軟件定義異構虛擬云車網移動大數據在線接入設計
2023-10-10 07:45:10余庚
長春師范大學學報 2023年8期
余 庚
(福建船政交通職業學院,福建 福州350007)
0 引言
近年來智能網聯汽車市場高速發展促進了車聯網技術的深度推廣。云計算技術在服務質量(Quality of Service,QoS)方面良好地鞏固了車聯網[1]技術的部署成效。隨著惠民購車政策相繼出臺,該云車網將涌現出大規模移動智能汽車終端,并由此產生出大規模隨機突發移動智能車端應用服務請求。這勢必在QoS方面給云數據中心帶來較大的挑戰。諸如,在不增加投建成本的現實環境中,云計算方案在帶寬有限的廣域網內響應海量傳感數據計算請求時,既要保證通信時延效率,也要兼顧數據計算的可信度。不僅如此,對于大量部署在邊緣方位的云端而言,移動計算依然需在滿足時延敏感性應用服務要求的同時確保云端能耗的節能減排。
在移動應用請求持續增長的大數據環境下,為進一步延伸云端QoS的有效覆蓋范圍,考慮在移動邊緣網絡定義一個半虛擬化的霧計算模式[2]。通過挖掘和調度邊緣霧計算資源為移動車端應用服務請求提供邊緣分析和響應能力,以延伸虛擬云車網應對移動大數據服務需求。為弱化大規模移動應用請求的隨機突發特性對云端和邊緣霧端產生的偏好[3],在一種效能約束前提下,通過分布式移動霧計算(Distributed Mobile Fog Computing,DMFC)算法協同異構云車網中云霧兩端資源來響應邊緣移動車端用戶的大數據應用服務請求。
1 算法思想
為兼顧移動車端用戶請求的QoS與異構云車網的效能,考慮通過分布式挖掘邊緣霧端移動計算資源來逐級配合云計算的協作[4]服務模式。為便于說明異構云車網的工作機制,將全網分為邊緣霧層和遠端云層。其中,邊緣霧層面向移動車端用戶。該層引入管控解耦的軟件定義控制器以便協作移動數據通信。經由該軟件定義控制器可實時監視每個移動邊緣網絡中核心霧節點的已用資源、剩余可響應資源的比例。當移動車端用戶發起計算服務請求時,此控制器將根據資源使用情況為每一個核心霧節點評估可受理的數據流量規模。
并按照負載均衡原則動態調配各個核心霧節點的計算量。若核心霧節點可用計算資源不足以響應移動車端用戶提請的移動計算請求,則協作霧節點在軟件定義控制器的指引下將剩余的超載數據量轉發至遠程云端。所有移動車端用戶均通過邊緣霧層的無線基站和路側單元來實現移動大數據應用服務請求接入。
DMFC算法自下而上的分布式均衡計算機制可提供包括時延級QoS和能耗管理在內的個性化移動邊緣服務。通常在節假日或上下班交通繁忙時段,核心霧節點難以承載大規模的移動大數據流量。協作霧節點則結合軟件定義控制器根據每個核心霧節點的數據處理能力和空間分布距離制定最佳流量調度策略,從而實現時延級QoS目標。能源管理對于輕量級移動服務器構成的邊緣霧層而言是一個敏感的熱點問題,關乎到整個異構云車網的數據通信成本。因此,實現既定規模數據任務下的節能減排也應作為FCM算法約束成本的另一目標。
為充分挖掘資源節點的數據分析能力,提高數據計算效率,在異構云車網中的邊緣霧層嵌入虛擬化技術以滿足個性化應用請求。每個節點內部的虛擬機在數據通信效率和能耗方面各有差異,協作霧節點下發移動數據流量后核心霧節點將科學評估該節點內部每個虛擬機的可受理載荷量。力爭以最佳的時延效率和最低的能耗完成FCM算法的效能[5]目標。
2 時延級QoS目標設計
