回收連鎖店選址問(wèn)題及蘑菇繁殖算法求解
2023-10-13 06:47:09張宇恒張惠珍馬良朱寧
上海理工大學(xué)學(xué)報(bào) 2023年4期
張宇恒 張惠珍 馬良 朱寧

摘要:針對(duì)日益增長(zhǎng)的多樣化回收服務(wù)需求,解決了多服務(wù)方式、多規(guī)模的回收連鎖店選址優(yōu)化問(wèn)題。構(gòu)建了建設(shè)與服務(wù)成本最小化和客戶滿意度最大化的回收連鎖店雙目標(biāo)選址模型,并針對(duì)模型的具體特征,將交叉與變異算子和精英保留策略等與基本蘑菇繁殖算法相結(jié)合,設(shè)計(jì)了改進(jìn)的蘑菇繁殖算法對(duì)模型求解。通過(guò)對(duì)某電子產(chǎn)品回收連鎖店的選址優(yōu)化實(shí)例,確定其服務(wù)方式和選址的數(shù)量、位置及規(guī)模。驗(yàn)證了模型的有效性和算法的可行性。同時(shí),不同的服務(wù)方式及規(guī)模選擇,對(duì)回收連鎖店的選址有顯著影響,企業(yè)相關(guān)決策者可通過(guò)合理提供不同服務(wù)來(lái)提升利潤(rùn)。
關(guān)鍵詞:多目標(biāo)選址問(wèn)題;蘑菇繁殖算法;多服務(wù)方式;回收連鎖店
中圖分類號(hào):? O 224???????????? 文獻(xiàn)標(biāo)志碼:?? A
Mushroom reproduction algorithm for solving location problem of recycling chain stores
ZHANG Yuheng,ZHANG Huizhen,MA Liang,ZHU Ning
(Business School, University of Shanghai for Science and Technology, Shanghai 200093, China)
Abstract:? In? view? of the? growing? demand? for? diversified? recycling? services,? this? paper? solves? the location problem of recycling chain stores with multi-service and multi-scale. A bi-objective location model? of? recycling? chain? stores? was? constructed? to? minimize? construction? and? service? costs? and maximize customer satisfaction. According to the specific characteristics of the model, an improved mushroom reproduction optimization was designed to solve the model by combining the crossover and mutation operator and elitist preservation strategy. The algorithm determined the service modes and the number, location and scale of recycling chain stores through an example of location optimization of an electronics recycling chain? store. Finally, the paper verified the effectiveness of the model and the feasibility of the algorithm. Different service modes and scale choices have a significant impact on the location? of? recycling? chain?? stores.? Relevant? decision? makers? can? improve? profits? by? reasonably providing different services.
Keywords:? multi-objective? location? problem ; mushroom? reproduction? optimization; multi-service; recycling chain store
