基于知識圖譜的項目文檔智能管理與應用系統(tǒng)
2023-04-13 11:40:28王志剛吳士泓李孟全
現(xiàn)代計算機 2023年3期
王志剛,吳士泓,李孟全,李 向
(1.遠光軟件股份有限公司,珠海 519085;2.華中科技大學管理學院,武漢 430074)
0 引言
在互聯(lián)網與計算機科學技術快速發(fā)展的形勢下,信息化是企業(yè)發(fā)展的必由之路,對企業(yè)文檔進行網絡化、自動化和電子化管理,實現(xiàn)全面信息共享是大勢所趨[1]。因為企業(yè)大部分有價值的信息都是以文件形式存在且很多重要的業(yè)務流程是以文件流驅動的,所以文檔管理在企業(yè)管理中非常重要[2]。國內外的項目文檔管理研究更多的集中在項目文檔管理流程自動化方面[3-4],對于文檔內容自身的價值并沒有重點關注導致文檔難以發(fā)揮應有價值[5-6]。
現(xiàn)有文檔管理系統(tǒng)造成項目文檔價值不能充分利用的主要原因包括以下3點:①現(xiàn)有的文檔管理系統(tǒng)對于文檔的管理比較粗糙,大多是以整個文檔作為最小粒度,更多考慮的是項目文檔的流程自動化,提升項目文檔的編寫、存儲與使用。并沒有從單個文檔本身內容處理出發(fā),對于文檔中更小粒度的重要的和有用的信息進行捕獲和提取,導致文檔價值難以充分體現(xiàn)和發(fā)揮。②現(xiàn)有文檔管理系統(tǒng)涉及文檔內容處理的過程主要使用人工進行,存在大量重復性高、內容枯燥的工作,這將會導致難以避免的人為失誤。③現(xiàn)有文檔管理系統(tǒng)對于文檔的分析與應用技術手段落后,文檔處理質量和效率低下,難以實現(xiàn)多維度文檔智能分析與應用。總體來說,現(xiàn)有文檔管理系統(tǒng)對于企業(yè)各種類型的項目文檔管理與價值深度挖掘能力不足,自動化和智能化程度有待提高。隨著信息化技術的發(fā)展,如何使用新技術提高項目文檔處理質量和效率,深度挖掘文檔數(shù)據(jù)價值變得尤為重要。
招投標文檔管理系統(tǒng)作為文檔管理系統(tǒng)的一種,也存在文檔價值利用率低的問題。為解決這個問題,本文提供一種基于知識圖譜的招投標文檔管理與應用系統(tǒng)。該系統(tǒng)以企業(yè)商務招投標項目管理(項目管理的文檔包括招標文檔、投標文檔和合同文檔)為例,基于機器學習、自然語言處理、知識圖譜和光學字符識別等人工智能技術支持智能文檔處理與應用,充分挖掘文檔價值,保證文檔處理質量,減少人力成本,提升工作效率。具體而言,針對非結構化文檔數(shù)據(jù)價值挖掘不足的問題,分別構建預訓練模型與規(guī)則相融合的提取模型、圖片分類與光學字符識別融合模型進行文檔關鍵文字內容和圖片內容提取。使用知識圖譜技術將抽取的知識、項目、文檔、外部支撐和佐證等數(shù)據(jù)一起構建文檔知識圖譜,著重構建文檔與文檔內容之間的深度關聯(lián),實現(xiàn)招投標文檔數(shù)據(jù)的統(tǒng)一組織與存儲,支撐深度知識挖掘和智能應用開發(fā)。針對文檔處理智能化程度低下和人力成本高等問題,提供基于機器學習和自然語言處理的文檔智能查重和比對、基于文檔信息的企業(yè)資質審查等模型,將機械重復的、內容枯燥的文檔處理工作交由機器自動完成。系統(tǒng)提供文檔的智能多維分析、語義檢索、智能問答與推薦等應用,能夠實現(xiàn)文檔管理的多維度智能分析與可視化展示,方便用戶快速獲取文檔知識,實現(xiàn)挖掘的文檔數(shù)據(jù)輔助決策支持。