為便于說明FCM算法特性,為異構虛擬云車網定義一個遠程云數據服務中心C和軟控制設備S。同時定義一個協作霧節點F,用于配合n個核心霧節點fn開展移動大數據計算。由此可構建整個軟件定義異構虛擬云車網拓撲結構圖,記作G={C,S,F,f1,f2,…,fm,…,fn}。為描述在開展移動大數據接入計算時云霧兩端之間節點交互性,引入節點連通度L={lf1-c,lf2-c,…,lfm-c,…,lfn-c,lf1-f2,…,lf1-fm,…,lf1-fn}。其中,lfn-c表示第n個核心霧節點fn和云端數據服務中心之間的連通度;lf1-fn表示第1個核心霧節點f1和第n個核心霧節點fn之間的連通度。假設遠程云端和核心霧節點的數據響應能力分別為rc和rm。當邊緣移動車端發起規模為q的移動大數據計算流量時,在軟控制器和協作霧節點的調度下每一個核心霧節點都將被分配到比例為?m的移動大數據計算流量,于是算得每個核心霧節點要受理的流量規模為sm=q·?m。當協作霧節點無法受理移動大數據流量計算時,將調度?c的流量比例到遠程云端數據中心,則云端數據中心需受理的流量規模為sc=q·?c。進一步算得霧節點處理數據業務的時延成本為t0=sm/rm。
假設兩個核心霧節點fm和fx的關聯度[6]為Wm-x。若節點對之間無法數據通信則置0;若節點對在受理計算請求時可實現數據通信則置1。假設核心霧節點fm到達遠程云端數據服務中心C和核心霧節點fx的時延分別為tm-c和tm-x。可求得流量傳輸的時延成本為t1=Wm-x·tm-x。
在FCM算法模型下,從核心霧節點接收到邊緣車端發起的移動大數據接入請求到邊緣車端獲得響應的時間作為全程數據通信時延t。將遠程云端數據中心C和核心霧節點fm的數據通信時延分別設為Tc和Tm。
Tc=Wm-c·tm-c+(q·?c)/rc,
(1)
Tm=Wm-x·tm-x+(q·?m)/rm.
(2)
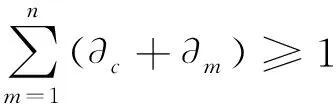
mint=min{max{Wm-c·tm-c+q·?c/rc,Wm-x·tm-x+q·?m/rm}}.
(3)
該模型僅研究云車網節點在單獨工作情形下的數據通信時延。然而根據算法思想中關于QoS的描述,經由軟定義控制設備和協作霧節點的調度,移動大數據計算流量可被分配到其他核心霧節點。故通過引入向量級流量規模s來表征遠端云數據服務中心和n個節點所獲取的待分配流量規模,記作s=(sc,s1,s2,…,sm,…,sn)。相應地,遠端云數據服務中心和n個節點所獲取的待分配流量的比例為?=(?c,?1,?2,…,?m,…,?n),當邊緣移動車端向軟件定義異構云車網核心霧節點f1發起的服務計算請求被成功受理并返回,所消耗的時延表示為
t(s)=max{t1-c·W1-c+q·?c/rc,q·?1/r1,t1-2·W1-2+q·?2/r2,…,t1-n·W1-n+q·?n/rn}.
(4)
相對于計算性能薄弱的輕量級邊緣霧節點,遠端云數據服務中心強大的計算能力在受理一定規模的移動大數據服務計算請求時所需時延基本不會有較大波動,且數據計算時延通常較小。因此遠端云數據服務中心在響應移動大數據計算服務請求時所產生時延成本主要來自流量的上傳下達[7]過程。因此可對式(4)的第一項云設備數據處理時延做缺省處理。則有
t(s)=max{t1-c·W1-c,q·?1/r1,t1-2·W1-2+q·?2/r2,…,t1-n·W1-n+q·?n/rn}.
