基于梯度懲罰生成對抗網絡的過采樣算法
2023-07-27 02:10:04陶家亮魏國亮宋燕竇軍穆偉蒙
上海理工大學學報 2023年3期
陶家亮 魏國亮 宋燕 竇軍 穆偉蒙

摘要:在不平衡數據分類問題中,為了更注重學習原始樣本的概率密度分布,提出基于梯度懲罰 生成對抗網絡的過采樣算法(OGPG)。該算法首先引入生成對抗網絡(GAN), 有效地學習原始數 據的概率分布;其次,采用梯度懲罰對判別器輸入項的梯度二范數進行約束,降低了 GAN 易出現 的過擬合和梯度消失,合理地生成新樣本。實驗部分,在 14 個公開數據集上運用k 近鄰和決策樹 分類器對比其他過采樣算法,在評價指標上均有顯著提升,并利用 Wilcoxon符號秩檢驗驗證了該 算法與對比算法在統計學上的差異。結果表明該算法具有良好的有效性和通用性。
關鍵詞:? 不平衡數據 ;過采樣算法 ;概率密度分布 ;生成對抗網絡 ;梯度懲罰
中圖分類號:? TP 181???????????? 文獻標志碼:?? A
Oversampling algorithm based on gradient penalty generative adversarial network
TAO Jialiang1, WEI Guoliang2, SONG Yan3, DOU Jun3, MU Weimeng1
(1. College of Science, University of Shanghai for Science and Technology, Shanghai 200093, China;2. Business School, University of Shanghai for Science and Technology, Shanghai 200093, China;3. School of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China)
Abstract: In order to pay more attention to learning for probability density distribution of original samples in imbalanced data classification problem, an oversampling algorithm based on the gradient penalty generation adversarial network (OGPG) was proposed. Firstly, generation adversarial network (GAN) was adopted to effectively learn the probability density distribution of original data. Secondly, the gradient penalty was used to constrain the gradient two-norm of the input term of discriminator, which reduced the overfitting and gradient disappearance that