基于改進YOLO v7的籠養雞/蛋自動識別與計數方法
2023-07-31 08:07:04趙春江梁雪文于合龍王海峰樊世杰
農業機械學報 2023年7期
趙春江 梁雪文 于合龍 王海峰 樊世杰 李 斌
(1.吉林農業大學信息技術學院, 長春 130118; 2.北京市農林科學院智能裝備技術研究中心, 北京 100097;3.北京市華都峪口禽業有限責任公司, 北京 101206)
0 引言
作為重要的家禽種類之一,蛋雞為人們提供了豐富的動物蛋白營養食源[1]。近年來,隨著消費需求日益增加,規模化養殖趨勢加速,立體籠養成為主要飼養模式[2-4]。死亡/低產蛋雞的高效巡檢與動態清零成為當前蛋雞養殖產業的重要需求。一般來講,籠內蛋雞存活和產能狀況通過籠內雞/蛋數量精確盤點實現,而立體籠養模式下,養殖密度大、雞只間遮擋和光線分布不均等因素使雞只和雞蛋準確識別與計數工作難度增加。
當前,人工觀測方法清點雞只與雞蛋數目效率低下且易使蛋雞產生應激反應[5]。傳統機器視覺方法主要應用特征信息提取和閾值分割技術開展雞/蛋目標檢測。畢敏娜等[6]采用SVM算法檢測散養病雞,應用數碼相機采集RGB圖像,將雞頭雞冠紋理特征和雞眼瞳孔幾何特征作為病雞與健康雞分類的特征向量,結果表明病雞識別正確率為92.5%。INDRA等[7]基于大津閾值法設計雞蛋檢測模型,以獲取受精卵和不育卵的信息。MUVVA等[8]提出一種基于熱度圖和可見光圖像的死雞檢測方法,使用閾值分割技術提取熱度圖中活雞像素和可見光圖像中所有肉雞(活雞和死雞)的像素,根據兩幅圖像像素差值,輸出死雞坐標信息,該方法在常規飼養密度和稀疏飼養密度下肉雞(≤5周齡)的死雞識別正確率分別為90.7%與95.0%。LI等[9]開發了基于圖像分析和體質量計數的母雞傳感器計數系統,圖像分析計數是將原始彩色圖像轉換為灰度圖,然后根據最終生成的二值圖像中白色像素數確定母雞數量,計數準確率為71.23%;體質量計數是指首先求得母雞平均體質量,再根據傳感器獲得的籠內母雞體質量計算母雞數量,準確率達到99.70%,但是這種方法每次僅能檢測8只母雞,效率低。上述基于各自研究場景下的檢測研究雖然準確率較高,但無法解決籠養雞舍內光線不均、雞與籠之間遮擋及雞蛋粘連等復雜場景下的雞只與雞蛋自動化識別與計數問題。
近年來,深度學習技術發展迅速,目標檢測網絡已在畜禽個體識別研究領域表現出優越性能[10-12]。GEFFEN等[13]利用Faster R-CNN網絡實現籠養模式下母雞的檢測和計數工作,準確率為89.6%,平均絕對誤差為每籠2.5只母雞。LI等[14]應用改進后網絡QueryPNet檢測和分割大鵝,大鵝檢測與分割的準確率均為96.3%。JIANG等[15]通過改進的YOLO v7網絡實現實時監控麻鴨數量,平均精度均值(Mean average precision,mAP)為97.57%。上述模型檢測性能良好,但模型參數量較大,難以部署到GPU資源匱乏的邊緣計算設備進行實時檢測。面對輕簡化設備的應用需求,模型小、檢測速度快的輕量級目標檢測網絡優勢較為突出[16-18]。其中應用較為廣泛的輕量級網絡有SSD與YOLO微型系列網絡。劉慧等[19]應用改進的SSD網絡實時檢測田間行人,當交并比閾值為0.4時,模型mAP與檢測速度分別為97.46%和62.5 f/s。易詩等[20]提出一種基于YOLO v3-tiny的適宜于嵌入式系統部署的野雞識別方法,模型mAP和檢測速度分別為86.5%與62 f/s。ZHENG等[21]使用改進的YOLO v5模型快速檢測麻鴨,并對比了基于不同標注范圍(鴨頭和鴨身)的模型檢測性能,結果表明,基于鴨頭標注的模型檢測性能更好,準確率與檢測速度分別為99.29%和269.68 f/s。綜上,輕量化網絡的高實時性、少參數量和易部署等特點為實際場景下的應用研發提供了可能。
