基于機器學習的SAE 患者30 天死亡風險預測模型
2023-04-19 06:38:54肖曉霞龔后武鄭立瑞譚建聰
智能計算機與應用 2023年3期
劉 彬, 肖曉霞,2, 龔后武, 周 展, 鄭立瑞, 譚建聰
(1 湖南中醫藥大學 信息科學與工程學院, 長沙 410208; 2 湖南中醫藥大學 中醫學國內一流建設學科, 長沙 410208;3 東華醫為科技有限公司, 北京 100089)
0 引 言
膿毒癥是由感染引起的全身炎癥反應綜合征,全球發病率較高,每年患膿毒癥的人數約為3 100萬,住院病死率約為17%[1]。 膿毒癥相關性腦病(SAE)是指在患膿毒癥過程中發生的腦功能障礙,是一種比較嚴重的膿毒癥并發癥,也是造成膿毒癥患者死亡的獨立危險因素[2]。 并與人體行為、記憶、認知功能的長期損害密切相關,給患者的家庭和社會帶來沉重的經濟負擔。 仍需指出的是,SAE 患者的死亡率往往高于只患膿毒癥的患者。 格拉斯哥昏迷評分法(Glasgow Coma Scale,GCS) 是一種用來評估病人昏迷程度的方法,滿分為15 分[3],表示意識清楚;12~14 分表示輕度意識障礙;9 ~11 分表示中度意識障礙;8 分以下為昏迷。 Eidelman 等學者[4]的研究表明腦病與醫院死亡率的增加成正相關性,當格拉斯哥昏迷評分(GCS) 為15 分時,死亡率為16%,而當GCS分數為3 到8 分時,死亡率為63%。 Sonneville 等學者[5]的研究也得出了類似的結論,研究顯示當GCS分數為15 時,患者30 天生存率為67%;當GCS分數為3~8 分時,30 天生存率下降到32%。 即使發生輕度意識障礙(GCS分數為12~14)也是影響30 天死亡的一個獨立危險因素。綜上表明,SAE 對于膿毒癥患者短期死亡率的增加是有影響的,而這將進一步影響患者的健康,同時加重醫療資源的消耗。
