基于YOLOv5+DeepSORT檢測數據的車頭時距混合分布模型研究
2023-08-12 03:47:22丁正道吳紅蘭孫有朝
測控技術 2023年7期
丁正道, 吳紅蘭, 孫有朝
(南京航空航天大學 民航學院,江蘇 南京 211106)
車頭時距是指在同向行駛的一列車隊中,兩輛連續行駛的車輛的車頭駛過某一點的時間間隔。車輛的到達被視為一個隨機事件序列,因此車頭時距是一個隨機變量,研究該變量的分布規律對于交通安全研究、通行能力分析、道路服務水平、優化道路設計和管理等具有重要意義[1]。
由于交通流的到達具有某種程度的隨機性,采用單一的標準統計模型很難描述這種隨機性的統計規律。嚴穎等[2]基于高斯混合模型將車頭時距分為飽和狀態和非飽和狀態,但只考慮了飽和狀態交通流的車頭時距分布,未對自由流狀態的車頭時距進行研究。陶鵬飛等[3]將車輛的行駛狀態分為跟馳和自由流2種狀態,提出車頭時距的混合分布模型。王福建等[4]在陶鵬飛的研究基礎上,引入強弱跟馳狀態,結合自由流狀態的負指數分布模型,構建三元混合分布模型,但對于描述自由流狀態的負指數分布模型,較小的車頭時距出現的概率較大,這與實際情況不符。
此外,對于車頭時距研究的數據采集方式,以往多采用實地采集并填調查表格的方法,這種方法耗費大量人力和時間,且采集車頭時距精確度較低。隨著智能交通采集技術的發展,車頭時距采集的方式逐漸增多。章慶等[5]提出一種基于雷達數據的飽和車頭時距檢測方法,此種方法需要在道路上搭建微波發射設備,但對于多車道的檢測需要布置多個雷達設備,且雷達在惡劣天氣檢測效果差。王殿海等[6]采用基于自動車牌識別數據對不同車型的車頭時距進行檢測,采用不同數量單一模型的高斯混合模型對采集的數據進行擬合,最后使用AIC準則對最優單一模型數量進行判斷,計算過程復雜,且僅采用過車視頻結合人工調查的方式模擬車牌數據采集,未進行車頭時距自動采集的實踐。嚴穎等[2]雖然采用交叉口電子警察的號牌識別數據進行采集,但僅限于在有專業交通電子設備的路段進行采集,不具有便捷性,而且自動車牌識別數據的時間戳僅精確到秒,采樣精度低。
為實現車頭時距樣本的自動化采集并提高車頭時距模型的準確性,采用YOLOv5+DeepSORT算法對車頭時距樣本進行自動精確采集,并提出一種車頭時距混合模型。首先,分別訓練用于車輛目標檢測的YOLOv5檢測器模型和DeepSORT算法中用于描述車輛外觀特征的ReID模型,接著將過車視頻每一幀輸入到訓練好的YOLOv5模型和DeepSORT算法便可實現對車輛的實時檢測跟蹤。在此基礎上,抽取過車視頻第一幀為基準圖,在基準圖中框選檢測區域和設置檢測線,通過檢測車輛是否觸碰到檢測線來對車頭時距樣本進行自動采集;針對強跟馳、弱跟馳和自由流三種駕駛行為特性,構建雙高斯-移位負指數混合模型;根據自動采集的樣本,采用最大期望(Expectation Maximization,EM)算法擬合出雙高斯-移位負指數混合模型,最后采用K-S(Kolmogorov-Smirnov)檢驗對擬合結果進行擬合優度檢驗,并與三元混合分布、二元混合分布和威布爾分布模型的擬合效果進行對比。
