基于BERT 和交互注意力的方面級情感分類模型
2023-04-19 06:37:50袁逸飛單劍鋒
智能計算機與應用 2023年3期
袁逸飛, 單劍鋒
(南京郵電大學 電子與光學工程學院, 南京 210023)
0 引 言
情感分析是當前自然語言處理領域的重要分支之一。 而基于方面級的情感分類任務將情緒分類又推進了一步。 通常情況下,如果只知道一個句子或者文檔的極性雖然有一定的作用,但不能分辨出極性是針對誰,于是方面級的情感分類應運而生[1]。任務描述如圖1 所示。
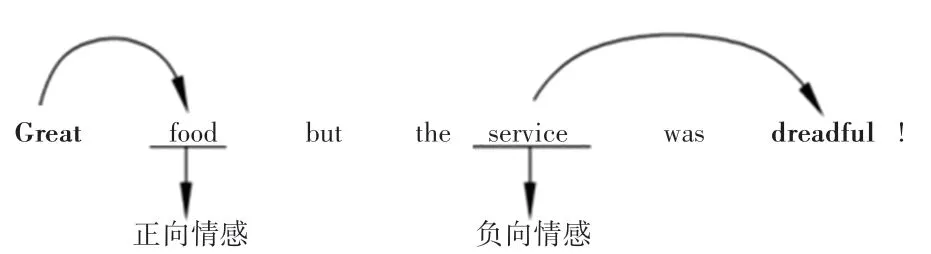
圖1 方面級情感分類任務實例Fig. 1 Task instance of aspect level sentiment classification
當前,神經(jīng)網(wǎng)絡模型已越來越多地用在方面級的情緒分類中[2-4]。 現(xiàn)有的研究大多采用監(jiān)督學習的方法構建情感分類器,比如基于特征的支持向量機[5]、基于神經(jīng)網(wǎng)絡的方法[6],大多數(shù)基于注意力機制的模型沒有考慮上下文與方面詞之間的交互信息。 Ma 等學者[7]提出交互注意力網(wǎng)絡,但是研究中使用的雙向長短期記憶網(wǎng)絡(BiLSTM)可能存在在小數(shù)據(jù)集下表現(xiàn)不如雙向門控單元(BiGRU)的結果,同時傳統(tǒng)的詞向量工具word2vec 不能很好地表征出每個詞的向量,不能產(chǎn)生一詞多義的效果,在實際的操作中,則無法獲取最終想要的向量。 受文獻[8]的啟發(fā),本文以BiGRU 為基礎,提出面向方面級情感分類的模型。 首先使用BERT 預訓練語言模型進行詞嵌入,并通過BiGRU 獲得輸入向量間的隱藏向量,接著分別輸入多頭自注意力層和交互注意力層,最后兩者拼接得到結果。
1 相關工作
在最初的基于機器學習方法中,方面級的情感分類被視作一個文本分類的任務。 樸素貝葉斯和支持向量機的方法可以不再需要方面詞就可預測情感極性。 但是這類方法有個無法避免的缺陷,即要依賴情感詞典和手工設計的特征。 就使得訓練結果強烈依賴手工設計的特征的質量,同時,由于特征都是手工標記,所以特征數(shù)量有上限的,預測精度也隨之遇到瓶頸。
2 相關技術及BiIAGRU-BERT 模型
模型由詞嵌入層、語義學習層、注意力層和融合層組合而成。 為了便于理解, 文本上下文使用S={ω1,ω2,…,ωt,…,ωt+l,ωn}表示,其中,n表示上下文中詞的個數(shù),方面詞為{ωt,…,ωt+l}。 這里,t和l分別表示詞的位置和方面詞的長度。
2.1 詞嵌入層
傳統(tǒng)使用的是Word2Vec、FastText、Glove 等方法。 但是本文引入BERT 預訓練模型。 BERT 模型相比傳統(tǒng)的其他方法,主要是引入了注意力機制,同時解決了傳統(tǒng)方法不能做到的一詞多義問題,BERT 預訓練模型是基于語義理解的深度雙向語言模型,由Google 的Devlin 等學者[9]于2018 年10 月提出的預訓練模型。 模型用的是比Word2Vec 更強大 的 雙 向 Transformer 編 碼 器, 是 基 于 多 層Transformer 編碼器演化而來的。 每句話采用[CLS]開始,[SEP] 結束,并以遮蔽語言建模(Masked language model) 和 下 一 句 話 預 測(next sentence prediction)為無監(jiān)督目標,因此具有了更強的詞向量抽象能力,BERT 在大量任務中都獲得了相比Glove而言更好的性能。 本文在將[CLS]文本[SEP]、[CLS]方面詞[SEP]作為輸入的基礎上進行了拓展,加入了[CLS]+文本+[SEP]+方面詞+[SEP]的第三個輸入。
