404 Not Found
404 Not Found
基于視覺DQN的無人車換道決策算法研究*
付一豪,鮑 泓,梁天驕,付東普,潘 峰
(1.北京聯合大學 北京市信息服務工程重點實驗室,北京 100101;2.北京聯合大學 機器人學院,北京 100027;3.首都經濟貿易大學 管理工程學院,北京 100070)
0 引 言
隨著無人駕駛技術的逐漸落地,這些技術運行的安全性和魯棒性問題得到了廣泛關注。基于機器學習的算法無需嚴格的編程規則就能解決復雜問題,在對大量樣本數據進行適當訓練后,模型就擁有處理不可預見情況的能力[1,2]。但該類算法存在訓練需要大量數據,而數據的獲得以及標注成為發展的一大障礙。
近些年,隨著AlphaGo[3]在圍棋比賽上出色的發揮,深度強化學習迅速成為研究熱點并應用在各個領域[4~8]。有研究者將深度強化學習應用在換道決策算法中,比如基于深度Q網絡(deep Q network,DQN)的換道決策方法[9~12],其中,文獻[10]將周圍車輛的位置和速度信息進行卷積特征提取,讓DQN進行車速與換道的決策,但在實驗中過于理想化,雖可直接獲取所有車輛的信息,但沒有很好地解決DQN收斂速度慢的問題。另外,在基于視覺的無人車換道決策研究方面,DQN 相關文獻較少,大多數是使用DDPG(deep deterministic policy gradient)與長短期記憶(long short-term memory,LSTM)結合的方式[13],這些方法較為復雜,不易實現且實時性較差,難以滿足實際需求。
為了更好地解決上述問題,本文提出了基于視覺DQN的無人車換道決策模型。
1 理論與方法
本文所提決策模型結構如圖1 所示。基于視覺DQN的換道決策模塊,根據前方視覺圖像進行換道決策,基于DQN的速度決策模塊,根據前車及本車信息進行速度決策。
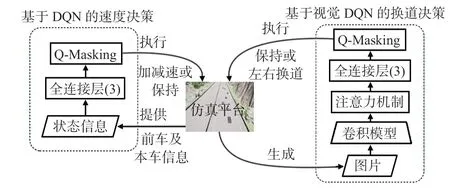
圖1 基于視覺DQN的無人車換道決策模型結構
1.1 DQN
DQN針對傳統的強化學習方法無法處理高維輸入的問題,使用神經網絡來替代原始的學習Q 表,直接將環境狀態映射為智能體動作。它擁有兩大特點:經驗回放和雙網絡結構。經驗回放可讓DQN進行離線訓練,并去除樣本相關性。雙網絡結構也是打亂相關性的一種機制,它建立2個參數不同、結構相同的網絡,分別為估值網絡和目標網絡。估值網絡擁有最新的參數,每訓練一段時間,就將其參數更新到目標網絡上。算法更新公式如式(1)所示
