深度強化學(xué)習(xí)技術(shù)在地外探測自主操控中的應(yīng)用與挑戰(zhàn)
2023-04-19 06:07:04高錫珍湯亮黃煌
航空學(xué)報 2023年6期
高錫珍,湯亮,黃煌
1.北京控制工程研究所,北京 100094
2.空間智能控制技術(shù)重點實驗室,北京 100094
地外探測從最近的月球逐步延伸到越來越遠的火星、小行星等天體,探測方式從掠飛環(huán)繞,逐漸進步到著陸巡視和采樣返回[1]。地外探測自主操控(Autonomous Manipulation)是在環(huán)境不確定下,不依賴于地面測控,僅依靠自身敏感器和控制裝置,根據(jù)實時獲取的環(huán)境信息及時調(diào)整自身狀態(tài),并自主完成空間規(guī)定動作或任務(wù)的技術(shù)手段,其應(yīng)用主要包括定點著陸、移動巡視、近距離操作、取樣采集等任務(wù)。地外星表探測器中美國“好奇號”火星車具備7 m 范圍內(nèi)自主選擇探測目標的能力,能夠自主識別探測目標[2]。“洞察號”探測器具備厘米級的操作精度,可實現(xiàn)著陸點附近鉆探取樣[3]。中國“嫦娥3 號”實現(xiàn)復(fù)雜地形自主懸停避障[4],“嫦娥5 號”探測器通過表取和鉆取2 種操作方式成功實現(xiàn)了月球探測采樣返回[5]。目前地外探測自主操控能力有限,主要采用“地面遙操作+有限自主”的半自主探測方式,大部分時間由地面根據(jù)有限的遙測數(shù)據(jù)和圖像,對周圍環(huán)境進行分析判斷后,將決策指令信息及時傳送到探測器并使設(shè)備按預(yù)期要求運行。
但地外探測面臨環(huán)境復(fù)雜不確知、通訊時延大、以及器上資源約束嚴苛之間的沖突,僅靠傳統(tǒng)方法或技術(shù)優(yōu)化改進難以從根本上提升在復(fù)雜無約束地外環(huán)境的自主能力,導(dǎo)致危險識別難,操控作業(yè)精度低,降低了探測效能。隨著新一代人工智能技術(shù)的發(fā)展,通過積累經(jīng)驗、持續(xù)學(xué)習(xí)并生成知識,提升探測器的自主智能水平,實現(xiàn)在陌生、未知不確定探測環(huán)境中類人操控,是解決上述問題的有效途徑。目前各國已開展將人工智能引入地外探測無人系統(tǒng)的探索性研究[6],“毅力號”“好奇號”任務(wù)分別開展了基于深度學(xué)習(xí)的地形分類、車輪打滑預(yù)測等研究[7]。強化學(xué)習(xí)通過與環(huán)境不斷交互,從而試錯學(xué)習(xí)到當前任務(wù)最優(yōu)或較優(yōu)的策略,“機遇號”在火星運行15 a 獲得了大量交互數(shù)據(jù),展現(xiàn)了強化學(xué)習(xí)在地外探測中應(yīng)用的巨大潛力。而未來地外探測任務(wù)復(fù)雜多樣,深度強化學(xué)習(xí)(Deep Reinforcement Learning, DRL)融合了深度學(xué)習(xí)強大的特征表示能力和強化學(xué)習(xí)高效策略搜索能力,可在線實時感知信息進行推理并執(zhí)行合理操作,主動適應(yīng)地外星表環(huán)境,從而全自主地開展表面著陸巡視、多地取樣歸集、移動采集和設(shè)施建造等操控任務(wù),具有廣闊的應(yīng)用前景。
本文圍繞地外探測任務(wù)對自主操控的需求,首先總結(jié)了地外探測操控任務(wù)的發(fā)展現(xiàn)狀,通過分析地外探測操控任務(wù)的特點,總結(jié)出地外探測自主操控面臨的挑戰(zhàn)與難點,然后對現(xiàn)有基于深度強化學(xué)習(xí)的操控算法進行概括,接著以地外探測自主操控任務(wù)難點為驅(qū)動,對深度強化學(xué)習(xí)技術(shù)在地外探測操控中的應(yīng)用成果進行了綜述與分析。最后結(jié)合上述難點問題及未來任務(wù)需求,概括了智能操控在地外探測應(yīng)用和發(fā)展中需要突破的關(guān)鍵技術(shù)問題。
1 地外探測操控任務(wù)概況
操控能力是反映自主能力高低的關(guān)鍵因素之一,通過評估危險、規(guī)劃安全軌跡、到達感興趣的目標,使安全高效地完成地外探測任務(wù)成為可能。目前地外探測完成了在不確定環(huán)境下著陸巡視,探測設(shè)備部署和取樣分析等復(fù)雜操控任務(wù)。已有典型地外探測器的操控能力如表1所示。

表1 地外探測操控能力現(xiàn)狀Table 1 Manipulative ability of celestial body explorers
在地外探測操控任務(wù)中,采樣探測是拓展探測深度的有效途徑,有助于擴大科學(xué)探測成果。目前,各國地外采樣探測主要通過巡視/著陸器搭載操作臂,進行星表鏟挖和鉆取等交互接觸式操作。美國國家航空航天局(National Aeronautics and Space Administration, NASA)在深空探測任務(wù)中對操作臂探測進行了大量的應(yīng)用,如“海盜號”“勇氣號”“機遇號”“鳳凰號”“好奇號”“毅力號”等火星探測器,依托操作臂實現(xiàn)了自主/半自主式樣品獲取,收集與分析。
中國的“玉兔號”巡視器采樣則采用地面遙控操作為主的控制方式。在“嫦娥3 號”任務(wù)中,考慮操作臂的構(gòu)造特點和科學(xué)探測的各類約束條件,建立了精確的控制算法模型,研發(fā)了操作臂遙控操作控制系統(tǒng),實現(xiàn)了對操作臂毫米量級的精確控制[8]。“嫦娥5 號”任務(wù)首次提出遙操作表取、鉆取的采樣方案,建立了三位一體的天-地交互操作工作模式,實現(xiàn)了高可靠、多樣性的預(yù)定采樣目標[9]。地外探測典型操作臂性能、任務(wù)流程等方案設(shè)計如表2[10-15]所示。

