基于大數據技術的電商用戶畫像可視化系統設計與實現
2023-04-19 06:38:56梁肇敏梁婷婷
智能計算機與應用 2023年3期
梁肇敏, 梁婷婷
(南寧學院 人工智能學院, 南寧 530200)
0 引 言
互聯網飛速發展的現代社會,信息技術正從各個方面影響著企業商業模式的改變。 在企業的商業活動中,客戶是商業活動的中心,只有客戶在商業活動中產生消費行為,企業才能獲得利潤和發展[1]。所以企業為了能夠讓客戶在自己的商業活動中消費,就需要投入很多成本來吸引客戶。 在當代社會,電子商務日益發達,更多的人喜歡在線上購買自己想要的商品。 考慮到人們在線上各種各樣的消費行為,隨即產生了大量的數據,同時商家在線上也會提供大量的商品信息。 這樣導致用戶將無法精確選擇自己感興趣的商品,企業也無法對海量用戶進行精確廣告投送,從而產生了網絡上信息過載的問題[2]。 為解決上述問題,需要對數據信息進行精準的推薦,用戶畫像則是實現推薦的重要環節[3]。 研究發現,利用客戶產生的行為數據構建用戶畫像,可以讓企業全面了解客戶的喜好,摒棄傳統單一的商品信息投送策略,進而轉向精準推薦投送,就能讓企業花費最小代價找到契合客戶,客戶也能找到自己感興趣的商品,這對企業的發展和提高企業與用戶的溝通效率等都有積極的意義[4]。
本系統是基于電商平臺進行設計和開發,是面向注冊會員的偏好、行為習慣和人口屬性的畫像還原,同時也包括對商品信息的畫像還原。 提供用戶喜好和商品特征幫助營銷平臺提升營銷的精準度,也有利于個性化推薦系統快速準確地為每個用戶推薦相關的商品。
1 需求分析
本系統設計并實現基于大數據的電商用戶畫像系統是為了將電商客戶數據收集起來,深度挖掘出其價值,從而應用在企業的各種營銷活動中。 所以系統應該滿足:能從網速抓取客戶網上基本屬性、行為等數據,全方位地分析用戶數據,構建用戶畫像,并且能以良好的交互方式展現給使用者[5]。 分析可知,系統應該具有以下功能:
(1)服務端數據采集功能。 系統自身的客戶數據作為用戶畫像數據源的一部分,以文件的形式從各個子系統傳輸到服務器的指定存儲目錄,系統進行統一的匯總分析。
(2)網絡爬蟲功能。 電商網絡產生海量客戶行為數據,這對構建用戶畫像系統具有重要意義。 但是網上客戶行為更多是一些網頁鏈接地址數據,所以需要爬蟲技術根據客戶訪問的網絡鏈接爬取鏈接所指向的文本內容數據,從而分析出行為偏好。 而面對網絡海量的電商客戶數據,利用分布式爬蟲技術是很好的解決方案。
(3)數據存儲功能。 構建用戶畫像系統所需要的數據具有海量、且數據類型多樣性等特點,這就需要系統具備存儲海量多樣性數據的能力,以滿足海量多樣性數據存儲的需求。
