基于腦電小波特征與長短期記憶神經網絡的駕駛疲勞識別方法*
2023-10-17 08:47:00羅旭張巖楊亮
汽車工程師 2023年10期
羅旭 張巖 楊亮
(沈陽師范大學,沈陽 110034)
1 前言
駕駛疲勞是導致交通事故發生的重要因素。在我國,疲勞駕駛引起的事故約占總事故數量的20%[1]。全球每年發生的交通事故高達10 多億次,且疲勞駕駛造成的事故死亡人數占所有交通事故死亡人數的70%左右[2]。因此,及時準確地識別駕駛疲勞并進行預警,對交通安全具有重要意義。
識別疲勞駕駛的方法主要有面部圖像識別法、眼動識別法、肌電信號分析法和腦電信號分析法等[3],其中腦電信號分析法被認為是識別疲勞駕駛狀態的“金標準”[4]。文獻[5]通過分析運動成像任務中的頂葉α 波和額葉θ 波,發現人感到疲勞時注意力水平下降,導致α 能量增加。文獻[6]提出了一種基于模型的特征提取策略,將主成分分析網絡(Principal Component Analysis Net,PCANet)實際應用于基于腦電圖(Electro-EncephaloGram,EEG)的駕駛疲勞識別研究,獲得了較高的識別精度和效率,并發現大腦的頂葉和枕葉與駕駛疲勞密切相關。文獻[7]提出了基于前額腦電信號的多尺度小波系數作為特征指標的識別方法,理論上駕駛疲勞識別的平均正確率達91.8%。文獻[8]基于疲勞駕駛者的腦電波和正常駕駛者的腦電波有明顯區別的特點,設計了一套實時疲勞駕駛檢測與自動報警系統。研究發現,在駕駛員疲勞駕駛過程中,腦電信號的功率譜比值表現出規律性變化[9-11]。文獻[12]基于長短期記憶(Long Short-Term Memory,LSTM)網絡與卷積神經網絡(Convolutional Neural Networks,CNN),以單通道腦電信號中的部分特征識別受試者獨立的嗜睡狀態,平均識別準確率為72.97%。文獻[13]在時空域深度卷積雙向長短期記憶神經網絡模型中,對非疲勞與疲勞2 種精神狀態進行分類測試評估,分類精度均約為87%。
