基于LSTM-Adam的刮板輸送機鏈傳動系統故障預警方法
2023-10-12 05:31:32李博郭星燃李娟莉王學文夏蕊
工礦自動化 2023年9期
李博, 郭星燃, 李娟莉, 王學文, 夏蕊
(1. 太原理工大學 機械與運載工程學院,山西 太原 030024;2. 煤礦綜采裝備山西省重點實驗室,山西 太原 030024)
0 引言
刮板輸送機作為煤礦井下運輸的關鍵設備,其工作的安全性與穩定性對實現煤礦高效綠色開采極其重要。刮板輸送機長期處于惡劣工況環境下,導致其各種故障頻發,尤其是鏈傳動系統,所受載荷變化頻繁,常發生卡鏈和斷鏈等故障,對煤礦經濟效益與煤礦安全造成巨大威脅。因此,在鏈傳動系統發生故障前進行預測性維護與更換,對煤礦高效安全開采具有重大意義。在傳統故障診斷領域,眾多學者針對刮板輸送機故障診斷方法開展了研究。于林[1]采用磁場與霍爾元件相結合的刮板檢測傳感器監測斷鏈故障。趙馭陽[2]提出了基于有向無環圖支持向量機(Directed Acyclic Graph-Support Vector Machine,DAG-SVM)的刮板輸送機故障監測方法。崔宏堯等[3]提出了基于混沌差分進化的刮板輸送機故障診斷方法。以上方法能夠在一定程度上實現對刮板輸送機部分結構的故障診斷,然而,傳統的故障診斷需要大量的先驗知識和主觀干預,要求技術人員經驗豐富。
深度學習具有強大的自主判斷與感知能力,廣泛應用于語音識別[4]、圖像識別[5]、機械故障預警與診斷[6-9]等領域。王學文等[10]使用神經網絡對刮板輸送機的運行軌跡進行預測。劉家瑞等[11]提出將深度卷積自編碼器用于風電機組狀態故障預警中。深度學習方法以數據為驅動,能夠提取數據的隱藏特征,對相關數據趨勢進行精準預測,最終實現對異常情況的準確預警。常用的深度學習模型主要有長短期記憶神經網絡(Long Short-Term Memory,LSTM)[12]、卷積神經網絡(Convolutional Neural Network,CNN)[13]、相鄰差分神經網絡(Adaptive Deep Neural Network,ADNN)[14]等,其中LSTM在數據預測和故障預警方面具有良好效果[15-17]。鑒此,本文提出了基于LSTM-Adam的刮板輸送機鏈傳動系統故障預警方法。在LSTM的基礎上結合Adam算法建立LSTM-Adam預測模型,對正常運行工況下的刮板鏈運行數據進行預測,并采用滑動加權平均法對預測數據進行殘差分析,得到合理的預警閾值,當殘差超過預警閾值時進行預警。
1 刮板輸送機故障預警框架
基于LSTM-Adam的刮板輸送機故障預警包括數據采集、數據預處理、LSTM-Adam預測模型構建、預警判斷4個步驟,如圖1所示。

圖1 基于LSTM-Adam的刮板輸送機故障預警框架Fig. 1 Fault warning framework of scraper conveyor based on LSTM-Adam
1) 數據采集。試驗中使用的數據來源于刮板輸送機工況監測系統,將傳感器采集的數據導入SQL Server數據庫中。
2) 數據預處理。從SQL Server數據庫中提取數據,對數據進行清洗和min-max歸一化處理。
3) LSTM-Adam預測模型構建。搭建LSTM模型,使用Adam算法對模型進行優化,得到最優預測模型。
4) 預警判斷。將數據導入優化后的LSTM-Adam預測模型,利用滑動加權平均法進行殘差分析,確定預警閾值。
2 數據采集與預處理
2.1 數據采集
以SGZ1000/2×1200型刮板輸送機為原型,依據相似理論,按照1∶3的相似比設計刮板輸送機試驗臺,如圖2所示。基于組態技術建立刮板輸送機工況監測系統,如圖3所示。