基于上述問題,識別出短期死亡率較高的SAE患者,有利于及時進行醫療干預,對于改善這類患者的預后也具有重要的意義。 因此本研究的主要目的是通過大型的臨床數據庫MIMIC 去提取相應的SAE 患者數據,然后通過rfe 算法[6]對相應特征進行篩選,選出影響SAE 患者30 天死亡率的重要特征,最后基于這些特征構建機器學習模型,用于改善SAE 患者的預后。
1 算法原理
1.1 RFE 特征篩選
特征遞歸消除(Recursive Feature Elimination,RFE)是一種用來衡量特征變量重要性的方法,通過重復構建模型,逐步迭代選出最重要的特征變量,能夠尋找出最優的特征子集,剔除不重要的特征變量。具體運算步驟如下:
(1)設定需要進行選擇的特征數。
(2)選擇一個基模型來進行多輪訓練, 每次訓練將J(k)=(wk)2作為每個特征的排序準則,并且每次迭代去除排序最后需要移除的特征數量。
(3)基于新的特征集進行下一輪訓練,直至特征個數為特征設定值。
本文選擇的基模型為XGBoost 模型,對總計17個特征進行篩選。
1.2 邏輯回歸
邏輯回歸[7]是一種廣義的線性回歸模型,屬于機器學習中的監督算法,主要是用來解決二分類問題。 該算法首先通過輸入數據擬合出一條直線z =wTx +b,顯然這樣的函數圖像是一條斜線,難以達到最終想要的結果(0 或1),于是要將z通過一個函數映射成0~1 之間的數,這個函數就是sigmoid函數,式子如下:
然后,通過極大似然估計推導出損失函數:
最后,通過梯度下降法求解出式(2)中的參數,從而解決了二分類問題。
1.3 GBDT
GBDT(Gradient Boosting Decision Tree)是一種基于決策樹的集成算法。 算法采用將基函數線性組合的方法[8],在訓練過程中使得殘差不斷地減小,最終實現數據回歸或者分類。 GBDT 算法的訓練過程具體如圖1 所示。
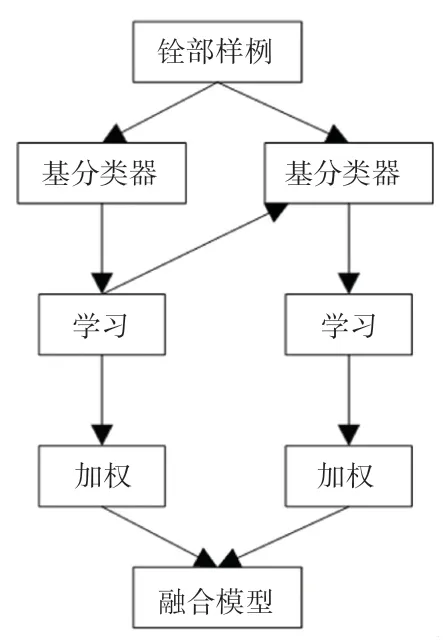
圖1 GBDT 算法訓練過程Fig. 1 GBDT algorithm training process
