新興技術概念辨析與識別方法研究進展
2023-03-29 16:46:34高楠周慶山
現代情報 2023年4期
高楠 周慶山
關鍵詞: 新興技術; 識別方法; 演化方法; 概念屬性
DOI:10.3969 / j.issn.1008-0821.2023.04.014
〔中圖分類號〕G252.8 〔文獻標識碼〕A 〔文章編號〕1008-0821 (2023) 04-0150-15
隨著新一輪科技革命和產業變革的加速演進,新興技術識別成為影響一個國家和地區未來發展戰略的重要議題。從歐盟“地平線2020” 計劃到德國“工業4 0” 戰略計劃, 再到中國的“十四五”國家科技創新規劃, 世界各國(地區)都在積極制定科技發展戰略并加強科技創新部署。在這樣的社會大背景下, 技術的增長和更新迭代的速度持續提升, 同時, 技術之間的組合性、交叉性、變化性和依賴性也在不斷占據越來越重要的地位, 尤其是新興技術可能會改變已有產業的發展形態, 創造出新興行業, 并催生出一系列新的發展模式, 對加強科技戰略規劃、占領科技制高點、支撐科研前瞻布局等具有重要作用, 而如何快速、準確地識別出具有較大發展潛力的新興技術成為各國(地區)關注的熱點。從國家角度來講, 新興技術的預測與識別有助于國家技術的總體布局與發展規劃; 從企業角度來講, 發現并識別具有潛力的新興技術有助于提前規劃、快速研發、節約成本和降低風險, 更有助于確定研發重點和投資方向; 從研究人員個人的角度來講, 識別新興技術可以幫助研究人員了解領域新動向, 使得關鍵的早期投資能更好地獲得回報, 促進產學研的結合。因此, 拓展新興技術識別方法,提高新興技術識別準確性, 縮短新興技術預測周期, 深入把握技術領域適用性, 描繪技術演化路徑, 對于新興技術在未來的發展布局具有重要戰略意義, 也是迫切的現實需要。
1“新興技術”及相關概念
“新興技術” 已經成為許多研究領域的核心術語之一, 尤其是在科學計量學、文獻計量學和技術挖掘領域。盡管被頻繁使用, 但目前仍然沒有形成明確的定義和屬性特征。
新興技術有許多不同的表達方式, 如新興研究主題、新興趨勢、新興研究領域等[1] , 其常用的英文表達為“Emerging technology”, Rotolo D 等[2]提煉了新興技術表達方式, 包括emerg? technolog?、tech? emergence、emergence of? technolog?、emerg?scien? technolog?、emerg? research、emerg? theme等, 并發現學者在開展新興技術相關研究時, 標題中出現“emerging” 及“emergence” 的覆蓋率高達57%, 且在表達“新興技術” 的概念時, “Emer?ging technology” 與“technology emergence” 經常交替使用。因此, 要追溯新興技術的起源, “emer?gence” 是核心關鍵詞之一。Burmaoglu S 等[3] 以科學哲學、復雜性理論和經濟學3 個學科中“emer?gence” 概念的演變為切入點, 揭示了新興技術的理論背景。“emergence” 一詞最早出現于19 世紀末, 并于20 世紀初在科學哲學領域流行起來; 20世紀30 年代, 該詞出現在復雜系統的研究中; 20世紀50 年代, 經濟學家從進化經濟學的角度對“emergence” 進行研究。
