基于一致性圖卷積模型的多模態對話情緒識別
2023-10-17 12:07:01譚曉聰郭軍軍線巖團相艷
計算機應用研究 2023年10期
譚曉聰 郭軍軍 線巖團 相艷

摘 要:多模態對話情緒識別是一項根據對話中話語的文本、語音、圖像模態預測其情緒類別的任務。針對現有研究主要關注話語上下文的多模態特征提取和融合,而沒有充分考慮每個說話人情緒特征利用的問題,提出一種基于一致性圖卷積網絡的多模態對話情緒識別模型。該模型首先構建了多模態特征學習和融合的圖卷積網絡,獲得每條話語的上下文特征;在此基礎上,以說話人在完整對話中的平均特征為一致性約束,使模型學習到更合理的話語特征,從而提高預測情緒類別的性能。在兩個基準數據集IEMOCAP和MELD上與其他基線模型進行了比較,結果表明所提模型優于其他模型。此外,還通過消融實驗驗證了一致性約束和模型其他組成部分的有效性。
關鍵詞:多模態;情緒識別;一致性約束;圖卷積網絡;情感分析
中圖分類號:TP391 文獻標志碼:A 文章編號:1001-3695(2023)10-033-3100-07
doi:10.19734/j.issn.1001-3695.2023.02.0064
Consistency based graph convolution network for multimodal emotion recognition in conversation
Tan Xiaoconga,Guo Junjuna,b,Xian Yantuana,b,Xiang Yana,b
(a.Faculty of Information Engineering & Automation,b.Yunnan Key Laboratory of Artificial Intelligence,Kunming University of Science & Technology,Kunming 650500,China)
Abstract:Multimodal emotion recognition in conversations (MERC) is a task to predict the emotional category of the discourse in a dialogue based on its textual,audio,and visual modality.Existing studies focus on multimodal feature extraction and fusion of discourse context without fully considering the utilization of emotional features of different speakers.Therefore,this paper proposed a model of multimodal dialogue emotion recognition based on a consistent graph convolutional network.The model first constructed a graph convolutional network of multimodal feature learning and fusion,and obtained the context features of each discourse.On this basis,the average features of the speaker in the complete dialogue as the constraint to make the model learn more reasonable discourse features,so as to improve the performance of predicting emotion class.The paper compared with other baseline models on two benchmark datasets IEMOCAP and MELD.And the results show that the proposed model is superior to the other models.In addition,the paper verifies the consistency constraints and other components of the model through ablation experiments.
