基于知識圖譜的圖書館智能化資源推薦系統架構與優化策略
2023-06-17 01:03:34陳安琪陶興華
圖書館界 2023年2期
陳安琪,金 昆,陶興華,徐 鋒
(南京圖書館,江蘇 南京 210000)
隨著互聯網和信息技術的發展,人們獲取信息的方式不斷變化,接受信息的途徑越來越多,隨之而來的信息過載導致人們接收有效信息的效率下降。用戶對信息的需求愈發精準化和個性化,圖書館傳統的文獻資源和服務方式已經無法滿足讀者當下對于信息的需求。在此背景下,圖書館的文獻資源不再局限于傳統的紙質文獻,而是包含電子資源和數字資源,圖書館的信息服務也在向人工智能時代邁進,即從過去的以人的服務為中心,發展為以智能機器的服務為中心。其中,基于知識圖譜技術的個性化和智能化資源推薦系統,是圖書館向用戶提供高效便捷的智能化信息服務的重要環節。
1 知識圖譜及其在圖書館資源推薦中的應用概述
1.1 知識圖譜的概念
知識圖譜最早是谷歌公司在互聯網背景下提出的語義網絡知識庫,其核心在于從互聯網的海量信息中抽取實體、屬性及關系,解決個性化推薦、智能問答等方面的問題,并有效提高谷歌搜索引擎的效率。知識圖譜使用“實體—關系—實體”模型描述數據,不僅能夠表現各種客觀存在的實體和知識,還能體現個體間的關聯,從而形成語義網絡,網絡中的節點代表客觀存在的概念或實體,節點之間的連線代表它們之間的關系。通過引入知識圖譜,圖書館可以賦予知識庫邏輯推理的能力,從而挖掘信息之間的關聯,將其組織成有一定內在邏輯、能夠滿足用戶需求的知識體系。同時,知識圖譜還能夠挖掘用戶與信息之間,以及用戶與用戶之間的關系,通過推理和計算,進一步提升資源推薦的精準性。
1.2 圖書館個性化資源推薦研究進展
個性化推薦是基于數據挖掘、融合人工智能技術的智能化推薦,已廣泛應用于電子商務等領域,獲得了良好的經濟效益。圖情界的專家學者也就館藏資源的個性化推薦開展研究,獲得一定的理論成果和實踐經驗。筆者以“圖書館”和“個性化推薦”為關鍵詞,精確搜索2010年以后中國知網數據庫中的相關文獻,發現2010—2015年之間,我國對于圖書館個性化資源推薦的相關研究開始涌現。例如,朱世清[1]研究個性化推薦在高校圖書館學科服務中的應用;王連喜[2]從數據資源、技術方法和評價標準三個方面對個性化資源推薦進行論述。此外,也有學者對個性化資源推薦的相關技術進行研究,如孔功勝[3]對協同過濾、數據挖掘與發現、信息檢索與抽取技術在圖書館個性化推薦系統中的應用進行探討;陳雅等[4]研究基于自適應網絡的高校圖書館用戶模型構建和個性化知識推薦服務。2015年以后,隨著大數據技術和人工智能的發展,圖情領域對個性化推薦的研究開始融入知識圖譜、情境感知等人工智能技術,如劉海鷗等[5]通過融合情境感知的用戶信息分析,結合協同過濾算法,構建情境化的圖書館資源推薦系統;邵必林等[6]在知識圖譜的視域下研究圖書館個性化資源推薦的發展。可見,我國關于圖書館資源推薦的研究與智慧圖書館、人工智能等新技術的發展,以及個性化服務理念的深化密不可分。