1 車頭時距采集算法
1.1 YOLOv5車輛檢測模型
YOLOv5是一個單階段探測器和基于區域的目標檢測網絡模型,由3個主要組件構成:BackBone、Neck和Head[7],因其高檢測準確性和實時性而在各個領域被廣泛研究與應用。YOLOv5的官方模型中有YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x等多個版本,性能和特點如表1所示。
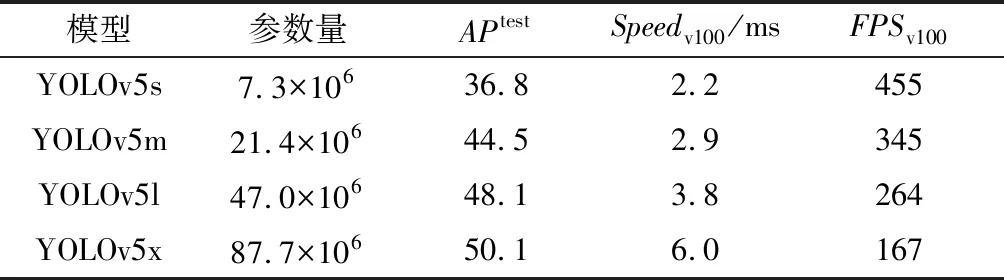
表1 YOLOv5的官方模型的性能及特點
表1中,YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x的模型參數量依次增大,其相應的檢測精度也隨著提升。然而隨之模型變大,檢測速度也有所降低,可以看到YOLOv5s檢測速度為2.2 ms,而YOLOv5x的檢測速度是其將近3倍。而在車頭時距樣本采集時,在滿足檢測實時性的情況下,模型的檢測速度越高,則代表其每秒處理的幀數越多,從而其采集車頭時距樣本的準確度也越高。
此外,在實際的采集車頭時距樣本中,為避免因傳輸過車視頻環節帶來的時間延遲導致樣本采集的實時性降低,從而降低了車頭時距自動采集在智能交通中的實時性應用價值的問題,應采用路側邊緣端處理,較大參數量的模型對邊緣端設備的性能有很高的要求,設備采購成本將會極大地增加。
因此,選擇小參數量的YOLOv5s模型無疑是降低車頭時距采集成本,提高車頭時距采集準確度和實時性的較好選擇。故本文選用YOLOv5s模型檢測車輛,關于YOLOv5s模型的車輛檢測精確度問題,將在下文的測試結果中表明其是否滿足采集需求。
1.1.1 數據集
本文所采用訓練YOLOv5模型的數據集是從網絡上的過車視頻中截取,圖像中車輛全為朝向鏡頭行駛方向,共300張,其中包括單目標圖像、多目標圖像和目標重疊等圖像,圖1為數據集中車輛檢測的主要場景,展現了數據集中幾種較為典型的檢測場景。

圖1 數據集中車輛檢測的主要場景
因為用來訓練模型的數據較少,為了提升模型泛化性并避免過度擬合,所以對數據集進行數據增強處理以擴充數據集[8],數據增強的部分圖片如圖2所示。

圖2 數據增強的部分圖片
每張圖像都有2個增強版本,因此最終數據集圖像數量比原始圖像數量增加了2倍。
利用makesense.ai標注軟件對所用數據集圖片進行標注,轉化為訓練所用的txt格式,并將數據集以8:1:1的比例分為訓練集、驗證集和測試集。
1.1.2 模型改進
(1) 采用CIoU損失函數。
交并比(IoU)是一種評價目標檢測器性能的指標,是由預測框與目標框間交集和并集的比值計算,其考慮的是預測框和目標框重疊面積。
(1)
式中:A為預測框;B為目標框。
然而,IoU沒有引入目標框與預測框中心的之間的距離信息和邊界框寬高比的尺度信息,這使得目標物體的預測框無法準確貼合目標。但在采集車頭時距樣本時,檢測框是否貼合目標的真實輪廓和是否穩定決定著檢測框能否代表車輛的準確位置,這直接影響著樣本的采集精度。而LossCIoU作為改進模型的邊界框損失函數,考慮了邊框中心距離和邊框寬高比的尺度信息,使網絡在訓練時可以保證預測框快速收斂,并能夠得到更高的回歸定位精度。CIoU計算公式為
