面向新一代國產異構眾核處理器的數據流計算系統
2023-10-27 02:51:10趙美佳李名凡陳俊仕周文浩
計算機研究與發展 2023年10期
肖 謙 趙美佳 李名凡 沈 莉 陳俊仕 周文浩 王 飛 安 虹
1(中國科學技術大學計算機科學與技術學院 合肥 230026)
2(國家超級計算無錫中心 江蘇無錫 214100)
3(清華大學計算機科學與技術系 北京 100084)
一直以來,高性能計算機(high performance computer,HPC)都是解決科學研究各領域實際問題的重要工具,依靠HPC 的強大計算能力,能使很多求解空間極大的科研問題在現實可見的時間內完成解算.
最近20 年,科學研究已經從計算科學時代進入數據科學范式時代,科學家需要從海量的數據中去探索科學規律和突破科學發展瓶頸,這就意味著傳統的用高密度計算去模擬復雜現象進行科學研究的方法需要創新發展,用高性能計算與人工智能相融合的新方法(HPC+AI)去解決實際問題,正逐漸成為一種行之有效的科研方法,例如2020 年的戈登貝爾高性能計算應用獎就頒發給基于深度學習實現1 億原子分子動力學的應用[1].
人工智能應用的開發和運行,往往依賴于人工智能編程框架,如TensorFlow[2],Pytorch[3]等,這些框架在本質上均是數據流計算系統,它們將神經網絡模型組織成數據流圖,并利用圖節點融合、圖剪枝、常量傳播等技術進行圖優化,然后再通過運行系統將圖節點調度到實際的計算資源上執行.換言之,數據流計算系統是支撐人工智能應用的重要基礎軟件,但是,要在國產高性能計算機上支持高效的數據流系統,則面臨著嚴峻的挑戰.
從底層硬件的角度來說,國產異構眾核處理器具有獨特的復雜結構,新一代國產異構處理器sw26010pro[4-5]具有多級計算資源、多層次存儲和多級互聯網絡結構,在體系架構上與傳統的多核CPU、眾核GPU 以及專用的人工智能處理器相比有著本質的區別.
要在sw26010pro 上高效執行數據流系統,需重點解決2 個問題:
1)如何充分利用sw26010pro 的眾核計算資源.計算核心陣列是國產異構眾核處理器的性能來源,具有眾多的精簡核心和強大算力,但也存在著訪存效率低、片上緩存小和管理復雜等實際問題.為實現數據流圖的高效執行,就需要實現自適應的眾核陣列加速方法,能夠自動加速數據流圖中的關鍵節點,充分利用眾核計算資源.
2)如何設計高效的兩級并行策略,充分利用國產異構眾核處理器的全片計算資源.sw26010pro 采用全片多核組集成的體系結構,每個核組都是同構的眾核陣列,多核組之間可以共享全局存儲,數據流圖中的節點執行以單核組為基本單元.要充分結合硬件結構特性,實現兩級并行策略,通過相應的圖優化和調度方法,確保多核組能夠并行執行數據流圖,提升系統性能.
對于上層用戶而言,傳統高性能計算機的軟件環境也很難滿足HPC+AI 領域應用的動態化和智能化需求,并且,用戶更希望將重心放在上層算法設計上,而非底層體系結構相關的優化上.
為此,本文提出了一種面向國產異構眾核處理器的數據流計算系統swFLOWpro,支持使用TensorFlow接口構建數據流計算和深度學習典型模型,并實現了對用戶透明的眾核并行加速,可以支持數據流程序的高效開發,在運行時充分利用國產異構眾核處理器的硬件能力.
本文的主要貢獻有4 點:
1)在國產異構眾核處理器上構建了功能完備的數據流計算系統swFLOWpro,能夠支持以深度學習為代表的數據流應用的開發和運行;
2)設計并實現了一種專門針對國產異構眾核處理器的核心計算加速引擎swHMAE,將之與數據流計算系統松耦合,實現自動化的眾核并行加速及算子分析、調試功能;
3)針對sw26010pro 的多核組共享內存結構,設計了一種面向異構融合體系結構的兩級并行策略,結合圖分裂技術,能充分利用全片核組的計算資源;
4)基于swFLOWpro 進行Alexnet,ResNet,VGG,Inception 等典型CNN 神經網絡模型訓練測試,實驗結果表明本文設計的數據流計算系統能夠獲得很好的異構眾核并行加速效果.
1 相關工作
1.1 數據流計算
傳統的馮·諾依曼計算機以控制流為執行模型,而數據流計算則采用了不同的思路,將程序組織成有向圖,每個圖節點表示一個算子,邊則代表節點之間的依賴關系,數據在邊上流動,當一個節點的所有輸入數據均已就緒時,該節點就會被啟動.數據流計算由程序本身的數據依賴關系來激活計算,更有利于充分發揮其天然的可并行性.
20 世紀90 年代,麻省理工大學提出一種基于數據流思想的處理器設計方案,該方案沒有共享存儲和寄存器的設計,數據直接在計算部件之間流動.當一條指令所有操作數均已就緒時,即可以進入執行狀態.這種體系架構能夠充分挖掘程序的指令級可并行性,但也存在著運行開銷大、并行粒度過小等實際問題,與傳統計算機系統的天淵之別也限制了其進一步發展.
相關研究[6]還提出了一種硬件集成數據流芯片和馮·諾依曼架構芯片的體系結構設計,程序在編譯系統的支持下,可以在運行過程中動態調度到不同的芯片架構上去.這種處理器架構設計比較新穎,但對編譯和硬件實現的環境要求比較高.