基于此,針對立體籠養模式下巡檢過程中存在的光線不均、雞只易被遮擋和雞蛋粘連等問題,本研究提出基于YOLO v7-tiny-DO網絡的籠養雞/蛋自動化識別與分籠計數方法(Counting in different cages,CDC)。首先,在高效聚合層網絡內構建深度過參數化深度卷積層提取目標深層特征,在特征融合模塊引入坐標注意力機制提高模型捕獲雞只和雞蛋空間位置信息的能力;然后,設計和發展自動化分籠計數方法;最后,將其部署到邊緣計算設備進行實地測試驗證,以期為規模化蛋雞養殖智能化管理提供思路。
1 材料與方法
1.1 試驗平臺搭建
為實現自動化數據采集和減少人工參與以保證數據的客觀性,設計并搭建了雞只視頻數據采集平臺,示意圖如圖1所示。該平臺由視頻采集單元、邊緣計算單元、數據展示單元與電力供應單元組成。其中視頻采集單元選用低成本JRWT1412型無畸變攝像頭,內置RGB傳感器(分辨率為640像素×480像素,幀率為30 f/s);邊緣計算單元采用NVIDIA Jetson AGX Xavier開發者套件,內置512個NVIDIA CUDA Cores、64個Tensor Cores、8塊Carmel ARM CPU、2個DL Accelerator和1個Vision Accelerator深度學習加速器引擎,以支持視頻數據采集、模型部署與算法推理等功能的實現;數據展示單元采用11.6寸IPS高清觸摸屏,用以展示攝像頭捕獲的視頻圖像;電力供應單元采用便攜式移動電源支撐巡檢機器人運轉,輸出電壓為48 V。
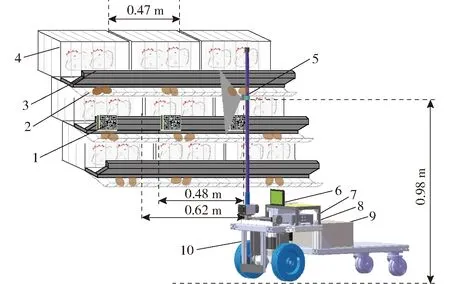
圖1 視頻數據采集平臺
1.2 數據獲取與預處理
本研究所有數據均采集于北京市華都峪口禽業有限責任公司第3場階梯式雞舍。采集對象為中層30籠雞,品種為京粉1號蛋雞。采集時間為2021年10月9—13日與2022年3月28日—4月14日06:00—18:00,期間每隔2 h采集1批次視頻,單個視頻時長約2.5 min,從中選取雞頭未被食槽完全遮擋的視頻進行試驗。
數據采集流程如下:首先,在食槽特定位置張貼二維碼作為雞籠編號;其次,在相機鏡頭距雞籠水平距離0.62 m處運行巡檢機器人,以速度 0.1 m/s沿直線前進,行走過程中鏡頭距二維碼與雞籠的水平距離基本保持不變(誤差小于0.005 m);最后,獲取的雞只視頻數據(分辨率為640像素×480像素)通過USB接口傳輸至邊緣計算單元,在數據展示單元顯示并保存到本地磁盤。共拍攝視頻378 min,格式為MP4,幀率為30 f/s。采用OpenCV圖像處理庫每隔10幀截取一幅圖像,從中篩選出2 146幅圖像(分辨率為640像素×480像素)作為數據源,格式為JPG。由于籠養雞舍內采用暖光燈照明,且雞只靈活性較高,因此本文采集圖像大多具有以下1種或多種特點:①雞只被鐵絲或食槽遮擋(圖2a紅色框)。②雞只快速移動產生運動模糊(圖2b藍色框)。③多枚雞蛋粘連在一起(圖2c黃色框)。④兩個暖光燈中間位置光線昏暗(圖2d綠色框)。