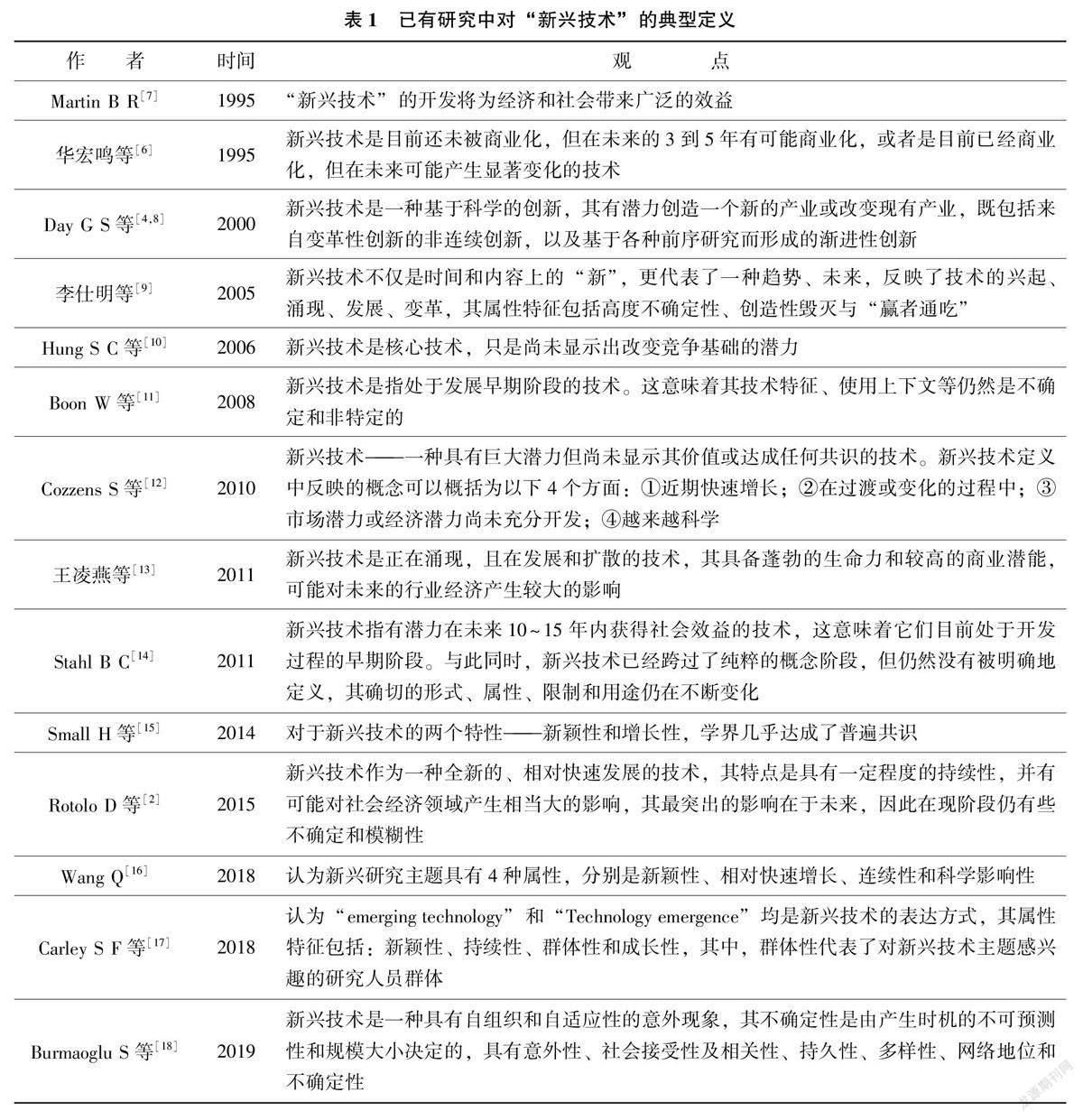
國外關于新興技術開創性的研究成果集中出現在由沃頓商學院的Day G S 等[4] 在2000 年出版的Wharton on Managing Emerging Technologies 著作中,提出“新興技術是一種基于科學的創新, 其有潛力創造一個新的產業或改變現有產業, 既包括來自變革性創新的非連續創新, 以及基于各種前序研究而形成的漸進性創新”。全球結構和標準工作組將新興技術定義為: 已具備一定的實現條件, 但尚未得到充分、成熟的應用的技術[5] 。國內學者亦對新興技術展開積極研究, 華宏鳴等[6] 最早于1995年出版的《高新技術管理》中提出, “新興技術是目前還未被商業化, 但在未來的3 到5 年有可能商業化, 或者是目前已經商業化, 但在未來可能產生顯著變化的技術”。目前最受業界認可的是RotoloD 等[2] 給出新興技術的定義: “新興技術作為一種全新的、相對快速發展的技術, 其特點是具有一定程度的持續性, 并有可能對社會經濟領域產生相當大的影響, 其最突出的影響在于未來, 因此在現階段仍有些不確定和模糊性”。其他學者對于新興技術的定義如表1 所示。
綜上, 本文認為新興技術是一種正在興起或相對快速發展的、具有激進新穎性的技術, 經過持續性發展, 很可能對未來的經濟結構或產業發展產生顯著性影響。
與“新興技術” 概念相近的有“熱點技術”“研究前沿” “顛覆性技術” 等。①熱點技術一般認為是被學科共同體廣泛關注的具有重要影響力的研究內容[19] , 重點在于受到的“關注” 更多, “熱度” 更高, 其學科影響力已經得到積累并顯露。與新興技術相比, 熱點技術的范圍更廣, 但其對新穎性、創新性的要求沒有新興技術高。隨著新興技術的發展, 有可能成為下一個熱點技術。但也有學者認為新興技術與熱點技術是同一個概念的不同稱謂[20-21] ; ②研究前沿最早由Price D J[22] 于1965 年提出, 他認為研究前沿由領域的30~50 篇最新發表的高被引文獻及其相關研究主題來反映, 具備成長性、影響力及新穎性的特征, 這3 個特征與新興技術類似。與新興技術相比, 研究前沿的市場潛力已有所顯現, 而新興技術能否成功還很難定論, 因此, 在不確定與模糊性上新興技術更高一些[23] 。但Toivanen H[24] 、Chen C M[25] 、盧超[26] 等學者則認為“研究前沿” 與“新興技術” 是不同時代的不同表述, 但所反映的內涵基本一致; ③顛覆性技術最早由Christensen C M[27] 于1997 年提出, 認為其能夠對現有產業或市場格局帶來破壞性、顛覆性的影響, 并具有取代現有主流技術、形成新價值體系的能力。與新興技術相比, 顛覆性技術的不確定性與破壞性更強, 更加強調創新的突破性, 其顛覆性需被投入市場應用時才得以體現[28] 。
本文認為新興技術與熱點技術、研究前沿、顛覆性技術在理論上確實存在區別, 但在實際的技術識別過程中可以發現, 各類技術的識別方法區別度不大, 尤其是采用計量學方法進行技術識別時, 因此, 更為客觀的技術識別方法應在通用的技術主題識別的基礎上, 結合各類技術的屬性特征進行篩選與甄別。
2新興技術屬性特征與測量指標