2.2 GRU
由于LSTM 內部結構復雜、計算量大,在模型訓練上不僅需要較長的時間,模型所需參數(shù)也較多。
2014 年,提出了GRU 模型[10]。 與LSTM 相比,GRU 模型解決了長短期記憶的問題。 研究可知,GRU 只有2 個門,參數(shù)減少了1/3,因此更易收斂,收斂速度更快,可以大大加速迭代過程。 GRU 模型的單元結構如圖2 所示。 對此模型中用到的數(shù)學方法,可由如下公式分別進行描述:
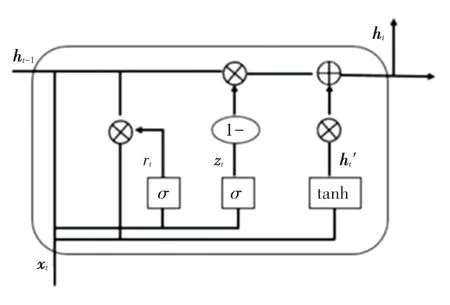
圖2 GRU 神經(jīng)元結構Fig. 2 GRU neuron structure
其中,zt和rt分別表示更新門和重置門;ht是t時刻的激活狀態(tài);ht-1是t -1 時刻的隱層狀態(tài)。 重置門rt控制著前一個狀態(tài)的信息ht-1傳入狀態(tài)。
2.3 BiGRU
在GRU 基礎上,若要當前時刻的輸出能獲取更多信息,故而使用雙向GRU 模型,將順向和反向GRU 相結合,BiGRU 是由2 個GRU 上下正反向合并在一起組成的。 在每一個時刻t,輸入會提供這2個方向相反的GRU,輸出則是由2 個單向GRU 拼接而成。 BiGRU 網(wǎng)絡結構如圖3 所示。
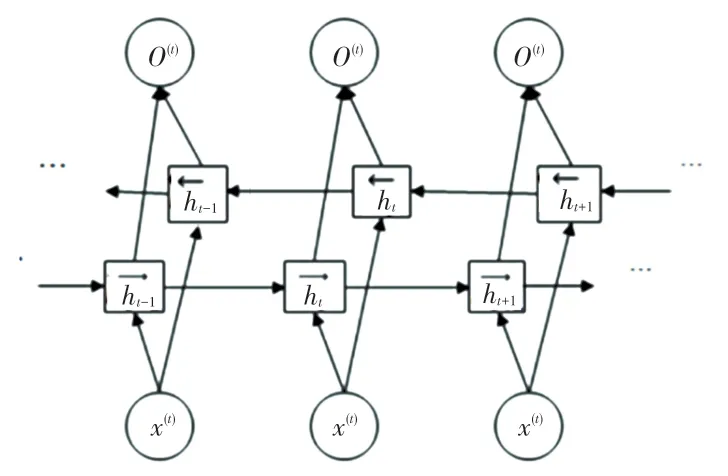
圖3 BiGRU 網(wǎng)絡結構Fig. 3 BiGRU neural network structure
2.4 交互注意力層
其中,tavg是目標表示;γ是計算在上下文中重要性的函數(shù);Wa是權重;ba是偏置項;tanh 是非線性函數(shù);是tavg的轉置。
同理,針對方面詞的表示,見如下:
其中,各個參數(shù)的含義與式(6)相同。 通過計算單詞的注意力權重后,可以利用注意力向量得到上下文cr和方面詞tr的表示,即:
2.5 多頭自注意力層
多頭注意力是指能夠同時執(zhí)行多個注意力函數(shù)。一個注意力函數(shù)映射鍵向量K={k1,k2,…,kn}和查詢向量Q={q1,q2,…,qm} 作為輸出向量。 同時,計算一組查詢Q上的注意力函數(shù),用到的公式為:
其中,fs表示對齊函數(shù),能夠學習qj和ki之間的語義關系;Watt∈U2dhid是可學習的權重。
多頭注意力機制可同時關注來自并行子空間中學習n個不同的分數(shù),并且在對齊方面的功能尤為強大。n頭的輸出是串聯(lián)起來投射到特定隱藏維度dhid,推得的數(shù)學公式具體見如下:
其中,Wmh∈Udhid×dhid表示向量的拼接;om是第m個注意力頭的輸出;m∈ [ 1,nhead] 。
多頭自注意力是一種q =k的特殊情況。 給定一個上下文的詞嵌入向量ec,可以得到多頭自注意上下文表示:
3 模型實現(xiàn)
本文給出的模型框架如圖4 所示。 由圖4 可看到,主要由詞嵌入層、特征提取層、詞級交互注意力層、輸出層組成:

圖4 BiIAGRU-BERT 模型的整體框架Fig. 4 BiIAGRU-BERT model structure
(1)詞嵌入層。 使用預訓練BERT 模型進行詞嵌入,將訓練數(shù)據(jù)輸入。
(2)特征提取層。 BiGRU 對詞向量進行編碼,用于提取語義特征。 前一個隱層的輸出是后一個隱層的輸入,最后得到隱藏層。
