基于油浸式機器人的變壓器故障識別研究
2023-06-21 01:58:44李自榮冉艷紅
智能計算機與應用 2023年6期
晏 剛, 李自榮, 冉艷紅, 彭 水, 鄭 凱
(重慶賽寶工業技術研究院有限公司, 重慶 401332)
0 引 言
目前油浸式變壓器內檢方式存在效率低、檢測盲區、故障判別難度大、變壓器內部二次污染和破壞等問題。 油浸式智能內檢機器人通過機器視覺和人工智能技術進行故障分析和定位,一方面代替人工在不放油、充氣的情況下進入變壓器內部工作,減少檢修天數,提高檢修效率;另一方面,可通過圖像的智能識別提高故障判別準確率,降低檢修成本。 本文研究變壓器油浸式智能內檢機器人,將變壓器內部視頻圖像傳輸到工作站,使用卷積神經網絡進行故障識別、分析預測,提高大型電力變壓器的檢修效率、發現潛伏缺陷、提高故障診斷準確性。
1 油浸式變壓器故障類型分析
電力變壓器內部故障主要表現為機械故障、熱故障和電故障3 種類型,以后兩種故障類型為主,大多數機械故障最終也會表現為熱故障和放電性故障[1]。 過熱性故障是熱應力所造成的絕緣加速劣化;放電性故障可根據其放電能量的密度分為電弧放電、火花放電和局部放電3 類[2]。 一旦出現運行缺陷或故障,或者需要對設備大修時,仍需要將設備停電放油,由專業技術人員從入孔爬進設備箱體內進行內檢排查,發現設備里的缺陷或故障,必要時還需要對變壓器進行吊罩處理和解體檢查。
2 卷積神經網絡
本文研究的油浸式變壓器故障識別卷積神經網絡使用Hu 特征提取和Hog 特征提取兩種圖像數據特征提取算法。
2.1 Hu 特征提取算法
采用Hu 特征提取算法進行Hu 不變矩提取時,主要利用0、1、2 和3 階矩陣進行提取[3]。 首先計算各階矩陣的幾何矩,再計算中心矩,然后歸一化中心矩,最后計算7 個Hu 不變矩并進行歸一化。 Hu 不變矩特征提取流程圖如圖1 所示。

圖1 Hu 不變矩特征提取流程圖Fig. 1 Hu invariant matrix feature extraction flow chart
2.2 Hog 特征提取算法
采用Hog 特征提取算法進行特征提取時,首先將圖像進行灰度處理,然后計算每個像素點的梯度,在每個梯度方向上劃分區間,在各個方向投影,得到并統計每個區間的特征向量,一個塊又由4 個相鄰單元構成,同樣對其在每個梯度方向的各個方向進行投影,得到并統計每個塊的特征向量,最后對每個塊的特征向量進行結合,就可以得到總的特征向量[4]。 在設計時有部分參數很關鍵,例如胞元大小計算Hog 的單元大小,每個單元可以得到一個直方圖,默認值為[8,8];一個塊的大小,默認值為[2,2];重疊塊說明塊之間的重疊部分的大小,默認值是0.5。 在識別時將圖像尺寸轉換為40×40,為了遍歷圖像時讓塊正好分開,將胞元大小改為[10,10]。Hog 特征提取流程圖如圖2 所示。

圖2 Hog 特征提取流程圖Fig. 2 Hog feature extraction flow chart
3 油浸式變壓器故障圖像的預處理
3.1 智能機器人圖像采集
變壓器油浸式智能內檢機器人進入變壓器內部,攝像機采集到的圖像上傳到工作站后采用卷積神經網絡進行故障智能識別。
因為采集到的圖像都是3 個層次的色彩深度達到800×800 的圖像,卷積神經網絡需要的是具有3個深度的RGB 三色頻譜416×416 像素的圖像,所以需要采用雙線性插值法對數據集圖像進行比例轉換,轉換為416×416 像素的圖像[5]。
利用雙線性插值進行圖像縮放的步驟包括:計算目標圖片與原始圖片之間的縮放因子(寬度、高度方向);利用縮放因子,由目標圖片像素位置反推回原始圖片中的虛擬像素位置;由虛擬像素位置找到寬度和高度方向相鄰的4 個像素點;由4 個像素點進行雙線性插值計算,得出目標圖像中的像素值[6]。 雙線性插值法的原理示意如圖3 所示。

