學術論文研究亮點的語言特征與主題識別*
2023-08-08 09:32:06楊思洛莫瑩瑩
圖書館論壇 2023年7期
楊思洛,程 濛,莫瑩瑩
0 引言
在學術成果海量增長和網絡知識加速流動背景下,一篇學術論文受到讀者發現與認可的成本越來越高。為了更加精確地匹配讀者和論文,同時吸引受眾的閱讀興趣,愛思唯爾出版集團ScienceDirect數據庫推出了研究亮點(Research Highlight),并對其全部投稿論文提供研究亮點做出了強制性要求。根據作者指南的說明,在形式和內容上,亮點由3-5個要點構成,篇幅限制在85個字符以內,凸顯研究的新穎結果和創新方法,最終逐條展示于論文網頁版本的標題之下;在作用價值上,經由數據庫的機器閱讀匹配,亮點被證明有助于提高論文在搜索引擎中的曝光度,擴大學術成果的傳播范圍,引發科學工作者的關注[1]。當用戶使用ScienceDirect 數據庫進行檢索時,可以發現在返還頁面中,每一條結果與檢索詞匹配的突出黃色標記有兩處,一是標題,二是“Extracts”欄目下的亮點文本,充分表明了亮點對于提升文章可發現性的重要作用。一方面,亮點語言簡明通俗,能夠更加精確地匹配論文與讀者,擴大論文的傳播范圍。對亮點的語言特征進行研究,在當前亮點寫作規范下,探究作者對這一體裁的具體呈現形式,以及受到更多讀者利用的論文如何撰寫亮點,有利于深度發揮亮點的宣傳作用,幫助作者提升文章潛在利用的可能性,促進學術交流與合作。另一方面,亮點作為獨立的組成部分,濃縮了一篇論文最重要且最具特色的新方法和新結論,能夠幫助學者快速獲取論文核心觀點[2],降低文獻閱讀和篩選的成本。對亮點的內容主題進行識別,有利于發現一門學科領域最具突破性的創新貢獻,明確研究重點和發展方向,進一步推動知識流動與科研創新。
目前專門對于學術論文亮點的關注少,研究主題分散,主要在于亮點的概念特征和自動抽取兩方面。在亮點的概念特征上,Yang W以亮點的評價性語言和交互性語篇為研究對象,探究240篇期刊論文亮點的語言學特征,并利用問卷調查總結了編輯和作者對亮點的看法,認為亮點能夠支持論文的學術立場和塑造可靠的學術形象[3];索傳軍等借助關鍵詞分析法和自然語言處理算法,探索了亮點的語言學特征及其在論文中的位置分布規律,歸納出亮點具有新穎性、簡明性、易讀性、宣傳性等特點[2]。在亮點的自動抽取上,Wang W等對多種無監督自動抽取文本方法進行評估,研究了亮點的提取特征[4];Cagliero L等通過預測文章句子和亮點的相似度,提出了基于回歸模型的有監督的亮點自動抽取方法[5]。
已有研究成果對亮點的特征和價值做了總結,探索了亮點的自動抽取方法,然而整體數量少,對這一具有獨特價值的文本的探索尚處于初步階段,認識有待深入,其中關于亮點語言特征的研究限于部分語法統計和關鍵詞頻數統計,沒有進行語言寫作風格的深入分析,且尚未有研究探討亮點的內容主題構成。為了豐富亮點相關研究,提升學術界和出版界的認識,引發對于亮點應用和普及的思考,本文參考現有其他類型學術文本的相關研究,從外部特征和內部特征兩個方向對亮點展開探索性研究:結合亮點的宣傳性功能和創新性特點,用語言特征反映外部特征,用主題識別反映內部特征,借助自然語言標注處理工具、主題模型以及科學知識圖譜聚類方法,建立較為系統的研究框架對亮點文本進行實證探索。
1 研究思路與數據
針對亮點內外部特征的研究思路從語言特征和主題識別兩個方面展開,見圖1。具體步驟為:(1)獲取學科領域的研究亮點和摘要數據集,分別導入自然語言標注處理工具MAT,獲取表示語言特征頻率的標準化數據;(2)將亮點和摘要語言特征的頻率標準化數據進行獨立樣本T檢驗,分析亮點的語言特征;(3)依據論文的被引次數,將亮點的語言特征頻率標準化數據劃分為高被引、中被引和低被引3 個層次,通過Kruskal-Wallis檢驗探究論文被引次數與亮點語言特征的關系;(4)對研究亮點數據集進行數據預處理、特征提取、文本向量化,通過構建LDA主題模型進行亮點的整體主題識別;(5)通過人工標注對亮點進行分類,采用VOSviewer 文本主題挖掘工具識別亮點不同類型的主題。
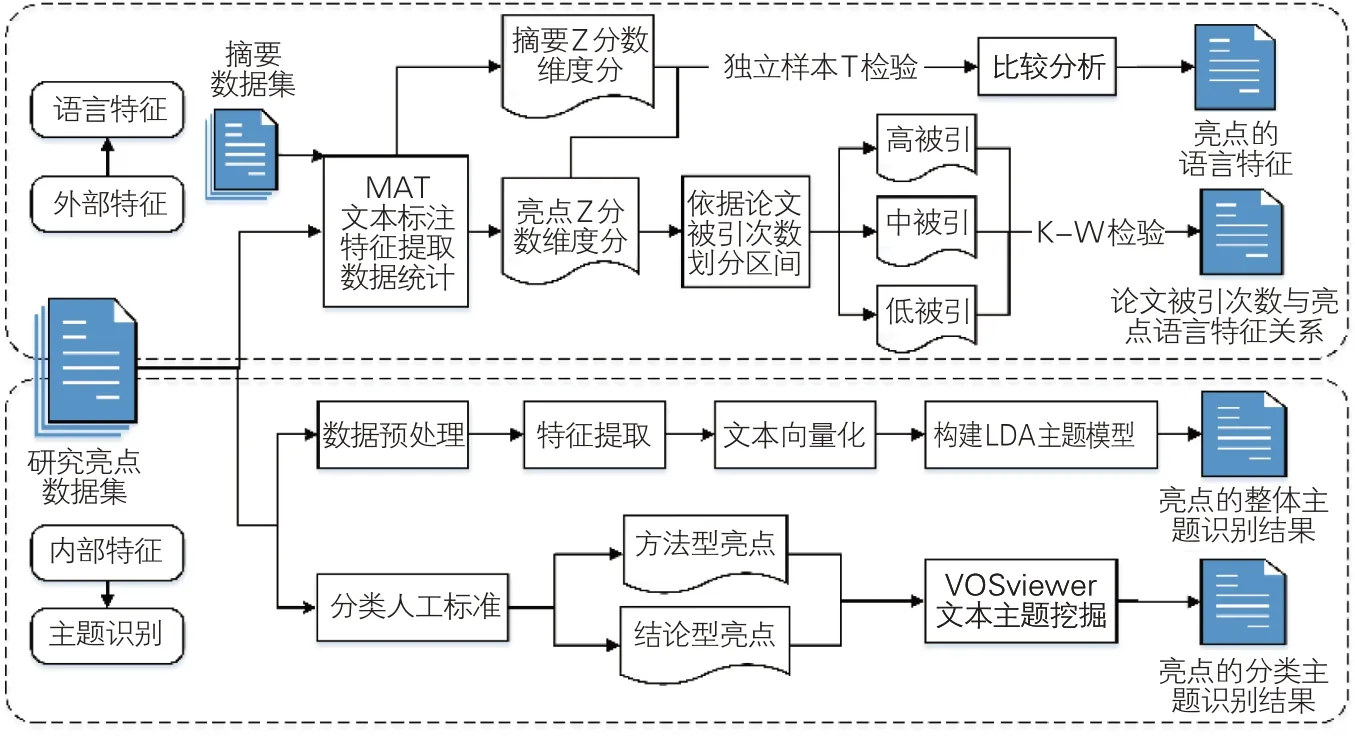
圖1 亮點的語言特征與主題識別研究思路
在研究數據上,本文從愛思唯爾數據庫Science Direct 選擇期刊Journal of Informetrics(JOI)2013-2020 年發表的論文,獲取其每篇論文的亮點、摘要和被引次數等信息,經過整理剔除缺失的數據后,得到亮點文本564篇。JOI創刊于2007年,2021年JCR分區位于Q2,期刊影響因子為4.373,是信息計量學領域權威期刊。國內外許多研究者以JOI 為數據分析信息計量學領域的研究趨勢,如Halevi G 等通過JOI期刊論文的引文語境分析,揭示其跨學科領域的主題演變[6],劉麗敏等以JOI 為樣本分析國際信息計量學研究足跡與知識結構[7]。JOI自2013年起實行ScienceDirect對出版論文亮點提出的要求,即規定亮點由3-5個獨立句子構成,每一句的長度限定為包括空格在內的85 個字符,內容上主要介紹研究中新穎的成果和新方法。一篇論文的亮點如下例所示[8]:
·Exploring knowledge communication and scientific structure by author direct-citation.
