面向電力領域自然語言理解的數據增強研究與實現
2023-10-30 04:32:42施俊威
現代計算機 2023年16期
施俊威,宋 暉
(東華大學計算機科學與技術學院,上海 201620)
0 引言
隨著人工智能技術的不斷發展和應用,電力領域也逐漸迎來了智能化轉型的浪潮。在電力行業中,用戶往往通過人工客服和電力公司網站等傳統方式獲取與用電相關的各種信息,然而,這些方式存在著諸多問題,如人工客服效率低、需要等待時間長。因此,在人工智能系統與電力系統的融合中,智能問答成為一種重要的應用方式和技術手段,將自然語言處理技術應用于電力系統中,提高溝通效率和工作效率,節省了人力資源[1],使電力系統向自動化、智能化方向發展[2]。
在電力領域的智能問答中正確地理解用戶的問題至關重要,目前通常采用自然語言理解(NLU)模型來實現[2]。在面向電力營銷指標問答的應用時,由于業務場景很多,需要識別的槽也很多,直接標注企業提供的少量問題,構建NLU 模型,識別準確率只能達到60%左右,離實際應用要求相去甚遠。研究表明,大量的訓練數據能夠顯著提高NLU 模型的準確性[3]。在實際應用中,用戶和企業提供的領域問題數據并不能滿足模型訓練要求,并且人工數據標注的成本大,所以需要使用數據增強技術生成大量的電力領域樣本數據,以此滿足NLU 模型訓練需求。
傳統的文本數據增強方法包含詞匯替換、文本表面轉換以及隨機噪聲注入[4]。但是在面向電力領域NLU 任務里,通過使用這些方法生成的文本不能保證文本語義的連貫性和文本多樣性,這會導致NLU 模型性能下降[5],因此考慮采用生成式模型生成問題樣本,生成模型能夠基于給出的關鍵詞生成問題句。我們首先通過槽值替換方法獲得部分樣本,再利用這些樣本一起訓練生成式模型。
目前生成式模型的解碼方法一般是基于集集中搜索[6],其生成的文本會出現重復詞或者多個同類型詞連續出現,導致生成的文本語義不正確。本文提出了一種基于對比搜索[7]關鍵詞文本生成模型(neural text generaion with contrastive search,CSTG)。在文本生成過程中,生成的輸出應該從模型預測的最有可能的候選詞集合中選擇,生成的輸出應該具有充分的區分性,以便于與前文上下文的關系進行區分。通過這種方式,在電力領域樣本數據生成任務中,模型所生成的問題文本既能夠更好地保持語義連貫性,同時避免模型退化和在生成的文本中出現連續的重復詞。實驗結果表明,該模型降低了生成電力領域問題文本的重復率,從而使得訓練后的NLU模型能夠更加準確地理解用戶的問題,提升電力指標檢索系統的準確率。
1 基于對比搜索關鍵詞文本生成模型
1.1 模型框架
在電力領域的指標問答應用中,NLU模型需要理解用戶問句對應的業務領域、指標問法,以及關鍵槽值。如領域domain為配變異常,指標意圖intent為query_total,槽和對應的槽值slots:{“org”:“南因供電所”,“time”:“2022 年 1月”,“detail”:“情況”}。
我們首先使用傳統的槽替換、值替換等方法,基于用戶提供的典型和應用系統數據,獲得的樣本數據作為訓練數據集,用于訓練問題生成模型:模型將問題句的各種槽值(關鍵字)作為輸入,輸出一段完整的文本,該段文本應盡可能包含這些給定的領域關鍵詞。輸入領域關鍵詞包含售電量、石家莊、3月和排名,經過模型的文本生成,生成完整的文本:“今年3月份在石家莊的售電量排名是多少?”