圖2 不同場景下圖像示例
由于籠養模式下養殖密度大,雞籠邊界不易區分,本研究通過檢測雞頭識別雞只個體,檢測二維碼區分不同雞籠。在人工可識別情況下,采用LabelImg標注雞只頭部(head)、雞蛋(egg)與二維碼(qrcode),并生成包含目標類別、坐標及圖像像素信息的.xml文件,最終得到2 146幅圖像和對應標注文件用于訓練與測試網絡模型性能。為增強模型泛化性和魯棒性,在訓練過程中應用在線數據增強,主要方法包括色調變換、仿射變換、Mosaic增強與Mixup增強,如圖3所示。數據集按照比例7∶2∶1隨機劃分為訓練集、驗證集和測試集,對應圖像分別為1 501、430、215幅。

圖3 在線數據增強
1.3 籠養雞/蛋識別模型
1.3.1YOLO v7-tiny網絡模型結構
YOLO v7-tiny[22]是YOLO系列的輕量化模型之一,該網絡在公開數據集Microsoft COCO Dataset上取得較高的精度與較快的速度。YOLO v7-tiny整個網絡結構可分為Input、Backbone與Head共3部分,網絡結構如圖4所示。Input主要對輸入數據進行預處理,對于輸入的任意尺寸圖像被自適應放縮為模型適用分辨率(640像素×480像素),采用動態標簽分配策略確定正負樣本,并對數據進行Mosaic與Mixup增強。
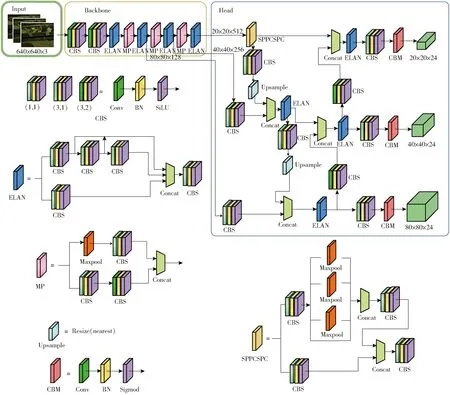
圖4 YOLO v7-tiny網絡結構
Backbone由卷積模塊、高效層聚合網絡(Efficient layer aggregation network,ELAN)與MP模塊構成。卷積模塊包含卷積層、數據歸一化層與激活函數3部分,激活函數采用Sigmoid加權線性單元(Sigmoid-weighted linear unit,SiLU)[23],其具有無上界、有下界、平滑與非單調等特點。ELAN通過控制最短與最長的梯度路徑,使網絡在不破壞原有梯度路徑的情況下不斷增強網絡的特征學習能力,提高模型的魯棒性。MP模塊采用兩個不同分支分別進行下采樣操作,二者采用殘差連接,以增強模型的特征提取能力。
Head主要包含SPPCSPC、ELAN與Detect 3個模塊。SPPCSPC由金字塔池化結構(Spatial pyramid pooling,SPP)[24]與跨階段區域網絡(Cross stage partial,CSP)[25]組成,CSP將特征拆分為兩部分,特征1經過SPP池化操作后與特征2融合,獲取4個不同尺寸(1、5、9、13)的感受野,以便Detect層檢測不同大小的目標。Detect層輸出目標邊界框坐標、置信度和類別信息。
原始YOLO v7-tiny對粘連的雞蛋和光線較暗處目標檢測性能較差,為提高模型整體檢測精度,滿足籠養雞舍復雜環境的應用需求,本研究在YOLO v7-tiny網絡的基礎上,首先將SiLU激活函數替換為指數線性單元(Exponential linear unit,ELU),減少模型訓練時間和提高目標檢測網絡的整體性能。其次在ELAN結構中采用深度過參數化深度卷積層(Depthwise over-parameterized depthwise convolutional layer,DO-DConv)[26]提取目標深層特征,以提升光線較暗條件下目標的識別能力。最后在Head的第2、4層引入坐標注意力機制(Coordate attention mechanism,CoordAtt)[27],提取特征圖像中目標空間位置信息。
