基于LDA的中小企業(yè)科技需求關(guān)鍵信息提取方法
2023-05-30 10:48:04張震
電腦知識與技術(shù) 2023年2期
張震


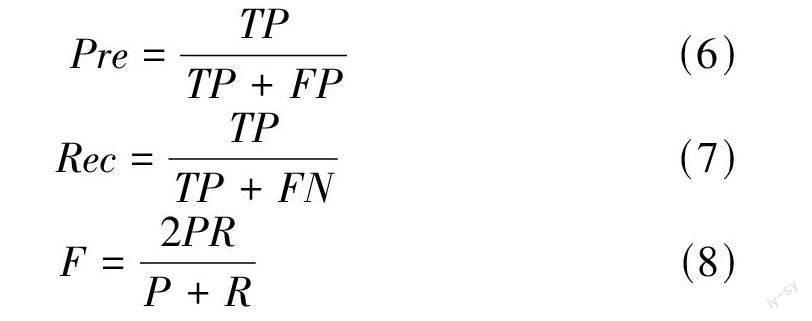
關(guān)鍵詞:LDA 主題模型;文本預(yù)處理;關(guān)鍵詞提取技術(shù);企業(yè)科技需求
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2023)02-0016-04
1 概述
中小企業(yè)在我國的經(jīng)濟發(fā)展中的地位十分重要,在促進經(jīng)濟發(fā)展的同時,更能維護社會穩(wěn)定。在協(xié)同創(chuàng)新模式下,中小企業(yè)的核心技術(shù)升級和企業(yè)綜合發(fā)展的壓力隨之而來。中小企業(yè)的不足之處在于其高技術(shù)人才儲備量不足,科學技術(shù)團隊發(fā)展不夠先進,在人才競爭方面處于劣勢,當遇到企業(yè)科技需求問題自身不能更好解決時,往往通過企業(yè)家自身的社會關(guān)系尋找相關(guān)的專家或團隊來解決難題,但最終成效往往取決于企業(yè)家自身所擁有的資源水平。所以,科技需求關(guān)鍵詞的提取技術(shù)與科技協(xié)同創(chuàng)新平臺相結(jié)合,將中小企業(yè)需求信息精準推薦給高校、研究所和科研團隊,搭建企業(yè)與高校、研究所、科研團隊所組成的科技協(xié)同,使中小企業(yè)的科技需求問題得到更好的解決方案[1]。
2相關(guān)研究
針對企業(yè)需求方面,文獻[2]分析了在企業(yè)建模過程中使用機器學習方法是可行的,王學娟[3]提出了GM(1,1)模型和BP人工神經(jīng)網(wǎng)絡(luò)組合的企業(yè)人力資源需求預(yù)測模型來解決企業(yè)人力資源需求問題,但沒有與高校或科研團隊結(jié)合。李瑩[4]通過主題模型的應(yīng)用構(gòu)建企業(yè)技術(shù)需求文本的向量空間模型對專家進行匹配,重點針對專家端的推薦和分析展開。Kang[5]等人結(jié)合潛在Dirichlet分配主題模型(Latent Dirichlet Allo?cation,LDA)和聚類算法,通過對技術(shù)類別進行分類后確定最佳匹配的團隊,以此來選擇產(chǎn)學研的合作伙伴,但忽視了企業(yè)方面的分析。綜上所述,研究者對于企業(yè)需求文本特征的研究較少,需求大多為非結(jié)構(gòu)化的中文文本,導致特征提取的精度也相對較低。主題模型方面,詞頻逆文檔(Term Frequency - InverseDocument Frequency, TF-IDF)模型是最早的文本概率模型之一[6]。在企業(yè)科技需求的關(guān)鍵詞提取上的不足之處在于該模型僅以詞頻來判斷是否為關(guān)鍵詞,在精度上會出現(xiàn)誤差。經(jīng)過潛在語義索引(Latent Seman?tic Indexing, LSI)、概率潛在語義索引(Probability La?tent Semantic Indexing, PLSI)等模型的優(yōu)化,Blei等人[7]在此基礎(chǔ)上提出了LDA模型,該模型可以挖掘不同主題下的關(guān)鍵信息,避免語義重復(fù),因此更受廣泛應(yīng)用。
3模型構(gòu)建
3.1 文本獲取