本文設計了CSTG模型來實現生成過程,該模型是基于注意力機制的LSTM文本生成模型[8],如圖1所示。根據輸入的電力領域關鍵詞W生成與電力領域關鍵詞相關的問題文本。
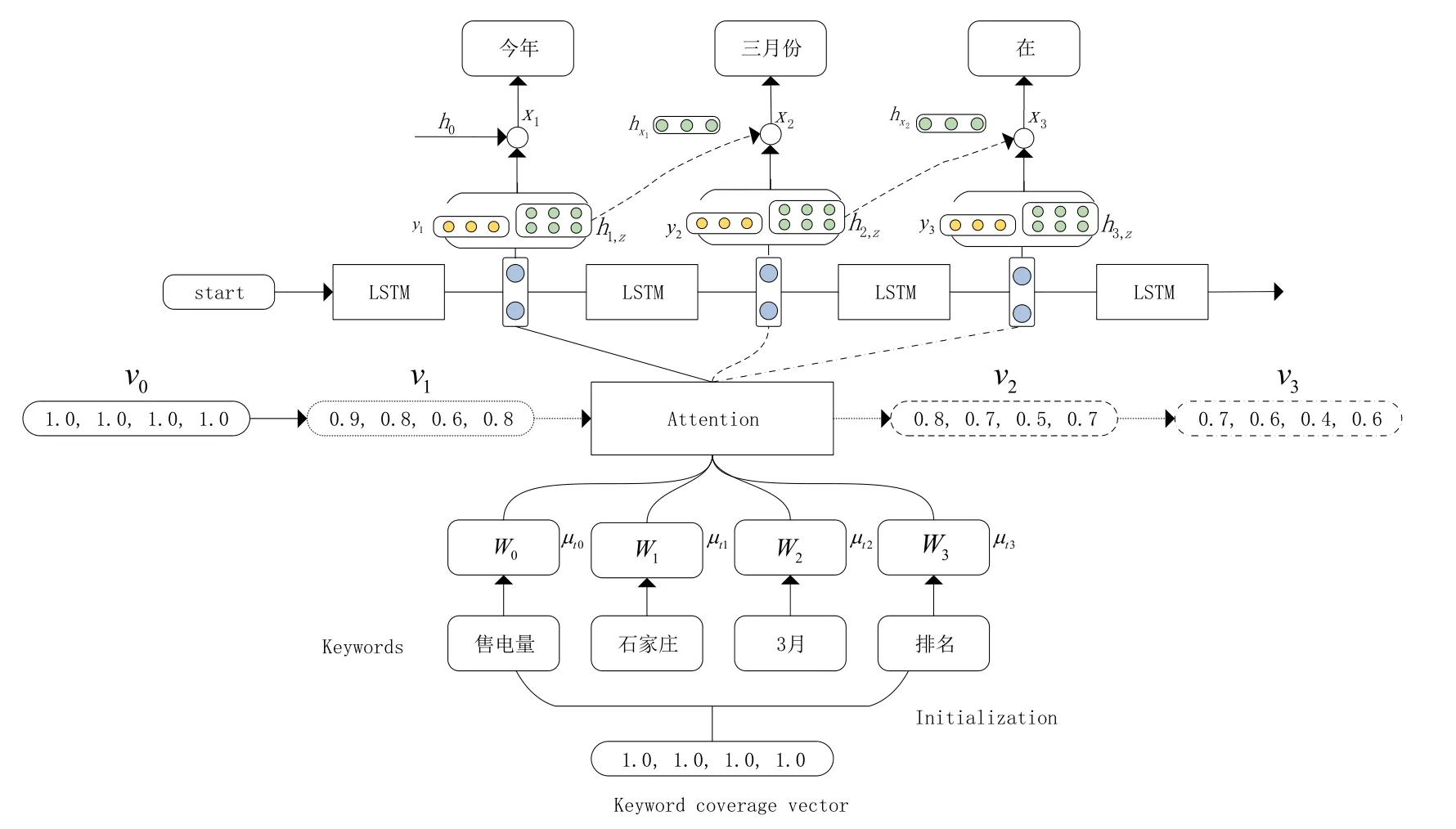
圖1 模型結構
CSTG模型由編碼和解碼兩部分組成,在編碼部分,主要包含對關鍵詞的編碼以及設置關鍵詞表達的覆蓋向量,覆蓋向量是控制關鍵詞在文本生成中被表達的權重值向量,使得關鍵詞盡可能地在文本中被表達出來。在解碼部分,包含注意力模塊和解碼策略,注意力模塊讓解碼器基于自身歷史輸出,來計算輸出。解碼策略則基于所給候選詞選擇最優項作為輸出。
1.1.1 編碼
在模型的編碼階段,首先模型將輸入的關鍵詞通過一個詞嵌入層轉換成向量表示W,然后,通過引入注意力參數μ,我們可以將每個關鍵詞表示為Tt,并將每個關鍵詞的語義通過注意力機制傳遞到生成的單詞中,該注意力參數定義為一個向量:μ1、μ2、…、μk,其中μi表示領域關鍵詞詞匯i的分數。在時間步t生成文本時,Tt的計算公式如下:
其中,Wj表示第j個關鍵詞的編碼張量,μtj的計算方式如下:
并且qtj的計算公式表示為
其中va,Xa和Ya是三個矩陣,在模型訓練期間需要進行優化。
1.1.2 關鍵詞覆蓋向量
模型設置一個關于所給關鍵詞的覆蓋向量v,每一維度代表該關鍵詞在將來的文本生成中被表達的程度,關鍵詞覆蓋向量通過一個參數φj進行更新,這個參數可以被視為關鍵詞Wj的話語級重要性權重。該參數用于調整生成過程中領域關鍵詞的表達程度,從而影響模型對關鍵詞Wj的關注程度,使得生成的文本能夠更好地符合關鍵詞Wj的內容要求。在模型的生成過程中,模型會根據覆蓋向量v和注意力機制調整生成策略,使得模型能夠讓未被表達的關鍵詞在生成過程中表達,從而提升生成文本的可讀性和完整性。在當前時間步t生成新的詞時,第j個關鍵詞Vt,j的計算方式如下:
其中μt,j表示第j個關鍵詞在時間步t的注意力權重。φj=N·σ(Uf[T1,T2,…,Tk]),Uf∈。
在模型的訓練過程中,可以利用已有的電力領域問題和關鍵詞來訓練模型的參數和關鍵詞覆蓋向量。在模型訓練的過程中,可以采用基于梯度下降的方法對模型的參數和關鍵詞覆蓋向量進行更新。綜合上述,基于關鍵詞的文本生成模型可以幫助解決電力領域NLU 任務中數據數量不足的問題,提高訓練數據的數量和質量,從而提高模型的性能和準確率。同時,利用關鍵詞覆蓋向量可以讓模型更好地理解關鍵詞,并根據關鍵詞生成符合要求的文本。
