基于BERT 模型的勘探開發(fā)資料關(guān)鍵信息智能提取
2023-05-18 02:47:10李新鋒黃凌宇崔立敏倪子顏中海石油中國(guó)有限公司深圳分公司廣東深圳518000
化工管理 2023年14期
李新鋒,黃凌宇,崔立敏,倪子顏 (中海石油(中國(guó))有限公司深圳分公司,廣東 深圳 518000)
1 基于BERT 模型的關(guān)鍵信息提取
BERT 預(yù)訓(xùn)練語(yǔ)言模型是一種基于Transformer結(jié)構(gòu)的預(yù)訓(xùn)練網(wǎng)絡(luò)[1]。根據(jù)給定的輸入文本,學(xué)習(xí)利用上下文給出詞嵌入表示,分別計(jì)算關(guān)鍵向量、查詢向量和值向量,融合使用注意力機(jī)制,獲得當(dāng)前輸入文本與上下文語(yǔ)義的關(guān)系及其業(yè)務(wù)信息和含義,使用多頭注意力機(jī)制,動(dòng)態(tài)生成詞向量,不斷獲取更符合實(shí)際的向量表示。
1.1 提取流程
本文將勘探開發(fā)成果資料關(guān)鍵信息抽取的分析過程看作是文本分類任務(wù),對(duì)文本預(yù)處理、分詞、模型構(gòu)建和分類,結(jié)合BERT 預(yù)訓(xùn)練語(yǔ)言模型實(shí)現(xiàn)關(guān)鍵信息提煉抽取。本文模型框架如圖1 所示。
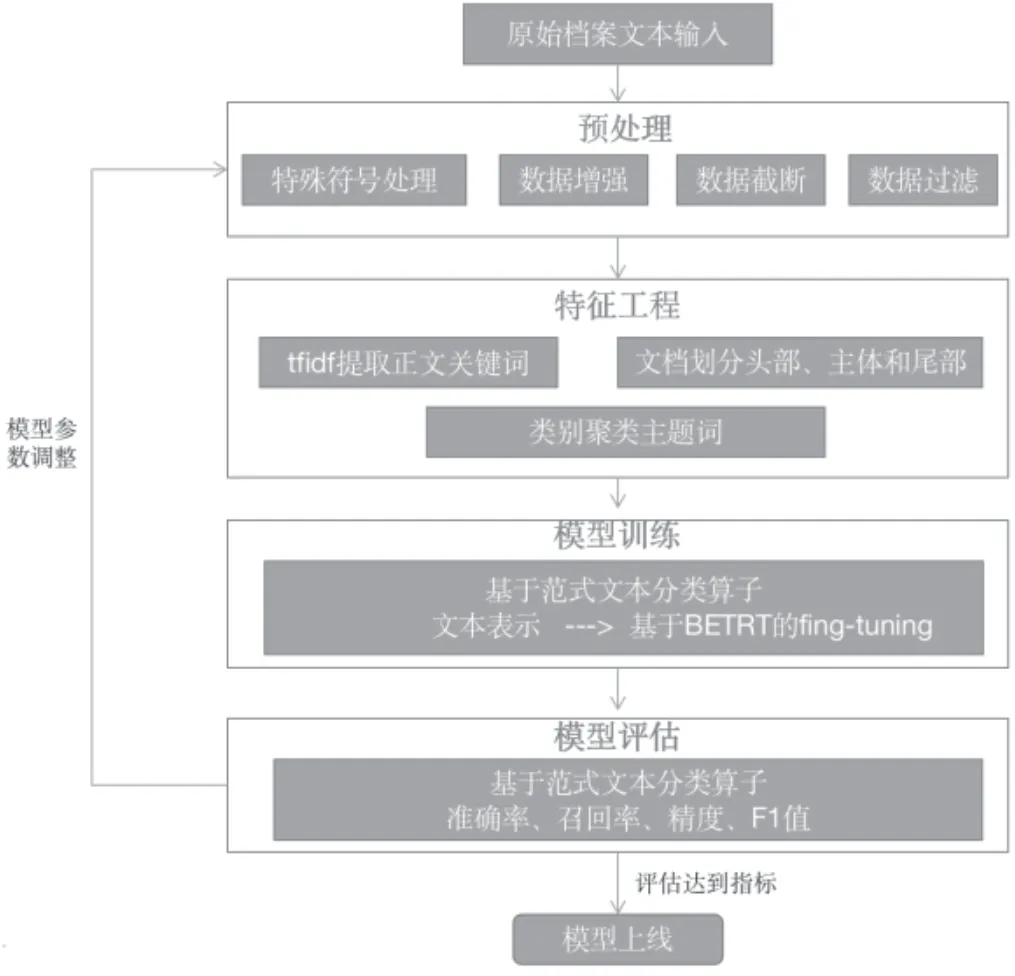
圖1 關(guān)鍵信息抽取模型框架
主要包含三個(gè)部分:(1) 數(shù)據(jù)輸入層:為了分詞準(zhǔn)確,對(duì)數(shù)據(jù)預(yù)處理過濾,在分詞后停用詞處理。根據(jù)資料特性,將文本劃分為頭部、主體和尾部三個(gè)結(jié)構(gòu),對(duì)每個(gè)結(jié)構(gòu)模塊分別處理;(2)模型構(gòu)建層:利用海油AI 平臺(tái)的文本分類算子逐層訓(xùn)練,結(jié)合業(yè)務(wù)含義拼接生成表征文本的向量,將結(jié)果輸入到網(wǎng)絡(luò)模型。樣本數(shù)據(jù)量不足時(shí),使用通用領(lǐng)域語(yǔ)料預(yù)處理和微調(diào)(Finetuning)技術(shù)防止過擬合[2],免去模型設(shè)計(jì)的復(fù)雜度及訓(xùn)練的久耗時(shí),通過生成的詞嵌入向量得到上下文信息,獲取文本中業(yè)務(wù)領(lǐng)域詞匯的語(yǔ)義特征最優(yōu)結(jié)果;(3) 結(jié)果輸出層:通過本模型獲取到的語(yǔ)義向量輸入歸一化指數(shù)函數(shù)(Softmax)以概率的形式展示多分類結(jié)果[3],實(shí)現(xiàn)對(duì)成果信息提取的設(shè)定。
1.2 模型訓(xùn)練
本文模型訓(xùn)練涵蓋以下六項(xiàng)內(nèi)容。
(1) 數(shù)據(jù)預(yù)處理。通過海油數(shù)據(jù)湖平臺(tái)獲取到油氣田勘探開發(fā)成果數(shù)據(jù),對(duì)部分成果資料中存在錯(cuò)誤或無(wú)實(shí)際意義的特殊字符以及停用詞,使用Python 語(yǔ)言編寫規(guī)則化表達(dá)式刪除無(wú)意義的符號(hào),確保數(shù)據(jù)清潔。