圖3 雙線性插值法原理示意圖Fig. 3 The principle of bilinear interpolation
在進行雙線性插值處理時,點P00,P01,P10,P11為已知的4 個像素點,要得到Px點的像素值,首先在W軸方向進行線性插值,得到Px0,Px1點的像素值,式(1) 和式(2):
其次,在H軸上由Px0和Px1分別計算線性差值,得到Px的像素值,式(3):
從式(1) ~式(3)得到了雙線性插值總公式(4):
采用雙線性插值法,將離散分布的像素圖進行直線化處理,使之能夠準確地估計出2×2 像素區塊內的任何點處的像素值,最大限度地減少在非比例放大時丟失的物體特性,降低對后續的特征抽取工作的干擾。
3.2 圖像濾波
在卷積神經網絡中,隨著樣本的聚集程度越來越高,網絡訓練的運算能力和參數的收斂性也越來越強,因此在網絡訓練之前,需要對原始圖像數據進行預處理,常用的方法是去均值和歸一化。 去均值就是把每個圖像的數據減去全部的圖像數據的平均值,把圖像的亮度統一,把所有的圖像都變成0 值中心;而規一化則是通過把圖像的像素變換成較小的值域,從而減小了奇異樣本的影響。 通過對圖像原始數據去均值和規一化處理,可以實現對樣本的更精確地分布,更易于訓練。
將圖像中的均值分成兩類: 全圖像均值(imagemean)和像素均值(Pixelmean)。 全圖像均值是指各幅圖像在某一深度上的各個空間位置上的像素的平均值,包含了空間分布數據;像素均值則是在一定的深度,對所有像素進行均值的計算,而不會考慮各圖像的空間分配。 由于DIOR 數據集合內沒有任何空間上的分布規則,因此本文使用了像素均值。對具有d深度的像素均值進行了運算,公式(5):
其中,num代表了數據集訓練集的圖像數量;H代表圖像的高;W代表圖像的寬;DIOR 對應的數值為800; 而img[n][h][W][d] 代表深度中的第(D) 圖像的像素數值;d分別取0,1,2,對應于圖像的RGB3 個層次深度。
通過對5 862 張圖像訓練集的像素均值進行運算,得出RGB_mean =[100.28,1,028,393.05],去均值后的圖像綠色深度上的像素值更低,過濾掉綠干擾后的指標表現得更加明顯。
3.3 圖像增強及算法
利用卷積神經網絡對圖像局部細節進行增強,能夠在一定程度上限制圖像局部的過度增強,但這種方法的局限性在于對比度的放大是通過在預先定義的剪裁限制下剪裁直方圖來實現的。
對比度受限自適應直方圖均衡化的基本步驟如下:
第一步,將原始圖像分割成若干大小相等的子塊,每個子塊是連續的,彼此不重疊;
第二步,計算每個子塊的局部直方圖;
第三步,計算分配給每個子塊中每個灰度級的平均像素數,由參數AvNum表示,可由公式(6)定義:
其中,Xp和Yp分別是子塊X方向和Y方向上的像素數,GrayNum表示子塊的可能灰度。
第四步,設置剪切系數CV,并假設其范圍為[ 0,1]。 對于不同的圖像,通過模擬結果將其調整為最佳值,然后按照公式(7)計算實際剪切極限值NV:
其中,round是一個舍入函數。
第五步,使用剪切極限,剪切局部直方圖的每個灰度級的像素,并將額外的像素數重新分配到每個直方圖的每個灰度級。 假設NClip表示被忽略的像素總數,可以通過等式獲得每個灰度級應分配的像素數NAcp,式(8), 式(9):
伴隨著我國飛機發動機的發展,航空用高溫合金標準也在不斷壯大,如表1所示。我國在引進的基礎上也研制出了一些高溫合金材料,并相繼制定了各自的材料標準,涵蓋航空研制生產的所有高溫合金材料類型和品種。這些標準應用于航空發動機的設計、生產和使用,對高溫合金的整體發展起到了重要作用。
其中H(i),i=i0,i1…in表示子塊的局部直方圖。
假設CH(i) 是重新分配后的直方圖,可以得到等式(10):
第六步,假設上述分布后剩余的像素數為NumLeft,分布的步長可以定義為等式(11):
按步長從最小灰度開始搜索,以便在像素數小于剪切閾值時分配像素。 完成從最小灰度到最大灰度的循環,直到NumLeft為0。 直方圖分配就完成了,并獲得了一個新的直方圖。
第七步,剪切后對每個子區域執行直方圖均衡化。
第八步,每個子塊的中心點作為參考點,以獲得灰度值;對圖像中的每個像素進行雙線性插值處理,每個像素的映射由對應的區域4 個鄰接參考點確定。 利用雙線性插值進行灰度值計算的原理如圖4所示,黑色小矩形(x,y) 表示目標點,f(x,y) 是要計算的(x,y) 的灰度值,4 個相鄰區域的中心點用黑點表示,4 個相鄰點分別為A(x -,y -)、B(x+,y -)、C(x -,y+)、D(x+,y+)。 灰度值f(x,y) 可以用公式(12)給出的4 個點A、B、C、D的灰度值的線性組合來表示。 對于邊界區域中的像素,通過兩個相鄰采樣點的線性插值計算灰度;而圖像4 個角的點是用相鄰的采樣點計算的。