Key words:multimodal;emotion recognition;consistency constraint;graph convolution network;sentiment analysis
0 引言
隨著社交媒體的快速發展,對話中的多模態情緒識別(multimodal emotion recognition in conversation,MERC)受到學術界越來越多的關注,該任務旨在根據對話中話語的文本、語音、圖像、模態信息預測其情緒類別。由于對話本身具有多種要素,多模態對話情緒識別需要綜合考慮多種模態信息的提取和交互,以及對話中的上下文、說話人等信息的利用。在多模態信息的利用方面,研究者常常關注不同模態特征的表征和融合策略。例如Tsai等人[1]采用基于Transformer的框架對不同模態的特征進行抽取;文獻[2,3]提出基于張量融合網絡對不同的模態信息進行融合。在對話情緒識別(emotion recognition in conversation,ERC)方面,現有工作主要考慮對話中不同話語和模態表征的關系。例如文獻[4,5]提出基于圖卷積網絡(graph convolution network,GCN)的模型,通過圖卷積網絡的節點特征傳遞和學習機制可以解決不同話語的長距離依賴和話語模態特征融合問題,協助完成情緒分類。但該模型對模態進行平等的融合,會產生一定的信息冗余。此外,與傳統的獨白演講等情感識別不同,對話中個體的話語關系和語境建模有助于情緒識別。對話中的語境可歸納為歷史話語、會話中的時間性或說話人相關信息等。Li等人[6]提出可以從說話人的音頻信息中提取個性化信息。Hu等人[5]構建了一種說話人編碼器來區分不同的說話人。然而,這些模型在上下文信息提取方面的處理成本較高,或者具有說話人特征學習的局限性。
Wang等人[7]指出,對話中每個說話人具有自我依賴關系,即在情感慣性的影響下,說話人傾向于保持一種相對穩定的情緒狀態。在表1所示的一段節選對話中有兩個說話人,說話人B提出了一個針對說話人A丟失行李箱的補償方案。雖然說話人B的話語中有“bad”“frustrating”等負面情感詞,但他在整個談話過程中基本保持中性的情緒。本文統計了兩個多模態數據集中,說話人在對話中穩定情緒的比例(說話者穩定情緒比例的計算過程為:a)計算某段對話中說話者出現次數最多的情緒類別的話語數目,除以他在整個對話中總的話語數量;b)計算整個數據集中所有說話人所有對話中這個比例的平均值),數據集IEMOCAP[8]比值為68%,MELD[9]比值為72%。可以看出,在一段對話中,同一個說話人的情緒特征呈現一定的整體一致性,即同一個說話人的情緒特征在特征空間中應該具有一定的相似性。
基于以上分析可以看出,利用同一個說話人的情緒特征相似性作為指導將有助于情緒判別。現有研究雖然注意到說話人個性信息對于MERC的作用,但沒有充分考慮說話人情緒特征的整體一致性。為此,本文提出了一種基于一致性的多模態圖卷積網絡(consistency based multimodal graph convolution network,CMGCN)模型。CMGCN根據兩個話語是否屬于同一對話,以及是否具有模態特征相似性來構建多關系圖,采用圖卷積網絡對不同模態的信息進行信息傳遞和融合;同時,將話語情緒特征和對應說話人平均情緒特征的相似度作為一致性損失加入模型,以約束模型調整話語的特征學習;最后,利用調整后的情緒特征進行分類。通過大量的實驗表明,CMGCN在兩個公共數據集上優于基線模型,并且一致性有益于MERC。
1 相關工作
1.1 多模態情緒識別
在多模態情緒分析中,研究的重點是如何提取和融合不同的模態信息。非對齊多模態語言序列模型的多模態Transformer(multimodal transformer for unaligned multimodal language sequences model,MulT)[1]通過端到端方式處理數據對齊、跨模態元素之間的長期依賴關系。基于多模態Transformer的seq2seq模型(multi-modal seq2seq model,MMS2S)[10]使用三個單峰編碼器來捕獲文本、視覺和聲學模態的單模態特性,并使用多頭軟模態注意來控制不同模態的貢獻。張量融合網絡(tensor fusion network,TFN)[3]通過矩陣運算來融合特征。對每個模態進行維數展開,然后用不同模態的張量笛卡爾積來計算不同模態之間的相關性。記憶融合網絡(memory fusion network,MFN)[11]利用LSTM分別對模態內部進行建模,然后利用delta記憶注意網絡和多視圖門控記憶對不同模態之間的信息進行建模,可以保存多模態交互信息,得到更好的預測效果。