明晰新興技術屬性特征的意義在于使新興技術識別有了可依據、可測量的標準, 而不是像前序相關研究那樣對專家智慧的依賴性很強, 或缺乏可驗證性。因此, 對于每種屬性特征, 有必要將學者常采用的經典的測量指標進行梳理。Rotolo D 等[2] 通過對有關新興技術的經典文獻進行系統地回顧, 確定了新興技術的5 個屬性特征, 包括激進的新穎性、相對快速增長、連續性/ 一致性、顯著性影響、不確定與模糊性, 受到學界的廣泛認可。本文采用Rotolo D 歸納的新興技術屬性特征, 并提煉了各特征典型的測量指標。
2.1激進的新穎性
在創新性研究中, 新穎性是將現有知識以一種全新的、前所未有的方式結合起來的結果, 可以是一種漸進式的技術進步, 也可以是一種躍進性的技術革新[29] 。作為新興技術屬性特征的核心[2] , SmallH 等[15] 認為, 新興技術的新穎性具備一種激進的不連續的創新性; Bai G Z 等[30] 提出, 如果一個新主題在連續兩個時間窗口均被識別出, 則該主題可能代表一個新興技術的萌芽, 可作為一個候選新興主題。
評估新穎性最常用的方法有: ①比較候選新興技術主題與前序主題時間上的新舊度, 最常用的指標有“被引文獻的平均發表時間”“簇類論文的平均發表時間”[31-33] 。如Jaric' I等[34] 通過被引文獻的平均年齡和近兩年參考文獻占比來反映主題新穎性。Huang L 等[35] 以主題詞出現的最早年份來反映新穎性; ②比較候選新興技術主題與前序主題內容上的相似性, 如Liu Y 等[36] 將專利文本向量化,通過計算向量距離來評估新穎性; Liu X 等[37] 認為, 新興技術主題在總數據集中出現的比例不能高于15%, 以保證其內容上的新穎性。此外, 還有針對文獻類型的特點提出的反映新穎性的指標, 如Zhou Y 等[38] 通過兩個指標來反映專利的新穎性,一是技術原創性, 即覆蓋的專利分類號數量越多,新穎性越高; 二是知識原創性, 即后向被引次數越高, 新穎度越低。
2.2相對快速增長
Cozzens S 等[12] 、Small H 等[15] 、Wang Q[16] 均提出新興技術具有“在短時間內快速增長” 或至少是“增長” 的屬性特征, 增長性可以在多種維度上觀測到, 如領域參與者數量、基金資助金額、學術產出數量等。Boyack K W 等[39] 總結了增長性的兩種表現形式: 一種是萌芽期漲勢不明顯, 但后續會爆發式增長; 另一種是在萌芽期迅速發展為領域焦點, 隨后穩步增長。因此, 新興技術是相比于同領域其他技術而言, 發展得更快的技術, 采用“相對快速增長” 更為準確。Xu H 等[40] 通過論文、期刊、基金和作者數量的平均增長率來反映增長性。Huang L 等[35] 為避免數據庫文獻收錄對結果測度的影響, 使用滑動詞頻平均增長率來反映該屬性特征。Zhou Y 等[38] 通過被引專利年齡的中位數來反映技術增長速度。Liu X 等[37] 認為, 新興技術主題的增長速度至少為所有主題增長速度的1 5倍。Poter A L 等[41] 認為, 技術術語出現在活躍期的數量是出現在基期的2 倍以上, 即滿足了增長性。宋欣娜等[42] 結合增長因子與主題擴散性模型來衡量技術的增長性。此外, 還有研究通過基尼系數[43] 、前景因子[44] 、互信息[45] 來反映技術主題的增長性。
2.3連續性/ 一致性