1.2 模型解碼
1.2.1 文本生成
模型在生成文本階段,是基于上一個生成的詞預測下一個詞,下一個預測詞的概率根據下式得出。
上式中模型在時間步t的隱層狀態ht的公式如下所示:
一般生成式模型,在得到預測詞的概率后會選擇搜索算法,從候選詞中選取較為合適的詞作為生成文本。本文選用對比搜索作為模型的解碼策略,生成語義正確的文本數據。
1.2.2 對比搜索
基于關鍵詞的文本生成模型普遍的解碼方法包括集中搜索、貪心搜索和隨機采樣,雖然這些方法在一般情況下可以保證生成文本的語義正確性,但是在電力領域中,領域詞之間存在相似性,使用這些方法容易導致生成的文本出現重復詞或連續生成同類詞,從而影響生成文本的質量。究其原因,是因為解碼算法沒有對語言模型的偏差合理規避[9]。為此,在基于關鍵詞的文本生成模型的基礎上,可以采用對比搜索的解碼方法來解決這一問題。對比搜索的方法會基于候選詞的選中概率,在每個解碼步驟中選擇模型預測的最可能候選詞集合,在選取最優候選詞時,生成的輸出與前一個上下文有足夠的區別性,以避免模型的退化。這種方法可以更好地保持生成文本與前綴的語義連貫性,并避免生成的文本質量下降。
對比搜索是一種用于解碼的策略。在每個解碼步驟中,該策略會從模型預測的最有可能的候選集合中選擇輸出,以確保生成的文本與人類編寫的前綴之間的語義一致,并保持生成文本的詞匯相似度矩陣的稀疏性,從而避免模型退化。一般解碼方法會選擇概率最高的候選項作為輸出,而候選集合通常包含模型預測的前k個最高概率的選項,k的取值通常為3到10。對比搜索引入了一項懲罰機制,用于評估候選項與先前上下文的可區分性,從而保證生成的文本具有足夠的多樣性。在時間步驟t,給定先前上下文x<t,選擇輸出xt的過程如下:
在上式中Z(k)是模型概率分布中前k個最高預測的候選集合,通常設置為3 到10。第一項模型置信度是模型預測的候選z的概率。第二項衰變懲罰度量候選z相對于先前上下文x<t的可區分性。s在公式中被定義為z的表示和x<t中所有tokens 的表示之間的相似度。這里ht,z是表示在當前時間步候選詞在模型中的隱層狀態。表示時間步t-1,選擇的最優候選詞的隱層狀態,其中z的更大的退化懲罰意味著它更類似于上下文,因此更容易導致模型的退化。超參數θ∈[ 0,1] 調節這兩個組件的重要性。當θ=0時,對比搜索退化為貪心搜索方法。
2 實驗
2.1 數據集與實驗設置