(2)
式中:b和bgt分別為預測邊框和真實邊框的中心點;ρ(b,bgt)為兩框中心點間距離;c為預測框與目標框的最小外接矩形的對角線距離;α和v由式(3)、式(4)計算。
(3)
(4)
式中:h和hgt分別為預測框與目標框的高度;w和wgt分別為預測框與目標框的寬度。LossCIoU計算公式為
LossCIoU=1-CIoU
(5)
(2) 采用DIoU-NMS。
在傳統的NMS中,IoU常用于提取置信度高的目標檢測框,而抑制置信度低的誤檢框。其操作方法是,選取得分最高的檢測框M,將與M的IoU大于NMS閾值的其他檢測框的置信度置為0,從而剔除了冗余檢測框。然而在面對車輛重疊場景的時候,兩輛車很接近,由于兩車輛檢測框的IoU值較大,經過傳統的NMS處理后,有可能只剩下一個檢測框,導致與實際情況不符。對于傳統NMS在重疊遮擋情況中經常產生錯誤抑制,DIoU-NMS引入了檢測框之間的中心距離作為額外的檢測準則。DIoU-NMS的得分Score更新公式定義如下。
(6)
式中:si為類別得分值;M為得分最高的檢測框;Bi為其他檢測框;ε為NMS閾值。對于兩物體檢測框IoU較大的情況,DIoU-NMS將考慮兩個框之間的中心距離大小,若它們之間的中心距離較大時,將同時保留這兩個物體的檢測框,從而有效提高檢測精度。因此,本文選用DIoU-NMS替代NMS。
1.1.3 實驗設置
YOLOv5s模型實驗配置如表2所示。

表2 YOLOv5s模型實驗配置
訓練參數設置為:輸入圖像尺寸為640像素×640像素;訓練過程中,初始學習率為0.01,終止學習率為0.2;動量參數設為0.937;衰減系數為0.0005;Batch-size為8;訓練輪數為200 epoches。
1.1.4 YOLOv5訓練結果
本文采用YOLOv5官方給出的預訓練網絡模型YOLOv5s進行遷移學習,經200 epoches迭代訓練后,選取得到的最優模型對測試集進行測試。測試結果如表3所示。

表3 原YOLOv5s模型和本文改進模型經測試的結果對比
經過訓練后的本文模型精準率達到了95.5%,召回率為96.9%,平均精度AP(0.5)達到98.1%,滿足后期檢測需求,選取該模型用于車頭時距檢測。
1.2 DeepSORT多目標跟蹤算法
在對車頭時距樣本進行采集時,需要跟蹤每一輛駛入檢測區域的車輛。DeepSORT算法可對檢測到的每輛車進行軌跡跟蹤,并為其分配特定的ID號。DeepSORT算法帶有深度關聯特征[9],在SORT算法的基礎上,添加了一個CNN模型[10]。這個CNN模型被稱為重識別ReID模型,用來提取由檢測器界定目標部分的圖像的特征,利用深度學習算法以減少大量ID切換。
1.2.1 跟蹤處理和狀態估計