圖2 刮板輸送機試驗臺Fig. 2 Test platform of scraper conveyor

圖3 刮板輸送機工況監測系統Fig. 3 Working condition monitoring system of scraper conveyor
系統監測的物理量:減速器輸出軸轉矩及轉速,用以表征刮板輸送機運行阻力與運行速度;中部槽中板壓力,用以表征刮板輸送機運輸能力;刮板在豎直方向的振動加速度,用以表征鏈傳動系統中刮板的振動狀態;刮板鏈在運行方向的應變,用以表征鏈條張力。
采用傳感器、測量儀表、無線網關等硬件設備(圖4)進行數據采集,將設備與上位機建立通信,保證數據實時傳輸。

圖4 數據采集設備Fig. 4 Data acquisition equipment
利用組態王等上位機監測軟件將設備采集的數據暫存至實時數據庫及歷史數據庫,并將采集的數據實時保存至SQL Server數據庫中,為后續故障預警提供數據源。
2.2 數據預處理
刮板輸送機運行時,刮板鏈應變等物理量存在明顯的周期性,將采集的數據按周期劃分進行分析,可以發現不同周期內數據變化規律相似。因此,選擇對不同周期內缺失數據所在位置對應的臨近值求算術平均,以填補缺失數據,實現數據清洗。
為了消除各類參數對應量綱的影響,防止數量級較大的參數在訓練時占據主導地位,減小數量級的差異以加快迭代收斂速度,需要對樣本數據進行歸一化處理。采用min-max歸一化方法來對樣本數據進行處理。
3 LSTM-Adam預測模型構建
3.1 LSTM模型
LSTM是在循環神經網絡(Recurrent Neural Network,RNN)基礎上建立的,可避免RNN在處理長時間序列數據時出現長期依賴的問題,且LSTM增添了門控結構,可利用該結構控制信息的保留與舍棄,完成對信息流的動態控制。
LSTM單元結構如圖5所示。
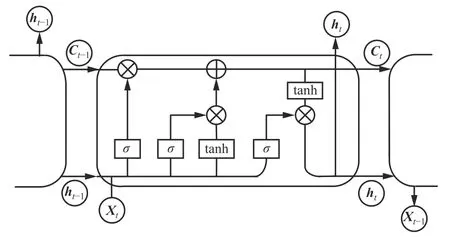
圖5 LSTM單元結構Fig. 5 LSTM unit structure
LSTM主要由遺忘門、輸入門和輸出門來控制細胞狀態。其中遺忘門是由上一時刻隱藏層狀態ht-1和當前t時刻輸入向量Xt共同作用,通過Sigmoid函數得到輸出向量ft,上一時刻細胞狀態Ct-1再與ft逐點相乘,完成數據遺忘的功能。
式中:σ(·)為Sigmoid函數;Wt為遺忘門待訓練參數矩陣;bc為遺忘門待訓練偏置項。
輸入門運算表達式為
獲取遺忘門輸出向量ft、候選狀態候選狀態權重向量it后,可將上一時刻細胞狀態Ct-1轉換為當前時刻細胞狀態Ct,轉換公式為
式中*為矩陣中每個相同位置的元素相乘運算符。
輸出門運算表達式為
式中:Ot為隱藏層狀態權重向量;W0為輸出門待訓練參數矩陣;b0為輸出門待訓練偏置項;ht為當前時刻隱藏層狀態。
ht和Xt共同作用在輸入門上,通過Sigmoid函數得到隱藏層狀態權重向量Ot,當前時刻細胞狀態Ct通過tanh函數歸一化,得到一個所有元素值在-1~1之間的向量,將其與隱藏層狀態權重向量Ot相乘,有選擇地遺忘部分信息,即可得到當前時刻的隱藏層狀態ht,完成短期記憶的更新。
3.2 Adam算法
在LSTM模型訓練過程中,需要使用優化算法來計算和更新模型的網絡參數,使其盡可能地逼近最優值,得到最佳模型,實現對數據變化趨勢的準確預測。
Adam算法[18]作為一種自適應學習率優化算法,會獨立為每一個模型參數設計自適應學習率,充分利用學習率對模型性能的影響,提高模型訓練速度。Adam算法迭代過程:① 對學習率等參數進行初始化。② 計算目標函數梯度和帶偏差的一階、二階矩估計。③ 對一階、二階矩估計進行校正并更新待求解參數。
3.3 LSTM-Adam預測模型建立流程
將預處理后的數據以8∶2的比例劃分為訓練集與測試集。采用Adam算法來計算和更新LSTM模型的網絡參數,構建LSTM-Adam預測模型,如圖6所示。

