面向新冠疫情應對的文本挖掘框架研究
2023-04-14 03:09:26譚明亮
電腦知識與技術 2023年6期
關鍵詞:文本挖掘
譚明亮
摘要:非結構化文本是最基礎和最主要的數據類型之一,蘊含著巨大的價值與潛能,對其進行分析挖掘和有效利用對于新冠疫情的應對處置有著重要的意義。文章從中國知網數據庫中檢索2020年和2021年兩年間發表于重要學術期刊上,與新冠疫情文本挖掘相關的研究文獻共計127篇,然后對研究文獻進行逐篇閱讀和內容分析,以實現研究文獻的系統化梳理和深層次分析。文章構建了面向新冠疫情應對的文本挖掘框架,從應用場景、文本數據、分析方法、算法模型和軟件工具五個方面展開分析論述,為開展面向新冠疫情應對的文本挖掘提供了整體系統的架構設計和切實可行的解決路徑。
關鍵詞:新冠疫情應對;文本挖掘;突發公共衛生事件;大數據分析
中圖分類號:TP301? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2023)06-0051-03
開放科學(資源服務)標識碼(OSID)
1 引言
2020年爆發的新冠疫情是新中國成立以來傳播速度最快、感染范圍最廣、防控難度最大的重大突發公共衛生事件,同時也是百年來全球發生的最嚴重的大流行傳染病。目前,新冠疫情已蔓延至上百個國家和地區,截至2022年2月,全球新冠感染確診病例超過4億,死亡病例超過580萬例。如何有效地應對新冠疫情是黨和國家的重大現實需求,同時也是各學科領域的研究者們所共同面臨的重要學術問題。
作為一種新興的基礎性戰略資源,大數據中蘊含著巨大的價值與潛能,對于重塑國家競爭優勢、提升國家治理能力、推動經濟發展、引領科技創新有著十分重要的作用。在數據驅動的管理決策和科學研究的第四范式的背景下,以數據為中心,分析、挖掘、組織和利用數據資源能夠有效地推動科學知識發現、提升科學決策水平、強化綜合治理能力和創造社會經濟價值。非結構化文本數據是數據資源中最基本和最主要的構成之一,對其進行分析挖掘對于新冠疫情的應對處置有著重要的意義。
2 文獻數據收集
本文通過收集新冠疫情文本挖掘相關的研究文獻,對文獻進行逐篇閱讀和內容分析;然后以此為基礎,結合數據挖掘和情報分析領域的相關理論方法,構建面向新冠疫情應對的文本挖掘模型。考慮到研究文獻的權威性和代表性,本文將學術期刊的來源類別確定為北大核心、CSSCI和CSCD;將出版年度設定為2021年和2022年。
為了全面充分地從CNKI數據庫中檢索出相關的研究文獻,本文將檢索條件設定為(主題=“新冠感染”OR“新型冠狀病毒感染”OR“COVID-19”OR“新冠疫情”OR“新冠感染疫情”OR“新型冠狀病毒感染疫情”)AND(主題OR摘要=“文本挖掘”OR“文本分析”OR“情感分析”OR“文本聚類”OR“文本分類”OR“信息抽取”OR“關聯分析”OR“文本”OR“詞頻”OR“頻數”OR“主題挖掘”OR“主題聚類”OR“LDA”)。
完成文獻檢索后,接下來需要對獲得的檢索結果進行篩選。在信息管理和計算機科學的語境下,文本挖掘主要是利用計算機從非結構化文本數據中提取和發現有價值的模式和知識。因此,本文去除了檢索結果中通過人工的方式來對文本數據進行分析的研究文獻,最終得到研究文獻共計127篇。
3 面向新冠疫情應對的文本挖掘框架構建
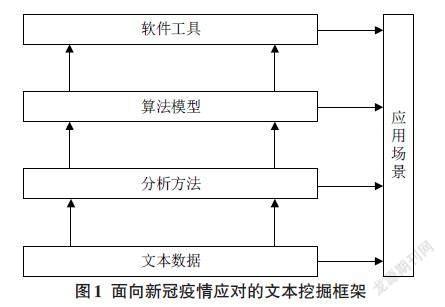
本文對以127篇研究文獻的內容分析為基礎,結合數據挖掘的基本思路和流程,以及中信所提出的“事實型數據+專用方法工具+專家智慧”方法論,構建了面向新冠疫情應對的文本挖掘框架,如圖1所示。該框架主要由應用場景、文本數據、分析方法、算法模型、軟件工具五部分所構成,通過采集非結構化文本數據,運用相關的分析方法、算法模型和軟件工具對文本數據進行分析、處理和挖掘,從而為管理決策提供支持和依據。