(5)
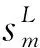
(6)
進一步求得
(7)
針對求解時延等QoS目標函數優化問題,常用的方法為粒子群算法。該算法下的每一個粒子通過相互協作將自身最優方位解傳播給群內其他所有粒子。該算法精確的計算精度和良好的傳播協作特性輔以解耦分離的軟件定義控制器,使其部署在異構虛擬云車網中發揮出目標函數優化成為可能。尤其對于計算資源有限的霧節點而言尤為適用。然而該算法同時存在一些瓶頸。首先,收斂速度與種群多樣性成反比。若將該特征直接用于應對邊緣移動車端突發提請大規模服務計算請求的場景收效甚微。其次,針對本文FCM算法模型所提出的效能約束問題并不在粒子群算法直接攻克的范圍內。這是由于粒子群算法主要目標在于目標優化,面對目標約束性的求解則束手無策。因此可考慮將效能約束的優化求解轉換成無約束的優化求解。

(8)
受遺傳算法[8]求解目標約束函數的啟發,本文FCM算法方案構建一個可行的假設模型:在搜索最小的優化目標函數值時,無效解的目標函數值一定大于所有有效解的目標函數值G(P)。即有效解的值其對應的收斂性最好。相應地,有效粒子的有效域D較小。換言之,獲得有效解的種群粒子一定是滿足了算法預設的約束前提。為評估每一個種群粒子對于當前所獲方位值的適應情況,引入適應性函數f(P)。未能遵守任何一個約束前提的種群粒子都將得到一個較大的適應性變量值。假設存在一個種群粒子因不遵守約束前提條件i使其成為一個無效解。此時,該粒子在搜索空間內的方位為P(i),其違背約束的度為Gi(P)。
(9)

(10)
于是,將式(6)的求解轉換成式(11)進行無約束的優化求解:
(11)
其中,c表示為不遵守約束前提條件i的無效種群粒子分配的偏差系數。


(12)
其中,粒子的移動速度表示如下:
(13)
通過頻繁迭代計算持續更新粒子移動速度和實時方位,便可持續優化式(11)的值。由于粒子群算法存在收斂速度與種群多樣性成反比的瓶頸。為解決該問題,本研究要求粒子在頻繁迭代計算中搜索到最優方位解后立即開始反向移動執行反向優化,以避免由于種群多樣性的下降導致出現收斂過快的情形。反向移動后的方位表示如下:
(14)
其中,粒子反向移動速度為
(15)
關于粒子群優化算法的諸多研討表明,粒子在搜索空間內最佳的搜索系數s的取值區間應在0.3至0.8之間[9],移動系數m1和m2應一致取2。這樣的取值最有利于算法性能的發揮,因此需實時更新粒子在反向和正向移動期間的搜索系數。假設粒子尋找到最佳方位值共開展了FAll次的迭代計算,搜索系數的最大值和最小值分別為sH和sL,則粒子反向的實施搜索系數s-表征如下:
(16)
粒子正向的實時搜索系數s+表征如下:
(17)
根據上述算法過程的描述可知,在軟件定義異構虛擬云車網中部署了FCM算法的霧節點,最終通過降低移動流量的傳輸時延來實現全網移動流量均衡是完全可行的。
3 能耗管控目標設計
經軟件定義控制器和協作霧節點決策后調度到霧層節點的移動大數據計算流量,FCM算法將為其引入虛擬計算技術來實現邊緣網絡霧節點能耗[10]科學管控的目標。霧節點在應對移動大數據計算流量時通常先執行緩存再開展流量計算,相應地產生存儲能耗和計算能耗。
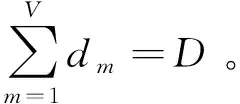
(18)