純硬件的數據流計算系統面臨著諸多問題,最本質的問題在于其與傳統計算機軟硬件生態無法兼容,發展嚴重受限.于是,數據流計算機逐漸向與馮·諾依曼架構融合的方向發展,出現了“類數據流”計算機,這一類計算機融合了控制流和數據流的思想,將程序組織成一系列的宏指令或者代碼塊,每個宏指令或代碼塊內部采用數據流執行模式,而在宏指令和代碼塊之間依然采用傳統的控制流思想進行組織管理,該類計算機包括TRIPS[7],T3,EVX 等.類數據流計算機將數據流的思想用于最底層的指令層面,在程序層面則保持著和傳統架構相同的程序邏輯,例如EDGE[8]架構執行模型,就是將程序編譯成由超塊組成的控制流圖,將超塊內部的代碼編譯成數據流指令,數據直接在計算部件之間流動而不通過寄存器,但EDGE 架構必須運行在專門的類數據流處理器架構上,通用性較差.目前,最常見的數據流系統是在傳統馮·諾依曼架構上實現的軟件數據流系統.
Codelet[9-10]執行模型由特拉華大學提出,它是一種針對E 級計算機的需求而進行設計的細粒度并行、事件驅動的程序執行模型.Codelet 模型從數據流執行模型中得到啟發,結合傳統的馮·諾依曼體系架構,形成了一種在通用計算機上運行的數據流程序執行系統.
TensorFlow 是一款具有數據流思想的軟件計算系統,該系統運行于通用處理器架構上,并對眾核GPU和人工智能專用芯片TPU 有后端支持.TensorFlow 是人工智能領域非常熱門的編程框架,它將人工智能的算法模型組織成數據流圖,并通過運行支持數據流圖的高效映射和資源分配.TensorFlow 給用戶提供了豐富的API 接口來構建數據流計算,對深度學習的支持也比較完善,不過缺乏對于國產異構眾核架構的后端支持.
1.2 在國產異構眾核處理器上的數據流計算系統
在國產異構眾核處理器上,關于數據流計算系統的研究也一直在進行中.
SunwayFlow[11]是基于神威太湖之光高性能計算機系統開發的數據流計算系統,該系統將Codelet 執行模型移植到國產處理器上,并使用高性能共軛梯度基準測試(HPCG)作為測試數據,獲得10.32 倍的加速效果.但SunwayFlow 支持的Codelet 模型適用范圍有限,特別是對深度學習的支持嚴重不足.
swCaffe[12-13]是面向國產異構眾核處理器的深度學習編程框架,它在底層通過swDNN 庫支持眾核加速,針對VGG-16 有4 倍的加速效果.但是Caffe 框架[14]的編程接口已逐漸被淘汰,而swCaffe 要實現眾核加速,對模型的參數也有嚴格的限制,已無法適應數據流計算和深度學習應用的實際需求.
swFLOW[15]是2021 年推出的針對國產異構眾核處理器的數據流計算系統,該系統重構了TensorFlow框架,支持在sw26010 處理器上執行數據流計算,針對典型神經網絡模型有10.42 倍的加速.不過,swFLOW在功能上只支持TensorFlow 的C++接口,在優化設計上重點考慮面向大規模計算資源的分布式訓練,缺乏針對單進程的深度優化,也沒有針對全片多核組運行模式的優化支持,實際使用效果有待增強.
針對上述多款數據流計算系統軟件的缺陷,本文設計并實現了面向國產異構眾核處理器sw26010pro的新一代數據流計算系統swFLOWpro.該系統在編程接口支持上復用了TensorFlow 的前端模塊,可以完全兼容TensorFlow 的Python 和C++編程接口,提升系統易用性,在后端則通過獨立的核心計算加速引擎模塊來提供針對數據流圖節點的執行加速,除此之外,還針對sw26010pro 的多核組共享內存設計,開發了一種面向異構融合的兩級并行方法,從而提升全片計算資源的應用效率.
1.3 面向數據流計算的相關研究
Megatron-LM[16]主要討論如何在大規模GPU 集群上通過tensor/pipline/data 等多種并行模式高效實現大模型的訓練,通過并行模式的混合能夠提升10%的數據吞吐量,在3 072 個GPU 上訓練1 萬億參數模型,單GPU 峰值效率達到52%.
Gspmd[17]提出一種基于編譯器的自動化機器學習并行系統,可以在單節點代碼上通過添加編譯指示實現自動化并行代碼生成,在2 048 塊TPUv3 上達到了50%~62%的計算利用率.
DAPPL[18]面向大模型提出了結合數據并行和流水線并行方法的并行訓練框架,主要解決的問題是針對模型結構和硬件配置決策最優并行策略,如何調度數據流計算的不同流水線階段.
Alpa[19]針對分布式深度學習訓練提出了算子內和算子間并行策略,通過系統化的方式將分布式并行策略的優化空間結構化,并在這個優化空間中尋找最優策略并實現自動化.Alpa 以計算圖為輸入,輸出并行方案,主要考慮如何劃分子圖和計算任務調度.
目前,面向數據流計算的相關研究大多是針對大模型和大規模并行系統,專注于如何切割數據流圖并將其調度到各計算節點上,本文則主要針對sw26010pro的異構眾核結構和普通深度學習模型,專注于單處理器內部的計算流程,通過算子內和算子間的兩級并行策略,高效利用單處理器計算能力.在后續工作中,swFLOWpro 會在尋找最優并行策略以及調度模型的優化上加強研究.