在模態信息融合方面,可以分為模型無關的融合方法和基于模型的融合方法[12]。其中模型無關的方法較簡單但實用性低,可以分為早期融合(特征級融合[13])、晚期融合(決策級融合)、混合融合;其中基于模型的融合方法較多,例如宋云峰等人[14]利用跨模態注意力機制融合兩兩模態。深度特征融合模型(deep feature fusion-audio and text modality fusion,DFF-ATMF)[15]通過多特征向量和多模態注意機制融合語音模態和文本模態。層次特征融合網絡(hierarchical feature fusion network,HFFN)[2]通過雙向跳躍連接的LSTM直接連接局部交互,并整合了兩層注意機制,以獲得多模態的整體視圖。此外,對話圖卷積模型DialogueGCN[4]使用圖卷積網絡來獲取遠距離上下文信息;深度圖卷積多模態融合模型(multimodal fusion via deep graph convolution,MMGCN)[5]同樣構造了一個圖網絡來建模不同的模態數據。利用圖卷積網絡的拓撲結構和節點信息傳輸的特征,可以很好地解決長距離依賴性和模態融合問題。
1.2 對話情緒識別
隨著ERC的應用越來越廣泛,出現了較多基于對話形式的情緒識別模型,包括會話記憶網絡(conversational memory network,CMN)模型[16]、交互式對話記憶網絡(interactive conversational memory network,ICON)模型[17]、對話循環神經網絡模型DialogueRNN[18]、以及基于常識知識的對話情緒識別(commonsense knowledge for emotion identification in conversations,COSMIC)模型[19]等。這些方法的主要思路是在文本模態情境下對上下文對話信息進行建模。
研究人員指出,不同說話人的話語應該被區別對待。會話記憶網絡CMN[16]通過注意機制對每個說話人的歷史話語和當前話語的表征進行整合,進行話語情感分類,從而模擬了說話人個體的狀態以及不同說話人狀態對當前話語的影響。與CMN類似,交互式會話記憶網絡ICON[17]利用兩個依賴于說話人的GRU和一個全局GRU來跟蹤整個對話過程中情緒狀態的變化,并利用一個多層記憶網絡來模擬全局情緒狀態。DialogueRNN[18]則通過一個具有注意機制的RNN來模擬說話人之間的情緒影響,并使用三個GRU來分別捕獲說話人之前的話語信息、上下文和情感信息。此外,深度圖卷積多模態融合模型MMGCN[5]增加了說話人身份嵌入,在一定程度上增強了情感表征,但這種嵌入只能區分不同的說話人,而不能區分同一說話人的不同話語之間的關系。
1.3 圖卷積網絡
圖卷積網絡由于其具有處理非歐幾里德數據的能力,在過去的幾年中得到了廣泛應用。主流GCN方法可分為譜域法和非譜域法[20]。譜域GCN方法[21]是基于拉普拉斯譜分解理論,只能處理無向圖。非譜域GCN方法[22]可以應用于有向圖和無向圖,但消耗更大的計算資源。近來研究人員提出了在不過度平滑的情況下加深譜域GCN的方法[23]。GCN在MERC任務上也有所應用,例如MMGCN模型使用具有深層的譜域GCN對多模態圖進行編碼,取得了較好的結果。但是該模型在對上下文進行建模時,僅考慮相同模態下相同對話、不同模態下相同話語的關系,而忽略了相同模態下不同對話、不同模態下不同話語之間的關系。
根據上述分析可以看出,多模態情緒識別側重于不同模態特征的提取與模態特征融合,而對話情緒識別需要考慮話語上下文的信息。因此,本文模型同時考慮了不同模態特征的學習和交互,以及話語上下文特征的提取,以更好地完成MERC任務。
2 本文模型
2.1 問題定義
給定多模態對話數據集,每個數據集中有若干個對話(dialogue),每個對話包含若干個話語(utterance),則整個數據集有N個話語,每個話語均有語音(a)、文本(t)、圖像(v)三種模態信息。ERC的任務是識別出第i個話語ui的情緒類別標簽i。
2.2 模型整體結構