隨著科技的不斷發(fā)展,電子產(chǎn)品的更新速度逐步加快,廢舊電子產(chǎn)品也在源源不斷地產(chǎn)生。2020年中國(guó)總共產(chǎn)生約5.24億臺(tái)廢舊手機(jī),且 2014年至今,我國(guó)廢舊二手手機(jī)存量累計(jì)超過(guò) 20億部,但廢舊手機(jī)的回收率僅有7%,遠(yuǎn)遠(yuǎn)低于日本和歐美國(guó)家的46%和66%。這不僅造成了我國(guó)資源的嚴(yán)重浪費(fèi),也與可持續(xù)發(fā)展的理念相背離。回收需求無(wú)法被滿足是造成這種局面的主要原因之一,因此,滿足顧客多樣的回收需求成為了回收企業(yè)線下連鎖店選址重點(diǎn)考慮的問(wèn)題,引起了國(guó)內(nèi)外很多學(xué)者的關(guān)注和深入研究。例如,周林等[1]在電商最后1 km 配送問(wèn)題中考慮了顧客自提和送貨兩種服務(wù)方式,并基于自提點(diǎn)共享的情況,研究了系統(tǒng)總成本最小的選址路徑問(wèn)題,發(fā)現(xiàn)送提一體和終端共享是有效的配送策略。黃露等[2]在延誤風(fēng)險(xiǎn)下,對(duì)配送網(wǎng)絡(luò)中心選址問(wèn)題提出了雙層規(guī)劃的模型,上層為企業(yè)決策模型,下層為顧客選擇模型,得出了有效選址不僅節(jié)約成本還能降低顧客損失的結(jié)論。陳義友等[3] 以取貨距離和自提點(diǎn)吸引力為主要因素,設(shè)計(jì)了效用函數(shù),構(gòu)建了2種不同的模型,求解結(jié)果表明,顧客對(duì)服務(wù)方式的不同選擇行為,對(duì)自提點(diǎn)的選址有很大影響。 Zhang 等[4]研究了顧客選擇行為對(duì)于預(yù)防性健康設(shè)施的選址影響,提出了概率選擇模型和最優(yōu)選擇模型這2個(gè)模型,并且進(jìn)行對(duì)比。
在實(shí)際選址問(wèn)題中,決策者考慮的因素往往不只一個(gè),而是在多方面作出權(quán)衡。因此,多目標(biāo)選址更能反映選址決策的實(shí)際情況,其所給出的選址方案比單目標(biāo)選址方案更加合理。 Naimi 等[5]以交貨時(shí)間、供應(yīng)鏈成本和產(chǎn)品質(zhì)量作為目標(biāo)函數(shù),建立了多目標(biāo)配送中心選址模型,并以加權(quán)的方式進(jìn)行求解。 Ramezani 等[6]將逆向供應(yīng)鏈中的利潤(rùn)、顧客響應(yīng)能力、質(zhì)量作為目標(biāo),構(gòu)建了多目標(biāo)選址模型,并獲得 Pareto最優(yōu)解集,分析了目標(biāo)之間的權(quán)衡。陳義友等[7]考慮了送貨上門服務(wù)對(duì)自提點(diǎn)選址的影響,提出了顧客有限理性行為下多目標(biāo)選址的模型。周向紅等[8]考慮了政府補(bǔ)貼行為對(duì)再制造逆向物流的影響,建立以社會(huì)成本、經(jīng)濟(jì)成本、收入為多目標(biāo)的動(dòng)態(tài)選址模型。本文在研究回收企業(yè)線下連鎖店的選址過(guò)程中,不僅考慮了建設(shè)成本問(wèn)題和服務(wù)成本問(wèn)題,還考慮了顧客對(duì)服務(wù)的滿意度問(wèn)題,同時(shí)將多樣化的服務(wù)方式納入考慮范圍。因此,本文構(gòu)建了以建設(shè)服務(wù)成本和顧客滿意度水平為雙目標(biāo)的設(shè)施選址模型,以更好地滿足企業(yè)利潤(rùn)和客戶需求的目標(biāo)。
回收門店選址問(wèn)題是經(jīng)典選址問(wèn)題(如無(wú)容量設(shè)施選址問(wèn)題、 p-中位問(wèn)題、覆蓋問(wèn)題等)的擴(kuò)展,屬于 NP-hard 問(wèn)題。精確算法在可接受時(shí)間內(nèi)難以給出問(wèn)題的最優(yōu)解,而智能優(yōu)化算法則可以在較短的時(shí)間內(nèi)為大規(guī)模優(yōu)化問(wèn)題提供較優(yōu)的解,因此,智能優(yōu)化算法在選址問(wèn)題中的應(yīng)用引起了國(guó)內(nèi)外學(xué)者的重視。李鳳月等[9]利用麻雀搜索算法的協(xié)同進(jìn)化優(yōu)點(diǎn),改進(jìn)了果蠅優(yōu)化算法,并采用兩層搜索策略解決了選址庫(kù)存的聯(lián)合優(yōu)化問(wèn)題。宋艷等[10]提出了分段式染色體編碼方式,彌補(bǔ)傳統(tǒng)的二進(jìn)制編碼在多級(jí)服務(wù)設(shè)施選址問(wèn)題中染色體長(zhǎng)度過(guò)長(zhǎng)的缺點(diǎn),以此來(lái)改進(jìn) NSGA-Ⅱ算法,有效地求解了多目標(biāo)覆蓋問(wèn)題。劉凡等[11] 將適用于連續(xù)型優(yōu)化的蘑菇繁殖算法進(jìn)行編碼和交叉算子的變化,求解了選址路徑問(wèn)題,并測(cè)試和比較了其有效性。
蘑菇繁殖算法能有效地考慮各父代間的關(guān)系,并且其局部搜索的方式能較好地發(fā)揮優(yōu)秀父代的優(yōu)勢(shì)。此外,蘑菇繁殖算法的選擇機(jī)制將整體與部分相結(jié)合,有效地平衡了全局搜索與局部搜索,避免了算法過(guò)早陷入局部最優(yōu)的問(wèn)題。目前該算法還尚未應(yīng)用在選址問(wèn)題中,為了擴(kuò)大蘑菇繁殖算法在選址領(lǐng)域的應(yīng)用,測(cè)試算法在求解選址問(wèn)題時(shí)的性能,本文根據(jù)多服務(wù)方式回收連鎖店選址模型的特點(diǎn),對(duì)蘑菇繁殖算法進(jìn)行改進(jìn),并通過(guò)算例分析和對(duì)比已有算法,驗(yàn)證模型及算法的有效性和可行性。本文研究?jī)?nèi)容不僅可以為回收企業(yè)線下連鎖店的選址提供解決方案,也進(jìn)一步拓展了蘑菇繁殖算法的應(yīng)用領(lǐng)域。
1 多服務(wù)方式回收連鎖店選址模型