(3)詞級交互注意力層。 將方面詞和上下文的隱藏層分別進行池化,提取出其中的特征。
(4)多頭自注意力層。 計算每個詞向量和其它詞向量之間的關系。
(5)輸出層。 將得到的局部特征和全局特征進行融合,再經(jīng)過softmax歸一化操作,得到最終的情感預測結果。
3.1 實驗平臺與實驗數(shù)據(jù)
本 文 選 取 Twitter 數(shù) 據(jù) 集[11], SemEval2014 Task4 中Restaurant 和Laptop 的數(shù)據(jù)集,其中極性分成消極、中性、積極三種,具體見表1。
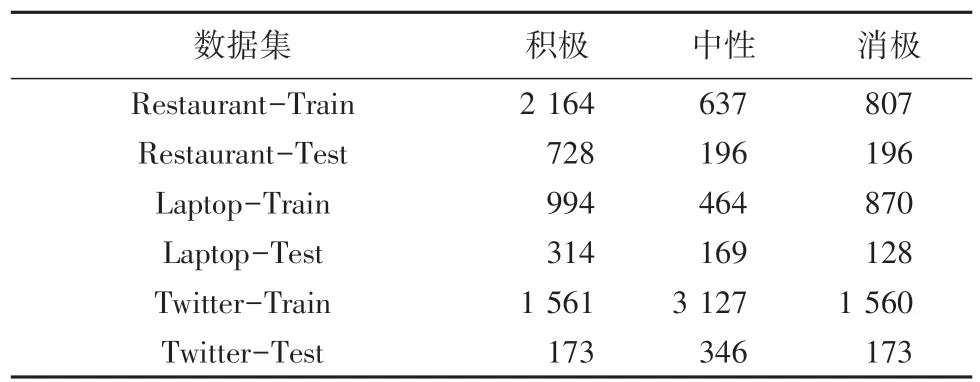
表1 數(shù)據(jù)集信息Tab. 1 Data set
3.2 實驗參數(shù)設置
BERT 詞向量維度設置為768,用正態(tài)分布對權重矩陣進行初始化,偏差初始化為0。 在訓練中,用Adam 優(yōu)化器更新參數(shù)。 設置Batch為16,學習率為5e-5。 實驗軟硬件環(huán)境見表2。
表2 實驗環(huán)境Tab. 2 Experimental environment
3.3 實驗結果分析
為了全面地評價網(wǎng)絡的性能,列出了一些基線模型方法進行比較,對比的基線模型介紹如下。
(1)SVM[12]:支持向量機,通過人工構造特征,引入外部情感詞典完成分類。
(2)LSTM:LSTM 模型,只使用LSTM 對上下文進行處理。
(3)Bi-LSTM[13]:直接將文本輸入LSTM,只是從前后有雙向的LSTM。
(4)TD-LSTM[14]:用了2 個LSTM 模型,分別輸入左半部分的上文帶上方面詞,右半部分的下文帶上方面詞。
(5)ATAE-LSTM[15]:提出了融合方面信息的LSTM 和注意力機制的模型。 能夠通過注意力機制只關注特定方面。
(6)IAN:用LSTM 對方面詞和句子分別建模,并通過注意力機制,分別對其中的隱層進行提取,再進行拼接得到情感分類。
(7)RAM[16]:循環(huán)注意力網(wǎng)絡,提出循環(huán)注意力機制,多跳數(shù)目設置為3。
(8)BiIAGRU-BERT:基于BERT 的交互注意力模型,即本模型。
仿真實驗對比結果見表3。 實驗結果表明,加入方面信息和交互注意力能夠顯著改善分類效果。因為LSTM 神經(jīng)網(wǎng)絡相對復雜且在小數(shù)據(jù)集下的效果不如GRU,因此本文采用GRU 作為特征提取層。BiIAGRU-Glove 模型證明,效果比僅有交互注意力IAN 模型和注意力 ATAE - LSTM 模型要好。BiIAGRU-BERT 和BiIAGRU-Glove 具有相同的模型結構,不同的是前一個模型采用的是BERT 預訓練模型,結果表明與BERT 模型相結合能在方面級情感分類任務中取得更好的效果。

表3 實驗結果對比Tab. 3 Experimental results of different models
4 結束語
本文提出一個基于注意力編碼器與交互注意力網(wǎng)絡模型,采用基于注意力的編碼器對上下文和目標之間建模,還將預訓練模型BERT 應用到模型中,結果表明能夠提高方面級情感分類的準確率和F1值,達到了較好的分類的效果。 實驗結果表明注意力機制結合BERT 預訓練語言模型在基于方面級的情感分類任務中的有效性。
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