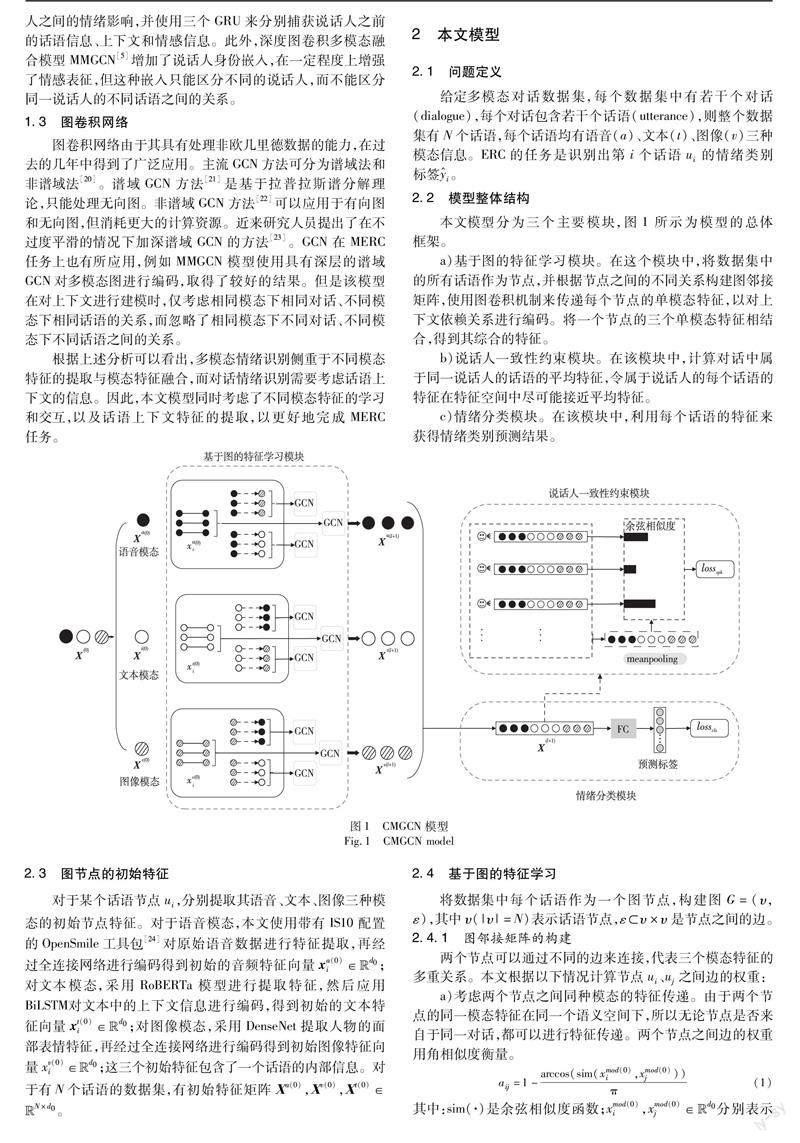
本文模型分為三個主要模塊,圖1所示為模型的總體框架。
a)基于圖的特征學習模塊。在這個模塊中,將數據集中的所有話語作為節點,并根據節點之間的不同關系構建圖鄰接矩陣,使用圖卷積機制來傳遞每個節點的單模態特征,以對上下文依賴關系進行編碼。將一個節點的三個單模態特征相結合,得到其綜合的特征。
b)說話人一致性約束模塊。在該模塊中,計算對話中屬于同一說話人的話語的平均特征,令屬于說話人的每個話語的特征在特征空間中盡可能接近平均特征。
c)情緒分類模塊。在該模塊中,利用每個話語的特征來獲得情緒類別預測結果。
2.3 圖節點的初始特征
對于某個話語節點ui,分別提取其語音、文本、圖像三種模態的初始節點特征。對于語音模態,本文使用帶有IS10配置的OpenSmile工具包[24]對原始語音數據進行特征提取,再經過全連接網絡進行編碼得到初始的音頻特征向量xa(0)i∈Euclid Math TwoRApd0;對文本模態,采用RoBERTa模型進行提取特征,然后應用BiLSTM對文本中的上下文信息進行編碼,得到初始的文本特征向量xt(0)i∈Euclid Math TwoRApd0;對圖像模態,采用DenseNet提取人物的面部表情特征,再經過全連接網絡進行編碼得到初始圖像特征向量xv(0)i∈Euclid Math TwoRApd0;這三個初始特征包含了一個話語的內部信息。對于有N個話語的數據集,有初始特征矩陣Χa(0),Χv(0),Χt(0)∈Euclid Math TwoRApN×d0。
2.4 基于圖的特征學習
將數據集中每個話語作為一個圖節點,構建圖G=(υ,ε),其中υ(|υ|=N)表示話語節點,ευ×υ是節點之間的邊。
2.4.1 圖鄰接矩陣的構建
兩個節點可以通過不同的邊來連接,代表三個模態特征的多重關系。本文根據以下情況計算節點ui、uj之間邊的權重:
a)考慮兩個節點之間同種模態的特征傳遞。由于兩個節點的同一模態特征在同一個語義空間下,所以無論節點是否來自于同一對話,都可以進行特征傳遞。兩個節點之間邊的權重用角相似度衡量。
其中:sim(·)是余弦相似度函數;xmod(0)i,xmod(0)j∈Euclid Math TwoRApd0分別表示第i和j個話語某種相同模態的初始特征,mod{a,t,v}。
b)考慮兩個節點之間不同模態的特征傳遞,可以根據兩個節點是否來自于一個對話,分為兩種情況:
(a)如果兩個節點來自于不同的對話,則不同模態特征不進行傳遞,這種情況下邊的權重為0。這是因為三種模態的初始特征抽取過程中雖然都進行了線性變換,不同模態特征在語義空間中可以認為基本對齊,但不同對話的場景和對話內容差異較大,加大了不同模態之間的鴻溝,因此本文認為這種情況下不應該進行特征傳遞。
(b)如果兩個節點來自于相同的對話,則由于對話的主題和內容一致,不同模態特征也是具有相關性的,需要進行特征傳遞。兩個節點之間邊的權重同樣用角相似度衡量:
其中:xmod′(0)i,xmod″(0)j∈Euclid Math TwoRApd0分別表示第i和j個話語不同模態的初始特征;mod′,mod″{a,t,v},mod′≠mod″。
根據上述節點之間邊的權重計算方法構建鄰接矩陣。對于某個節點的某種模態特征,可以構建三種鄰接矩陣來進行特征傳遞和學習。以節點的語音模態a的特征學習為例,如圖2所示,分別考慮語音模態a與自身語音模態a、文本模態t和圖像模態v的關系,可以構建三種圖鄰接矩陣,始特征矩陣Χa(0)進行更新。
此外,對于節點的文本模態t的特征學習,構建了三種圖鄰接矩陣Αtt、Αta、Αtv;對于節點的圖像模態v的特征學習,構建了三種圖鄰接矩陣Αvv、Αva、Αvt。
2.4.2 圖節點特征的學習
本文以節點的語音模態a的特征學習為例,說明不同模態的特征學習過程。如圖2所示,將三種圖鄰接矩陣Aaa、Aat、Aav,分別與節點的初始語音特征Xa(0)進行多層的GCN卷積,這里使用四層的GCN進行編碼,得到更新后的三種語音特征Xaa(l)、Xat(l)、Xav(l)。具體過程為
2.5 說話人一致性約束
3 實驗與分析
3.1 數據集
在IEMOCAP[8]和MELD[9]兩個多模態對話數據集進行了實驗,兩個數據集都包含文本、圖像、音頻三種模態。如表2所示,本文將數據集大致以8:1:1的比例分為訓練集、驗證集與測試集。