在現(xiàn)實(shí)生活中,回收企業(yè)及相關(guān)部門為了滿足客戶的需求,通常向客戶提供多種服務(wù)方式,其主要包括:以郵寄方式為主的第三方配送回收服務(wù)、以客戶線下主動(dòng)前往店面為主的回收服務(wù)和以上門取貨為主的回收服務(wù)。為了降低連鎖店的服務(wù)運(yùn)營(yíng)和建設(shè)成本,同時(shí)增加客戶線下回收的滿意度,連鎖店的選址和規(guī)模成了重要的決策內(nèi)容。連鎖店的規(guī)模不同,其服務(wù)覆蓋范圍也不同,小規(guī)模的連鎖店可快速滿足周邊局部需求,但覆蓋范圍小;大規(guī)模的連鎖店覆蓋范圍大,能提供更好更廣的服務(wù),但建設(shè)費(fèi)用高。
1.1 模型假設(shè)
為了更好地構(gòu)建模型,提出如下假設(shè): a.連鎖店建設(shè)的規(guī)模不同,規(guī)模越大的店面,所需要的建設(shè)成本越大; b.連鎖店的服務(wù)覆蓋范圍以覆蓋半徑作為衡量標(biāo)準(zhǔn),覆蓋半徑越大則覆蓋范圍越廣; c.連鎖店郵寄服務(wù)和上門取貨的成本與顧客的距離成正比; d.顧客對(duì)于線下回收服務(wù)的滿意度與距離成反比,與店面規(guī)模成正比; e.對(duì)于某一個(gè)連鎖店來(lái)說(shuō),位于其服務(wù)范圍之內(nèi)的顧客,可被提供上門取貨和線下門店回收的服務(wù)方式;而位于其服務(wù)范圍之外的顧客,可被提供郵寄回收和線下門店回收的服務(wù)方式; f.對(duì)于任一需求點(diǎn)來(lái)說(shuō),總有一部分顧客主觀上會(huì)優(yōu)先選擇線下回收的服務(wù)方式來(lái)滿足服務(wù)的體驗(yàn)性。
現(xiàn)介紹模型所用的符號(hào)。
集合:
式中: Z1為成本函數(shù); Z2為滿意度函數(shù)。
目標(biāo)函數(shù)式(1)表示最小化候選點(diǎn)的建設(shè)成本和服務(wù)運(yùn)營(yíng)成本之和;目標(biāo)函數(shù)式(2)表示最大化顧客對(duì)于線下回收服務(wù)的滿意度;約束式(3)表示每個(gè)候選點(diǎn)的位置只能建立一種規(guī)模的連鎖店;約束式(4)表示只有被候選點(diǎn)覆蓋時(shí),顧客才會(huì)被提供上門取貨的服務(wù);約束式(5)表示只有沒(méi)被候選點(diǎn)覆蓋時(shí),顧客才會(huì)被提供郵寄回收的服務(wù);約束式(6)表示在需求點(diǎn)內(nèi),總有追求線下回收服務(wù)的顧客存在,并占據(jù)一定比例;約束式(7)表示需求點(diǎn)的總需求量要與所提供的回收服務(wù)總量相同;約束式(8)表示只有當(dāng)候選點(diǎn)建立時(shí),才可以為顧客提供不同的服務(wù);約束式(9)為決策變量的取值范圍。
2 求解回收連鎖店選址模型的混合離散蘑菇繁殖算法
蘑菇繁殖算法(mushroom reproduction optimi-zation, MRO)[11, 13]是仿照蘑菇生長(zhǎng)繁殖特性設(shè)計(jì)出的一種新型群智能優(yōu)化算法。 MRO 算法以父代的蘑菇為初始種群,其通過(guò)傳播自己的孢子來(lái)探索各個(gè)繁殖區(qū)域并細(xì)化搜索空間,找到更優(yōu)秀的繁殖區(qū)域進(jìn)行生長(zhǎng)繁殖搜索活動(dòng)。 MRO 算法在鄰域搜索前,計(jì)算每個(gè)菌落的平均適應(yīng)度值 Avg(i)和所有菌落的平均適應(yīng)度值Tavg,并通過(guò)判斷(Avg(i)+Tavg/c)與Tavg的大小關(guān)系(c 為一個(gè)固定的閾值)決定每個(gè)菌落是否利用人工風(fēng)方式進(jìn)行全局搜索。對(duì)于最大化問(wèn)題,若前者小于后者,并且存在比該菌落優(yōu)秀的菌落,則對(duì)該菌落進(jìn)行人工風(fēng)方式的全局搜索。若前者大于后者,則繼續(xù)利用產(chǎn)生孢子的行為進(jìn)行鄰域搜索。完成一輪迭代后,更新菌落中的父代和全局最優(yōu)解,重新計(jì)算每個(gè)菌落的平均適應(yīng)度值和全體菌落的平均適應(yīng)度值。
MRO 算法所采用的鄰域搜索方式可表示為
Xij = Xi;p + Rand(-r; r)(10)
式中:Xij為第i個(gè)父代蘑菇所生成的第 j 個(gè)孢子;Xi,p表示第i個(gè)父代蘑菇的位置, Rand(-r; r)為 r 步長(zhǎng)內(nèi)隨機(jī)搜索的距離。
MRO 算法通過(guò)人工風(fēng)進(jìn)行全局搜索的方式可表示為
Mj=(Xi *- Xk *)-mRand(-δ;δ)rs +
式中: xi*和xk *分別代表第i個(gè)和第 k 個(gè)菌落的父代蘑菇位置; m 為風(fēng)的強(qiáng)度參數(shù);δ為風(fēng)的方向系數(shù);rs表示搜索步長(zhǎng); r 為搜索半徑;Mj為第j 個(gè)子代移動(dòng)的距離。
以 MRO 算法中菌落的思想為核心,結(jié)合所構(gòu)建模型的特征,通過(guò)對(duì)解形式的改變,并結(jié)合改進(jìn)的交叉算子和變異算子,設(shè)計(jì)求解回收連鎖店選址模型的 MRO 算法。
2.1 算法設(shè)計(jì)