·Author direct-citation analysis among prolific,highly cited,and core authors.
· Research subjects on information science around the world be divided into 10 clusters.
·Author direct-citation analysis is different from author co-citation analysis.
通過對亮點語料庫進行統計,564篇亮點文本主要由3-5個語句構成,其中有3篇包含6條語句,羅列要點的語句總數量為2,341條,單詞總數為32,875 個,平均每篇亮點長度為58.29個單詞,每條要點平均長度為14.04 個單詞。表1描述不同語句長度亮點的基本統計概況。
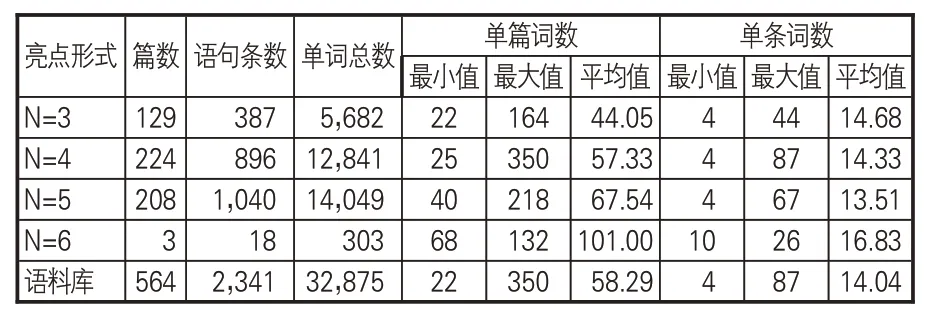
表1 亮點語料庫統計描述
2 亮點的語言特征多維度分析
亮點位于論文摘要之前的重要位置,要求以簡短的篇幅和通俗的語言展示最重要的方法或結論,對學術論文進行宣傳推廣,能引起讀者的閱覽興趣,擴大文章的傳播范圍,提升文章潛在利用的可能性。作者進行亮點編寫時需要關注語言特征,在觀點表達以及讀者互動上使用一定的策略,才能達到更好的宣傳效果。本文使用多維度分析法,結合論文摘要進行比較研究,考察亮點語言特征的使用情況,并探究論文被引次數與亮點語言特征的關系,分析高被引論文的亮點在語言風格上的傾向性,為作者撰寫亮點的語言表述提供參考。
2.1 多維度分析法
多維度分析法(Multidimensional Analysis,MDA)是由Douglas Biber提出的語言特征量化研究方法,其基本思想是文本的語言表達形式反映了文本的交際、認知和語境等功能,而文本的某一功能對應一組具有相關性的詞匯語法特征。Biber利用LLC英語口語語料庫和LOB英語書面語語料庫,選取且確定了67個語言特征,并統計它們在每個語篇中的分布頻率,采用因子分析法將語篇中共現的語言特征歸結為7個因子,代表7個語言功能分析維度,每一維度的語言特征又根據因子載荷的正負值分為功能相反的兩類。不同語域的文本使用的語言特征在各維度上的分布不同,從而體現出文本語言功能的差異。7 個維度具體包括:維度1,交互性/信息性表達(Involved vs.Informational production);維度2,敘述性/非敘述性關切(Narrative vs. Nonnarrative concerns);維度3,明確指稱/情景依賴型指稱(Explicit vs. Situation- dependent Reference);維度4,顯性勸說型表述(Overt Expression of Persuasion);維度5,抽象信息/非抽象信息(Abstract vs.Non-abstract Information)維度6,即席信息組織精細度(Online Information Elaboration);維度7,學術性模糊表達(Academic Hedging),維度7由于數據量的單薄在實際研究中通常被省略。每個維度上分布有數量不同的語言特征,同一維度上可能存在性質相對、功能相反的兩組特征,如維度1中代表文本強交互性的特征(如第一人稱代詞和現在時態)為正特征,代表文本強信息性的特征(如名詞和形容詞)為負特征。多維度分析法廣泛應用于語域差異研究,如高校學生學術英語寫作水平在培訓前后的縱向對比[9],博士論文摘要的歷時對比[10],英語學習者和母語者論文的寫作風格對比[11],以及著作不同翻譯版本的特征對比[12]。該方法從不同功能維度考察亮點的語言特征使用情況,與多元統計分析結合可以針對不同的文本進行量化比較分析。