DeepSORT 利用目標檢測器的結果初始化跟蹤器,每個跟蹤器都設置有一個計數器,該計數器在卡爾曼濾波預測期間遞增,并在軌跡與測量關聯匹配時重置為0。跟蹤器在預定的最大時間內沒有關聯匹配到合適的檢測結果,則認為該目標已離開場景,將其從軌跡集中刪除。對于無法從現有軌跡集中關聯匹配的每個檢測目標,都會分配跟蹤器,若這些跟蹤器在前3幀都能有預測結果匹配檢測結果,則認為出現了新的軌跡;若前3幀內無法成功關聯軌跡,則刪除跟蹤器。
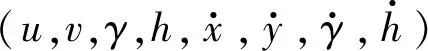
1.2.2 分配問題
DeepSORT通過匈牙利算法匹配預測框和跟蹤框,并在此過程中結合運動信息和外觀特征兩項指標。對于運動信息,算法使用馬氏距離度量卡爾曼濾波器的預測結果和檢測器結果的匹配程度,馬氏距離的計算公式為
d(1)(i,j)=(dj-yi)TSi-1(dj-yi)
(7)
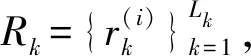
(8)
然后指定一個閾值,比較d(2)(i,j)與閾值的大小來判斷關聯與否。此時,就可以使用馬氏距離提供關于物體短期運動的位置信息預測;使用余弦距離提供的外觀特征信息來對長期遮擋后的目標進行ID恢復。最后使用加權和將這兩個指標進行結合。
ci,j=λd(1)(i,j)+(1-λ)d(2)(i,j)
(9)
1.2.3 ReID模型訓練
DeepSORT算法使用一個殘差卷積神經網絡作為ReID模型以提取目標的外觀特征。原始算法是對行人進行檢測跟蹤,其輸入圖像均被縮放為128像素×64像素大小[9],為使ReID模型適用于車輛特征的提取,將ReID模型的輸入圖像大小設置為128像素×128像素[11],該ReID模型如表4所示。
訓練ReID模型的數據集來自VeRi數據集[12],其由20臺攝像機拍攝完成,包含超過50000張776輛車的圖像。模型結構采用上述調整后的CNN模型選取VeRi數據集中常見車型的100輛車的圖片為訓練數據集,并且提取每輛車的第一個圖片為測試集。經200 epoches訓練后得到的ReID模型,測試結果的Top-1準確率為80%。采用過車視頻對模型進行檢測,無明顯ID跳變和漏檢。
2 樣本數據采集
采用基于YOLOv5+DeepSORT的方法對車頭時距樣本進行采集,圖3為車頭時距樣本數據的采集流程。
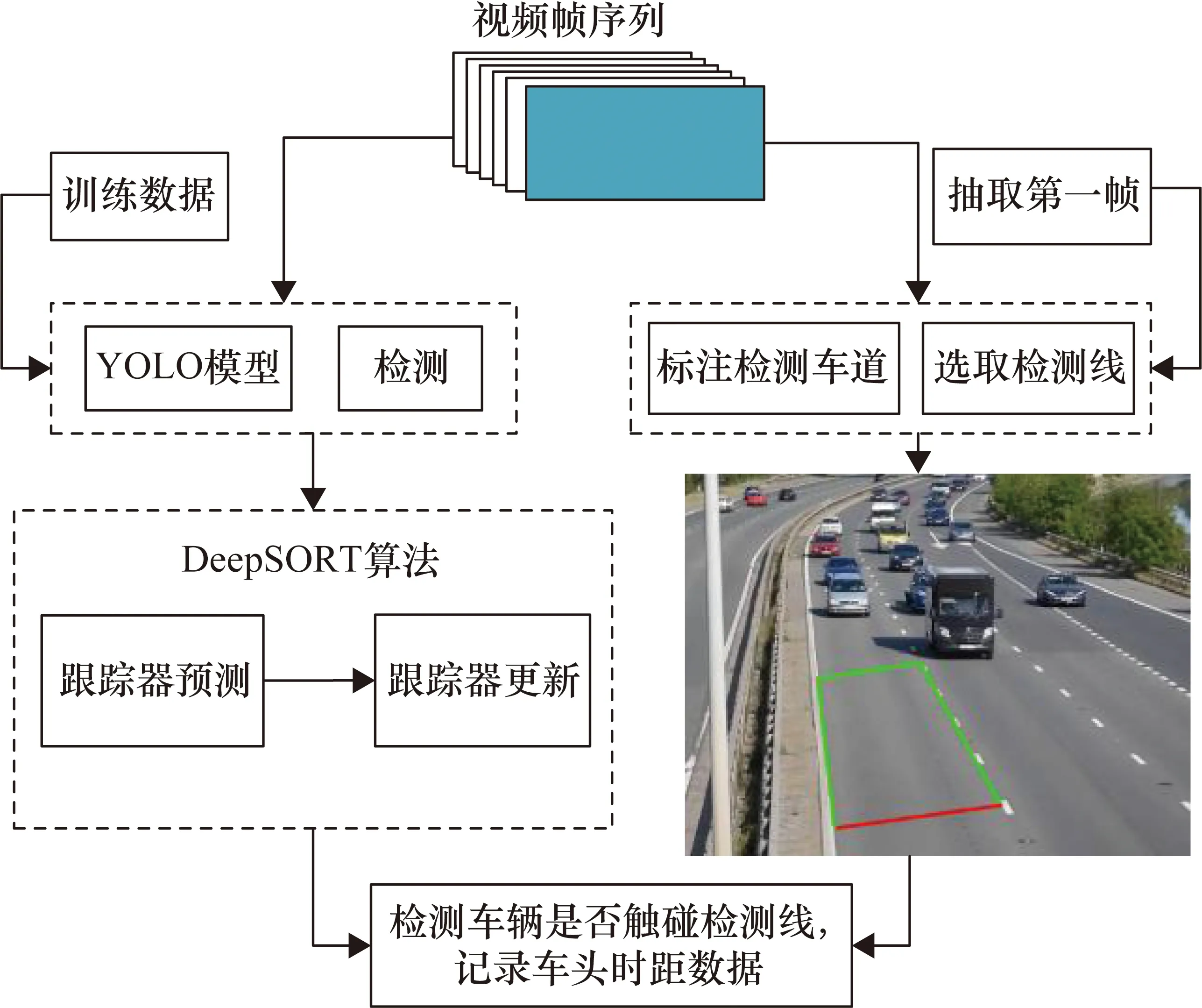
圖3 采集車頭時距樣本數據的方法流程
2.1 過車視頻拍攝與樣本采集
攝像機在拍攝過車視頻時應避免較大的抖動,防止因抖動導致檢測線標定位置相對于路面移動導致車頭時距檢測出現誤差。
抽取過車視頻第一幀圖像作為基準并標定檢測區域,如圖4所示,在要檢測的車道上沿車道線選取合適的四邊形檢測區域,以四邊形底邊為車頭時距檢測線,當有車輛越過該線時,記錄此車與前車之間的車頭時距。

圖4 提取出過車視頻的第一幀為基準并標定檢測區域
采集單個車頭時距樣本的具體流程如下:
① 通過YOLOv5和DeepSORT算法檢測和跟蹤每輛車,并取每輛車的檢測邊框底邊中心點作為此輛車的位置。
