Nutch在中醫藥信息融合中的應用研究
2023-04-13 11:38:54區卓越覃姜維孫曉翠
現代計算機 2023年3期
區卓越,覃姜維,趙 峰,孫曉翠,4*
(1.廣東藥科大學醫藥信息工程學院,廣州 510006;2. 廣東工業大學數學與統計學院,廣州 510520;3. 中鐵工程設計咨詢集團有限公司,北京 100071;4. 廣東普通高校工程技術研究中心-醫藥信息真實世界工程技術研究中心,廣州 510006)
0 引言
2000 年以來,隨著互聯網技術的快速發展以及數據之間高度交叉的發展趨勢,再加上民眾對健康意識、醫藥意識的逐步增強,民眾對于中醫藥信息的需求日益增加,鑒于此,中醫藥信息融合的相關應用研究推陳出新。其中,設計以中醫藥信息為導向的搜索引擎是滿足信息搜尋需求的好方法。分析國內外現有的信息檢索系統,存在以下問題,一是缺乏針對性,如今市面上搜索引擎的檢索對象過于寬泛,并不是面向某一特定領域的垂直搜索引擎[1],沒有對中醫藥信息做出針對性的歸納、關聯處理與融合[2],用戶需花費大量時間在無關數據中獲取所需的中醫藥信息。隨著數據采集量的增多與數據更新頻率的增高,加之缺乏必要的數據過濾與篩選[3],搜索引擎的檢索信息有效率與使用率會逐步下降,難以實現對中醫藥信息的針對性搜索服務;二是欠缺共享性,由于中醫藥信息來源分散,數據呈現形式多樣化,數據結構形式不盡相同,傳統的基于SQL 語句的信息檢索系統難以實現對中醫藥信息的精確搜索。即便是使用非關系型的數據庫對數據進行存儲,也難以根據數據的重要性做出預測性的結果排序返回至用戶[4],造成存儲空間、算力資源和數據價值的浪費。隨著國家“互聯網+”戰略的實施與“大健康”理念的提出,在大數據時代下[5],信息化能有效推動經濟社會發展,有效推進以國內大循環為主體的新發展格局的構建。就中醫藥現代化、中醫藥信息化來講,亟需構建以信息技術為中心的醫藥數據處理分析[6]、數據挖掘[7-9]、知識發現[10]等服務建設面向中醫藥信息的搜索引擎,提供大眾的醫藥信息獲取途徑,喚醒民眾的醫藥健康意識,并為衛生部門提供中醫藥信息普及宣傳的輿論口,為監管部門把握醫藥信息化發展現狀、制定政策、定制惠民服務等提供輔助決策支持[11],也可搭配其他內容管理系統平臺如Drupal[12]、WordPress[13]或Joomla[14]進行中醫藥信息的深度利用與挖掘。