本文使用多維度標注與分析工具MAT(Multidimensional Analysis Tagger),該軟件整合Biber的8種語域類別、67個語言特征和前6個功能維度,借助斯坦福詞性賦碼器(Stanford Tagger)對詞性和語言功能特征進行標注,實現多維度分析過程中文本標注、特征提取和數據統計等一系列工作的自動化操作,并輸出文本最接近類型、每個語言特征的出現頻率、頻率標準化后的得分(Z-scores,Z分數)、每個維度的維度分(Dimension Scores)。維度分的計算規則是,因子載荷為正值和負值的兩類語言特征Z分數之和相減,如維度1:D1=(ZPRIV+ZTHATD+ZVPRT+……)-(ZNN+ZAWL+ZJJ+……)。將564篇亮點文本分別以txt文件保存并導入MAT進行全部語言特征標簽的標記與分析,獲取每篇亮點文本的維度分和Z分數,以及該篇亮點文本最接近的文本類型,將以上數據導入Excel和SPSS以備分析和檢驗。
2.2 亮點的文本類型和維度特征
根據MAT標注分析結果得到亮點文本564篇,學術論文亮點整體語料庫“最接近文本類型”為學術說明型(Learned Exposition)。學術說明型文本是典型的正式的信息說明文本,注重傳遞信息[13],表現在維度1得分較低,維度3和維度5得分較高。從單篇亮點的標注結果來看,所有文本歸類共呈現4種形式,學術說明型(481篇,85.3%)占據主體,另有少量文本最接近科學說明型(Scientific Exposition)(41篇,7.3%)、一般敘述型(General Narrative Exposition)(29 篇,5.1%)和交互勸說型(Involved Persuasion)(13篇,2.3%)。語料庫整體的維度分以及各類型亮點文本6個維度分平均值如圖2所示。維度1分數越低,表明文本的語言中偏向信息性的特征(負特征)越多,反之則傾向于情感交互性的表達,一般分別對應書面語和口語對話,亮點文本在維度1的負值低分呈現出其較強的信息性。維度2的分值從正到負意味著文本語言特征由敘述性到非敘述性的轉換,亮點的負分值表明文本的非敘述性特征密集出現。維度3的高分表明亮點文本指稱明確且不依賴于時間地點等情境。維度4上,大量文本的負分值顯示其呈現較弱的勸說性。維度5的高分表明信息抽象程度較高,文本詞匯的技術性較強。維度6的負值表示文本以將信息囊括在較少的詞匯和句子中這樣完整的方式來詳述,并不是有限時間內的即興語言組織[14]。總體上,亮點的語言表達呈現信息性、技術性和精確性較強,互動性、敘述性和勸說性較弱的特點。
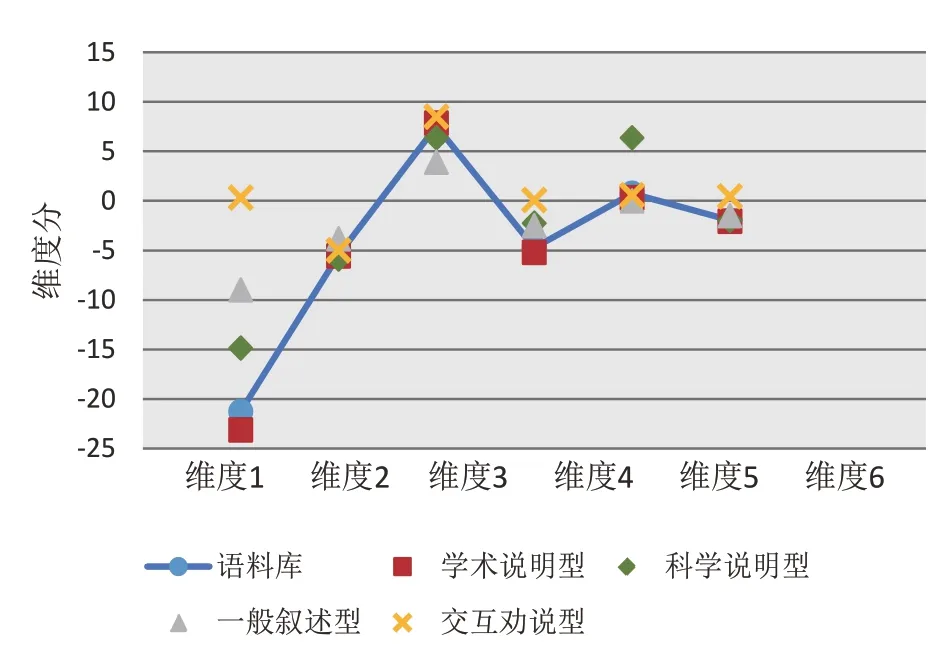
圖2 各類型亮點維度分平均值
2.3 亮點與摘要的語言特征多維度對比分析
亮點與摘要在內容上有說明研究方法和結果結論的相似之處,但前者在語言上更為簡潔凝練,并要求面向一般受眾,不使用專業性強的文字表述。為了對比分析二者在語言風格上的差異,將獲取的摘要數據利用MAT以同樣的方式完成標注分析,借助SPSS對兩類文本的6個維度分和全部語言特征Z 分數進行獨立樣本T 檢驗。檢驗結果顯示,在維度2、維度3、維度5、維度6上,亮點與摘要文本存在顯著差異,而維度1和維度4的差異不顯著,兩類文本均值差異如圖3所示。
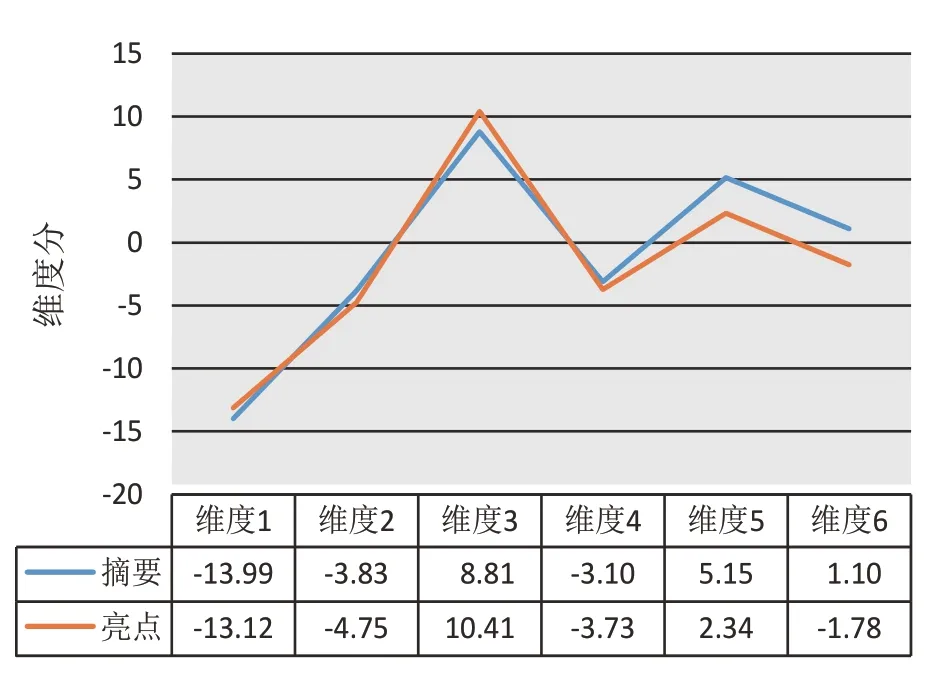
圖3 亮點與摘要維度分均值差異
在語言特征上,由于文本長度和內容撰寫重點的不同,摘要運用的語言特征種類和頻次明顯多于亮點。為了排除幾乎未被使用的語言特征的干擾,確定亮點文本中實際影響各維度的具體語言特征,先對亮點和摘要每個維度分及其對應的語言特征Z分數進行逐步回歸,從而得到每個維度真實使用的語言特征變量,然后在回歸結果的基礎之上進行比較,表2展示了獨立樣本T檢驗結果中,亮點和摘要各維度存在明顯差異的具體語言特征。
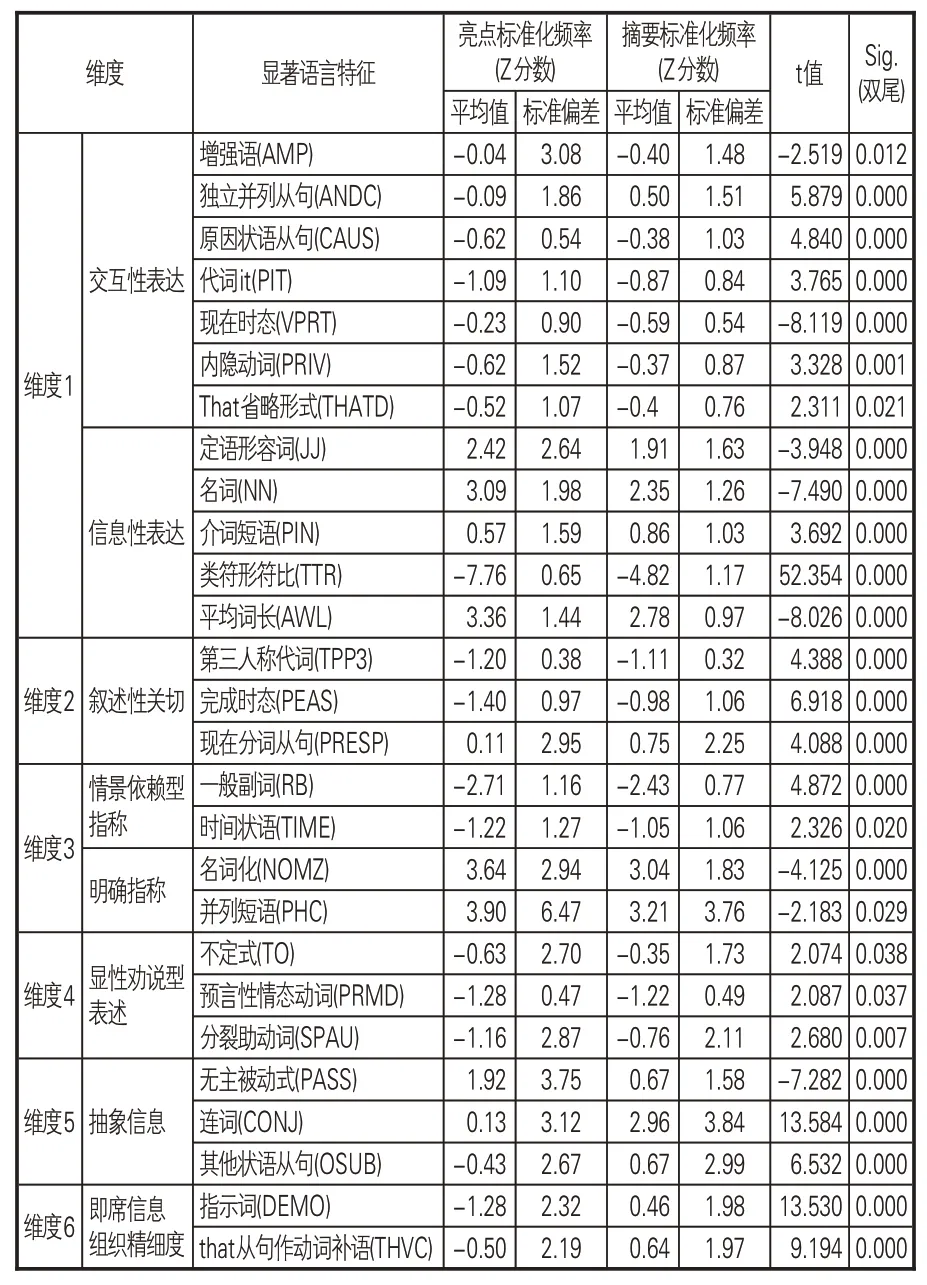
表2 亮點與摘要的各維度語言特征差異