與剛萌芽的技術主題不同, 新興技術已經表現出了持續一段時間的一致性或連續性, 其中, 一致性強調技術主題內部結構特征的邏輯互聯; 連續性強調新興技術脫離始源技術, 能夠以獨立主題存續一段時間, Day G S 等[8] 將之稱為“前序離散研究的匯集”。這個屬性特征為新興技術獲得更高的經濟和社會影響力奠定了基礎, 使之脫離了純粹的概念階段[14] 。Xu H 等[40] 使用Jaccard 系數來衡量相鄰時間窗內主題的關聯性, 以是否具備連續的關聯性來體現技術主題的連續性。Huang L 等[35] 認為,隨著技術主題成熟性的提高, 其在網絡社區中與其他節點間的聯系會變得更緊密, 因此, 以網絡密度比來衡量技術主題的一致性。Liu X 等[37] 通過設定的兩個標準來衡量技術主題的連續性, 一是主題詞至少出現在3 個時間窗口內; 二是主題詞在單個時間窗內至少出現于7 份文檔中。
2.4顯著性影響
由于新興技術往往起源于為解決復雜問題而創建的復雜創新系統[46] , 因此, 新興技術有機會通過社會經濟體系的多層次應用與傳播, 從而產生廣泛的影響, 如改變競爭基礎[10] , 創造一個新產業或改變現有產業[47] , 產生更大的經濟影響力等。Xu H 等[48] 使用被引頻次反映主題的科學影響性。Huang L 等[35] 以PageRank 來計算網絡中節點的影響性, 主題影響度等于屬于該主題的節點的平均PageRank 值。Jang W 等[49] 使用特征向量中心性來計算網絡節點的影響力。Xu S 等[50] 用DIM 模型中的線性回歸法計算主題的科學影響力。唐恒等[51]通過賦權后的用戶支持率與專利轉化率的和, 來表達技術主題的發展前景。黃璐等[52] 考慮到單純地依靠引用量測度技術主題的影響力會存在時間偏差, 因此, 將Time-rescaled 處理方法引入到Pag?eRank 中, 使節點得分能夠與同一時間段出現的節點進行Z-score 標準化處理。
2.5不確定性與模糊性
新興技術是一種具有自組織和自適應性的意外現象, 其不確定性是由產生時機的不可預測性和規模大小決定的[53] , 且由于技術涌現具有非線性和多因素性, 這使得新興技術的發展總是伴隨著不確定性與模糊性[54] 。由于這些技術仍然在開發中,其最終的影響還需要時間來檢驗, 況且技術的發展并不總伴隨著成功, 也存在失敗的風險, 尤其是在技術發展早期, 信息不足使得大部分預測分析方法均失效。因此, 不確定性與模糊性是一個很難評估的屬性特征。目前, 對于該屬性特征的研究還很少, Wei L 等[55] 提出可通過跨學科的弱聯系或弱信號的捕捉, 來一定程度地反映新興技術發展的不確定性與模糊性; 許海云等[56] 基于知識網絡強弱關系變遷測度新興主題的未來不確定性。
3新興技術識別方法
通過文獻總結與歸納, 將新興技術識別方法分為定性分析法和定量分析法, 常見的定性分析法包括德爾菲法、情景分析法、頭腦風暴法、技術路線圖等; 定量分析法主要分為三大類: 科學計量分析法、文本挖掘分析法和機器學習方法, 本文將重點介紹定量分析方法。
3.1科學計量分析法
3.1.1引文網絡
作為文獻計量學領域最常用的分析方法之一,也是新興技術識別最經典的識別方法之一, 引文網絡分析法包括直接引文分析、共被引分析和耦合分析, 以及較少出現的作者引用網絡等。該類方法首先是構建文獻間的引用關系網絡, 再通過各種聚類方法, 實現對直接引用網絡、共被引網絡及耦合網絡的聚類與可視化分析, 從而對新興技術進行識別。