表2 典型采樣操作臂設(shè)計方案Table 2 Design schemes of typical sampling manipulators
地外探測采用操作臂攜帶一定的科學(xué)載荷完成表面科學(xué)目標的探測,從而使得星表探測器具備了強大的星表操作能力。其中“好奇號”巡視器在前200 火星日期間,操作臂參與了大約50%的探測活動[16]。目前地外探測操作臂具有如下特點:
1)探測方式
地外探測不僅有定點和移動巡視探測,還包括采樣收集等復(fù)雜作業(yè)任務(wù)。采樣方式主要有表層鏟挖和深層鉆取2 種方式。為保留樣品的層理特性,采樣方式逐漸從表面探測向土壤底層或巖石內(nèi)部,以及鏟、挖、鉆等混合采樣發(fā)展。
2)采樣機構(gòu)設(shè)計
探測器所攜帶的有效載荷和能源有限,采樣裝置采用輕量化、大負載、高精度和寬采樣范圍設(shè)計。機械臂自由度決定了工作方式和工作空間,考慮結(jié)構(gòu)強度的影響,根據(jù)不同的科學(xué)探測目標和任務(wù)要求,機械臂在設(shè)計時一般不超過4自由度,僅在有樣本轉(zhuǎn)移、設(shè)備抓取等用途,以及探測器本體存在側(cè)傾時,才考慮增加自由度。
機械臂關(guān)節(jié)采用模塊化設(shè)計方式,每個關(guān)節(jié)獨立驅(qū)動,驅(qū)動器主要采用無刷直流電動機,其具有轉(zhuǎn)動平滑,力矩穩(wěn)定,控制簡單,已成功應(yīng)用于“好奇號”“毅力號”探測器等采樣機械臂上。但其裝置結(jié)構(gòu)復(fù)雜,傳動數(shù)量多,在嚴苛空間環(huán)境下,容易發(fā)生機械失效。直線電機,如超聲波電動機,具有低速大力矩和高精度,不需要齒輪減速裝置,可以實現(xiàn)直接驅(qū)動,提高了傳動效率,結(jié)構(gòu)簡單緊湊,可內(nèi)部走線,大大縮小體積空間,滿足未來探測器“質(zhì)量輕、體積小、耗功低”的需求,具有廣闊的應(yīng)用前景。
3)操控策略
操控策略主要通過行星探測車上安裝的雙目視覺測量系統(tǒng)對行星表面目標進行精確定位,然后控制操作臂實現(xiàn)目標就位探測。從技術(shù)角度,操作臂探測目標主要包括視覺系統(tǒng)對探測目標的精確定位和操作臂無碰撞操作規(guī)劃兩部分。
2 地外探測操控難點問題
國內(nèi)外雖然已經(jīng)實施了多次地外探測,但探測效率非常低,在地外天體表面的大部分時間,都處于非移動探測狀態(tài)。“好奇號”巡視器設(shè)計最大移動速度為180 m/h,但在自主避障移動時平均速度僅約54 m/h。截止到2020-03-18,中國“玉兔2 號”月球車在月背存活周期為440 d,但累計行程僅為400 m,平均每個地球日的行程僅約為l m。上述地外探測器之所以探測效率低,是由地外天體探測任務(wù)的固有特點導(dǎo)致的。地外天體探測存在運行環(huán)境嚴苛未知、操作對象物理化學(xué)性質(zhì)不確定以及通訊能力受限等挑戰(zhàn),導(dǎo)致難以實現(xiàn)高效探測。具體原因分析如2.1~2.3 節(jié)所示。
2.1 環(huán)境嚴苛未知
地外環(huán)境復(fù)雜嚴苛未知,地外存在強輻射、大溫差等惡劣因素,而任務(wù)要求高可靠,導(dǎo)致器件選型,通訊等器上資源約束嚴苛,加之有限圖像測量設(shè)備受沙塵影響遮擋嚴重。而形貌原始自然,存在鏈坑、溝壑、陡坡、松軟沙地等非結(jié)構(gòu)化地形,目前地外環(huán)境測量主要對局部幾何環(huán)境識別,對危險識別能力弱,運行風(fēng)險高。此外,地形、地質(zhì)、光照等環(huán)境特點與地面差異大、樣本稀少,操作過程難以仿真,地外探測試驗困難。
2.2 物理化學(xué)性質(zhì)不確定
地外探測操作任務(wù)多樣,在不確定環(huán)境下需要完成著陸巡視、取樣歸集等多種任務(wù)。探測器會面臨車輪破損、動力學(xué)模型發(fā)生變化、低重力下不易控制等問題,同時探測目標形狀、硬度、成分、慣量、質(zhì)量分布等物理化學(xué)特性先驗知識欠缺,精確建模難,使得基于模型和確定試驗環(huán)境的傳統(tǒng)設(shè)計難以實現(xiàn)精準柔順操控,環(huán)境的主動適應(yīng)能力差,無法勝任定點著陸、安全巡視、柔順取樣等復(fù)雜操作任務(wù)。
2.3 通訊能力受限
由于天地時間通信鏈路和帶寬限制,天地之間的信息交互存在非常大時延。目前,最先進的“毅力號”火星車可與地球直接通信或通過火星軌道器進行中繼通信。與地球直接通信數(shù)據(jù)傳輸速率為3 kbps,與火星軌道器的數(shù)據(jù)傳輸速率為2 Mbps,但火星軌道器,如“奧德賽號”與地球的帶寬為256 kbps。火星和地球之間傳播大約需要5~20 min。同樣,中國“玉兔號”月球車一次移動絕大部分時間耗費在信息傳輸和地面處理上。因此“地面遙操作+有限自主”的探測方式,難以對復(fù)雜不確定環(huán)境及操作過程作出及時有效的反應(yīng),可能破壞或污損高價值目標,導(dǎo)致探測效能極低,甚至威脅自身安全。
上述難點問題直接或間接導(dǎo)致“勇氣號”車輪陷入松軟的火星土壤中[17];“洞察號”鉆探到50 cm 時,難有寸進,且偏離原定軌跡15°,最終任務(wù)被迫終止[18];“好奇號”遇到巖石下方的松軟層時,難以取回樣品[19];“毅力號”采樣目標巖石特性未知,首次采樣失敗[20]。圖1[17-20]分別展示了地外探測操控任務(wù)所遇到的上述幾個問題的典型案例。