1.3.2激活函數
深度學習中激活函數是將神經網絡非線性化,激發隱藏結點,此類函數通常具有連續且可微等特點。SiLU激活函數雖然滿足以上要求,但僅在深度神經網絡的隱藏層中可用[28]。因此,本研究引入ELU激活函數。圖5為ELU與SiLU激活函數對比曲線圖,可以看出,ELU函數在定義域內均連續且可微,滿足激活函數的基本要求。當輸入特征向量x大于0時,輸出為x本身,減輕了梯度彌散問題(導數為1);當x小于0時,采用指數函數連接,避免陷入局部最優。ELU函數輸出均值為0,與SiLU函數相比,降低了模型計算復雜度,且單側飽和,使模型收斂效果更好。

圖5 激活函數ELU與SiLU的對比圖
1.3.3改進的高效層聚合網絡
目標檢測模型中特征提取是后續特征融合的基礎數據來源。YOLO v7-tiny網絡中ELAN采用常規卷積提取目標特征,但實際雞舍環境較為復雜,常規卷積操作難以挖掘目標深層次特征。因此,本研究將ELAN模塊內的常規卷積層替換為深度卷積層(Depthwise convolutional layer,DConv)以減少模型參數量,并在其基礎上添加過參數化組件(深度卷積)構建深度過參數化深度卷積層,改進后的ELAN結構如圖6所示。與常規卷積不同,DO-DConv模塊不僅能夠通過增加網絡深度提高網絡的表達能力,而且采用多層復合線性操作,使其在推理階段折疊為單層形式,從而減少計算量。
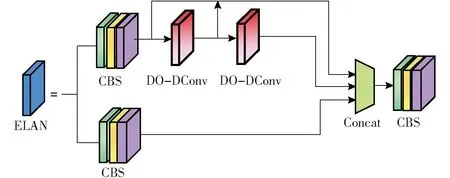
圖6 改進后的ELAN結構
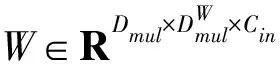
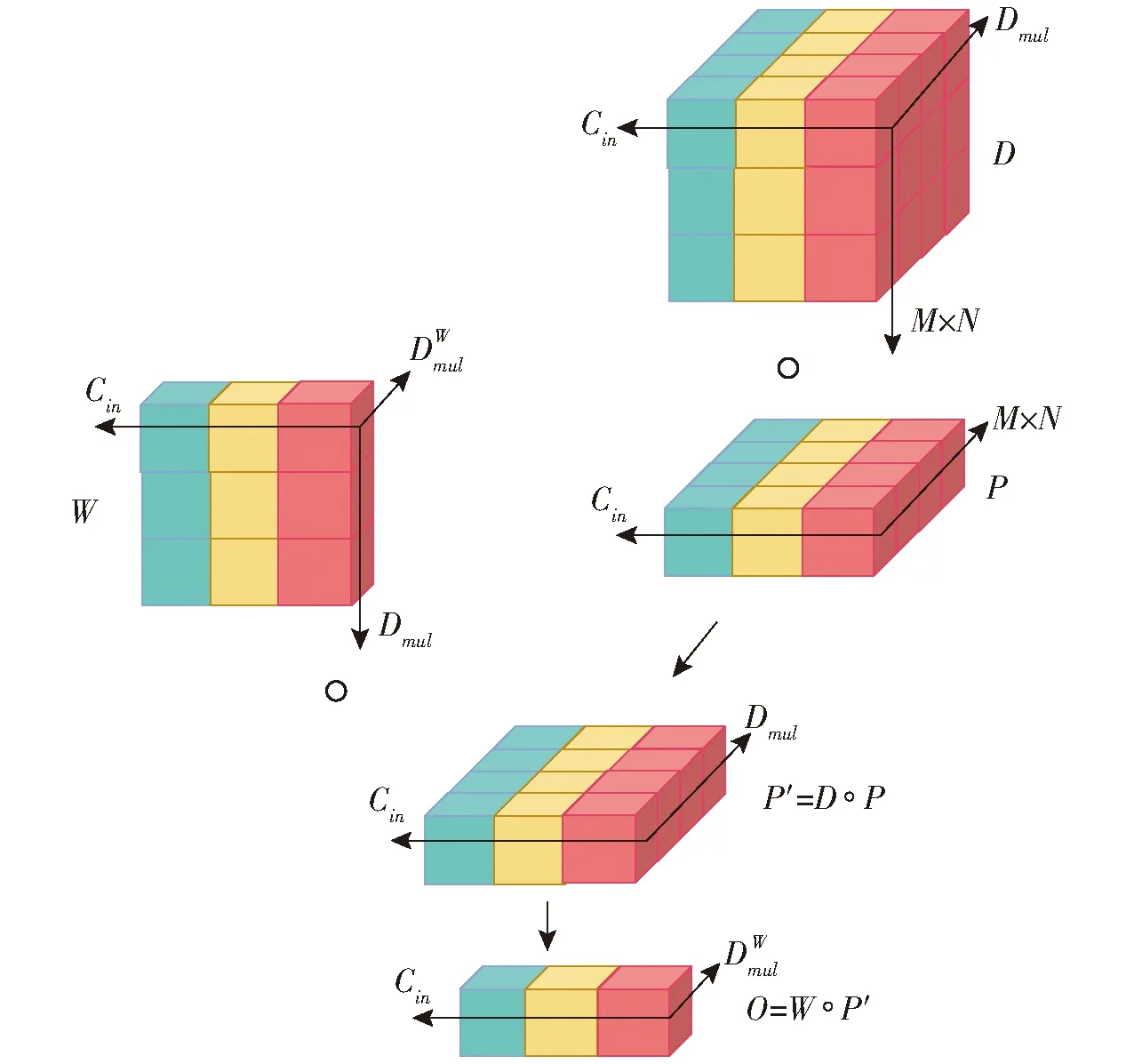
圖7 深度過參數化深度卷積層結構
1.3.4坐標注意力機制
為了進一步提升模型對雞只和雞蛋空間位置信息的捕獲能力,本研究在網絡Head端引入坐標注意力機制。CoordAtt通過精確的位置信息對通道關系和長期依賴性進行編碼,形成一個對方向和位置敏感的特征圖用于增強目標的特征表示。圖8為CoordAtt編碼過程,總體可分為坐標信息嵌入與坐標注意力生成兩部分。
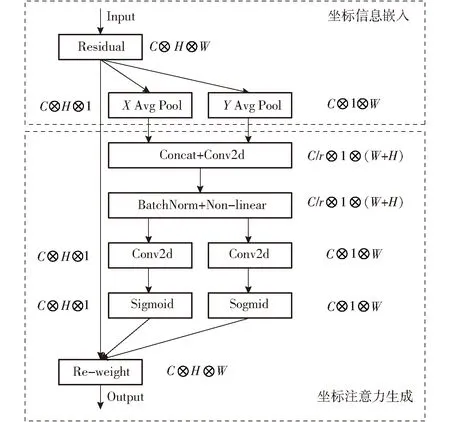
圖8 坐標注意力機制
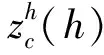
(1)
(2)
式中Xc(h,i)——高度h在第c個通道的分量
Xc(j,w)——寬度w在第c個通道的分量
這種轉換使注意力機制模塊可以捕捉空間方向的長期依賴關系,并保存沿著另一空間方向特征的精確位置信息。經過信息嵌入模塊的變換后,將兩個方向的坐標信息進行拼接,然后輸入1×1卷積函數F1中進行變換操作,計算公式為
f=δ(F1([zh,zw]))
(3)
式中 [,]——沿空間維度的串聯操作
δ——非線性激活函數
f——對空間信息在水平與垂直方向進行編碼的中間特征
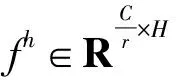
gh=σ(Fh(fh))
(4)
gw=σ(Fw(fw))
(5)
式中σ——Sigmoid激活函數
gh——沿水平方向特征張量
gw——沿垂直方向特征張量