1.3 知識圖譜應用于圖書館資源推薦服務的優勢
首先,應用知識圖譜能夠有效整合海量信息資源,為資源推薦服務提供基礎。圖書館擁有包括傳統紙質文獻和數字資源、網絡資源在內的大量文獻信息資源,涵蓋豐富多樣的內容。應用知識圖譜可以對各類信息資源進行深度挖掘和有機融合,形成具有邏輯關聯的知識網絡,從而提供更精準的信息服務,減少信息過載的問題。其次,應用知識圖譜能夠進一步優化用戶數據的分析和用戶畫像的構建,從而真正理解用戶的需求。人工智能技術的發展讓圖書館能夠實時擁有海量的多元異構用戶數據,包括用戶的基本信息、在圖書館的行動路線、信息搜索和瀏覽記錄、對信息和服務的反饋評價等。構建用戶信息知識圖譜能夠全方位地對用戶的特征和需求進行畫像,并分析用戶之間的動態聯系,從而實時掌握用戶的需求。再次,構建場景知識圖譜可以為場景服務提供助力。可穿戴設備、定位技術、社交網絡的發展,讓圖書館能夠實現對用戶所處場景的動態捕捉。構建場景知識圖譜能夠建立用戶和場景之間的聯系,推理各個場景要素之間的關聯,并根據用戶在不同場景中的需求進行資源推薦[7]。
2 知識圖譜的構建
知識圖譜的構建主要有自下而上和自上而下兩種方式。自下而上是在實體數據的基礎上構建本體;自上而下是指先定義本體,再引入實體數據。目前主流的知識圖譜大多采用自下而上的構建方式,包括知識抽取、知識融合、知識推理和更新、知識存儲等流程,是一個不斷反復循環的過程[8]。
2.1 知識抽取
知識抽取即對采集的數據進行解析,對其中的信息進行識別、篩選和總結歸納,從中抽取包含關系、實體和屬性三大要素的知識單元。知識抽取的對象包括結構化、半結構化和非結構化的數據。結構化數據是指能夠直接轉化為Rdf格式的數據,可以基于規則直接抽取;半結構化數據可以通過包裝器進行處理;文本數據等非結構化數據,可以將其轉化為結構化數據,或是基于學習進行抽取。
2.2 知識融合
知識融合指的是將多個不同知識庫中的數據進行清理、合并,消除歧義,整合為一個知識庫,其關鍵在于通過聚類分析、相似度分析等技術,實現實體對齊。知識庫對知識的搜集和描述各有側重,同一個知識實體在不同的知識庫中可能存在不同的描述,有的側重于對實體本身的描述,有的則側重于對關系和屬性的描述。知識融合可以有機整合實體在不同知識庫中的描述,從而使該實體在融合后的知識庫中的描述更加全面。
2.3 知識推理和更新
知識圖譜能夠通過推理和更新不斷擴充。知識圖譜中的知識以三元組的形式存在,知識推理可以使用神經網絡、矩陣分解等方法,基于現有的知識庫中已有的關系推理和挖掘隱含的信息與知識,從而推導出新的關系,形成新的三元組[9]。知識更新是指對新的實體數據進行處理,將其添加進已有的知識圖譜,實現對知識圖譜的深化和拓展。
2.4 知識存儲