appeared easily in GAN, so that the new samples were reasonably generated. In the experiment, the k-nearest neighbor and decision tree classifiers were adopted to compare the other oversampling algorithms, the evaluation indicators were significantly improved. The Wilcoxon signed-rank test was used to verify the statistical difference between this algorithm and the comparison algorithm. The results show that this algorithm has good effectiveness and generality.
Keywords:?? imbalanced? data; oversampling algorithm; probability? density? distribution; GAN; gradientpenalty
不平衡數據的分類問題在數據挖掘和機器學習領域中一直倍受關注。美國人工智能協會和國際機器學習會議分別就這個問題舉行了研討會。現實生活中,很多領域都會出現數據不平衡的問題,例如金融詐騙[1]、精準醫療[2]、故障診斷[3]、人臉識別[4-5]等。
數據不平衡[6]是指數據中某些類別的樣本數量遠比其他類別的多。通常情況下,少數類數據中包含更多重要的信息,是研究者重點關注對象。
目前處理不平衡數據分類的方法可以分為兩大類:基于算法層面[7]和基于數據層面[8]。算法層面主要包括代價敏感學習[9]和集成學習[10]:代價敏感學習通過最小化貝葉斯風險確定代價函數,以最小化誤分類代價為目標,但是誤分類代價的先驗信息是難以獲得的;集成學習是將多個分類器的分類結果結合在一起,提高集成分類器的精度,進而關注少數類的重要性。但這兩類算法沒有改變數據分布。數據層面主要包括欠采樣技術[11]、過采樣技術[12]。數據層面的技術主要通過改變樣本比例,例如欠采樣技術主要是通過減少多數類樣本,使得多數類樣本和少數類樣本趨于平衡,但隨機地舍棄樣本可能會丟失潛在的有用信息。隨機過采樣方法通過隨機復制少數類樣本,但是該方法只是簡單的復制樣本,增加了過擬合的風險。目前,過采樣技術的應用較為廣泛,因為該技術不僅保證了數據平衡,還沒有損失原始數據的有效信息。
過采樣技術的研究有很多,例如 Chawla等[13] 提出了合成少數類過采樣技術(synthetic minority oversampling technique, SMOTE),該算法在少數類樣本中與其近鄰樣本之間線性插值合成新樣本,沒有考慮少數類樣本內部的數據分布情況。He 等[14] 提出了自適應合成(adaptive synthetic, ADASYN)過采樣方法,該算法通過樣本點的學習難易程度給少數類樣本賦予權值。此外,為了加強對邊界樣本的學習,邊界自適應合成過采樣技術[15](B-SMOTE1, B-SMOTE2)被提出。