本文構(gòu)建的模型既包含整數(shù)變量,又包含連續(xù)變量,且目標(biāo)函數(shù)為非線性函數(shù),求解比較困難。因此,首先利用設(shè)計(jì)的蘑菇繁殖算法確定整數(shù)變量的取值(即蘑菇繁殖算法中每一個(gè)菌落和孢子僅對(duì)應(yīng)模型中整數(shù)變量的取值),然后調(diào)用優(yōu)化軟件 CPLEX 確定連續(xù)變量的取值,并計(jì)算目標(biāo)函數(shù)值。
2.1.1編碼方式
文中整數(shù)變量的取值用含有 n 個(gè)分量的行向量來(lái)進(jìn)行轉(zhuǎn)化。向量中第i個(gè)分量的取值為 h,此時(shí)整數(shù)變量xih =1,表示在候選點(diǎn)i處建設(shè)第 h 種規(guī)模的回收站[14];若第i個(gè)分量的取值為0,表示在第i個(gè)候選點(diǎn)處不建任何規(guī)模回收站。此種轉(zhuǎn)化方式可直接滿足模型中對(duì)整數(shù)變量的約束條件。13個(gè)侯選點(diǎn)、3種規(guī)模的可行解編碼形式如圖1所示,侯選點(diǎn)2,10處不建回收站;侯選點(diǎn)1,5,7,11,12處建立規(guī)模為1類的回收站;侯選點(diǎn)3,6,8,13處建立規(guī)模為2類的回收站;侯選點(diǎn)4,9處建立規(guī)模為3類的回收站。
采用含有 p 行(每一行代表一個(gè)可行解中整數(shù)變量的取值)和 n 列(候選點(diǎn)個(gè)數(shù))的矩陣表示一個(gè)菌落。每個(gè)菌落的適應(yīng)度值由菌落中所有解的平均適應(yīng)度值表示。如含有5個(gè)可行解的菌落可表示為圖2的形式。
2.1.2初始解的生成
首先采用隨機(jī)生成的方式產(chǎn)生 q 個(gè)解,再分別對(duì)這些解擾動(dòng)處理,形成以每個(gè)解自身為基礎(chǔ)的 q 個(gè)菌落。該方法既避免了隨機(jī)生成菌落的無(wú)序性,又可形成以初始解為基礎(chǔ)的局部搜索來(lái)避免菌落中解的適應(yīng)度相差太大的問(wèn)題。
2.1.3適應(yīng)度函數(shù)及評(píng)價(jià)標(biāo)準(zhǔn)
采用加權(quán)法構(gòu)造適應(yīng)度函數(shù)。第 s 個(gè)解的適應(yīng)度函數(shù)為
f (s)=α -(1-α)
式中: Z1*和 Z2*分別為單獨(dú)考慮各目標(biāo)函數(shù)時(shí)的最優(yōu)目標(biāo)值[15];參數(shù)α(0≤α≤1)為權(quán)重。
該方法不僅消除了2個(gè)目標(biāo)之間的量綱差異,還消除了2個(gè)目標(biāo)之間的數(shù)量級(jí)差異。
由于需評(píng)價(jià)的指標(biāo)較為復(fù)雜,合理設(shè)置各評(píng)價(jià)標(biāo)準(zhǔn)尤為關(guān)鍵。每個(gè)菌落之間存在對(duì)比關(guān)系,將第i個(gè)菌落中所有解的適應(yīng)度均值作為此菌落的平均適應(yīng)度值 Avg(i)。同理,將所有菌落中解的適應(yīng)度均值作為種群的全局適應(yīng)度均值Tavg。
2.1.4交叉算子
為了將 MRO 算法應(yīng)用于本文研究的問(wèn)題,將 MRO 算法與遺傳算法中的交叉和變異操作相結(jié)合,并引入精英保留策略來(lái)提升算法的搜索效率。將一般策略與精英保留策略交叉使用,并利用漢明距離來(lái)評(píng)估種群的多樣性,避免在算法后期出現(xiàn)菌落同質(zhì)化現(xiàn)象,導(dǎo)致陷入局部最優(yōu)。
本文結(jié)合菌落的表示形式,基于位置交叉(position-based crossover , PBX)[16]的交叉方式設(shè)計(jì)交叉算子。首先,在父代菌落中隨機(jī)選擇2個(gè)菌落,并在選中的菌落中隨機(jī)選擇若干交叉點(diǎn);然后,將父代 P1中被選中的列替換為父代 P2中對(duì)應(yīng)的列,產(chǎn)生臨時(shí)子代 TC1;最后,將子代菌落 TC1與原父代菌落 P1進(jìn)行平均漢明距離的比較,若符合差異度的要求,則說(shuō)明子代菌落 TC1的多樣性得以滿足,將臨時(shí)子代 TC1與父代 P1以精英保留策略進(jìn)行篩選或直接保留臨時(shí)子代 TC1,使得后代菌落的規(guī)模不變;若不符合差異度要求,則重新選擇進(jìn)行交叉操作,如果達(dá)到規(guī)定上限次數(shù)還未產(chǎn)生符合差異度規(guī)定的子代,則將父代與隨機(jī)產(chǎn)生的菌落進(jìn)行交叉操作,直接保留子代菌落,以彌補(bǔ)差異度不足所帶來(lái)的同質(zhì)化[17]。如圖3所示,在擁有5個(gè)可行解的父代 P1和父代 P2菌落中,選取父代 P1中第1和4列,將其替換為父代 P2中對(duì)應(yīng)的列并生成臨時(shí)子代 TC1,若符合差異度要求,將其篩選或保留,從而生成子代 C1。
2.1.5變異算子
為了提高算法優(yōu)化性能,現(xiàn)以等概率的方式隨機(jī)選擇實(shí)數(shù)變異[18]和單列交換[19],設(shè)計(jì)變異算子。