圖1 地外探測操控任務(wù)所遇到的幾個問題典型案例[17-20]Fig.1 Typical cases diagram showing several problems encountered in celestial body exploration missions[17-20]
3 基于深度強化學(xué)習(xí)的操控方法
深度強化學(xué)習(xí)將深度學(xué)習(xí)的感知能力和強化學(xué)習(xí)的決策能力相結(jié)合,可以直接根據(jù)輸入進行決策與控制,是一種更接近人類思維方式的智能方法[21]。根據(jù)學(xué)習(xí)方式不同,即目標策略和行為策略是否一致(其中目標策略是算法需要評估的策略,而行為策略是智能體與環(huán)境交互時所采取的策略),深度強化學(xué)習(xí)分為在策略和離策略兩種方法。此外,深度強化學(xué)習(xí)根據(jù)模型是否完全給定,還可以分為基于模型的強化學(xué)習(xí)和無模型強化學(xué)習(xí)。考慮到地外探測環(huán)境動態(tài)變化和動力學(xué)模型不確知,系統(tǒng)狀態(tài)轉(zhuǎn)移模型建立困難,本節(jié)重點從在策略和離策略兩方面總結(jié)無模型深度強化學(xué)習(xí)方法的研究現(xiàn)狀,并對其操控應(yīng)用進行概括,而對基于模型的深度強化學(xué)習(xí)方法進行簡要總結(jié)。典型的深度強化學(xué)習(xí)算法及其應(yīng)用場景如圖2 所示。
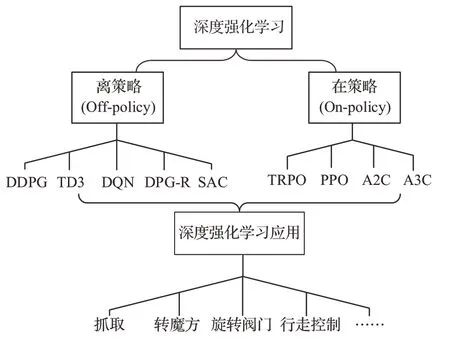
圖2 深度強化學(xué)習(xí)算法分類及應(yīng)用Fig.2 Classification and applications of DLR
3.1 離策略(Off-policy)方法
針對現(xiàn)有條件下目標策略無法有效地執(zhí)行并產(chǎn)生樣本、執(zhí)行目標策略所需要的代價過大等問題,深度Q 學(xué)習(xí)網(wǎng)絡(luò)(Deep Q-learning Network,DQN)用深度神經(jīng)網(wǎng)絡(luò)替代傳統(tǒng)強化學(xué)習(xí)中的價值函數(shù),通過引入樣本池打破樣本間的關(guān)聯(lián)性,得到了獨立分布的樣本,同時引入更新較慢的目標Q 網(wǎng)絡(luò),避免了網(wǎng)絡(luò)震蕩不收斂的問題[22]。DQN 方法是值優(yōu)化方法,將DQN 方法應(yīng)用到高維連續(xù)動作空間時,離散化將導(dǎo)致維數(shù)災(zāi)難。
相較于值優(yōu)化方法,策略優(yōu)化法對最優(yōu)策略進行優(yōu)化,能夠直接處理高維連續(xù)動作空間。2016 年,DeepMind 公司[23]提出了深度確定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG),DDPG 直接采用網(wǎng)絡(luò)來學(xué)習(xí)動作的策略,直接輸出控制指令,實現(xiàn)了深度強化學(xué)習(xí)方法在高維連續(xù)運動空間中的控制。此后,F(xiàn)ujimoto 等[24]進 一 步 提 出 了 雙 延 時DDPG 算 法(Twin Delayed Deep Deterministic Policy Gradient Algorithm,TD3),通過同時學(xué)習(xí)2 個評價網(wǎng)絡(luò)并用其中較小的值來進行Bellman 方程的求解,同時在策略網(wǎng)絡(luò)的輸出中添加噪聲,提高了DDPG 算法的收斂可靠性和穩(wěn)定性。Popov等[25]對DDPG 算法進一步改進,提出了DPG-R算法,在進行多步動作后進行學(xué)習(xí),而不是每一次動作后都更新策略網(wǎng)絡(luò)。仿真結(jié)果表明,DPG-R 算法的學(xué)習(xí)效率得到顯著提高。當經(jīng)驗的數(shù)據(jù)分布和當前策略差距很大時,由于推斷誤差引入,標準Off-policy 深度強化學(xué)習(xí)算法,如DQN 和DDPG,難以進行有效學(xué)習(xí)。為此,F(xiàn)ujimoto 等[26]提出了批約束強化學(xué)習(xí)算法(Batchconstrained Reinforcement Learning),通過限制動作空間,使得該算法可以利用任意策略采樣得到的離線數(shù)據(jù)學(xué)習(xí)在該環(huán)境中的最優(yōu)策略。針對真實世界機器人如何進行高效學(xué)習(xí)的問題,Haarnoja 等[27]提出了柔性動作-評價算法(Soft Actor-Critic,SAC),SAC 同樣是一種動作-評價框架下的強化學(xué)習(xí)算法,其基于最大熵思想,同時優(yōu)化期望和期望的熵,從而實現(xiàn)對樣本的高效利用。與其它主流深度強化學(xué)習(xí)算法DDPG、TD3 等進行比較,結(jié)果表明SAC 算法是目前最適用于真實世界中機器人的學(xué)習(xí)算法。
3.2 在策略(On-policy)方法
離策略算法利用離線數(shù)據(jù)進行訓(xùn)練,樣本的利用率較高,適用場景廣泛,但無法保證策略的最優(yōu)性和可靠性,且算法對超參數(shù)敏感且收斂不穩(wěn)定。與離策略相比,在策略算法直接根據(jù)在線數(shù)據(jù)對策略進行優(yōu)化,數(shù)據(jù)生成通過當前學(xué)習(xí)到的策略獲得,收斂更快速且穩(wěn)定。