隨著深度學習的高速發展,基于網絡過采樣的算法應運而生, Goodfellow 等[16] 提出生成對抗網絡(generative adversarial network, GAN)模型,通過生成器網絡學習原始數據的分布。 Douzas 等[17]提出利用條件生成對抗網絡學習原始數據的分布,再對少數類進行過采樣算法。何新林等[18]提出了基于隱變量后驗生成對抗網絡的過采樣算法( latent posterior based GAN for oversampling,LGOS),該算法引入隱變量模型,降低了高斯噪聲對生成樣本的隨機性影響。但 GAN 在訓練過程易出現過擬合或梯度消失的風險,可以對損失函數施加懲罰項[19],降低風險的發生。上述方法雖然在分類精度上有所提升,但沒有充分考慮原始數據的分布,進而影響合成樣本的安全性以及分類結果。
針對上述問題,本文提出了一種基于梯度懲罰生成對抗網絡的過采樣算法( oversampling algorithm based on the gradient penalty generation adversarial network , OGPG )。該算法引入生成對抗網絡,通過網絡的生成器模型有效地學習原始數據的概率密度分布;運用梯度損失模型對生成對抗網絡判別器輸入項的梯度二范數進行約束,降低過擬合和梯度消失的風險;在14個公共數據集上采用兩個分類器與多種算法進行了對比實驗,并利用 Wilcoxon符號秩檢驗[20]驗證了所提算法的有效性和通用性。
1 生成對抗網絡模型及梯度懲罰模型
生成對抗網絡(generative adversarial network, GAN)模型是一種無監督的生成模型,由生成器和判別器網絡組成,能夠有效地學習原始數據的概率密度分布。梯度懲罰模型是一種基于梯度損失的約束模型,降低了生成對抗網絡出現過擬合和梯度消失的風險。
1.1 生成對抗網絡模型
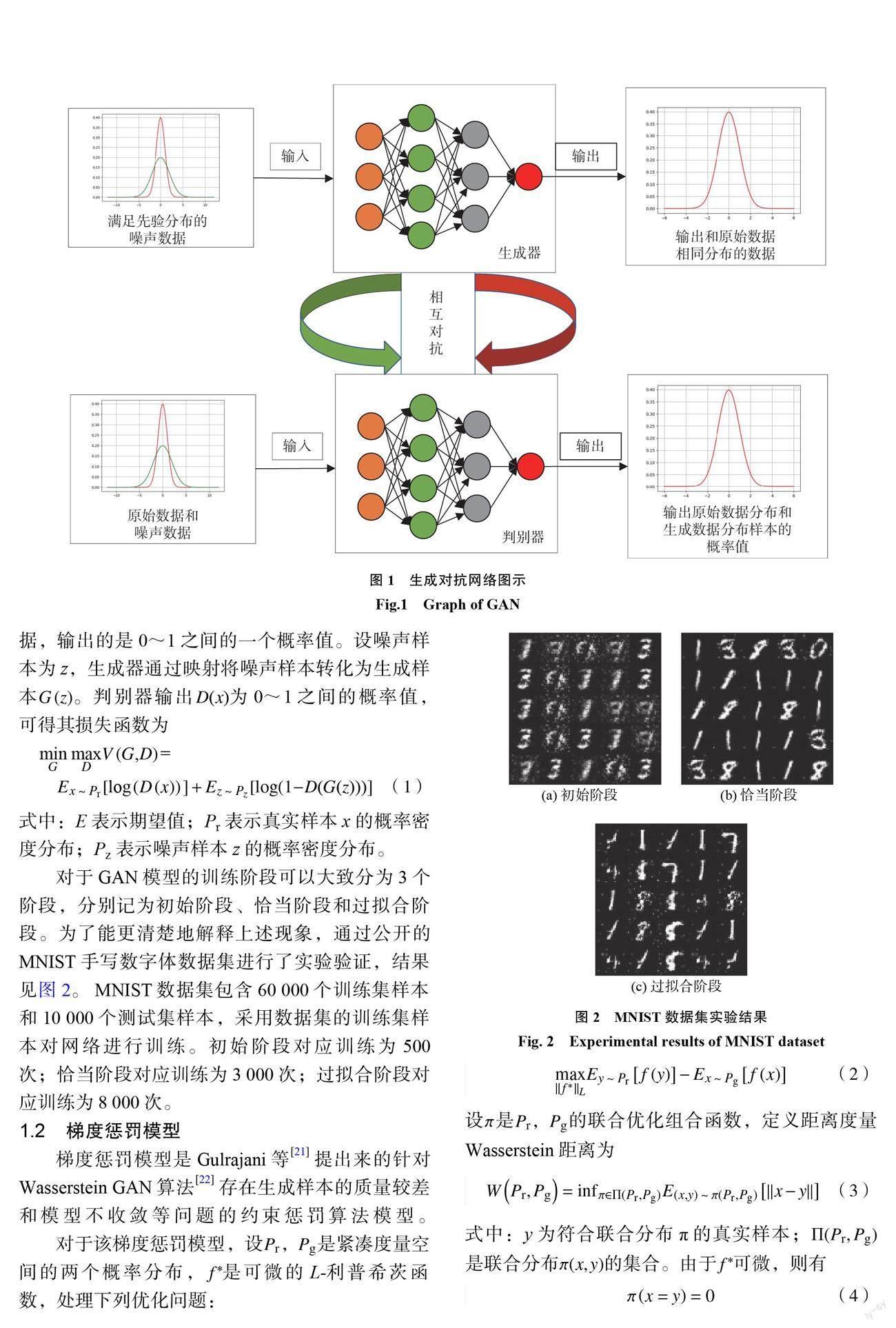
GAN 是 Goodfellow 等提出來的一種神經網絡模型,也是一種無監督的生成模型。它由生成器網絡和判別器網絡兩部分組成,網絡模型結構如圖1所示。 GAN 也是一個相互博弈的對抗模型,是判別器和生成器之間的相互博弈。其中,生成器是通過對先驗噪聲的學習,學習原始數據的概率密度分布;判別器主要對輸入數據進行判斷,判斷數據是原始數據或者是生成器網絡生成的數據,輸出的是0~1之間的一個概率值。設噪聲樣本為 z ,生成器通過映射將噪聲樣本轉化為生成樣本G(z)。判別器輸出 D(x)為0~1之間的概率值,可得其損失函數為
式中:E 表示期望值;Pr 表示真實樣本 x 的概率密度分布; Pz 表示噪聲樣本 z 的概率密度分布。
對于 GAN 模型的訓練階段可以大致分為3個階段,分別記為初始階段、恰當階段和過擬合階段。為了能更清楚地解釋上述現象,通過公開的 MNIST 手寫數字體數據集進行了實驗驗證,結果見圖2。 MNIST 數據集包含60000個訓練集樣本和10000個測試集樣本,采用數據集的訓練集樣本對網絡進行訓練。初始階段對應訓練為500次;恰當階段對應訓練為3000次;過擬合階段對應訓練為8000次。
1.2 梯度懲罰模型