現有的基于腦電的疲勞識別方法,特別是基于LSTM 分類網絡的識別方法,通常使用單通道或少數局部通道的腦電信號進行分析,且提取的腦電特征值維度較低,導致分類性能不穩定。本文采集真實駕駛環境下的駕駛員非疲勞與駕駛疲勞狀態腦電信號,利用離散小波變換對腦電信號進行濾波并提取多維度特征值,采用LSTM神經網絡對2類特征數據進行分類識別,通過試驗數據分析通道位置與通道數量對分類性能的影響,并采用合適的特征組合與通道組合獲得較好的分類性能。
2 腦電數據采集
2.1 環境設置
在真實的高速公路駕駛環境下使用Emotiv 腦電儀采集腦電信號,采樣率為128 Hz,如圖1所示。

圖1 Emotiv腦電儀
Emotiv 腦電儀14 個通道布局參照10-20 系統國際標準,如圖2所示。
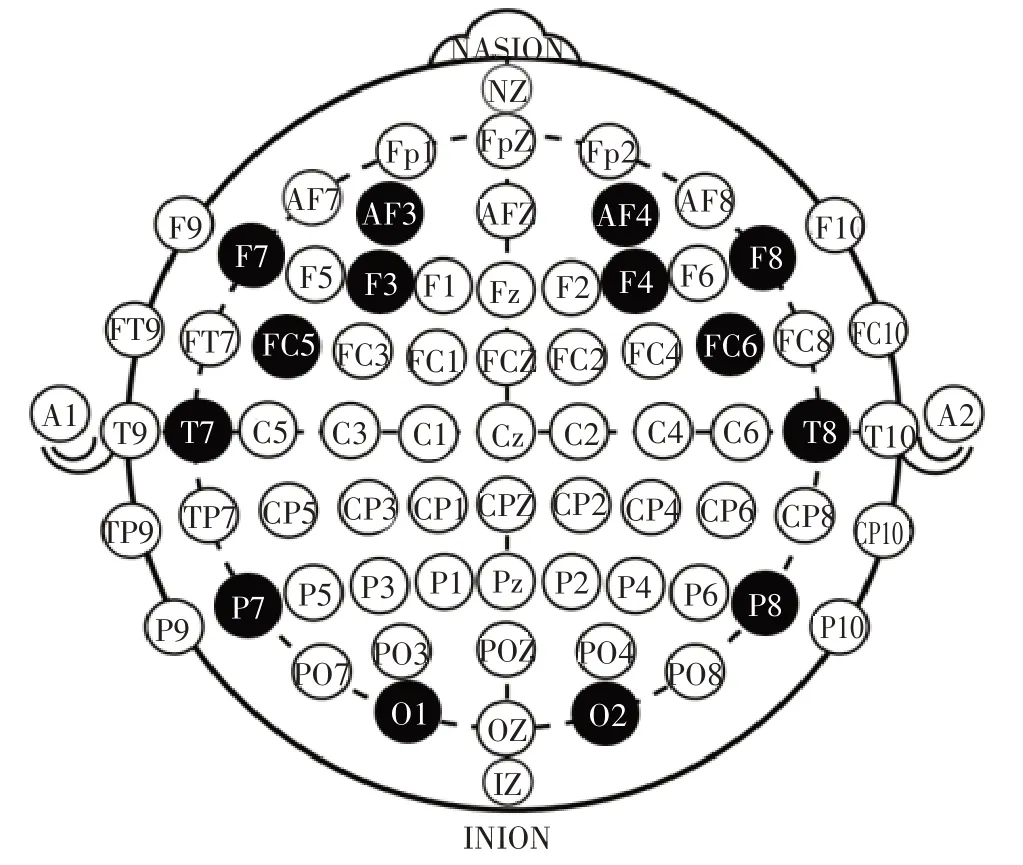
圖2 10-20系統國際標準的通道
被試者年齡范圍為30~55 歲,身體健康且無睡眠相關疾病,自愿參與試驗。在采集腦電前48 h內,禁止被試者飲用對神經產生刺激的飲品,被試者沒有高水平的身心活動,保證正常的睡眠和飲食。
2.2 采集過程
根據《中華人民共和國道路交通安全法實施條例》,駕駛員連續駕駛4 h 即認定為駕駛疲勞。在腦電采集試驗中,當駕駛員駕駛時間約為10 min 時,采集3 min的腦電數據作為非疲勞數據,當駕駛時間達4 h 以上時,采集3 min 的腦電數據作為駕駛疲勞數據,共采集了33名駕駛員的腦電數據。為提高駕駛疲勞數據的準確性,在駕駛4 h 后,每名駕駛員填寫《疲勞癥狀自評量表》[14],自評量表得分大于平均分的駕駛員(共16名)的腦電數據被選為試驗組數據。