本文從現實出發,充分考慮當今數字時代尤其是疫情時代下的實際情況,秉承中醫藥現代化與中醫藥信息融合應用的發展理念,設計并實現一款“中醫藥信息搜索引擎”。該搜索引擎以開源軟件Nutch 為基礎,結合其“網絡爬蟲”與“全文搜索”兩大功能,解決了漢字識別與搜索的改進、以用戶友好性為導向的網頁UI 優化等問題,實現了類似百度、必應、Yandex 等搜索引擎的功能,減少了無關信息如廣告商、營銷號的干擾,使獲取中醫藥信息的過程更加便捷、精確,更有針對性地、高效地向民眾提供實用的中醫藥信息。
1 中醫藥信息搜索引擎的設計與實現
1.1 Nutch簡介
經過比較后[15],決定使用Nutch進行項目搭建。Nutch 是Apach Lucene 下屬的一個高度可擴展、成熟的Web 爬蟲程序,用于處理各種數據采集任務,包括“網絡爬蟲”和“全文搜索”兩大部分,是一個優秀的、基于Java 的開源爬蟲軟件,在城市交通[16]、社交情報[17]、電商貿易[18]、就業招聘[19]等領域有廣泛應用前例。本項目將會基于Nutch設計與實現中醫藥信息搜索引擎。Nutch的工作流程如圖1所示。
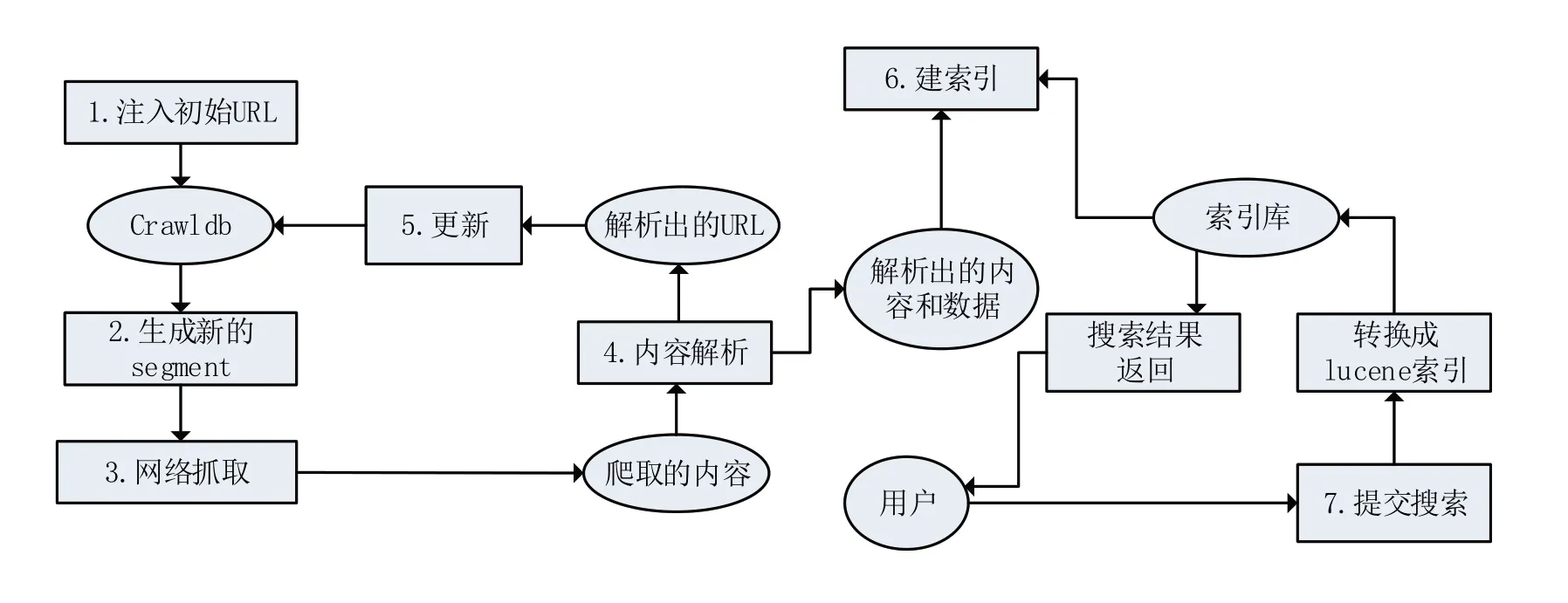
圖1 Nutch工作流程
其步驟可總結如下:
(1)注入(inject)初試URL:將管理員提供的URL 進行統一化及過濾非法URL、重復URL后,將剩余的可用URL 及其最新狀態存入Crawldb數據庫。
(2)生成(generate)新的segment:按照Crawldb中的URL生成抓取列表并存入segments目錄中。
(3)網絡抓取(fetch):按照上一步在segments目錄中生成的抓取列表進行抓取,同時對抓取內容解析。
(4)內容解析(parse):將抓取的內容解析為兩大部分:URL與數據內容。
(5)更新(update)Crawldb:更新存儲URL的Crawldb,為下一輪的抓取做好新的URL準備。
(6)建索引(index):由于Nutch 是Apache Lucene的子項目,Nutch使用Lucene完成數據索引,通過索引庫完成用戶搜索的功能。
(7)用戶搜索:用戶鍵入關鍵字進行檢索,Nutch 檢索到內容后,將結果按照一定的算法打分后排序并返回至用戶。
上述過程中的步驟(1)~(6)即“網絡爬蟲”部分,步驟(7)即為“全文搜索”部分。