(2)數(shù)據(jù)增強(qiáng)。針對(duì)部分業(yè)務(wù)場(chǎng)景數(shù)據(jù)量較少的類別,模型很難學(xué)習(xí)到該業(yè)務(wù)類別的特征。面對(duì)數(shù)據(jù)集中存在長(zhǎng)尾數(shù)據(jù)場(chǎng)景,本文通過簡(jiǎn)單數(shù)據(jù)增強(qiáng)(easy data augmentation, EDA)方法對(duì)長(zhǎng)尾數(shù)據(jù)擴(kuò)充,在較少數(shù)據(jù)集上訓(xùn)練時(shí)可顯著提升性能并減少過擬合。EDA采用四種操作:
同義詞替換(synonyms replace,SR):隨機(jī)從句子中抽n 個(gè)詞( 不包括停用詞),然后隨機(jī)找出抽取這些詞的同義詞,用同義詞將原詞替換。例如將句子“這是我使用的勘探開發(fā)業(yè)務(wù)數(shù)據(jù)”替換成 “這是我所用的勘探開發(fā)數(shù)據(jù)”。SR 后句子大概率還是會(huì)有相同標(biāo)簽。
隨機(jī)插入(randomly insert,RI):隨機(jī)從句子中抽取1 個(gè)詞(抽取時(shí)不包括停用詞),然后隨機(jī)選擇一個(gè)該詞的同義詞,插入原來句子中的隨機(jī)位置,重復(fù)n次。例如將句子“這是我使用的勘探開發(fā)業(yè)務(wù)數(shù)據(jù)”改為“這是我勘探開發(fā)業(yè)務(wù)數(shù)據(jù)使用的”。
隨機(jī)交換(randomly swap,RS):在句子中,隨機(jī)交換兩個(gè)詞位置,重復(fù)這一過程n 次。例如將句子“這是我使用的勘探開發(fā)業(yè)務(wù)數(shù)據(jù)”改為“使用的我勘探開發(fā)業(yè)務(wù)數(shù)據(jù)這是”。
隨機(jī)刪除(randomly delete,RD):對(duì)于句子的每一個(gè)單詞,都有p 的概率會(huì)被刪除。例如將句子“這是我使用的勘探開發(fā)業(yè)務(wù)數(shù)據(jù)”改為“這是我勘探開發(fā)業(yè)務(wù)數(shù)據(jù)”。
(3)特征工程。從文本長(zhǎng)度角度來看,油氣田勘探開發(fā)成果資料文本屬于長(zhǎng)文本,且重要信息比較分散。為方便模型更好地學(xué)習(xí)到分類特征,本文將此類文本切分成頭部、主體和尾部三部分。其中頭部主要包含標(biāo)題、編寫人信息、文件編號(hào)等信息;尾部包含歸檔日期、歸檔提交公司名稱等信息;主體則包含了文本除了頭部和尾部之外的所有具有勘探開發(fā)業(yè)務(wù)情況的正文內(nèi)容。
對(duì)于地層研究、地質(zhì)設(shè)計(jì)和工程設(shè)計(jì)文檔等經(jīng)過切分后正文內(nèi)容依舊很長(zhǎng)的文本,本文決定采用TF-IDF(Term Frequency & Inverse Documentation Frequency)技術(shù)[4]進(jìn)行關(guān)鍵詞提取,在信息檢索領(lǐng)域,技術(shù)人員廣泛使用此算法計(jì)算權(quán)重。
對(duì)于某一特征值,權(quán)重越大表明該特征項(xiàng)較為重要,一個(gè)詞在特定的文檔中出現(xiàn)的頻率越高,說明它在區(qū)分該文檔內(nèi)容屬性方面的能力越強(qiáng);一個(gè)詞在文檔中出現(xiàn)的范圍越廣,說明它區(qū)分文檔內(nèi)容的屬性越低,選擇那些對(duì)一類作用大而對(duì)其他類作用小的特征保留下來。