采用的實(shí)數(shù)變異為:首先,在給定的菌落中隨機(jī)選擇若干行(每一行表示一個(gè)解),然后,在每個(gè)選中的行中,隨機(jī)選擇若干個(gè)變異點(diǎn),將這些點(diǎn)的取值在可行的集合內(nèi)隨機(jī)變動(dòng)。如圖4所示,在有5個(gè)可行解的菌落中,選取第1行第4列變異為實(shí)數(shù)3;第3行第2列變異為實(shí)數(shù)1;第5行第3列變異為實(shí)數(shù)0。
采用的單列交換為:首先,隨機(jī)選取不相同的偶數(shù)列,然后,將其兩兩配對(duì),并交換其取值,得到新的菌落。如圖5所示,在有5個(gè)可行解的菌落中,選取第1,3列并將其交換位置;選取第2,4列并將其交換位置。
將變異得到的新菌落與原來(lái)的菌落比較漢明距離,若符合差異度要求,則將新菌落與父代菌落進(jìn)行精英保留策略的篩選或直接保留新菌落;若不符,則重新選擇進(jìn)行變異操作,當(dāng)達(dá)到規(guī)定上限次數(shù)時(shí),還未產(chǎn)生新的菌落,則選取當(dāng)代中
最優(yōu)菌落的若干解和隨機(jī)生成的若干解組成新的菌落來(lái)代替此菌落。
2.2 算法流程
在上述算法設(shè)計(jì)的基礎(chǔ)上,將改進(jìn)的 MRO 算法的優(yōu)化迭代步驟進(jìn)行概括。
步驟1 參數(shù)初始化。算法最大迭代次數(shù)Gmax,最大交叉或變異次數(shù)Tmax,初始迭代次數(shù) g=0,初始交叉和變異次數(shù) t=0,產(chǎn)生菌落的個(gè)數(shù) Q 及菌落中包含解的個(gè)數(shù) P。
步驟2產(chǎn)生初始解。根據(jù)產(chǎn)生初始解的規(guī)則和參數(shù)的設(shè)定產(chǎn)生初始解,并計(jì)算菌落的適應(yīng)度均值和當(dāng)前種群的適應(yīng)度均值,將適應(yīng)度均值最小的菌落作為全局最優(yōu)菌落和同代最優(yōu)菌落,將適應(yīng)度值最小的解作為全局最優(yōu)解。
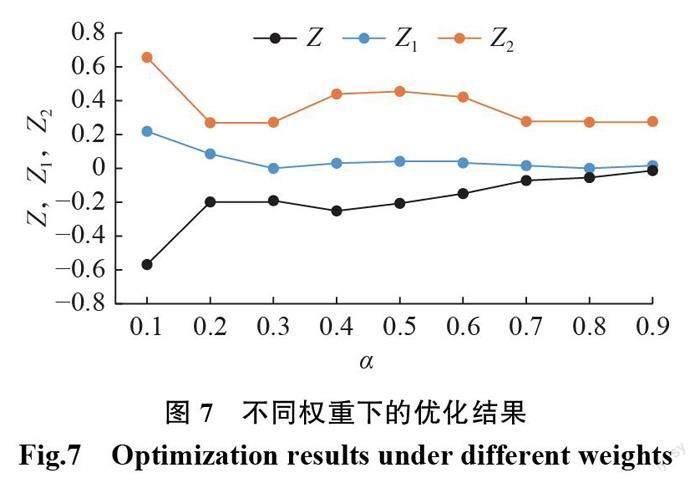
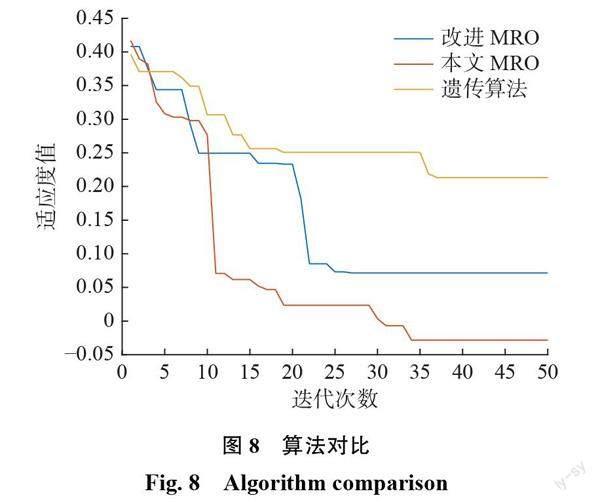
步驟3對(duì)于第i個(gè)菌落,若 Avg(i)+Tavg/c 步驟4變異操作。若 t 步驟5交叉操作。若 t 步驟6將達(dá)到交叉或變異操作上限次數(shù)的菌落進(jìn)行相應(yīng)規(guī)則的處理后,保留新菌落。 步驟7更新操作。在同代所有菌落都進(jìn)行完迭代過(guò)程后,更新當(dāng)前的種群,并且更新全局最優(yōu)菌落、同代最優(yōu)菌落和全局最優(yōu)解。 步驟8g=g+1,若 g 2.3 時(shí)間復(fù)雜度分析 算法的時(shí)間復(fù)雜度可以作為評(píng)估其優(yōu)化性能的標(biāo)準(zhǔn)之一。本文改進(jìn)的 MRO 算法時(shí)間復(fù)雜度分析基于初始菌落的個(gè)數(shù) Q、菌落中所包含的解的個(gè)數(shù) P、變異或交叉的最大次數(shù)Tmax、候選點(diǎn)個(gè)數(shù) n、候選點(diǎn)規(guī)模個(gè)數(shù) h、需求點(diǎn)個(gè)數(shù) m 和算法的主要步驟進(jìn)行。 由初始解生成的方法可知,算法中初始解生成的時(shí)間復(fù)雜度為 O(Q×P×n×h)。在計(jì)算解的適應(yīng)度時(shí),由于計(jì)算xij,Oj,rj的時(shí)間復(fù)雜度均為 O(n),而計(jì)算dik,yik的時(shí)間復(fù)雜度為 O(n×m),因此,適應(yīng)度值計(jì)算的時(shí)間復(fù)雜度為 O(n×m)。交叉操作與變異操作在最壞情況下進(jìn)行Tmax次,而每次操作中,產(chǎn)生新解的個(gè)數(shù)為 P0,在選擇階段涉及到各菌落排序時(shí),采用快速排序法,其時(shí)間復(fù)雜度為 O(QTmax(P+P0)log2(P+P0))。對(duì)菌落的更新與對(duì)全局最優(yōu)解的更新時(shí)間復(fù)雜度分別為 O(Q)與 O(QP)。綜合以上各步驟,根據(jù)時(shí)間復(fù)雜度計(jì)算規(guī)則,在迭代Gmax次情況下,改進(jìn)的 MRO 算法時(shí)間復(fù)雜度為 O(GmaxQPnh+ GmaxQPnm+ GmaxQTmax(P+P0)log2(P+P0))。 3 算例測(cè)試及分析 3.1 算例描述 選擇某電子產(chǎn)品回收連鎖店的選址作為測(cè)試算例。經(jīng)過(guò)實(shí)地調(diào)研,該電子產(chǎn)品回收企業(yè)預(yù)計(jì)在某區(qū)域內(nèi)13個(gè)候選點(diǎn)中開(kāi)設(shè)3種店面規(guī)模不同的回收連鎖店,對(duì)區(qū)域內(nèi)48個(gè)需求點(diǎn)進(jìn)行服務(wù)。候選點(diǎn)的坐標(biāo)位置如表1所示。需求點(diǎn)的坐標(biāo)位置和需求量如表2所示。 