GBDT 通過多輪迭代,產生多個弱分類器,每個分類器在上一輪分類器的梯度(如果損失函數是平方損失函數,則梯度就是殘差值)基礎上進行訓練。弱分類器一般會選擇CART TREE(分類回歸樹),這種樹具有結構簡單、高偏差、低方差的特點,因此十分適合用于GBDT 算法的訓練中。
1.4 XGBoost
XGBoost 算法[9]是在GBDT 算法的基礎上發展而來的,主要改進有:算法不僅可以使用CART 分類回歸樹,還能使用線性基礎模型;在目標函數中加入了正則化項,用來防止模型出現過擬合;借鑒了隨機森林的原理,支持列抽樣,不僅能降低過擬合,還能夠減少模型的計算量;考慮到了訓練數據為稀疏值的情況,能為缺失值指定分支的默認方向,從而提高算法效率。
2 數據與方法
2.1 數據來源
MIMIC[10](Medical Information Mart for ICU)是一個大型的、免費提供的數據庫,其中包括來自美國馬薩諸塞州波士頓貝斯以色列女執事醫療中心重癥監護病房住院病人的高質量健康相關數據,數據包括生命體征、藥物、化驗數據、護理人員的觀察和記錄、輸液、手術、診斷代碼、成像報告、住院時間、生存數據。 MIMIC 數據庫到現在已經發布4 個版本。MIMIC-II 中包含2001 ~2008 年的數據,MIMIC-Ⅲ包含2001 ~2012 年的數據,MIMIC-IV 包含2008 ~2019 年的數據。 本文將基于MIMIC-IV 數據庫抽取相應的SAE 患者數據。
2.2 數據抽取
SAE 被定義為膿毒癥患者中GCS分數小于15的患者。 研究使用的主要軟件為Navicat Premium(15.0.12 版本), 按 照 關 鍵 字[11]“ s - epsis”、“severe sepsis”、“septic shoc-k”從數據庫中搜索被診斷為“膿毒癥”、“嚴重膿毒癥”、“膿毒癥休克”患者的原始數據。 根據以往研究,確定好納排標準后進一步篩選患者。 患者篩選的詳細過程如圖2 所示。