② 當前幀中,通過判斷車輛邊框底邊中心點相對于檢測區域四條邊的位置關系,判斷此車輛是否在該檢測區域內,并依此計算當前幀中四邊形檢測區域內所有車輛,將車輛編號計入數組Car_Array=[C1,C2,…,Ci,…,Cn]。
③ 若接下來的某幀中,其上一幀的Car_Array內Ci不在當前幀的Car_Array中,則代表前車越過車頭時距檢測線,并記當前此幀序號第k1幀。
④ 同理,當相鄰的下一次車輛越過車頭時距檢測線時,記此幀序號第k2幀。
⑤ 計算得到車頭時距為
t=(k2-k1)×tframe
(10)
式中:tframe為相鄰兩幀之間的時間間隔;若視頻幀率為30 f/s,則tframe=1/30 s。
此外,通過車輛計數的方法也可對車頭時距樣本進行自動采集,采集流程與上述使用車輛編號的方法類似,通過對比前后兩幀檢測區域內車輛的數量是否減少來確定前車是否駛過檢測線,從而確定駛過時刻。但若在同一幀中,前車越過檢測線駛出檢測區域,后邊一輛車正好越過檢測區域四邊形的頂邊進入檢測區域,此種情況無法判斷是否有車輛駛離檢測區域,則會帶來樣本漏采的情況。
2.2 樣本采集可靠性分析
在對車頭時距樣本進行采集時,誤差可能來自以下幾個方面。
(1) YOLOv5檢測車輛時,目標車輛檢測的位置誤差。
① 檢測框上代表車輛的像素點選取不當。
② 檢測邊框無法貼合實際車輛輪廓。
(2) 多目標跟蹤準確度(Multiple Object Tracking Accuracy,MOTA)[13]。
① YOLOv5檢測時漏檢和誤檢車輛。
② DeepSORT算法跟蹤車輛時目標ID跳變。
(3) 其他情況:攝像機拍攝時的抖動、視頻幀率大小情況等。
采集誤差來源的第(1)條,YOLOv5模型檢測車輛位置的誤差來自兩個方面。
一是選取YOLOv5目標檢測框上的像素點無法準確代表車輛在地平面上的位置而帶來系統誤差。車頭時距視頻監控視角如圖5所示。
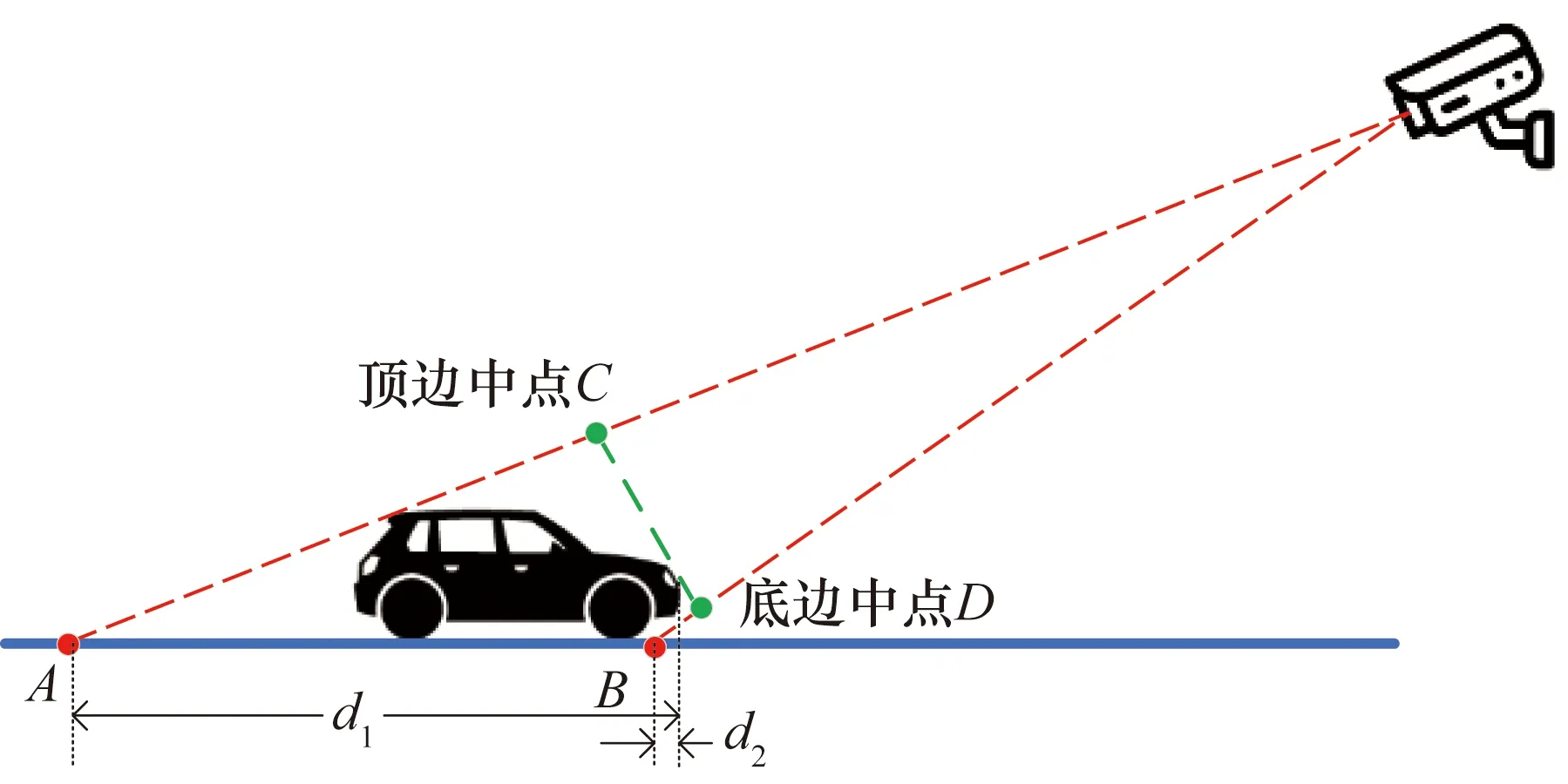
圖5 代表目標車輛位置的檢測框上像素點
由投影幾何學知識可知,若選擇檢測邊框頂邊中點C用以采集樣本(如圖6(a)所示),邊框頂邊中點C在地面的投影距離車輛車頭真實位置的長度為d1,位置誤差較大。采集樣本的過程中,當車頭駛過檢測區域很大一段距離時,才記錄當前車輛的駛離時間。而且對于不同車高的車輛,即便是處于同一位置,其投影點位置也會有所不同,會導致車輛位置檢測誤差和不穩定。本文選擇車輛檢測邊框的底邊中點D來代表車輛車頭位置(如圖6(b)所示),其在地平面上的投影點B相比于其他投影點要更接近于車頭的實際位置,車輛底盤高度帶來的位置檢測誤差為d2,且不同車輛的底盤高度差別并不是很大,這也提高了YOLOv5車輛位置檢測的穩定性。所以選擇目標檢測邊框的底邊中點代表每一輛車的位置更符合實際情況,提高了車輛位置檢測的可靠性。
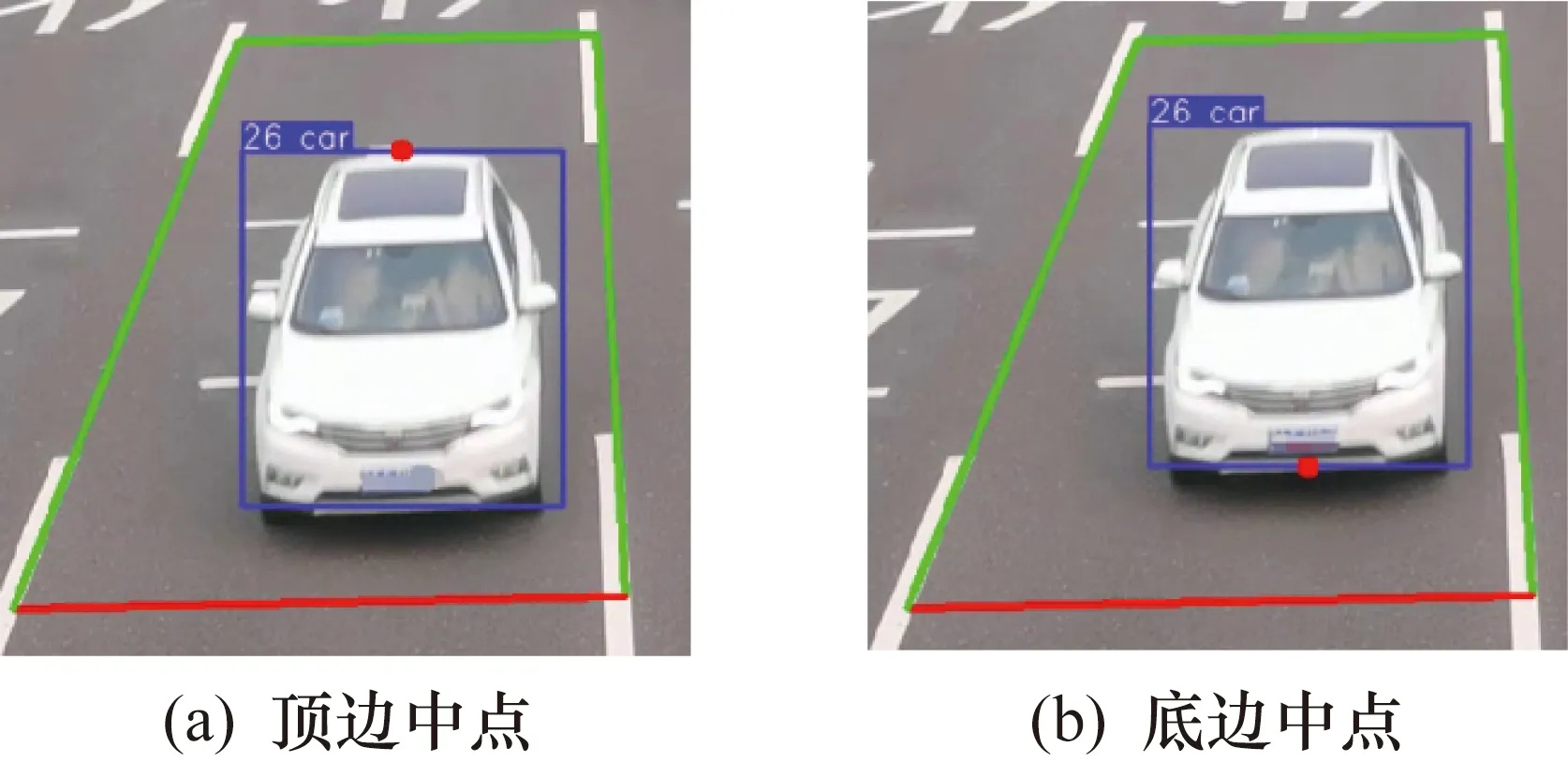
圖6 車輛監控視角攝影示意圖