概括來講,Nutch 是以管理員給定的網站作為入口進行爬取,將所爬取的內容進行解析,并建立相應的爬取結果索引,再通過一定的算法對搜索結果進行評分、排序以響應用戶的搜索需求,以實現爬取、建索引、搜索的高度統一。
1.2 Nutch的評分機制
在1.1 的工作流程步驟(7)中,Nutch 使用評分機制對搜索結果進行評分,按照分數排序后返回至用戶。
Nutch 構建于Apach Lucene 之上,在Lucene中,文檔的分數受用戶查詢語句影響,在用戶進行搜索時實時返回排序結果。而Lucene 的評分機制在Lucene的Similarity類中,用公式表示,即:
公式(1)基于TF-IDF 算法進行評分(具體解釋見表1),通過查詢詞項在文檔中出現的頻率TF 與詞項在整個文檔集合中的逆文檔頻率IDF進行計算[20]。TF-IDF算法公式如下:
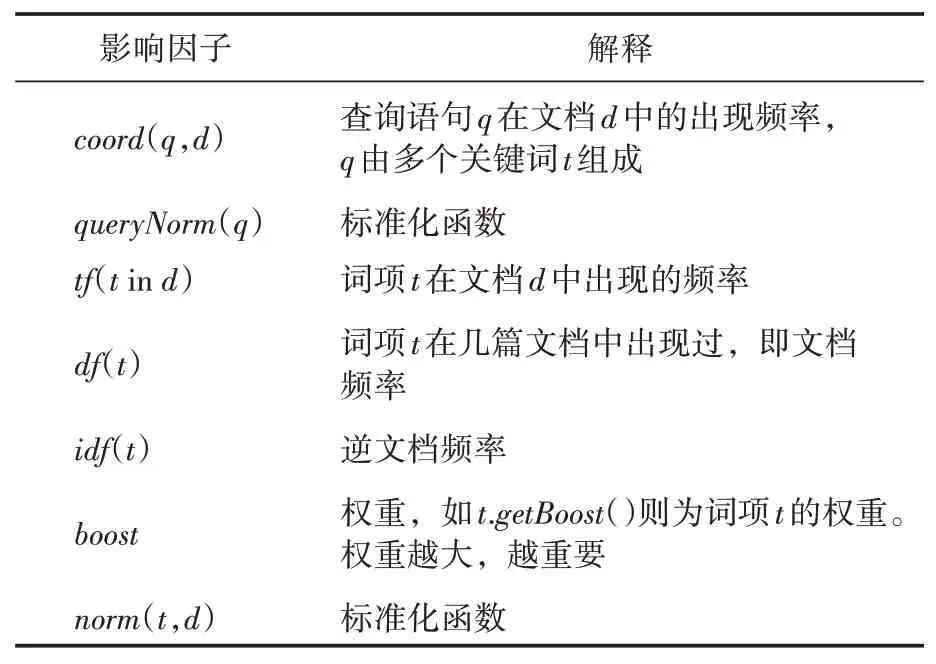
表1 Lucene得分計算公式解釋
1.3 基于Nutch的中醫藥信息搜索引擎
基于Nutch進行開發后的中醫藥信息搜索引擎如圖2所示,此時輸入英文或數字才能正常搜索;若輸入中文搜索,則會出現亂碼,搜索失敗,如圖3所示。
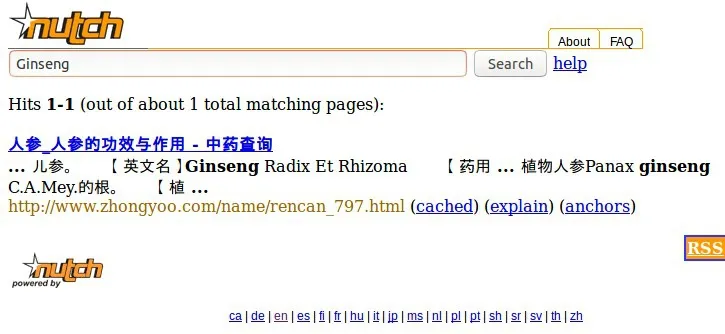
圖2 輸入“Ginseng(人參)”搜索
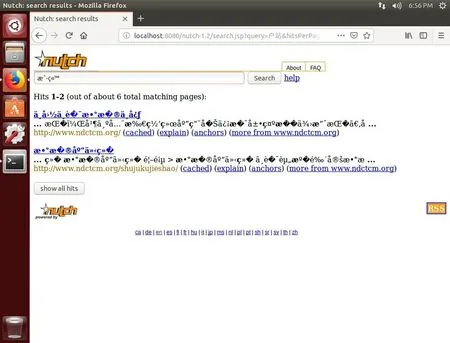
圖3 搜索中文出現亂碼
仍然面臨的難題,一是Nutch本身不支持對中文的識別與搜索,鍵入漢字進行檢索時,頁面會發生亂碼現象;二是Nutch的頁面對檢索結果的呈現過于簡陋,效率低下,缺乏用戶友好性。下面介紹漢字識別與搜索的改進、以用戶友好性為導向的網頁UI優化等問題的實現方法。
2 中醫藥信息搜索引擎的優化及應用結果分析
2.1 漢字識別與搜索
長久以來,漢字的識別與搜索一直是國內研究的重點課題之一。為了解決漢字的識別與劃分,涌現了許多優秀的漢字分詞組件,如北京理工大學張華平博士團隊研發的NLPIRICTCLAS 分詞系統[21]、清華大學自然語言處理與社會人文計算實驗室研發的THULAC 分詞包[22]、盤古分詞等,也有學者使用詞典進行中文分詞。由于Nutch源于外國,故其對漢字的搜索與識別能力低,甚至會出現無法搜索、亂碼等情況,故需要對其進行優化與改進,使其支持漢字的識別與搜索。Tan 等[23]曾探索過Nutch處理中文索引的優化方案。綜合比較各種方案[24-26],本項目將使用漢字分詞組件IKAnalyzer對Nutch 進行優化和改進。