圖4 雙線性插值法灰度值圖計算原理Fig. 4 Principle of grayscale value calculation by bilinear interpolation
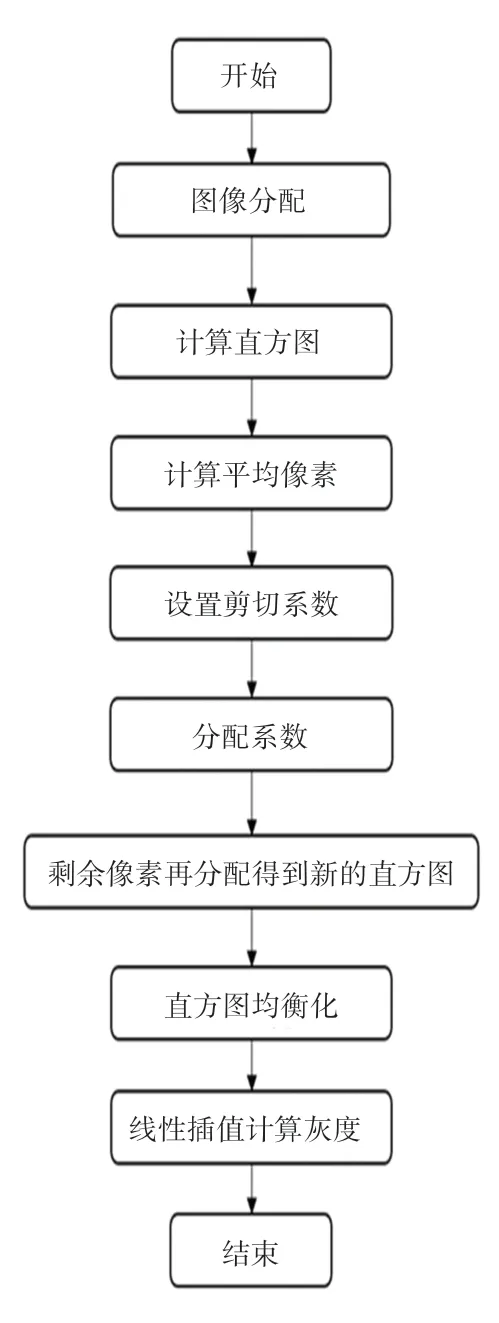
圖5 自適應直方圖均衡化流程圖Fig. 5 Adaptive histogram equalization flow chart
卷積神經網絡對讀入的圖像數據進行處理時,首先對直方圖進行分塊處理,將輸入進去的圖像劃分為大小相等的不重疊的子塊;通過對圖像分塊,將每個單獨的區域進行處理,每個圖像塊的局部圖像增強,從而解決全局均衡化處理的問題。 為了方便后續雙線性插值處理,分塊必須為2 的倍數,計算子塊的直方圖,并根據公式(6)得到每個子塊中每個灰度級的平均像素數。 例如:假定一幅圖像的像素為288×352,要分成8×8 個圖像塊,那么此時得到的每個圖像塊的像素就會變成36×44;剪切閾值的計算仿真,將其范圍設置在 [0,1],再按照公式(7)得到剪切閾值。 再對剩余的像素點分配,根據公式(8)先得到被忽略的像素總數,通過公式(9)得到每個灰度級能分配到的像素數,并按步長從最小灰度開始搜索,完成到最大灰度的循環,讓剩余像素數全都分配進去,獲得一個新的直方圖;再根據公式(10)進行直方圖均衡化,將每個子塊的中心點作為參考點,獲得灰度值,并使用對比度限制進行映射,改善噪聲的問題;再根據公式(12)對其雙線性插值處理,如果不進行插值處理,得到的圖像會分塊。 使用卷積神經網絡進行圖像數據處理的流程如圖6 所示。