針對策略梯度法存在訓(xùn)練不穩(wěn)定問題,Schulman 等[28-29]提出了一種置信域策略梯度算法(Trust Region Policy Optimization,TRPO),利用KL-散度衡量前后兩次更新的策略網(wǎng)絡(luò)參數(shù)的概率分布相似度,在一定的閾值范圍內(nèi)進行策略的更新,從而解決了迭代步長難以選取問題,避免策略在迭代過程中出現(xiàn)較大波動。仿真和物理試驗分別驗證了TRPO 算法在學(xué)習(xí)速度、穩(wěn)定性、收斂性和遷移能力方面的優(yōu)異性能[30-31]。考慮到TRPO 算法需要對KL-散度進行二次求導(dǎo),計算資源消耗嚴重,Schulman 等[32]進一步提出了近端策略優(yōu)化算法(Proximal Policy Optimization,PPO),通過對目標函數(shù)的上下界進行截斷,避免了新舊策略波動。OpenAI 和DeepMind公司在仿真環(huán)境下驗證了PPO 在學(xué)習(xí)效率和性能上都優(yōu)于TRPO 算法[33],并成功用于訓(xùn)練多類型機器人行走、奔跑、翻越、匍匐、擊球等高級行為[34]。針對連續(xù)動作空間離散化導(dǎo)致的動作數(shù)量激增問題,Tang 和Agrawal[35]提出了跨動作維度的因子分布策略,并證明了該離散策略在復(fù)雜動態(tài)的高維任務(wù)上可以顯著提升策略優(yōu)化算法(PPO, TRPO)的性能。針對具有多維離散動作的 任 務(wù) 場 景,Yue 等[36]提 出 了 一 種 將ARSM(Augment-Reinforce-Swap-Merge)梯度估計器和動作價值批判相結(jié)合的Critical-ARSM 策略梯度,提高了On-policy 算法的采樣效率。與優(yōu)勢動作評論算法(Advantage Actor Critic, A2C)、TRPO 等基準算法相比,該算法在高維動作空間情況下具有較好穩(wěn)定性[37]。此外,針對樣本利用率低的問題,Mnih 等[38]提出了一種多線程異步優(yōu)勢學(xué)習(xí)方法(Asynchronous Advantage Actor-Critic,A3C),通過多線程異步地將樣本傳到一個全局網(wǎng)絡(luò),進行全局網(wǎng)絡(luò)的訓(xùn)練。該分布式樣本生成和學(xué)習(xí)的方式,使得算法能夠運行在“多核CPU 單機”上,降低了硬件需求,縮短了訓(xùn)練時間。
上述深度強化學(xué)習(xí)方法主要為無模型方法,已被證明能夠?qū)W習(xí)各種機器人技能,其需要大量和環(huán)境的交互才能獲得良好的性能。基于模型的強化學(xué)習(xí)方法,依賴于環(huán)境在各個動作下的狀態(tài)轉(zhuǎn)移模型,具有采樣效率高等優(yōu)勢,尤其適用于機器人操作等數(shù)據(jù)量較少的實際物理場景中。目前,基于模型的方法,如PICLO(Probabilistic Inference for Learning Control)[39],在 簡 單 轉(zhuǎn) 移模型任務(wù)中取得了極大進展,然而,這些方法難以勝任具有高維空間和強非線性動力學(xué)的任務(wù)。為此,Watter 等[40-41]提出利用神經(jīng)網(wǎng)絡(luò)擬合動力學(xué)模型的方法,實現(xiàn)從圖像信息預(yù)測模型和策略。此外,結(jié)合基于模型的方法和無模型方法,使用模型來加速無模型方法,值得深入研究。Ha 和Schmidhuber[42]將無模型和基于模型的方法進行結(jié)合,建立了“世界模型”,僅利用少數(shù)轉(zhuǎn)移樣本學(xué)習(xí)了虛擬環(huán)境模型,在虛擬環(huán)境中利用進化算法求解策略取得很好效果。Levine 等[43]將環(huán)境圖像信息作為策略狀態(tài)的一部分,通過端到端的訓(xùn)練學(xué)習(xí)了機器人抓取、搭衣服等多種操作技能。
深度強化學(xué)習(xí)的發(fā)展,經(jīng)歷了從低維離散動作空間到高維連續(xù)動作空間,從解決交互式?jīng)Q策問題到解決與環(huán)境深度耦合的運動體控制問題,從仿真環(huán)境中學(xué)習(xí)訓(xùn)練到真實世界應(yīng)用的發(fā)展歷程。當前深度強化學(xué)習(xí)在理論算法和實際應(yīng)用上同步發(fā)展,實現(xiàn)了轉(zhuǎn)魔方、抓取,行走、跳躍等操作控制[44-45],并逐步擴展到地外探測領(lǐng)域,主要應(yīng)用于環(huán)境未知或局部信息未知的高動態(tài)環(huán)境中,根據(jù)實時感知信息進行推理并執(zhí)行合理操作,最大限度地提高任務(wù)的滿意度。
4 深度強化學(xué)習(xí)在地外探測操控中應(yīng)用
深度強化學(xué)習(xí)因其強大的特征表示能力和實時決策能力,在地外探測月球/行星軟著陸及其智能巡航等領(lǐng)域已得到廣泛應(yīng)用。考慮地外探測環(huán)境復(fù)雜嚴苛未知,操作對象先驗知識欠缺,操作過程動態(tài)不確定性強,強化學(xué)習(xí)技術(shù)已在著陸和巡視探測任務(wù)中路徑規(guī)劃、制導(dǎo)控制等方向取得多項創(chuàng)新研究成果。本節(jié)將以地外探測難點問題為導(dǎo)向,對深度強化學(xué)習(xí)方法在不同地外探測操控任務(wù)中的應(yīng)用進行歸納和總結(jié)。
4.1 著陸探測
