工廠檢測檢驗(yàn)用手寫表格的識(shí)別及數(shù)字化處理方法
2023-05-09 04:09:43方浩東鮑敏
軟件工程 2023年5期
方浩東 鮑敏


關(guān)鍵詞:預(yù)處理;形態(tài)學(xué)檢測;Tesseract-OCR;表格框架;動(dòng)態(tài)掩膜
中圖分類號(hào):TP391 文獻(xiàn)標(biāo)識(shí)碼:A
1 引言(Introduction)
當(dāng)前,我國的大部分軸承生產(chǎn)企業(yè)處于向數(shù)字化[1]、智能化演進(jìn)的階段。在這個(gè)大趨勢(shì)下,一部分企業(yè)已經(jīng)開始實(shí)施數(shù)據(jù)自動(dòng)化接入工作,但出于對(duì)成本、工具及工作效率等因素的考慮,通常在原料入廠檢驗(yàn)及現(xiàn)場首檢、抽檢環(huán)節(jié)仍然使用了較多的需要人工手寫的表格。
常見的原料檢測數(shù)字化方式包括直接在上位機(jī)或App上錄入數(shù)據(jù),但是這兩種方式存在效率低和數(shù)據(jù)兼容性問題。馬致遠(yuǎn)等[2]提出基于Faster-RCNN(區(qū)域生成網(wǎng)絡(luò))的表格檢測算法,將文檔中的表格信息提取出來。毛尚偉等[3]提出基于Transfer-crf神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)對(duì)電子表格結(jié)構(gòu)的識(shí)別。潘煒等[4]設(shè)計(jì)一種基于光學(xué)字符識(shí)別技術(shù)和TensorFlow深度學(xué)習(xí)框架的表格文本識(shí)別模型,可以實(shí)現(xiàn)對(duì)表格的批量識(shí)別。然而,深度學(xué)習(xí)對(duì)海量數(shù)據(jù)集訓(xùn)練出最佳算法模型,對(duì)企業(yè)硬件要求高,增加成本的同時(shí)會(huì)導(dǎo)致訓(xùn)練時(shí)間過長。基于此,本文設(shè)計(jì)一套字符識(shí)別系統(tǒng):基于形態(tài)學(xué)[5]提取表格框架,設(shè)計(jì)動(dòng)態(tài)掩膜結(jié)合角點(diǎn)檢測實(shí)現(xiàn)單元格分割,基于Tesseract-OCR[6]訓(xùn)練專用字庫對(duì)單元格內(nèi)字符進(jìn)行識(shí)別,主要包括表格圖像預(yù)處理模塊、表格提取和單元格分割模塊及字符識(shí)別三大模塊。
2 表格圖像預(yù)處理模塊(Preprocessing module ofform image)
本研究要處理的表格圖片總共分為七類,依次為熱處理、正標(biāo)套圈大圈、正標(biāo)套圈小圈、軸承成品、非標(biāo)套圈、聯(lián)軸器、鋼球檢驗(yàn)報(bào)告單。
2.1 消噪處理
噪聲的存在對(duì)圖像的質(zhì)量有著很大的影響,它會(huì)使圖像模糊、丟失關(guān)鍵信息等。噪聲主要有兩個(gè)來源方式,分別是在獲取和傳輸過程中會(huì)產(chǎn)生噪聲。在獲取圖像時(shí)會(huì)受材料特性、環(huán)境因素和電子元器件等因素的影響而產(chǎn)生各種噪聲,在傳輸過程中會(huì)受傳輸設(shè)備或傳輸介質(zhì)等因素的影響而產(chǎn)生噪聲。常見的噪聲主要有椒鹽噪聲、高斯噪聲、泊松噪聲、乘性噪聲四種。