目前,知識圖譜的存儲主要有Rdf和圖數據庫兩種方式。Rdf即資源描述框架(Resource Description Framework),使用Rdfs語法的Rdf/xml是最常用的知識存儲形式,它是一種在xml的基礎上構建的Rdf存儲形式,能夠方便地發布和共享知識數據,在使用過程中可以通過sparql訪問和操作。知識圖譜是一種基于圖形的直觀數據結構,因此圖數據庫(Graph Database)也是一種常用的存儲方式,能夠高效進行數據插入和查詢,并提供針對圖形的算法工具和查詢語言。例如,目前廣泛使用的neo4j系統,其優勢在于具有較強的可擴展性,安全性能高,操作友好,能夠通過可視化操作進行圖形的檢索和訪問,具有較高的搜索效率。
3 知識圖譜在圖書館智能化資源推薦系統中的應用框架
智能化資源推薦是知識圖譜在圖書館信息服務中的典型應用場景,其業務邏輯就是智能化地篩選、過濾海量信息資源,向用戶推薦他們最需要、最感興趣的資源,提升信息利用效率和用戶滿意度。智能化資源推薦系統不需要用戶主動提出明確的需求,可以自動根據用戶畫像和信息檢索行為實時分析用戶的信息需求,計算出最符合用戶需求的內容。引入知識圖譜的智能化資源推薦系統通過抽取資源信息和用戶信息,構建信息資源和用戶畫像知識圖譜,通過智能化的算法實現信息資源的智能推薦,整個系統分為數據采集及處理、知識圖譜構建、智能化推薦三大模塊(見圖1)。
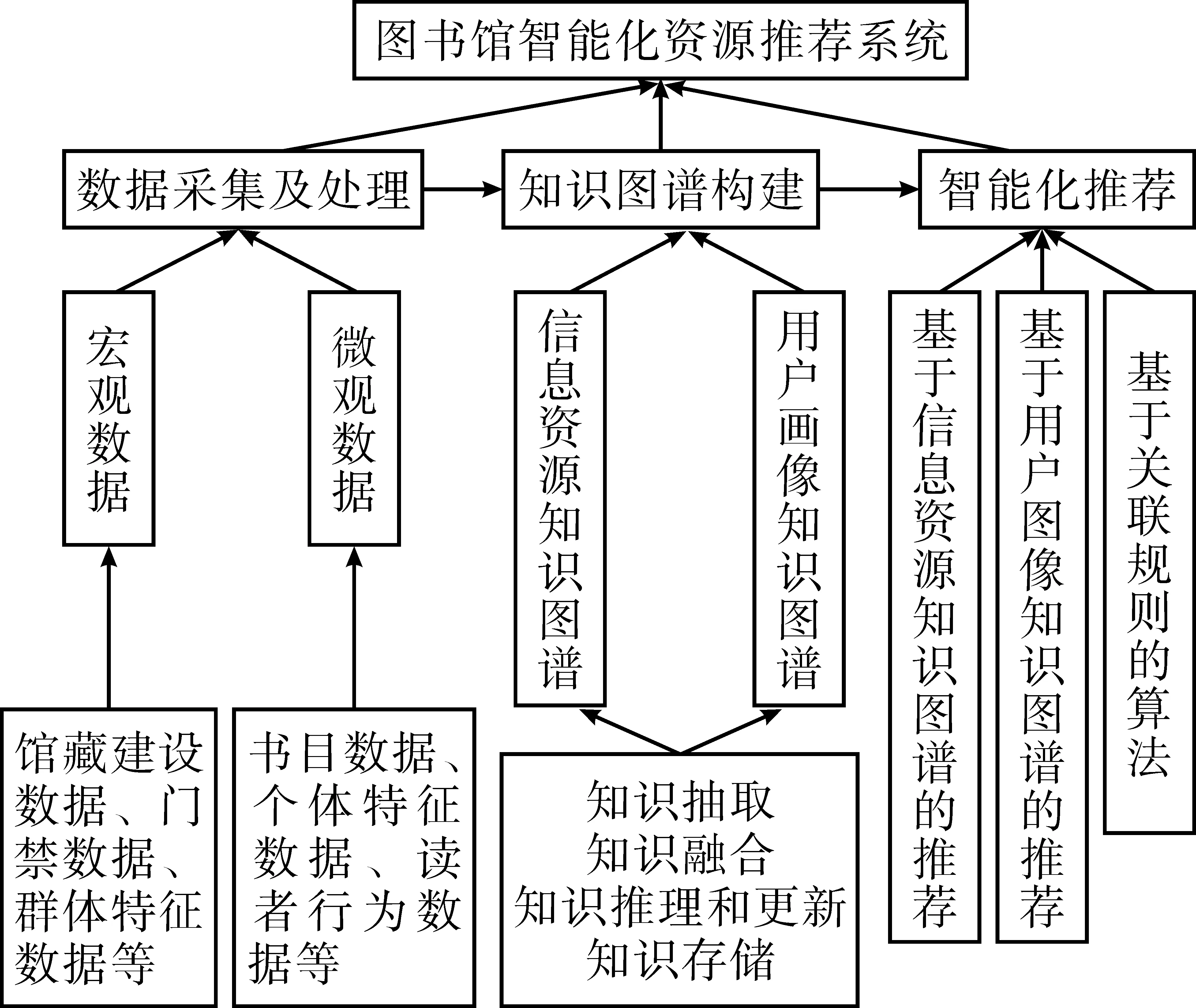
圖1 基于知識圖譜的圖書館智能化資源推薦系統應用框架
3.1 數據采集及處理
采集和處理圖書館大數據為知識圖譜的構建提供依據,是整個資源推薦系統的基礎。這些數據包括宏觀的館藏建設數據、門禁數據、讀者群體特征數據,也包括微觀的書目數據、讀者個體的特征和行為數據。這些數據來源多樣、形式豐富,是典型的多元異構大數據,有靜態數據,也有動態數據;有結構化數據,也有半結構化和非結構化的數據,需要對其進行清洗和處理,形成格式統一、結構完整的數據集。
3.2 知識圖譜構建
3.2.1 信息資源知識圖譜的構建。圖書館智能化資源推薦系統需要構建的知識圖譜包括信息資源知識圖譜和用戶畫像知識圖譜。圖書館的館藏信息資源來源和形式各異、內容豐富,深入挖掘和有效整合其中蘊含的知識和信息形成知識圖譜,使原本碎片化的信息資源形成有機聯系的整體,是圖書館提供資源推薦服務的基礎。構建信息資源知識圖譜需要從圖書館采編系統中抽取館藏書目和預購書目信息,包括書名、出版單位、著者、版本信息、分類號等,一般為MARC格式的數據。對于數字資源和網絡資源,圖書館可以通過構建數字資源庫的方式整合相關資源。此外,還需要抽取反映資源的利用率和半衰期的流通數據,如借閱率、下載率等。在數據抽取完成后,需要進行融合和推理,之后存儲為信息資源知識圖譜,并且在圖書館的信息資源發生更新時同步更新。信息資源知識圖譜能夠可視化地展現內容和主題相關的資源、同一著者或出版來源的資源,以及哪些資源被同一讀者或同一類型的讀者使用過,從而反映資源之間的關系,將碎片化的信息資源聯結成結構化的信息資源體系。
