融合注意力機制的YOLOv5火災煙霧檢測
2023-04-27 04:05:42李志華王連賀王超劉春雷張元彪
電腦知識與技術 2023年8期
李志華 王連賀 王超 劉春雷 張元彪






關鍵詞:目標檢測;煙霧檢測;YOLOv5;注意力機制;ACON激活函數
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2023)08-0001-04
0 引言
由于采用傳統的煙霧報警或檢測手段的煙霧探測器裝置只能在靠近排放源的地方識別煙霧的存在,并且受各種天氣環境影響,其感受到的溫度、濕度及顆粒密度都會影響檢測效果[1]。由于設備的探測范圍的局限性,一些戶外場所的地理屬性導致無法大范圍鋪設傳統的探測設備,它們缺乏檢測局部煙霧的能力。
2018年,Yanmin Luo等人[2]在文獻中提出一種基于背景動態更新和暗通道先驗的運動目標檢測算法,檢測疑似煙霧區域。然后,通過CNN自動提取疑似區域的特征,進行煙霧識別。但該模型算法泛化程度較差,對于煙霧特性分析不足,且運算過程中容易造成特征丟失。2020年,Sergio Saponara等人[3]提出了一種利用YOLOv2卷積神經網絡(CNN)在防火系統中進行實時視頻火災和煙霧檢測的方法,并采用輕量級神經網絡架構設計,以兼顧嵌入式平臺的需求,但模型滿足輕量化設計的同時并沒有很好的兼顧精準度。
目前,基于深度學習的火焰煙霧的檢測與識別普遍存在著精度不足,提取特征丟失,檢測效率過慢,成本過高或者模型泛化程度不夠等問題。在工業化程度大幅增長,生活場景復雜和監控來源較多的時代背景下,為解決上述問題,本文提出了一種基于YOLOv5的融合注意力機制(CBAM)的煙火檢測算法,滿足安全生產,精準防控的目的。
1 算法原理
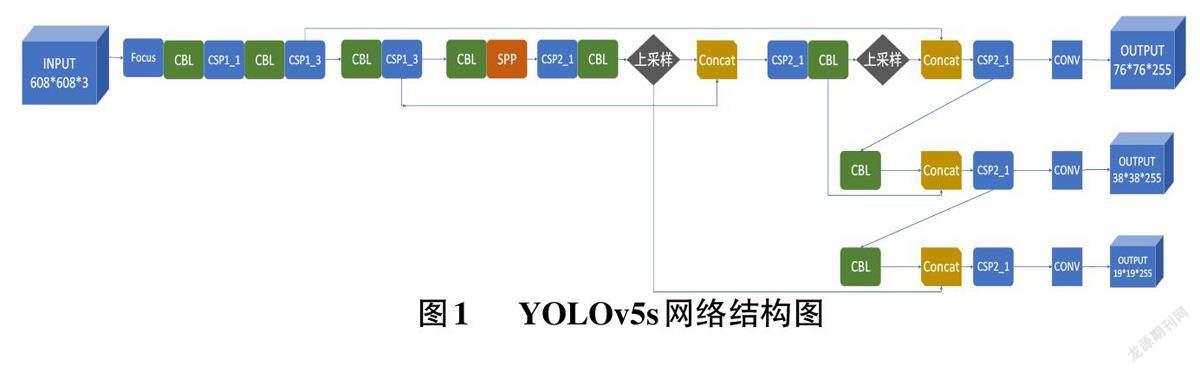
1.1 YOLOv5結構
在YOLOv5的四個模型中,YOLOv5s具有參數量較少、版本兼容性高、處理速度快等優點,因此本次實驗是在YOLOv5s結構的基礎上進行改進,其原本的網絡結構如圖1所示。
1.2 注意力機制
注意力機制的原理是利用計算機模擬人類在接收視覺信號時的處理過程,當人類掃描接收全部視覺信號時,會把自身的注意力放在重要的部分獲取更多細節信息,從而提高任務效率。注意力機制基于此,將一些重要信息進行加權抽象出重要的特征信息。注意力機制的本質就是進行篩選,通過注意力機制的處理將信息進行區分,符合任務條件的特征會被優先處理,從而快速精準地檢測目標。
本次實驗使用的是CBAM(Convolutional Block At?tention Module) ,在通道和空間雙維度進行Atten?tion[4]。通道注意力(CAM) 結構如圖2所示:
在通道注意力中圖像擁有三種屬性:長、寬和通道數。其原理是保持通道維度不變,壓縮空間維度,具體操作是首先讓特征圖分別經過Max Pooling(最大池化)與Average Pooling(平均池化)進行處理,處理后的特征圖的長和寬尺寸為1通道數則不變,然后接入第一層神經網絡壓縮通道,壓縮后再接入第二層神經網絡進行通道擴張得到兩個經激活后的結果。而后,將輸出的特征C1和C2相加求和,再經過sigmoid激活函數激活后,與原始尺寸圖像相乘,完成注意力操作。