本文采用高斯濾波[7]的方法對(duì)圖像進(jìn)行消噪處理。高斯濾波是一種線性的平滑濾波,它將頻域處理和時(shí)域處理相結(jié)合。對(duì)需要識(shí)別的圖像進(jìn)行平均加權(quán)計(jì)算,使得圖像上每一個(gè)像素點(diǎn)都是由它本身和相鄰其他像素點(diǎn)值計(jì)算得到,從而實(shí)現(xiàn)將噪聲信息過濾掉,對(duì)圖像起到一個(gè)平滑作用。
一維高斯函數(shù)分布式:
二維高斯函數(shù)分布式:
高斯函數(shù)是單值函數(shù),它在所有的方向上都是單調(diào)遞減的,其中心點(diǎn)像素不會(huì)受到距離中心點(diǎn)較遠(yuǎn)處像素過大的影響,從而能保證中心點(diǎn)和邊緣處的特性;并且,二維高斯函數(shù)是旋轉(zhuǎn)對(duì)稱的,它在各個(gè)方向上的平滑程度都是相同的,因此使用高斯濾波能有效消除待處理圖像中的噪聲影響。
2.2 二值化處理
在對(duì)圖像進(jìn)行數(shù)字化處理的過程中,二值化處理[8]是不可或缺的步驟,它將灰度圖像轉(zhuǎn)化為二值圖像,能顯著減少圖像中的干擾信息。圖1(a)為輸入樣本圖,是由眾多像素點(diǎn)組成,而像素點(diǎn)又是通過RGB(紅綠藍(lán))三原色表現(xiàn)的,二值化就是讓圖像像素點(diǎn)矩陣中的值為255(白色)或0(黑色),即讓整個(gè)圖像呈現(xiàn)出只有黑色和白色的效果。本文使用自適應(yīng)閾值二值化cv2.adaptiveThreshold函數(shù)對(duì)圖像進(jìn)行二值化處理,該函數(shù)在去除背景和提取前景的有用信息方面更加有效,如圖1(b)所示。
2.3 傾斜矯正
由于紙質(zhì)數(shù)據(jù)在拍攝時(shí)難免存在傾斜現(xiàn)象,會(huì)對(duì)后期表格處理存在干擾,尤其對(duì)文字不能分割成單個(gè)字符時(shí),會(huì)降低識(shí)別的準(zhǔn)確率,因此對(duì)傾斜的圖像進(jìn)行校正,會(huì)對(duì)識(shí)別準(zhǔn)確率有很大程度的提高。
圖像進(jìn)行灰度化和二值化處理后,對(duì)傾斜圖像校正的關(guān)鍵問題在于要準(zhǔn)確找到它的傾斜角度,本文采用霍夫變換,其基本實(shí)現(xiàn)原理是首先識(shí)別圖像中的幾何圖形,從中檢測到對(duì)應(yīng)的直線,然后通過計(jì)算直線的傾斜角度判斷圖形的傾斜度數(shù),最后進(jìn)行旋轉(zhuǎn)校正;而表格圖像的框線是橫平豎直的,所以使用霍夫變換對(duì)表格圖像進(jìn)行傾斜校正,能獲得一個(gè)很好的識(shí)別結(jié)果。
對(duì)圖像進(jìn)行矯正計(jì)算得到角度脫粒圖像及直線圖像,如圖3所示。
3.3 動(dòng)態(tài)掩膜
由于待識(shí)別表格復(fù)雜且表格上有很多信息是固定的,因此全部進(jìn)行識(shí)別會(huì)大大增加識(shí)別時(shí)間,而且會(huì)降低識(shí)別精度。為了解決上述問題,本文提出一種基于傳統(tǒng)圖像掩膜方式的動(dòng)態(tài)掩膜方法,將不感興趣的區(qū)域遮蔽。圖像掩膜是借鑒制作PCB(印制電路板)的過程,計(jì)算機(jī)中則是將圖像當(dāng)作一個(gè)矩陣,圖像掩膜即制作一個(gè)模板圖像,對(duì)需要保留有用信息的部分置為“1”,而無用信息部分置為“0”進(jìn)行過濾處理,之后對(duì)待處理圖像操作就是將掩膜圖像矩陣與待處理圖像矩陣進(jìn)行乘積運(yùn)算,從而得到最后需要處理的圖像,掩膜過程如圖6所示。