經(jīng)實(shí)際調(diào)研和企業(yè)領(lǐng)導(dǎo)層決策,相關(guān)參數(shù)設(shè)置如下:1類規(guī)模的回收店服務(wù)半徑和固定成本分別為 r1=0.3 km 和 O1=1000元;2類規(guī)模的回收店服務(wù)半徑和固定成本分別為 r2=0.9 km 和 O2=1500元;3類規(guī)模的回收店服務(wù)半徑和固定成本分別為 r3=1.5 km 和 O3=2000元;線下門店需求比例β=0.3;上門服務(wù)成本 C=10元/(kg·km);郵寄服務(wù)成本 E=5元/(kg·km);顧客滿意度值 B=10單位/kg;距離衰減系數(shù)λ=1.5。 3.2 優(yōu)化結(jié)果與分析 利用 MATLAB 2020a 軟件編程實(shí)現(xiàn)所設(shè)計(jì)的算法,對(duì)算例進(jìn)行求解。實(shí)驗(yàn)在64位 Windows 10操作系統(tǒng)下進(jìn)行, CPU 配置為 AMD Ryzen 74800U 1.8 GHz ,16 GB 內(nèi)存。在 MATLAB 中調(diào)用Cplex(64bit)12.10.0軟件求解連續(xù)型變量和目標(biāo)函數(shù)值。經(jīng)多次實(shí)驗(yàn),設(shè)置初始種群數(shù)量 Q=40,最大迭代次數(shù)Gmax=50,最大交叉變異次數(shù)Tmax=20和閾值c=10時(shí),求解效率較高,效果較好。 采用加權(quán)法計(jì)算適應(yīng)度值,將多目標(biāo)問(wèn)題轉(zhuǎn)化為帶有權(quán)重的單目標(biāo)問(wèn)題進(jìn)行求解,并對(duì)不同權(quán)重下最優(yōu)解的情況進(jìn)行分析。實(shí)驗(yàn)結(jié)果如表3所示。 首先采用權(quán)重極小化的方法[20]對(duì)2個(gè)目標(biāo)進(jìn)行獨(dú)立分析,即為某一目標(biāo)設(shè)置一個(gè)極小的權(quán)重δ(δ=10?4),而另一目標(biāo)的權(quán)重(1?δ)接近1,在此情況下,分析目標(biāo)函數(shù)的變化情況。之后,通過(guò)改變目標(biāo)函數(shù)的權(quán)重來(lái)分析結(jié)果的變化情況。當(dāng)利用極小的權(quán)重來(lái)分析某個(gè)目標(biāo)時(shí),得到或逼近另一目標(biāo)在加權(quán)分析法中的最優(yōu)解。在目標(biāo)權(quán)重α取值為δ時(shí),主要考慮客戶滿意度目標(biāo),對(duì)建設(shè)與服務(wù)成本目標(biāo)的考慮很少,主要表現(xiàn)在選址時(shí)不僅開(kāi)放的候選點(diǎn)較多,且候選點(diǎn)的規(guī)模較大,這導(dǎo)致建設(shè)與服務(wù)成本目標(biāo)高達(dá)22482.07元,客戶滿意度目標(biāo)達(dá)到了3054.696單位;而相較于目標(biāo)權(quán)重α取值為1?δ時(shí),建設(shè)與服務(wù)成本目標(biāo)為7715.482元,與實(shí)驗(yàn)中所得出的最優(yōu)解相比僅提高2.73%,相較于最劣解卻優(yōu)化了65.7%,表現(xiàn)在開(kāi)放的候選點(diǎn)較少,且規(guī)模較小;但此時(shí)客戶滿意度僅有1613.601單位,相較于實(shí)驗(yàn)中的最優(yōu)解降低了47.2%。因此,權(quán)重極小化方法可以較好地得到某個(gè)單獨(dú)目標(biāo)的優(yōu)劣解,為目標(biāo)優(yōu)化方向提供了較好的參考。 在其他權(quán)重變化中,當(dāng)α為0.3與0.8時(shí),建設(shè)與服務(wù)成本目標(biāo)達(dá)到最優(yōu)7510.095元。當(dāng)α=0.8時(shí),建設(shè)與服務(wù)成本占總目標(biāo)的比重較大,因此,在總目標(biāo)的優(yōu)化過(guò)程中,減少成本的支出成為主要目的,這使得決策者可以在高權(quán)重的情況下,最優(yōu)化成本目標(biāo)來(lái)達(dá)到最優(yōu)決策的目的。當(dāng)α=0.3時(shí),此時(shí)客戶滿意度的權(quán)重較大,但成本目標(biāo)也達(dá)到了優(yōu)化的目的。這可為決策者提供多方案的選擇,并且由于客戶滿意度權(quán)重較高,因此,可以在不影響成本目標(biāo)的前提下,結(jié)合實(shí)際情況優(yōu)化某些可控參數(shù)來(lái)繼續(xù)優(yōu)化滿意度目標(biāo)。 當(dāng)1?α=0.9時(shí),客戶滿意度目標(biāo)達(dá)到最優(yōu)2558.788單位。此時(shí)總目標(biāo)優(yōu)化中,增大客戶滿意度成為主要目的,這也體現(xiàn)在店面建設(shè)的數(shù)量較多,使更多的客戶更容易獲得店面服務(wù)。同時(shí),在權(quán)重變化中,客戶滿意度目標(biāo)波動(dòng)沒(méi)有成本目標(biāo)波動(dòng)明顯,滿意度目標(biāo)的優(yōu)劣相差為21.7%,而成本目標(biāo)的優(yōu)劣相差為30.4%。 