由于σ計算耗時較大,為了加快運算速度,采用下采樣比r減少f通道數。綜上,對于輸入X的第c個通道上高度i和寬度j的特征Xc(i,j),經過坐標注意力模塊的輸出可表示為
(6)
式中yc(i,j)——嵌入坐標注意力模塊后的輸出結果
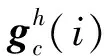
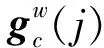
1.4 分籠計數法
ALPATOV等[29]提出車輛檢測與道路標線檢測算法,并根據道路標線算法劃分車道從而實現多通道車輛計數,結果表明,5個通道平均計數準確率為98.9%。基于此,本研究通過檢測二維碼獲取檢測框坐標和存儲信息區分不同雞籠,并設計分籠計數法(Counting in different cages,CDC)實現雞只與雞蛋自動化計數。該算法可分為計數感興趣區域(Counting in region of interest,CRoI)設置與自動化分籠計數兩個階段。CRoI設置流程如下:機器運動過程中,采用YOLO v7-tiny-DO檢測圖像中目標,當識別到2個二維碼時,根據其檢測框坐標分別計算待測圖像中雞只與雞蛋計數區域的橫、縱坐標,并以此為邊界劃分目標CRoI,如圖9a(紅色框表示雞只CRoI,綠色框為雞蛋CRoI),計算過程為

圖9 計數感興趣區域
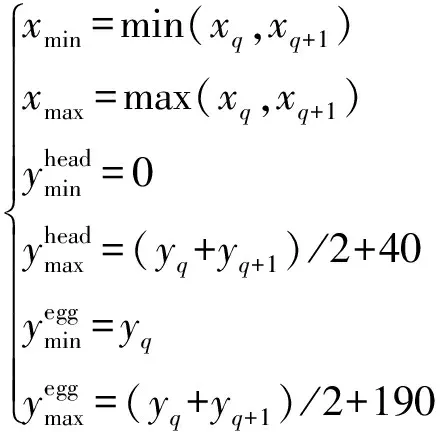
(q=0,1,…,29)
(7)
式中q——二維碼存儲的雞籠編號
xq——二維碼檢測框左側上頂點橫坐標
yq——二維碼檢測框左側下頂點縱坐標
[xmin,xmax]——計數區域橫坐標取值范圍
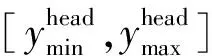
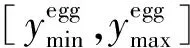
值得注意的是,若未識別到2個二維碼,則不進行CRoI設置操作,跳至下一幀。
選定CRoI后進行自動化分籠計數。過程如下:首先采用pyzbar函數識別二維碼信息,選擇較小數值作為待測雞籠編號q;然后獲取當前幀F(k,q)所有雞只與雞蛋檢測框的中心點坐標(xi,yi),計算其在CRoI范圍內的目標個數觀測值F(k,q)num,計算過程為
(8)
其中
式中k——幀序號
最后,當二維碼信息發生變化時,統計雞籠編號q所有視頻幀的觀測值,計算其均值作為目標數量預測值P(k,q),計算過程為
(9)
式中 「?——小數向上取整計算符號
mean——所有幀預測值的均值
實際計數過程中,巡檢機器人移動時獲取的計數感興趣區域與實際雞籠區域相比誤差較大,導致分籠計數錯誤(圖9a綠色虛線框)。為減小運動過程中計數區域的誤差,本研究采用單目相機標定模型[30]對CRoI進行校正,實現CRoI在像素坐標與世界坐標之間的相互轉換,坐標變換過程為
(10)
(11)
式中 (cx,cy)——圖像中心點坐標
(ix,iy)——雞籠邊界坐標
z1——鏡頭到二維碼的水平距離
z2——鏡頭到雞籠的水平距離
(Wx,Wy,Wz)——(ix,iy)轉換后的世界坐標
(Ix,Iy)——(ix,iy)糾正后坐標
fx、fy——橫、縱像素焦距
1.5 模型訓練
1.5.1訓練環境
模型訓練硬件環境主要包括Intel(R)Core(TM)i9-10900X處理器,主頻3.70 GHz,運行內存24 GB,GPU型號為Titan RTX,操作系統為Ubantu 18.04。軟件環境為Python 3.7語言版本、PyTorch 1.7框架、OpenCV 4.3.5圖像處理庫與pyzbar 0.1.8二維碼識別庫。