1 系統(tǒng)使用的人工智能技術
人工智能技術是引領未來的一種戰(zhàn)略性技術,世界上的主要發(fā)達國家都把發(fā)展人工智能作為提高生產力,提升工作效率的有效途徑。2016 年10 月,美國白宮發(fā)布《為人工智能的未來做好準備》和《人工智能研究與發(fā)展戰(zhàn)略規(guī)劃》兩份報告,將人工智能技術放到很重要的地位。2017 年7 月,中國國務院印發(fā)《新一代人工智能發(fā)展規(guī)劃》,提出將人工智能放在國家戰(zhàn)略層面進行系統(tǒng)布局[7]。2018年4月,歐盟委員會通過《人工智能通訊》,旨在建立《歐洲人工智能聯(lián)盟》,提升歐盟在人工智能相關領域的生產力和影響力。
當前,人工智能已經產生了許多細分領域,比如自然語言處理、知識圖譜、語音識別和圖像識別等,這些領域正在逐步改變著人類的生活。無論在學術界還是工業(yè)界,研究人員都在緊鑼密鼓地研究著人工智能技術,全力搶占人工智能制高點[8]。本文設計的文檔管理與應用系統(tǒng)充分吸收自然語言處理、知識圖譜和OCR等多種人工智能技術的優(yōu)勢,輔助解決文檔管理的各種難題,提升文檔的處理質量和效率,提升項目文檔管理的智能化和自動化程度,降低人力成本。以下將對項目文檔管理過程中使用的幾種關鍵智能技術進行簡單介紹。
1.1 自然語言處理
自然語言處理技術(natural language processing,NLP)可以讓計算機能夠理解人類語言,實現(xiàn)人與計算機之間的信息交互[9-10]。依據(jù)對語言處理的粒度粗細不同,自然語言處理可以分為字詞級、句法級和篇章級等三大類技術。當前環(huán)境下,自然語言處理技術被廣泛應用在文本處理[11-12]、問答系統(tǒng)[13]等領域。
本文所設計的系統(tǒng)主要處理對象是各種類型的項目文檔,從項目文檔中進行知識提取和對文檔進行查重比對及校驗是一個重點工作。本文通過使用自然語言處理字詞級技術擬解決項目文檔知識抽取難度大、文檔比對和校驗困難等問題,提升項目文檔知識挖掘與文檔處理的自動化和智能化程度。
1.2 知識圖譜
知識圖譜(knowledge graph,KG)以其強大的語義表達、存儲和推理能力,為互聯(lián)網時代的數(shù)據(jù)知識化組織和智能應用提供了有效解決方案[14]。谷歌公司的阿米特·辛格博士曾說:“The world is not made of strings,but is made of things”,這句話表達的深層含義是知識圖譜描述真實世界中存在的各種實體和概念,以及這些實體、概念之間的關聯(lián)關系[15]。通常來說,知識圖譜包括本體層和實例層,本體層是以概念/實體、關系、屬性等要素組成的語義網絡,實例層是本體為模式具體存儲的實例數(shù)據(jù)記錄。