根據回歸分析結果,維度1“交互性/信息性表達”中,進入方程的語言特征變量有可能意義情態動詞(POMD)、定語形容詞(JJ)、名詞(NN)等。在偏向信息性表達的語言特征中,亮點的平均詞長(AWL)、名詞(NN)和定語形容詞(JJ)出現頻率均高于摘要,它們都用于確定具體的信息以增加文本的信息密度。交互性表達中,亮點中出現highly、strongly、very、completely、greatly等增強語(AMP)的相對頻率更高,體現在程度、數量關系、作用強度的表述上,用以強化觀點、表明文章立場,提升對論文的宣傳作用。整體而言維度1 差異不顯著,摘要的維度分平均值更高,因而兩類文本均偏向信息性表達,但摘要與讀者的情感互動性相對更強。
維度2“敘述性關切”中,回歸分析顯示,主要影響因素包括公動詞(PUBV)、現在分詞從句(PRESP)、完成時態(PEAS)等語言特征。存在顯著差異的第三人稱代詞(TPP3)、完成時態、現在分詞從句等3個語言特征在摘要的出現頻率均大于亮點,摘要的維度分均值更高,具有更強的敘述性。例如,文獻[15]的亮點指出研究方法:“An Index of National Orientation (INO) is used,based on the geographical distribution of a journals’publishing and citing authors.”在摘要中的對應論述“It calculates for journals covered in Scopus an Index of National Orientation(INO),and analyses the distribution of INO values across disciplines and countries,and the correlation between INO values and journal impact factors”則展開說明了該方法的應用場景和對象,使用到更多的分句和代詞。同時,亮點論述的研究結論并不涵蓋全部,而是在有限的篇幅內選擇最重要的加以展示,相比摘要會省略“It is found that”“The main findings are”“Our analysis shows that”等引導性用語,顯示更弱的敘述性。
維度3“明確指稱/情景依賴型指稱”所識別的預測變量有并列短語(PHC)、地點狀語(PLACE)、名詞化(NOMZ)、時間狀語(TIME)等7個。呈現顯著差異的語言特征中,亮點的名詞化和并列短語的頻率高于摘要,偏向情景依賴的一般副詞和時間狀語的使用少于摘要;由于其逐條羅列的形式特點,不依賴上下文的程度明顯強于摘要。
維度4“顯性勸說型表述”,經過6次逐步回歸分析,得到不定式(TO)、分裂助動詞(SPAU)、勸說性動詞(SUAV)等6個最佳預測變量。維度4的t檢驗結果差異不顯著,數值上摘要的得分平均值略高于亮點,有顯著差異的不定式、預期情態動詞和分裂助動詞等3 個語言特征均略高于亮點。
維度5“抽象信息”納入的預測變量包含4個:無主被動式(PASS)、過去分詞省略WH 式(WZPAST)、 連詞(CONJ)、 其他狀語從句(OSUB)。亮點得分均值顯著低于摘要,摘要中更多使用連詞和其他狀語從句,增加了信息的抽象程度和技術性,原因是摘要中闡述研究問題和研究背景的語句更多。但在有限的文本篇幅中,亮點不帶施動者的被動語態應用的頻率更高,主因是“is proposed”“is compared”“is analyzed”“is constructed”“is used”“is introduced”等表示研究方法的被動形式的普遍應用。
維度6“即席信息組織精細度”的最佳預測變量有2個:指示詞(DEMO)和that從句作動詞補語(THVC)。同樣地,摘要得分的平均值更高。that等指示詞及其引導從句作補語的情況出現較多,因而信息組織更為精細嚴密,是亮點相較于摘要語言篇幅更短的體現。