1.5.2參數設置
網絡訓練參數設置如下:輸入圖像尺寸為 640像素×480像素,批量大小為32,初始學習率設置為0.001。采用隨機梯度下降(Stochastic gradient descent,SGD)方法優化模型,動量因子為0.937,權重衰減因子為0.000 5。模型共訓練300輪,迭代1個輪次保存一次模型權重,最終選擇識別精度最高的模型。
1.5.3評價指標
采用精確率(Precision,P)、召回率(Recall,R)、平均精確率(Average precision,AP)、F1值、模型內存占用量(Model size)和幀率(Frames per seconds,FPS)來評價模型性能,采用平均絕對誤差(Mean absolute error,MAE)和平均準確率(Mean accuracy rate,MAR)評估分籠計數算法。
2 結果與分析
2.1 不同檢測模型性能對比
為驗證YOLO v7-tiny-DO模型對雞只與雞蛋的識別能力,本研究選擇主流目標檢測網絡Faster R-CNN、SSD、YOLO v4-tiny、YOLO v5n、YOLO v7-tiny與YOLO v7-tiny-DO進行對比試驗。訓練過程中,所有網絡使用相同訓練集,并應用215幅測試集圖像對模型性能進行綜合評估。經完整測試后,不同模型檢測結果如表1所示,表中AP0.5表示交并比為0.5時的平均精確率。從表1可以看出,與Faster R-CNN、SSD、YOLO v4-tiny、YOLO v5n和YOLO v7-tiny相比,YOLO v7-tiny-DO的F1值優勢較為突出,雞只的F1值為97.0%,分別高于以上模型21.0、4.0、8.0、1.5、1.7個百分點;雞蛋的F1值為98.4%,比其他模型分別高31.4、25.4、6.4、4.4、0.7個百分點。
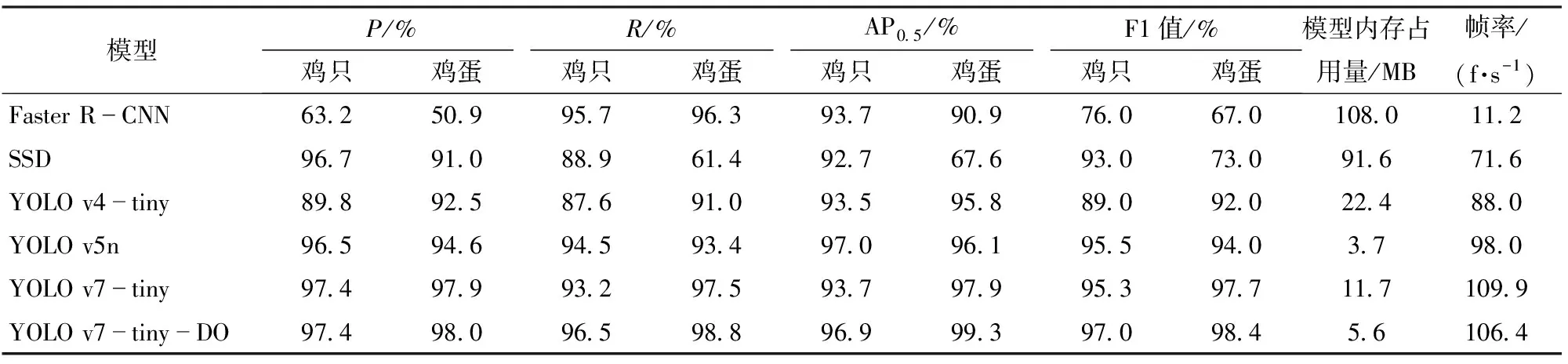
表1 不同檢測網絡對比
對比YOLO v7-tiny-DO與YOLO v7-tiny,二者幀率均高于100 f/s,能夠滿足實時檢測任務的需要;YOLO v7-tiny-DO模型檢測雞只和雞蛋的AP分別為96.9%與99.3%,相比YOLO v7-tiny分別提高3.2、1.4個百分點;YOLO v7-tiny-DO模型內存占用量為5.6 MB,比原模型減小6.1 MB,適用于算力匱乏的巡檢機器人。綜上,YOLO v7-tiny-DO網絡在提升模型精度的情況下降低了模型參數量,證明了改進后模型的有效性。
2.2 不同場景下檢測結果分析
由于實際雞舍環境較為復雜,采集圖像中通常存在局部遮擋、運動模糊、雞蛋粘連與光線昏暗等問題,導致雞只與雞蛋自動化識別與計數困難。因此,針對以上4種場景分別進行討論。
2.2.1局部遮擋情況下識別結果對比