為了研究 z1,ik ,z2,ik ,z3,ik 的具體優(yōu)化情況,選取α=0.3時(shí)的優(yōu)化結(jié)果為例,此時(shí)開(kāi)放服務(wù)點(diǎn)1,8,13,各種服務(wù)方式的服務(wù)量如圖6所示。 由圖6(a)可知,服務(wù)點(diǎn)1為需求點(diǎn)13~18,21~27提供服務(wù),并且為需求點(diǎn)23提供線下門店回收服務(wù)10.5 kg 和上門回收服務(wù)24.5 kg,為其他需求點(diǎn)提供線下門店回收服務(wù)和郵寄回收服務(wù)。由圖6(b)可知,服務(wù)點(diǎn)8為需求點(diǎn)1~11,36~39提供服務(wù),并且為需求點(diǎn)7,11提供線下門店回收服務(wù)13.5,9 kg 和上門回收服務(wù)31.5,21 kg,為其他需求點(diǎn)提供線下門店回收服務(wù)和郵寄回收服務(wù)。由圖6(c)可知,服務(wù)點(diǎn)13為需求點(diǎn)12,19,20,28~35,40~48提供服務(wù),并且為需求點(diǎn)32提供線下門店回收服務(wù)11.1 kg 和上門回收服務(wù)25.9 kg,為其他需求點(diǎn)提供線下門店回收服務(wù)和郵寄回收服務(wù)。 在本算例中,當(dāng)需求點(diǎn)的線下服務(wù)需求被完全滿足后,即達(dá)到了限制的最大需求βDk 后,需求點(diǎn)的剩余需求量將結(jié)合需求點(diǎn)是否被覆蓋的具體情況,選擇不同的且唯一的服務(wù)方式。如需求點(diǎn)7的需求總量為45 kg,此時(shí)服務(wù)點(diǎn)8滿足了其線下門店服務(wù)的最大需求量13.5 kg,而剩余 31.5 kg 的需求量則全部由服務(wù)點(diǎn)8所提供的上門服務(wù)的服務(wù)方式滿足;需求點(diǎn)13的需求總量為40 kg,此時(shí)服務(wù)點(diǎn)1滿足了其線下門店服務(wù)的最大需求量12 kg,而剩余28 kg 的需求量則全部由服務(wù)點(diǎn)1所提供的郵寄服務(wù)的服務(wù)方式滿足。由此可看出,在一定范圍內(nèi),若決策者可通過(guò)激勵(lì)或營(yíng)銷的管理方式來(lái)提升客戶線下服務(wù)的意愿,不僅可以增加客戶滿意度,同時(shí)也可減少其他服務(wù)方式所產(chǎn)生的運(yùn)營(yíng)成本,以此來(lái)實(shí)現(xiàn)利益最大化。 權(quán)重的變化影響著各目標(biāo)函數(shù)的優(yōu)化結(jié)果,也是決策者所關(guān)心的重點(diǎn)。α值的變化對(duì)決策產(chǎn)生的影響如圖7所示。Z 為優(yōu)化目標(biāo)。將2個(gè)目標(biāo)函數(shù)的優(yōu)化結(jié)果進(jìn)行歸一化處理,消除量綱和數(shù)量級(jí)的差異。再將建設(shè)與服務(wù)成本結(jié)果與權(quán)重α值相乘,減去客戶滿意度結(jié)果與(1?α)相乘后得到優(yōu)化目標(biāo)值。在α=0.1時(shí),優(yōu)化目標(biāo)達(dá)到最小,此時(shí)客戶滿意度的權(quán)重很大,雖然客戶滿意度優(yōu)化效果最好,但建設(shè)與服務(wù)成本的優(yōu)化效果卻最差,這種極度偏差的權(quán)重設(shè)置在決策時(shí)往往是與現(xiàn)實(shí)相沖突的,也是不可行的。因此,選取“=0.4時(shí)的優(yōu)化結(jié)果作為最優(yōu)解提供給決策者,此時(shí)建設(shè)與服務(wù)成本和客戶滿意度雖然都沒(méi)達(dá)到最優(yōu),但總體的優(yōu)化結(jié)果卻是最優(yōu)的,并且權(quán)重值也較為均衡,符合現(xiàn)實(shí)考慮的情況。 此外,為了驗(yàn)證本文所設(shè)計(jì)算法的求解性能,選擇“=0.4的情況下,對(duì)比本文算法、改進(jìn)蘑菇算法[21]、遺傳算法的求解效率,結(jié)果如圖8所示。改進(jìn)蘑菇算法和遺傳算法在解的質(zhì)量上均不如本文改進(jìn)的算法。 4 結(jié)束語(yǔ) 回收企業(yè)線下門店選址的決策很大程度上決定了潛在回收量的多少,而想要提高回收量,為客戶提供多樣化的服務(wù)方式將是重要的手段之一,其可為企業(yè)帶來(lái)強(qiáng)有力的競(jìng)爭(zhēng)優(yōu)勢(shì)。因此,本文將企業(yè)的選址問(wèn)題與服務(wù)方式相結(jié)合,建立了以建設(shè)與服務(wù)成本最小化、客戶滿意度最大化為目標(biāo)的非線性數(shù)學(xué)模型來(lái)定量研究企業(yè)的回收連鎖店選址問(wèn)題。根據(jù)所構(gòu)建模型的特點(diǎn),設(shè)計(jì)了改進(jìn)的 MRO 算法對(duì)其求解,并利用某電子產(chǎn)品回收連鎖店選址的實(shí)際算例驗(yàn)證了模型的有效性和算法的可行性。 在后續(xù)研究中,一方面將進(jìn)一步探索多目標(biāo)問(wèn)題的智能優(yōu)化求解方法;另一方面,將更多的影響因素(如政府補(bǔ)貼、定價(jià)策略)納入回收連鎖店的選址問(wèn)題中,使其更加符合實(shí)際情況。 參考文獻(xiàn): [1]周林, 康燕, 宋寒, 等.送提一體與終端共享下的最后一公里配送選址——路徑問(wèn)題[J].