梯度懲罰模型是 Gulrajani 等[21]提出來的針對 Wasserstein GAN 算法[22]存在生成樣本的質量較差和模型不收斂等問題的約束懲罰算法模型。
對于該梯度懲罰模型,設Pr ,Pg 是緊湊度量空間的兩個概率分布, f *是可微的 L-利普希茨函數,處理下列優化問題:
設π是Pr ,Pg 的聯合優化組合函數,定義距離度量 Wasserstein 距離為
式中:y 為符合聯合分布π的真實樣本;Ⅱ(Pr ; Pg )是聯合分布π(x;y)的集合。由于f *可微,則有
即,對于所有的 L-利普希茨函數幾乎都滿足,若該函數可微則處處都有梯度,且梯度的范數值為1。根據上述理論知識, Ishaan 等研究者將梯度范數約束在不大于1的范圍之內,提出如下新的約束懲罰:
式中: LGP表示梯度懲罰損失;?(x)表示訓練樣本;ⅡΔ?(x)Dw(?(x))Ⅱ2表示 Wasserstein GAN 中判別器網絡輸入項梯度的二范數;α是梯度懲罰因子; w 是判別器網絡的參數,即D(?(x); w)。
2 基于梯度懲罰生成對抗網絡的過采樣算法
由于傳統的過采樣算法沒有充分考慮原始樣本的概率密度分布,且易導致生成低質量的樣本,因此本文引入生成對抗網絡模型和梯度懲罰模型,提出了一種基于梯度懲罰生成對抗網絡的過采樣算法(OGPG)來解決上述問題。
在 OGPG 算法中,為防止少數類樣本過少導致網絡模型學習不到原始數據的有效信息,先對原始數據中的少類樣本自適應生成部分樣本。該算法主要包括3個步驟。
a.去除噪聲樣本。
在數據預處理階段,先處理原始數據中存在的噪聲數據。對每個樣本采用 k 近鄰算法,計算樣本點與其他樣本點的距離,找到該樣本點的 k 個最近鄰樣本點,如果該樣本點的標簽與 k 近鄰中的所有樣本點的標簽不一致,則認定為噪聲數據,并刪除該樣本點。
b.合成部分少數類樣本。
在步驟(a)的基礎上,通過線性插值優先合成部分少數類樣本數據,通過合成后的樣本,學習樣本的均值和方差,以便后續訓練網絡生成新的樣本。
首先,設 T 為去噪后原始數據的總樣本集合, Tmaj為多數類樣本集合, Tmin為少數類樣本集合,則有
過采樣所需要的生成的樣本量
接著,采用線性插值合成部分少數類樣本,對于任意的Tmin中的一個樣本點xi,運用歐氏距離度量,隨機選取 k 近鄰中的一個近鄰樣本xj,通過線性插值合成樣本?(x),
式中,? e [0;1],通過線性插值合成的樣本量集合記為T syn。通過合成少數類樣本后得到新的少數類樣本集合記為Tnew_min 。其中,
c.生成新樣本。
結合生成對抗網絡模型和梯度懲罰模型優良性質,針對過采樣問題提出了改進后的損失函數為
式中, P?(x)表示真實數據分布和生成數據分布采樣的線性均勻采樣分布,即?(x)=βxr+(1一β)xg ;β e (0;1)。
通過步驟(a)的去除噪聲和步驟(b)合成部分少數類樣本之后,采用梯度懲罰生成對抗網絡算法生成新樣本。
首先,把合成的新的少數類樣本記為新少數類樣本,即Tnew_min 。通過計算得到該樣本的均值和方差,分別記為?和σ2。對于噪聲樣本 z ,假設滿足
噪聲數據通過映射將數據轉化為生成樣本
接著,將噪聲樣本和新少數類樣本分別用生成器網絡和判別器網絡進行迭代,計算各個網絡及梯度懲罰的損失,由式(12)得到判別器損失 LD 、生成器損失 LG 和梯度懲罰損失 LGP ,分別為