空間注意力(SAM) 結構如圖3所示:
空間注意力其原理是保持空間維度不變,壓縮通道數,來獲取關鍵目標的位置信息。具體操作是給定一個尺寸的特征圖,我們先分別進行一個通道維度的平均池化和最大池化,長和寬的尺度不變將通道數壓縮為1,并將這兩個信息按照通道拼接在一起。再通過卷積操作將通道數重新壓縮為1,通過sigmoid函數進行激活后,乘以最開始的特征圖,完成空間注意力操作。
2 設計方案
2.1 方案流程圖
如圖4所示,首先輸入捕捉到的視頻或圖像,然后對攝像頭捕捉的畫面進行一個是否失焦的判斷,由于對失焦的圖像進行識別意義不大而且失焦的圖片容易造成識別錯誤,濃煙與環境背景像素的灰度值往往相差較高,對焦準確清晰的圖片內,物體與物體輪廓明顯,顏色像素差較大,而失焦圖片由于圖像模糊,所以像素值之間的變化很小,可利用這一特點設立閾值判斷圖像是否失焦。若圖像失焦則跳轉下一張圖片,若未失焦則輸入改進的YOLOv5算法模型中,判斷圖像是否存在煙霧區域,若不存在則跳轉下一張,若存在則框出圖像中煙霧區域,結束本次程序。
2.2 數據集介紹
2.2.1 數據集來源
CVPR Lab ——KMU Fire and Smoke database(https://cvpr.kmu.ac.kr/)
Fire Image Data Set ——Durham University(https://collections. durham. ac. uk/files/r2d217qp536#.X5F5G2gzZnK)
江西財經大學袁非牛教授(http://staff.ustc.edu.cn/~yfn/vsd.html)
利用Python等爬蟲工具在網上下載各種火災煙霧視頻及圖片
3 改進模型
3.1 空間+通道雙注意力機制
為了能夠更好的對檢測目標投入更多的資源,本次實驗在YOLOv5原有的網絡結構基礎上添加CBAM 機制。在YOLOv5主干道網絡(backbone) 后依次加入通道、空間注意力模塊,將卷積核設為7×7,步長設為3,在特征圖通過進入瓶頸層前,將會得到注意力機制處理過的特征圖,這樣在火災煙霧識別的過程中會提高目標的識別精度。插入結構如圖5所示。
3.2 ACON 激活函數(Activate Or Not , ACON)
ReLU激活函數在深度學習中有著廣泛的應用,由于其非飽和、稀疏性等優秀的特性在構建稀疏性的神經網絡矩陣時十分方便,但是它也同樣會造成神經元權重不更新從而導致神經元壞死。而Leaky ReLU 也存著在函數負半軸收斂速度過慢,函數在零點位置不平滑的問題。基于Leaky ReLU函數的特性提出了一種與Leaky ReLU相似的ACON family 激活函數[5]。本次算法改進是將CSP1_X 及CBL 結構中原有的Leaky ReLU激活函數替換成ACON激活函數。