同Nutch 一樣,IKAnalyzer 也基于Java 語言開發,是一個輕量級的漢字分詞組件工具包。IKAnalyzer 使用“正向迭代最細粒度切分算法”進行漢字分詞,主要包含“細粒度”和“智能分詞”兩種切分模式,不僅可實現中文分詞處理,還兼容日文、朝鮮文字符等[27]。
為使Nutch 實現基于IKAnalyzer 的中文分詞,具體來講,即是修改Nutch 相關代碼接口、xml 文件,將分詞軟件嵌入Nutch 后,使用javacc 再次進行編譯,即可使其支持中文的識別與搜索功能。
首先,改寫安裝目錄/src/java/org/apache/nutch/searcher 下的Query.java,為其導入一個org.apache.nutch.analysis 包下的異常類ParseException,同時改寫line 456附近的parse函數,使它拋出一個異常ParseException,用以處理解析特點語言(中文)時發生的異常事件。
接著,修改上方目錄中/analysis 路徑下的NutchAnalysis.jj,將其從按字劃分修改為按詞劃分。具體來講,就是將該文件中line 130 附近的“|
在新生成的java 文件中,找到NutchAnalysis.java,所有用于解析文本的分詞插件都需要重寫實現NutchAnalyzer 類中的tokenStream 抽象方法,首先為其導入包org.wltea.analyzer.lucene.IKTokenizer,同時重新編寫line 51 附近的兩個parseQuery 函數,具體地,即分別讓它們拋出異常ParseException,處理解析字符串時發生的異常事件。接下來繼續修改繼承自NutchAnalyzer的NutchDocumentAnalyzer類。
修改同一目錄下的NutchDocumentAnalyzer.java,為其添加分詞組件IKAnalyzer,使用IKAnalyzer 的分詞方法替換實現Nutch 原來的分詞方法。具體方法是,在該文件中導入包org.wltea.analyzer.lucene.IKAnalyzer 和org.apache.lucene.analysis.tokenattributes.*,同時重新編寫line 110 附近處的函數,為其加入IKAnalyzer 實例。具體地,即將原代碼的analyzer 對象賦值為IKAnalyzer實例并返回。