式中: x為訓練樣本;∥ΔxD(x)∥2為求該樣本的梯度的二范數。
再設置判別器網絡和生成器網絡的收斂閾值,在達到閾值之后停止迭代,實驗設置循環迭代閾值為3000次。最后,通過網絡收斂時生成器生成的樣本即為新樣本,通過梯度懲罰的生成對抗網絡模型生成的樣本集合記為Tgen。
根據上述對于 OGPG 算法步驟的描述,給出算法的合成樣本示意圖,見圖3。
3 實驗結果及分析
3.1 數據集
為了驗證 OGPG 算法的有效性,實驗從 UCI 機器學習庫中挑選了14組二類不平衡數據集,其樣本量、特征數以及不平衡率(imbalanced ratio ,IR)都不相同。表1是所選取的數據集的詳細信息:
3.2 評價指標
在處理不平衡數據的分類問題的時候,分類器的超平面會向少數類樣本偏移,因此精確率不適合作為評價指標。實驗采用 Fm 和 Gm 作為評價指標[23]。其中 Fm 表示單一類別精確率和召回率的均衡指標, Gm 表示召回兩個類別數據的綜合表現指標。Fm 和 Gm 的計算式如下:
式中: TP 表示將正例樣本預測為正例;FP 表示將正例樣本預測為反例;FN 表示將反例樣本預測為正例; TN表示將反例樣本預測為反例; P 為查準率; R 為召回率; S 為特異性。
3.3 實驗分析
為了驗證 OGPG 算法的優越性,首先通過前8組數據集對比了 SMOTE, ADASYN ,B-SMOTE, CBSO[24]傳統過采樣算法。其次通過后4組數據集對比了采用 GAN 的 LGOS 算法。此外,在對比傳統算法中,采用 k 近鄰分類器和決策樹分類器隨機選取70%的數據作為測試集,剩余30%的數據作為測試集,每個數據集取5次實驗結果的平均值作為報告結果。在對比 LGOS 算法中采用決策樹分類器選取80%的數據作為測試集,剩余20%的數據作為測試集,每個數據集取10次實驗結果的平均值作為報告結果。粗體表示的是實驗的最優值。通過上述實驗驗證本算法的有效性和泛化能力。所有實驗都是在2.80 GHz CPU 、16.0 GB 內存的電腦上運行的,軟件環境是 Python3.7。
從表2和表3的結果可以看出,無論是 k 近鄰分類器還是決策樹分類器, OGPG 算法在 Fm, Gm 上均獲得了明顯提升。在 Fm 指標下,8個數據集中都表現較好;在 Gm 指標下,8個數據集中7個表現相對較好。通過對表2、表3對各指標的分析,可以發現算法在 Gm 指標下 abalone3vs11數據集上表現相對沒有優勢。該數據集在 CBSO 算法上表現相對較好,之所以出現該現象,是因為數據集中存在邊界較難學習的樣本, OGPG 算法較難學習到該樣本的有效信息,導致評價指標相對較低。但是從結果上看仍然非常接近最優指標,充分說明了 OGPG 算法的有效性。通過上述對表2和表3的結果分析,驗證了 OGPG 算法的有效性。
為了驗證 OGPG 算法的穩定性,實驗繪制了數據集在 Fm 指標和 Gm 指標下的箱線圖,分別見圖4和圖5。箱線圖包括一個矩形箱體和上下兩條線,箱體中間的線為中位線,上限和下限分別為上四分位數和下四分位數,箱子的寬度顯示數據的波動程度,箱體的上下方各有一條線是數據的最大值和最小值,超出最大最小值線的數據為異常數據。從圖4和圖5中可以看出, OGPG算法的數據波動性相對較小,數據的中值、上下四分位數與其他算法相比要更加穩定,且數值也優于其他算法,這說明了 OGPG 算法穩定性較好。