a)IEMOCAP。該數據集包含12 h的二元對話視頻,每個視頻都包含一個的二元對話,共有7 433條話語和151個對話。對話中的每一條話語都有六個類別的情感標簽,包括快樂、悲傷、中性、憤怒、興奮和沮喪。
b)MELD。該數據集同樣是一個多模態對話數據集,但MELD是一個多元的對話數據集。MELD包含了《老友記》電視劇中1 400多個對話和13 000條話語的文本、語音和圖像信息。每個對話中的每一個話語都被標注為憤怒、厭惡、悲傷、快樂、驚訝、恐懼或中性七個情緒類別之一。
3.2 實驗設置
本文所有實驗在CPU為Intel I9-10900K,顯卡為NVIDIA GeForce GTX 3090的實驗環境中進行,深度學習框架為PyTorch。本文將初始特征維度d0設置為200,d1設置為100。通過實驗比較,將GCN層數設置為4,dropout率設置為0.32。batchsize設置為58,epoch設置為120。使用Adam優化器[25]優化模型參數,學習率設置為0.000 221。超參數α和η分別設置為0.1和0.5;λ1設置為0.000 03,λ2設置為0.01。
3.3 基模型
為了驗證模型的有效性,本文模型與以下基線模型進行了比較。其中文本模態的初始特征采用GloVe和RoBERTa兩種。
a)DialogueRNN-{GloVe,RoBERTa}[18]。該模型使用了三個GRU來對說話者、來自前面話語的上下文和前面話語的情緒進行建模,三種不同類型的GRU都是以遞歸的方式連接的。
b)DialogueGCN-{GloVe,RoBERTa}[4]。該模型通過構建圖卷積網絡對會話進行建模,通過圖網絡解決了基于RNN的方法中存在的上下文傳播問題。
c)MMGCN-{GloVe,RoBERTa}[5]。該模型提出了一種多模態的圖卷積神經網絡,將對話中一句話對應三個模態的特征和說話嵌入分別進行拼接來構建多模態圖,之后通過多層GCN來進行編碼,最后拼接GCN編碼后的特征和圖的節點初始化特征,送入一個全連接層,完成情感分類。
d)COSMIC[19]。該模型以常識知識為基礎來進行建模,從而解決對話中話語級別的情感識別問題,其中常識要素包括心理狀態、事件、因果關系等。模型由三部分組成:從預訓練的Transformer語言模型中提取獨立于上下文的特征;從常識知識圖中提取常識特征;整合常識知識以設計更好的上下文表示并將其用于最終的情感分類。
e)TUCORE-GCN[26]。該模型提出將對話中的情緒識別視為基于對話的關系提取任務,即提取對話中出現的兩個參數之間的關系。通過構建對話圖并應用GCN機制結合BiLSTM,結合先前節點信息來預測結果。
4 實驗與討論
4.1 與基模型的比較
本文模型與其他基模型的實驗結果如表3所示。可以看出,本文模型在IEMOCAP和MELD數據集上都優于其他模型。對于IEMOCAP數據集,在本文模型結合GloVe預訓練向量的條件下,micro-F1達到67.32%,比性能第二的MMGCN提高了1.1%。本文模型結合RoBERTa的micro-F1達到67.92%,比性能第二的MMGCN-RoBERTa增加了0.66%。對于MELD數據集,在GloVe與RoBERTa預處理模型下本文模型的micro-F1分別比性能次優的模型提高了0.74%、0.44%。
本文進一步比較了不同模型的表現。DialogueGCN-{GloVe,RoBERTa}比DialogueRNN-{GloVe,RoBERTa}有更好的性能。分析原因是,DialogueRNN-{GloVe,RoBERTa}只對單個話語序列進行特征學習,而DialogueGCN-{GloVe,RoBERTa}使用GCN框架獲取每個話語的上下文信息,從而提高了性能。MMGCN-{GloVe,RoBERTa}在DialogueGCN-{GloVe,RoBERTa}上引入了不同的模態特性,進一步改善了模型。此外,在模型中使用RoBERTa的文本初始向量比GloVe更有效。在使用RoBERTa后,DialogueRNN、DialogueGCN和其他模型的micro-F1在IEMOCAP數據集上增加了約2%,在MELD數據集上增加了約7%。
4.2 一致性約束的實驗分析
4.2.1 約束條件的消融分析
為了研究CMGCN中一致性約束的貢獻,將模型中的一致性損失去掉,即只用分類損失來指導模型進行參數優化。消融結果如表4所示。
可以看出,一致性約束對于模型性能的影響較大。在去除一致性約束后,模型在兩個數據集的性能分別下降了近1%。這證明了一致性約束對于MERC作用較大。本文模型在一致性約束下能更好地捕捉每個說話人的情緒狀態,提升模型預測每條話語情緒的能力。