知識圖譜能夠克服企業(yè)各種結構類型的數(shù)據(jù)不能進行有效整合和關聯(lián)、數(shù)據(jù)價值挖掘難度大等數(shù)據(jù)管理難題,其強大的語義處理和數(shù)據(jù)結構化組織能力,為企業(yè)充分挖掘數(shù)據(jù)價值支撐決策提供重要支撐,為企業(yè)的智能化信息應用提供基礎。知識圖譜的常見應用包括語義搜索[16-18]、智能問答[19-21]和個性化推薦[22]等。
本文使用知識圖譜技術對企業(yè)項目文檔及其上下游業(yè)務數(shù)據(jù)構建文檔知識圖譜,解決項目文檔知識結構化存儲與管理難、知識檢索不便捷等問題。并且,以文檔知識圖譜為基礎,支撐企業(yè)實現(xiàn)知識快速檢索、多維統(tǒng)計分析、智能問答與推薦等各種智能應用,充分發(fā)揮企業(yè)文檔知識的價值,提高知識服務的便捷性和準確性。
1.3 光學字符識別
光學字符識別(optical character recognition,OCR)是利用計算機技術對圖片上的信息內容進行提取并轉換成一種計算機可以處理的字符。基于OCR的識別系統(tǒng)將圖片文字自動轉換為字符文本,不僅可以有效縮減存儲空間,還可以減少人工處理信息的成本,提供查詢便捷性以及提升檢索速度。OCR的常見應用主要體現(xiàn)在圖片信息檢測與提取[23-24]、票據(jù)識別[25]等。
企業(yè)項目文檔中包含大量的非結構化圖片數(shù)據(jù),這些數(shù)據(jù)在實際應用中具有價值量大、難以挖掘等特征。本文擬使用OCR 技術對文檔中的圖片進行檢測與信息提取,解決圖片數(shù)據(jù)難以被機器自動挖掘價值信息的問題。并且,以使用OCR 對圖片數(shù)據(jù)進行提取的結構化信息作為文檔知識圖譜的數(shù)據(jù)來源之一,實現(xiàn)非結構化圖片數(shù)據(jù)的結構化過程,達到充分利用圖片數(shù)據(jù)信息的目標。
2 系統(tǒng)功能設計
本文所設計系統(tǒng)是基于知識圖譜、自然語言處理、OCR 和機器學習等人工智能技術設計的項目文檔智能管理與應用系統(tǒng),系統(tǒng)核心功能模塊包括項目管理、模板管理、知識圖譜和統(tǒng)計查詢。項目管理模塊提供項目管理與數(shù)據(jù)收集、文檔關鍵信息提取、文檔查重比對和企業(yè)資格審查。模板管理提供文件模板、知識抽取模板和企業(yè)資質審查資格證書模板。知識圖譜模板將抽取的知識與元數(shù)據(jù)構建知識圖譜,實現(xiàn)文檔的語義互聯(lián)。統(tǒng)計查詢模塊基于構建的文檔知識圖譜實現(xiàn)多維統(tǒng)計分析、語義檢索與智能問答等應用。依據(jù)文檔處理流程,系統(tǒng)的功能視圖如圖1所示。
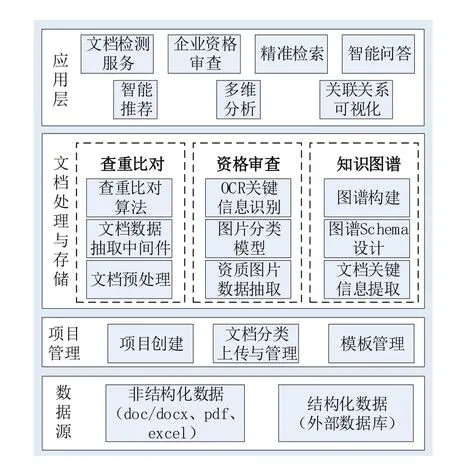
圖1 系統(tǒng)功能視圖
2.1 數(shù)據(jù)源
本文設計的文檔管理系統(tǒng),首先需要對各種類型的非結構化的電子文檔數(shù)據(jù)(doc/docx、pdf和excel等文檔)進行收集與分類存儲,同時需要從外部數(shù)據(jù)庫獲取業(yè)務上下游的結構化數(shù)據(jù)。
2.2 項目管理