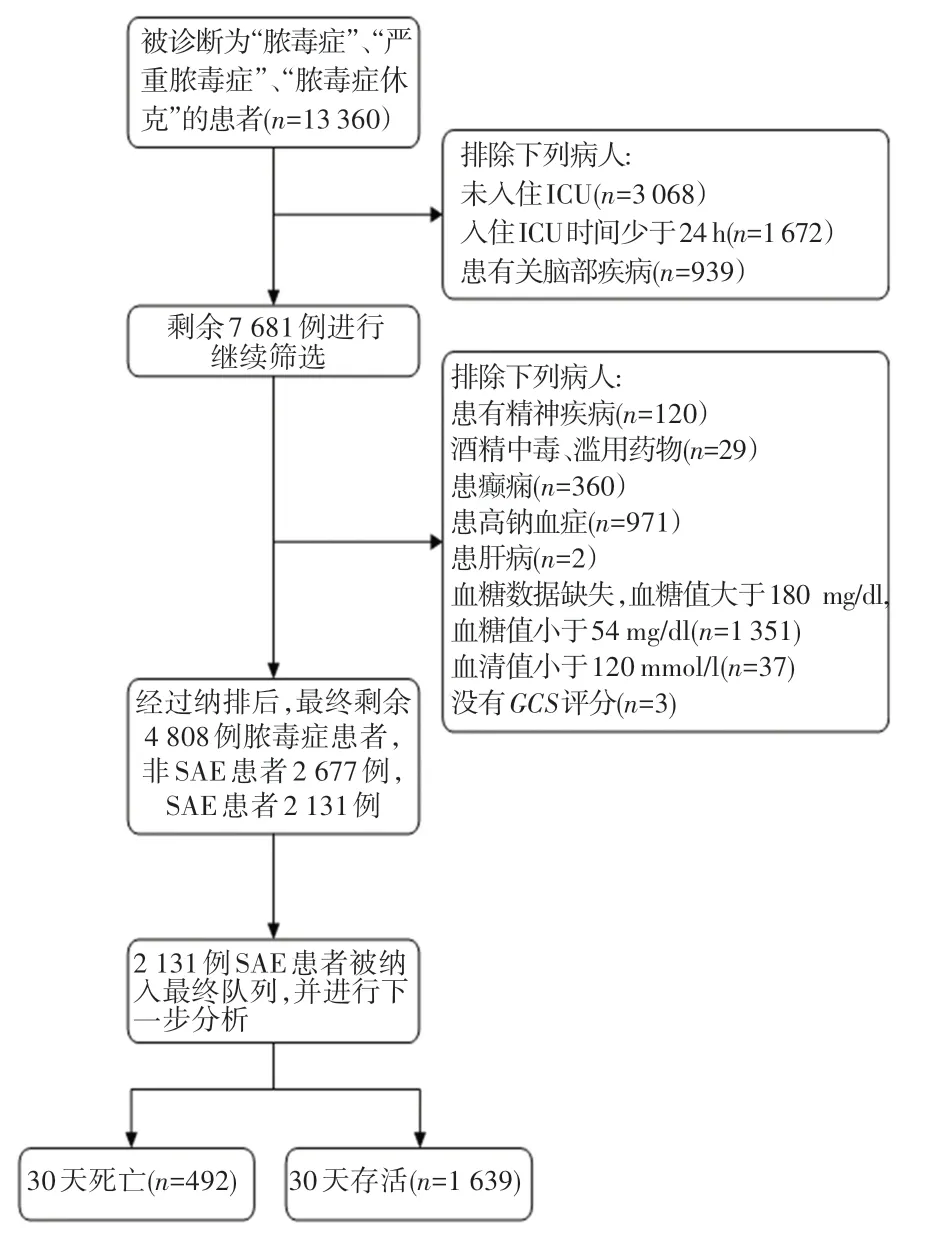
圖2 患者篩選圖Fig. 2 Patient screening
確定最終的SAE 患者后,根據此前的研究文獻,從MIMIC 數據庫中提取患者首次入院時對應的年齡(anchor_age)、性別(gender)、住院天數(day)、葡萄糖(glucose)、鈉(sodium)、GCS 分數(gcs)、血小板( platelet)、 肌 酐 ( creatinine )、 血 紅 蛋 白(hemoglobin)、鉀(potassium)、血尿素氮(BUN)、白細胞(WBC)、乳酸鹽(lactate)、血漿凝血酶原時間(PT)、心率(heart_rate)、血氧飽和度(spo2)、呼吸速率(respiratory_rate)、30 天是否死亡(morality)。 數據總計17 個特征屬性,再加一個類別標簽屬性,其中類別標簽表明患者是否在患病30 天內死亡。
2.3 數據預處理
提取了數據后,對數據的缺失情況進行統計,結果見表1。
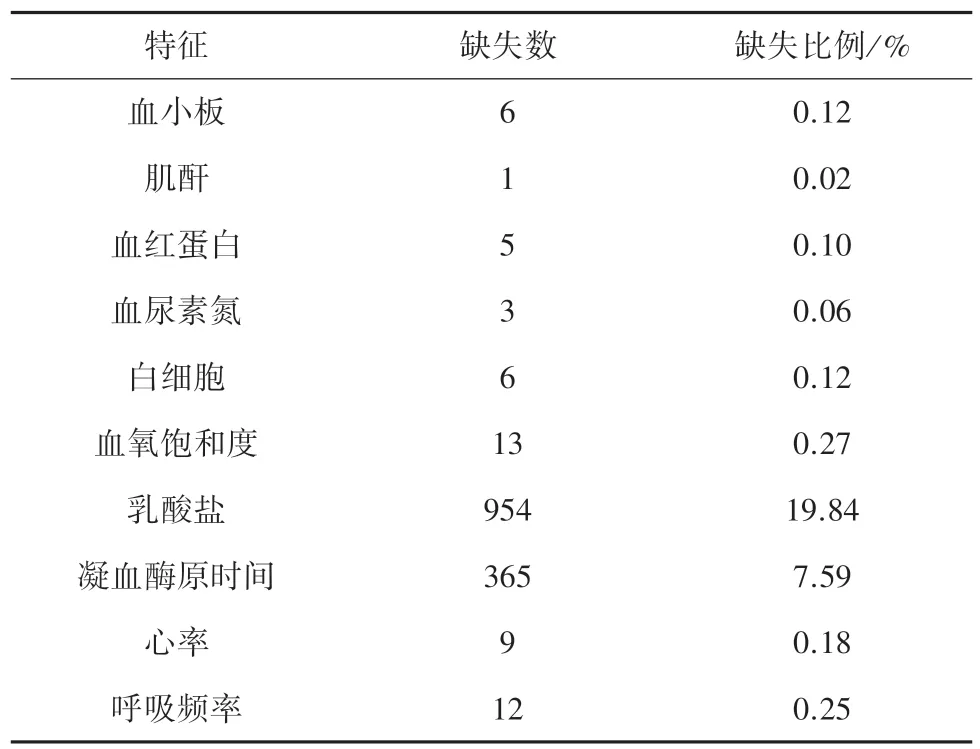
表1 數據缺失情況表Tab. 1 Data missing table
從表1 的結果中可以看出10 個特征存在數據缺失的問題,缺失最多的特征是乳酸鹽,缺失比例為19.84%,缺失最少的是肌酐,僅缺失一例。 根據文獻[8]中對缺失數據的處理方法來看,缺失特征比例均小于20%,予以保留,并統一采用平均值對其進行填補,在此基礎上將對數據進行具體分析。
3 結果
3.1 納入病例的基本信息
總計納入4 808 例膿毒癥患者,其中2 131 例為SAE 患者。 SAE 患者年齡為19 ~91 歲之間,中位年齡數為68 歲。 男性為1 127 例,女性為1 004 例。30 天內死亡病例為492 例,存活病例為1 639 例,數據分布較為均衡。
3.2 篩選得到的特征變量