二是檢測邊框的跳動,檢測邊框無法貼合實際車輛輪廓,導致車輛的檢測位置不定帶來的不定誤差。通過測量車輛實際邊框底邊中點相對于YOLOv5檢測邊框的底邊中點的距離d,然后對該距離進行歸一化處理以衡量車輛位置因檢測邊框的跳動帶來的檢測誤差(err):
(11)
式中:Ddiagonal為當前幀中實際車輛檢測邊框的對角線長度。
樣本采集誤差來源第(2)條中,由于YOLOv5在檢測目標時出現車輛漏檢和誤檢的情況,與DeepSORT算法跟蹤目標時出現車輛ID跳變的情況將直接影響車頭時距樣本采集的準確性。為綜合考慮漏檢、誤檢和ID跳變所帶來的誤差影響,采用MOTA指標綜合評價本文算法的有效性,MOTA被定義為
(12)
式中:t為幀序列數;FN為車輛漏檢數;FP為車輛誤檢數;IDSW為目標ID跳變數;GTt為當前幀中總目標數量。
采用過車視頻對采集算法進行測試。在過車視頻中,實際過車數量為248輛,實測車頭時距平均值為2.66 s;隨機抽取過車中的50輛車,再抽取每一個車輛的任意2幀圖片進行位置誤差計算,最后計算得到平均位置檢測誤差;選取檢測區域內車輛的。本文方法檢測結果及其對比如表5所示。
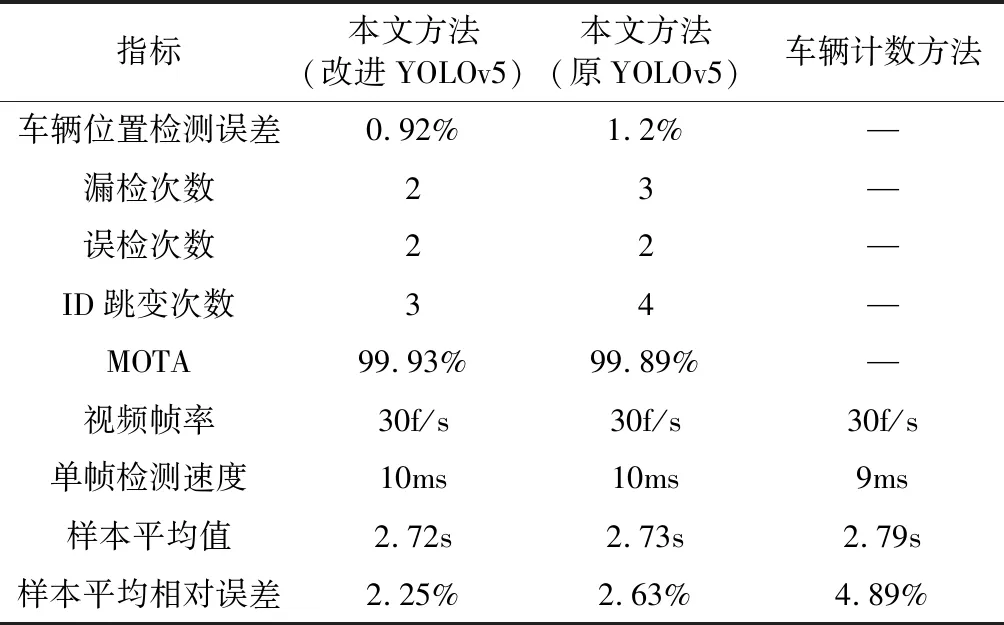
表5 本文采集方法與其他采集方法的檢測結果
由表5可知,采用車輛計數的方法采集車頭時距獲得的車頭時距誤差較大為4.89%。使用改進YOLOv5s模型作為檢測器的方法的車輛位置檢測平均誤差為0.92%,使用原YOLOv5s模型的采集方法的檢測位置平均誤差為1.2%,這表明本文方法中YOLOv5檢測車輛位置具有較高的可靠性,且前者相比于后者的位置檢測更加準確。此外改進后模型的漏檢次數為2次,ID跳變3次,均小于使用原始YOLOv5s模型的采集方法。本文算法對檢測區域內的MOTA指標為99.93%,表明此算法可有效滿足車頭時距樣本采集的需求。
兩者采集的車頭時距樣本平均值相當,分別為2.72 s和2.73 s,樣本平均相對誤差分別為2.25%和2.63%,車頭時距樣本采集誤差在5%以內即可接受[14],所以,雖然本文方法在車頭時距樣本采集時有漏檢、車輛ID跳變、檢測位置誤差、視頻幀率等原因存在,但其平均相對誤差仍在可接受范圍之內,所以本文方法滿足車頭時距樣本采集精確度的需求。過車視頻的幀率為30 f/s,而本文算法的單幀檢測速度為10 ms左右,滿足車頭時距實時性采集需求。
3 車頭時距分布模型構建
對于正常行駛在道路上的車輛,在對車頭時距的概率分布進行研究時,分為跟馳狀態和自由流狀態,兩者的概率分布性質不同。
跟馳狀態主要出現在交通流的密度較大時,車隊中任意一輛車的車速受前車的制約,與前車保持緊隨。但前后車之間保持一個安全距離,以留給后車足夠的反應時間來面對前車的突發制動。由于車隊具有制約性、延遲性和傳遞性,所有這個安全距離是波動的。不同的駕駛員對安全距離的心理閾值不同,基于此類情況將跟馳行為分為謹慎型和激進型,故跟馳所保持的車頭時距概率分布情況亦有所不同。王福建[4]和Taieb-Maimon[15]等對激進型和謹慎型兩種駕駛行為的車頭時距進行了研究,表明其概率分布呈現以均值為中心的左右對稱的情況,并成功用高斯混合模型對跟馳狀態的車頭時距做出通過顯著性水平為0.05假設檢驗的擬合。