項目管理功能正是以企業(yè)招投標項目為單位,創(chuàng)建招投標項目基本信息,上傳與存儲招投標過程中產生的各類非結構化文檔數(shù)據(jù)。項目管理還包含模板功能,模板管理用于管理與配置各類招標項目的招標文件模板和招標項目類型對應的企業(yè)資質審核要求模板以及文檔知識抽取模板。
2.3 文檔處理與存儲
文檔處理與存儲功能模塊是對項目管理模塊收集的各種項目文檔進行處理與統(tǒng)一結構化存儲,其主要包括三個核心功能:文檔查重比對、企業(yè)資質審查與文檔知識圖譜構建。
2.3.1 文檔查重比對
文檔查重比對是文檔處理的一個重要功能。文檔查重比對是使用自然語言處理和機器學習算法模型實現(xiàn)文檔重復率檢查和文檔版本差異比對等應用,其目標是將機械重復的文檔處理工作交由機器自主實現(xiàn),提高文檔處理效率和降低人力成本。具體而言,本系統(tǒng)提供包括招標文檔與招標文檔模板、投標文檔與招標文檔、合同與合同模板等之間的比對,以及投標文檔與投標文檔之間重復率查詢等查重比對功能。文檔查重比對包括文檔預處理、文檔數(shù)據(jù)抽取和查重比對算法等幾個關鍵部分。其中,查重比對算法包括采用simHash 和winnowing 等兩種機器學習算法模型實現(xiàn)文檔查重,采用diff算法模型實現(xiàn)文檔比對。文檔查重比對的技術方案如圖2所示。
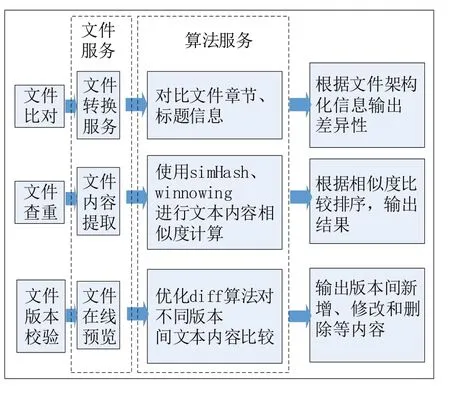
圖2 文檔查重比對技術方案
2.3.2 資格審查
資格審查是文檔處理的另外一個重要功能。資格審查是對投標企業(yè)的相關資質是否滿足招標方的要求以及對資質證明文件的真?zhèn)芜M行校驗。企業(yè)資質證明文件通常是依據(jù)招標要求由投標方寫在投標文件之中。該功能目標是將企業(yè)資質審核的問題交由機器自動實現(xiàn),進而能夠節(jié)省大量時間成本和人力成本。資格審查的實現(xiàn)首先需要從招標文件中識別出相應的資質圖片并分類,使用OCR技術從資質圖片中提取到關鍵信息以備到發(fā)證機關提供的接口進行查驗。具體而言,本系統(tǒng)進行資格審查的過程包括從投標文件中進行資質圖片數(shù)據(jù)抽取、圖片分類和OCR關鍵信息識別等,其中進行關鍵信息提取的技術路徑是使用DBnet進行文本檢測,使用CTC進行文本識別以及使用Inception V3 進行文本分類。企業(yè)資格審查的技術方案如圖3所示。
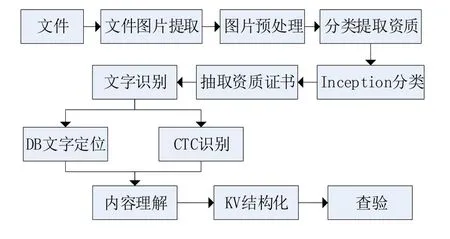
圖3 企業(yè)資格審查的技術方案
2.3.3 文檔知識圖譜構建
知識圖譜是文檔智能管理與應用的一個核心功能之一,它實現(xiàn)文檔處理結果結構化存儲與支持文檔上層應用。構建文檔知識圖譜是將項目、項目文檔、文檔關鍵要素、招投標公司等項目招標過程中產生的結構化、半結構化和和非結構化等數(shù)據(jù)進行統(tǒng)一的結構化組織和存儲。文檔知識圖譜是以文檔價值利用為出發(fā)點,解決項目文檔知識結構化存儲與管理難、知識檢索不便捷等問題,支撐企業(yè)的文檔知識快速檢索、多維統(tǒng)計分析、智能問答與智能推薦等智能應用。構建文檔知識圖譜的一個重要前提是從文檔中提取關鍵信息。