因?yàn)椴煌谋韱喂潭▍^(qū)域是不同的,所以會(huì)先對(duì)不同的表格定義其需要掩膜內(nèi)容的坐標(biāo)交點(diǎn)信息,并存入數(shù)組中,再根據(jù)得到的表單類型到mylisty和mylistx數(shù)組中匹配對(duì)應(yīng)的交點(diǎn)位置信息,以交點(diǎn)位置定位繪制掩膜圖像,將掩膜圖像與目標(biāo)圖像實(shí)施與運(yùn)算操作,動(dòng)態(tài)掩膜流程圖如圖7所示。
未掩膜操作如圖8(a)所示,對(duì)輸入樣本圖片掩膜并提取單元格信息如圖8(b)所示。
由圖8可知,經(jīng)過掩膜后單元格明顯減少,識(shí)別內(nèi)容也會(huì)相應(yīng)減少。
4 字符識(shí)別模塊(Character recognition module)
本文基于Tesseract-OCR[11]完成表格內(nèi)文字的識(shí)別,由于表單上的字符含有數(shù)字、英文、中文、特殊字符等,但Tesseract-OCR自帶的字庫存在識(shí)別效率低、識(shí)別精度不高的問題,所以利用jTessBoxEditor工具訓(xùn)練專門針對(duì)原料檢驗(yàn)單識(shí)別的字庫,訓(xùn)練步驟如下。
(1)準(zhǔn)備訓(xùn)練樣本圖片,分別準(zhǔn)備手寫和印刷數(shù)字、英文、中文、特殊符號(hào)共10萬余張照片數(shù)據(jù)集,進(jìn)行灰度化處理后將文件保存到待訓(xùn)練文件夾下。
(2)合并樣本圖片,使用jTessBoxEditor將所有樣本圖片合并成一個(gè)tif文件。
(3)生成box文件,執(zhí)行tesseract langyp.figen.exp0.tiflangyp.figen.exp0 -lbatch.nochopmakebox命令,生成tif文件對(duì)應(yīng)的box文件,其中l(wèi)angyp為語言名稱,figen為生成的字體名稱。
(4)修改box文件,針對(duì)生成的box文件,會(huì)出現(xiàn)一些錯(cuò)誤識(shí)別和字符切分出錯(cuò)的問題,例如兩個(gè)字符在一個(gè)字符識(shí)別框中,如圖9所示。
使用jTessBoxEditor工具將合并在一起的字符識(shí)別框分割為兩個(gè)部分,如圖10所示。
(5)生成font_properties文件,執(zhí)行echo figen 0 0 0 0 0后生成,其中figen為訓(xùn)練的字體名。
(6)生成tr訓(xùn)練文件,執(zhí)行l(wèi)angyp.figen.exp0.tr命令訓(xùn)練文件。
(7)生成字符集文件,執(zhí)行unicharset_extractor langyp.figen.exp0.box命令。
(8)生成shape文件,執(zhí)行shapeclustering -F font_properties -U unicharset -O langyp.unicharset langyp.figen.exp0.tr命令。
(9)生成聚集字符特征文件,執(zhí)行mftraining -F font_properties -U unicharset -O命令。