數(shù)據(jù)來源于課題項目平臺后臺數(shù)據(jù)和科學家在線網(wǎng)絡(luò)爬蟲數(shù)據(jù),包含需求標題、詳細需求、限定時間、基本預(yù)算情況等信息。數(shù)據(jù)標題和詳細需求是企業(yè)需求關(guān)鍵信息提取的重要內(nèi)容,因此利用標題和詳細需求將文檔合并成一個文檔,既能方便掌握需求主題信息,又能降低模型的時間復(fù)雜度。
3.2 預(yù)處理
由于文本的字詞間無明顯區(qū)分符號,所以在預(yù)處理上應(yīng)進行文本的分詞,文章主要運用Python語言版的Jieba分詞器和Jieba庫中的默認詞性標注器進行標注。停用詞通常是文本中出現(xiàn)頻率高,卻影響關(guān)鍵詞提取效果的一類詞語,停用詞不但不利于表現(xiàn)文本所表達的主要內(nèi)容,且給文本特征選擇和提取帶來干擾[8]。文章采用基于停用詞表的停用詞過濾方法,停用詞表使用通用停用詞表和專有停用詞表,避免專業(yè)術(shù)語上不準確的停用詞標記[9]。
4實驗
4.1 實驗環(huán)境
實驗在內(nèi)存為8G,系統(tǒng)為Windows 10的PC機上進行。訓練及測試使用Python 3.7版本,調(diào)用gensim 庫中的lda 包對LDA 算法實現(xiàn)。實驗數(shù)據(jù)共計300 條,其中爬蟲200條,采用Python第三方模塊requests 抓取數(shù)據(jù),通過循環(huán)翻頁,獲取網(wǎng)站的每頁項目列表,使用正則表達式抓取每個項目列表對應(yīng)的主頁網(wǎng)址,進一步檢索并抓取每個項目主頁上的項目標題和項目內(nèi)容描述,并保存在Excel表格中。經(jīng)過數(shù)據(jù)預(yù)處理清洗后,將數(shù)據(jù)重新編號,并劃分200 條數(shù)據(jù)作為訓練集,主要訓練模型主題數(shù)k,另外100 條作為測試集,作為評價本文算法的依據(jù)。針對數(shù)據(jù)集,每個文檔采用10 人手動提取關(guān)鍵詞,按照提取關(guān)鍵詞的頻率高低排序得出手動標注的關(guān)鍵信息。除此之外,基于相同的測試集,采用本文算法、TFIDF模型和傳統(tǒng)的LDA 模型三種算法做對比實驗。
4.2 評價標準
從關(guān)鍵詞的定義和內(nèi)在意義方面來講,文本中提取關(guān)鍵詞的評價標準是確定關(guān)鍵詞本身是否符合文檔的實際主題和語義。從關(guān)鍵詞的科研角度和學術(shù)角度來講,評價標準為所提取關(guān)鍵詞的結(jié)構(gòu)是否穩(wěn)定,是否有利于對文本信息更好地挖掘[14]。當前多數(shù)使用精準率Pre(Precision)、召回率Rec(Recall)和二者綜合值F 值(定量評價)對主題模型的效果進行評價,Pre、Rec和F值的計算公式見公式(6)、(7)和(8)。其中TP 表示預(yù)測為正,實際為正,F(xiàn)P表示預(yù)測為正,實際為負,F(xiàn)N 表示預(yù)測為負,實際為正。因此,精準率Pre 表示抽取的正確關(guān)鍵詞占提取出的關(guān)鍵詞條數(shù)的比例,召回率Rec表示抽取的正確關(guān)鍵詞占樣本中手動標注關(guān)鍵詞的比例,F(xiàn)值為二者的綜合評價。
4.3 實驗結(jié)果及分析