(4)數據處理與分析功能。 從不同的數據源傳輸過來的數據并不能直接加以利用,更多是摻雜著許多“臟數據”,需要系統首先對數據進行去重、數據標準化等預處理,此后才能利用各種算法模型去分析和挖掘出有價值的數據,進而構建電商用戶畫像。
(5)數據可視化功能。 構建用戶畫像后,提供給用戶使用。 系統需要提供生動、直觀的報表、圖形等可視化界面,讓用戶更容易獲取和理解用戶畫像的分析結果。
2 系統總體架構設計
2.1 系統體系結構設計
基于大數據技術的電商用戶畫像的總體架構如圖1 所示。 由圖1 可知,系統主要分為數據源層、數據獲取層、數據存儲和處理層、數據訪問層、數據服務和展現層。 系統中的每一層都對數據的處理有不同的任務和分工,根據整體架構圖的設計,對系統的各個功能層進行全面的功能說明和描述。
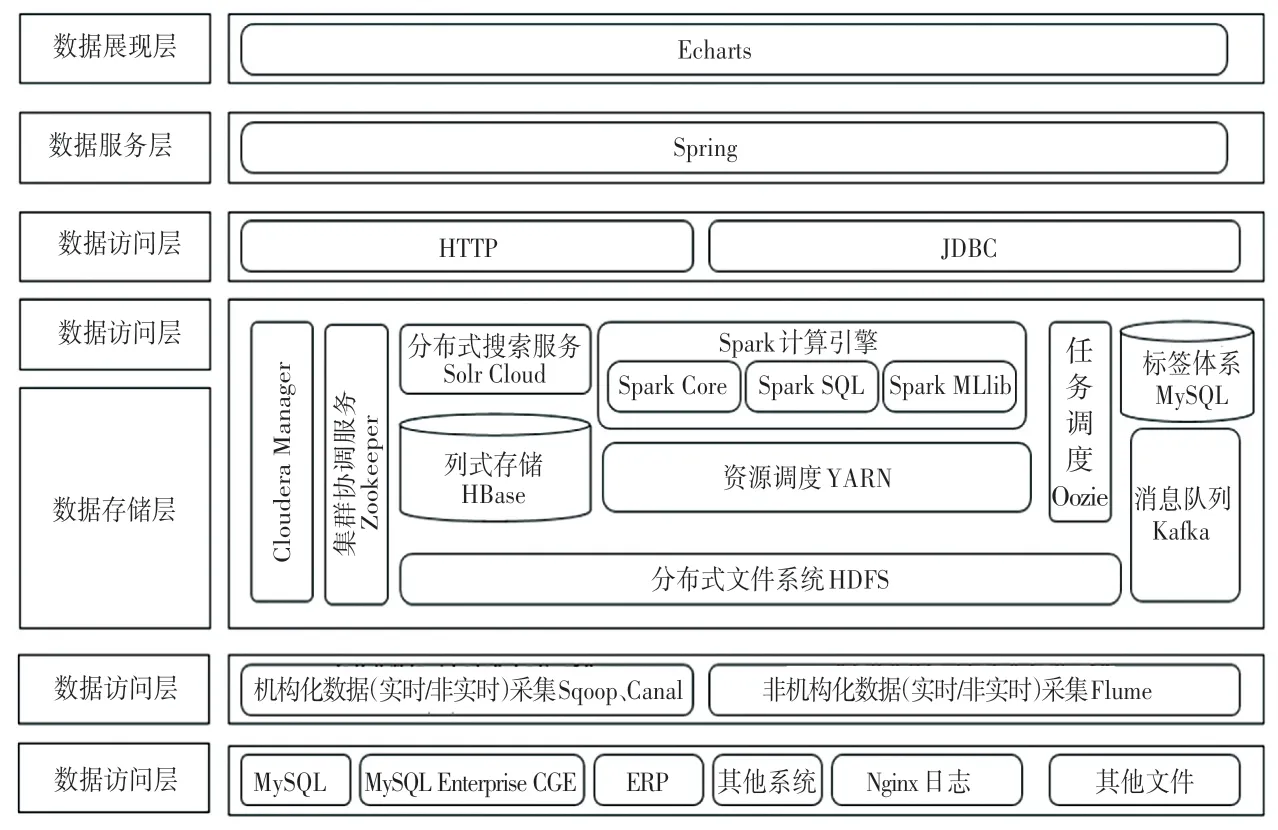
圖1 系統整體體系架構圖Fig. 1 Overall system architecture diagram
(1)數據源層。 用戶畫像系統的最低層是數據源層,該層以實現數據的ETL(Extract&Transform&Load)過程和利用Hadoop 進行數據存儲,不管是海量數據的存儲、還是其他形式的數據,都應持久化在本層,并通過Hadoop 的高可用、高可靠,保障數據使用的效率與存儲的安全性。
(2) 數 據 獲 取 層。 該 層 主 要 是 對 數 據 庫MySQL、MySQL Enterprise CGE、ERP 或者其他系統中的數據進行采集,通過Sqoop 導入到大數據平臺中,Canal 是將數據實時采集到大數據平臺中,而Nginx 日志和其他文件通過Flume 進行采集。
(3) 數據存儲層和數據處理層。 這2 層對數據的操作都是基于Hadoop 平臺來完成,主要是對用戶原始數據和中間數據進行適當的處理和存儲。 體系里分布式文件系統HDFS 負責對系統相關數據和用戶數據進行存儲。 系統產生的標簽存儲在傳統關系數據庫MySQL 中。 不論是系統產生數據、還是從外部源爬取的數據都會以大文件形式存儲在HSFS 和MySQL 中,隨后再導入到Hive 中進行數據分析。Hive 分析結束后,會將分析的用戶畫像結果存儲在HBase 中,為最終數據可視化提供數據支撐。
(4)數據訪問層。 該層主要是為上層可視化或其他應用提供數據接口服務,使前端平臺能對其進行有效連接。
(5)數據服務和數據展示層。 該層主要是利用SparkMLlib 相關算法庫進行復雜的標簽計算后,通過簡潔清晰的界面展示給用戶。
