 的 文 檔—主 題 分布,完成文本主題特征的提取。 其次,通過(guò)Doc2Vec模型提取文本語(yǔ)義特征。 本文采用Doc2Vec 中的PV-DM 模型,使用Python 中Gensim 庫(kù)的Doc2Vec接口來(lái)訓(xùn)練語(yǔ)料庫(kù),從而得到語(yǔ)料庫(kù)中每個(gè)文本d的句向量表示Sd =[s(d,1),s(d,2),…,s(d,m)].
由于基于詞袋模型的LDA 主題模型所提取的主題特征往往忽略了文本語(yǔ)義信息,而Doc2Vec 模型所訓(xùn)練的文本句向量能夠補(bǔ)充性地提取上下文語(yǔ)義信息,彌補(bǔ)LDA 主題特征的這一缺陷。 因此,本文將基于LDA 主題模型與Doc2Vec 模型所提取文本主題特征與文本語(yǔ)義特征進(jìn)行橫向拼接,構(gòu)建文本融合特征矩陣ST。
3.3 文本相似度計(jì)算
文本相似度的計(jì)算是子話(huà)題聚類(lèi)的前提,本文將基于KL 散度與余弦相似度計(jì)算文本主題概率分布相似度與句向量相似度,并將二者進(jìn)行線(xiàn)性組合,從而得到本文所構(gòu)建的融合特征相似度,即文本相似度,式(2):
其中,di與dj表示評(píng)論文本。
3.3.1 基于KL 距離的文本主題特征相似度
KL 距離(Kullback-Leibler Divergence,KL)用來(lái)衡量相同事件空間里的兩個(gè)概率分布的差異情況,又被稱(chēng)為相對(duì)熵。 在本文中,評(píng)論文本di的文檔—主題分布表示為p(t),評(píng)論文本dj的文檔—主題分布表示為q(t),p(t) 與q(t) 的概率分布越相似,則兩者之間的KL距離越小[16]。p(t) 與q(t) 之間的KL距離如式(3) 所示:
考慮到KL距離具有非對(duì)稱(chēng)性,交換p(t) 與q(t) 的位置后結(jié)果大不相同,參考文獻(xiàn)[9]的做法,可采用公式(4)計(jì)算文檔—主題概率分布之間的距離:
3.3.2 基于余弦相似度的文本語(yǔ)義特征相似度
針對(duì)通過(guò)Doc2Vec 模型訓(xùn)練所提取的表征文本語(yǔ)義特征的句向量,采用余弦相似度來(lái)計(jì)算文本語(yǔ)義特征相似度,如式(5)所示。
其中,Sdi、Sdj為評(píng)論文本di、dj的文本語(yǔ)義特征。
3.4 子話(huà)題聚類(lèi)算法流程
本文采用Single-Pass 增量聚類(lèi)[22]實(shí)現(xiàn)子話(huà)題聚類(lèi),該算法是話(huà)題檢測(cè)中一種常用算法,又稱(chēng)單通道法。 在Single-Pass 算法中,需要自主預(yù)設(shè)一個(gè)聚類(lèi)閾值,對(duì)于所輸入的評(píng)論文本,計(jì)算當(dāng)前評(píng)論文本與已有話(huà)題聚類(lèi)簇之間的相似度,若相似度大于預(yù)設(shè)的聚類(lèi)閾值,則將該評(píng)論文本判為已有話(huà)題聚類(lèi)簇;否則,將該評(píng)論文本作為簇核心創(chuàng)建新的話(huà)題簇。 本文將所構(gòu)建的文本融合特征與文本相似度計(jì)算嵌入Single-Pass 聚類(lèi)算法中,具體算法流程見(jiàn)表1。

表1 子話(huà)題聚類(lèi)算法流程Tab.1 The process of sub-topic clustering algorithm
4 實(shí)驗(yàn)與分析