在休息狀態下,經過4 h 被試者也會積累一定的疲勞,因此還需要采集休息狀態開始時和休息4 h后的2種腦電信號作為對照組數據。試驗組和對照組數據都用于神經網絡的分類訓練與測試,如果在測試結果中,試驗組的分類準確率明顯高于對照組,則可驗證算法對非疲勞與駕駛疲勞分類的有效性,即排除時間因素。對照組中采集了16個被試者的腦電信號,每次采集時長為3 min。
3 特征提取
3.1 小波分解
腦電信號在采集過程中摻雜大量噪聲,在識別前必須經過濾波。針對腦電信號的非線性與非平穩性的特點,考慮到小波變換是較為有效的時頻分析方法[15],因此本文采用快速離散小波變換(Discrete Wavelet Transformation,DWT)[16]設計濾波器。信號經小波變換后,可產生壓縮式的小波系數,分別為代表原信號低頻部分的逼近小波系數和代表高頻部分的細節小波系數。腦電信號經離散小波變換多級分解,得到頻率低于32 Hz(腦電信號頻率主要分布在0~30 Hz范圍內)的4個子帶內的小波包系數,從而過濾掉頻率較高的干擾信號。離散小波分解過程如下:腦電信號經首次分解,得到第1層低通逼近分量A1和高通細節分量D1;對A1繼續分解得到第2層的逼近分量和細節分量AA2和DA2;以此類推,一直分解到第4 層。在第4 層中,將小波分解擴展為小波包分解,即除了分解逼近分量AAA3,得到AAAA4和DAAA4外,還分解細節分量DAA3,得到ADAA4和DDAA4。為表述方便,將這4 個分量分別標記為P1、P2、P3和P4。每個分量包含若干分解得到小波系數,分解過程如圖3所示。
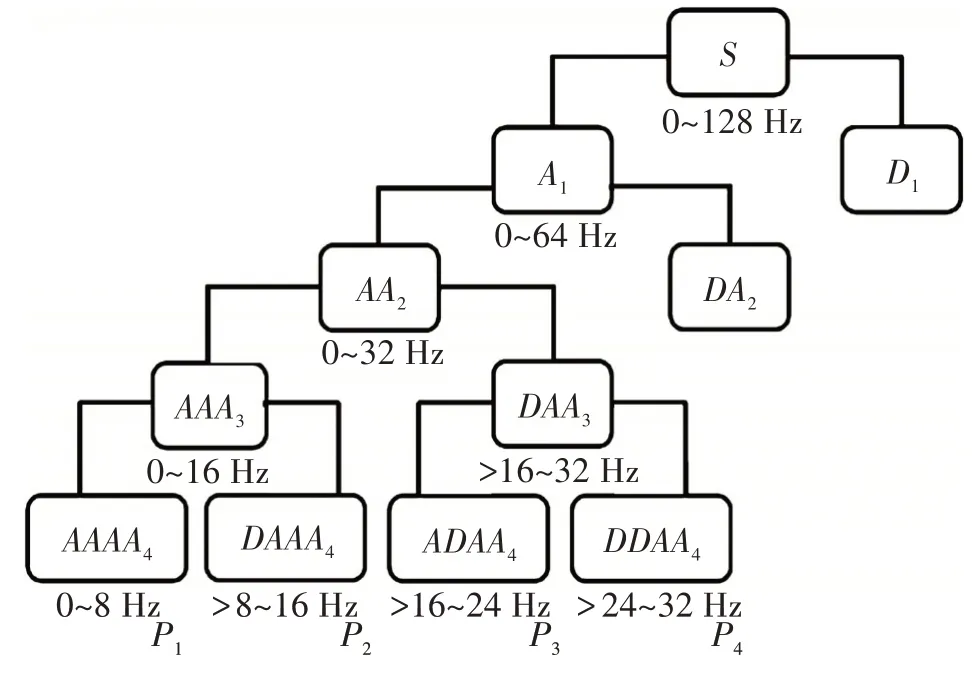
圖3 小波分解過程
3.2 提取特征
為提高2 種狀態小波系數的區分度,將小波系數的多種特征值組合在一起構成特征向量,這些特征值包括小波系數的最大值、最小值、均值、標準差、能量值和相對能量值。設Ejmax、Ejmin、Ejavg和Ejstd分別為分量Pj中小波系數的最大值、最小值、平均值和標準差。
小波系數能量值計算如下:
式中,xj(i)為分量Pj的第i個小波系數;Ej為分量Pj的能量值。