籠養雞舍環境中鐵絲或食槽遮擋易造成目標部分特征丟失,為驗證改進后模型在局部遮擋情況下檢測能力,將圖2a的2幅圖像輸入6個模型進行測試,檢測結果如圖10所示,圖中綠色、橙色、藍色和紫色橢圓分別表示雞只漏檢、雞只錯檢、雞蛋漏檢與雞蛋錯檢。表2為對應檢測結果,可以看出,YOLO v7-tiny-DO、YOLO v7-tiny和YOLO v5n能夠識別圖像中所有目標;Faster R-CNN雖然能夠識別被遮擋目標,但誤將紅色飲水器識別為雞只或雞蛋(圖10a),與其模型精確率低、召回率高相對應,發生錯檢次數較多;與Faster R-CNN不同,SSD和YOLO v4-tiny召回率低、精確率高,在遮擋較嚴重情況下,雞只或雞蛋特征缺失,易發生漏檢現象(圖10b、10c)。經過對比分析,YOLO v7-tiny-DO、YOLO v7-tiny和YOLO v5n模型對于遮擋目標檢測結果較好,未發生漏檢或錯檢情況。
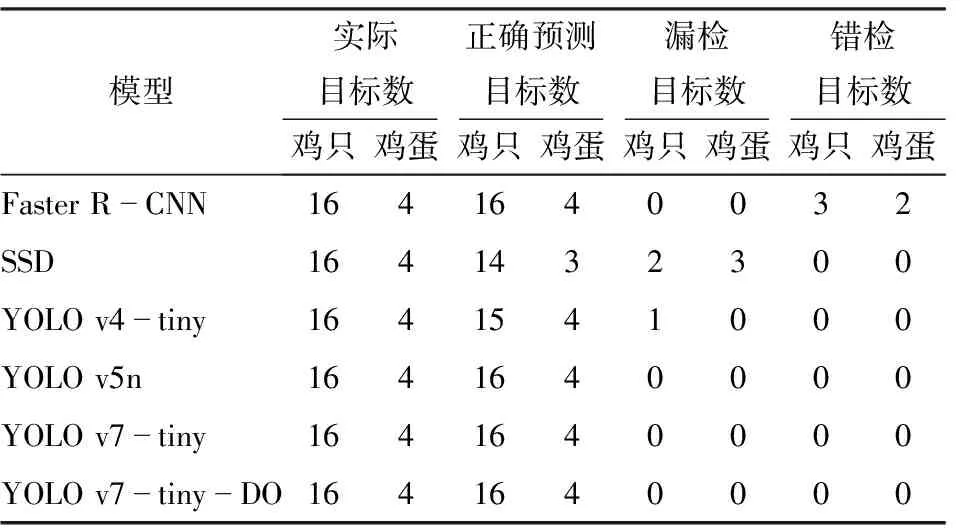
表2 局部遮擋情況下檢測結果對比

圖10 局部遮擋情況圖像檢測結果對比
2.2.2運動模糊情況下識別結果對比
實際巡檢過程中,雞只快速移動易導致圖像中雞只頭部發生模糊現象,圖11為6個模型檢測圖2b中模糊雞頭情況的結果,對應試驗結果如表3所示。由表3可以看出,YOLO v7-tiny-DO能夠識別圖像中所有模糊雞頭,Faster R-CNN漏檢1只雞(圖11a),SSD漏檢2只雞(圖11b),YOLO v4-tiny漏檢2只雞(圖11c),YOLO v5n漏檢1只雞(圖11d),YOLO v7-tiny漏檢2只雞(圖11e)。當圖像中雞頭發生運動模糊時,目標特征較為發散,不易識別。經過對比,在運動模糊情況下本研究提出的YOLO v7-tiny-DO檢測性能優于其他模型。
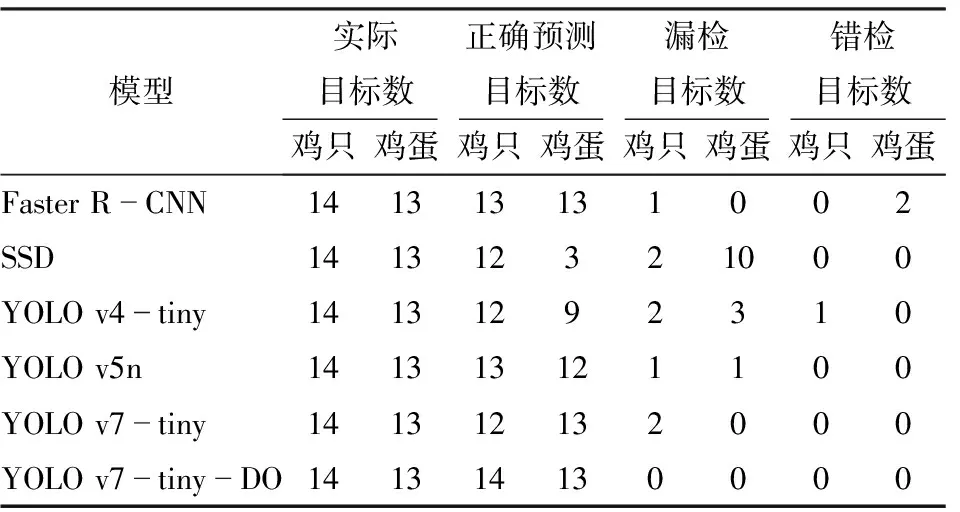
表3 運動模糊情況下檢測結果對比

圖11 運動模糊情況圖像檢測結果對比
2.2.3雞蛋粘連情況下識別結果對比
籠養模式下蛋雞飼養密度較大,蛋網上雞蛋粘連現象較為嚴重,圖12為6個模型在圖2c中粘連雞蛋情況下的識別結果,對應試驗結果如表4所示。由表4可知,YOLO v7-tiny-DO準確識別圖像中所有粘連雞蛋,其他模型均存在不同程度的雞蛋漏檢情況(圖12a~12e),其中SSD識別結果最差(圖12b),僅能檢測到多個粘連雞蛋中的一枚雞蛋。經過對比,YOLO v7-tiny-DO在雞蛋粘連情況下的雞蛋計數性能最優。
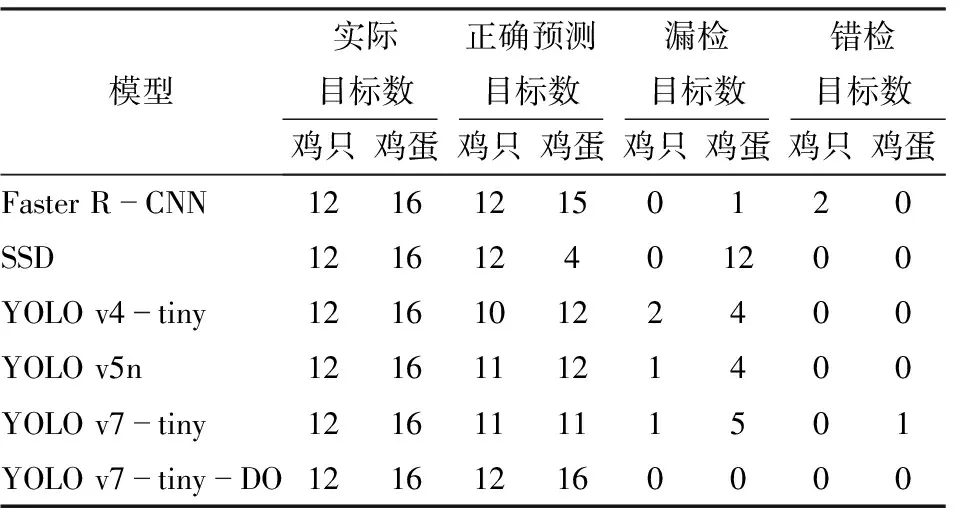
表4 雞蛋粘連情況下檢測結果對比

圖12 雞蛋粘連情況圖像檢測結果對比
2.2.4光線昏暗情況下識別結果對比
籠養雞舍內昏暗的環境為蛋雞和雞蛋識別與計數工作帶來巨大挑戰。圖13為6個模型在圖2d光線昏暗環境下的檢測結果,對應試驗結果如表5所示。由表5可以看出,YOLO v7-tiny-DO漏檢了 1只雞(圖13f);Faster R-CNN錯檢3只雞和2個雞蛋(圖13a);SSD漏檢2只雞和12枚雞蛋(圖13b);YOLO v4-tiny漏檢2只雞和2個雞蛋,錯檢2只雞(圖13c);YOLO v5n漏檢2只雞和2枚雞蛋(圖13d);YOLO v7-tiny漏檢2只雞和2枚雞蛋(圖13e)。綜上,圖中雞只與雞蛋的形態特征較為模糊,所有模型均存在漏檢或錯檢情況,但相比其他模型,YOLO v7-tiny-DO漏檢與錯檢數目最少,說明本研究提出的模型性能更好。

表5 光線昏暗環境下檢測結果對比

圖13 光線昏暗環境圖像檢測結果對比
2.3 計數試驗結果與分析