2.2 構建用戶畫像流程
用戶畫像構建流程如圖2 所示。 就是將數據通過一系列操作轉換成映射的方法,以數據為驅動力推動用戶畫像的構建。 先是將用戶的性別、郵箱、地址等屬性數據和行為、興趣愛好等行為數據進行收集,然后利用相關機器學習算法對用戶數據做標簽化轉換并進行用戶畫像建模,最后根據用戶畫像模型進行分析和可視化[6]。
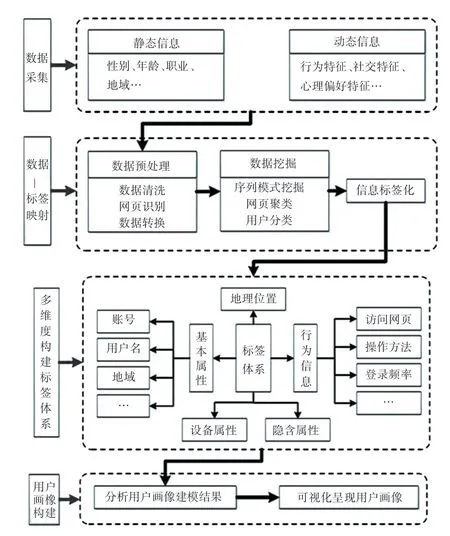
圖2 用戶畫像構建流程圖Fig. 2 User portrait building flowchart
3 系統功能設計
3.1 標簽體系的建立
標簽體系是根據已注冊用戶的偏好、行為習慣和人口屬性等不同的領域而建立起來的[7]。 標簽體現劃分需求分析見圖2,按領域可以分為人口屬性、商業屬性、行為屬性和用戶價值四類。
按具體的實現方式分為規則標簽、統計標簽和挖掘標簽。
在本項目中,標簽體系按照業務類型劃分為基礎標簽和組合標簽。 按領域可以劃分為:人口屬性、用戶的社會特征相關標簽;商業屬性、電商平臺中購物相關的標簽;行為屬性、電商平臺中的瀏覽、購買等行為標簽。
按實現方式劃分為:規則標簽、通過匹配標簽的屬性值實現標簽的業務邏輯;統計標簽、使用數學統計方法實現標簽業務邏輯;挖掘標簽、使用數據挖掘算法實現標簽的業務邏輯。
按業務類型劃分為基本標簽和組合標簽。 其中,基本標簽描述基本屬性,如性別、民族、職業等。組合標簽是多種基本屬性組合而成的,如高凈值用戶就是學歷、消費能力、房產屬性的組合。
3.2 標簽挖掘流程與算法
標簽挖掘與算法總體流程如圖3 所示,對于挖掘類型標簽開發來說,分為2 步:
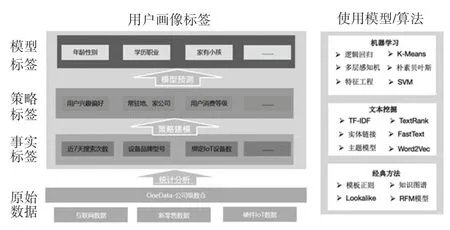
圖3 標簽挖掘流程與算法圖Fig. 3 Label mining process and algorithm diagram
(1)構建算法模型。 構建算法模型從業務數據中獲取算法特征數據(features),此外如果是監督學習算法,需要標注數據(label)。 流程包括業務數據、特征工程、訓練模型、最佳模型、保存模型、標注數據、特征轉換、特征提取、算法超參數和模型評估[8]。
(2) 模型預測值。 加載模型(算法模型提取訓練好,保存起來),封裝方法(loadModel),如果模型不存在,使用數據訓練,獲取最佳模型,并保存起來。predictionDF 結合屬性標簽規則,給每個用戶標注上具體的標簽值。
3.3 標簽體系的存儲