式中 Q(st,at)為估計值,Q′(st+1)為目標值,lr為學習率,R為獎勵值,γ為衰減因子,結構如圖2所示。
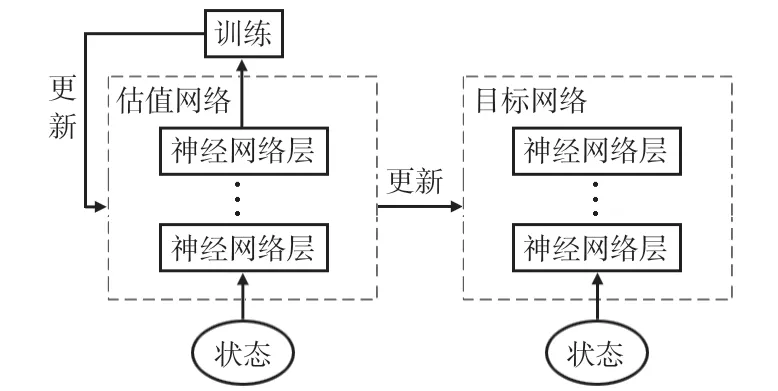
圖2 DQN結構
1.2 基于視覺DQN的換道決策算法
本文算法以DQN 為網絡主體,輸入數據為三原色(RGB)圖像。首先將Xception 卷積模型[14]加入在網絡前部,并與注意力機制結合,用以提取特征,接著將特征信息展平與全連接層結合輸出Q 值,最后結合Q-Masking 輸出最終動作,如圖3所示。
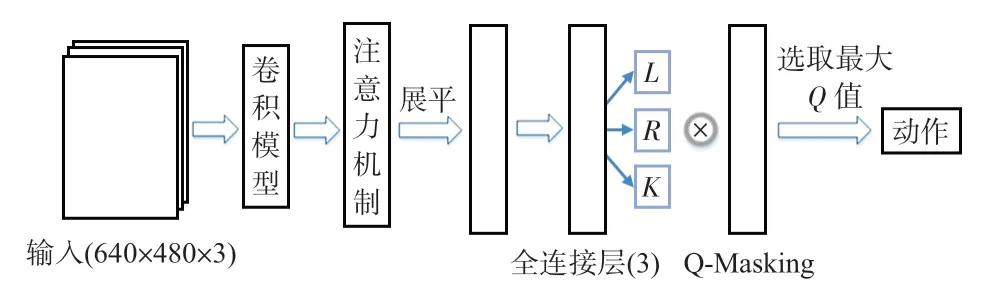
圖3 基于視覺DQN的無人車換道決策算法結構
1.2.1 注意力機制
本文網絡模型為了使DQN 聚焦圖像中的重要特征以提高網絡的收斂速度,特引入注意力機制,其模塊為卷積塊注意力模塊(convolutional block attention module,CBAM)[15],該模塊分為兩部分:通道注意力和空間注意力,通道注意力主要關注有意義的特征,而空間注意力則關注特征的位置信息。其過程如式(2)所示
式中 ?為element-wise乘法操作,Mc為通道注意力操作,F為輸入的特征圖,Ms為空間注意力操作,結構如圖4。
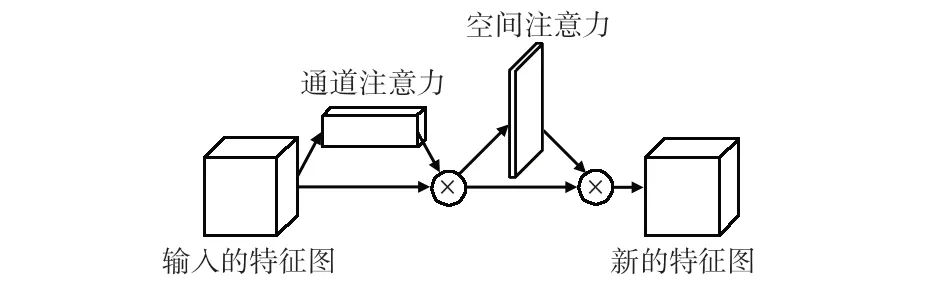
圖4 CBAM結構
1.2.2 狀態空間、動作空間、獎勵函數及Q-Masking定義
狀態空間s,動作空間a及獎勵函數R定義
其中,s為680 ×480的RGB圖像;a1為保持車道動作,a2,a3分別為左、右換道;dchange為期望換道距離,dfront為前車距無人車的距離,dtarget為目標車道(換道對應的車道)上目標車輛的距離;w1,w2皆為權重參數。該獎勵函數用以引導無人車做出合適的換道決策:當無人車保持車道時,按式(3)獎勵函數R公式中第一行給予獎勵;當無人車選擇換道時,按第二行給予獎勵。
Q-Masking設置:1)當車道為0 時禁止左轉,車道為3時禁止右轉;2)當無人車距目標車道車輛距離小于安全距離,則禁止換道。
1.3 基于DQN的速度決策模塊