3.1 應用場景
新冠疫情文本挖掘所面向的應用場景和實際需求主要包括網絡輿情分析與管理、虛假信息和網絡謠言識別與治理、新冠感染用藥規律與診療方案分析、政府政策分析與評價、公眾信息需求和訴求分析等。CNNIC發布的第48次《中國互聯網絡發展狀況統計報告》顯示,目前我國的網民規模達到了10億以上,并呈現出逐年上升的趨勢;在此背景下,對網民在微博、貼吧、BBS論壇和微信等社交媒體上發表的文本內容進行分析挖掘,從而有效地監測、管理和引導網絡輿情具有重要的意義。因此,網絡輿情分析對于文本挖掘技術的需求和應用尤為突出。
新冠感染用藥規律與診療方案分析主要通過挖掘新冠感染的防治處方、研究論文、國家及各省市自治區衛健委推薦的COVID-19診療方案和指南建議等來探究新冠感染的用藥規律、組方特征,從而為新冠感染的防治和用藥提供參考與依據。新冠疫情爆發后,國家和各級政府管理部門針對疫情防控、復工復產、產業扶持等發布了大量的政策文件;政府政策分析與評價主要研究政策主題演化、政策擴散特征、政策量化、政策差異和協同等。公眾信息需求和訴求分析主要通過挖掘用戶在網絡平臺發表的文本信息來掌握新冠感染期間人們的信息需求和訴求。
3.2 文本數據
面向新冠疫情應對的文本挖掘需要根據應用場景和實際問題采集和獲取相應的非結構化文本數據,典型的文本數據例如社交媒體文本、政策文本、診療方案文本、醫藥處方文本、學術論文文本、新聞報道文本、領導留言板文本、病例軌跡描述性文本等。文本數據的來源主要包括政府部門官方網站、網絡平臺、文獻數據庫、社交媒體平臺、新聞門戶網站等。文本數據采集的方式主要有爬蟲爬取、數據庫導出、手工下載和API接口獲取等。在數據采集方式的選擇上,需要綜合考慮數據源的特點、數據量的大小等諸多方面的因素,例如,針對文獻數據庫中的數據適合通過批量導出的方式獲取,新浪微博平臺上的數據則適合通過爬蟲和API接口的方式獲取。
網絡輿情分析與管理、虛假信息和網絡謠言識別與治理場景所需要采集的文本數據主要包括新浪微博文本、百度貼吧帖子、知乎帖子、抖音評論文本、QQ空間文本、微信公眾號文本等。新冠感染用藥規律與診療方案分析所需要采集的文本數據主要包括CNKI、萬方、Pubmed、Elsevier、SpringerLink等數據庫中的學術論文文本,國家及各省自治區直轄市發布和推薦的診療方案、指南建議,HIS系統中的處方文本和全國名醫公開的新冠感染防治處方文本等。政府政策分析與評價所需要采集的文本數據主要是各級政府管理部門發布的疫情防控、企業復工復產等相關的政策文本。公眾信息需求和訴求分析所需要采集的文本數據則主要是公眾在知乎、新浪微博等網絡平臺和領導留言板上發表的熱門話題和咨詢提問文本等。
3.3 分析方法
運用數據采集方法獲取了實際應用場景所需的非結構化文本數據之后,為了獲取對于應對新冠感染疫情潛在有價值的知識和模式,需要運用一定的文本分析方法對采集的文本數據進行處理和挖掘。針對新冠疫情文本數據所采用的分析方法主要包括詞頻分析、情感分析、文本分類、文本聚類、主題分析、關聯規則挖掘、社會網絡分析、文本相似度分析、信息抽取和可視化分析等。
詞頻分析主要通過統計新冠疫情文本數據中各個詞語出現的次數,從而揭示文本數據所表達的核心內容。詞頻分析法具有實現簡單、便于理解、易于操作等特點,是新冠疫情文本挖掘研究文獻中使用最為廣泛的分析方法之一。例如,陳雅薇等利用詞頻分析法來研究長三角地區各政府產業政策的相似性與差異化[1];彭宗超等基于詞頻分析法來對網絡大數據進行挖掘,以分析新冠疫情各個階段中社會輿論的核心關注點[2]。