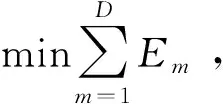
節點在響應移動大數據服務期間,能耗總是與調度的移動流量規模成正比。要想獲得最佳目標函數優化值就要讓虛擬機提供的數據處理資源恰好能夠受理完所調度的移動載荷規模。不存在數據處理資源冗余或短缺的情形。此情形可用如下函數表征:
f(pm,dm)=Em.
(19)
當虛擬機實際功耗取值與每個虛擬機在單位時間受理的計算量相同時,該函數的解便是最佳目標解。
4 方案測試
為驗證所構思的FCM方案模型部署在軟件定義異構虛擬云車網中的成效,測試方案開展了三部分的驗證工作。首先,驗證云霧結合共同為軟件定義異構虛擬云車網節點制定移動計算流量分配方案的可行性。其次,針對基于約束特征的粒子群算法展開通信時延效率的論證。最后,考察節點隨著移動流量規模持續增加所表現出的能耗情況。最終確定全網移動QoS成效。
測試過程引入3個帶寬為3 Mb/s的節點作為遠程云數據服務中心,引入12個帶寬資源介于[100 Mb/s,250 Mb/s]的節點視為核心霧節點,并為每個核心霧節點內部規劃7個虛擬服務模塊。當節點處于滿載時,單位時間內虛擬服務模塊的數據響應能力置為25 Mb/s,此時最高功耗pH取值在區間[15 J,20 J]內;當節點處于靜默休眠狀態時,單位時間內虛擬服務模塊的數據響應能力置為20 Mb/s,功耗pL取值在區間[5 J,10 J]內。部署FCM模型時定義如下相關參數:A=60,FH=1 200,c=15,m1=m2=3,c(F)=1010。實際環境中部署軟件定義異構虛擬云車網存在遠近效應[11],這使得移動計算流量在不同節點之間調度的時延成本有所差異。因此測試方案通過增加核心霧節點和云數據服務中心節點之間帶寬差距來表征實際環境中遠近效應對移動流量的時延影響。
圖1中曲線記錄了云車網中3種移動流量調度方案為車端提供的移動服務響應時延。不難看出采用純云服務方式提供移動服務響應的時延較低,效率較高。這是由于云數據中心服務網絡中的節點具有絕對優勢的數據處理性能。強大的計算響應能力可允許其在一定規模的移動流量范圍內開展低時延的數據響應。但受限于云端和終端的物理間距導致,采用純云服務在數據上傳和下發期間消耗較多時延。倘若通過協調各類霧節點來應對移動計算服務請求,則要付出更大的時延代價。因為缺少云端強大的計算能力支持,僅依托輕量級霧節點有限的數據存儲與并行計算性能,不僅無法受理大規模移動終端發起的隨機突發計算流,同時極易在短時間內達到滿載而顯著降低QoS。因此該方式表現出的時延代價最大。隨著發起的移動流量規模持續增加,輕量級霧節點計算瓶頸越加凸顯流量阻塞、載荷失衡等一系列QoS異常問題。因此時延曲線斜率瞬間增大、走勢瞬間攀升。相應地,移動服務響應效率瞬間陡降。本文構思的云霧結合服務方式則通過軟件定義控制、虛擬計算等全局自適應評估技術充分考量每個霧節點載荷承受度的同時引入強大的云計算能力給予高效協助。通過充分挖掘云霧節點計算潛能不僅有效突破霧節點應對大規模移動流量的瓶頸,同時良好地規避了移動流量對云節點產生的硬件資源偏好風險,為移動終端贏取良好的時延級QoS效果。因此時延曲線走勢最低。

圖1 移動服務響應效率