綜上所述,亮點與摘要整體維度趨勢具有相似性。在信息密集的同時,亮點相對不注重與讀者的互動,更加強調語言的描述性和說明性,比起摘要顯示出相對更弱的敘事性和勸說性,以及更強的內容獨立性和指向明確性。另外,數據表明,摘要平均詞數(176.9)是亮點平均詞數(58.3)的3倍以上。摘要中研究背景和過程的敘述,增加了讀者獲取文章創新內容的閱讀成本,而亮點用于增強語氣、增強信息密度的語法表達以及被動語態明顯多于摘要,且語言組織不求復雜精細,內容表述不依賴上下文,對作者立場觀點的傳遞更為簡潔、明確有力。
2.4 論文被引次數與亮點語言特征關系分析
為探究論文被引次數與亮點語言特征的關系,借鑒文獻[16]引文預測模型的四分位數分類法,將564篇亮點文本依據論文被引次數劃分為4個區間,分別為Q1:被引次數0~5;Q2:被引次數6~10;Q3:被引次數11~20;Q4:被引次數21 及以上,使得每一區間亮點的篇數相當。由于數據樣本不完全滿足方差齊性,采用Kruskal-Wallis單因素ANOVA分析,對不同引文區間的亮點的維度分以及語言特征Z分數的差異進行檢驗,P<0.05認為有顯著差異。結果顯示,不同引文區間的亮點文本在6個維度上無明顯差異,在具體語言特征上差異達到顯著水平的有:獨立并列從句(ANDC)、勸說性動詞(SUAV)、強調語(EMPH)、基數詞(CD)和數量詞(QUAN)。
獨立并列從句主要指逗號后接and連詞引導的句式,如“Technical details on the construction,visualization,and analysis of citation networks are discussed.”。勸說性動詞主要指propose、suggest、allow、determine、recommend、intend、prefer 等帶有觀點性的動詞。強調語主要指more、most、really、so、do等表示強調副詞的應用,在研究結果中突出比較關系。基數詞指文本中出現的所有數值,包括年份、比例、個數、版本等各種數字表示。數量詞指some、all、many、any、few、several等表示數量的修飾語。
根據表3的成對比較結果,除勸說性動詞在被引次數更高論文的亮點中使用較少(Q4>Q1)外,其余4 種語言特征在Q4 的使用頻率均更高。即,被引次數更高的論文,其亮點通常會更多使用獨立并列從句、強調語、基數詞、數量詞,更少使用的勸說性動詞。這可能是由于獨立并列從句比長句更容易閱讀,強調語、基數詞和數量詞以比較和量化的方式,直觀展示論文的重點信息,更容易被瀏覽發現,吸引閱讀興趣。通過對語料庫標注信息的檢索,勸說性動詞在亮點中的使用以“propose”及其改變形式為主,而新提出的理論、方法、模型、技術可能需要歷經更長時期的檢驗,才得到廣泛利用。
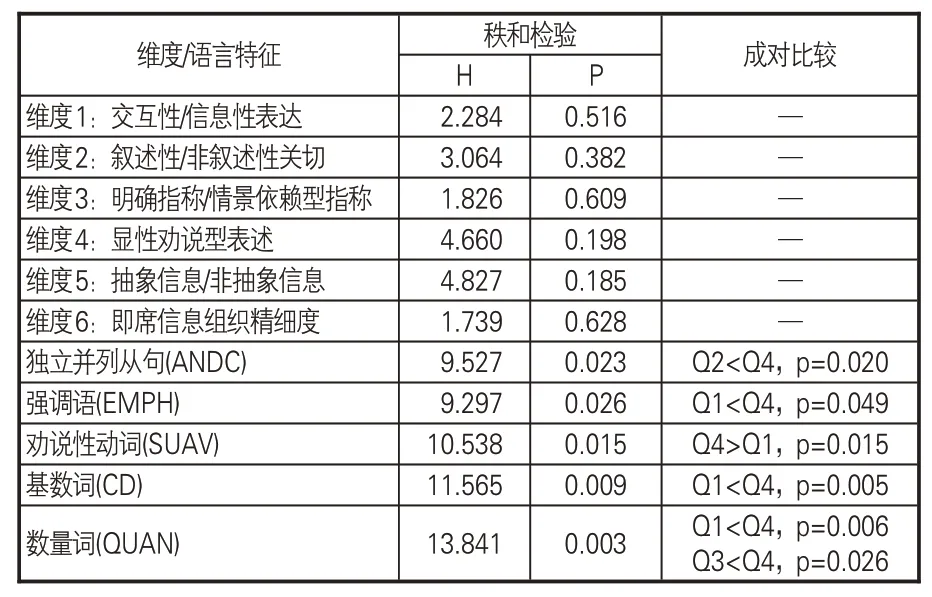
表3 不同引文區間亮點各維度和語言特征對比
3 亮點的內容主題識別分析
在反映科技創新主題和研究熱點上,相比于廣泛應用的文獻摘要等題錄信息,亮點經由作者遴選,精練了論文中最具特色的方法和最重要的發現,其獨立成句的形式排除了大量語義信息,為識別創新的研究方法和結論提供了更為便捷的條件。本文首先采用LDA主題建模方法從整體上識別亮點語篇,其次對亮點語句逐條進行人工分類標注,并根據分類結果使用VOSviewer進行文本挖掘,從而梳理亮點在表達論文創新主題上的內部特征,以及不同類型亮點的分布特征。
3.1 亮點整體主題識別
LDA主題模型的應用能增強學科領域研究熱點的語義信息解釋性[17]。針對亮點文本的總體內容特征,利用Python對數據預處理,清洗不必要的符號并將亮點文本進行分詞和詞形還原,使用nltk 停用詞表對分詞結果進行停用詞過濾處理,調用WordNet內置函數實現詞形還原,并自行設置同義詞和停用詞讀取替換,計算并保存文本詞頻結果。經過統計和分類后,出現頻率較高的名詞和形容詞關鍵詞見表4。
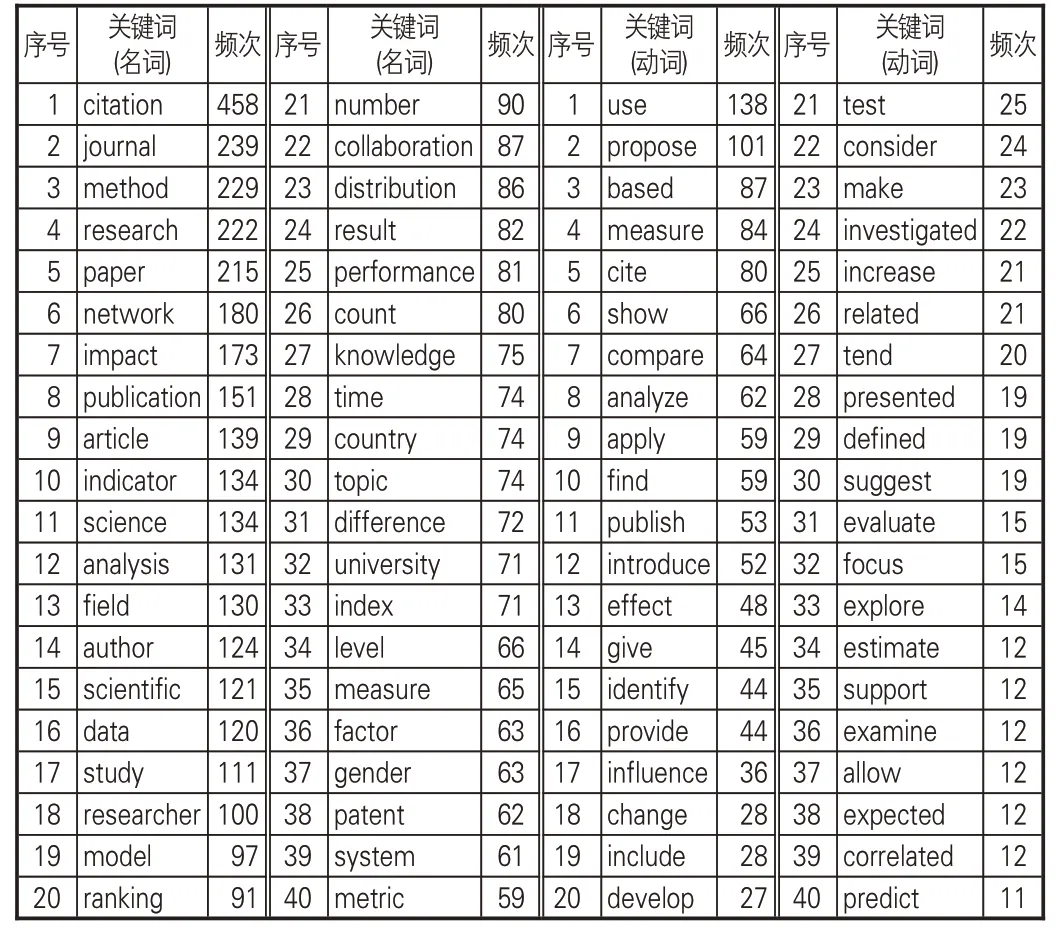