文檔關鍵信息提取是文檔處理中構建知識圖譜的一個子功能,其主要目標是從招投標文檔、合同文檔中提取有價值的要素,如從合同文件中抽取合同金額、簽訂日期、簽訂地址、支付方式、權利與義務、違約責任、爭議解決和合同變更等關鍵要素。文檔關鍵信息提取的目標是采用人工智能技術手段將文檔這種非結構化類型的數(shù)據(jù)轉化成結構化數(shù)據(jù),實現(xiàn)文檔信息的快速利用和價值挖掘。具體而言,本系統(tǒng)設計的信息抽取包括從招投標文件中進行實體抽取和文本段落抽取(文本段落可以視為一個要素)。為達到信息提取目標,使用預訓練模型和規(guī)則配置相結合的模型進行實現(xiàn)。本系統(tǒng)所使用的預訓練模型是百度中文NLP 預訓練模型飛槳ERNIE[26]。以合同要素(實體和文本段落)抽取為例,使用該預訓練模型和規(guī)則配置相結合的方法流程圖如圖4所示。
合同要素抽取主要包括以下幾個步驟:
(1)將合同以段落為單位進行劃分(合同中獨占一行的章節(jié)標題也作為一個段落)。
(2)讀取一個段落,判斷段落是否為空,如果為空則說明達到合同結尾,結束流程并返回結果;如果不為空,則進入步驟(3)。
(3)依據(jù)配置的規(guī)則判斷段落是章節(jié)標題還是一段長文本,如果是長文本則使用NRNIE 模型抽取滿足要求的實體并返回步驟(2);如果是章節(jié)標題則進入步驟(4)。
(4)判斷章節(jié)標題是否滿足需求,如果不滿足則返回步驟(2);如果滿足則開始記錄該段落讀取相鄰下一段落直至出現(xiàn)新的段落標題,記錄兩個段落標題之間的內容作為長文本要素,返回步驟(2)。
在實現(xiàn)文檔關鍵信息提取后,可以進行文檔知識圖譜構建。實現(xiàn)知識圖譜構建的過程包括圖譜Schema 設計、數(shù)據(jù)導入(文檔關鍵信息提取的數(shù)據(jù)以及源數(shù)據(jù))和圖譜構建等。其中圖譜Schema 設計是定義知識圖譜中的“實體”和“關系”; 文檔關鍵信息提取是從文檔中提取結構化關鍵信息作為知識圖譜的數(shù)據(jù)來源之一;圖譜構建是基于圖譜Schema 設計與數(shù)據(jù)源進行具體的構建過程。
2.4 文檔智能應用
文檔智能應用以滿足企業(yè)智能化建設為需求,以體現(xiàn)文檔價值為主要目標,實現(xiàn)文檔的智能化處理,提升文檔信息獲取效率和精度,從而實現(xiàn)輔助企業(yè)進行決策。本系統(tǒng)設計的文檔智能應用的核心能力包括多維文檔信息可視化統(tǒng)計與分析、文檔檢測、企業(yè)資格審查、文檔信息精準檢索、智能問答與智能推薦等。多維文檔信息可視化統(tǒng)計與分析提供自定義維度的文檔信息可視化統(tǒng)計與展示。文檔檢測提供文檔查重和比對功能。企業(yè)資格審查實現(xiàn)從文檔中獲取企業(yè)資質信息并進行校驗。文檔信息精準檢索實現(xiàn)實體和多條實體關系的精準查詢,可視化顯示實體關系關聯(lián)路徑。智能問答提供基于自然語言處理技術的問句意圖解析和答案精準匹配,實現(xiàn)智能交互。智能推薦實現(xiàn)相似內容推薦,輔助文檔編寫。
3 系統(tǒng)架構設計與功能展示