4.2.2 一致性約束中的特征分析
本文進一步分析了使用不同特征計算一致性約束損失對模型的影響。CMGCN使用的是GCN學習更新的特征向量來計算一致性約束損失。而CMGCNitl則使用三個模態的初始特征向量拼接來計算一致性約束損失。表5展示了實驗結果,與CMGCNitl相比,CMGCN的micro-F1在兩個數據集上分別提高了1.38%和1.49%。分析原因可能是,經過圖卷積學習后的節點特征具有更強的表征能力,模型使用這些節點特征作為一致性約束能獲得更好的情緒分類。
4.3 鄰接矩陣的消融分析
為了證明CMGCN中鄰接矩陣的合理性,本文使用以下方法來計算邊權重,構造新的鄰接矩陣來進行比較:
a)CMGCNadj_A。在該模型的鄰接矩陣Aaa、Att、Avv中,如果兩個節點來自不同的對話,則將它們的邊權重置為0。其他鄰接矩陣的構建方式保持不變。
b)CMGCNadj_B。對于鄰接矩陣Amod′mod″,mod′≠mod″,即使兩個節點來自不同的對話,也使用角相似度來計算邊的權重。
本文在兩個數據集上用新的鄰接矩陣來測試模型的性能,比較結果如表6所示。與CMGCNadj_A相比,本文模型的micro-F1得分在兩個數據集上分別增加了1.11%和1.52%。結果表明,即使兩個話語來自不同的對話,它們相同的模態之間也會存在相關性。因此,在這些節點之間傳輸相同的模態特征是有益的。同時,CMGCNadj_B的micro-F1比CMGCN分別降低了1.07%和2.22%。原因可能是:如果兩個節點來自不同的對話,它們不同的模態之間存在語義差距,這種情況下不應該進行特征傳遞,否則過度的模態特征傳播會干擾節點的特征學習。
4.4 不同模態設置對比
為了驗證多種模態組合下的實驗結果,本文做了單一模態與任意兩種模態組合設置下的實驗,結果如表7所示。對基于單一模態的情緒識別模型而言,選擇某一種模態的初始特征進行DeepGCN特征學習,并用更新后的單一模態特征進行情緒預測;對基于兩種模態的情緒識別模型而言,選擇其中兩種模態的初始特征構建鄰接矩陣,從而對兩種模態特征進行特征學習。
從表7的結果可以看出,當同時使用三種模態進行情緒預測時,能獲得最優的性能,證明了多模態設置的優越性。在單一模態下,圖像模態表現最差,原因可能是圖像模態中的手勢動作或者臉部表情并不能很好地表征當前話語的情緒狀態;相較于視覺模態,語音語調的特征提取更能表征情緒狀態,所以性能優于基于單一圖像模態的模型;三種單一模態中,文本模態表現最好,而在文本模態基礎上添加語音和圖像模態后,可以比單一的文本模態帶來額外的性能改進。
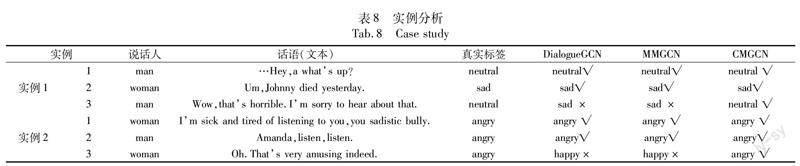
4.5 實例分析
本文對IEMOCAP數據集中兩個不同對話進行了實例分析,如表8所示,其中“√”表示分類正確,“×”表示分類錯誤。DialogueGCN和MMGCN錯誤地將實例1的第3句話預測為“sad”的情緒類別,原因可能是該話語中含有負向的情緒詞。同樣地,由于受到“amusing”一詞的干擾,DialogueGCN和MMGCN未能正確預測實例2的第3句話語的“angry”情緒。由于本文方法能夠感知多模態的語境信息和說話者的整體一致性,從而能正確捕捉到潛在的情緒類別。
5 結束語
本文提出了一種基于一致性約束的MERC圖卷積網絡,該網絡將話語作為圖網絡的節點,通過GCN的特征傳遞和交互機制使模型能學習到話語的不同模態上下文特征;同時,利用說話人一致性約束引導模型學習到更符合對話情感邏輯的話語情緒特征,從而提高識別準確性。實驗結果表明,本文模型在公共數據集上的性能優于其他對比模型。通過消融實驗驗證了一致性約束的有效性和重要性。本文方法皆在模態信息完整的情況下進行,未來工作將對模態信息受損下的模態模糊問題的魯棒性融合問題進行探討。
參考文獻:
[1]Tsai Y H H,Bai Shaojie,Liang P P,et al.Multimodal transformer for unaligned multimodal language sequences[EB/OL].(2019-06-01).https://arxiv.org/abs/1906.00295.
