污水處理曝氣系統優化控制仿真研究
2023-05-31 09:14:02孫宏存于廣平
計算機仿真 2023年4期
孫宏存,于廣平,李 崇,劉 堅
(1. 沈陽化工大學信息工程學院,遼寧 沈陽 110142;2. 廣州中國科學院沈陽自動化研究所分所,廣東 廣州 511458)
1 引言
污水處理中的活性污泥法是一種污水生化處理方法,曝氣系統是極其重要的控制部分 ̄[1],主要是向污水處理的好氧池中通入氧氣,曝氣量直接影響污水中溶解氧的濃度,從而影響出水水質的好壞,污水處理系統具有耦合性強[2],大滯后等特性[3],精準曝氣一直以來都是污水處理過程中的一個難點,魏偉等針對溶解氧的控制,設計了一種有限時間自抗擾控制,來解決污水處理過程中的不確定性,對溶解氧調控取得一定效果[4]。栗三一等提出污水處理決策優化控制方法,對出水氨氮和出水總氮峰值進行抑制并降低能耗[5]。項雷軍等提出了自適應補償能力的輸出反饋預測控制系統,當溶解氧濃度測量不準確時可通過反饋系統進行補償調整[6]。周紅標針對污水處理過程提出了基于自組織模糊神經網絡的控制方法,在實際工況的動態變化下,溶解氧濃度的設定值可以被精確的跟蹤,有著穩定的控制[7]。喬俊飛等提出一種基于知識的優化控制方法,采用記憶多目標優化算法構建環境變量參數與最優解之間的知識模型,算法的收斂性提高以獲取更高質量的解[8]。
以上研究對污水處理溶解氧濃度的設定值優化和跟蹤控制都取得顯著的成效,但是未考慮污泥狀態及出水的平穩性等問題,對設定值優化未形成閉環的反饋系統,針對這一問題本文在建立預測模型時考慮多因素影響,設定值優化后設計評估反饋系統,不斷更新模型參數,使溶解氧設定值趨于最優。
2 污水處理曝氣過程優化
污水處理曝氣過程優化是通過優化目標函數產生優化設定值,采用BSM1仿真平臺進行仿真[9],評估出水水質,對系統進行反饋。主要包括建立基于BP神經網絡[10-12]的能耗和出水水質模型;研究關于能耗和出水水質的多目標優化方法[13,14];建立對于復雜入水工況的識別[15]、出水評估反饋系統。
首先根據BSM1模型提供的三類歷史數據,通過搭建的simulink模型對三類數據進行仿真,采用BP神經網絡分別以入水流量、組分、溶解氧設定值與能耗和出水氨氮建立兩個模型。以能耗最小為優化目標,以出水氨氮值作為約束條件。用粒子群算法尋找出該數據對應的最優溶解氧設定值。將每一類入水工況與溶解氧設定值存入工況庫中。對于新的輸入數據通過高斯混合模型[16]與已有類別進行比較,通過歐氏距離匹配得到相應的操作參數。若經高斯混合模型比較相似度未達預設閾值,則將該組數據作為新的一類,仿真、尋優得到溶解氧設定值,最后用該設定值通過仿真平臺驗證,評估出水水質指標對模型數據庫進行更新。系統框圖如圖1所示。
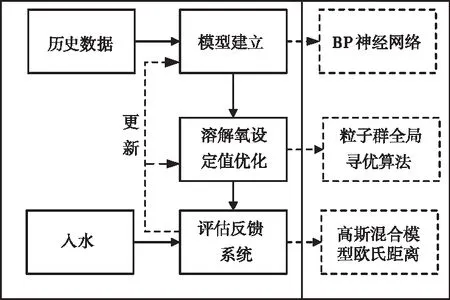
圖1 系統框圖
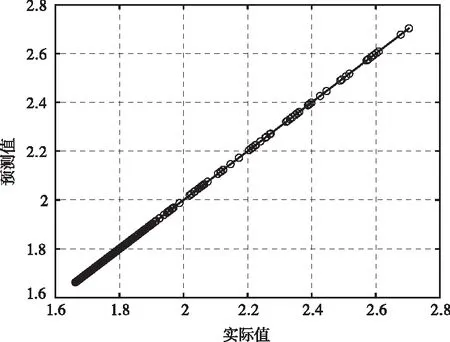
圖2 氨氮值預測模型效果圖
2.1 BP神經網絡能耗和出水水質模型
考慮到污水處理過程出水水質指標和操作變量之間關系具有強非線性、不確定性、機理不清的特點,通過機理建模來預測出水水質的指標難以保證其模型的準確性可靠性。因此引入能耗和出水水質模型代替污水處理系統對能耗和水質的計算。
BP 神經網絡是一種基于誤差反向傳播算法訓練的多層感知器前饋網絡,不需要了解輸入與輸出之間的關系。模型通過簡單的非線性函數多次擬合后,實現高維度非線性的精確映射[17],具有較強的自適應能力,根據活性污泥1號模型(ASM1)提供的三類歷史數據,本文采用BP神經網絡分別以入水流量13種入水組分及曝氣池3、4、5池溶解氧設定值為輸入,出水能耗和出水氨氮為輸出建立兩個預測模型。采用Trainlm函數、Levenberg-Marquardt算法、隱含層2層15-20、激活函數tansig、函數訓練次數1000、學習效率0.01、收斂誤差1e-7。
氨氮值預測結果如2所示,mse=2.48*10-8,能耗預測結果如圖3所示,mse=1.4*10-3。