主體網絡為DQN,輸入數據為前車距離、前車速度和本車車速。其結構如圖5所示。
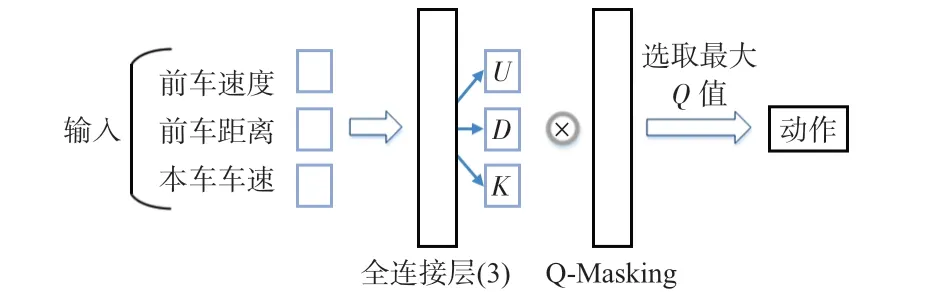
圖5 基于DQN的速度決策算法結構
狀態空間s,動作空間a及獎勵函數R定義
其中,vfront為前車車速,vself為本車車速;a4為保持車速,a5,a6分別為加、減速5 km/h;dwilling為無人車期望與前車保持的距離;w3為權重系數。該獎勵函數期望與前車保持合適的距離來應對換道需求。
Q-Masking設置:1)若前車較遠,則最高速行駛;若與前車距離接近安全距離,則強制減速。2)當車速達到最高時,禁止加速;當車速達到最低時,禁止減速。
1.4 Q-Masking
Q-Masking在本文的應用體現在以下3個方面:1)先驗規則的應用,例如在換道過程中,若無人車在最左側車道,則禁止向左換道;2)約束的應用,例如限速,當車速達到最高時,屏蔽加速動作;3)基于規則的方法應用,例如基于規則的碰撞時間方法,屏蔽導致碰撞的決策。
經過上述3個方面的應用,無人車直接將已有的先驗知識納入學習過程,無需為異常狀態(碰撞)設置負獎勵,從而簡化獎勵函數,擺脫這類先驗狀態的探索。其本身學習速度加快,在學習過程中更加專注于高級策略。
Q-Masking與DQN結合的算法流程如下:初始化記憶表M初始化估值網絡Q以及目標網絡Q′
其中,N為總回合數,Tmax為單回合最大時間,p為隨機概率,ε為貪婪因子即以多少概率采取隨機動作。
2 實驗結果與分析
2.1 實驗環境與相關參數設定
仿真平臺為Carla。它主要用于城市自動駕駛系統的開發、訓練以及驗證。實驗場景為具有四車道的高速路,如圖6(a)所示。實驗采用Python3.7 作為編程語言,神經網絡框架使用Tensorflow-GPU2.1,顯卡NVIDIA GTX3070。設定訓練最大回合數為10000,單回合最大時間為2 min,終止條件為無人車達到單回合最大時間或到達終點,車程為1 km,單回合車流量為40,中間兩車道車流量大,兩邊車道車流量相對較小,其車流量分布如圖6(b)所示。
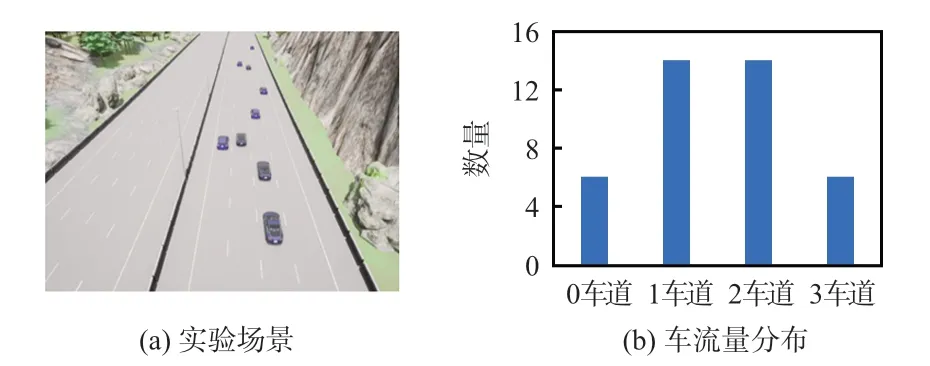
圖6 實驗場景與車流量分布
每輛車的初始位置在預設置的200個出生點中隨機選取,初始車速范圍為30 ~40 km/h,道路限速為50 km/h,車輛的行駛控制采用Carla自帶的自動駕駛功能。無人車的橫向控制采用傳統的純追蹤算法。