2 swFLOWpro:新一代數據流計算系統
本節主要介紹國產異構眾核處理器sw26010pro的結構特點,以及swFLOWpro 的整體架構和工作流程.
2.1 sw26010pro 架構
sw26010pro 是一款國產異構眾核處理器,它包含6 個核組(core group,CG),核組之間通過片上環網互連,每個核組包含2 種異構核心,一種是管理核心(management processing element,MPE),另一種是計算核心(computing processing elements,CPE),1 個MPE 和1 個8×8 的CPE 組成1 個異構計算陣列.一般而言,MPE 主要負責計算任務、全局內存和運算核心的管理;CPE 負責計算任務的執行,每個CPE 通過一個軟件管理的片上便簽存儲器(LDM)來提升訪存效率.sw26010pro 結構如圖1 所示.

Fig.1 The structure of sw26010pro圖1 sw26010pro 結構
sw26010pro 采用SW64 自主指令集設計.其中,MPE具有32 KB L1 指令緩存、32 KB L1 數據高速緩存和512 KB L2 高速緩存;CPE 支持512 b 的SIMD 運算,支持雙精度、單精度和半精度浮點及整數等多種數據類型的向量運算,每個CPE 具有獨立的指令緩存和片上LDM 存儲,其中LDM 可以配置為L1 數據緩存,也可以配置為用戶管理的局存空間,支持通過DMA方式實現LDM 和全局內存之間的數據傳輸;支持通過RMA 方式實現不同CPE 之間的LDM 存儲傳輸.
sw26010pro 全處理器包含6 個同構的核組,6 核組之間可以共享全局內存.通常情況下,1 個進程運行在1 個核組上,多個核組之間通過MPI 消息進行通信,但這樣會導致單進程可用的內存空間和計算能力都較小,頻繁的MPI 通信也會造成性能損失.事實上,通過多核組的共享全局內存,可以結合多線程管理和核組資源分配,實現全片視角的統一編程,這樣能大幅度提升單進程的可用內存空間和計算能力,減少進程間通信造成的性能損失.
與常規的處理器設計不同,sw26010pro 將更多的硬件邏輯用于計算,從而最大程度地提升計算密度,精簡的CPE 核心設計導致了其計算能力很強,但訪存能力較弱.sw26010pro 提供了用戶可以顯式管理的LDM 存儲來彌補訪存與計算能力不匹配的問題,從而支持用戶充分挖掘異構眾核的計算能力.不過,這種設計模式就意味著程序的高效運行需要更加復雜的優化策略和更加全面的算法改造.
對于數據流計算和深度學習領域的編程用戶來說,他們更關注的是數據流圖的結構、模型的構造以及訓練模型的超參數調整等上層算法設計,而非底層硬件細節和體系結構相關優化技術.
為此,swFLOWpro 的主要設計目標就是構建國產異構眾核處理器與用戶之間的橋梁,提供可移植性強、功能豐富的編程接口,并將底層硬件細節對用戶透明,實現自動化的眾核并行加速.
2.2 swFLOWpro 結構設計
swFLOWpro 數據流計算系統的整體架構圖如圖2所示.swFLOWpro 系統可以劃分為2 個子模塊:前端模塊和后端模塊.中間層由C-API 橋接.
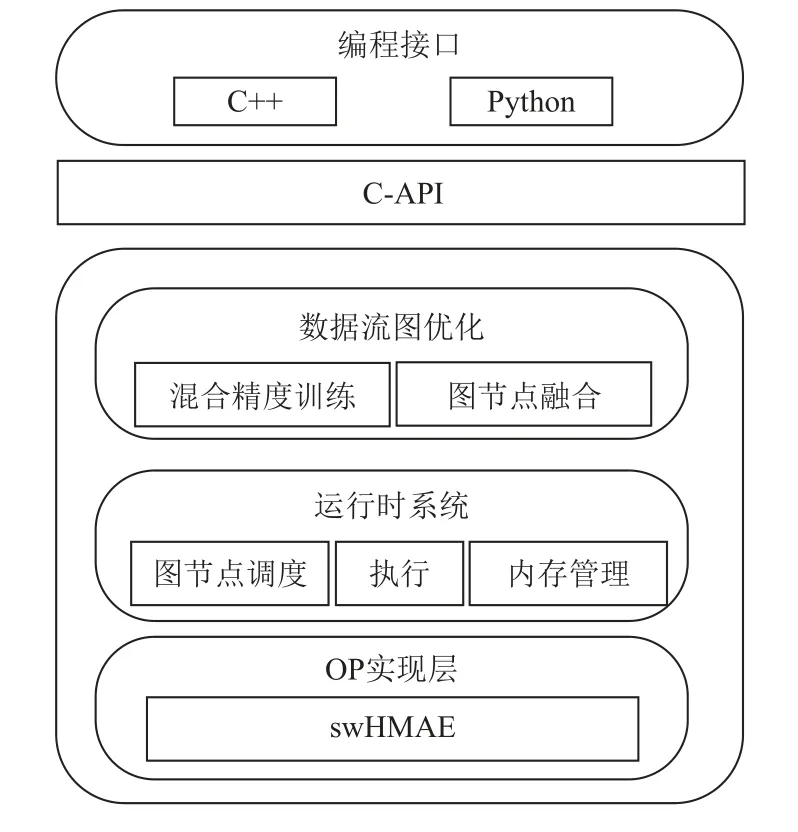
Fig.2 The overall architecture of swFLOWpro圖2 swFLOWpro 整體架構
前端模塊是一個支持多語言的編程環境,它提供基于數據流圖的編程模型,方便用戶使用TensorFlow的Python 和C++編程接口構造各種復雜的計算圖,從而實現各種形態的模型搭建.