圖6 LSTM-Adam預測模型建立流程Fig. 6 Build process of LSTM-Adam prediction model
3.4 LSTM-Adam預測模型評估
為檢驗LSTM-Adam預測模型在刮板輸送機鏈傳動系統故障預警中的可行性與準確性,從刮板輸送機工況監測系統數據庫中選取部分刮板鏈應變歷史數據,對LSTM-Adam預測模型進行評估。
3.4.1 模型評估標準
選擇均方誤差[19]對LSTM-Adam預測模型進行評估。均方誤差是指真實值與預測值之差的平方的數學期望,反映真實值與預測值之間的差異程度。均方誤差越小,說明預測模型精度越高。
3.4.2 模型訓練
將刮板輸送機試驗臺的刮板鏈應變歷史數據導入LSTM-Adam預測模型,經過預處理后,隨機將數據集劃分為訓練集和測試集。
針對刮板鏈應變的預測,選擇不同模型節點數進行多次調試,不同模型節點數下的均方誤差見表1。綜合考慮節點數對模型訓練效果的影響,選擇節點數為128。

表1 不同模型節點數下的均方誤差Table 1 Mean square error under different model node numbers
選取Adam算法學習率分別為0.01,0.001,0.000 1,對模型參數進行優化。結果發現在不同學習率下,測試集的均方誤差在第2次迭代時均發生驟降,且學習率為0.001和0.000 1時的下降速度基本一致,學習率為0.01時的下降速度較慢;在后續迭代過程中,使用學習率為0.001的Adam算法得到的測試集均方誤差比使用學習率為0.000 1的Adam算法得到的測試集均方誤差要小,綜合考慮,設置Adam算法學習率為0.001。此外,設置批大小為128。通過Adam算法不斷進行迭代,以優化模型參數,得到最優模型。
3.4.3 模型擬合
將LSTM-Adam預測模型的預測結果與試驗臺實際運行數據進行擬合對比,結果如圖7所示。可看出在第30,70,110,150個監測點處,預測值與真實值之間的差異較大,這是由于刮板鏈通過驅動鏈輪時,鏈條拉力快速變化引起應變突變,預測模型可能會存在一些誤差;但總體來看,預測模型能夠對刮板鏈應變數據的變化趨勢進行準確預測。

圖7 刮板鏈應變Fig. 7 Scraper chain strain
4 預警判斷
4.1 滑動加權平均法
滑動加權平均法是由滑動平均法和加權平均法發展而來的一種數據處理方法[20-21]。滑動加權平均法使用滑動時間窗口進行數據計算,并考慮了數據的加權平均值,可提高數據的可靠性和精度。
結合試驗臺采集數據的特性,對數據的周期、周期內采樣次數和各點殘差變化規律進行分析,在計算點k前后,分別選取20個在時間序列上連續的數據,將它們乘以對應的權重,再計算數學期望,即可得到計算點k的滑動加權平均值:
式中:xk為計算點k對應的數值;pk為xk的權重。
在式(7)中還需確定各點權重的大小,考慮到使用滑動加權平均法處理殘差的目的是利用滑動加權得到的殘差均值來代替該點殘差,因此選擇給當前點賦予單獨的權重p1=4,其余各點賦予相同的權重p2=1,則計算點k的滑動加權平均值為
4.2 預警判斷流程
基于對刮板輸送機大量運行數據的分析,可將正常運行工況下同類數據的最大殘差作為預警閾值。預警判斷流程如圖8所示。