[2]Mai Sijie,Hu Haifeng,Xing Songlong.Divide,conquer and combine:hierarchical feature fusion network with local and global perspectives for multimodal affective computing[C]//Proc of the 57th Annual Meeting of Association for Computational Linguistics.2019:481-492.
[3]Zadeh A,Chen Minghai,Poria S,et al.Tensor fusion network for multimodal sentiment analysis [EB/OL].(2017).https://arxiv.org/abs/1707.07250.
[4]Ghosal D,Majumder N,Poria S,et al.DialogueGCN:a graph convolutional neural network for emotion recognition in conversation[EB/OL].(2019).https://arxiv.org/abs/1908.11540.
[5]Hu Jingwen,Liu Yuchen,Zhao Jinming,et al.MMGCN:multimodal fusion via deep graph convolution network for emotion recognition in conversation[EB/OL].(2021-07-14).https://arxiv.org/abs/ 2107.06779.
[6]Li Jiwei,Galley M,Brockett C,et al.A persona-based neural conversation model[EB/OL].(2016).https://arxiv.org/abs/ 1603.06155.
[7]Wang Yan,Zhang Jiayu,Ma Jun,et al.Contextualized emotion recognition in conversation as sequence tagging [C]// Proc of the 21st Annual Meeting of the Special Interest Group on Iscourse and Dialogue.2020:186-195.
[8]Busso C,Bulut M,Lee C C,et al.IEMOCAP:interactive emotional dyadic motion capture database [J].Language Resources and Evaluation,2008,42(4):335-359.
[9]Poria S,Hazarika D,Majumder N,et al.MELD:a multimodal multi-party dataset for emotion recognition in conversations [EB/OL].(2018).https://arxiv.org/abs/1810.02508.
[10]Zhang Dong,Ju Xingchen,Li Junhui,et al.Multi-modal multi-label emotion detection with modality and label dependence[C]//Proc of Conference on Empirical Methods in Natural Language Processing.2020:3584-3593.
[11]Zadeh A,Liang P P,Mazumder N,et al.Memory fusion network for multi-view sequential learning[C]//Proc of the 32nd AAAI Confe-rence on Artificial Intelligence.2018:5634-5641.
[12]任澤裕,王振超,柯尊旺,等.多模態數據融合綜述 [J].計算機工程與應用,2021,57(18):49-64.(Ren Zeyu,Wang Zhenchao,Ke Zunwang,et al.Review of multimodal data fusion[J].Computer Engineering and Applications,2021,57(18):49-64.)