C-API 是橋接前端模塊和后端模塊的中間層次,主要是通過SWIG(simplified wrapper and interface generator)機制支持前端多語言編程環境與C++實現的后端模塊之間的通道.
為保證系統的易用性和提升深度學習程序的可移植性,swFLOWpro 框架的前端模塊和C-API 復用了TensorFlow 框架的相應模塊,主要是為了保持對TensorFlow 編程的兼容性.
后端模塊則是體系結構相關的運行模塊,也是swFLOWpro 針對sw26010pro 架構特點重點開發的模塊.swFLOWpro 的后端模塊主要包括數據流圖優化、運行時系統、算子(OP)實現層等子模塊.其中,數據流圖優化模塊支持面向異構眾核處理器的混合精度訓練優化和節點融合優化,混合精度訓練優化在數據流圖中插入數據類型轉化節點,將單精度運算轉換為效率更高、精度更低的半精度運算,而在更新參數節點等對精度要求更高的節點之前,再將半精度轉化為單精度,從而支持混合精度訓練;圖節點融合優化則將多個圖節點融合,形成更大的計算單元,減少內存管理開銷,提升運行效率.運行時系統主要負責計算圖節點的管理、調度、執行以及內存分配,根據圖中依賴關系依次執行各個節點.OP 實現層則是針對sw26010pro 的存儲層次和結構特點,將OP 的定義和執行解耦,通過獨立的異構眾核加速引擎(swHMAE)實現對關鍵性能OP 的眾核加速,這一部分將在2.3 節中詳細介紹.
2.3 異構眾核加速引擎(swHMAE)
swHMAE 是一個獨立于swFLOWpro 系統之外的獨立模塊,其設計目的是為數據流計算系統提供一個松耦合的、體系結構相關深度優化的核心計算加速框架.框架整體結構如圖3 所示.

Fig.3 The structure of swHMAE圖3 swHMAE 結構
swHMAE 提供了一系列性能關鍵計算的調用接口,這些接口在swFLOWpro 的算子實現層進行調用,而其真正實現則集成于一個獨立的動態庫中.
swHMAE 提供的這些接口是完全虛擬化的,僅用來描述要完成哪種運算和需要哪些參數,swHMAE 可以向上支持不同的人工智能編程框架或數據流系統的圖節點實現模塊,向下則可以調用多種眾核加速算法庫,也可以集成用戶自定義的眾核算法,具有很好的可擴展性.
在swHMAE 中,針對不同的計算類型,主要完成2 方面的工作:1)收集核心計算的參數.2)根據參數類型、參數特性及輸入規模,判斷是否適合使用眾核加速,如不適合,則該API 返回失敗,swFLOWpro將調用默認的實現算法;否則,swHMAE 將根據不同的參數類型和規模自適應地選擇最優的異構眾核加速算法.
swHMAE 支持的核心計算類型涵蓋了數據流計算常見的計算類型,核心計算類型既有深度學習領域的常見計算,例如卷積、矩陣乘、激活、歸一化等,這類計算的眾核加速主要是通過swDNN,swBLAS,Sw_OPs 等第三方庫來支持,又有一些更通用的數據流計算節點類型,如批量數據的基礎運算、數據的Padding,tile,slice 等訪存操作,以及其他一些定制的計算類型.
swHMAE 的工作原理算法如算法1 所示:
算法1.swHMAE 工作原理算法.
swHMAE 是面向國產異構眾核處理器的數據流計算后端,作為一個獨立模塊,它將關鍵計算的眾核加速與數據流系統的整體框架解耦,既能夠高效利用swDNN,swBLAS,sw_OPs 等眾核計算庫,由于本身也集成了一系列眾核優化算子,也能夠對更多的核心計算進行眾核加速.
swHMAE 針對非計算密集類運算實現了眾核加速算法,其主要思想是通過數據分割將運算任務分配到各CPE 上執行,通過DMA 數據傳輸機制將具有局部性的數據顯式地搬運到CPE 的片上內存LDM中,并通過2 個數據傳輸緩沖的動態切換,實現數據傳輸與數據計算的并行操作,其算法思想如圖4 所示.

Fig.4 Double buffer algorithm idea for CPE圖4 CPE 雙緩沖算法思想
除此之外,swHMAE 還可以通過多種方式對關鍵計算進行調試、錯誤定位和性能分析,進一步提升易用性.
swHMAE 的松耦合和模塊化設計使得用戶可以更加方便地集成新的眾核計算到swFLOWpro 系統中去.事實上,swHMAE 還可以支持其他的數據流計算系統,其僅需要在原始系統中做極少量的修改.
3 面向異構融合的兩級并行策略
在異構融合的眾核處理器上執行數據流圖的基本流程為:MPE 負責數據流圖的生成、優化和調度管理;在執行過程中,將已滿足執行需求的圖節點分配到眾核陣列上執行.
有2 種任務分配方法可以考慮:1)將每個節點調度到1 個CPE 上,CPE 陣列協同完成整個數據流圖的執行過程;2)將CPE 陣列視為一個整體部件,所有計算核心共同完成數據流圖中的一個節點.