系統所涉及標簽數據存儲在MySQL 數據庫中。對于標簽表和模型表,標簽表負責存儲基礎標簽,主要存儲標簽名稱、標簽規則、等級等基本信息。 模型表存儲每個4 級標簽,具體Spark 應用程序的相關信息。 存儲標簽數據時,也將標簽數據同步存儲到Elasticsearch 索引中,方便使用標簽進行用戶查詢,基于Elasticsearch 為HBase 表構建二級索引。
3.4 標簽模型開發流程
每個標簽模型開發流程如圖4 所示。 首先是標簽管理平臺新建標簽,然后開發標簽模型,最后調度執行。
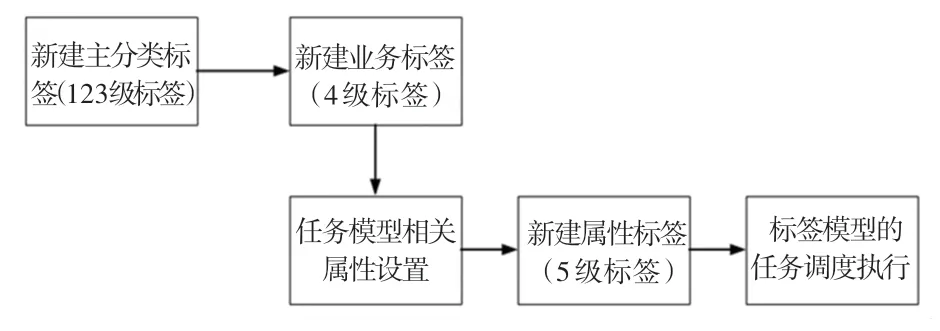
圖4 標簽模型開發流程圖Fig. 4 Label model development flow chart
3.5 標簽調度
標簽調度如圖5 所示。 主要是基于Oozie 實現Web 管理平臺和Yarn 計算平臺的調度,方便計算任務的管理。 Oozie 在這里發揮公共協同的作用,所有的標簽(模型應用)都需要使用Oozie 來進行調度、執行標簽計算。
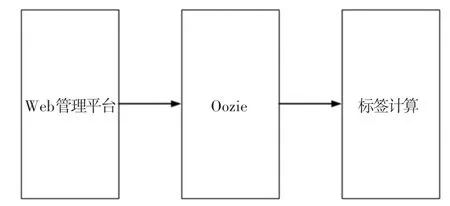
圖5 標簽調度流程圖Fig. 5 Label scheduling flowchart
3.6 標簽管理平臺設計
標簽管理平臺前端使用Vue,后端開發使用SpringBoot,這個管理平臺主要負責對標簽的創建/查詢等進行操作,并且對標簽運行狀態等進行管理。開發人員可以使用平臺并應用JAR 包上傳相應的標簽計算,啟動標簽計算任務,方便標簽管理[9]。
3.7 標簽模型計算
標簽模型計算如圖6 所示。 主要負責根據原始表數據以及MySQL 中的預先設置的標簽規則進行相應的計算,比如對規則匹配型、統計型和數據挖掘型等標簽有關的計算操作,最終得到用戶的標簽結果,并將其存儲到HBase 中。 這里需要注意的是,在保存到HBase 的時候,本次的保存一定不能覆蓋掉上次計算的標簽結果,要將歷史的標簽數據和新生成的標簽數據進行合并操作,這樣才能保證數據的完整保存,不會造成數據丟失。 本模塊是用戶畫像的核心,主要負責根據原始數據以及標簽規則進行相應的計算,比如規則匹配/統計/挖掘等相關操作,最終得到標簽結果,將結果存入HBase 中。

圖6 標簽模型計算流程圖Fig. 6 Label model calculation flowchart
4 系統可視化效果實現