[13]劉繼明,張培翔,劉穎,等.多模態的情感分析技術綜述 [J].計算機科學與探索,2021,15(7):1165-1182.(Liu Jiming,Zhang Pei-xiang,Liu Ying, et al.Review of multimodal sentiment analysis techniques[J].Journal of Frontiers of Computer Science & Techno-logy,2021,15(7):1165-1182.)
[14]宋云峰,任鴿,楊勇,等.基于注意力的多層次混合融合的多任務多模態情感分析 [J].計算機應用研究,2022,39(3):716-720.(Song Yunfeng,Ren Ge,Yang Yong,et al.Multi-task multimodal sentiment analysis based on multi-level mixed fusion based on attention[J].Application Research of Computers,2022,39(3):716-720.)
[15]Chen Feiyang,Luo Ziqian,Xu Yanyan,et al.Complementary fusion of multi-features and multi-modalities in sentiment analysis[EB/OL].(2019).https://arxiv.org/abs/1904.08138.
[16]Hazarika D,Poria S,Zadeh A,et al.Conversational memory network for emotion recognition in dyadic dialogue videos[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.2018:2122-2132.
[17]Hazarika D,Poria S,Mihalcea R,et al.ICON:interactive conversational memory network for multimodal emotion detection[C]//Proc of Conference on Empirical Methods in Natural Language Processing.2018:2594-2604.
[18]Majumder N,Poria S,Hazarika D,et al.DialogueRNN:an attentive RNN for emotion detection in conversations[C]//Proc of AAAI Confe-rence on Artificial Intelligence.2019:6818-6825.
[19]Ghosal D,Majumder N,Gelbukh A,et al.COSMIC:commonsense knowledge for emotion identification in conversations [EB/OL].(2020).https://arxiv.org/abs/2010.02795.
[20]Velic′kovic′ P,Cucurull G,Casanova A,et al.Graph attention networks [EB/OL].(2017).https://arxiv.org/abs/ 1710.10903.
[21]Zhang Dong,Wu Liangqing,Sun Changlong,et al.Modeling both context-and speaker-sensitive dependence for emotion detection in multi-speaker conversations[C]//Proc of the 28th International Joint Conference on Artificial Intelligence.2019:5415-5421.
[22]Schlichtkrull M,Kipf T N,Bloem P,et al.Modeling relational data with graph convolutional networks [C]//Proc of European Semantic Web Conference.Cham:Springer,2018:593-607.
[23]Li Guohao,Muller M,Thabet A,et al.DeepGCNs:can GCNs go as deep as CNNs? [C]//Proc of IEEE/CVF International Conference on Computer Vision.2019:9267-9276.
[24]Schuller B,Batliner A,Steidl S,et al.Recognising realistic emotions and affect in speech:state of the art and lessons learnt from the first challenge[J].Speech Communication,2011,53(9-10):1062-1087.
[25]Kingma D P,Ba J.Adam:a method for stochastic optimization[EB/OL].(2014).https://arxiv.org/abs/ 1412.6980.
[26]Lee B,Choi Y S.Graph based network with contextualized representations of turns in dialogue[EB/OL].(2021).https://arxiv.org/abs/ 2109.04008.
[27]Li Yujia,Tarlow D,Brockschmidt M,et al.Gated graph sequence neural networks[EB/OL].(2015).https://arxiv.org/abs/1511.05493.
[28]Chen Ming,Wei Zhewei,Huang Zengfeng,et al.Simple and deep graph convolutional networks [C]//Proc of International Conference on Machine Learning.2020:1725-1735.
收稿日期:2023-02-14;修回日期:2023-04-19基金項目:國家自然科學基金地區項目(62162037);云南省科技廳面上項目(202001AT070047,202001AT070046)
作者簡介:譚曉聰(1998-),男,廣東茂名人,碩士研究生,主要研究方向為自然語言處理、多模態情感分析;郭軍軍(1987-),男,山西呂梁人,副教授,博士,CCF會員,主要研究方向為自然語言處理、神經機器翻譯、多模態情感分析;線巖團(1981-),男,云南芒市人,副教授,博士,CCF會員,主要研究方向為自然語言處理、信息檢索;相艷(1979-),女(通信作者),云南大理人,副教授,博士,CCF會員,主要研究方向為自然語言處理、情感計算(sharonxiang@126.com).