根據RFE 特征篩選,每一輪篩選移去特征系數(wk)2最小的特征,直到特征個數為設定值。 結果顯示,當特征數設定為13 時,3 個模型中GBDT 的AUC值最高,其在測試集上AUC為0.783。 此時選出的13 個特征分別為:年齡、住院天數、鈉、GCS 分數、血小板、肌酐、鉀、血尿素氮、乳酸鹽、血漿凝血酶原時間、血氧飽和度、心率、呼吸速率。
3.3 實驗結果
將SAE 數據集按照7:3 的比例隨機劃分為訓練集和測試集進行訓練。 本文采用的評價指標為準確率、P值、R值、F1值、AUC值。 具體的實驗結果見表2、表3。
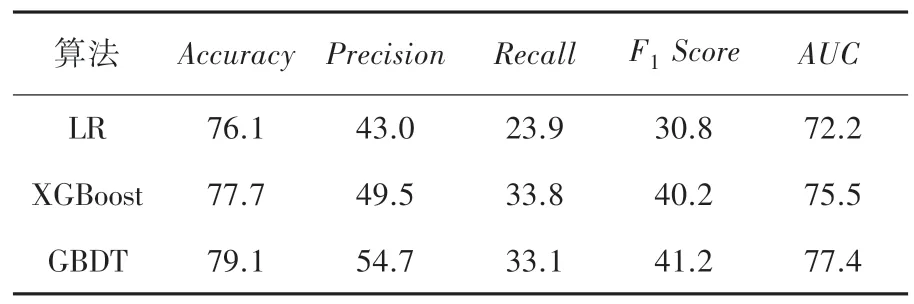
表2 未進行特征篩選結果Tab. 2 No feature filtering results
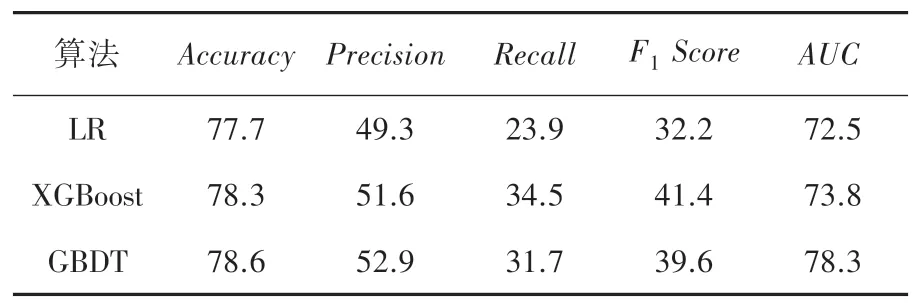
表3 特征篩選后結果Tab. 3 Results after feature screening
從表2 和表3 中可以看出,數據集經過特征篩選后,3 個模型的某些指標得到了提高。 邏輯回歸模型的準確率提高了1.6%、精度提高了6.3%、F1值提高了1.4%、AUC值提高了0.3%;XGboost 模型的準確率提高了0.6%、精度提高了2.1%、召回率提高了0.7%、F1值提高了1.2%;GBDT 模型的AUC值提高了0.9%。
為了更直觀地比較3 個不同算法的性能,繪制的ROC曲線如圖3 所示。
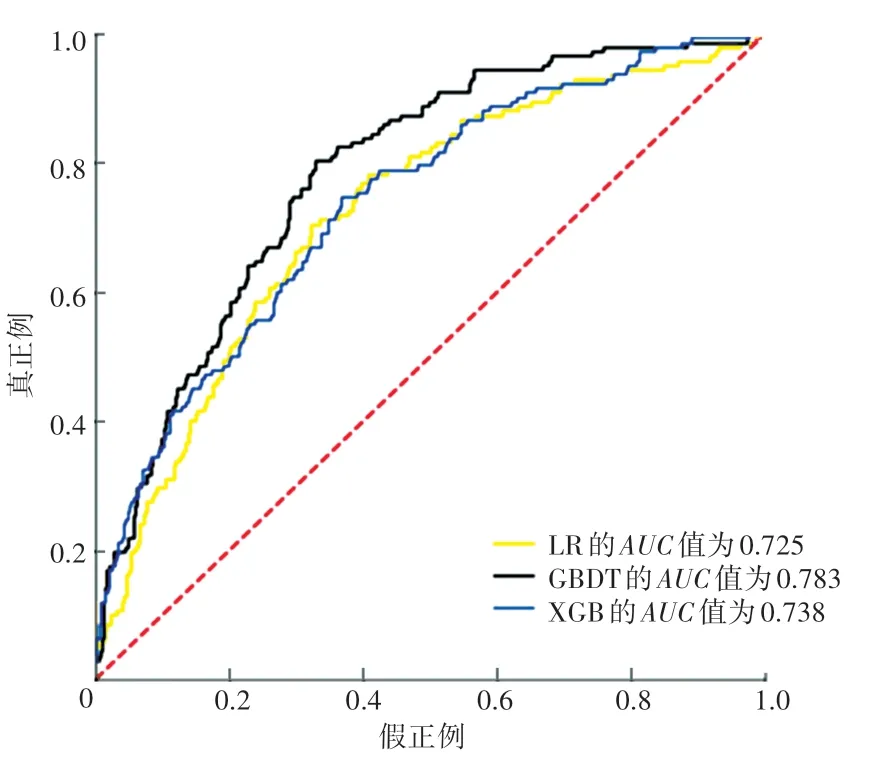
圖3 3 種分類算法的ROC 曲線Fig. 3 ROC curves of three classification algorithms
從圖3 中可以看出,在3 個算法中GBDT 算法的AUC值最大、為0.783,說明GBDT 算法性能最優,更適合用于SAE 患者30 天死亡預測。
4 分析與討論