第1 種任務分配方法與異構融合眾核架構的適應性并不好,其主要原因有3 點:1)單CPE 的訪存能力有限,其LDM 的容量大小也很難承載一個完整的圖節點計算邏輯,比如卷積、矩陣乘等常用算子,在單CPE 上執行效率較差;2)數據流圖的可并行性有限,考慮某些具有強相關性的數據流圖,每個節點都依賴于上一個節點的計算結果,則程序在這種模式下執行的效率就會很差,因為大部分時間內CPE 可能因為依賴另一個CPE 的計算結果而處于等待狀態;3)負載均衡問題,由于每個數據流圖節點運算量相差較大,保證各計算核心的負載均衡也是個難以解決的問題.
本文主要采用第2 種任務分配方法,也就是將CPE 陣列視為整體部件,所有CPE 協同完成一個圖節點的執行過程,這樣每個CPE 的計算任務量都在可以接受的范圍之內,而在每個圖節點內部,主要通過數據分割的方式將輸入數據映射到各個CPE 上,這樣能保證LDM 空間夠用和保證各計算節點的負載均衡性.并且,由于并行發生在圖節點內部,整體效率不會受限于數據流圖本身的可并行性.
圖5 是在sw26010pro 的單核組上運行一個數據流圖的示例.

Fig.5 Dataflow scheduling example for single CG圖5 面向單核組的數據流調度示例
輸入數據的后繼圖節點是Reshape,該節點是為了改變輸入形狀,屬于功能類算子,所以將其調度到MPE 上執行即可;其后的Matmul,Biasadd,Softmax 都是計算密集的圖節點,需要調度到CPE 陣列上進行眾核并行計算,例如,CPE 在執行Matmul 圖節點的時候,首先將矩陣進行分塊,每個CPE 執行子矩陣乘法運算,再通過CPE 陣列內部的RMA 操作進行全局通信,獲得原始矩陣的乘法運算結果.
sw26010pro 異構眾核芯片采用多核組設計,處理器內部包含6 個同構的核組,每個核組都有一個MPE和一個8×8 的CPE 陣列.因此,要在6 核組結構上實現更高層次的并行.
在單核組內部,我們將1 個圖節點分配到1 個MPE或者1 個CPE 陣列上執行,實現了低層次的圖節點內并行;在基于全片視角的多核組上,利用6 個等價隊列分別維護由上層圖計算過程產生的計算任務;在運行核組選擇過程中采用Round-Robin 的輪詢調度策略;在計算任務選擇中采用先入先出(FIFO)方法,進而支持高層次的圖節點間并行.這就是本節提出的兩級并行策略,該策略能夠充分適應sw26010pro的異構融合架構.
值得注意的是,圖節點間的并行要求圖節點之間沒有數據依賴關系,但實際上一般單輸入的數據流計算圖可并行性并不高,如果將不同的圖節點調度到不同核組上,由于圖節點之間的數據依賴關系,會導致部分核組處于空閑狀態,需要等待其他核組的計算結果才能開始計算.
為此,本文設計了一種圖分裂優化方法,首先將輸入數據進行平均分割,分割之后的每個輸入都進行相同的數據流圖執行流程,在輸出結果時再進行歸并,從而生成并行性更好的數據流計算圖.
以圖5 的數據流圖為例,將split值設置為2,經過圖分裂之后的數據流圖如圖6 所示.
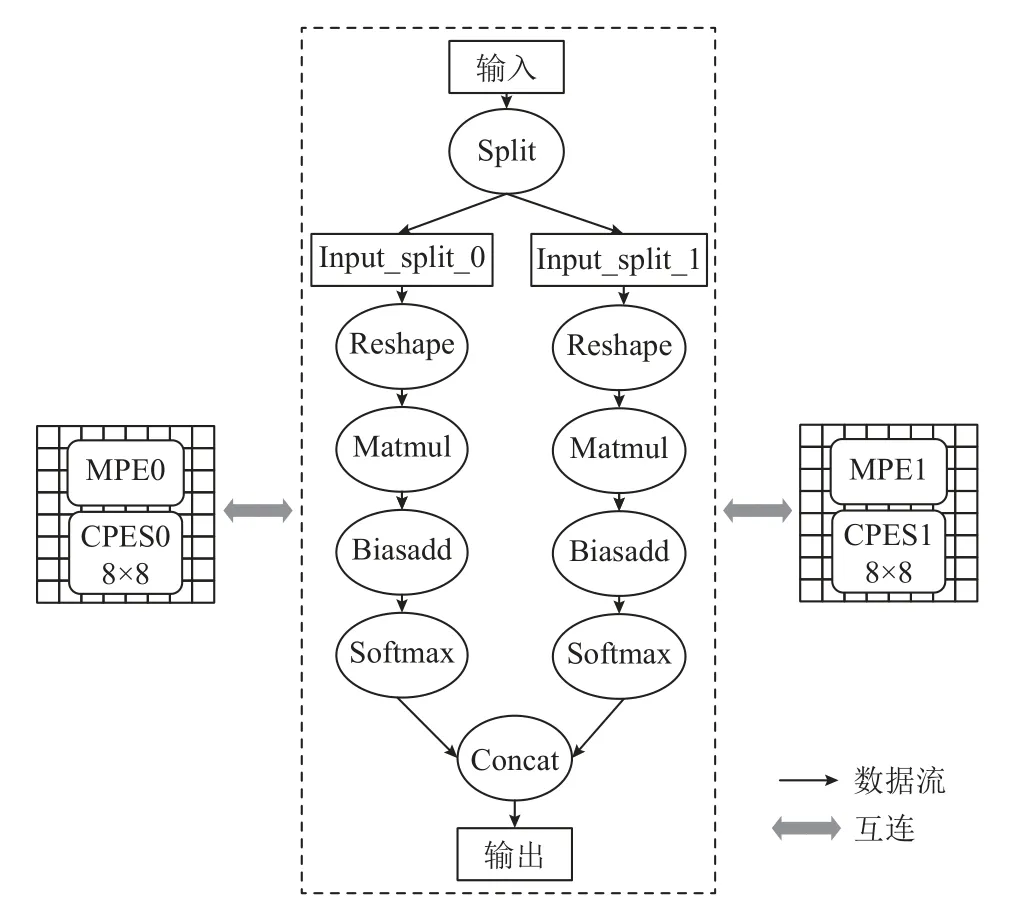
Fig.6 Dataflow scheduling example after graph splitting圖6 經過圖分裂之后的數據流調度示例
經過圖分裂之后,數據并行輸入到不同的數據流子圖中,每個子圖都是原數據流圖的一個復制,各個子圖之間沒有強相關性,從而具有很好的可并行性,可以映射到不同的處理器分區上執行.