本文設計的項目文檔智能管理與應用系統(tǒng)的系統(tǒng)架構與流程實現(xiàn)如下文所示。
3.1 系統(tǒng)架構
本系統(tǒng)的整體架構設計如圖5所示,其包括數(shù)據(jù)層、預處理層、算法層、存儲層、能力層和應用層,架構中各層的主要功能如下。
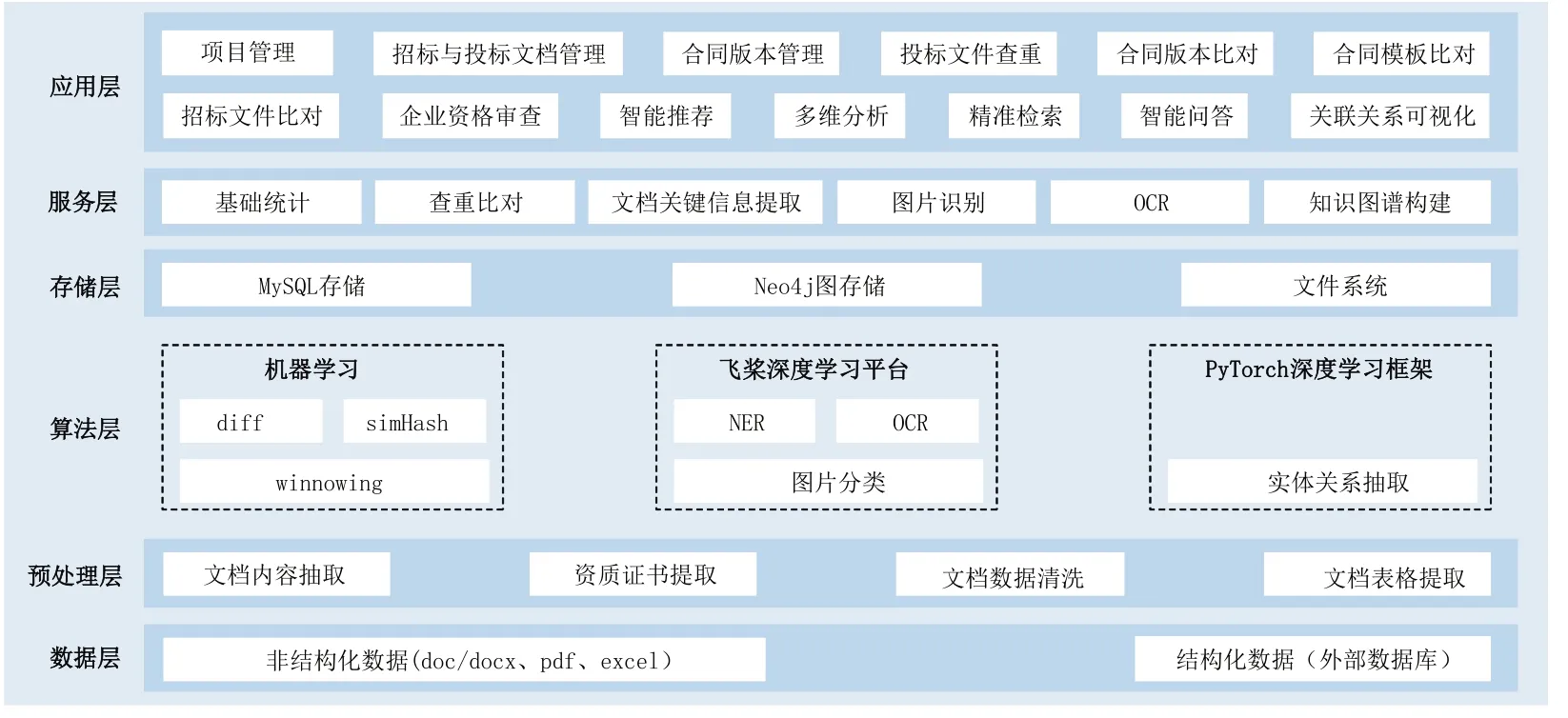
圖5 系統(tǒng)整體架構
(1)數(shù)據(jù)層:作為系統(tǒng)建設的第一個環(huán)節(jié),數(shù)據(jù)層收集項目管理上下游的不同來源的數(shù)據(jù),包括doc/docx、pdf、excel 等非結構化格式以及外部數(shù)據(jù)庫的結構化數(shù)據(jù),為系統(tǒng)建設提供數(shù)據(jù)支撐。
(2)預處理層:對數(shù)據(jù)層獲取的非結構化的文檔數(shù)據(jù)進行預處理,主要包括文檔數(shù)據(jù)清洗、格式轉換、文字內容提取、資質證書提取和文檔表格提取等,將文檔預處理成算法層可以讀取的輸入數(shù)據(jù)模式,以便進行信息抽取。
(3)算法層:對文檔數(shù)據(jù)進行處理和信息抽取,支撐文檔查重比對和文檔數(shù)據(jù)結構化過程。具體而言,使用diff、simHash 和winnowing 等機器學習算法實現(xiàn)文檔查重比對;基于百度公司的飛槳深度學習平臺實現(xiàn)文檔命名實體識別、OCR 和圖片分類等相關的算法服務;基于Facebook 公司的PyTorch 深度學習框架實現(xiàn)文檔數(shù)據(jù)的實體關系抽取。
(4)存儲層:實現(xiàn)對原始的非結構化文檔數(shù)據(jù)、結構化的相關文檔管理上下游數(shù)據(jù)以及從文檔中抽取的數(shù)據(jù)進行存儲。其中,Neo4j 圖數(shù)據(jù)庫用于存儲所有的結構化數(shù)據(jù),為知識圖譜構建與應用提供支撐。
(5)服務層:基于算法層和存儲層的能力為系統(tǒng)提供基礎數(shù)據(jù)統(tǒng)計、文檔查重比對、文檔關鍵信息提取、文檔中的圖片識別與OCR 以及知識圖譜構建等服務能力。
(6)應用層:實現(xiàn)文檔智能管理與應用,主要包括項目管理、招標與投標文檔管理、招標與投標及合同的查重比對、企業(yè)資格審查、文檔多維分析、智能推薦與智能問答、精準檢索和關聯(lián)關系可視化展示等功能。
3.2 系統(tǒng)實施流程
基于系統(tǒng)的主要功能與系統(tǒng)架構,系統(tǒng)實施流程設計如圖6所示。
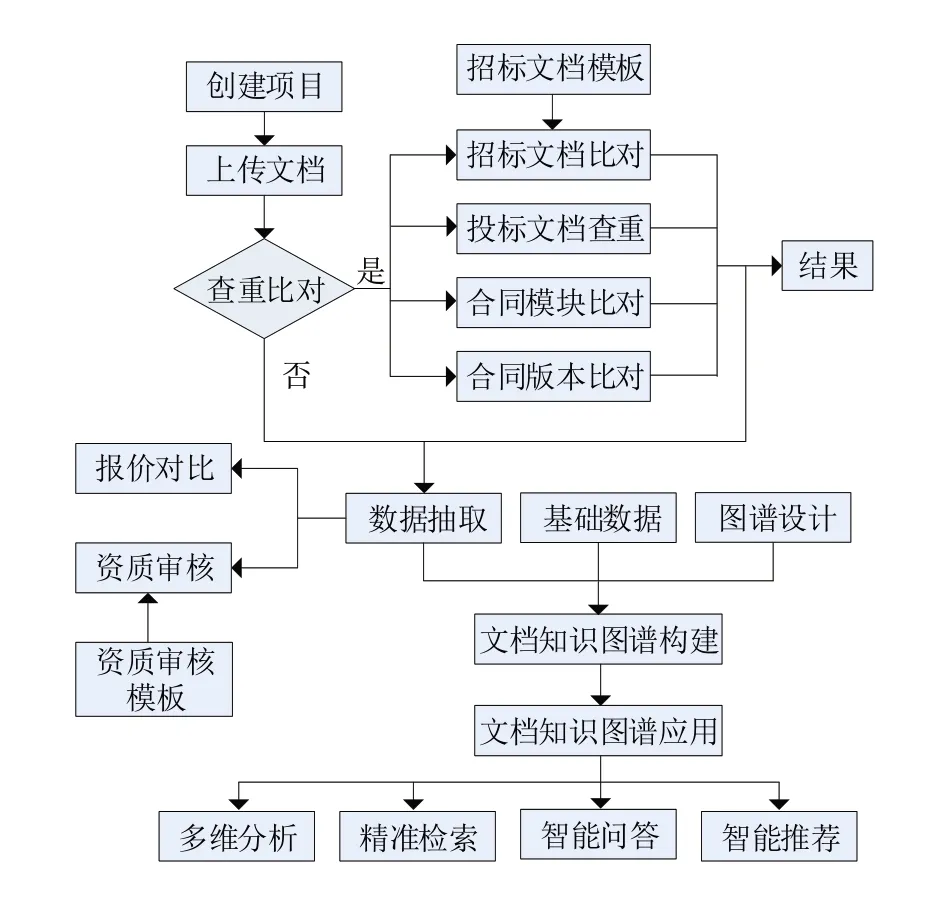
圖6 系統(tǒng)實施流程
(1)用戶通過“創(chuàng)建項目”功能新建項目并填寫項目信息。每個項目是以招標項目為基本單位進行組織。
(2)項目創(chuàng)建完成后,通過“上傳文檔”功能分類上傳項目相關的招投標文檔,包括招標模板文檔、招標文檔、各個投標公司的投標文檔、各個版本的合同文檔等。