表4 亮點高頻關鍵詞統計
在主題建模階段,通過工具包Gensim 中LdaModel 函數結合TF-IDF 加權處理方法對經過清洗后的亮點文本進行迭代訓練,在困惑度隨主題數目增加而上升的情況下,選用一致性檢驗方法確定最優主題數目,形成主題-特征詞分布。不斷調整各項參數以提升主題結果的可解釋性,最終設置主題數為10,迭代次數為600,每組特征詞個數為100。形成主題特征詞分布后,分別依據主題詞內容進行命名,選取每個主題前20個關鍵詞,如表5所示。引文分析主題趨向引文預測模型、網絡數據庫的比較評估、引文與其他因素的影響作用關系等研究。科研主題類涉及學術研究和社交網絡中的熱點主題挖掘以及學科領域的主題演化。期刊與出版物主題關注出版物的分類、影響力、書目特征和開放獲取。影響因子主題主要研究JIF為主的期刊影響力指數,涉及計算方式的優化比較以及標準化方法的應用,如文獻[18]指出對于JIF計算,幾何平均值比算術平均值給出更穩定的結果。績效評價主題關注學者、高校等科研機構績效的影響因素和評價方法。專利計量主題主要探討專利引用的方法和科學技術的聯系、發展與融合,如文獻[19]利用文本相似性論證專利引用可以表示知識鏈接。合作主題涉及研究人員、科研機構、國家層面跨領域合作的動態網絡、合作模式、作用效果以及性別差異等。科技指標主要研究h 指數、g指數基礎上新指標的構建和應用,同時關注基于社交網絡的替代計量指標。方法和技術主題指面向解決領域問題所提出的方法模型和軟件工具,如引文網絡分析與可視化工具CitNetExplorer[20]和科學地圖分析工具bibliometrix[21]。網絡分析主題主要包括社會網絡、復雜網絡等分析方法在信息計量學中的應用。對比目前已有利用題錄數據分析信息計量學知識結構的研究,田沛霖等通過分析Journal of Informetrics的文獻題錄數據,總結評價指標的理論與實踐、網絡指標對績效的影響、高校科研績效評價、期刊影響力與跨學科性測度、基于網絡數據庫的引文分析、研究的社會影響測度6個主題社區[22],其歸納的知識來源與上述部分識別結果基本對應,另有科研主題、專利計量、合作、方法和技術等主題與該研究總結的高頻關鍵詞大致契合,表明亮點在內容特征上具有表達論文核心主題的功能,可用于揭示特定學科領域的研究結構。
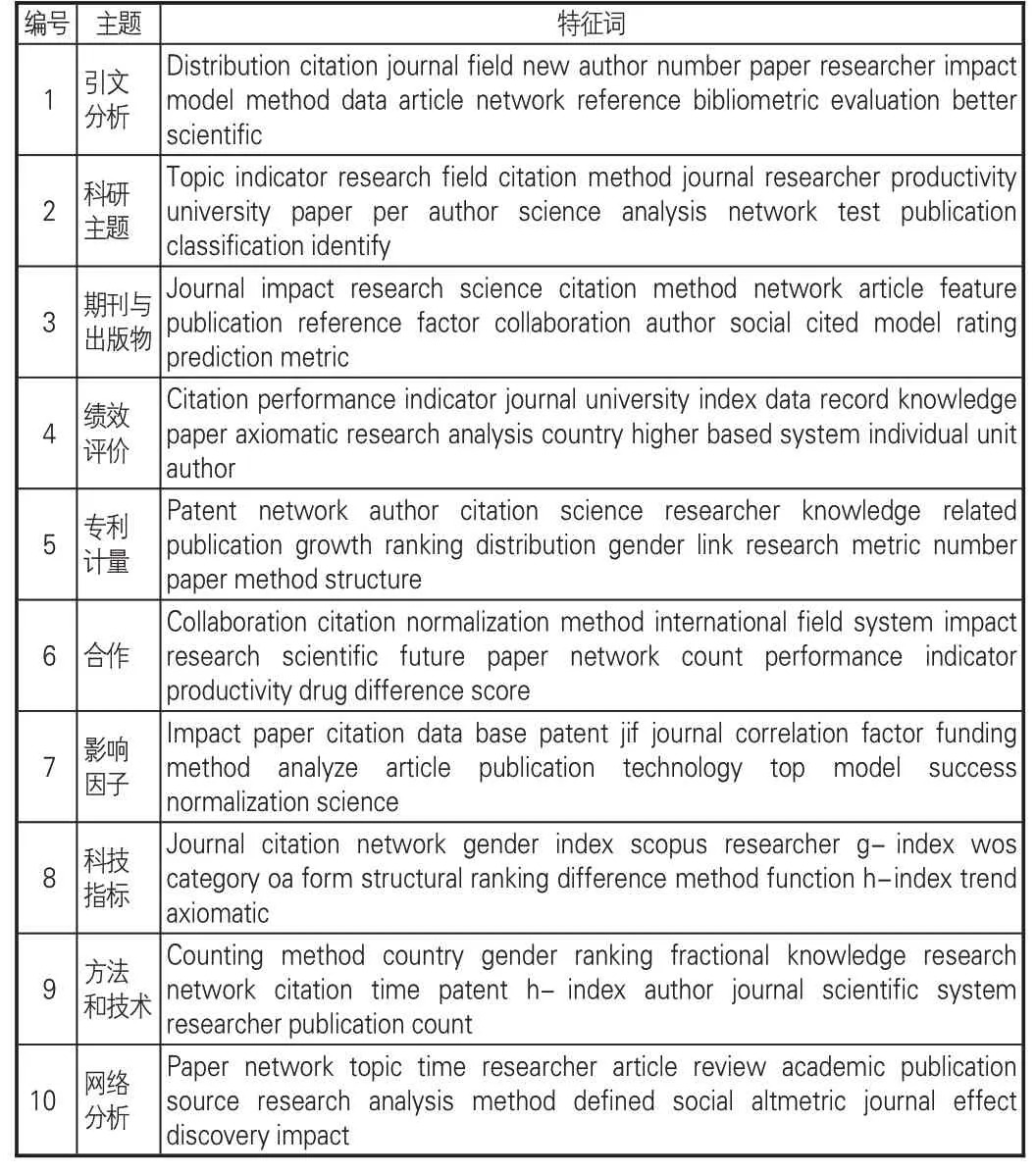
表5 亮點主題-特征詞分布
3.2 亮點分類主題識別
3.2.1 亮點類型分布特征
ScienceDirect作者指南要求,亮點應突出創新的研究成果或研究方法。結合對亮點文本內容的判讀,本文將亮點劃分為方法型亮點、結論型亮點和其他型亮點。方法型亮點描述了研究采用的具體研究方法、數據來源、研究設計流程,介紹提出的新方法、新方法的功能效果、新技術工具等,對應“提出、測量、分析、使用、比較”等動詞關鍵詞。結論型亮點總結了研究結果或結論,以及結果相關討論,對應了發現、確定、展現、揭示、建議等動詞關鍵詞。除此之外,部分亮點還會涉及研究目的和意義、研究背景和問題,歸屬于其他型亮點。人工分類標注由兩位成員共同進行,首先通過閱讀梳理就分類標準達成一致,然后相互獨立初步標注50篇作為試驗樣本,對存在分歧之處通過討論進一步調整和完善類型的定義,確定更加明確的區分細并完成全部文本的標注。最終分類結果Kappa 系數達到了0.8以上,具有較高的信度。
在單條語句層面,數據集共有2,341 條亮點,涵蓋方法型亮點1,053條,分布于428篇文獻;結論型亮點1,133條,分布于433篇文獻;其他型亮點155條,分布于132篇文獻,見表6。在語篇層面,亮點語篇包含6種結構:(1)全部為方法型,共96 篇;(2)全部為結論型,共106 篇;(3)方法型和結論型,共230篇;(4)方法型和其他型,共34 篇;(5)結論型和其他型,共29 篇;(6)方法型、結論型和其他型,共29 篇。另有1 篇只提出研究問題,為其他型亮點。圖4 展示了亮點語篇結構,藍色、紅色、黃色依次代表方法型、結論型和其他型的3 類亮點成分,交叉重疊后形成6 個系列色塊,分別代表了上述6 種結構。由統計結果發現,方法型亮點和結論型亮點總體數量接近,結構(1)和結構(2)的占比相當,約有一半的亮點語篇同時論述了方法和結論,通篇僅闡述方法或僅說明結論的分別約占四分之一,顯示了研究方法和研究結論在亮點中具有同等重要性。