圖分裂是一種與體系結構無關的圖變換技術,分裂值split可以調整,以適應不同的硬件體系結構.如果眾核處理器集成更多的核組數,只需要提升分裂值,無需改變整體算法就能充分利用硬件計算資源.
在具體實現上,本文采用多線程機制來管理圖節點的調度,根據核組數來確定線程個數.在sw26010pro上會啟動6 個線程來執行數據流圖,每個線程綁定在1 個核組上運行,這樣能保證各線程不存在資源沖突問題.
調度器將所有圖節點組織成任務池,并記錄每個節點的前繼節點.在執行過程中,一個圖節點可能處于不可用、可用、執行中、完成中這4 種狀態的一種.每種狀態對應一個任務池.
初始情況下,將沒有前繼節點的圖節點狀態設置為“待命”,其余節點狀態均設置為“不可用”.線程函數從任務池里通過搶占方式獲取一個圖節點任務,如果該圖節點的已處于可用狀態(所有前繼節點均已完成),則執行該節點,并將該節點狀態設置為“執行中”,完成后則設置狀態為“完成”.值得注意的是,線程選擇下一個執行節點時,優先從該節點的后繼節點中選取,如果后繼節點不可用,則從該節點前繼節點的其他后繼節點中選擇.這種搜索方法可以使得單個相對獨立的數據流子圖在一個線程內部完成.
圖節點狀態變換關系如圖7 所示.

Fig.7 Graph node state transformation diagram圖7 圖節點狀態變換圖
4 實驗
本文選擇6 種典型神經網絡模型作為數據流計算的輸入,通過TensorFlow 編程接口編寫數據流程序,實現這些模型的訓練過程,這些模型及其變種也是HPC+AI 領域應用經常使用的模型.具體模型信息如表1 所示.

Table 1 Six Typical Neural Network Models表1 6 種典型神經網絡模型
測試硬件平臺為sw26010pro 處理器,其包含6個核組,6 個MPE 和384 個CPE,全片主存空間大小為96 GB,每個CPE 的片上高速緩存LDM 大小為256 KB.
軟件環境為swFLOWpro 數據流計算系統、swHMAE核心計算加速引擎,以及swPython 編程環境.
本文選擇眾核加速比ManyAccRatio作為主要的性能評價指標,其定義為:
其中MPE_time表示在MPE 主核上的運行時間,CPE_time表示在單核組陣列上的運行時間.由于sw26010-pro 結構的特殊性,其與GPU,TPU 等人工智能專用芯片的性能對比意義不大,通過眾核加速比可以體現SwFlowpro 在sw26010pro 獨特的異構融合結構上的適配性和優化效果.
4.1 swHMAE 針對典型模型核心計算的眾核加速效果
本文使用swFLOWpro 構建了6 種典型模型,并統計了模型中所有核心計算(數據流圖節點)類型,選擇7 種典型核心計算類型,通過swHMAE 引擎進行眾核加速.具體統計信息如表2 所示.其中Conv2D,Conv2DBackpropFilter,Conv2DBackpropInput 都是卷積類計算,Matmul 是矩陣乘計算,Relu是激活類計算,Poolmax 是池化類計算,ApplyGradientDescent 是訓練更新參數計算.

Table 2 Typical Core Computing表2 典型核心計算
在表1 的6 種典型模型中,統計了典型核心計算在sw26010pro 的單核組CPE 上的運行時間,通過對比swFLOWpro 未經眾核優化的MPE 運行時間,并獲得眾核加速比.詳細測試數據如表3 所示.通過計算,獲得的各類型的典型核心計算眾核加速比如圖8 所示.

Table 3 Test Time of Typical Core Computing in Typical Models表3 典型模型中的典型核心計算測試時間 ms

Fig.8 The many-core acceleration ratios of convolutional core computing for different typical models圖8 不同典型模型的卷積類核心計算眾核加速比
卷積類運算是實驗的6 種典型模型的關鍵,也是swHMAE 實現眾核加速的重點運算.swHMAE 會根據輸入規模和相關參數,自適應選擇swDNN 庫中最優的算法實現.由圖8 實驗結果可以看出,Conv2D的眾核加速比達250~545,Conv2DBackpropFilter 的眾核加速比達107~583,Conv2DBackpropInput 的眾核加速比達90~310,加速效果良好.