地外天體探測著陸過程,探測器軌道動力學(xué)模型存在高動態(tài)和強不確定性,Gaudet 和Furfaro[46]首次將強化學(xué)習(xí)用于地外天體著陸的研究。針對火星探測精確定點著陸需求,將著陸問題解釋為馬爾可夫決策過程,提出了基于強化學(xué)習(xí)技術(shù)自適應(yīng)在線制導(dǎo)算法。著陸器狀態(tài)映射為控制動作的策略,獎勵由真實狀態(tài)向量與目標狀態(tài)向量之間的殘差組成,實現(xiàn)了燃耗最優(yōu)的動力下降軌跡精確制導(dǎo),同時對環(huán)境不確定性和未建模動力學(xué)具有魯棒性。Cheng 等[47]針對月球燃料最優(yōu)著陸問題,利用交互式深度強化學(xué)習(xí)算法采用actor-indirect 體系結(jié)構(gòu),對燃料最優(yōu)軌跡進行規(guī)劃,實現(xiàn)了登月任務(wù)的最優(yōu)控制。Gaudet和Linares[48]設(shè)計了一種智能的聯(lián)合制導(dǎo)、導(dǎo)航和控 制 系 統(tǒng)(Guidance, Navigation and Control, GNC),如圖3[48]所示,其中IMU 為慣性測量單元(Inertial Measurement Unit)。使用PPO 算法學(xué)習(xí)著陸器的估計狀態(tài)直接映射到執(zhí)行器命令,從而產(chǎn)生精確和燃料效率高的軌跡,提高著陸器對噪聲及系統(tǒng)參數(shù)不確定性的魯棒性。Jiang[49]通過整合火星再入與動力下降過程,利用自適應(yīng)偽譜法同時進行最優(yōu)再入與動力下降制導(dǎo),并利用強化學(xué)習(xí)技術(shù)進行制導(dǎo)過程的切換,提高了軌跡制導(dǎo)的最優(yōu)性、魯棒性和精度。此外,Gaudet等[50-51]還利用深度強化學(xué)習(xí)技術(shù)建立自適應(yīng)在線制導(dǎo)算法,滿足EDL(Entry, Descent, Landing)任務(wù)實時性要求,實現(xiàn)燃耗最優(yōu)的魯棒軌跡精確制 導(dǎo)。Shirobokov[52]和 黃 旭 星[53]等 對 人 工 智 能技術(shù)在航天器制導(dǎo)控制方面的研究現(xiàn)狀進行了總結(jié),并分析了人工智能技術(shù)在航天任務(wù)中的應(yīng)用優(yōu)勢,表明深度強化學(xué)習(xí)技術(shù)對于解決未知不確定動力學(xué)模型有較大潛力。

圖3 基于深度強化學(xué)習(xí)的火星著陸GNC 系統(tǒng)[48]Fig.3 DRL-based GNC system[48]
火星表面地形復(fù)雜,探測器著陸位置和飛行路徑受到嚴格限制,而傳統(tǒng)ZEM (Zero Effort Miss)和ZEV (Zero Effort Velocity)最優(yōu)反饋制導(dǎo)律的性能指標函數(shù)只考慮能量消耗,文獻[54-55]基于深度強化學(xué)習(xí)對傳統(tǒng)ZEM/ZEV 最優(yōu)反饋制導(dǎo)律進行了改進。文獻[54]提出了基于路徑點的ZEM/ZEV 算法,利用Q 學(xué)習(xí)設(shè)計了最優(yōu)路徑點選擇策略,在著陸位置和飛行路徑受限情況下具有良好性能,但其缺乏靈活性和實時適應(yīng)能力。為此,文獻[55]提出了一種基于ZEM/ZEV 的動力下降著陸制導(dǎo)方法A-ZEM/ZEV,該方法通過確定性策略梯度方法學(xué)習(xí)ZEM/ZEV方法參數(shù),將路徑約束直接納入制導(dǎo)律設(shè)計,可自適應(yīng)地改變制導(dǎo)增益和飛行時間,生成一類閉環(huán)軌跡,實現(xiàn)了滿足約束條件下燃料接近最優(yōu)。圖4[55]表明了所提出方法在規(guī)避障礙約束方面表現(xiàn)優(yōu)于傳統(tǒng)方法。在參數(shù)確定方面,F(xiàn)urfaro 等[56]針對多滑模面制導(dǎo)方法對參數(shù)異常敏感導(dǎo)致軌跡燃耗次優(yōu)問題,采用強化學(xué)習(xí)選擇制導(dǎo)增益集,優(yōu)化制導(dǎo)參數(shù),在著陸誤差和燃料消耗方面實現(xiàn)了性能最優(yōu)。為實現(xiàn)安全著陸,文獻[57]提出了一種用于識別安全著陸位置的深度強化學(xué)習(xí)框架,采用TD3 算法學(xué)習(xí)的模型用于評估和選擇著陸地點,在同時考慮地形特征、未來特征觀測質(zhì)量和控制能力前提下,獲得了安全有效的著陸軌跡。

圖4 不同算法生成軌跡比較 [55]Fig.4 Comparison of trajectories generated by different algorithms[55]
此外,文獻[58]提出了一種基于元強化學(xué)習(xí)的自適應(yīng)小行星繞飛制導(dǎo)控制策略。假定著陸器裝備有測量地形特征或主動信標的光學(xué)儀器,控制策略將傳感器輸出直接映射到執(zhí)行機構(gòu)能夠提供精確的小行星著陸。該策略對作用于探測器的環(huán)境力和內(nèi)部干擾,如執(zhí)行器故障和質(zhì)量中心變化以及小行星固有特性具有實時適應(yīng)能力。文獻[59]利用循環(huán)神經(jīng)網(wǎng)絡(luò)表示值函數(shù)和策略,采用PPO 優(yōu)化元強化學(xué)習(xí)策略,該策略僅使用火星著陸過程中多普勒雷達高度計和小行星著陸過程中激光雷達高度計的觀測數(shù)據(jù)分別設(shè)計制導(dǎo)律,仿真試驗對引擎故障的情況下安全著陸火星,以及在動力學(xué)未知的小行星上著陸進行了有效驗證,該控制方法優(yōu)于傳統(tǒng)燃料最優(yōu)反饋制導(dǎo)算法[60-61]。