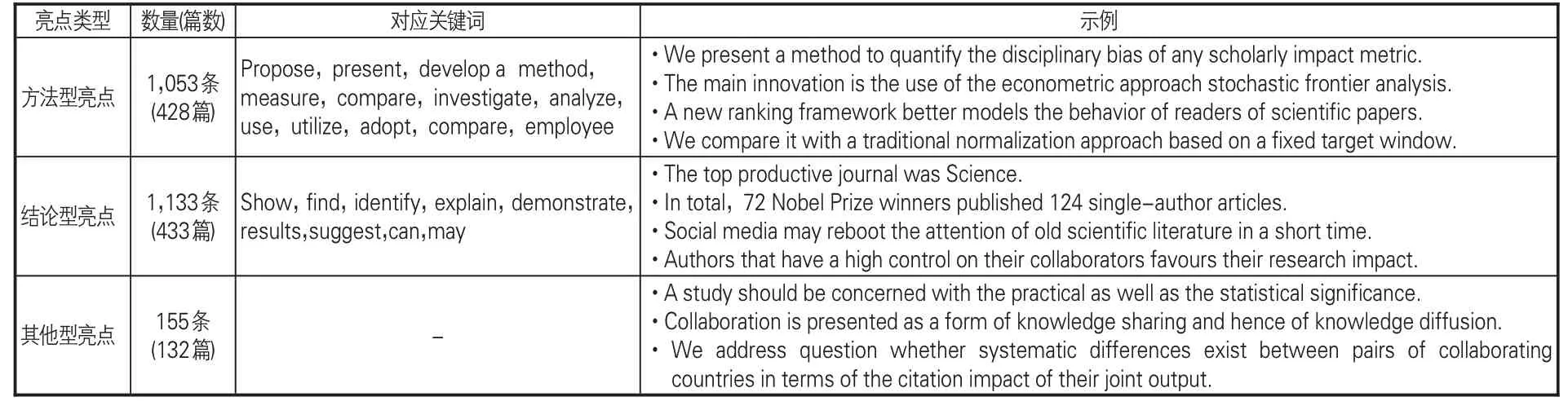
表6 亮點語句類型分布
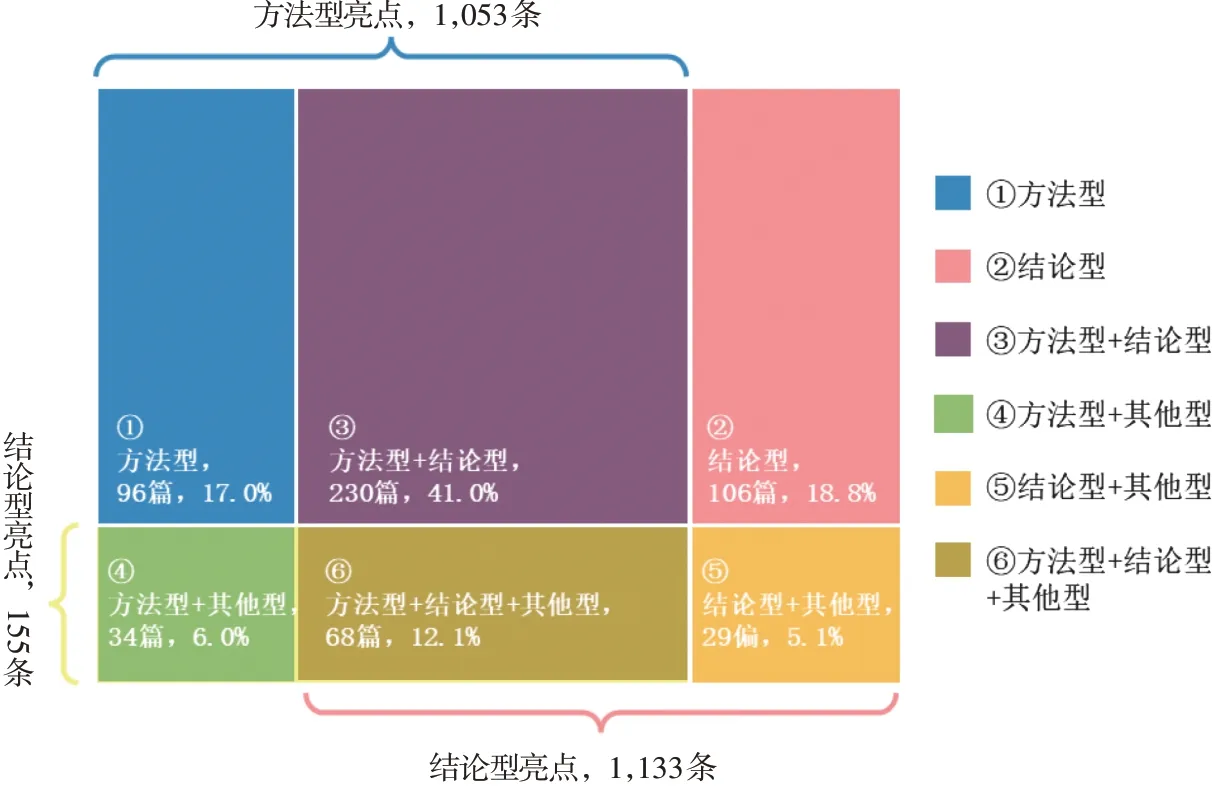
圖4 亮點語篇結構
3.2.2 分類主題挖掘
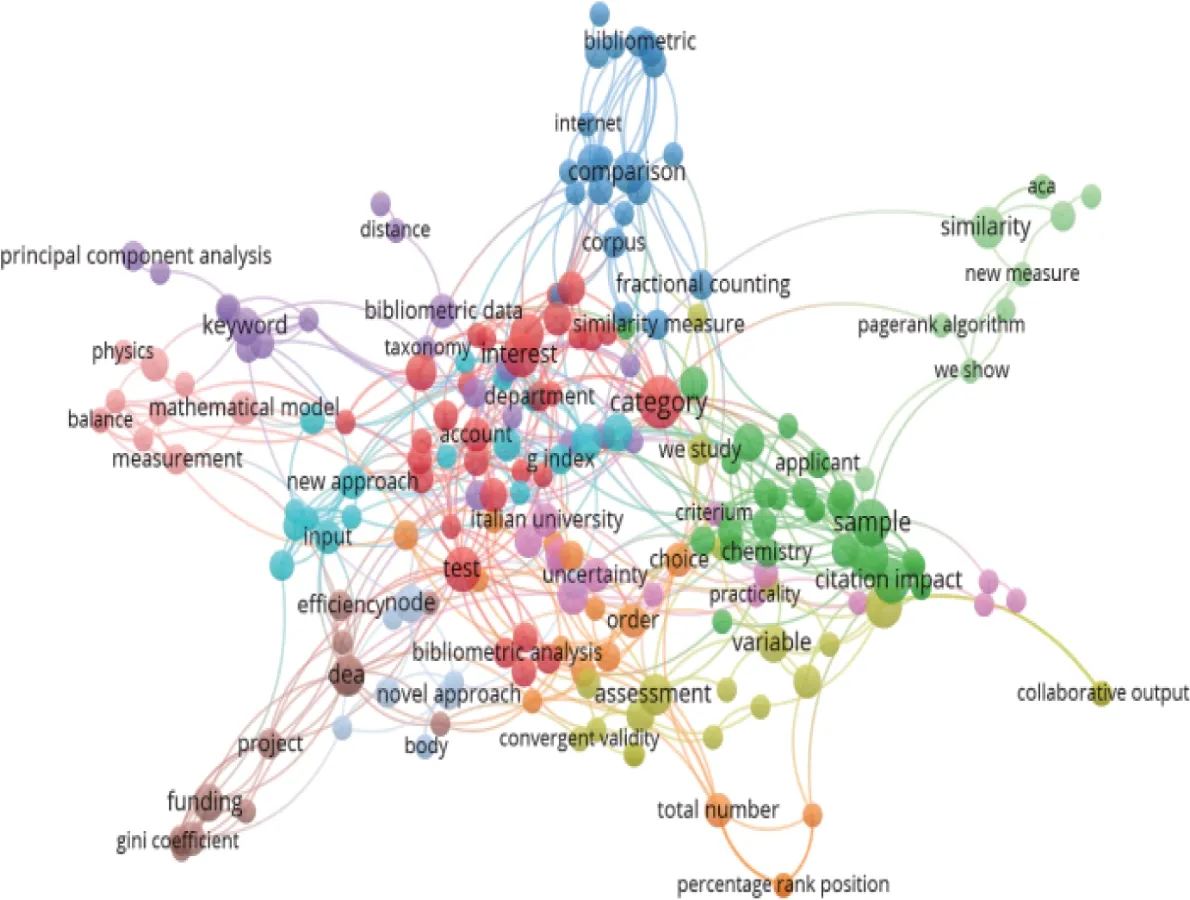
圖5 方法型亮點主題共現
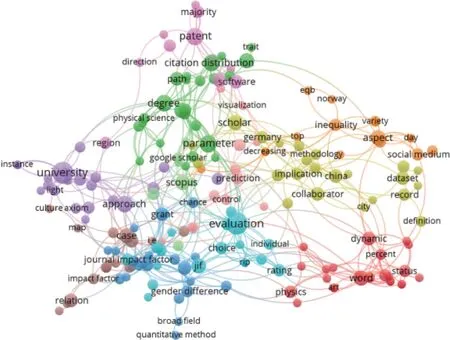
圖6 結論型亮點主題共現
在分類標注的基礎上,利用VOSviewer文本主題挖掘功能,將摘要字段替換為亮點文本,設置同義詞替換和不同詞性詞合并,如h-index 與hirsch index、h index,normalize 和normalization,對方法型亮點和結論創新型亮點分別進行主題可視化分析,見圖5-6。方法型亮點描述具體方法創新和特色,包括其他領域方法的引入或已有方法的創新,也包括新方法的提出或原有方法基礎上的有效改進。JOI鼓勵投稿使用其他定量領域的方法研究信息問題[23],如數學、統計學、計算機科學、經濟學和計量經濟學以及網絡科學。由于樣本限制以及新穎方法的獨特性,聚類結果較為分散,參考輸出的分詞結果列表將方法進行歸類,主要有6 種。(1)信息計量指標。傳統引文分析指標中影響因子、h指數、g指數指標依舊出現頻率較高,Almetric指標及Mendeley、Twitter等社交媒體新型評價工具也受到學術界關注,還有如百分位數排序位置指標(percentage rank position,PRP)、引文時間窗(citation time window)和作者共引統計等指標。(2)科研績效評價方法。數據包絡分析方法(data envelopment analysis,DEA)在期刊、機構、國家和地區績效評價中廣泛應用創新。此外,統計標準化方法探索較多,如分數計數法(fractional counting)、被引端標準化(cited-side normalization)和施引端標準化(citingside normalization),以及具體的來源標準化方法(source normalization approach)和平均標準化讀者得分(mean normalized reader score,MNRS)。(3)數據統計方法,包括主成分分析法(principal component analysis)、回歸模型(regression model)、TF-IDF 算法、相似度計算(similarity)、 聚類(cluster)、時間序列分析(time series)、可視化方法(visualization)、魯棒性測試(robustness)。(4)網絡分析方法,如引文網絡、社會網絡、共詞網絡、作者共現網絡、合作網絡、異構網絡、二部網絡、度分布(degree distribution)。(5)數據挖掘方法,如機器學習(machine learning)、主題模型(topic model)、PageRank 算法、優先連接算法(preferential attachment)。(6)跨學科方法,如以數學為基礎的公理化方法(axiom)、經濟學的基尼系數(Gini coefficient)以及合作博弈與收益分配的沙普利值方法(shapley value)。除具體方法之外,部分文獻主要提出新理論和概念框架,通常伴隨案例研究的實證,WoS、Google Scholar、Scopus、國家自然科學基金委員會等平臺機構,以及意大利等國家地區大量出現于數據源中,醫藥學、物理學、3D打印領域是主要的熱點分析領域。