計(jì)算機(jī)集成制造系統(tǒng), 2019, 25(7):1855–1864. [2]黃露, 紀(jì)延光.考慮顧客延誤損失的配送中心選址雙層規(guī)劃問(wèn)題研究[J].工業(yè)工程, 2021, 24(2):141–147. [3]陳義友, 張錦, 羅建強(qiáng).顧客選擇行為對(duì)自提點(diǎn)選址的影響研究[J].中國(guó)管理科學(xué), 2017, 25(5):135–144. [4] ZHANGY,BERMANO,VERTERV. Theimpactof clientchoiceonpreventivehealthcarefacilitynetwork design[J]. OR Spectrum, 2012, 34(2):349–370. [5] NAIMISADIGHA,F(xiàn)ALLAHH,NAHAVANDIN. A multi-objective supply chain model integrated with location of distribution centers and supplier selection decisions[J]. TheInternationalJournalofAdvancedManufacturing Technology, 2013, 69(1/4):225–235. [6] RAMEZANIM,BASHIRIM,TAVAKKOLI- MOGHADDAMR. Anewmulti-objectivestochastic model for a forward/reverse logistic network design with responsiveness and quality level[J]. Applied Mathematical Modelling, 2013, 37(1/2):328–344. [7]陳義友, 韓珣, 曾倩.考慮送貨上門影響的自提點(diǎn)多目標(biāo)選址問(wèn)題[J].計(jì)算機(jī)集成制造系統(tǒng) , 2016, 22(11):2679–2690. [8]周向紅, 高陽(yáng), 任劍, 等.政府補(bǔ)貼下的再制造逆向物流多目標(biāo)選址模型及算法[J].系統(tǒng)工程理論與實(shí)踐, 2015, 35(8):1996–2003. [9]李鳳月, 齊小剛, 宋衛(wèi)星, 等.基于混合果蠅優(yōu)化算法的選址?庫(kù)存聯(lián)合優(yōu)化策略[J].控制與決策, 2022, 37(9):2343–2352. [10]宋艷, 滕辰妹, 姜金貴.基于改進(jìn) NSGA-Ⅱ算法的多級(jí)服務(wù)設(shè)施備用覆蓋選址決策模型[J].運(yùn)籌與管理 , 2019, 28(1):71–78. [11]劉凡, 張惠珍, 周迅.帶模糊需求的開(kāi)放式選址路徑問(wèn)題的混合離散蘑菇繁殖算法[J].計(jì)算機(jī)應(yīng)用研究, 2021, 38(3):738–744,750. [12]陳剛, 付江月, 何美玲.考慮居民選擇行為的應(yīng)急避難場(chǎng)所選址問(wèn)題研究[J].運(yùn)籌與管理, 2019, 28(9):6–14. [13] BIDARM,KANANHR,MOUHOUBM,etal.Mushroomreproductionoptimization (MRO): anovel nature-inspiredevolutionaryalgorithm[C]//2018IEEE congressonevolutionarycomputation (CEC). Riode Janeiro: IEEE, 2018:1–10. [14]宋英華, 葛艷, 杜麗敬,等.考慮車輛等待的應(yīng)急物資調(diào)配方案優(yōu)化研究[J].控制與決策 , 2019, 34(10):2229–2236. [15]賴志柱, 王錚, 戈冬梅, 等.多目標(biāo)應(yīng)急物流中心選址的魯棒優(yōu)化模型[J].運(yùn)籌與管理, 2020, 29(5):74–83. [16]宋存利.求解混合流水車間調(diào)度的改進(jìn)貪婪遺傳算法[J].系統(tǒng)工程與電子技術(shù), 2019, 41(5):1079–1086. [17]魏士偉, 鄧維.基于多精英協(xié)同進(jìn)化遺傳算法的云資源調(diào)度[J].計(jì)算機(jī)應(yīng)用與軟件, 2021, 38(5):274–280. [18]馮晨微, 王艷.云制造系統(tǒng)并行任務(wù)優(yōu)化調(diào)度[J].系統(tǒng)仿真學(xué)報(bào), 2019, 31(12):2626–2635. [19]李珍萍, 毛小寸.多需求多類型自提點(diǎn)選址分配問(wèn)題[J].計(jì)算機(jī)集成制造系統(tǒng), 2018, 24(11):2889–2897. [20]張沁莞, 張惠珍.深埋式垃圾桶多目標(biāo)選址模型研究及其應(yīng)用[J].系統(tǒng)工程, 2018, 36(10):91–101. [21]賴志柱, 王錚, 戈冬梅, 等.多目標(biāo)應(yīng)急物流中心選址的魯棒優(yōu)化模型[J].運(yùn)籌與管理, 2020, 29(5):78–87. (編輯:石瑛)