4.2 巡視探測
巡視探測是目前對地外天體近距離探測最直接有效的探測方式,但地外環(huán)境復(fù)雜非結(jié)構(gòu)化,星表土壤等物理化學(xué)性質(zhì)不確知,探測器通過與地外星表的交互式接觸,基于深度強化學(xué)習(xí)技術(shù)可對不確定性進行在線識別逼近,對提高巡視安全性,完成預(yù)定科學(xué)探測任務(wù)具有重要現(xiàn)實意義。
為了實現(xiàn)行星車的自主決策,并解決傳統(tǒng)人為規(guī)劃框架中過于依賴地圖信息的問題,周思雨等基于深度強化學(xué)習(xí)理論提出了端到端的路徑規(guī)劃方法,直接從傳感器信息映射出動作指令[62]。Serna 等[63]綜述了火星生物特征探測中無人機自主任務(wù)規(guī)劃研究現(xiàn)狀,提出將部分可觀測馬氏決策過程的強化學(xué)習(xí)算法應(yīng)用于火星無人機導(dǎo)航規(guī)劃任務(wù)中,提高探測任務(wù)的自主性。同時指出未來可利用火星數(shù)字高程模型[64]模擬火星表面,并整合生物特征構(gòu)建仿真訓(xùn)練環(huán)境。Tavallali 等[65]針對復(fù)雜地形下移動模式選擇問題,提出了一種火星車移動模式自動切換的強化學(xué)習(xí)框架,該框架不依賴地形先驗知識,直接從物理環(huán)境交互過程中學(xué)習(xí),優(yōu)化了復(fù)雜地形穿越方案,提高了探測任務(wù)效率。需要強調(diào)的是,該學(xué)習(xí)框架獎勵函數(shù)動態(tài)變化,獎勵函數(shù)設(shè)計僅取決于火星車能源效率。同樣地,考慮到星表環(huán)境未知而探測任務(wù)復(fù)雜,強化學(xué)習(xí)獎勵函數(shù)難以設(shè)定,Pflueger 等[66]基于反向強化學(xué)習(xí)設(shè)計路徑規(guī)劃任務(wù)學(xué)習(xí)框架,結(jié)合卷積神經(jīng)網(wǎng)絡(luò)和值迭代算法更新獎勵函數(shù),實現(xiàn)可通行區(qū)域選取。圖5[66]給出了帶路徑地圖。

圖5 帶路徑地圖 [66]Fig.5 Map with paths[66]
為提高地外探測任務(wù)成功率,Huang 等[67]提出了基于DDPG 的多智能體深度強化學(xué)習(xí)方案,結(jié)果表明多智能體協(xié)同探測相比單智能體探測效率明顯提高。火星巡視器協(xié)同探索方案如圖6[67]所 示,其 中POI 表表探 測 興 趣 點(Point of Interset)。Wachi 等[68-70]考慮不安全操作可能導(dǎo)致系統(tǒng)故障問題,研究了未知安全約束下的馬爾可夫決策過程,獲得了接近最優(yōu)的決策,實現(xiàn)火星不確定環(huán)境安全探索。星上資源有限,Bernstein 和Zilberstein[71]將行星車控制問題建模為弱耦合馬爾可夫決策過程(Markov Decision Processes, MDP),研究了一種弱耦合多探測目標的分層強化學(xué)習(xí)算法,實現(xiàn)了有限資源充分利用,提高了探測效率。該算法的初始性能優(yōu)于Q 學(xué)習(xí),但并不能收斂到最優(yōu)策略。

圖6 火星巡視器協(xié)同探索方案[67]Fig.6 Collaborative exploration scenario on Mars surface [67]
地外星表土壤機械特性直接影響地外巡視及 采 樣 探 測 的 操 控 性 能,Song[72]和Arreguin等[72-73]調(diào)研了機器學(xué)習(xí)在地外星表土壤機械特性識別中應(yīng)用前景,由于環(huán)境動態(tài)變化,實時應(yīng)用需要具備在線自適應(yīng)特點,因此總結(jié)出深度強化學(xué)習(xí)對于實時識別非均勻地形中的土壤特性具有應(yīng)用價值。
4.3 采樣探測
深度強化學(xué)習(xí)在地外采樣探測領(lǐng)域中應(yīng)用有限,目前僅取得了少量研究成果。如文獻[74]利用深度強化學(xué)習(xí),構(gòu)建了一套樣品采集學(xué)習(xí)訓(xùn)練系統(tǒng),使機械臂從零開始,通過自主訓(xùn)練具備了自主智能感知、規(guī)劃與操控能力,最終實現(xiàn)了未知環(huán)境下端到端樣品采集全自主操作。在該方案中機械臂抓取的策略網(wǎng)絡(luò),以被操作物體原始圖像信息為輸入,輸出為機械臂抓取的位置和姿態(tài)。同時考慮到機械臂的動作空間是連續(xù)的,抓取動作直接進行離散化難以實現(xiàn)精準抓取,或出現(xiàn)維度災(zāi)難等情況,將強化學(xué)習(xí)算法PPO 和深度神經(jīng)網(wǎng)絡(luò)結(jié)合,直接獲得抓取姿態(tài)連續(xù)控制量的推理。真實環(huán)境中抓取結(jié)果如圖7 所示。

圖7 真實環(huán)境抓取Fig.7 Grasp experiment in real world
此外,建立了地外采樣試驗場,可用于驗證智能操控算法在地外探測采樣任務(wù)中的性能,在地外試驗場上抓取未知石塊,結(jié)果如圖8 所示。

圖8 試驗場環(huán)境抓取Fig.8 Grasp experiment in test field
但是,地外探測面臨物品材質(zhì)不確定問題,上述僅依靠視覺測量信息抓取策略會導(dǎo)致物品變形甚至損壞,如黃土塊等易碎物品抓取。此外,為實現(xiàn)采樣物品最大化歸集裝箱,文獻[75]研究了基于DQN 算法的推撥優(yōu)化裝箱問題,通過推撥動作對于已放置的物品位置進行調(diào)整、歸集,提高了裝箱空間利用率。