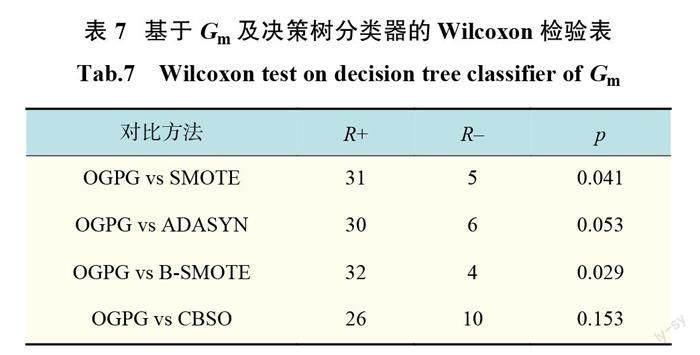
為了驗證 OGPG 算法在統計學上是否具有顯著性,本文采用 Wilcoxon符號秩檢驗來評估所提算法和其他對比算法之間的顯著性差異。表4~表7是 Wilcoxon符號秩檢驗的結果,其中 R+表示所提算法的秩和, R–表示對比算法的秩和,置信度是95%,p 為0.05。在 k 近鄰分類器下,可以看到,都是拒絕原假設;在決策樹分類器下,在對比算法 ADASYN 、CBSO 在 Gm 指標下是接受原假設,其余都是拒絕原假設,說明 OGPG 算法相對于其他算法具有較顯著的差異性。結合表2、表3在各指標的綜合表現情況,說明 OGPG 算法相對于傳統算法有顯著的有效性。
為了全面驗證算法的有效性,實驗還對比了文獻[18]的 LGOS 算法,即采用 GAN 的過采樣算法,如表8所示。從表8的結果可以看出,在決策樹分類器下,無論是 Fm 還是 Gm 指標,該算法均有較為明顯的提升。除此之外,在前8組數據集中,樣本量相對較少,在對比傳統算法中有顯著提升;在后6組數據集中,數據樣本量相對較多,在對比算法中同樣有著較為明顯的提升,說明了算法的有效性。
OGPG 算法和 LGOS 算法之間的顯著性差異見表9。可以看出,在置信度為95%的情況下,即 p 不大于0.05的情況下,均拒絕原假設。說明 OGPG 算法相對于 LGOS 算法具有顯著的差異性。通過該部分實驗也說明了 OGPG 算法具有顯著的有效性。
4 結束語
針對不平衡數據分類問題,傳統的過采樣算法沒有充分考慮原始數據的概率密度分布,從而導致生成的樣本不具有較強的安全性。通過引入生成對抗網絡以及梯度懲罰模型,提出了一種基于梯度懲罰生成對抗網絡的過采樣算法。在該算法中,首先引入生成對抗網絡,通過生成器網絡有效地學習原始數據的概率密度;其次,由于生成對抗網絡易出現過擬合或梯度消失等現象,因此采用梯度懲罰來對判別器網絡輸入項的梯度二范數進行約束,從而有效地降低了該情況的發生,使得生成器既能有效學習數據的概率密度分布又能合理地生成新樣本;最后,在14個公共數據集上采用兩個分類器與多種算法進行了對比實驗,并利用 Wilcoxon符號秩檢驗驗證了所提算法的有效性和通用性。當然,該算法也有一定的缺點,在時間復雜度上,因為算法引入了深度學習網絡,所以時間復雜度上較高,這也是后續將要努力的方向。
參考文獻:
[1] FIORE U, DE SANTIS A, PERLA F, et al. Using generative? adversarial? networks? for? improving classification effectiveness in credit card fraud detection[J]. Information Sciences, 2019, 479:448–455.
[2] FOTOUHI S, ASADI S, KATTAN M W. A comprehensive data level analysis for cancer diagnosis on imbalanced data[J]. Journal of Biomedical Informatics, 2019, 90:103089.
