基于粒度神經網絡的大數據標簽分類算法研究
2023-06-01 13:43:08時慶濤
計算機仿真 2023年4期
張 倩,吳 瓊,時慶濤
(長春工業大學人文信息學院,吉林 長春 130000)
1 引言
隨著信息技術研究的不斷深入,人們獲取大數據的方式越來越多,成本也越來越低,使得大數據的形式多種多樣,來源也無法確定。因此,對大數據標簽的分類已經遠遠超出了現有系統的正常處理極限。不僅如此,對于大數據的標簽分類不同于小規模數據分類,其具有大量的的深度知識,信息含量偏高。為此,對于大數據標簽如何實現高效分類成為了當前研究熱點之一。
文獻[1]利用樸素貝葉斯算法,以Map Reduce和Apache Spark框架為依據,構建了分布式樸素貝葉斯文本分類模型。在該模型中實現對樣本數據集的分類。該算法中將Map Reduce的并行優勢運用的非常到位,最終直接在分類結果中找出最大值所對應的文本標簽即可。但是在該算法中,文本數據的復雜程度較高且訪問量較大,在后續的計算過程中將會浪費大量的時間,因此,不利于大范圍推廣使用;文獻[2]以深度自動編碼器為基礎,展開對多標簽分類的研究。利用軌跡計算算法對網絡中不同節點之間的結構相似性進行研究,并將最終結果輸入到深度自動編碼器中;然后對網絡中所有節點的領域信息進行聯合優化處理,使得網絡展現出高度非線性的特性,最后,再利用支持向量機實現對多標簽的分類。該算法充分考慮了節點之間的相似性,分類效果比較明顯,但是計算量巨大,過程較為繁瑣,分類實時性能較低。
綜合考慮以上算法的優缺點,本文將粒度神經網絡引入其中,提出了一種新的大數據標簽分類方法。首先,通過對大數據的數據結構以及先驗信息進行處理,得到大數據標簽的矢量長度值,進而展開對大數據標簽的屬性特征分析。然后通過大數據信息重排序列,完成對大數據標簽的屬性分類,由此構建大數據采樣序列的擬合模型。將粒度神經網絡應用其中,通過設置合理的隱含層節點數以及主要的參數值,使輸出結果為理想值。最后通過建立一個無監督學習過程,選取合適的全局適應度與標簽屬性適應度,實現對大數據標簽的分類。
2 大數據結構及先驗信息處理
2.1 大數據的存儲模型
大數據的存儲數據庫常以交互信息網絡[3]的形式存在,存儲數據庫主要由三層構成:I/O輸入/輸出、USB接口和磁盤層,三層模塊協同工作,完成對大數據的存儲以及交互。
在大數據存儲庫模型中,假設存儲數據庫的一個分支為Ti=(i=1,2…,n),其中,n表示分支數量,其長度用Qi(Qi≥1)來表示,由此可得到帶有支持度值的所有存儲節點集合。對于主支干節點,只能進行一次支持度計算和集合操作,掃描分支還可得到與之對應的B的節點集合{B,D}{B,A}{…},對于大數據存儲庫中的頻繁項集D,在設置大數據標簽特征分類匹配條件時,要充分考慮標簽特征的分布函數,其結果對大數據標簽的分類尤為重要。大數據標簽分布函數計算公式如式(1)所示:
F(Gj,i)=w1·R(Gj,i)+w2·(1-dis(Gj,i))
(1)
其中,i表示大數據標簽在特征采樣過程中所占用的時間序列節點數;w1表示簇頭節點所對應的加權權重值w;w2表示大數據標簽分類節點所對應的加權權重值;R(Gj,i)表示大數據標簽在存儲數據庫內遞歸特征;dis(Gj,i)表示兩個大數據標簽在存儲庫內的歐式距離,可用式(2)表示為
dis(Gj,i)=[x(t0),x(t0+Δt),…,x(t0+(K-1)Δt)]
(2)
式中,x(t0)表示存儲庫內,對大數據進行采樣處理的時間序列;K為存儲數據庫內列空間的窗函數。
根據式(2)的計算結果以及存儲數據庫的時間序列模型,可得到大數據標簽的時間序列采樣如式(3)所示
I={x(t0+iΔt)},i=0,1,2,…,N-1
(3)
其中,N表示大數據標簽的矢量長度。
通過上述對大數據存儲結構模型的分析,以及對大數據標簽的矢量長度值[4]進行計算,可展開對大數據標簽屬性特征的劃分,進而實現對大數據標簽的分類計算。
2.2 大數據的標簽屬性特征劃分
通過高維相空間重構模型可對存儲數據庫中的大數據執行信息重排操作,利用因子分析法,對大數據標簽時間序列的主成分概率密度置信域進行分析計算,如式(4)所示