本文將以新浪微博為數(shù)據(jù)來(lái)源,以“鄭州地鐵7.20 事件”為突發(fā)事件評(píng)論語(yǔ)料庫(kù)進(jìn)行3 組實(shí)驗(yàn)。第一組實(shí)驗(yàn)采用困惑度(Perplexity)評(píng)價(jià)指標(biāo),得出1~10 個(gè)主題下的困惑度值,從而確定最優(yōu)主題數(shù);第二組實(shí)驗(yàn)采用F1 值尋找能夠使F1 值達(dá)到最高的聚類(lèi)閾值,從而確定最佳聚類(lèi)閾值σ; 第三組實(shí)驗(yàn)生成3 種評(píng)論文本特征向量,其中包括LDA 文檔—主題分布向量、Doc2Vec 句向量以及本文的融合特征向 量, 采 用查 準(zhǔn) 率(Precision)、 召 回 率(Recall) 與F1 值對(duì)比3 種文本特征向量子話(huà)題聚類(lèi)效果,以驗(yàn)證基于本文融合特征子話(huà)題聚類(lèi)的有效性。
4.1 突發(fā)事件概述與數(shù)據(jù)預(yù)處理
2021 年7 月20 日,河南鄭州發(fā)生罕見(jiàn)特大暴雨。 當(dāng)日晚19 時(shí)左右,據(jù)鄭州本地廣播官方微博@MyRadio 發(fā)布的微博稱(chēng),鄭州地鐵5 號(hào)線(xiàn)雨水倒灌,車(chē)廂內(nèi)積水已到達(dá)乘客胸部,數(shù)名乘客被困。 隨后該條微博被澎湃新聞官方微博@澎湃新聞轉(zhuǎn)發(fā),轉(zhuǎn)發(fā)人次5.2 萬(wàn),評(píng)論人次3.7 萬(wàn),事件爆發(fā)。 截至當(dāng)日晚間22 時(shí)左右,消防救援人員陸續(xù)疏散被困人員500 余人。 7 月21 日上午,鄭州地鐵官方發(fā)布稱(chēng)此次事件導(dǎo)致12 人遇難。 隨后,兩名個(gè)人用戶(hù)發(fā)布博文稱(chēng)有乘客鄒某、沙某仍失聯(lián)。 26 日,乘客鄒某、沙某確認(rèn)遇難。 27 日上午,鄭州官方發(fā)布此次事件最終導(dǎo)致14 人遇難,再次引起一波輿論高潮。 2022年1 月21 日,國(guó)務(wù)院調(diào)查組調(diào)查認(rèn)定鄭州地鐵5 號(hào)線(xiàn)亡人系責(zé)任事件,是造成重大人員傷亡與財(cái)產(chǎn)損失的突發(fā)事件。
本文以“鄭州地鐵5 號(hào)線(xiàn)”、“多人被困”等為關(guān)鍵詞,以2021 年7 月20 日19 時(shí)—2021 年7 月31日22 時(shí)為時(shí)間區(qū)間,每2 小時(shí)為一個(gè)時(shí)間段,利用Gooseeker 集搜客數(shù)據(jù)抓取器采集數(shù)據(jù),共采集到6 657條評(píng)論文本作為語(yǔ)料庫(kù)。 每條評(píng)論文本包含5個(gè)字段:用戶(hù)ID、發(fā)布時(shí)間、評(píng)論內(nèi)容、點(diǎn)贊數(shù)與評(píng)論數(shù)。 對(duì)語(yǔ)料庫(kù)進(jìn)行以下預(yù)處理操作:
(1)數(shù)據(jù)清洗。 去除與話(huà)題不相關(guān)的評(píng)論文本,剔除特殊字符如表情、評(píng)論圖片等;
(2)人工標(biāo)注。 結(jié)合鄭州地鐵5 號(hào)線(xiàn)事件期間微博熱搜內(nèi)容,對(duì)評(píng)論文本進(jìn)行話(huà)題標(biāo)注,以便后續(xù)有效性驗(yàn)證;
(3)分詞。 采用Python 中Jieba 庫(kù)對(duì)評(píng)論文本進(jìn)行分詞,同時(shí)加載分詞詞典以識(shí)別該事件特定詞;
(4)去停用詞。 根據(jù)停用詞表去除標(biāo)點(diǎn)符號(hào)、語(yǔ)氣助詞等詞語(yǔ)。
4.2 評(píng)估指標(biāo)
本文采用查準(zhǔn)率(Precision)、召回率(Recall)、F1 值來(lái)對(duì)比3 種文本特征向量子話(huà)題聚類(lèi)效果,其值越高,說(shuō)明方法效果越好。
查準(zhǔn)率(Precision) 是指預(yù)測(cè)為屬于子話(huà)題Ci的評(píng)論文本中,實(shí)際屬于子話(huà)題Ci的評(píng)論文本比例;召回率(Recall) 為實(shí)際屬于子話(huà)題Ci的評(píng)論文本中,被預(yù)測(cè)為屬于子話(huà)題Ci的評(píng)論文本比例。