用戶畫像模型封裝基于關系型數據庫(PG)和大數據平臺(Hive、Impala)包含基礎標簽與分析類知識標簽,實現用戶特征全貌刻畫,即多種封裝角度,分用戶類型、渠道內容、業務場景進行封裝配置。接口數據實時推送,實現用戶畫像數據實時更新至運營及營銷統一視圖(WeMeta、WeDate、WeSearch等)中進行展現,并實時反饋運營及營銷信息問題,保證數據應用的時效性。 展現UI 封裝依托用戶畫像,將推薦信息配置應用端進行可視化展現,集中活動運營,實現千人千面的運營效果[10]。
用戶數據畫像可視化界面如圖7 所示,涉及年齡分布、消費占比、行業區分比例、新增會員信息、消費記錄、所屬行業分布、用戶偏好、精準營銷、地區分布可視化功能模塊,為企業提供了足夠的信息基礎,能夠幫助企業快速找到精準用戶群體以及用戶需求等更為廣泛的反饋信息。 用戶畫像是在了解客戶需求和消費能力、以及客戶信用額度的基礎上,尋找潛在產品的目標客戶,并利用畫像信息為客戶開發產品。

圖7 用戶數據畫像可視化界面Fig. 7 Visual interface of user data portrait
在用戶消費數據可視化界面中,涉及用戶交易信息、交易量排名、商品分類占比、商品銷量排行、各平臺占比以及城市排行可視化功能板塊,可從多個維度了解用戶的消費數據。 實現了對用戶準確推送其感興趣內容,到后來電商行業借助社交平臺的畫像能力展開營銷推廣,再轉變為電商行業自行根據用戶消費習慣、消費能力進行主動畫像與營銷。
電商可根據用戶消費習慣、消費能力進行主動畫像與營銷。 在了解客戶需求和消費能力,以及客戶信用額度的基礎上,尋找潛在產品的目標客戶,并利用畫像信息為客戶開發產品。 只有對用戶的各個行為指標進行有效的分析,才能設計出讓用戶滿意的產品,最終創建出精準的用戶畫像。
5 結束語
當今的社會,隨著信息技術的發展,數據呈現出指數級增長,利用用戶畫像技術來解決信息匹配問題不僅是在電商領域,還可以在越來越多的領域中得到應用。 本文圍繞著大數據技術構建用戶畫像系統,通過抓取網上客戶數據進行抓取,然后進行數據去重、清洗和標準化等一系列數據處理后,根據實際商業業務需求構建系統框架。 將系統各個組件整合起來,完成搭建工作,并對數據進行處理、再計算出標簽,最后根據相關算法模型構建出用戶畫像模型,從而為下一步的信息匹配、推薦等業務奠定良好基礎。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
數學物理學報(2020年2期)2020-06-02 11:29:24
傳媒評論(2019年4期)2019-07-13 05:49:14
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