本文取衰減因子γ =0.95,學習率設置為0.001,批尺寸大小為32,記憶庫容量為20 000。此外,為了防止樣本失衡,特將記憶庫均分成2個部分:換道數據存儲與保持車道數據存儲,從而保證數據平衡性,使網絡最終能夠收斂。
2.2 算法訓練與分析
2.2.1 基于DQN的速度決策算法訓練與分析
本文提出的算法與2021 世界智能駕駛挑戰賽(天津)仿真賽中,自動駕駛賽項冠軍所采用的基于規則的換道決策算法[16]進行比較,最后通過分析總獎勵,來描述模型訓練結果,如圖7(a)所示。可知,本文算法在訓練350 次,獎勵趨于穩定,均值在290,優于對比算法的速度決策。
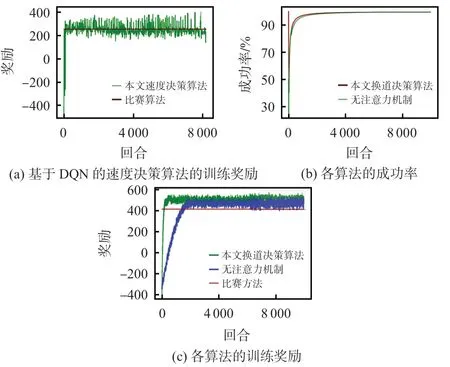
圖7 模型訓練結果
2.2.2 基于視覺DQN的換道決策算法訓練與分析
在基于DQN的速度決策算法的基礎上,本文對基于注意力機制的換道決策算法進行消融實驗并與比賽方法進行對比,通過分析規定時間內到達終點的成功率以及總獎勵,來描述模型訓練結果,如圖7(b)和圖7(c)所示。
由圖7(b)可知,訓練10 000 次后本文方法、無注意力機制方法的成功率分別為99.6%和99.3%,本文方法在訓練過程中成功率最高且提升快。由圖7(c)可知,本文算法在訓練400 次,獎勵趨于穩定,均值在510;無注意力機制算法在訓練1 800 次,獎勵趨于穩定,均值在440;比賽方法平均獎勵為410。綜上,本文方法可以明顯提升DQN 的收斂速度,同時體現了強化學習的優越性。
2.3 算法測試與分析
場景1的車流量為40,場景2的車流量為100。3種算法的測試結果如表1所示。

表1 3 種算法測試結果
由表1可知,場景1中,本文方法在平均獎勵和平均速度方面皆高于其他方法;場景2中,在車輛相對密集的條件下,3種方法的平均獎勵和平均速度有所下降,但本文方法仍能發揮較好的性能。
3 結 論
在基于視覺的無人車換道決策算法應用上,本文提出了基于視覺DQN的無人車換道決策算法,通過結合注意力機制和Q-Masking方法,簡化獎勵函數,解決了DQN收斂速度慢等問題。實驗結果表明:本文所提出的方法在滿足實時性要求的同時,在平均獎勵和平均速度方面都有較大提升,為無人駕駛技術提供了一種換道方案選擇。