分量相對于整體的相對能量值為:
式中,Ejr為能量值Ej與全部4 個分量能量之和的比值。
分量之間的相對能量為:E1/E2、E2/E3、E3/E4、(E1+E2)/(E3+E4)。
由以上特征值構成含28 個特征值的特征向量為:[E1;E2;E3;E4;E1r;E2r;E3r;E4r;E1max;E2max;E3max;E4max;E1min;E2min;E3min;E4min;E1avg;E2avg;E3avg;E4avg;E1std;E2std;E3std;E4std;E1/E2;E2/E3;E3/E4;(E1+E2)/(E3+E4)]。
特征向量所用的腦電數據需要從固定周期的分析窗口時間內采集,分析窗口的時長和采集頻率決定采集腦電信號的數量。考慮到實際應用中的疲勞識別實時性要求,針對128 Hz 的采集頻率,本文設定分析窗口時長為1 s。對于1 個腦電儀通道,1 s 的分析窗口內可以采集128 組腦電數據。從128組腦電數據中提取與之對應的28個特征值,這樣由每次采集的3 min 腦電數據,可構造一個180×28 的特征矩陣,這些特征矩陣將作為神經網絡的訓練與測試數據。
4 利用LSTM 神經網絡進行分類識別
4.1 LSTM 神經網絡
LSTM 神經網絡是一種特殊的遞歸神經網絡[17],其單元體系結構如圖4 所示。LSTM 神經網絡的核心部件是LSTM 單元,LSTM 單元通過使用3 個門對單元狀態進行移除或添加狀態信息。

圖4 LSTM單元體系結構
第1 個門(遺忘門)決定從單元中移除哪些信息,此門基于sigmoid函數構建:
式中,σ為sigmoid激活函數,負責將數值壓縮在(0,1)范圍內;W為權值矩陣;x為t時刻輸入向量;h為(t-1)時刻單元隱藏狀態;bf為偏移向量;ft為t時刻遺忘門狀態。
第2 個門(輸入門)由sigmoid 函數和tanh 雙曲正切激活函數組合構成,2 個函數分別負責決定哪些值將被更新和創建更新的向量,tanh 函數負責將數值壓縮在(-1,1)范圍內:
根據式(3)~式(5)的函數值更新t時刻單元狀態ct:
式中,Wi、Wc為權值矩陣;bi、bc為偏移向量;it為t時刻輸入門狀態;c~t為t時刻長記憶輸出值;⊙為哈達瑪積(Hadamard Product)。
第3 個門(輸出門)基于更新的單元狀態和sigmoid 函數計算當前狀態的最后輸出,此sigmoid函數決定單元狀態的哪一部分作為輸出信息:
式中,ot為t時刻輸出門狀態;Wo為權值矩陣;bo為偏移向量。
由LSTM單元構成的LSTM層為LSTM神經網絡中的核心組成部分。
具有C個長度與S個特征的時序X通過LSTM 層的流程如圖5 所示。
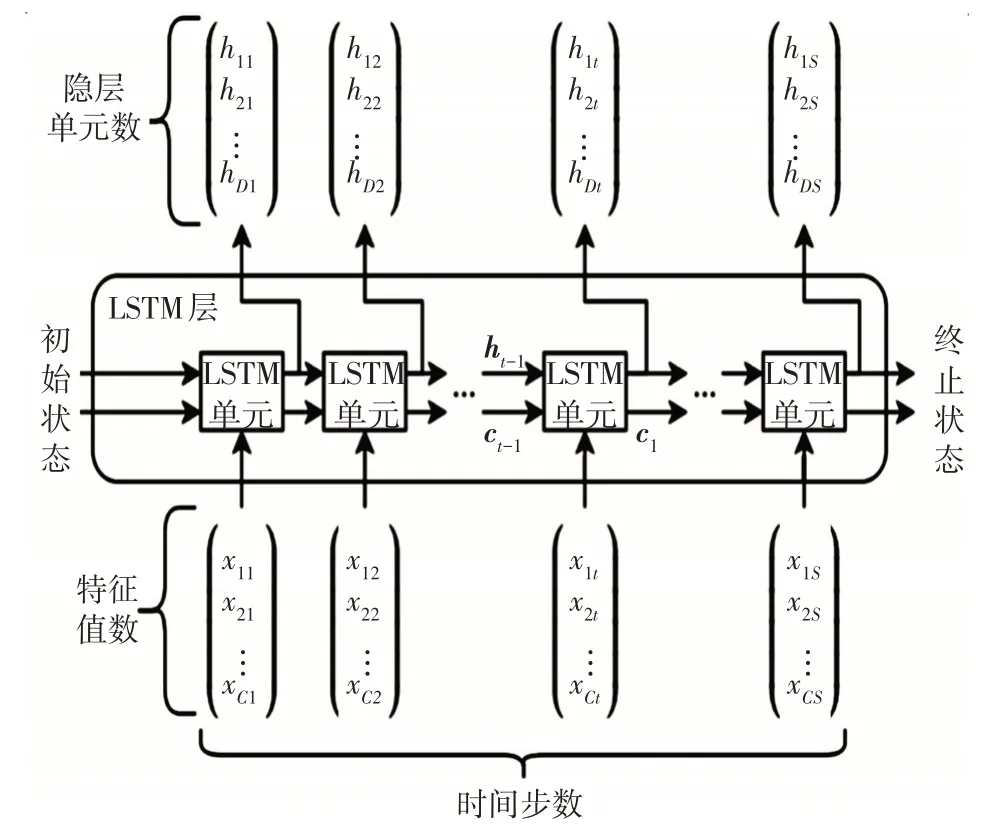
圖5 LSTM單元體系結構
第1 個LSTM 單元使用網絡的初始狀態和第1 個時間步的序列來計算第1 個輸出和更新后的單元狀態。其中ht和ct分別表示t時刻的輸出和單元狀態,h的長度為D。在時間步t上,該單元使用網絡的當前狀態(ct-1,ht-1)和下個時間步的序列來計算輸出和更新后的單元狀態ct,單元狀態包含從前面的時間步中獲得的信息。在每個時間步中,該層都會在單元狀態中添加或刪除信息,并使用不同的門控制這些信息的更新。
4.2 設計神經網絡
4.2.1 網絡結構
神經網絡采用7層結構,分別為順序輸入(Sequence-Input)層、LSTM 層1、隨機失活(Dropout)層、LSTM 層2、全連接(FullyConnected)層、Softmax 層、類 輸 出(ClassOutput)層,如圖6所示。

圖6 神經網絡結構