在這項基于MIMIC-IV 數據庫的研究中,從MIMIC 數據庫中抽取出對應的SAE 患者數據,然后使用了RFE 特征選擇,篩選出了與SAE 患者30 天死亡率相關的危險因素,最后基于這些特征建立了3 個機器學習模型去對SAE 患者30 天死亡進行預測。 其中,GBDT 算法對于SAE 患者30 天死亡預測效果最佳,其精度為52.9%,準確率為78.6%、AUC值為78.3%,3 個指標均為不同算法中最高的。 與其它研究方法進行對比,文獻[3]提出的列線圖模型在訓練集上的AUC值為0.763,在驗證集上的AUC值為0.753,均比本文提出的GBDT 算法的AUC值略低。 說明本文提出的模型性能更優、泛化能力也更強。 目前,對于SAE 的治療是具有挑戰性的,有許多關于膿毒癥的指南列出了各種治療膿毒癥的建議,但卻很少有治療SAE 的建議。 有關SAE 患者死亡預測的研究也較為匱乏,本研究很好地彌補了這方面的空白。 從應用價值來看,本文提出的GBDT 預測模型能夠輔助臨床醫生去評估SAE 患者的預后,從而制定出相應的治療措施,降低患者死亡率。 一旦研究出針對SAE 的具體治療方法,該模型的應用價值就會更高。 未來可以開發一款能嵌入電子醫療系統的軟件,該軟件能夠在不增加臨床醫生工作時間和負擔的情況下,輔助臨床醫生及時治療SAE。
5 結束語
本文基于MIMIC 數據庫,提取相應的膿毒癥患者數據,并通過GCS分數進一步篩選出SAE 患者的數據。 然后經過RFE 特征篩選,篩選出13 個重要的特征。 使用邏輯回歸、XGBoost、GBDT 三種算法基于篩選后的特征進行建模,實驗結果表明,GBDT算法更適合用于SAE 患者30 天死亡預測,其AUC值為78.3%,高于其他2 種算法,也比其他文獻中的方法略好。 對于SAE 患者的預后具有一定的參考價值。
本次研究也存在局限性,即只對該數據庫進行了內部驗證,在今后的研究中還需要根據其它的數據進行外部驗證,以進一步檢驗模型的魯棒性和性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