1) 共被引分析, 如González-Alcaide G 等[31]在選定了大規模集群領域作為知識基礎的278 篇核心文獻后, 對涉及的7 149篇參考文獻進行共被引聚類, 生成的共被引矩陣由165 899對不同的參考文獻組成, 共形成5 個聚類簇, 再結合科學活動、研究群體規模與穩定性、參考文獻年齡等指標, 對新興技術進行遴選與識別。Hou J 等[57] 采用共被引分析對信息科學領域2009—2016 年的新興研究主題進行揭示, 研究發現, 信息科學領域知識基礎發生了很大變化。
2) 耦合分析, 如Song K 等[58] 采用耦合分析法篩選出在聚類群外的離群專利, 結合回顧性技術特征分析和前瞻性市場需求分析, 對候選新興技術的技術特征和市場特征進行評價, 再根據這兩種特征值將候選技術映射到二維空間, 將第一象限的候選技術定義為新興技術, 并將該方法應用于汽車工業, 驗證了方法的可行性和可用性。Li M 等[59] 提出了一種衡量論文與專利間耦合關系的計算模型,結合耦合強度和耦合速度, 來對人工智能領域的新興技術和技術機會進行識別。Jarneving B[60] 結合耦合分析和完全連接聚類分析識別了嚴重呼吸道癥候群領域的新興技術。
3) 直接引文分析, 如Kajikawa Y 等[61] 根據文獻間是否存在直接引用關系, 對能源研究領域的文獻數據進行相關性過濾, 基于剩余文獻構建直接引文網絡, 再進行拓撲聚類, 發現了每一個引文聚類簇都有其特色的研究主題, 不同引文聚類簇的增長趨勢也不同, 研究表明, 通過直接引文網絡分析,可以從一系列文獻中有效地追蹤新興的研究領域,但研究也存在著因命名(根據集群中被引次數最多的20篇論文的標題和摘要來命名聚類簇)造成的對引用次數較少的文獻的忽略問題。
4) 作者引用網絡, 該方法用于新興技術探測的基礎共識是新興前沿的技術研究是由活躍作者所開展的, 但這種網絡聚類結果更適合于對領域的知識結構和研究團體進行揭示, 并不能直接反映領域的研究主題。如Zhao D 等[62] 結合作者共被引網絡與作者耦合網絡, 對信息科學領域的知識結構和新興研究主題進行揭示, 認為出現在作者耦合網絡,但未在作者共被引網絡中出現的聚類簇的作者所研究的主題即新興研究主題。Ma R[63] 采用作者耦合分析法對中國圖書情報領域的知識結構進行揭示,并提出了簡單法、最小法、組合法3 種耦合強度計算方法, 研究發現最小法是計算作者耦合強度最合適的方法, 與作者共被引分析法相比, 作者耦合分析法具有更全面、具體地發現某一學科知識結構的優勢, 也能反映該學科的研究前沿與新興研究。
引文網絡分析存在的共同問題包括: ①引用行為偏好無法避免, 引用內容不同側重點不同, 但在引文網絡分析時無法區分; ②進行引文網絡聚類的樣本數據選擇問題, 現有研究過多地關注于高被引文獻, 使得低被引文獻的研究內容被忽略; ③引文網絡構建對高質量的引文數據庫依賴性較大; ④構建的引文網絡多為無向網絡, 對有向網絡的應用較少, 加權引文網絡也要比非加權引文網絡少; ⑤由于識別結果是引文聚類簇, 不能直接得出技術主題, 還需要借助內容分析法、文本挖掘技術或專家智慧等方式來對聚類簇進行命名, 且命名結果存在一定的信息偏差或信息遺漏。