在當前的電力領域文本生成研究中,構建面向電力領域指標檢索的問題數據集是非常關鍵的。樣本數據集是JSON 的文件格式,每一條數據包含問題文本、領域、意圖、槽及槽對應的槽值。為了能夠更好地訓練和評估電力領域的文本生成模型,選擇了基于問題模板生成的電力營銷領域樣本數據,并從企業真實數據中獲取了用電量、售電收入、投訴數量、地市排名等多個問題句類型的數據。
該數據集包含了20920條樣本數據,其中訓練集包含17500 條文本數據,測試集包含3420條文本數據。為了更好地模擬真實情況,數據集的關鍵詞是選自于NLU 樣本問題的槽數據,能夠更好地體現電力領域的語境和特點。通過這樣的數據集構建,可以為電力領域的文本生成研究提供更加真實、具有代表性的數據,有助于研究者們更加深入地探究電力營銷領域文本生成模型的性能和應用場景。
2.2 實驗設置
在模型的實現上,該模型是基于LSTM 的文本生成模型,其中使用到注意力機制,模型的超參數設置為:batch_size 為32,候選詞的數量k為3,訓練輪次為45,最大關鍵詞詞數為5,embedding_dim 為100,hidden_dim 為512,最大句子長度為128,學習率為1e-7,ReLU 作為激活函數。
2.3 評估指標
為了評估模型的性能,我們采用以下三個指標:
(1)Bleu 指標通過比較機器翻譯結果與參考翻譯之間的n-gram重疊率來進行評估。
(2)MAUVE 是一種衡量生成的文本和人類編寫的文本之間的標記分布緊密度的指標。更高的MAUVE 分數意味著該模型生成更多類似人類的文本。
(3)rep-n這個指標以生成文本中重復n-gram的比例來衡量序列級別的重復,其中,n表示連續詞語或字符的數量。該重復率越低代表所生成的文本出現重復詞越少。對于所生成的文本n-gram級別的重復的定義如下:
(4)Diversity指標考慮到不同的n-gram 級別生成的重復,可以視為模型退化的整體評估,較低的多樣性意味著模型退化得更加嚴重。其公式如下:
3 實驗結果比較與分析
實驗1通過在文本生成模型中使用不同解碼方法,根據模型所生成的文本質量判斷模型整體的性能。該實驗中使用對比搜索和集中搜索兩種解碼方法,使用兩種解碼方法的模型在測試集中,實驗1的結果見表1,使用對比搜索的模型相較于使用集中搜索提高了9%,說明在電力領域使用對比搜索相較于傳統的集中搜索可以提高所生成文本的質量,模型的性能也會更好。
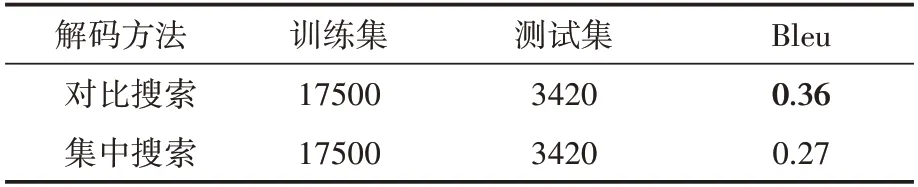
表1 模型性能實驗結果