(3)判斷用戶是否需要使用文檔“查重比對”功能。如果需要進行文檔查重比對,則可細分選擇招標文檔與招標文檔模板、合同與合同模板以及各個版本合同之間的比對,還可以進行投標文檔與投標文檔之間的重復率檢測,返回結果并進入“數(shù)據(jù)抽取”功能;如果不需要進行文檔查重比對,則直接進入“數(shù)據(jù)抽取”功能模塊。
(4)無論用戶是否使用文檔查重比對功能都會流轉到“數(shù)據(jù)抽取”功能模塊,該功能模塊既可以從招投標文檔及合同文檔中抽取關鍵信息,也可以根據(jù)需求對投標文檔中的企業(yè)資質文件和投標標價進行提取。對投標文件中的報價信息進行抽取用于“報價對比”功能,實現(xiàn)比對各個投標企業(yè)的報價及報價明細。
(5)完成根據(jù)資質審核模板中配置的資質證明文件類型從投標文件中抽取出企業(yè)資質證明文件圖片之后可以使用“資質審核”功能。該功能使用OCR 技術對資質文件圖片中的關鍵信息進行提取并依據(jù)這些信息到相應的發(fā)證機關網站查驗真?zhèn)巍?/p>
(6)利用“圖譜設計”“基礎數(shù)據(jù)”和“數(shù)據(jù)抽取”三個模塊的功能實現(xiàn)構建文檔知識圖譜。“圖譜設計”模塊是以可視化方式設計文檔知識圖譜Schema,是構造知識圖譜的必要前提。“基礎數(shù)據(jù)”模塊管理招標過程中的上下游結構化數(shù)據(jù)信息,可以實現(xiàn)關系型數(shù)據(jù)庫中的結構化數(shù)據(jù)到知識圖譜的映射。“數(shù)據(jù)抽取”模塊實現(xiàn)非結構化文檔中提取結構化信息并融合到知識圖譜。“基礎數(shù)據(jù)”和“數(shù)據(jù)抽取”都是為知識圖譜的構建提供數(shù)據(jù)支撐。
(7)在知識圖譜Schema 設計和支撐數(shù)據(jù)準備完成之后進入“文檔知識圖譜構建”功能模塊進行文檔知識圖譜的構建過程。文檔知識圖譜構建完成后可以通過“數(shù)據(jù)清洗”和“歸一消歧”等操作實現(xiàn)手動調優(yōu)和知識圖譜重構。
(8)在文檔知識圖譜構建完成之后,進入“文檔知識圖譜應用”功能模塊。該模塊的“多維分析”“精準檢索”“智能問答”和“智能推薦”等四個主要功能支撐企業(yè)文檔的智能應用。
3.3 系統(tǒng)功能展示
本小節(jié)將對系統(tǒng)的部分功能進行效果展示。圖7 和圖8 是項目信息創(chuàng)建和項目相關文檔上傳界面。

圖7 項目信息創(chuàng)建功能
圖8 項目文檔上傳功能
圖9 與圖10 分別展示項目文檔的查重與比對功能。圖9中左邊文檔中的紅色帶下劃線部分在右邊文檔中可以找到相同的描述(紅色部分)。圖10 展示兩個文檔之間的比對功能,綠色帶下劃線和紅色帶下劃線字體表示右邊文檔相對于左邊文檔增加和刪除的內容。

圖9 文檔查重功能
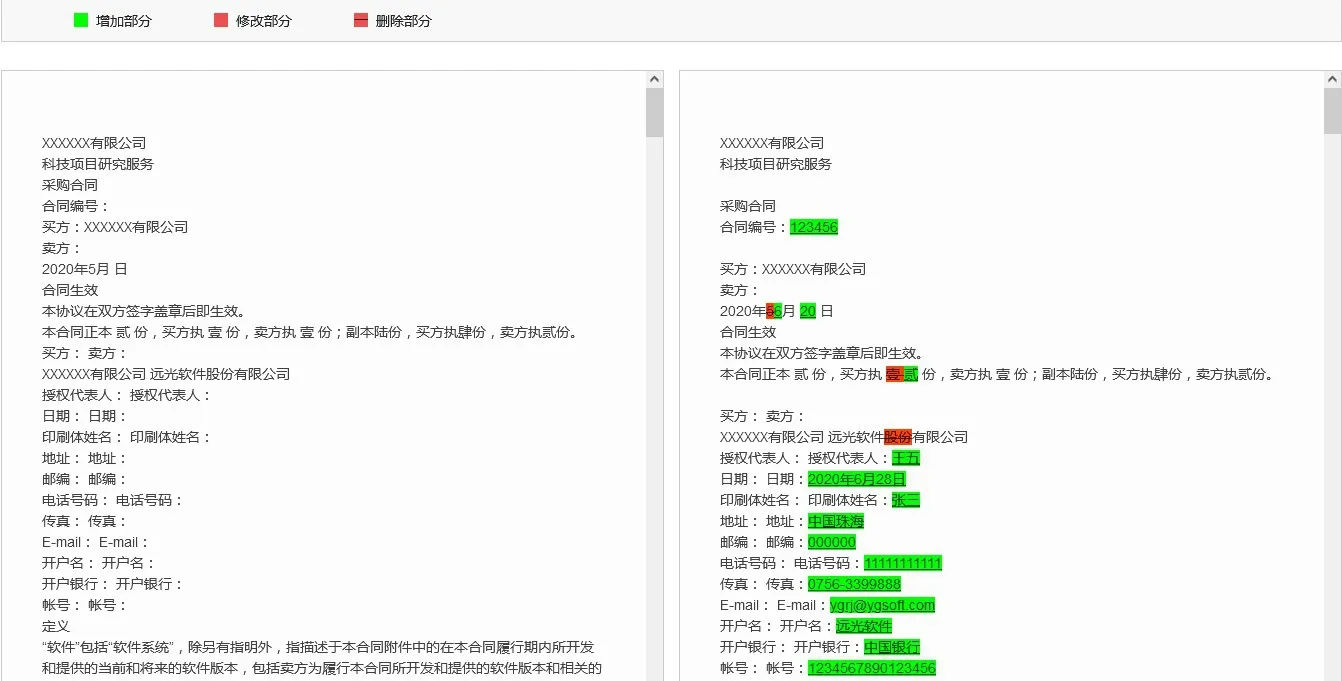
圖10 文檔比對功能
圖11是從文檔中提取出企業(yè)資格證書并進行識別的過程及結果,根據(jù)設計要求的字段均能正確提取。在提取字段內容后根據(jù)字段“名稱”和“統(tǒng)一社會信用代碼”以及證書類型可以到相應的發(fā)證機關驗證,從而判斷該資質的真?zhèn)巍?/p>
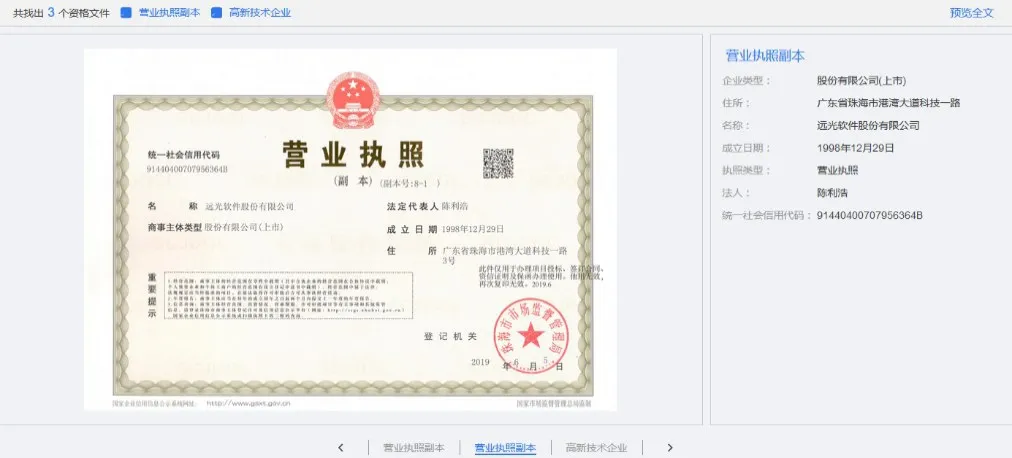
圖11 企業(yè)資質證書識別功能