3.2.2 用戶畫像知識圖譜的構建。用戶畫像知識圖譜的構建需要對用戶的基礎信息與行為信息進行抽取和融合,形成能夠從多個維度描述用戶特征和用戶之間關系的畫像。基礎信息主要是用戶注冊和登錄圖書館時所提交的信息,包括個人的年齡、性別、學歷、職業等。行為信息主要采集的是用戶在使用圖書館信息資源的過程中所產生的行為數據,包括對信息的瀏覽、下載、收藏、點贊、評論等。圖書館根據這些信息生成用戶標簽體系并給每一個標簽賦予權重,各個標簽之間相互關聯,形成用戶的整體畫像。根據圖書館的實際情況以及用戶的信息需求差異,圖書館用戶標簽體系通常包括基本信息標簽(性別、年齡、專業、學校等)、用戶行為標簽(訪問、下載、搜索、瀏覽等)、社交屬性標簽(交互信息、意見反饋等)和情境標簽(訪問時間、位置信息等),不同的標簽體系從不同的角度對用戶進行描述。利用知識圖譜技術可以對標簽進行擴展和推理,將用戶之間的關系通過可視化的方式呈現出來,從而形成用戶畫像知識圖譜,用以揭示哪些讀者具有相似的個人特征和興趣偏好。
3.3 智能化推薦
3.3.1 基于信息資源知識圖譜的資源推薦模式和協同過濾算法。信息資源知識圖譜能夠體現資源的內容和資源之間的關系,基于信息資源知識圖譜的資源推薦模式可以基于資源的相似度和用戶對信息資源的歷史偏好,為用戶推薦類似的資源。這種推薦模式主要基于資源本身的關聯度和用戶的興趣畫像,因此對缺少用戶交互數據的新資源,也能迅速推薦給可能感興趣的用戶,有效提升資源的利用率。此外,該模式具有可解釋性,可以通過可視化地呈現信息資源的知識圖譜展現資源推薦的邏輯,增加用戶對所推薦資源的信任和興趣[10]。
基于信息資源知識圖譜的協同過濾推薦算法的邏輯是建立資源本身,而不是用戶的相似度矩陣,即基于用戶的偏好發現相似的資源,然后結合用戶的交互行為數據生成相似資源列表,推薦給用戶。例如,對于資源A而言,如果喜歡資源A的用戶中,同時喜歡資源B的比例較高,則資源B與A相似度較高,系統將向喜歡資源A的用戶推薦資源B。該算法結合了用戶的行為數據,能夠根據用戶對資源的瀏覽時間、下載和點贊等行為,以及評價內容等反饋,剔除一些內容相似度較高但是用戶并不感興趣的資源,提升用戶滿意度。
3.3.2 基于用戶畫像知識圖譜的資源推薦模式和協同過濾算法。用戶畫像知識圖譜以標簽化的方式構建用戶畫像,同時體現用戶之間的關聯性,通過知識圖譜能夠發現與當前用戶相似度較高的其他用戶,并將這些用戶感興趣的資源推薦給當前用戶。這種推薦模式主要基于用戶本身的信息和屬性發現用戶之間的關聯度,對信息資源知識圖譜的依賴性不高。
基于用戶畫像的協同過濾算法的邏輯是基于用戶的偏好,找出與目標用戶相似度最高的用戶集合,然后將這些用戶感興趣的資源集合推薦給目標用戶。例如,對于用戶a而言,可以將其對所有資源的偏好程度作為一個向量,通過余弦公式計算出與其相似度較高的n個用戶,然后將他們所感興趣的N個資源進行加權計算,最后將用戶a可能感興趣的Top-N個資源按照降序進行推薦[11]。