圖3 能耗預測模型效果圖
2.2 溶解氧設定值優化
一般粒子群算法是通過模擬鳥群覓食行為的一種全局優化進化算法,該算法在計算過程中保留了最優全局位置和粒子已知的最優位置兩個信息[18]。對較快收斂速度以及避免過早陷入局部最優解產生了不錯的效果。在各個領域得到了廣泛的應用[19,20]。
本文在標準的粒子群算法的基礎引入了慣性因子,在算法的收斂性能有了很大的改善,在PSO算法中,在一個目標搜索范圍為D維的空間中,初始化M個粒子,組成一個種群T={X1,X2,…,XM}Xi=(xi1,xi2,…,xiD),i=1,2,…,M,表示第i個粒子在D維空間的位置,vi=(vi1,vi2,…,viD),i=1,2,…,M,表示第i個粒子的速度。第i個粒子到目前為止所搜索到的個體極值表示為Pi=(Pi1,Pi2,…,PiD),i=1,2,…,M,在整個粒子群中,所有粒子到目前為止所搜索到的全局極值表示為Pg=(Pg1,Pg2,…,PgD),g∈{1,2,…,M}。每個粒子代表一組溶解氧的設定值(DOset),粒子每更新一次適應度就隨之更新一次,在此過程中適應度值是由入水數據和粒子對應的DOset通過能耗模型計算出能耗,由于出水水質中有機物濃度越接近約束的最大值,污水處理過程能耗越低,且出水水質中氨氮值最容易超標,因此利用入水數據和粒子對應的DOset通過氨氮模型計算出的出水氨氮值作為約束值。則第i個粒子就是按照下面的式(1)和(2)來更新自己的速度和位置。

(1)

(2)
式中,i=1,2,…,M,M是群體中的粒子數;K是迭代次數;c1和c2為學習因子,r1,r2是均勻分布于[0,1]之間的兩個隨機數。ω為慣性因子。取晴天雨天暴雨天各4天,采樣時間為15分鐘共1152條數據進行溶解氧設定值尋優,粒子群相關參數:種群個體數60、迭代次數1000、慣性因子0.5~0.8、學習因子0.5,圖4、圖5、圖6分別為晴天、雨天、暴雨天三個好氧池優化后的溶解氧設定值。