該網格結構中:SequenceInput 層為序列數據的輸入層;Dropout 層[18]用于控制輸入線性變換的神經元斷開比例,設置合適的置零概率可以防止網絡過擬合;LSTM 層可以學習時間序列和序列數據中的時間步之間的長期依賴關系,與Dropout 層共同完成從原始腦電信號中學習特征的功能;Softmax[19]層負責將帶權輸入進行歸一化;FullyConnected 層將學到的特征映射到樣本標記空間;ClassOutput 層為輸出層,輸出0 或1,分別表示非疲勞與疲勞。2個LSTM 層與FullyConnected 層都使用sigmoid 激活函數。
4.2.2 關鍵參數確定
SequenceInput 層的輸入序列維度設置為28×n(對應n個通道的28個特征值)。通過試驗,確定2個LSTM 隱含層的節點數和Dropout 層的概率值,其他參數采用MATLAB 推薦值。測試方法為:以試驗組每個通道的特征矩陣作為輸入對網絡進行多次訓練,在每次訓練中,2 個隱含層分別取2i(i=1,2,…,10)個節點,Dropout 層的概率分別取0.1、0.2、……、0.9。通過統計對比14個通道(每個通道900次測試)的所有測試結果發現,當第1隱含層為128個節點,第2隱含層為64 個節點且Dropout 層的概率為0.2 時,網絡不會出現明顯的過擬合,同時神經網絡具備較好的分類性能,平均分類準確率維持在73%以上,據此2個隱含層的節點數分別設置為128×n與64×n。
5 分類試驗
分類試驗利用構造的特征數據作為網絡輸入,分別在單通道和多通道方案下,對LSTM神經網絡進行訓練和測試試驗,根據試驗結果對分類性能進行分析。
5.1 單通道分類
在單通道方案中,以每個通道的特征矩陣作為輸入數據對網絡進行分類訓練并測試。試驗組與對照組在單通道方案下的分類準確率的均值與標準差測試結果如表1所示。
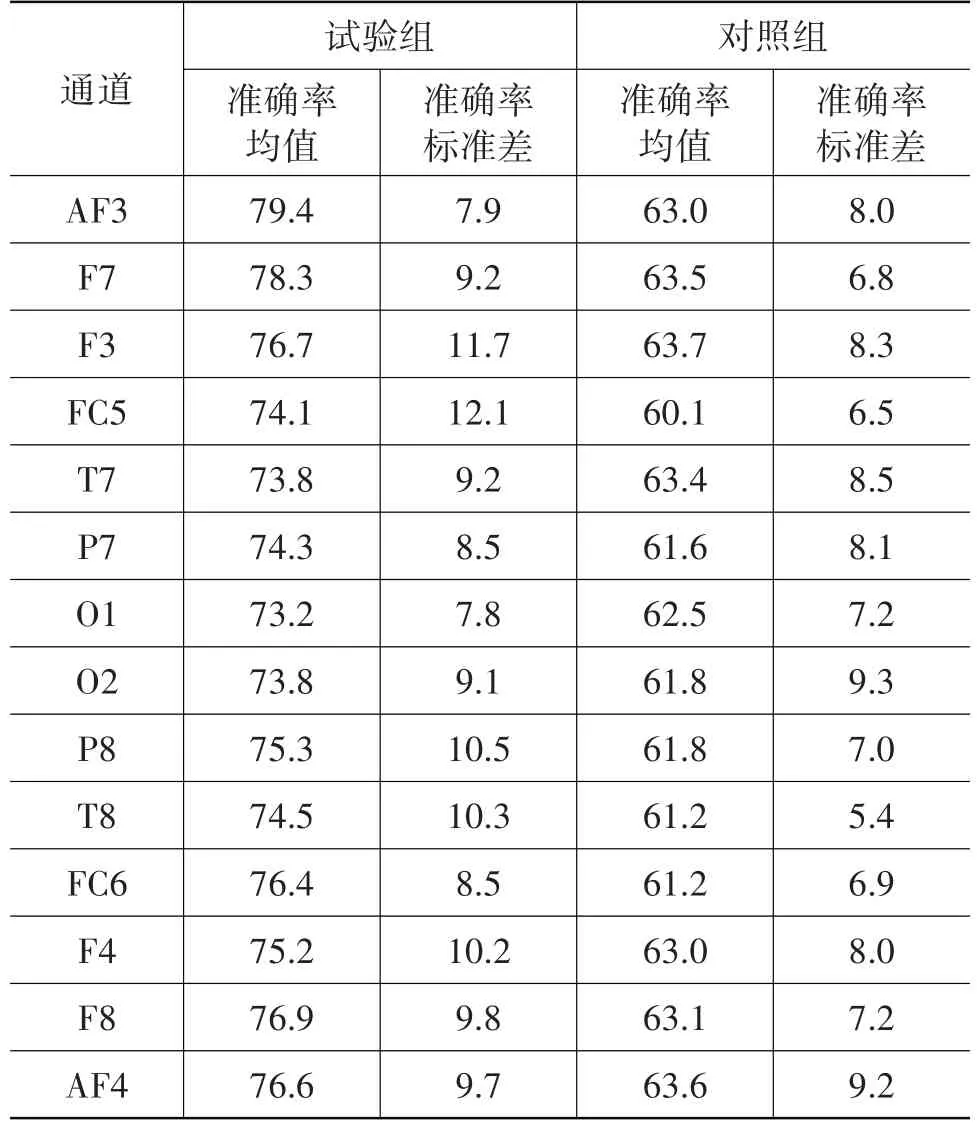
表1 單通道分類準確率的均值和標準差 %
對比發現,試驗組各通道下的分類準確率明顯高于對照組。這表明,單通道方案下LSTM網絡對非疲勞與駕駛疲勞的特征數據具備特定的分類能力。