情感分析被用于分析人們在新冠疫情文本中所表達的觀點、情感、評價、情緒和態度等,情感分析的具體方法主要包括:基于詞典的方法,將文本內容與情感詞典中的情感詞進行匹配以實現文本情感傾向判斷;基于機器學習的方法,利用經標注的數據集來訓練機器學習模型,然后基于訓練的模型來實現文本情感分類。例如,馮志仙等運用情感分析法來研究新冠疫情防控期間醫院重要通知群和護士交流群中信息的情感傾向[3]。
文本分類主要根據文本數據的語義特征將文本自動歸入到預先定義相應的類別中。例如,石鍇文等運用文本分類來將新冠感染微博謠言自動檢測出來[4]。不同于文本分類的監督學習,文本聚類自動地將新冠疫情文本數據集合劃分為若干個類簇,使得同一類簇中文本之間的相似性高,而不同類簇中文本之間的相異性高。例如,禹衛華等將文本聚類應用于探究新冠疫情下政務新媒體的議題[5]。
主題分析通過挖掘新冠疫情文本中的潛在主題來實現對文本數據語義內容的理解、整理和判斷。當前研究者們主要利用關聯規則挖掘方法來分析新冠感染相關的研究論文、防治處方、診療方案和指南建議等文本中藥物之間的關聯關系,從而為新冠感染的用藥和防治等提供決策支持。
社會網絡分析主要用于分析發布新冠疫情政策的主體的聯合發文關系,以及社交媒體用戶之間因轉發、評論、關注而形成的社會網絡關系。文本相似度分析通過判定給定文本在內容上之間的差異,從而確定相似程度,通常用0至1之間的數值進行衡量。
信息抽取主要用于抽取新冠肺炎流行病學調查形成的病例軌跡描述性文本中抽取時間、地點、病例關系等信息,以實現疫情傳播路徑的精準定位。可視化分析將新冠疫情文本內容以直觀易理解的圖形、圖像進行呈現,從而形象地表示文本數據的內在含義。
3.4 算法模型
選擇一種或多種文本分析方法在對新冠疫情文本數據進行挖掘的過程中表現為使用具體的算法模型,算法模型是分析方法的具體實現和體現。例如,利用主題分析法來對新冠疫情文本的語義內容進行挖掘時,專家學者們往往使用的是Blei等提出的LDA模型;應用關聯規則挖掘來對防治處方文本中的藥物關系進行分析時則使用的主要是Apriori算法。對于中文文本數據的挖掘,首先需要對非結構化文本進行中文分詞、詞性標注、去停用詞、文本表示、特征權重計算等文本預處理操作,然后在此基礎上進行主題分析、關聯規則挖掘、文本相似度分析、情感分析、文本分類和文本聚類等。
中文分詞和詞性標注所用的算法模型主要包括HMM模型、CRF模型和最大熵模型等。文本表示所用的算法模型主要包括詞袋模型、布爾模型、N-Gram模型、向量空間模型(VSM)、Word2vec詞嵌入模型、BERT詞向量模型等。特征權重計算所用的算法模型主要包括特征頻率、布爾函數、信息增益、倒排檔文本頻率、TF-IDF算法、互信息等。文本主題分析所用的算法模型主要包括LDA主題模型、ETM主題模型模型、STM主題模型模型等。關聯規則挖掘所用的算法模型主要是Apriori算法。文本相似度分析所用的算法模型主要包括余弦相似度算法、歐氏距離、皮爾遜系數等。
情感分析和文本分類所用的算法模型主要包括樸素貝葉斯算法、隨機森林算法、SVM算法、LSTM算法、CNN算法、RNN算法、Bi-LSTM算法、XGBoost算法、BiGRU模型、Transformer模型等。文本聚類所用的算法模型主要包括K-Means算法、DBSCAN算法、Fast Unfolding算法、Single-Pass算法等。基于采集的127篇研究文獻可以直觀地發現,隨著深度學習和人工智能技術的快速發展,大量的深度神經網絡算法模型已經被研究者們廣泛地應用于新冠疫情文本挖掘中。專家學者們還將多種模型進行融合和集成,以更好地實現文本的語義理解和語義挖掘;例如,融合LDA模型與BERT模型;集成CNN算法、BiLSTM算法與attention模型。
3.5 軟件工具