結論型亮點通常展示基于研究對象的數據結果、被確定的關系以及得到的效果或性能。從聚類結果來看,相較于方法型亮點,結論型亮點更難從語詞層面識別出解釋性較強的信息,更多涉及模式、參數、程度、表現、相關關系、強度、領域、結構、重要性等表示領域重要內容的詞匯。與亮點整體主題識別結果相似,引文、期刊影響因子、論文、專利、作者、國家、合作、出版物、績效評價、網絡分析等主題依舊是信息計量的重點研究方向。其次,更多主題和研究對象受到關注,如性別差異、開放獲取、生產力、信息政策、同行評議、主題挖掘,以及各個國家地區、學科領域、社交媒體平臺和學術平臺。另外,有一定數量的文獻針對不同的數據庫、計數方法或評價指標進行比較研究,在結論型亮點中直接指出各自的差異與優勢。例如,有研究認為,在專家判斷一致的情況下,期刊質量評價指數中,篇均來源期刊標準影響(source normalized impact per paper,SNIP)比粗計量篇均影響(row impact per paper,RIP)或期刊影響因子有著更好的效能[24]。
4 結語
學術論文亮點的提出旨在用簡明扼要的文字,介紹論文的研究要點,在搜索引擎中增強與用戶信息檢索的匹配程度,幫助讀者迅速篩選文獻,吸引不同學科領域研究者的關注和理解,起到宣傳推廣論文的效果,以提升其利用率,促進科研創新和知識流動。然而,這一學術體裁鮮少得到關注,本文對其外部特征和內部特征進行了探索性研究。
在外部特征上,亮點的語言呈現較強的信息性和非敘述性,指稱明確不依賴語境,情感交互性和顯性勸說性較弱,信息表達傾向于抽象和技術性,即席信息組織較為精細。與摘要文本對比,亮點文本的主要功能在于展示最重要的研究方法和研究結論,既不包含摘要中的研究問題和研究過程,也不囊括摘要中的具體方法和全部結論。獨立語句的形式使其指示詞和各類型從句的應用頻率較低,但詞匯密度較高,因而能更直觀地表達核心結論。被引次數較高的論文,其亮點更傾向于使用較多的基數詞、數量詞、強調語和獨立并列從句。在論文亮點撰寫的過程中,建議作者可以更多展示具體數據和數量關系,用數字和程度副詞說明研究所用的材料、得到的效能、確定的關系、對比的結果等,避免過于追求精煉而缺失實質信息;必要時可以使用并列從句,避免長難句帶來的閱讀阻力,從而展現論文的核心價值和競爭力,提升編輯審稿和讀者閱讀的效率。
在內部特征上,通過亮點主題識別結果與現有題錄信息相關研究的對比,發現亮點具有表達論文核心主題的功能,可以用于揭示特定學科領域的研究重點。亮點依據內容可分為方法型亮點、結論型亮點和其他型亮點。單篇亮點基于文章屬性對研究方法和研究結論的側重有所不同,但整體結構分布上數量相當;方法型亮點的文本比結論型更具可解釋性,能夠反映相關領域的前沿方法。亮點中對未來應用進行展望,可以作為創新點事實單元[25],相比文摘更易于分解為問題、方法、結果的實體和語義關系,便于機器處理和閱讀,可應用到學術資源檢索系統中助力知識問答功能的智能化。
本研究的不足體現在:(1)采用的數據僅限于JOI期刊的564篇亮點文本,樣本數量存在局限性,在語言特征與被引數量關系以及內容挖掘可解釋性上需要謹慎考慮;(2)亮點人工標注分類標準上,沒有將理論創新單獨考慮,不同類型的亮點統計結果精確程度有待提升;(3)研究領域相對單一,而不同學科領域的論文亮點在方法和結論上的創新側重點不同,語言風格傾向也不同,需要進行更多的實證對比。后續將針對以上問題,完善對學術論文亮點的認知和實踐探索,為亮點在知識交流和科研創新中的應用提供參考。
猜你喜歡
文苑(2020年4期)2020-05-30 12:35:30
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
小學教學參考(2015年20期)2016-01-15 08:44:38
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