(4)
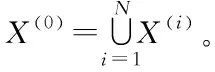
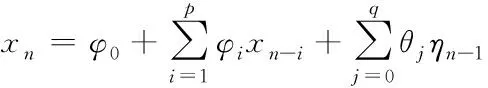
(5)
式中,{ηi}的均值始終為0,σ2表示大數據標簽標準正態分布[5]的方差值,φ0,φ1,φ2,…,φp統稱為大數據采樣時間序列的關聯系數,θ1,θ2,…,θq為滑動時間窗口的平均系數值。根據上述計算,即可完成對大數據標簽的屬性特征劃分,結合粒度神經網絡,展開對標簽分類算法的研究。
3 基于粒度神經網絡的大數據標簽分類算法
3.1 粒度神經網絡結構
粒度神經網絡主要由輸入層、隱含層和輸出層三個層次構成,結構圖如圖1所示。
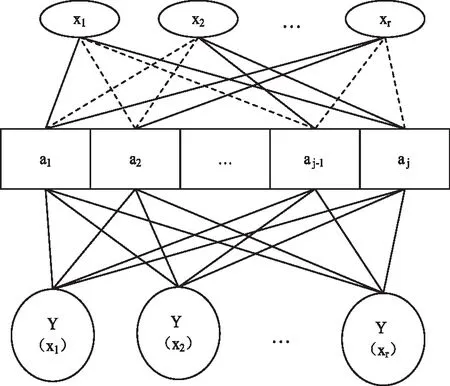
圖1 神經網絡結構圖
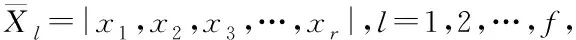
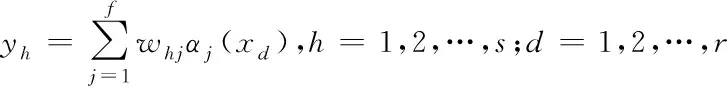
(6)
其中,yh表示粒度神經網絡中第h個節點的輸出結果;whj表示隱含層內節點j與輸出層內節點d之間連接的權重值;αj(xd)表示隱含層內與第j個節點所對應的基函數α。
通過對式(6)的計算結果可知,在粒度神經網絡中,隱含層內的節點信息將會影響到輸出層的輸出結果,為將影響控制在合理范圍內,可以通過設置隱含層內與節點對應的基函數,或者調整網絡結構中的一些主要參數值,使得各個節點之間的連接方式發生改變,選擇影響最小的連接方式即可。隨機給定一個輸入值,假設該值可以確保αj(xd)中非零節點個數最少,此時αj(xd)中大部分節點數都是零。在實際的運用中,對于隨機給定的輸入值,只要對隱含層內非零節點的輸出結果進行加權求和計算,即可得到理想數值。
3.2 大數據的主特征提取及標簽屬性計算
在對大數據主特征提取的多種方法中,多維標簽屬性的主成分分析法應用得最為廣泛,本文運用該方法進一步研究大數據標簽的屬性特征,本文對該方法做了部分改進,提出了一種基于粒度神經網絡的大數據標簽分類方法。通過粒度神經網絡實現對大數據聚類中心[7]的自動更新和標簽分類屬性識別。在標簽分類屬性識別過程中,在領域L內t時刻下對大數據標簽的分類進行學習迭代計算,如式(7)所示

(7)
選擇合適的大數據標簽加權權重值進行計算,得到任意k時刻下大數據的信息流狀態為
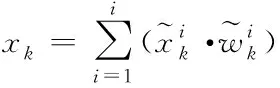
(8)
在高維相空間重構模型中,通過關聯規則協議[8]對大數據標簽進行屬性特征量的提取,再運用主成分分析法對大數據隱含的某些特征進行分析計算,最終結果即為大數據采樣時間序列在tn時刻下的狀態信息,如式(9)所示
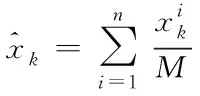
(9)
假設在粒度神經網絡中,對于大數據標簽的訓練樣本集中共有M個神經元信息,那么在計算大數據標簽中含有的主成分以及輸出結果時,可通過計算式(10)得到
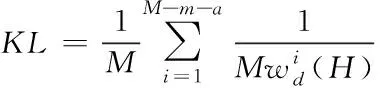
(10)
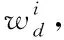
3.3 大數據標簽分類輸出
通過上文對大數據主成分進行特征提取[10],可結合粒度神經網絡,建立一個無監督學習過程,學習迭代式如式(11)所示
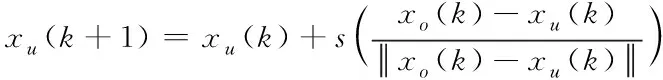
(11)
由于大數據標簽屬性[11]的全局適應度值低于標簽u屬性的適應度值,因此需要對粒度神經網絡的學習范圍重新進行調整,使二者滿足適應度條件函數。