在證實云霧結合服務方式的可行性后,針對本文構思的基于約束特征的粒子群算法(Constrained Feature Particle Swarm Optimization,CF)展開通信時延效率的論證。引用常用經典的極值均衡算法[12](Extremum Equalization Algorithm,EEA)、貪心算法[13](Greedy Algorithm,GA)作為本組測試的對比方案,考察三種算法方案部署在云霧結合服務的虛擬云車網中的移動計算時延,如圖2所示。根據圖2曲線走勢可知,GA算法和EEA算法部署成效較為接近。相對于CF算法,GA算法和EEA算法的曲線走勢高,意味著這兩種算法為響應終端提請的移動服務計算請求需要付出較大的數據通信時延代價。這樣的QoS顯然不符合車聯網對應用服務的嚴苛要求。導致該現象的原因主要是GA算法和EEA算法忽略了霧節點的數據處理能力,未能建立節點立體化管控模型來實現不同節點間信息交互與資源調度。這些缺乏考慮的性能要素在本文CF算法中均得到了體現。此外,為確保算法所求解具備可信的全局性,CF算法為獲得最優解的粒子增設了反向優化機制。這進一步增強了CF算法得到當前最優解在全局范圍內的自適應能力。這些優勢使得CF算法在本組測試中表現出絕對優勢的通信時延效率,獲得高可靠性的時延級QoS。
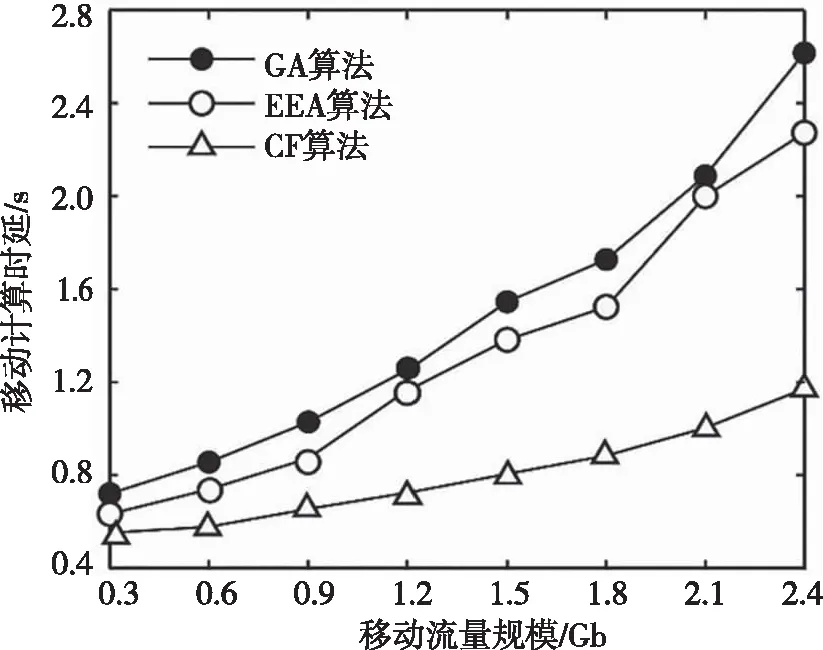
圖2 通信時延效率
能耗作為建設和維護虛擬云車網成本的要素,也是衡量QoS的重要指標。科學的能耗管理目標是當發起的隨機突發移動計算流到達節點時,節點能夠自適應調整其內部虛擬服務模塊的計算參數,以最低的能耗完成每一條移動流的響應服務。本文設計的能耗自適應管控技術正是以此為目標進行設計。為考察自適應管控優勢,引入當前使用相對頻繁的能耗固定[14]管控技術作為對比。測試主要通過持續增加移動流量規模來記錄兩種技術下節點的能耗表現,如圖3所示。
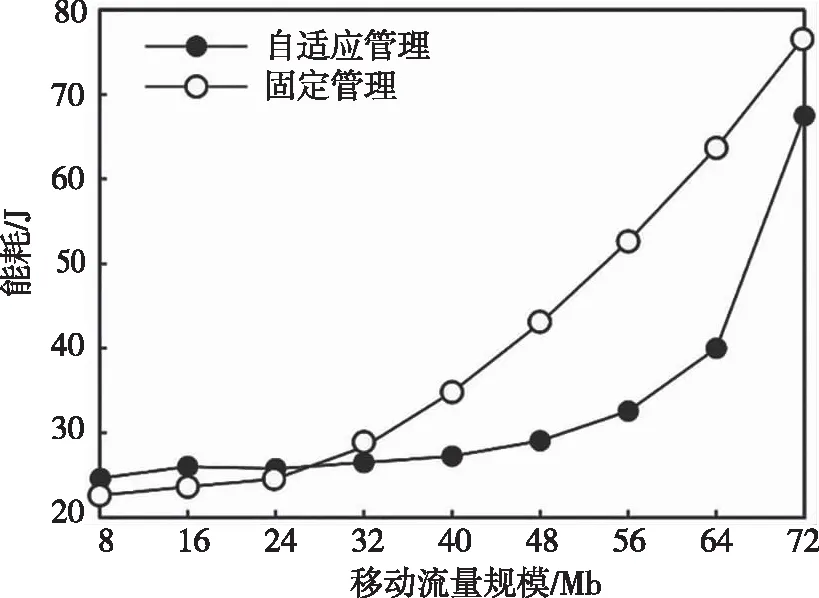
圖3 不同移動流量規模下的能耗管理
從兩種技術曲線走勢可以看出,在發起小規模移動流計算請求時兩種管控技術下的能耗都較低且高度接近,甚至固定管控技術略占優勢。原因是自適應管控技術在響應每一次提請的移動流時,虛擬服務單元都要開展一次工作狀態評估和計算參數調整的工作,額外消耗一系列能耗。而固定管控技術省去了這一過程。但隨著提請的移動計算流規模持續增加,數據處理能力較弱的霧節點很快進入重載狀態并引發移動流擁塞。這導致節點能耗急劇增加,曲線瞬間陡增。此時自適應管控技術則逐漸發揮出管理優勢。因為該技術采用了虛擬化計算策略,能夠根據移動流規模的動態變化科學地評估每個虛擬服務單元可執行的計算量。在確保順利響應移動計算服務的前提下,最小化每個虛擬機的能耗,并且在大規模的移動計算流通信環境中,自適應管控技術的個性化流量分配優勢越能得到發揮,因此曲線斜率并未隨移動流量規模持續增加而變大。隨著移動流量規模進一步增加,全網節點數據存儲和計算處理能力均趨于飽和,網絡擁塞現象逐漸顯現。這導致能耗瞬間陡增,曲線斜率陡增。這樣的趨勢無法避免,因此兩條曲線的末端將逐漸靠近。
5 結語
本文根據異構車聯網節點屬性提出一種基于移動計算資源個性化響應機制。該機制由遠程云端和邊緣霧端協作分工共同響應移動大數據流量的計算服務。所設計的自適應服務響應機制在輕量級移動接入中表現穩定,在應對邊緣車端發起大規模隨機突發移動接入計算時,潛在的優勢愈加得到良好的發揮,為移動車端用戶贏得QoS。