綜上,深度強化學(xué)習(xí)在地外探測中實現(xiàn)了著陸探測參數(shù)不確定在線識別到安全著陸區(qū)域選擇和巡視探測中從路徑規(guī)劃到自主決策,從單一智能發(fā)展為集群智能,以及樣品全自主發(fā)現(xiàn)與抓取。基于上述研究成果,并考慮地外探測環(huán)境及任務(wù)特點,總結(jié)分析了應(yīng)用于地外探測自主操控領(lǐng)域的深度強化學(xué)習(xí)有別于地面機器人領(lǐng)域的不同之處,如表3 所示。未來探測器在未知不確定環(huán)境中實現(xiàn)或提升自主功能,通過感知自身狀態(tài)及外部環(huán)境,進行任務(wù)規(guī)劃調(diào)度,實現(xiàn)群智能體協(xié)同操作,具備動態(tài)變化環(huán)境下學(xué)習(xí)、改進、適應(yīng)和再現(xiàn)任務(wù)的能力,仍值得進一步研究。
5 發(fā)展與展望
目前深度強化學(xué)習(xí)在地外探測著陸巡視及取樣操控任務(wù)中取得了一定的研究成果,但在實現(xiàn)地外探測自主操控中仍然留有許多亟待解決的問題。因此,本節(jié)根據(jù)地外探測難點問題及未來探測任務(wù)需求,按照“地面操控方法設(shè)計-地外持續(xù)學(xué)習(xí)-未來多智能體集群探測”這一思路,總結(jié)地外探測智能操控實現(xiàn)突破的關(guān)鍵點,其相互關(guān)系如圖9 所示。
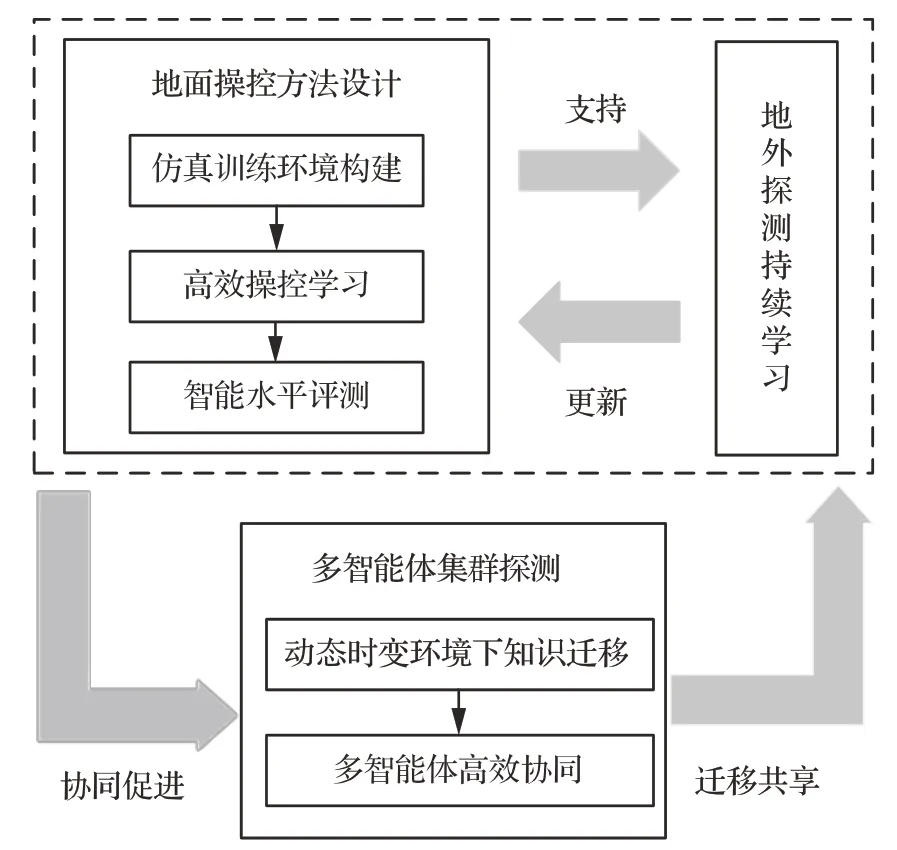
圖9 地外探測智能操控關(guān)鍵技術(shù)相互關(guān)系Fig.9 Relationship between key technologies of intelligent control for extraterrestrial exploration
“地面操控方法設(shè)計”需要解決仿真訓(xùn)練環(huán)境構(gòu)建,高效操控學(xué)習(xí)以及智能水平評測問題,針對地外探測面臨的環(huán)境嚴苛未知和操控對象物理化學(xué)性質(zhì)不確定等問題,基于基礎(chǔ)觀測數(shù)據(jù),建立仿真訓(xùn)練環(huán)境,在此基礎(chǔ)上,考慮地外探測任務(wù)特點,設(shè)計高效操控學(xué)習(xí)方法進行訓(xùn)練,從而得到智能操控基礎(chǔ)模型,并對其進行評測,完成在軌應(yīng)用可行性的量化評定,支撐地外操控性能持續(xù)進化;“地外持續(xù)學(xué)習(xí)”研究地外物理環(huán)境變化情況下的學(xué)習(xí)模型進化方法,并基于執(zhí)行-評價的學(xué)習(xí)結(jié)構(gòu),反向更新精準操控的基礎(chǔ)知識庫和初始模型,進一步提高地面設(shè)計方法的操控性能;“多智能體集群探測”在以上2 個關(guān)鍵點基礎(chǔ)上,需要解決知識遷移和高效協(xié)同問題,通過完成預(yù)定學(xué)習(xí)任務(wù),將學(xué)習(xí)經(jīng)驗遷移到其它任務(wù)中,從而設(shè)計多智能體的最優(yōu)協(xié)同決策與規(guī)劃方法,進行整體優(yōu)化,提升群體協(xié)同操作的性能、效率與可靠性,并根據(jù)協(xié)作結(jié)果及時調(diào)整各智能體自身策略,從而促進多智能體協(xié)同進化。相關(guān)關(guān)鍵點具體介紹如下。
5.1 地面操控方法設(shè)計
地面操控方法設(shè)計是實現(xiàn)智能操控在地外探測中應(yīng)用的基礎(chǔ)和前提。面向著陸巡視和高價值目標采樣任務(wù)需求,地外探測智能操控根據(jù)環(huán)境未知非結(jié)構(gòu)化和操作對象強不確定特點,從以下3 個方面開展研究:
1)仿真訓(xùn)練環(huán)境構(gòu)建
深度神經(jīng)網(wǎng)絡(luò)具有較強的非線性映射能力,其對數(shù)據(jù)的數(shù)量、質(zhì)量要求很高,具有嚴重的數(shù)據(jù)依賴性。然而,在地外探測中,由于操作任務(wù)數(shù)量有限,數(shù)據(jù)回傳困難,難以獲得大量有效真實數(shù)據(jù)。另一方面,地外的地形、地質(zhì)、光照等環(huán)境特點和操控對象的形狀、成分、慣量等物理化學(xué)特性,都與地面差異大,使得地面模擬地外環(huán)境困難。因此,數(shù)據(jù)量不足,難以有效構(gòu)建高逼真仿真訓(xùn)練環(huán)境支持網(wǎng)絡(luò)訓(xùn)練,是地外探測面臨的一個重要問題。針對上述問題,基于有限的真實空間樣本,研究樣本增強和增廣方法,結(jié)合地外試驗中星表環(huán)境間交互數(shù)據(jù)樣本,構(gòu)建高逼真數(shù)字地外任務(wù)場景模擬環(huán)境,用于地外探測的反復(fù)試錯學(xué)習(xí),提升仿真中學(xué)習(xí)到的策略在真實場景中的應(yīng)用效果。
2)高效操控學(xué)習(xí)