自由流狀態出現在交通流密度較小時,駕駛員能夠根據自己的駕駛風格、道路和車輛條件進行駕駛,基本不受道路上其他車輛的影響,并保持期望車速行駛。而在關于混合駕駛行為的車頭時距研究中,大多采用負指數分布來表示自由流交通的車頭時距分布特性,但這導致較小的車頭時距出現的概率較大,與實際情況不符。因此,對于車頭時距概率分布特性的描述很難用單一的標準分布模型來描述,故本文采用高斯混合模型結合移位負指數模型來描述路段車頭時距分布特性。本文車頭時距概率分布模型如式(13)所示。
f(t)=w1f1j+w2f2j+w3f3j
(13)
式中:f(t)為車頭時距t的概率混合分布模型函數;w1、w2、w3分別為兩種跟馳狀態和自由流狀態的樣本數據占總數據的比例,并且w1+w2+w3=1;f1j、f2j和f3j的表達式為
(14)
(15)
(16)
式中:j=1,2,3,…,N,N為樣本總量;μ1、μ2分別為兩種跟馳狀態模型的均值;σ1、σ2為兩種跟馳狀態模型的標準差,表示兩種狀態下車頭時距t相對于均值的離散程度;λ為自由流狀態下車輛到達率;τ為移位參數,取車頭時距t數據中最小的值min(t)。
4 模型參數估計算法
本文采用EM算法來對模型的參數進行估計。EM算法是一種迭代算法,用于含有隱變量的概率模型參數極大似然估計。算法步驟為:
輸入:檢測到車頭時距(t1,t2,…,tN),本文模型f(t)。
輸出:本文模型參數θ=(σ1,σ2,μ1,μ2,λ,w1,w2,w3)。
① 初始化模型參數的值進行迭代。
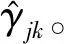
(17)
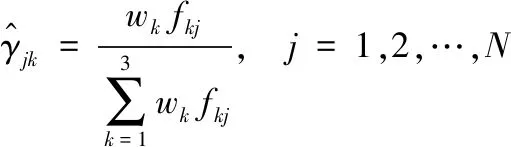
(18)
③ M步:計算下一輪迭代的模型參數。
(19)
(20)
(21)
(22)
④ 重復第②步和第③步,直至各參數收斂在給定范圍內波動停止迭代。
5 實例應用
5.1 樣本數據采集
過車視頻拍攝地點位于寧宣高速路段,時間為傍晚高峰時刻。視頻拍攝完成后,采用YOLOv5 + DeepSORT算法對過車視頻中車頭時距樣本進行采集。
對比分析基于ALPR采集方式[6]和本文采集方式因數據采樣所產生的誤差,如表6所示。
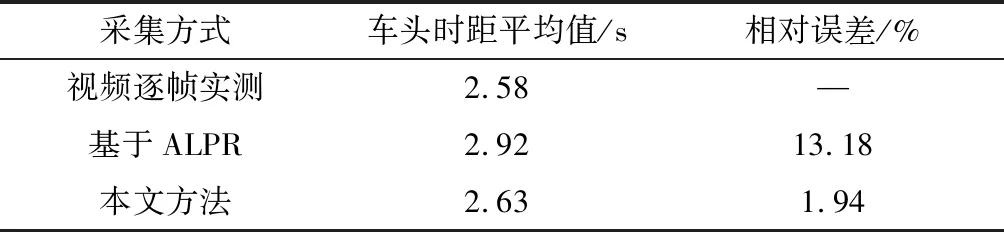
表6 不同車頭時距樣本采集方式與人工實測數據之間的平均相對誤差
表6中,車頭時距樣本的實測平均值為2.58 s,基于ALPR和本文方法的樣本平均值分別為2.92 s和2.63 s,兩種采樣方法相對與實測平均值的相對誤差分別為13.18%和1.94%。由于數據誤差在5%以內才可接受[14],基于ALPR的車頭時距采集方式誤差較大,采用本文YOLOv5+DeepSORT識別方法采集的車頭時距樣本滿足實際的數據輸入準確性要求。
5.2 模型估計結果與分析
利用YOLOv5+DeepSORT檢測過車視頻中車頭時距數據,按照統計檢驗方法對獲取的數據進行本文模型的擬合,應用EM算法進行參數估計,本文模型及對比模型的參數估計結果如表7所示。