3.1.2共現網絡
共現網絡以兩兩詞匯/ 類別在同一文獻中共同出現的次數為統計基礎, 建立特定領域內詞/ 類別的共現矩陣, 然后進行聚類以呈現這些詞/ 類別間的親疏關系, 進而反映出領域內研究的熱點與新興趨勢, 常見的有詞共現網絡和類別共現網絡。
1) 詞共現網絡, 如Katsurai M 等[64] 提出了一種優化的共詞網絡算法TrendNets, 其將共詞網絡矩陣分解為平滑部分和稀疏部分, 其中, 平滑部分表示平穩的研究主題, 稀疏部分表示新興的研究主題, 以動態共詞網絡來反映新興的研究趨勢, 研究發現, 與傳統共詞分析相比, TrendNets 在發現特征不明顯的新興話題方面具有優勢。Li M[65] 提出了一種基于關鍵詞共現和突發詞檢測的改進的共詞分析方法, 以共現次數與中間中心性來表示節點的權重, 以模塊度與平均輪廓系數來反映聚類結果,對技術預見領域的相關研究進行分析, 發現詞共現可以呈現新興研究的基本面, 突發詞頻可以作為一種重要的補充。Besselaar P 等[66] 以主題詞與參考文獻的共現關系為基礎構建共現矩陣并聚類, 將一組存在相似性的詞—參考文獻的聚類簇作為一個研究主題, 以兩篇論文共有的詞—參考文獻組合的數量來計算相似度, 該方法的優點是結合了論文的兩種屬性, 來確定所研究領域的細粒度主題結構。
近年來, 共詞分析法得到了持續改進, “共現詞” 從索引詞、關鍵詞發展到自由詞, 共現范圍從一篇論文之內細化到一個段落之內, 乃至同一個句子之內, 切詞方法也得到了豐富, 如KEA[67] 、TF-IDF[68] 、TF-ISF[69] 、TextRank[70] 、共現統計信息法[71] 、中心度量法[72] 、循環神經網絡[73] 等。該方法的缺陷在于對前期數據清洗要求較高, 如對同義詞、停用詞、低價值詞匯的篩選與處理等。此外, 受限于關鍵詞間的關聯關系, 如當新興研究主題與其他傳統領域的關聯度不高時, 很難通過共詞分析識別出來。還有學者認為, 共詞分析會破壞知識結構的穩定性, 因為這種分析只是基于單個詞[74] 。
2) 類別共現網絡, 如李瑞茜等[75] 將授權發明專利的IPC 主、副分類號對照到WIPO 發布的35個技術領域上, 構建35×35 的非對稱技術關聯共類矩陣, 該矩陣的行代表主分類號的技術領域, 列表示副分類號的技術領域, 行列交叉處為對應的主分類號與副分類號共同出現在一個專利的次數, 結合中心度、結構洞和中間人的分析, 識別了技術關聯網絡中的核心技術、中介技術和新興技術。
3.1.3異質網絡
引文網絡、共詞網絡一般都屬于同質網絡, 即網絡中的節點均屬于同一實體類型, 目前常見的混合不同網絡用以技術識別的研究, 也多基于同質網絡, 如混合共被引網絡與耦合網絡[76-77] 、混合直接引用網絡與共被引網絡。異質網絡指網絡中的節點屬于不同的節點類型, 如Sebastian Y 等[78] 提出了一種新的異構書目信息網絡模型(HBIN-LBD),旨在基于現有的各種書目元數據(包括作者、術語、出版商、被引文獻和論文)之間的相互聯系(包括詞共現關系、作者合著關系、耦合關系、直接引用關系), 構建基于圖的異構元路徑, 包括4 種二級元路徑、6 種三級元路徑、6 種四級元路徑, 并對不同類型實體間邊權重的計算方式進行設計, 從而發現研究論文之間的潛在聯系, 實現對自身聯系較少的交叉領域新興技術的識別。