圖8 預警判斷流程Fig. 8 Warning judgment process
5 試驗驗證
5.1 試驗條件
本試驗以刮板輸送機鏈傳動系統故障為例,對基于LSTM-Adam的刮板輸送機故障預警方法的可行性進行驗證。在刮板輸送機試驗臺上,通過加大刮板運行阻力、增加煤矸石數量和更換即將發生疲勞斷裂的鏈條等方法來模擬鏈傳動系統故障,并將采集到的故障數據存儲到數據庫中。
為了更加貼合實際情況,試驗中刮板輸送機均是在滿載情況下運行。
5.2 試驗過程
將正常運行工況下刮板鏈應變數據導入LSTMAdam預測模型中,并對預測所得數據進行殘差分析,結果如圖9所示。可看出刮板鏈應變的最大殘差為46.7,因此將刮板鏈應變的預警閾值設定為46.7。

圖9 正常運行工況下刮板鏈應變數據殘差分析結果Fig. 9 Residual analysis results of scraper chain strain data under normal working condition
確定故障預警閾值后,從故障數據庫中提取部分數據導入LSTM-Adam模型中進行預測,得到殘差,并對殘差進行處理,最終得到故障預警結果。
5.3 試驗結果
5.3.1 卡鏈工況
在試驗臺上模擬卡鏈故障,并將模擬故障實時運行數據導入LSTM-Adam預測模型中,得到殘差結果,如圖10所示。可看出殘差在第135個監測點處開始出現異常,超出預警閾值,隨后殘差又恢復到預警閾值以下。

圖10 卡鏈工況下的殘差Fig. 10 Residual under stuck chain condition
結合對鏈傳動系統常見故障形式的分析可知:當中部槽內出現異物致使刮板輸送機發生卡鏈故障時,刮板鏈應變急劇增大;當鏈條發生卡滯時,隨著鏈條拉力不斷增大,鏈條通常會克服異物的阻礙,恢復到正常運行狀態。這與卡鏈故障預警時的殘差分析結果相符。
5.3.2 斷鏈工況
在試驗臺上模擬斷鏈故障,并將模擬故障實時運行數據導入LSTM-Adam預測模型中,得到殘差結果,如圖11所示。可看出殘差在第137個監測點處開始出現異常,超出預警閾值,之后殘差雖有下降,但呈周期性波動,峰值仍高于預警閾值。

圖11 斷鏈工況下的殘差Fig. 11 Residual under broken chain condition
結合對鏈傳動系統常見故障形式的分析可知:雙鏈刮板輸送機在1條鏈發生斷裂時,未斷裂鏈條上的應變會急劇增大,已斷裂鏈條上的應變會急劇減小,且未斷裂鏈條上的應變無法恢復到正常值。由于預測值呈周期性變化,所以殘差分析結果呈周期性變化,這與斷鏈故障預警時的殘差分析結果相符。
6 結論
1) 基于組態技術搭建刮板輸送機工況監測系統,實時獲取刮板輸送機運行狀況數據,為刮板輸送機故障預警提供數據支撐。
2) 利用Adam算法優化LSTM模型,提出了LSTM-Adam預測模型。當學習率為0.001時,預測模型訓練效果最優,能夠準確預測出刮板鏈應變數據的變化趨勢。
3) 采用滑動加權平均法對正常運行工況下刮板鏈應變數據進行殘差分析,得到其預警閾值。試驗結果表明:基于LSTM-Adam的刮板輸送機故障預警方法能夠對鏈傳動系統異常情況進行準確預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
核科學與工程(2015年4期)2015-09-26 11:59:03
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年2期)2015-04-17 01:30:34