其他核心計算類型的眾核加速比測試數據如圖9所示.

Fig.9 The many-core acceleration ratios of other core computing for different typical models圖9 不同典型模型的其他核心計算眾核加速比
針對矩陣乘類核心計算,swHMAE 從swBLAS庫中自適應選擇眾核算法.測試表明,矩陣乘核心計算的眾核加速比僅有26.1~38.7,由表3 可以看出,本文選擇的典型模型都是卷積類神經網絡,矩陣乘的計算量很小,不能充分發揮CPE 從核陣列的全部計算能力.除此之外,swBLAS 庫中矩陣是按列優先模式存儲,在接入模型時還需要先進行矩陣轉置.所以,矩陣乘的實際眾核加速比效果遠低于卷積類算子,在后續工作中可以針對矩陣轉置進行優化.
針對Relu 激活類運算,swHMAE 通過swDNN 庫進行加速,眾核加速比達到26.1~38.7.
除了計算密集類運算之外,模型中也會用到一些其他算子,這類算子雖然計算量小,但如果不進行眾核優化,則會成為性能瓶頸.如本文實驗選擇的更新參數操作(ApplyGradientDescent),是模型訓練中常見的算子類型,但缺乏專屬的算法庫支持.本文選擇在swHMAE 中直接集成其眾核優化算法,實驗表明眾核加速比達13.9~25.2.
測試結果表明,在sw26010pro 上,卷積類運算的眾核加速比要遠高于其他運算類型,這主要是因為國產異構眾核的架構設計對于卷積這類計算密集類運算的適應性更好.
4.2 swFLOWpro+swHMAE 針對典型模型訓練的眾核加速效果
本文使用swFLOWpro+swHMAE 運行6 種典型模型的訓練過程,單步訓練batch大小統一設置為32.
實驗分別測試在sw26010pro 的單MPE 和單CPE 陣列上的單步訓練時間,并計算眾核加速比.測試數據如表4 所示.

Table 4 Single Step Training Test Data of Typical Models表4 典型模型的單步訓練測試數據
由圖10 可見,VGG16 模型的眾核加速比最高,達到346,其余的模型加速比相差不大,在115~155之間.
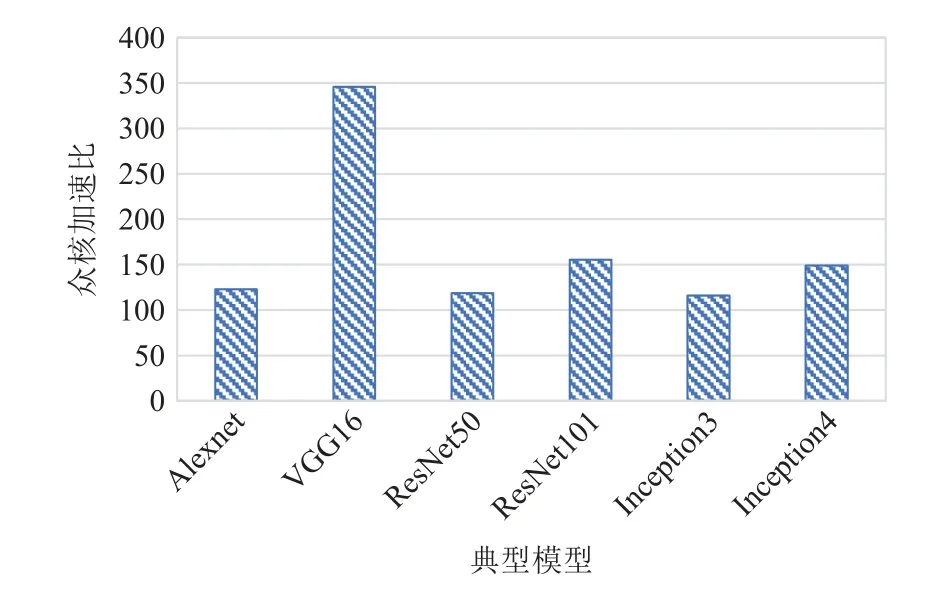
Fig.10 Muti-core acceleration ratios of typical models圖10 典型模型的眾核加速比
模型的性能與模型中各類型核心計算的性能緊密相關,由4.1 節測試結果可知,在sw26010pro 上,卷積類運算的眾核加速比要遠高于其他運算,所以卷積類運算占比較高的模型,在sw26010pro 上的整體加速比也更高.
本文統計了在6 種典型模型中,卷積類和非卷積類核心計算的運行時間占比,如表5 所示.這6 種典型模型都屬于卷積神經網絡,它們的卷積類運算占比為82.5%~97.4%.

Table 5 Core Computing Proportion of Convolutional and Non-Convolutional of Typical Models表5 典型模型的卷積類和非卷積類核心運算占比 %
表5 中,VGG16 的卷積類運算占比最高,達到了97.4%(11.1%+37.2%+49.1%),所以這個模型的眾核加速比也最高,Alexnet 的卷積類運算雖然占比高達93.5%(11.5%+27.2%+54.8%),但由于其卷積類運算的計算量較小,不能充分發揮sw26010pro 的計算能力,所以整體眾核加速比只有123.
實驗表明,針對典型模型的訓練過程,swFLOWpro+swHMAE 比原始運行模型,特別是卷積類計算占比較高的模型(如實驗中的VGG16)有顯著的眾核加速效果.