當前智能操控方法普遍存在面向單一任務(wù)設(shè)計的弊端,然而地外探測需要完成定點著陸、安全巡視、多地取樣歸集與設(shè)施建造等任務(wù),任務(wù)復(fù)雜且關(guān)聯(lián)性高,評價函數(shù)難以直接確定。加之地外探測資源受限,高維連續(xù)動作等復(fù)雜任務(wù)場景下深度神經(jīng)網(wǎng)絡(luò)設(shè)計復(fù)雜。為解決上述問題,考慮任務(wù)復(fù)雜性、環(huán)境動態(tài)變化、自身安全和資源約束等因素,結(jié)合地外探測操控學(xué)習(xí)的固有特性設(shè)計高效學(xué)習(xí)方法,優(yōu)化評價函數(shù)設(shè)計,精簡神經(jīng)網(wǎng)絡(luò),在有效資源下提高學(xué)習(xí)效率,實現(xiàn)柔順精準操控。
3)智能水平評測
地外探測器發(fā)射到地外后,一旦出現(xiàn)故障,維修和搶救幾乎不可能。當前基于深度神經(jīng)網(wǎng)絡(luò)的強化學(xué)習(xí)方法在不確定任務(wù)場景中作出的決策難以直觀解釋,可能會出現(xiàn)探測器及操作機構(gòu)受損等情況。針對未來地外智能操控在軌應(yīng)用面臨的高可靠需求,研究操控系統(tǒng)智能水平的定量評測方法,建立評測體系,對學(xué)習(xí)效能、操控水平以及空間應(yīng)用的可行性和有效性進行驗證評估,實現(xiàn)自主智能操控在復(fù)雜地外環(huán)境下的試驗驗證和智能水平評測,提高探測安全性。
5.2 地外探測持續(xù)學(xué)習(xí)
地外環(huán)境與地球環(huán)境在地面結(jié)構(gòu)、重力環(huán)境、大氣組成等方面差異顯著,地外探測存在不確定性大以及人工干預(yù)難等問題,因而迫切需求探測器在其生命周期內(nèi)具有自主學(xué)習(xí)的持續(xù)優(yōu)化能力。地外探測智能操控在突破上述關(guān)鍵點基礎(chǔ)上可遵循“數(shù)字仿真學(xué)習(xí)—地面試驗—地外持續(xù)學(xué)習(xí)”這一思路,通過在軌操作樣本積累、操作規(guī)律主動發(fā)現(xiàn)與優(yōu)化,實現(xiàn)操控性能持續(xù)進化。考慮上述需求,結(jié)合場景理解結(jié)果和目標特征及力、位移等多源傳感器的執(zhí)行反饋信息,研究不確定因素下感知執(zhí)行交互的精準操控學(xué)習(xí)方法,以安全自然為目標,建立基于風(fēng)險預(yù)測和操作性能評估的更新機制,實現(xiàn)操控性能的在線提升。
5.3 多智能體集群探測
未來地外具有協(xié)同探測的發(fā)展趨勢,綜合考慮探測任務(wù)需求及多個無人探測器自身能力等約束條件,從遷移和協(xié)同2 個方面開展研究:
1)動態(tài)時變環(huán)境下知識遷移
地外學(xué)習(xí)操控面臨實際環(huán)境訓(xùn)練成本高的問題,目前探測器需要在虛擬仿真環(huán)境下進行大量訓(xùn)練,將訓(xùn)練結(jié)果直接應(yīng)用到真實場景時無法達到預(yù)設(shè)操控效果。此外,地外探測環(huán)境的未知與動態(tài)特性也使得操控的學(xué)習(xí)訓(xùn)練場景與真實應(yīng)用場景存在較大差異,且面臨不同任務(wù)場景時需要再次利用大量時間和數(shù)據(jù)進行重新學(xué)習(xí)。探索不同環(huán)境和任務(wù)場景下的異地知識共享方法,最大化利用先驗知識和共性特征進行學(xué)習(xí)是解決上述問題的有效途徑。如可在深度強化學(xué)習(xí)中結(jié)合無模型方法和有模型方法,以及引入遷移學(xué)習(xí)和元學(xué)習(xí)實現(xiàn)知識遷移,提升探測器對環(huán)境和任務(wù)的適應(yīng)能力,支撐多智能體協(xié)同探測。
2)多智能體高效協(xié)同
未來無人探測任務(wù)復(fù)雜多樣,目前單一探測器難以獲取充足和準確的環(huán)境及目標信息,探測效能低。因此,大范圍樣本搜尋、設(shè)施建造等任務(wù)要求探測器需要具備多器協(xié)同的能力,而不同探測器具有運動模式各異、載荷多樣化、約束復(fù)雜等特點,如地外飛行器和巡視器運動模式和任務(wù)目標完全不同,且通訊能力和能源受限。需要研究多智能體任務(wù)分配、優(yōu)化機制以及協(xié)同策略,實現(xiàn)未知環(huán)境中高效可靠的多體協(xié)同,降低系統(tǒng)受單個成員故障或環(huán)境變化影響的敏感程度,提高系統(tǒng)整體魯棒性。
6 結(jié) 論
自主操控是實現(xiàn)地外安全高效探測的關(guān)鍵技術(shù)手段之一。本文分析了地外探測自主操控的難點,概括了深度強化學(xué)習(xí)算法及其在地外探測自主操控領(lǐng)域的研究成果,指出了存在的問題和發(fā)展的方向。
目前,地外探測已初步展現(xiàn)出人工智能的廣闊應(yīng)用場景,未來探測器可根據(jù)任務(wù)目標、自身狀態(tài)和未知環(huán)境特點,主動感知環(huán)境,理解場景,發(fā)現(xiàn)高價值目標,進行可靠推理,有效決策操控,開展分析試驗,從而全自主地開展地外探測任務(wù)。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學(xué)學(xué)報(自然科學(xué)版)(2021年1期)2021-06-09 08:43:00
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
中國生殖健康(2020年6期)2020-02-01 06:28:50
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
中國生殖健康(2019年11期)2019-01-07 01:28:02
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