當前國內外的相關研究機構和專家學者們針對文本挖掘、機器學習、自然語言處理、數據分析和人工智能等技術領域開發了大量的軟件、程序庫和工具,對算法模型進行了實現和封裝。這使得研究人員,特別是社會學、經濟學、管理科學、法學等非計算機科學領域的科研工作者能夠將注意力集中在新冠疫情文本挖掘所面向的應用場景和實際問題上,而不是將大量的精力和時間投入到文本挖掘相關的算法模型的編程實現上。例如,要基于LDA主題模型來對新冠疫情文本數據進行分析,不必從零開始編寫一行行的代碼來編程實現LDA模型,可以通過導入開源的Gensim工具包直接使用LDA模型。
數據采集所用的軟件工具主要包括八爪魚爬蟲軟件、谷歌爬蟲插件Web Scraper、火車頭采集器、后羿采集器、Scrapy爬蟲框架等。文本大數據的存儲和處理所用的基礎設施主要包括HDFS、MapReduce、Hadoop、MongoDB、Spark等。中文分詞、詞性標注所用的軟件工具主要包括jieba庫、ICTCLAS、哈工大LTP、北大pkuseg、HanLP中文處理包、清華THULAC等,所使用的停用詞表主要有哈工大停用詞表、四川大學機器智能實驗室停用詞、百度停用詞表等。
文本表示、文本分類、文本聚類、主題分析、情感分析、關聯規則挖掘和信息抽取主要使用自然語言處理、數據分析、機器學習和深度神經網絡相關的軟件工具,主要包括SPSS Modeler軟件、SPSS Statistics軟件、scikit-learn庫、Gensim包、bert-as-service庫、keras庫、Tensorflow庫、pytorch庫、百度智能云API等。社會網絡分析所用的軟件工具主要包括Gephi軟件、NetDraw軟件、Ucinet軟件等。可視化分析所用的軟件工具主要包括Vosviewer軟件、LDAvis包、WordCloud庫、Matplotlib庫等。
4 結語
本文以過去兩年內發表于核心期刊上關于新冠疫情文本挖掘的127篇研究文獻為基礎,構建了面向新冠疫情應對的文本挖掘框架,并框架所涉及的核心內容展開了分析論述,以期為面向新冠疫情應對的文本挖掘學術研究和應用實踐提供借鑒參考。文本數據具有著不同的粒度,按照信息粒度的大小可以分為篇章、段落、句子、詞語等層次。今后的重要研究方向之一是基于深度神經網絡、知識庫半自動構建、文本圖表示學習和文本語義分析等技術實現各層次文本單元的語義理解和知識關聯。
參考文獻:
[1] 陳雅薇,朱華晟,姚飛.長三角地區新冠肺炎疫情應急與產業政策響應——基于政策文本的詞頻分析[J].現代城市研究,2021,36(1):45-51.
[2] 彭宗超,黃昊,吳洪濤,等.新冠肺炎疫情前期應急防控的“五情”大數據分析[J].治理研究,2020,36(2):6-20.
[3] 馮志仙,沈鳴雁,陳翔,等.新型冠狀病毒肺炎疫情防控期間護理管理工作中信息傳遞質量改善研究[J].中國護理管理,2020,20(5):686-690.
[4] 石鍇文,劉勘.突發公共衛生事件中微博謠言的識別[J].圖書情報工作,2021,65(13):87-95.
[5] 禹衛華,黃陽坤.重大突發公共衛生事件的政務傳播:響應、議題與定位[J].新聞與傳播評論,2020,73(5):22-33.
【通聯編輯:王力】
猜你喜歡
科技資訊(2017年5期)2017-04-12 15:18:52
電腦知識與技術(2016年33期)2017-03-21 08:13:37
商情(2016年32期)2017-03-04 00:27:28
軟件導刊(2016年12期)2017-01-21 15:55:21
電子技術與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
中國中醫藥圖書情報(2016年4期)2016-10-20 23:35:25
湖南師范大學學報·自然科學版(2016年3期)2016-06-25 06:47:25
語文教學之友(2016年5期)2016-06-15 12:15:44