4.3 兩級并行優化效果
我們將sw26010pro 的單處理器(包含6 個核組)作為一個執行單元,測試6 種典型模型經過面向全片的兩級并行優化之后的加速效果.
首先,測試不使用圖分裂技術的6 個核組并行加速效果,在這種模式下,6 個核組的利用效率受限于不同模型構建出的數據流圖本身的可并行性,測試數據如圖11 所示.

Fig.11 Full chip acceleration ratios of typical models without graph splitting technology圖11 不使用圖分裂技術的典型模型全片加速比
加速比最高的是Inception4 模型,達1.49;最低的是Alexnet 模型,達1.19.這是因為,Inception 模型本身的數據流圖具有不錯的可并行性,而模型結構簡單的Alexnet 模型可并行性并不好.
整體而言,在不使用圖分裂的情況下,6 核組的加速比較低,這是因為計算圖的核心計算節點之間存在依賴關系,導致高層次的節點間并行不能同時進行計算,限制了并行效果,這也是本文提出圖分裂技術的主要原因.
然后,使用圖分裂技術進行優化,將split值分別設為2,4,6,并測試典型模型在全片6 核組上運行對比單核組(split=1)運行的加速比,測試數據如圖12所示.
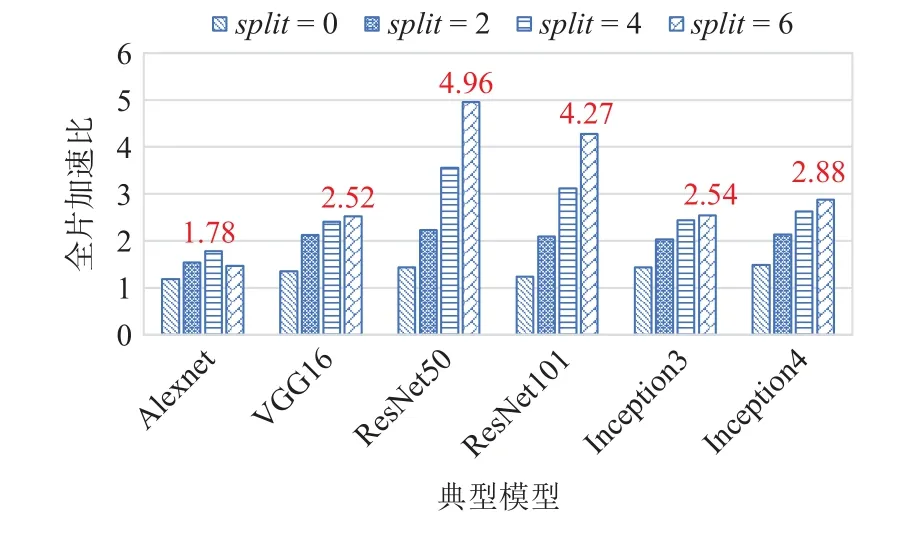
Fig.12 Full chip acceleration ratios of typical models with graph splitting圖12 典型模型使用圖分裂技術后的全片加速比
圖12 中加速效果最好的是ResNet50(split=6),加速比達4.96,并行效率達到了82.6%.通過使用圖分裂技術,選擇合適的參數split,典型模型全片加速比能達到1.78~4.96.
圖分裂技術結合面向異構融合的兩級并行策略,在sw26010pro 的多核組異構眾核結構上取得了很好的并行效果,測試表明,圖分裂技術針對典型模型的性能提升效果最高達到246%(ResNet50),最低也能達到50%(AlexNet).
值得一提的是,從實驗數據中也可以看出2 個問題:1)sw26010pro 的眾核結構對模型和核心計算的計算量要求較高,一些輕量級的模型無法充分利用眾核資源,所以Alexnet 的單核組和6 核組加速比都不理想.2)圖分裂結束也會帶來圖節點數量的大幅度增長,會增大內存需求,對于Inception 這種本身就具有一定并行性的計算圖,會出現圖節點膨脹的現象,進而增大節點調度和分配的開銷,所以其6 核組并行加速比只有2.54~2.88,這也是圖分裂技術目前存在的缺陷.
5 結論
本文提出了一種面向新一代國產異構眾核處理器的數據流計算系統swFLOWpro,該系統通過核心計算加速引擎swHMAE 支持在國產異構眾核處理器上的并行加速,并提出面向異構融合的兩級并行策略,支持面向國產異構眾核處理器全芯片視角的調度和并行方法.實驗表明,swHMAE 針對卷積類核心計算,眾核加速比達90~545,針對其他核心計算,眾核加速比達13.9~38.7;swFLOWpro+swHMAE 支持典型模型在sw26010pro 上的高效執行,VGG16 模型眾核加速比可達346;通過面向異構融合的數據流調度策略,全片ResNet50 加速比達4.96 倍,6 核組并行效率達到82.6%.
未來的工作主要包括3 個方面:1)繼續拓展swHMAE 支持的核心計算類型;2)優化面向全片多核組的兩級并行策略,優化圖分裂算法,探索更高效的數據流調度算法,提升圖節點間并行效率;3)完善系統,支持更多種類的神經網絡模型高效運行,并引入新的優化算法.
作者貢獻聲明:肖謙提出了技術方案,實現系統和撰寫論文;趙美佳和李名凡負責核心計算眾核優化實現和論文完善;沈莉和陳俊仕負責數據流調度算法實現和優化;周文浩和王飛負責部分實驗代碼編寫;安虹提出指導意見并修改論文.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