[3] MENA L J, GONZALEZ J A. Machine learning for imbalanced? datasets:? application? in? medical diagnostic[C]//Proceedings of the Nineteenth International Florida? Artificial? Intelligence? Research? Society Conference. Melbourne Beach: AAAI Press, 2006:574–579.
[4]武文娟, 李勇. Emfacenet:一種輕量級人臉識別的卷積神經網絡[J/OL].小型微型計算機系統, 2021:1–6.(2021-12-17). http://kns.cnki.net/kcms/detail/21.1106.tp.20211214.1436.004.html.
[5]周建含, 李英梅, 李文昊.一種改進的半監督集成軟件缺陷預測方法[J].小型微型計算機系統 , 2021, 42(10):2196–2202.
[6] ZHANG H L, LIU G S, PAN L, et al. GEV regression with convex? loss? applied? to? imbalanced? binary classification[C]//2016 IEEE First International Conference on Data Science in Cyberspace (DSC). Changsha: IEEE, 2016:532–537.
[7] JING X Y, ZHANG X Y, ZHU X K, et al. Multiset feature learning for highly imbalanced data classification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(1):139–156.
[8] ZHENG Z Y, CAI Y P, LI Y. Oversampling method for imbalanced classification[J]. Computing and Informatics, 2015, 34(5):1017–1037.
[9] CASTRO C L, BRAGA A P. Novel cost-sensitive approach to improve the multilayer perceptron performance on imbalanced data[J]. IEEE Transactions on Neural Networks and Learning Systems, 2013, 24(6):888–899.
[10] WANG C, DENG C Y, YU Z L, et al. Adaptive ensemble of classifiers with regularization for imbalanced dataclassification[J]. Information Fusion, 2021, 69:81–102.
[11]周傳華, 朱俊杰, 徐文倩, 等.基于聚類欠采樣的集成分類算法[J].計算機與現代化, 2021(11):72–76.
[12]陳剛, 郭曉梅.基于時間序列模型的非平衡數據的過采樣算法[J].信息與控制, 2021, 50(5):522–530.
[13] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16:321–357.
[14] HE H B, BAI Y, GARCIA E A, et al. ADASYN: Adaptive synthetic? sampling? approach? for? imbalanced learning[C]//2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence). HongKong, China: IEEE, 2008:1322–1328.
[15] HAN H, WANG W Y, MAO B H. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning[C]//International ?Conference? on? Intelligent Computing. Berlin, Heidelberg: Springer, 2005:878–887.
[16] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal: MIT Press, 2014:2672–2680.
[17] DOUZAS G,? BACAO F. Geometric? SMOTE a geometrically? enhanced? drop-in? replacement? for SMOTE[J]. Information Sciences, 2019, 501:118–135.
[18]何新林, 戚宗鋒, 李建勛.基于隱變量后驗生成對抗網絡的不平衡學習[J].上海交通大學學報 , 2021, 55(5):557–565.
[19] LUO X, CHANG X H, BAN X J. Regression and classification using extreme learning machine based on L1- norm and L2-norm[J]. Neurocomputing, 2016, 174:179–186.
[20] CUZICK J. A Wilcoxon ‐ type test for trend[J]. Statistics in Medicine, 1985, 4(1):87–90.
[21] GULRAJANI I, AHMED F, ARJOVSKY M, et al.Improved training of Wasserstein GANs[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: Curran Associates Inc. , 2017:5769–5779.
[22] ADLER? J,? LUNZ? S.? Banach? Wasserstein GAN[C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal:Curran Associates Inc. , 2018:6755–6764.
[23] HE H B, GARCIA E A. Learning from imbalanced data[J]. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9):1263–1284.
[24] YU Y, GAO S C, CHENG S, et al. CBSO: a memetic brain storm optimization with chaotic local search[J]. Memetic Computing, 2018, 10(4):353–367.
(編輯:董 偉)