然而,單通道分類能力仍然較低(分類準確率不到80%),較高的標準差也說明分類性能不穩定。因此,本文將更多通道特征數據輸入神經網絡,以改善分類性能。
5.2 多通道分類
在多通道方案中,為盡可能獲得較高的準確率,優先選擇單通道分類準確率較高的通道進行組合。各單通道平均分類準確率在腦皮層上的分布情況如圖7 所示。由圖7 可知,處于腦皮層前端的通道分類準確率較高,而處于同一水平線上的左右對稱通道上的準確率接近。

圖7 LSTM網絡各通道平均準確率分布
據此,多通道方案采用7個通道組合方案,如表2所示。每個方案中,優先選擇靠前的通道參與組合。

表2 多通道組合方案
在每個多通道組合方案中,將所選擇的多個通道的特征矩陣合并,并將合并的矩陣作為輸入矩陣對LSTM 網絡進行訓練并測試,得到試驗組與對照組的多通道分類準確率的均值和標準差,如表3所示。
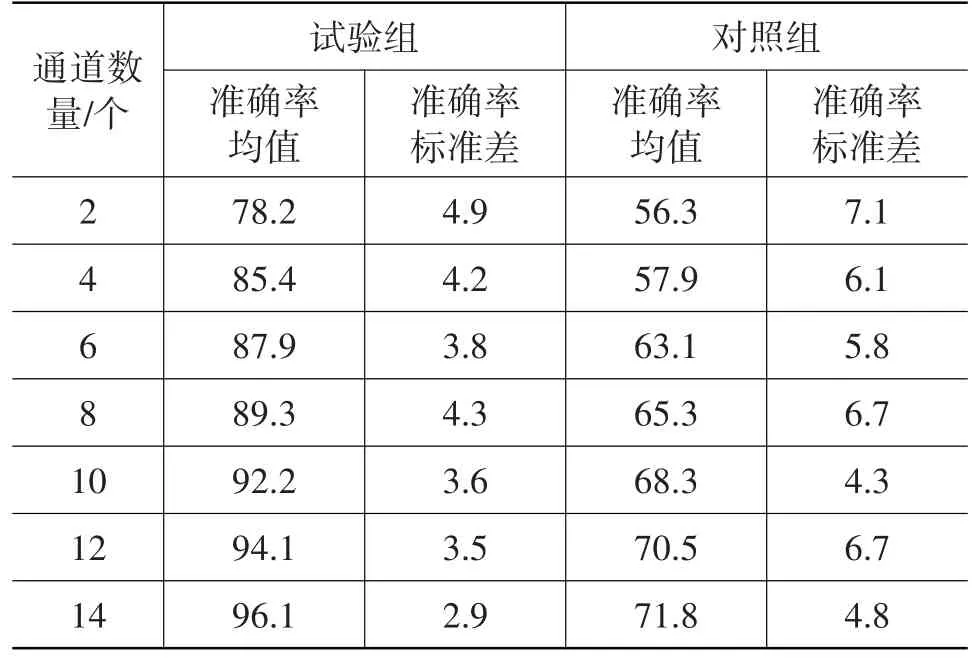
表3 多通道分類準確率的均值和標準差 %
由表3可知,在每種多通道方案中,試驗組的分類性能都明顯較對照組高且更穩定,分類準確率隨著通道數量的增多逐漸提高,從4通道方案開始,準確率明顯提高,特別是在通道數量最多的14通道方案中,試驗組的分類準確率可達96.1%。試驗結果表明,利用多通道方案,可使LSTM 網絡對非疲勞與駕駛疲勞2個狀態的腦電信號進行有效的分類識別。
5.3 本文方法與其他方法性能比較
駕駛疲勞識別準確率受采集環境、通道選擇、特征提取、分類算法等因素綜合影響,其中特征提取與分類算法為關鍵因素。為評估本文識別方法與其他方法的性能差異,以相同的14通道的多維特征數據分別在支持向量機(Support Vector Machine,SVM)、反向傳播(Back Propagation,BP)神經網絡、CNN 分類器中進行分類測試,得到如表4 所示的平均分類準確率。
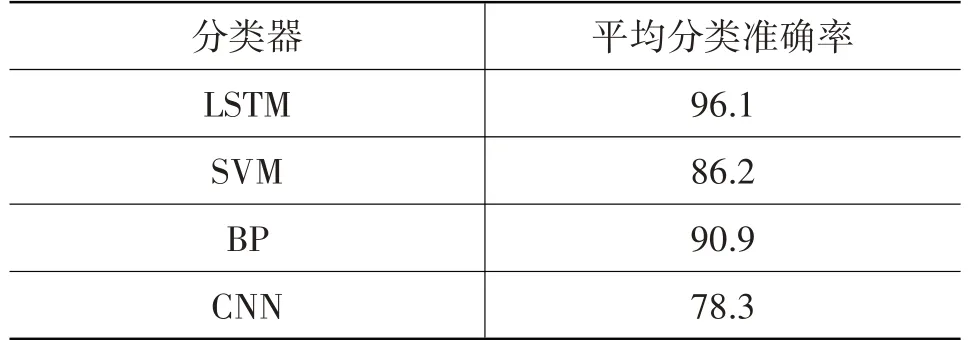