3.?1.4混合分析
混合分析常見的有以下幾種類型的研究:
1) 對不同的網絡分析方法進行對比研究, 如Boyack K W 等[79] 、Shibata N 等[80] 、張嘉彬[81] 、Jarneving B[82] 、Fujita K 等[83] 通過對直接引文網絡、共被引網絡、耦合網絡識別結果的對比研究發現: 在時間維度上, 直接引文網絡與耦合網絡的探測速度均要優于共被引網絡; 在精確度上, 耦合網絡要稍優于共被引網絡, 直接引文網絡是最不準確的方法; 不同的引文網絡識別結果在數量與內容上均存在差異, 但內容方面也有一定的重疊; 加權引文網絡在新興主題探測方面比無加權引文網絡顯示出更多的優越性, 且以引用頻次作為權重比以主題詞相似性、文獻相似性等作為權重的效果更好。
2) 對不同的網絡類型進行融合/ 組合, 包括:①對不同的同質網絡分析結果進行組合, 如SmallH 等[15] 將兩個基于大規模科學文獻的直接引用和共被引模型聚類結果進行結合, 通過差異函數來篩選技術主題, 該函數能有效識別新的、快速增長的主題集群, 最終識別出2007—2010 年每年的Top25新興研究主題, 并按照驅動新興技術主題出現的原因, 對其進行分類, 最后通過搜索與該主題相關的文獻或其主要研究人員所獲獎項來進行結果驗證;②對不同的同質網絡進行融合, 再基于融合后的實體關系形成新的融合網絡。如蘇娜等[84] 采用基于Z-score 的多關系融合方法, 對科學計量學領域文獻集間的共現關系、文獻耦合關系、共被引關系進行融合, 得到了比Janssens F 等[85] 所提的基于Fisher 的多關系融合方法更好的主題聚類結果。康宇航[86] 從異質網絡視角出發, 構建“耦合—共被引” 混合網絡分析模型, 并從網絡整體、網絡組群、網絡個體3 個層面進行技術機會分析。
3) 混合引文網絡與文本分析, 如Gl?nzel W等[87] 提出了一種基于耦合向量和文本相似性的線性組合算法來識別核心文檔, 通過核心文檔和不同時期聚類文檔集之間的交叉引用, 結合混合聚類算法, 來檢測新出現、增長異常, 或內容發生變化的新興技術主題, 并以生命科學、應用科學和社會科學領域為例進行實證分析。
3.2文本挖掘分析法
3.2.1詞頻統計分析法
新興技術出現時, 相關的主題詞出現的頻率也會越來越高, 甚至會突發性出現高集中性、高密度特性的新主題詞, 詞頻統計分析法就是利用這一特性, 通過分析詞頻變化來識別新興技術。KleinbergJ[88] 提出, 可通過詞頻密度變化來識別出詞頻突發性增長的一組詞, 進而輔助新興主題識別。ChenC[89] 將Kleinberg 詞頻突破算法應用于其開發的CiteSpace 系列軟件, 使之成為基于詞頻統計識別領域熱點及新興主題最常用的工具之一。劉自強等[90] 基于N-Gram 模型抽取蘊含時間標簽的多元詞匯Bi-Gram 與Tri-Gram, 以提高主題詞的語義表達能力, 然后構建多元詞匯的詞頻時間序列, 利用分段線性回歸模型(PWLR)結合新興特征值, 進行新興詞匯識別。基于高頻詞或爆發詞來識別新興技術的優點是操作簡單, 可直觀地揭示研究領域的內容特征, 但缺陷在于識別結果碎片化, 缺乏語義關聯, 能夠揭示的內容有限。
3.2.2主題模型分析法