其中,C為子話(huà)題簇個(gè)數(shù)。
整體聚類(lèi)效果采用F1 對(duì)各個(gè)子話(huà)題的聚類(lèi)效果求平均的方式來(lái)度量。
4.3 實(shí)驗(yàn)結(jié)果與分析
4.3.1 實(shí)驗(yàn)1 確定最優(yōu)話(huà)題個(gè)數(shù)
在LDA 主題模型提取文本主題特征中,主題個(gè)數(shù)的選取能夠直接影響到特征提取效果。 若僅依賴(lài)人為設(shè)定,LDA 主題模型的性能將無(wú)法保證。 因此,本實(shí)驗(yàn)采用困惑度(Perplexity)評(píng)價(jià)指標(biāo)來(lái)確定最優(yōu)主題個(gè)數(shù)。 困惑度常被用來(lái)衡量概率分布或概率模型樣本的優(yōu)劣性[23]。 在自然語(yǔ)言處理中,可用于LDA 主題模型,確定最優(yōu)主題個(gè)數(shù),如式(8)所示:
其中,V表示語(yǔ)料庫(kù)D中所有詞的集合;N表示語(yǔ)料庫(kù)中評(píng)論文本的數(shù)量;Wd表示評(píng)論文本d中的詞;Md表示每個(gè)評(píng)論文本d中的詞數(shù);p(Wd) 表示文本中詞出現(xiàn)的概率。
實(shí)驗(yàn)中根據(jù)“鄭州地鐵7.20 事件”期間新浪微博熱搜詞條,擬定1 ~10 區(qū)間內(nèi)的整數(shù)為實(shí)驗(yàn)主題數(shù),得到困惑度變化如圖4 所示。

圖4 確定最優(yōu)主題個(gè)數(shù)Fig.4 The determination of the optimal number of topics
通常情況下,困惑度隨著主題數(shù)量的增加而呈現(xiàn)遞減的規(guī)律。 困惑度越小,意味著主題模型的生成能力越強(qiáng)[24]。 通過(guò)圖4 可以看出,當(dāng)T =8 時(shí)LDA 主題模型困惑度最小,因此本文將主題個(gè)數(shù)T設(shè)定為8。
4.3.2 實(shí)驗(yàn)2 確定最佳聚類(lèi)閾值
實(shí)驗(yàn)中采用4.2 節(jié)所描述的F1 值來(lái)計(jì)算不同聚類(lèi)閾值下聚類(lèi)效果的優(yōu)劣。 經(jīng)多次實(shí)驗(yàn),當(dāng)聚類(lèi)閾值小于0.3 時(shí),所有評(píng)論文本被聚類(lèi)為同一簇,聚類(lèi)閾值過(guò)小。 因此,本實(shí)驗(yàn)中擬定聚類(lèi)閾值在σ∈(0.3,1) 這一區(qū)間內(nèi),分別進(jìn)行6 次實(shí)驗(yàn),得到F1值變化如圖5 所示。 可以看出,當(dāng)聚類(lèi)閾值σ =0.52時(shí),聚類(lèi)效果最好,此時(shí)的F1 值為0.724,因此本文將確定聚類(lèi)閾值σ為0.52。
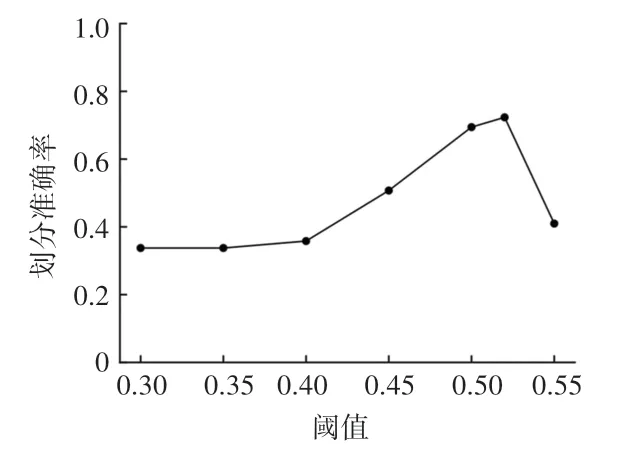
圖5 確定最佳聚類(lèi)閾值Fig.5 The determination of threshold value in clustering
4.3.3 實(shí)驗(yàn)3 對(duì)比實(shí)驗(yàn)與分析
為驗(yàn)證本文基于融合特征表示的子話(huà)題聚類(lèi)方法的有效性,對(duì)于LDA 主題模型所提取單一文本主題特征文檔—主題分布、Doc2Vec 模型提取單一文本語(yǔ)義特征句向量、3.2 節(jié)所表述的文本融合特征分別進(jìn)行Single-Pass 子話(huà)題聚類(lèi)實(shí)驗(yàn),并采用精確率、召回率、F1 值來(lái)度量聚類(lèi)效果的優(yōu)劣。 實(shí)驗(yàn)結(jié)果見(jiàn)表2。

表2 實(shí)驗(yàn)3 結(jié)果對(duì)比Tab.2 The result of test 3