表4 LSTM 與其他分類器的平均分類準確率比較 %
從表4中可以看出,使用LSTM分類器對以統計值、能量值和相對能量值組成的多維特征值進行分類,可以獲得更高的分類準確率。
5.4 實時性分析
在計算機(CPU 主頻為2.4 GHz,內存為8 GB)中,用經過訓練的LSTM 網絡(14 通道方案),對1 s的14 通道腦電數據進行1 000 次仿真分類運算,記錄運算平均運行耗時。結果顯示,小波濾波平均耗時10.6 ms,特征提取平均耗時5.2 ms,網絡對特征數據進行分類運算平均耗時1.8 ms,仿真過程合計平均耗時33.8 ms。
計算機的運算單元不代表車載駕駛疲勞實時識別單元,因此,以上仿真結果還不能直接說明疲勞識別算法在應用中的實時性。在實際應用中,為保證實時性,要求分類運算的合計耗時小于腦電信號采集窗口耗時(1 s)。因為單元計算能力主要取決于處理器的主頻(在內存等其他因素相同的情況下),因此根據仿真中2.4 GHz主頻對應33.8 ms耗時的情況,按比例計算得知,要實現耗時低于1 s,主頻需高于81.12 Hz。在實際應用中,符合該主頻要求的車載單元芯片容易獲取,采用頻率足夠高的車載芯片,可以保證疲勞識別算法的實時性。
6 結束語
本文在真實駕駛環境下采集非疲勞與駕駛疲勞腦電信號,經小波濾波,從小波系數中提取多維特征數據對LSTM 神經網絡進行分類訓練與測試。試驗結果表明,LSTM 神經網絡對2種特征數據的分類性能與構造特征數據的通道數量相關,通道數量越多,分類準確率越高,特別是在14通道方案中,可以得到96.1%的分類準確率。仿真數據顯示,腦電數據的濾波、特征提取和網絡分類計算的總耗時遠小于信號的采集耗時,算法具備良好的實時性。基于小波特征與LSTM 神經網絡分類器的分類方法可應用于駕駛疲勞的識別。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