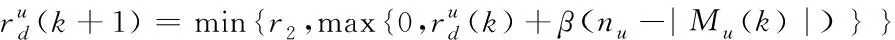
(12)
其中,β表示大數據在全局分類搜索[12]中的關聯特征變量,nu表示學習迭代計算式中的適應度值。當學習迭代次數達到最理想狀態時,粒度神經網絡對于大數據的分類學習收斂速度達到最優,輸出的加權權重值滿足式(13)條件
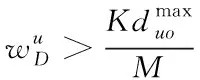
(13)
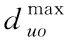
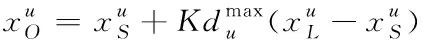
(14)

4 仿真研究
為驗證本文方法在大數據標簽特征匹配、分類效果以及系統運行效率方面是否具有可行性,與文獻[1]、文獻[2]方法展開了對比仿真。仿真平臺的硬盤主頻為2.89GHz,系統運行內存為8GB,仿真軟件使用的是比較常用的Matlab7。大數據樣本集來自數據存儲庫B400C20D40,覆蓋區域為200×200,共有452365條大數據信息。
通過上述對仿真環境的設定,將三種方法分別應用其中,對大數據標簽的分類性能在系統運行效率方面進行對比。大數據的采樣頻率為450kHz,以時寬Δ=15s來計算大數據標簽的特征匹配投影值,實驗結果如圖2所示。

圖2 本文方法大數據標簽特征匹配投影值
從圖3中可知,運用本文方法對大數據標簽特征進行匹配,展現出了較優的特征提取性能,隨著實驗時間的不斷推移,本文方法在20s處出現了投影匹配值峰值。以此特征匹配結果在后續對大數據標簽進行分類時,可起到很好的推動作用。運用本文方法進行特征分類,結果如圖2所示。

圖3 本文方法分類效果
從圖3中可以看出,采用本文方法對大數據標簽進行特征提取后,再進行分類,效果是非常明顯的。這樣不僅可以有效避開各類數據之間的特征融合和交叉,而且將一些冗余特征信息剔除掉,在一定程度上提高了標簽分類的準確性。
同時,為了驗證本文方法與文獻[1]、文獻[2]方法在系統運行效率上的性能對比,將大數據標簽分類的能量開銷作為對比依據,展開了仿真,三種方法實驗結果如圖4所示。
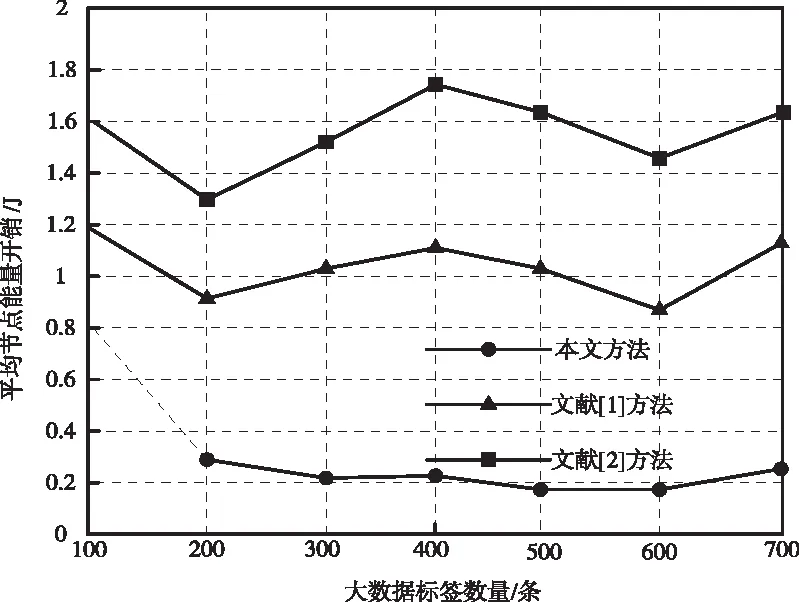
圖4 三種方法能量開銷對比圖
從圖4中可以看出,本文方法較其它兩種方法相比,所使用的能量開銷最低,說明本文方法在確保分類準確性的同時花費的系統開銷最小,以此證明了運用粒度神經網絡對大數據標簽進行分類是非常有效且可行的一種方法。
5 結論
針對傳統方法在對大數據標簽分類過程中存在計算開銷大、分類效率較差等問題,本文提出新的大數據標簽分類算法。首先,計算大數據標簽的矢量長度值,確保后續對標簽屬性的分析更精準。然后,通過主成分分析法對大數據的先驗特征以及大數據標簽的屬性特征進行分析計算。最后將粒度神經網絡應用其中,對標簽屬性的加權權重值加以控制,結合大數據標簽屬性特征向量,完成對大數據標簽的分類。通過搭建仿真平臺,將傳統方法與本文方法進行對比,驗證了本文方法在花費最少系統能量開銷的前提下,得到了較高的分類性能和特征匹配值,適合大范圍推廣使用。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