將YOLO v7-tiny-DO部署到NVIDIA Jetson AGX Xavier邊緣計算平臺,經深度學習引擎(DL accelerator與Vision accelerator)加速后,快速檢測視頻幀中目標,實現籠養模式下雞只與雞蛋自動化分籠計數。為驗證算法有效性,本研究在北京市華都峪口禽業有限公司第3場8舍選取30個雞籠開展計數試驗,巡檢機器人運動過程中,基于內置取幀算法每天采集15 min視頻數據用于測試,持續 3 d,期間第21號雞籠有1只死雞被淘汰。圖14為測試現場及計數結果。
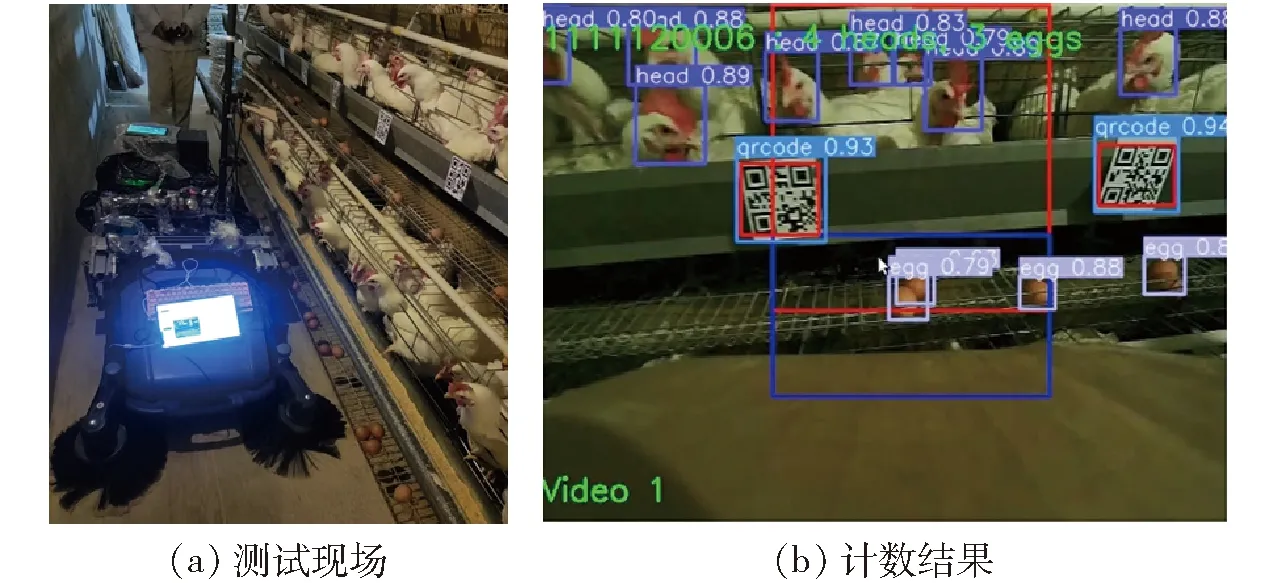
圖14 測試現場與計數結果
表6為不同測試批次雞只與雞蛋的自動化分籠計數結果。由表6可知,測試批次1中雞只和雞蛋分籠計數MAR分別為96.7%和97.2%,MAE分別為0.13只和0.07枚;測試批次2中雞/蛋分籠計數MAR分別為97.5%和94.5%,MAE分別為0.10只和0.13枚;測試批次3中雞只和雞蛋分籠計數MAR分別為96%和97.2%,MAE分別為0.17只和0.07枚。經過分析可知,3次測試雞只與雞蛋分籠計數平均準確率均值分別為96.7%和96.3%,每籠平均絕對誤差均值分別為0.13只和0.09枚,說明通過本文算法獲取籠內雞只與雞蛋個數是可行的。
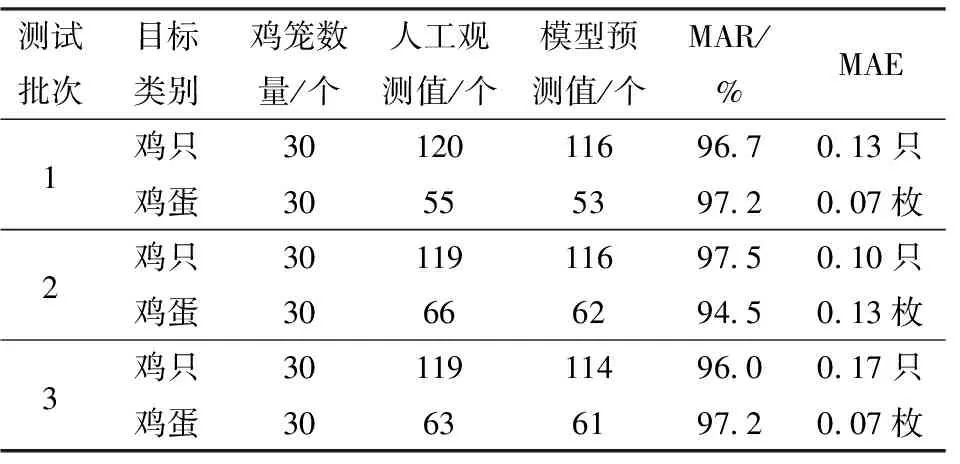
表6 雞/蛋自動化分籠計數結果
圖15為不同測試批次雞只與雞蛋自動化分籠計數結果統計圖。從圖中可以看出,測試批次1中0、9、26、29號雞籠均漏檢1只雞,21、25號雞籠均漏檢1枚雞蛋;測試批次2中7、10、12號雞籠存在雞只計數錯誤,7、22、26、27號雞籠存在雞蛋計數錯誤,平均絕對誤差均為1枚;測試批次3中7、8、11、17、20號雞籠均漏檢1只雞,3、27號雞籠均漏檢1枚雞蛋。對于漏檢目標,可能是因為雞舍內光線較為昏暗導致。
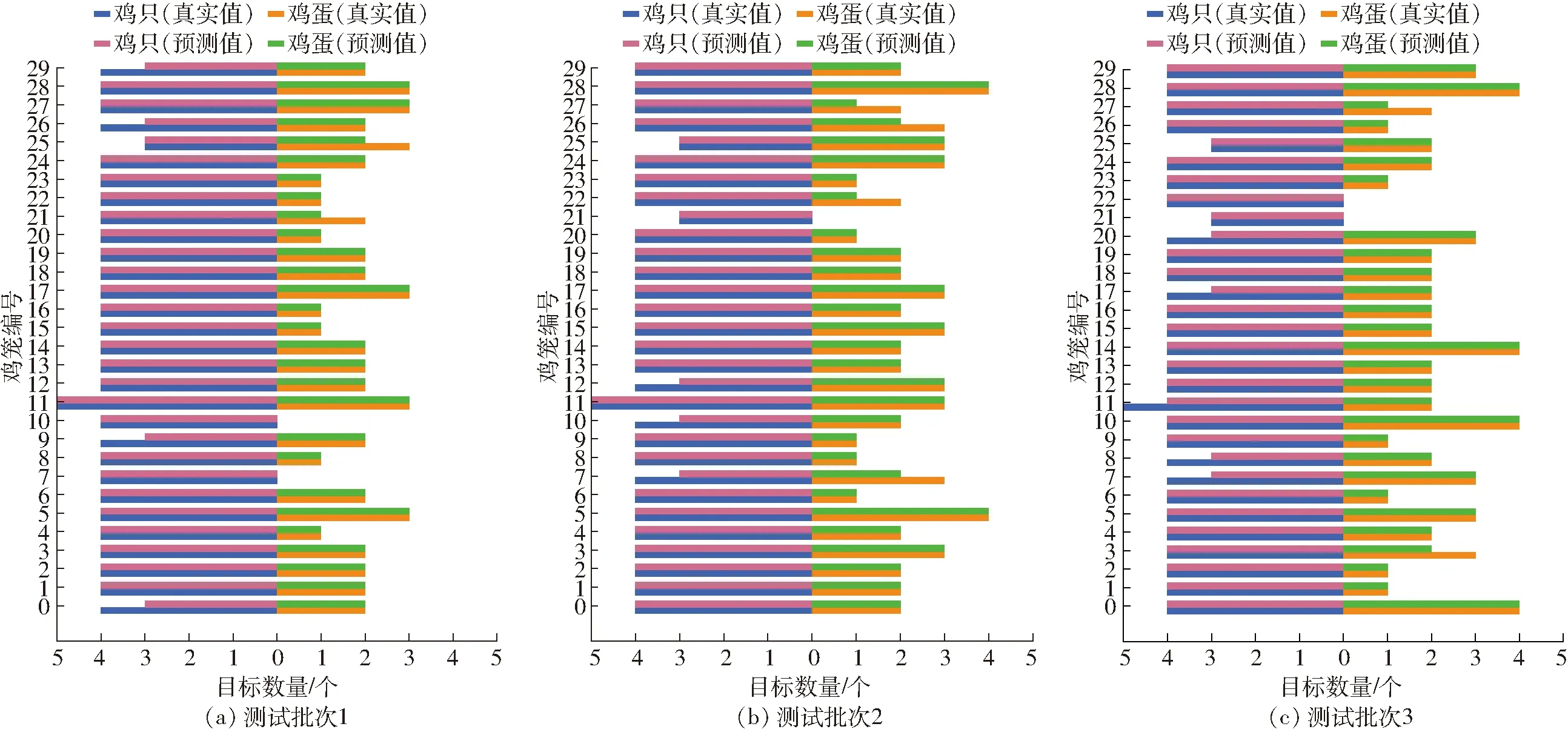
圖15 雞/蛋自動化分籠計數可視化結果
3 結論
(1)選擇YOLO v7-tiny為基礎網絡,首先將模型激活函數替換為ELU,然后在ELAN內構建深度過參數化深度卷積層,最后在Head端引入坐標注意力機制。試驗結果表明,YOLO v7-tiny-DO識別雞只與雞蛋的AP分別為96.9%與99.3%,幀率為106.4 f/s,模型內存占用量為5.6 MB,與原模型相比,識別雞只與雞蛋的AP分別提高了3.2、1.4個百分點,模型內存占用量減少了6.1 MB,適用于部署到算力匱乏的巡檢機器人上。
(2)與主流目標檢測網絡Faster R-CNN、SSD、YOLO v4-tiny和YOLO v5n相比,YOLO v7-tiny-DO的F1值更優,分別高21.0、4.0、8.0、1.5個百分點,雞蛋的F1值分別高31.4、25.4、6.4、4.4個百分點。對比以上模型在復雜場景下的檢測性能,結果表明,YOLO v7-tiny-DO在局部遮擋、動態模糊和雞蛋粘連情況下均能實現高精度識別與定位,在光線昏暗情況下識別結果優于其他模型。
(3)將YOLO v7-tiny-DO模型部署到搭載NVIDIA Jetson AGX Xavier的巡檢機器人上,開展為期3 d的計數測試。結果表明,3個測試批次雞只與雞蛋的分籠計數平均準確率均值分別為96.7%和96.3%,每籠平均絕對誤差均值分別為0.13只雞和0.09枚雞蛋。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