如圖6所示,ACON函數明確了線性和非線性參數的切換,從而決定了神經元是否激活。ACON fam?ily 激活函數分為三大類型:ACON-A、ACON-B、ACON-C。其公式如下:
其中ACON-A,ACON-B 是ReLU 函數和Leaky_ReLU的平滑近似,σ為S型函數,參數β為轉換因子,p 為一個可學習的參數,一般設小于1。
如圖7所示,ACON函數族曲線相較ReLU函數族更加平滑,在其曲線上任意一點連續可微的同時,也保留了ReLU函數族在正負半軸的梯度特點。
如圖8所示,ACON-C的一階導數的上下邊界范圍也是通過P 和P 兩個參數來調整決定的,通過學習P 和P 的邊界范圍,就可以獲得性能更好的激活函數。參數β控制激活函數的線性/非線性,這種特定的激活有助于提高泛化和傳遞性能。
4 實驗結果對比
4.1 實驗環境及說明
本次實驗在PyTorch深度學習框架下進行,服務器參數為CPU:Intel(R) Xeon(R) CPU E5-2609 v4 @1.70GHz,架構為:x86_64 GPU:12GB 顯存的NVIDIATesla P100。在訓練過程中使用隨機剪裁、水平翻轉等方式增強數據集,初始學習率為0.0001,輸入圖像尺寸統一設置為640×640,置信度設為0.7。
4.2 實驗結果對比
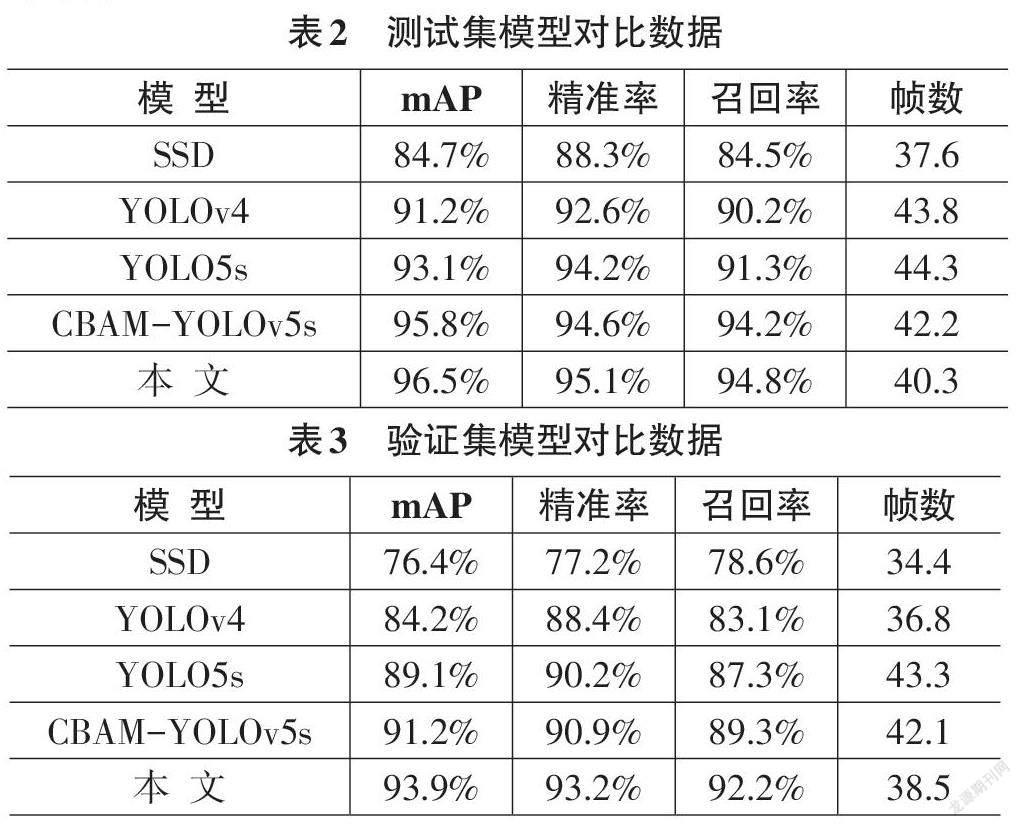
本次實驗在迭代300輪次的實驗環境下將三種算法模型YOLOv4、YOLOv5s、SSD和增加了CBAM注意力機制而未改變激活函數的CBAM-YOLOv5s模型與本文改進的YOLOv5算法結果進行對比,對比指標有mAP、精準率、召回率、處理速度(幀數),對比結果如下表。
經兩次數據集實驗對比,同時增加了CBAM 和ACON激活函數的模型在性能上明顯優于其他四種。而改進過的算法模型由于其增加了CBAM注意力機制,原本的激活函數替換成了ACON激活函數,在不同數據集上mAP、精準度和召回率對比其他模型均有所提高,而處理速度分別僅下降了2.5%、3%,這是完全可以接受的。由此可見,本文提出的算法模型整體上優于其他三種模型。
4.3 實驗檢測效果圖
如圖9所示,(1) (2) 為白色煙霧;(3) (5) 為黑色煙霧;(4) 則為無煙圖像;(6) 為電車起火瞬間;(7) 為系統判定失焦圖像。經檢驗,模型能夠很好地檢測出火災煙霧位置,及時發出警報,從而減少火災所造成的損失。
5結論
本次實驗是針對現有的火災煙霧檢測算法精度不足、誤檢率高以及在不同數據集上效果差距大等問題進行改進。本文采用YOLOv5算法融合CBAM注意力機制提高檢測精度的同時,將激活函數替換成ACON函數,提高了模型的抗過擬合能力。在不同數據集測試后,精準度與召回率均優于其他對比模型。在實際應用中,受光線、環境和天氣等因素影響,攝像裝置在采集圖像信息時,可能會發生煙霧信息采集不全、圖像亮度過低的情況,導致煙霧檢測效果不佳。本次實驗所用的改進的算法模型雖然在精準度與召回率上相比其他模型算法均有所提升,但檢測速度略微降低。下一步工作將針對攝像頭檢測條件不佳時的煙霧檢測,以及在檢測精度提高的情況下如何提高檢測速度兩方面進行更深入的研究。