表7 本文模型及對比模型的參數估計結果
各模型擬合效果對比如圖7所示,可以看出威布爾分布和二元混合分布模型對樣本數據的擬合效果較差,而本文模型和三元混合分布模型兩者的擬合曲線與樣本數據最為接近,可以明顯看出后兩者的雙峰特征,代表強跟馳和弱跟馳兩種跟馳狀態的車頭時距密度分布狀況。但本文模型由于引入移位負指數模型來描述自由流狀態的車頭時距分布,所以在較小車頭時距處的概率密度分布更貼合實際樣本數據。
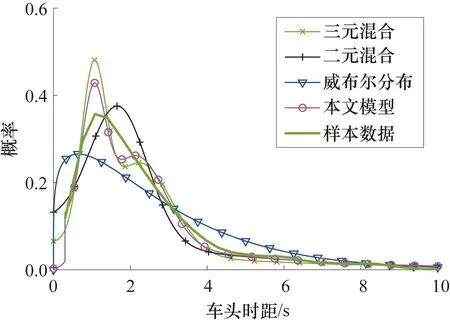
圖7 各模型擬合效果對比
擬合結果采用K-S檢驗[16]進行評估,原假設H0為總體樣本數據符合相應的模型分布,顯著性水平選取0.05,計算樣本數據與本文模型和對比模型的累計分布曲線之間相應的最大垂直差D值,然后與K-S檢驗臨界值表中的顯著性水平為0.05的臨界值D0進行比較,若D>D0則拒絕原假設,否則接受原假設。本文模型與對比模型的K-S檢驗結果如表8所示,表中p值是對原假設成立的評價,代表模型在顯著水平為0.05情況下的非拒絕率。如果p值較小,則對原假設有效性產生懷疑;若p值越大,則越能接受該模型[17]。
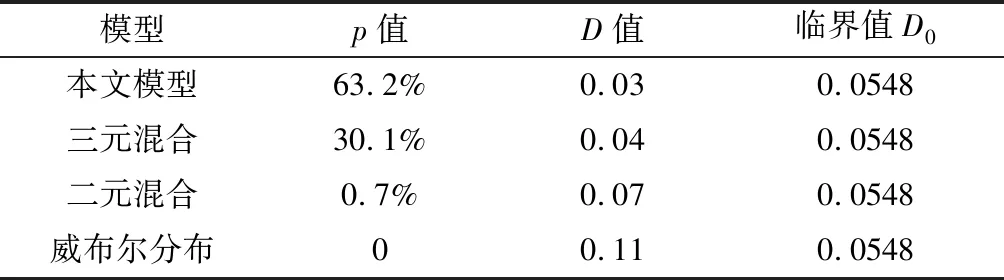
表8 顯著水平0.05情況下的K-S檢驗結果
在表8中,臨界值D0為0.0548,本文模型、三元混合分布、二元混合分布和威布爾分布模型的最大垂直差的D值分別為0.03、0.04、0.07和0.11。所以僅本文模型和三元混合模型的D值小于臨界值D0,接受原假設H0,即采集的車頭時距數據樣本符合本文模型和三元混合模型在顯著水平為0.05下的概率密度分布。但本文模型的非拒絕率p值為63.2%,要遠遠大于三元混合模型的非拒絕率p值30.1%,所以相比于三元混合模型,本文所建立的概率分布模型更好地擬合了實測的樣本數據。
6 結束語
采用YOLOv5+DeepSORT的方法對車頭時距數據進行自動化采集,此方法對車輛的位置檢測可靠,滿足車頭時距采集的準確度需求和實時性要求,并避免了樣本漏檢的情況,解決了人工采集方法工作量大、耗時長和基于ALPR車牌數據采集的不準確的問題。此算法可以部署在邊緣端智能化交通檢測器上對道路上的車頭時距進行實時采集,并通過通信技術將數據上傳至數據庫,可為智能化道路交通參數采集提供一種方法。此外,本文在三元混合分布模型的基礎上對車頭時距概率分布模型進行改進,引入移位負指數分布模型來描述自由流狀態車頭時距的概率密度分布。結果表明該模型具有更好地擬合效果,可以更好的體現車頭時距在各種交通流狀態下的變化特性,可將此模型進一步應用到交通安全研究、通行能力分析、道路服務水平、優化道路設計和管理等方面。
進行車頭時距采集的環境是在天氣晴朗的白天。在未來的研究中,可考慮加入雨天和黑夜等復雜交通場景下的車頭時距樣本采集,提高該車頭時距采集方法的通用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