3.3.3 基于關聯規則的資源推薦模式和算法。基于關聯規則的資源推薦算法最早應用于電子商務領域,是一種基于數據間關系的推薦算法。在圖書館資源推薦系統中,圖書館可以通過構建資源與用戶之間的關聯進行資源推薦,即分析對A資源感興趣的用戶中,同時對B資源感興趣的用戶所占的比例,從而推算出對A資源的感興趣的用戶對B資源感興趣的程度,并據此作出是否向該用戶推薦B資源的決策[12]。
4 基于知識圖譜的圖書館智能化資源推薦系統優化策略
基于知識圖譜的圖書館資源推薦系統具有智能化、個性化優勢,在閱讀推廣、公共數字文化服務等方面應用廣泛,能夠有效提升服務水平,但還存在一些不足。首先,資源建設的標準化程度較低,各個圖書館之間缺乏統一的資源建設標準,導致資源整合難度較大,缺乏共建共享的機制,且各館自建的資源存在滯后和重復建設的問題,質量參差不齊。其次,精品資源的建設相對缺乏,大部分資源以迎合大眾口味為主,沒有進行深度挖掘。再次,資源推薦應基于用戶需求展開,但目前的推薦系統對用戶的需求缺乏有效的采集和分析機制,不能做到及時更新,尤其是大部分基層公共圖書館的資源推薦系統功能簡單,缺乏用戶信息反饋和采集的渠道,難以作出精準的需求預測。最后,用戶對資源推薦服務的認識不足,導致服務的覆蓋面有限。因此,本研究提出以下優化策略,以期進一步完善基于知識圖譜的圖書館智能化資源推薦系統服務。
4.1 基于知識圖譜完善資源的整合與挖掘
信息資源是資源推薦的基礎,圖書館作為信息資源的提供者和管理者,必須做好信息資源的整合和挖掘工作,對各個平臺上分散的信息進行有序化的集中處理,以實現資源利用效率的最大化。在資源整合與挖掘的過程中引入知識圖譜技術,能夠使圖書館的信息整合工作更系統化,形成結構化的信息資源體系。此外,還可以根據用戶畫像知識圖譜,分析用戶可能需要和感興趣的資源,對其進行深度加工和挖掘,打造優質的數據庫。同時,圖書館應基于用戶畫像知識圖譜對用戶進行分類,針對不同的用戶群體進行個性化資源推薦,引導用戶更好地利用資源。此外,圖書館還應積極引導各類用戶發揮自己的優勢,互相交流和共享信息,并將其中有價值的信息進行整合,避免資源的浪費和信息的分散。
4.2 基于知識圖譜的更新提供動態資源推薦
知識圖譜能夠通過推理和更新不斷深化與拓展,館藏信息資源的剔舊和更新、流通數據的變化,都會導致信息資源知識圖譜的更新。此外,隨著用戶的年齡、工作單位、研究專業和方向等基本信息的變化,以及用戶在使用圖書館服務的過程中產生的一系列動態行為數據,用戶畫像知識圖譜也會隨之變化。為進一步優化圖書館智能化資源推薦系統服務的用戶體驗,圖書館應站在用戶的角度,以用戶為中心,基于動態更新的知識圖譜實時更新服務內容和策略,結合智能技術和移動終端,實時提供動態的資源推薦服務。
4.3 發展可視化資源推薦