依據(jù)表2 中數(shù)據(jù)分析可知:
(1)基于單一文本語(yǔ)義特征的子話(huà)題聚類(lèi)的F1值為67.3%。 Doc2Vec 模型通過(guò)三層神經(jīng)網(wǎng)絡(luò)根據(jù)所輸入的目標(biāo)詞來(lái)預(yù)測(cè)目標(biāo)詞的上下文單詞,從而得到副產(chǎn)物句向量與詞向量。 一方面,相比將一條評(píng)論文本中每個(gè)詞的詞向量進(jìn)行求和或加權(quán)平均求和來(lái)表示整條文本評(píng)論的方法,Doc2Vec 能夠給出整條文本評(píng)論的文檔向量化表示,能夠避免前者忽略單詞在句子中的語(yǔ)序問(wèn)題;另一方面,相比于LDA 主題模型基于詞袋模型,Doc2Vec 模型能夠有效提取文本中的語(yǔ)序及上下文語(yǔ)義信息。 但未考慮文本的全局信息,因而在F1 值位于另外兩種特征子話(huà)題聚類(lèi)之間。
(2)基于單一文本主題特征的子話(huà)題聚類(lèi)的F1值為64.4%,相較于另外兩種特征F1 值最低。 LDA主題模型將文本表示為維數(shù)為主題個(gè)數(shù)的多項(xiàng)分布,從而提取文本全局主題特征。 LDA 主題模型所基于的詞袋模型忽視了文本中單詞的語(yǔ)序與語(yǔ)義表達(dá),對(duì)于同一突發(fā)事件下相似度高、區(qū)分度差的評(píng)論文本而言,雖能夠提取文本的主題特征,但僅用LDA 主題特征來(lái)進(jìn)行相似背景子話(huà)題聚類(lèi),則難以發(fā)揮LDA 主題模型的優(yōu)勢(shì)與作用。
(3)基于融合特征的子話(huà)題聚類(lèi)方法相較于單一特征聚類(lèi)效果最佳,F(xiàn)1 值達(dá)72.4%。 融合特征考慮到同一突發(fā)事件下子話(huà)題具有相似背景詞而導(dǎo)致區(qū)分度差的特點(diǎn),且LDA 主題模型所提取主題特征基于詞袋模型,缺乏語(yǔ)義信息,從文本主題層面與語(yǔ)義層面融合LDA 文檔—主題分布與Doc2Vec 句向量,改善了單一特征進(jìn)行子話(huà)題聚類(lèi)的缺陷,能更加全面有效地表達(dá)文本特征,從而提高同一突發(fā)事件下子話(huà)題聚類(lèi)效果。
5 結(jié)束語(yǔ)
本文提出的基于文本融合特征的子話(huà)題聚類(lèi)方法,結(jié)合LDA 主題模型提取的文本主題特征與Doc2Vec 模型提取的文本語(yǔ)義特征構(gòu)建一種文本融合特征,并通過(guò)Single-Pass 增量聚類(lèi)實(shí)現(xiàn)子話(huà)題聚類(lèi)。 研究中使用本文方法,以新浪微博為數(shù)據(jù)來(lái)源平臺(tái),對(duì)“鄭州地鐵7.20 事件”這一突發(fā)事件評(píng)論文本進(jìn)行實(shí)驗(yàn)分析。 在對(duì)比實(shí)驗(yàn)中,采用F1 值與兩種單一特征子話(huà)題聚類(lèi)進(jìn)行聚類(lèi)效果評(píng)估。 實(shí)驗(yàn)結(jié)果表明,融合特征能更加全面地表達(dá)文本特征,改善了單一特征進(jìn)行子話(huà)題聚類(lèi)缺乏上下文語(yǔ)義信息及忽略語(yǔ)序的問(wèn)題,有效地提高了突發(fā)事件中子話(huà)題聚類(lèi)的準(zhǔn)確率。
受各方面因素所限,本文還存在一定的局限與不足。 在突發(fā)事件網(wǎng)絡(luò)輿論中,網(wǎng)民往往帶有濃烈的正向或負(fù)向的情感色彩。 因此,在文本的特征表達(dá)中,如何提取評(píng)論文本的情感特征并將其進(jìn)行融合處理,從而更有效地進(jìn)行子話(huà)題挖掘,在后續(xù)的研究中仍有待進(jìn)一步深入和突破。
猜你喜歡
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
語(yǔ)文知識(shí)(2014年1期)2014-02-28 21:59:13