(4)預(yù)訓(xùn)練BERT 算法模型。BERT 模型是有別于傳統(tǒng)CNN 和RNN 的一種新型架構(gòu),采用編碼器-解碼器框架,使用注意力機(jī)制進(jìn)行機(jī)器翻譯任務(wù),規(guī)避了CNN 不適合序列化的文本和RNN 無(wú)法并行容易超出內(nèi)容限制的問題。該模型的Encoder 將輸入序列映射到連續(xù)表示,然后Decoder 生成一個(gè)輸出序列,每個(gè)時(shí)刻輸出一個(gè)結(jié)果。
(5) 模型輸出。通過使用Softmax 分類器來預(yù)測(cè)成果資料關(guān)鍵標(biāo)簽,如:對(duì)具備業(yè)務(wù)含義的“壓裂”“出砂”“井下作業(yè)”等信息打標(biāo)簽,該分類器將上一層得到的隱狀態(tài)作為輸入。
(6)目標(biāo)損失函數(shù)。成果資料關(guān)鍵信息提取是一個(gè)多分類的問題,使用softmax 分類器輸出的標(biāo)簽概率與實(shí)際標(biāo)簽分布概率計(jì)算損失函數(shù)。
2 實(shí)驗(yàn)
2.1 實(shí)驗(yàn)環(huán)境及數(shù)據(jù)集
本實(shí)驗(yàn)是在海油AI 平臺(tái)提供的開發(fā)環(huán)境下,基于Python 語(yǔ)言使用Pytorch 框架在Linux 環(huán)境開展。該平臺(tái)建于2019 年,整合了大部分深度學(xué)習(xí)中的神經(jīng)網(wǎng)絡(luò)模型并結(jié)合海油業(yè)務(wù)實(shí)際定制開發(fā)和訓(xùn)練了較為成熟的算法模型,通過模型商城對(duì)外提供服務(wù)。
實(shí)驗(yàn)使用了中海油勘探開發(fā)數(shù)據(jù)湖推送的成果資料,對(duì)初始數(shù)據(jù)預(yù)處理,篩選、去除無(wú)用信息,共使用了934 個(gè)勘探開發(fā)成果資料文本。為保障實(shí)驗(yàn)效果,本文作者協(xié)同業(yè)務(wù)專家對(duì)獲取的文本關(guān)鍵信息進(jìn)行了標(biāo)注,全量數(shù)據(jù)的80%用作模型的訓(xùn)練集,10%用作測(cè)試集,10%用作驗(yàn)證集。
2.2 超參數(shù)設(shè)置及實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)
2.2.1 超參數(shù)設(shè)置
標(biāo)準(zhǔn)BERT 模型具有base 和large 兩個(gè)版本,考慮到本實(shí)驗(yàn)文件大、內(nèi)容復(fù)雜、對(duì)硬件要求高,本文選擇base 版本,分類模型采用的參數(shù),如表1 所示。

表1 參數(shù)設(shè)置
2.2.2 實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)
在機(jī)器學(xué)習(xí)、自然語(yǔ)言處理和信息檢索領(lǐng)域,混淆矩陣是一種表示精度評(píng)價(jià)的標(biāo)準(zhǔn)格式,具體評(píng)價(jià)指標(biāo)包含準(zhǔn)確率、精準(zhǔn)率、召回率和F1值等。
各項(xiàng)標(biāo)準(zhǔn)的具體計(jì)算公式為:
式中:TP表示樣本為正,預(yù)測(cè)結(jié)果為正;FP表示樣本為負(fù),預(yù)測(cè)結(jié)果為正;TN表示樣本為負(fù),預(yù)測(cè)結(jié)果為負(fù);FN表示樣本為正,預(yù)測(cè)結(jié)果為負(fù)。