應用知識圖譜能夠實現資源推薦的可視化,增強其可解釋性。相較于傳統的知識庫,知識圖譜能夠對信息進行推理,發現知識之間的深層關聯。圖書館在推送資源的同時通過可視化的圖形或是詞云的形式向用戶展示知識圖譜,能夠讓用戶直觀地了解資源推薦的理由,明確資源的特征和屬性,幫助用戶判斷資源與自身需求的適配度,從而提高信息搜索的效率。此外,可視化的知識圖譜還能夠幫助用戶了解所推薦的資源與知識之間的關系及其在知識鏈中的位置,并通過知識圖譜挖掘其他相關的資源,實現知識的遷移和創新。
4.4 樹立品牌意識,加強宣傳培訓
為進一步擴大服務的覆蓋面,增強服務效能,圖書館應有意識地加強服務的資源推薦宣傳和對用戶的培訓。相較于傳統的書刊借閱服務,很多公共圖書館的用戶對資源推薦服務并不了解。圖書館應樹立品牌意識,打造資源推薦服務平臺和品牌,同時靈活運用新媒體、社交平臺等,進行系統化、品牌化的宣傳推廣。
為幫助用戶更好地利用資源推薦服務,應通過教育、培訓等方式提高用戶的信息素養,使用戶能夠更有效地利用信息資源。在“互聯網+”時代,可以引入Web2.0技術,搭建線上信息素養教育平臺,如美國肯特州立大學圖書館建立TRAILS平臺,對用戶的信息素養進行實時測評,并為用戶提供有針對性的幫助[13]。國內圖書館可以在資源推薦服務的框架內搭建類似的信息素養教育平臺,幫助用戶進一步提升信息素養,更好地使用圖書館資源推薦服務。
5 結 語
基于知識圖譜的資源推薦服務通過智能化篩選、過濾海量信息資源,并根據用戶畫像和信息檢索行為實時分析用戶信息需求,提升信息利用率和用戶滿意度。在我國數字文化建設迅速發展的今天,基于知識圖譜的資源推薦系統將碎片化的數字資源進行有序整合并推送給目標用戶,其在一定程度上打破了時空的限制,為用戶提供了一站式的綜合信息服務,進而提高了圖書館的服務效能,實現了圖書館知識服務的數字化轉型。相較于傳統的圖書館服務,基于知識圖譜的資源推薦服務注重資源的深度挖掘和不同用戶的實際需求,能夠使圖書館為用戶實現更精準的信息服務,從而推動圖書館服務的供給側結構性改革,這也是圖書館提高服務效能、滿足用戶個性化和精準化需求的有效途徑。在信息服務與技術不斷融合的時代背景下,圖書館界應從宏觀視角出發,針對信息服務存在的問題,將圖書館信息服務的創新與知識圖譜技術相結合,利用知識圖譜服務的精準化供給更好地為公共文化服務賦能。
猜你喜歡
軍事文摘(2022年19期)2022-10-18 02:41:14
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
印刷工業(2020年4期)2020-10-27 02:45:52
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
中國交通信息化(2017年4期)2017-06-06 07:21:52
資源再生(2017年3期)2017-06-01 12:20:59
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