圖12是文檔知識圖譜Schema 設計樣例,其包含7個實體(“事物”看作所有實體的根節(jié)點)和14 個關系。圖13 是項目及項目文檔多維統(tǒng)計功能,圖中展示的統(tǒng)計維度包括年份、項目總個數(shù)、投標次數(shù)、投標單位個數(shù)、項目所在地區(qū)、項目類型及個數(shù)、項目標的類型及個數(shù)等。
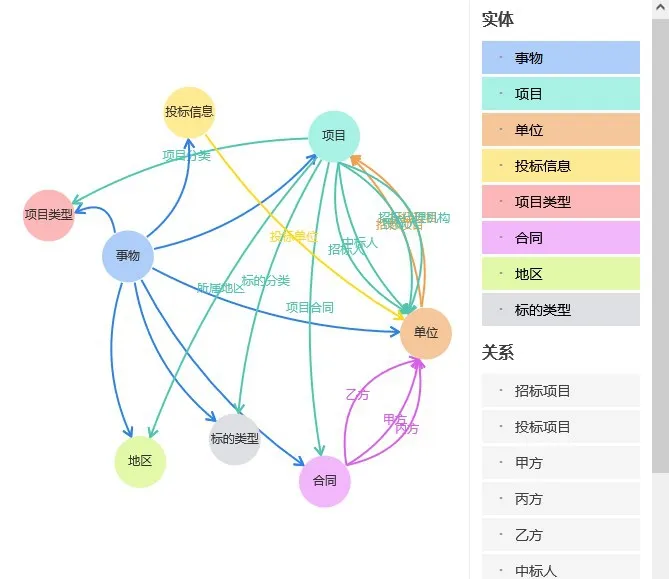
圖12 文檔知識圖譜Schema設計功能
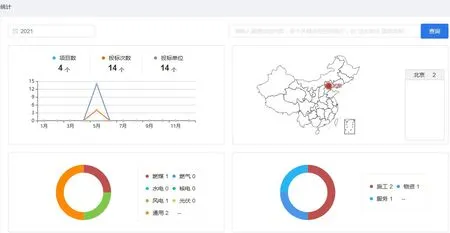
圖13 文檔多維統(tǒng)計分析功能
4 結語
現(xiàn)有的文檔管理系統(tǒng)主要存在兩方面的問題:(1)以整個文檔為管理對象,因不能提取文檔中的更細粒度的價值信息而導致文檔的價值不能被充分挖掘,且因忽略了文檔與文檔及文檔知識之間的關聯(lián)關系構建,導致整個文檔與文檔信息的組織較為松散;(2)文檔處理大多是使用人工進行的,效率低下且容易發(fā)生人為失誤。本文采用自然語言處理、知識圖譜和OCR等人工智能技術實現(xiàn)的基于知識圖譜的文檔智能管理系統(tǒng)能夠有效解決以上問題。體現(xiàn)在本文所設計系統(tǒng)的四大核心創(chuàng)新點::①智能抽取文檔關鍵信息。基于自然語言處理、OCR 和機器學習等相關技術,對于根據(jù)業(yè)務需求制定的數(shù)據(jù)模型(以知識圖譜Schema 設計進行表達)中的無法從已有結構化的數(shù)據(jù)源中獲取的數(shù)據(jù)創(chuàng)建機器學習模型自動從文檔中進行抽取。②智能企業(yè)資質審查。基于知識圖譜和OCR 技術對企業(yè)進行資質審核。③智能文檔查重比對。基于自然語言處理和機器學習算法模型實現(xiàn)文檔查重和比對等功能。④智能文檔多維分析。基于知識圖譜、自然語言處理和機器學習等相關技術進行文檔預處理、知識抽取和知識存儲,實現(xiàn)非結構化文檔知識的結構化組織與管理,并在此基礎上展開文檔信息多維統(tǒng)計與分析,支持文檔信息智能查詢與精準檢索,支持文檔信息智能問答與智能推薦。該系統(tǒng)能夠實現(xiàn)文檔價值深度挖掘,大幅提高文檔處理質量和效率,降低人力成本和提升工作效率。值得注意的是本文設計的項目文檔智能管理與應用系統(tǒng)在應用中可能存在功能設計不足、通用性較差等問題,在未來需要結合企業(yè)實際應用逐步完善系統(tǒng)的功能設計,提升系統(tǒng)的易用性和通用性。
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
商界(2019年12期)2019-01-03 06:59:05
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
IT經理世界(2018年20期)2018-10-24 02:38:24
中國科技論壇(2017年7期)2017-07-25 08:49:53
小康(2017年16期)2017-06-07 09:00:59
南風窗(2016年19期)2016-09-21 16:51:29