(10)生成字符正常化特征文件,執(zhí)行cntraining langyp.figen.exp0.tr命令。
(11)合并訓(xùn)練文件,執(zhí)行combine_tessdatafigen命令。
完成訓(xùn)練后,將字庫拷貝放入工程項(xiàng)目doc/fonts目錄下,當(dāng)表格單元格分割完畢后,需要對(duì)單元格內(nèi)的字符信息進(jìn)行識(shí)別,由于需要對(duì)識(shí)別后的信息再填充進(jìn)新的數(shù)字表格中,因此對(duì)單元格的左上角坐標(biāo)進(jìn)行標(biāo)記,調(diào)用訓(xùn)練的字庫將字符識(shí)別完畢后存入對(duì)應(yīng)的空表格內(nèi)。
5 實(shí)驗(yàn)結(jié)果分析(Analysis of results)
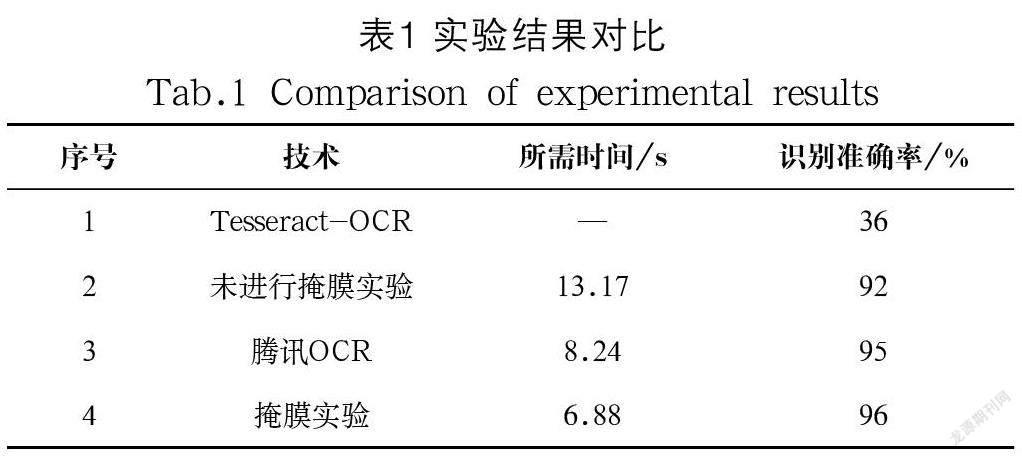
本文對(duì)樣本表格在原生Tesseract-OCR、未進(jìn)行掩膜實(shí)驗(yàn)、騰訊OCR和掩膜實(shí)驗(yàn)進(jìn)行識(shí)別實(shí)驗(yàn)對(duì)比,結(jié)果詳見表1。
實(shí)驗(yàn)硬件環(huán)境:CPU為第九代英特爾酷睿i7處理器,顯卡為NVIDIA GeForce GTX 1650,內(nèi)存為16 GB。軟件環(huán)境:python 3.6.8,Windows 10 64位操作系統(tǒng)。實(shí)驗(yàn)證明,原生Tesseract-OCR識(shí)別字符準(zhǔn)確率很低,難以達(dá)到識(shí)別精確度的標(biāo)準(zhǔn);騰訊OCR比未進(jìn)行掩膜實(shí)驗(yàn)的識(shí)別速度快且精度也高,但是該OCR引擎不能對(duì)參數(shù)進(jìn)行設(shè)置,只能對(duì)整張表格進(jìn)行識(shí)別;而掩膜實(shí)驗(yàn)識(shí)別所需時(shí)間比未掩膜實(shí)驗(yàn)少一半且比騰訊OCR快1.36 s,識(shí)別準(zhǔn)確率也提高了1%。
6 結(jié)論(Conclusion)
本文利用形態(tài)學(xué)檢測原理及Tesseract-OCR字符識(shí)別技術(shù),結(jié)合角點(diǎn)檢測方法實(shí)現(xiàn)對(duì)原料手寫表格的識(shí)別,描述了對(duì)圖像預(yù)處理的過程,以及動(dòng)態(tài)掩膜及單元格分割與字庫訓(xùn)練步驟。將本文所提手寫表格識(shí)別系統(tǒng)與市場主流騰訊OCR技術(shù)進(jìn)行對(duì)比實(shí)驗(yàn),證明本文所提系統(tǒng)對(duì)原料表格識(shí)別速度更快、準(zhǔn)確率更高,同時(shí)該識(shí)別系統(tǒng)可以部署到企業(yè)的所有上位機(jī)中,能很好地運(yùn)用到企業(yè)的實(shí)際生產(chǎn)過程中,降低生產(chǎn)成本、提高工作效率和實(shí)現(xiàn)數(shù)據(jù)的二次利用率。
作者簡介:
方浩東(1997-),男,碩士生.研究領(lǐng)域:數(shù)字化及自動(dòng)化.
鮑敏(1977-),男,博士,副教授.研究領(lǐng)域:智能制造,生產(chǎn)過程數(shù)據(jù)分析.