2.3 實(shí)驗(yàn)對(duì)比及結(jié)果分析
2.3.1 閾值設(shè)置
模型預(yù)測(cè)通常返回的是概率,可以原樣使用,也可以將概率轉(zhuǎn)換成二元值。處理復(fù)雜的勘探開發(fā)文檔時(shí),為提高模型算法對(duì)數(shù)據(jù)的感知能力,先以概率分布輸出預(yù)測(cè)結(jié)果,結(jié)合實(shí)際業(yè)務(wù)數(shù)據(jù)分析不同類別之間判定閾值,評(píng)估需人工干預(yù)的程度,確保模型對(duì)類別的分辨能力足夠支撐模型預(yù)測(cè)。
例如:在進(jìn)行鉆井地質(zhì)設(shè)計(jì)報(bào)告分類任務(wù)時(shí),如果模型對(duì)某設(shè)計(jì)報(bào)告進(jìn)行預(yù)測(cè)時(shí)返回的概率為0.999 5,表示模型預(yù)測(cè)這個(gè)非常可能是鉆井地質(zhì)設(shè)計(jì)報(bào)告。同一個(gè)模型預(yù)測(cè)分?jǐn)?shù)為 0.000 3 的設(shè)計(jì)報(bào)告很可能不是。如果預(yù)測(cè)分?jǐn)?shù)是0.6,為了將概率分布值映射到分類類別,必須指定分類閾值。當(dāng)概率值高于該閾值,則表示“是”,如果概率值低于該閾值,則表示“不是”。
2.3.1 閾值分析
本文嘗試設(shè)置多組不同閾值,通過結(jié)果分析以尋找較合適的閾值。調(diào)整閾值對(duì)整體評(píng)估指標(biāo)準(zhǔn)確度(ACC)及每一個(gè)類別評(píng)估指標(biāo)F1值的影響,如圖2 所示。
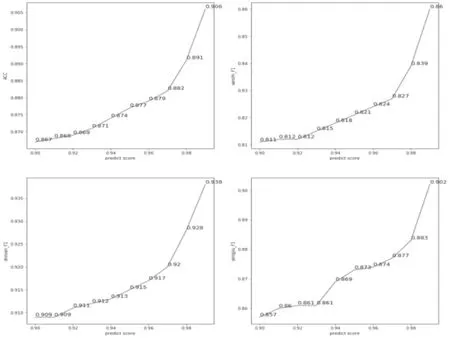
圖2 不同概率區(qū)間下ACC 及各類別F1 值分布
其中,左上圖代表整體ACC 隨著閾值設(shè)置的變化趨勢(shì),其他圖代表不同類別的評(píng)估指標(biāo)F1隨著閾值設(shè)置的變化趨勢(shì)。通過觀察可知,為了保證每一分類類別的指標(biāo)都較好,閾值選擇0.95 比較合適。
3 結(jié)語(yǔ)
本文基于預(yù)訓(xùn)練語(yǔ)言模型雙向Transformers 編碼表示的成果資料的關(guān)鍵信息提取,對(duì)實(shí)際業(yè)務(wù)場(chǎng)景下的文本進(jìn)行了訓(xùn)練預(yù)測(cè),將文本切分為頭部、主體和尾部,利用數(shù)據(jù)增強(qiáng)技術(shù)對(duì)數(shù)據(jù)較少的類別進(jìn)行擴(kuò)充。通過生成文本的詞嵌入向量,有效獲取到上下文信息及勘探開發(fā)領(lǐng)域詞匯的語(yǔ)義特征。通過對(duì)不同閾值下模型的分類效果分析,模型的各個(gè)指標(biāo)準(zhǔn)確率在85%以上。隨著樣本量的不斷增加和機(jī)器學(xué)習(xí)算法的優(yōu)化,準(zhǔn)確率將會(huì)進(jìn)一步提升。本文僅是對(duì)勘探開發(fā)成果資料的關(guān)鍵標(biāo)簽進(jìn)行了研究和實(shí)現(xiàn),是利用自然語(yǔ)言處理技術(shù)對(duì)油氣行業(yè)的關(guān)鍵信息智能提取、數(shù)據(jù)高效利用和業(yè)務(wù)數(shù)據(jù)知識(shí)圖譜建設(shè)作出的積極嘗試與探索。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