上述各類的繼承關系如圖4所示。
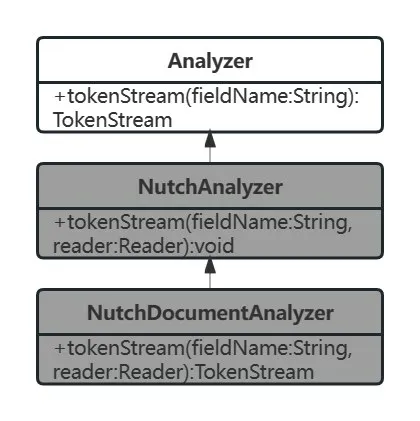
圖4 類間繼承關系的UML
其中的Analyzer 抽象類用作Nutch 的底層分析器,其來自于2.2 小節提到的Lucene。陰影部分則是經過優化的部分。
接下來按Nutch 安裝目錄下的配置文件build.xml 添加分詞包的信息。在Nutch 目錄下執行ant 編譯命令,它自動找到build.xml 并開始執行。
執行成功后,繼續用“ant war”編譯,可以在build目錄下得到以“nutch-1.2”為名的“.job”“.war”以及“.jar”文件,將上述三個文件覆蓋Nutch目錄下的同名文件。
此時需要更改tomcat 服務器的設置,將上述的“nutch-1.2.war”復制至tomcat 安裝目錄中的webapp 目錄,待其自動解壓。并在解壓后目錄中的/WEB-INF/classes 中修改nutch-site.xml,添加屬性“plugin.includes”,賦值為“protocolhttp”“urlfilter-regex”“analysis-(zh)”等,否則無法顯示搜索結果而顯示空白。
然后修改tomcat/conf 下的server.xml,找到下列屬性并修改:
然后重啟tomcat。此時可以使用中文查詢,如以“頭痛”為關鍵字搜索,結果見圖5,可見此時Nutch已支持漢字的識別與搜索。
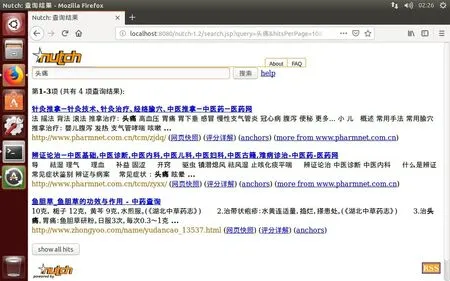
圖5 優化后支持漢字的中醫藥信息搜索引擎
加入中文分詞插件優化后的Nutch工作流程如圖6所示,對比圖1,陰影部分則為優化部分。
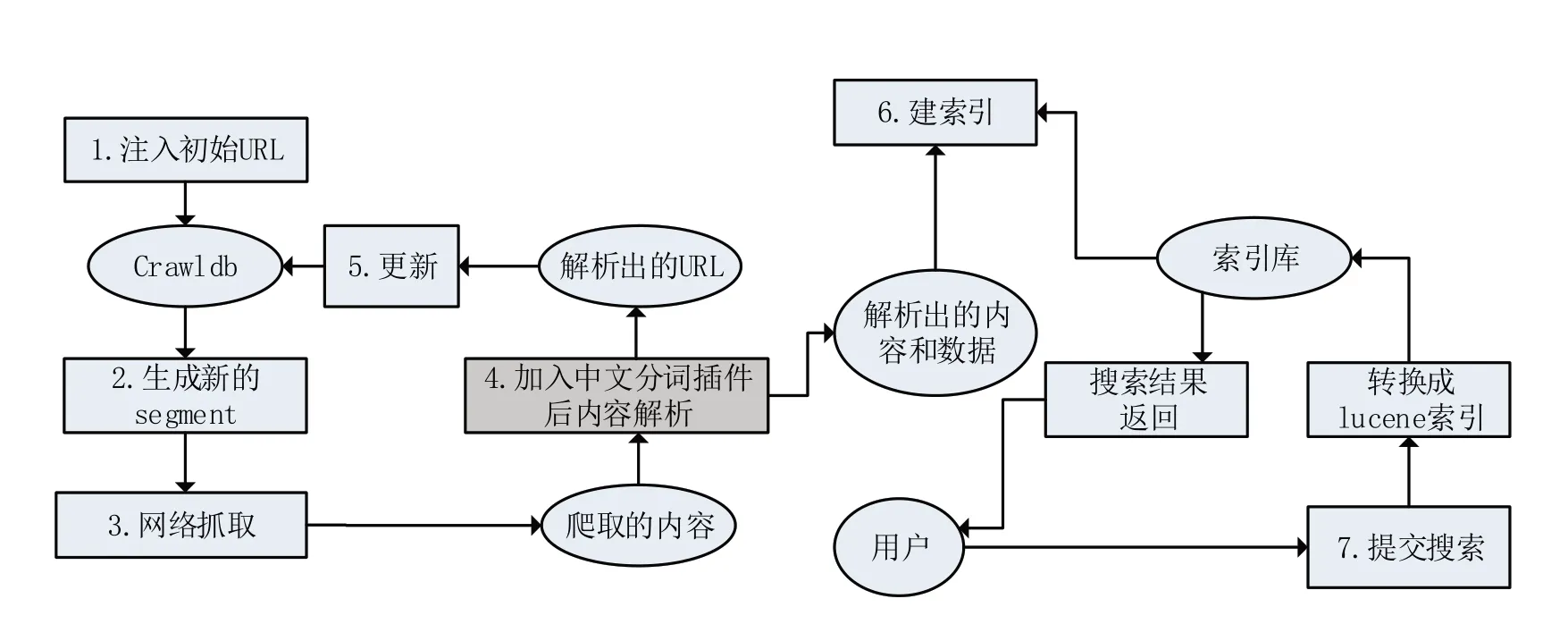
圖6 優化后的Nutch工作流程
2.2 以用戶友好性為導向的網頁UI優化
Nutch 本身的搜索結果呈現頁面較簡單,極度缺少用戶友好性。故需對頁面UI 進行優化改進,使其搜索結果更加突出,對用戶更友好。
首先,找出index.jsp 頁面,這個是Nutch 默認的首頁,需要根據中醫藥特色重寫該頁面,刪除其語言選擇、幫助、Nutch 介紹等無關緊要的功能,加入面向中醫藥信息的內容。
其次,核心是對search.jsp 頁面的重寫。如刪除“