實驗數(shù)據(jù)集的中小企業(yè)科技需求共計六個方向,模型參數(shù)主題數(shù)k 影響著LDA模型和本文算法的實驗精度,而TF-IDF算法的精度主要受關(guān)鍵詞數(shù)num的影響。因此,實驗利用控制變量的原則,對相關(guān)數(shù)據(jù)進行實驗。表1是在k=3,以及每個主題的關(guān)鍵詞為2個的條件下完成的(即num = 6),相應(yīng)的TF-IDF算法關(guān)鍵詞數(shù)num =6,保證實驗每個模型的關(guān)鍵詞數(shù)量為6個。為了便于比對和計算,每個需求文檔的人工手動標注的關(guān)鍵詞數(shù)為5。超參數(shù)α 和β 的值取α=50/k,β=0.01。本實驗在上述數(shù)據(jù)集和參數(shù)的基礎(chǔ)條件下完成。
根據(jù)表1和圖2實驗結(jié)果可以看出,本文提出算法在數(shù)據(jù)集的六個研究方向的F值依次為0.59、0.69、0.62、0.59、0.60、0.68。本文算法的每個研究方向的F值在數(shù)值上均高于另外的兩個算法。并且,表4-1也顯示了本文算法的Pre、Rec值也高于另外兩種算法。所以直接表明了本文算法優(yōu)于常用的TF-IDF和傳統(tǒng)的LDA算法。在實際應(yīng)用中,LDA模型將不同主題之間的關(guān)鍵詞提取出來,在一定程度上解決了語義重復(fù)和多義性的問題,對次要主題和無關(guān)語義有很好的過濾作用。
此外,主題數(shù)k 大小一方面決定了關(guān)鍵詞提取的數(shù)量,在另一方面對提取效果也有影響。本文設(shè)置k的取值在1至5之間,每個主題下的關(guān)鍵詞數(shù)為2的情況下進行實驗,保證關(guān)鍵詞的提取數(shù)量和質(zhì)量,從而訓練出k 的最佳值。圖3是本文算法與傳統(tǒng)的LDA模型的F值的整體變化情況,本文算法在1至5之間是優(yōu)于傳統(tǒng)的LDA模型,但是隨著主題數(shù)k 的增大,兩種算法的F值逐漸接近,且F值出現(xiàn)先上升后緩慢下降的趨勢。原因在于隨著k 的增大,模型中抽取的關(guān)鍵詞數(shù)越大,即公式(6)中的FP逐漸增大,因此精準率Pre在逐漸降低,F(xiàn)值也在不斷降低,本文算法在K =3時效果最好。
5結(jié)束語
本文針對中小企業(yè)的人才不足和科學技術(shù)不夠先進的問題,從需求文本入手,提出一種融合多特征加權(quán)的LDA算法,對中小企業(yè)科技需求關(guān)鍵詞進行提取。關(guān)鍵詞提取技術(shù)與科技協(xié)同創(chuàng)新平臺相結(jié)合,將企業(yè)需求精確表達,并爭取匹配到專家、高校或科研團隊,在一定程度上能夠促進產(chǎn)學研聯(lián)動。該算法與傳統(tǒng)算法相比,精度方面有明顯的提升。就本研究而言,今后將從以下幾個研究方向進行改進:首先是對LDA主題模型進一步改進和完善;其次是對中小企業(yè)科技協(xié)同平臺的運行體系機制進行進一步深化和完善;最后可以將此模型進行其他應(yīng)用領(lǐng)域的推廣,例如高校信息模型,專家信息模型等。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
少兒科學周刊·兒童版(2017年9期)2018-03-15 15:00:11
兒童故事畫報·發(fā)現(xiàn)號趣味百科(2017年4期)2017-06-30 12:41:53
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
兒童故事畫報·發(fā)現(xiàn)號趣味百科(2016年6期)2016-08-19 06:35:19
太空探索(2016年5期)2016-07-12 15:17:55
兒童故事畫報·發(fā)現(xiàn)號趣味百科(2015年10期)2016-01-20 00:47:36