圖6 卷積神經網絡圖像處理流程圖Fig. 6 Image processing of convolutional neural network
4 基于卷積神經網絡的油浸式變壓器故障識別
4.1 實驗準備
4.1.1 實驗環境及參數配置
本文以Zynq SoC 平臺為網絡部署流程的基礎,利用Xilinx 公司ZCU104 評估板,實現了網絡模型的硬件實現。 ZCU104 采用Zynq UltraScale+MPSoC系列的ZU7EV 芯片網,并在PS 上整合了四核心Arm Cortex-A53、 PL 端子UltraScale+FPGA 等各種應用。 ZCU104 主板的硬件資源見表1 所示。

表1 ZCU104 板硬件資源Tab. 1 Hardware resources of ZCU104 board
相對于Zynq7000 系列, MPSoC 的ZU7EV 系列的芯片邏輯能力得到了極大地提高。 PS 端與DDR4DDR4 的SDRAM 相連接,用以緩存運算時所生成的運算資料。 QSPI Flash 是用來儲存PS 端主電腦的開機影像,電腦啟動,會加載影像,以開啟PS端的主機系統。 JTAG 和Ethernet 界面可以使電腦向PS 終端傳送控制和傳送文檔。 此外,該面板具有USB3.0, HDMI 視頻輸入/輸出,LPC FMC 擴展卡接口等豐富的外部設備,能夠滿足各種不同的嵌入式系統的需求。
本文在充分利用FPGA 主芯片的設計和外部DDR 存儲能力的基礎上,將兩個并行的DPU 芯片在ZU7EV PL 上進行有效的部署,使系統充分利用現有的資源,加快了系統的運算速度。
4.1.2 數據集
卷積神經網絡模型的訓練需要大量的圖像。 然而收集和注釋龐大的數據集既費時又費力。 為了增加數據集的大小,采用常用的數據增強方法,通過一組計算成本低廉的轉換(例如旋轉、大小調整和縮放)以及顏色調整(例如亮度、飽和度和對比度的變化)在原始數據集的基礎上生成額外樣本。 本文使用旋轉、平移、翻轉和顏色轉換的數據增強技術。
本文的數據擴充是在“正常”和“在線”模式下進行的,并將相同的初始擴充數據存儲在磁盤上。正常模式將直接使用初始擴充數據集訓練卷積神經網絡模型,無需任何額外的預處理,而在線模式在訓練模型時額外應用在線數據擴充。 每個卷積神經網絡模型都在正常模式和在線模式下進行訓練,以研究兩種數據操作模式對模型性能的影響。
4.2 油浸式變壓器故障識別結果
利用卷積神經網絡進行分類識別,在訓練集Sample 文件夾中隨機抽取樣本圖片,以比例0.9 作為訓練樣本,剩下的作為測試樣本,計算每一種情況的油浸式變壓器故障識別的準確率,根據準確率來選取最佳的搭配方式,該準確率是在每種情況中經過反復抽樣測試而收集到的最大值,得到每種情況的準確率見表2。

表2 訓練樣本的準確率統計表Tab. 2 Statistics of accuracy of training samples
從表2 可以看出,兩種特征提取方式耗時相同,所以在耗時相同時選擇準確率較高的作為算法的實現過程。
5 結束語
采取Hog 特征提取的油浸式變壓器故障識別的準確率高于采取Hu 特征的識別準確率;兩種特征提取算法的識別速度相同。 本文設計變壓器油浸式智能內檢機器人,機器人配備攝像機將變壓器視頻圖像傳輸到電腦,使用卷積神經網絡進行故障識別的準確率可達到87.18%。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:08
汽車維修與保養(2019年7期)2020-01-06 03:30:42
電子制作(2019年15期)2019-08-27 01:12:00
通信電源技術(2018年3期)2018-06-26 06:33:30
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
汽車維護與修理(2016年10期)2016-07-10 08:17:41
現代工業經濟和信息化(2016年4期)2016-05-17 05:35:38
通信電源技術(2016年3期)2016-03-26 07:13:46
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