同時,將“”>”改為“”,增加可讀性;同時可刪除下兩行的queryLang 和anchors,項目不需要該額外搜索結果。
其中標簽有“i18n”字眼的靜態代碼用以自動生成搜索結果數值統計,被寫死以至于無法顯示成中文,故將其刪除,并將搜索結果數值統計改成:
為使搜索結果的關鍵字在頁面中高亮顯示、更加突出,修改./include/style.html的CSS配置文件,譬如將.highlight 的樣式屬性修改為紅色、加粗等,符合用戶閱讀習慣,更具用戶友好性。
優化完成后,重啟tomcat 服務器,打開搜索頁面,可見美觀許多(見圖7)。輸入文字搜索,搜索結果加粗、標紅,更加突出(圖8)。
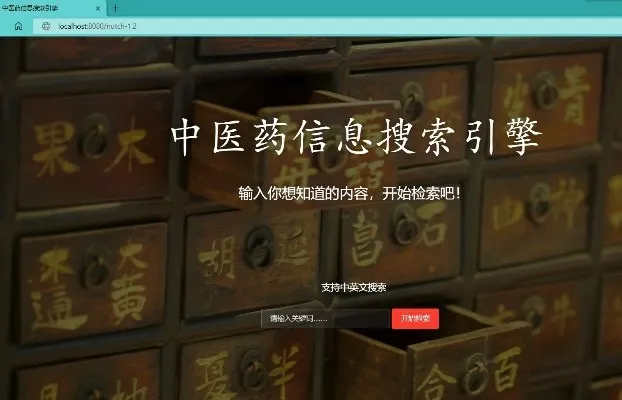
圖7 頁面UI優化后效果
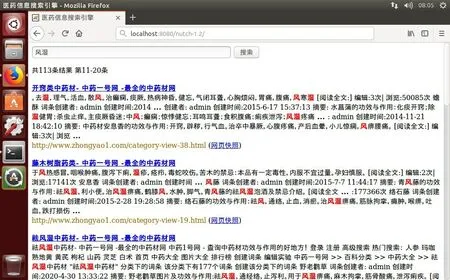
圖8 以用戶友好性為導向的搜索結果頁面
基于Nutch的中醫藥信息搜索引擎優化改進前后,發生的改變具體見表2。

表2 優化前后對比
3 結語
本文首先對Nutch的組成、工作流程等特點進行了描述與介紹,提出了疫情時代下民眾獲取中醫藥信息的新穎解決方法,即基于Nutch構建中醫藥信息搜索引擎。鑒于Nutch不支持漢字的識別與搜索,使用漢字分詞組件IKAnalyzer對Nutch 進行優化改造,提高了中文醫藥信息識別與搜索的準確性;并優化網頁UI 使搜索結果更加突出。基于Nutch的中醫藥信息搜索引擎契合當今“互聯網+”的時代發展潮流,符合醫藥信息化的發展趨勢,是中醫藥現代化的一個應用嘗試,能有效地處理、存儲、分享醫藥數據,相信在中醫藥信息資源處理的未來發展中會受到越來越多的重視。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
現代臨床醫學(2021年3期)2021-07-16 07:36:44
中國民間療法(2021年5期)2021-06-09 09:21:42
知識經濟·中國直銷(2017年7期)2017-07-24 14:12:41
中國衛生(2016年11期)2016-11-12 13:29:24
中國衛生(2015年12期)2015-11-10 05:13:38
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
電腦愛好者(2011年11期)2011-06-22 08:20:18