圖4 晴天溶解氧設定值
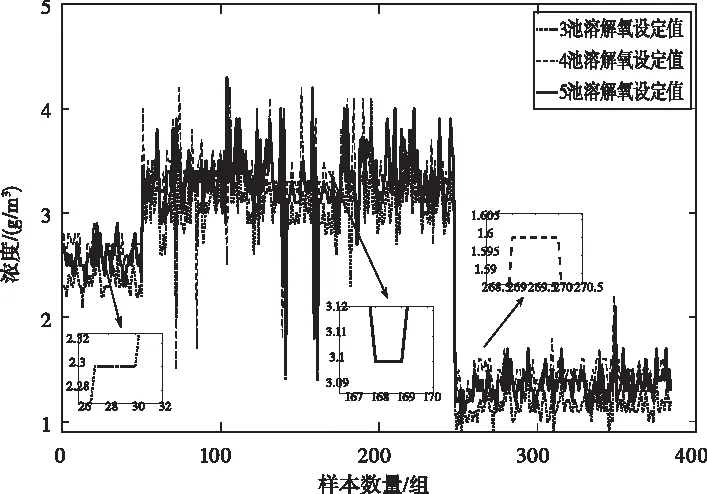
圖5 晴天溶解氧設定值

圖6 晴天溶解氧設定值
2.3 評估反饋系統
評估反饋系統包括入水工況識別和數據庫更新,入水數據通過高斯混合模型進行分類,采用歐氏距離進行入水工況匹配,結合Benchmark的污水處理仿真平臺BSM1對數據進行仿真驗證,通過對比仿真結果與出水水質標準進行數據庫更新。評估反饋系統框圖如圖7所示。

圖7 評估反饋框圖
圖中新工況A表示一組新的入水數據,其中參考變量包括入水的流量和13種組分,歷史工況庫1、2、3分別存放著晴天雨天暴雨天三類入水流量組分及每個池子的溶解氧濃度,d1、d2、d3為高斯混合模型所計算的概率,a為閾值(95%),操作變量為各個池子的溶解氧設定值。
混合高斯模型的數學模型為式(3)
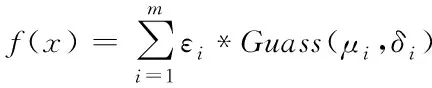
(3)

分類后計算當前入水工況與該歷史工況庫中的各工況之間的相似度。采用歐氏距離進行相似度計算記當前工況為T=(t1,…,ti,…tn),其中ti是第i個輸入屬性的歸一化特征值,Xk為歷史工況庫第k條入水工況,計算T與Xk的相似度如式(4)所示

(4)
k=1,2,…,p通過計算比較p個相似度,分別為S1,…,Sp,選相似度最高的一組,讀取操作參數。
本文的評估標準是采用Benchmark基準給出的出水水質指標(EQ)及曝氣能耗(AE)。
出水水質指標計算如式(5)所示:
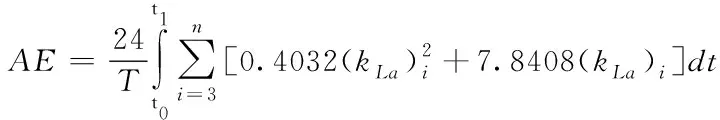
(5)
曝氣能耗計算如式(6)所示:

(6)
SS,COD,SNKj,e,SNO,e,BOD5,e為5種出水指標,Qa、Qr、Qw分別表示內回流流量、外回流流量、污泥排放量;Kla為氧轉移速率,表征好氧池的曝氣情況;T=4days,Qe為出水流量。
3 仿真驗證
為了更加有效地模擬和評估污水處理過程曝氣過程中使用的控制和優化策略,本文采用仿真基準模型 1號進行驗證,BSM1 主要由生化反應池和二次沉淀池構成,生化反應池共有5個模塊,2個厭氧區,主要進行反硝化反應,3個好氧區,主要進行硝化反應。配合內外回流,保證了曝氣池中固體懸浮物的濃度,維持了活性污泥系統的穩定性。取晴天雨天暴雨天各四天,采樣時間為15分鐘共1152條數據作為驗證數據,當入水數據進入系統后,通過優化得到得溶解氧設定值(下文統稱優化后)與BSM1的原系統(下文統稱優化前)Kla3=Kla4=10h-1,DO5set=2mg/L仿真結果進行比較。BSM1系統框圖如下圖8所示。
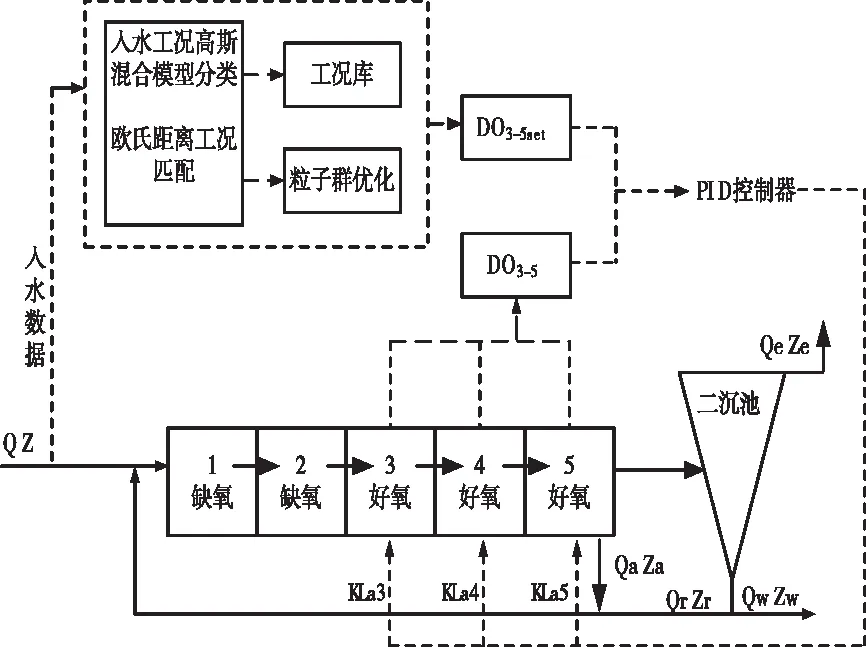
圖8 BSM1系統圖
優化前后出水水質對比圖如圖9、圖10、圖11、圖12所示。

圖9 出水氨氮濃度對比圖

圖10 出水COD濃度對比圖

圖11 出水BOD濃度對比圖

圖12 出水總氮濃度對比圖
出水水質各指標如表1所示。

表1 兩系統出水水質
兩系統的曝氣性能指標如表2所示。

表2 兩系統污水處理性能
由圖表信息可知經優化后晴天在出水水質降低2%的同時風機能耗降低18%左右,雨天在水質降低1%風機能耗上升不到3%,暴雨天在水質稍有上升的情況下風機能耗降低4%。
4 結語
與傳統的污水處理曝氣過程溶解氧控制相比,基于數據驅動的優化控制方法在復雜多變的入水工況下可以更精準的控制溶解氧的濃度。該方法具有以下特點:1)采用BP神經網絡建立預測模型,考慮綜合因素的干擾,非線性預測能力強,魯棒性好,可快速預測出水。2)粒子群優化算法,算法精度高,收斂速度快,避免算法停滯現象。3)具有評估反饋系統有不斷更新模型能力,使結果精度更高。最終經驗證與原始數據對比得出,在出水水質變化不大的情況下總能耗降低了7%左右。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環境(2023年5期)2023-06-30 01:20:01
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
當代水產(2019年1期)2019-05-16 02:42:04
光學精密工程(2016年6期)2016-11-07 09:07:19