在實驗2中,根據訓練數據集已有的領域關鍵詞利用已訓練的模型生成4000 條文本,分別計算基于不同的解碼方法所生成文本的文本重復率,以此評估生成的文本質量。實驗結果見表2,不同模型所生成的文本的重復率使用不同的解碼方法有了顯著的下降,其中對比搜索相較于集中搜索,在Rep-2、Rep-3、Rep-4 三個指標上都有較為明顯的下降,分別降低10.88、5.27、2.61,并且Diversity 與Mauve 指標有一定提高,對比搜索相較于貪心搜索和Nucleus Sampling 兩種解碼方法也有很大提升,表示對比搜索在該模型中能夠顯著降低生成文本的重復率,更好地保持模型生成文本與人類編寫的文本之間的語義一致性以及保留生成文本的詞匯相似度矩陣的稀疏性。

表2 不同解碼方法對文本重復率的影響
此外,通過對實驗2中所生成的文本進行分析,在模型訓練數據集中,根據不同文本長度的文本數據對應的領域關鍵詞生成文本,分析不同的文本長度對文本重復率是否產生影響。如表3所示。

表3 文本長度對重復率的影響
在電力領域數據集,平均文本長度分別為21.37和28.11,每種文本長度選取基于不同領域關鍵詞生成的1800 條文本數據進行分析,其對比搜索的重復率指標Rep-2、Rep-3 和Rep-4 相較于集中搜索都有一定幅度的降低,整體重復率指標Diversity 有一定提高。在分析不同長度的文本數據中,使用對比搜索的解碼方法相較于集中搜索取得更好的效果,基于對比搜索的模型所生成的文本,其重復率對于集中搜索有明顯的下降。
4 結語
本文針對智能問答中電力指標檢索系統的NLU 問題,訓練NLU 模型,其需要大量的樣本問題滿足訓練模型需要,但企業搜集的數據較少,人工標注成本較大,不能滿足需要,因此使用數據增強技術生成大量樣本數據。我們構建了一個面向電力領域的樣本問題數據集,提出并使用CSTG 生成了與電力領域相關的問題樣本。對比搜索的核心思想是在每個解碼步驟中,從模型預測的最可能候選集中選擇輸出,保持生成文本與給定前綴之間的語義一致性和詞匯的區分性,并避免模型的退化。實驗結果表明,相對于傳統的集中搜索,對比搜索能夠生成更加準確和合理的電力領域問題,且能夠有效地解決電力領域生成文本出現重復詞的問題,一定程度上減少高頻率文本的重復率[10],使得模型在各項評估指標都得到了提升,NLU 模型在使用模型所生成的文本數據后,模型識別用戶意圖的準確率有所提高,這也提升智能問答的電力指標檢索的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