主題模型能夠實現以非監督機器學習的方式,完成對文獻中隱含的語義結構的揭示。在新興技術識別中最常用的主題模型即LDA 及其各種衍化版模型, 如DTM、cDTM、DIM、PLDA 等。LDA 最早由Blei D M 等[91] 于2003 年提出, 該模型可基于統計概率層面表達詞間的語義層次關系; 后于2006 年[92] , 在代表主題的多項分布的自然參數上使用狀態空間模型, 推出DTM(Dynamic Topic Mod?el)模型; 后又陸續推出連續時間動態模型cDTM(Continuous Time Dynamic Topic)[93] 、動態影響模型DIM (Document Influence Model)[94] 。2009 年,Wang Y 等[95] 對cDTM 模型進行了改進, 提出PL?DA 模型。此外, 其他的主題模型還有MDTM(Mul?tiple Timescales DTM )[96] 、ToT ( Topic OverTime)[97] 、TDM(Trend Detection Model)[98] 等。
具體來看, Ranaei S 等[99] 以LED 和閃存技術為例, 對比分析了詞頻統計分析法(TF-IDF)、涌現評分法(Emergence Score, EScore) 和LDA 在識別新興技術方面的效果, 研究顯示, 詞頻統計分析法提供了新興技術更細節的涌現模式, 但結果中通用術語占了很大比例, 需要專家輔助解讀; EScore由于綜合考慮了術語頻率、規模和起源地, 能夠提供更全面的新興技術視角; LDA 能夠揭示新興技術主題間的聯系, 對于主題中每個詞的出現, 可以根據其相鄰的關鍵詞進行解釋。Yan E[100] 采用LDA 模型結合主題流行性和主題影響力指標, 以及對LIS 領域的新興技術主題進行識別。徐路路等[101] 采用PLDA 模型結合項目、論文、專利3 種科技文獻數據源對石墨烯領域新興主題進行探測,并通過文獻調研結合專家智慧驗證了該方法的可行性和有效性。
主題模型能高效地分析大規模非結構化文檔集, 且在語義抽取與語義表達方面具有優勢, 但由于其屬于無監督學習算法, 結果的可控性不高, 且前期對于數據的預處理要求較高, 包括通用詞刪除、主題詞規范、術語詞典構建等, 否則會影響主題識別效果。
3.2.3結構語義分析法
最常見的基于結構語義進行新興技術識別的方法, 即基于SAO(Subject-Action-Object)結構的語義分析法。該方法在提取文獻中“主語—謂語—賓語” 結構的基礎上, 通過分析Subject(S)、Ac?tion(A)、Object(O)間的語義關系, 來判斷所提取的SAO 結構是表達了何種含義, 若AO 代表關鍵問題, S 代表解決方案, 則SAO 形成了“問題———解決方案” 模式; 若SO 代表系統組件, A 代表功能,則SAO 形成了“功能———系統組件” 模式[102] 。MaT 等[103] 提出了一種結合LDA 主題模型、SAO 結構語義模型、機器學習和專家判斷的混合方法, 來識別染料敏化太陽能電池領域的新興技術和潛在機會, 研究發現, 與摘要相比, 標題對專利技術主題識別準確度的影響更大; 專利IPC 分類越獨特, 即與其他專利共通的IPC 分類越少, 技術主題識別的準確度越大。周海煒等[104] 構建了基于專利SAO 結構和多指標評價的新興技術識別模型, 該算法首先將SAO 與TF-IDF 算法相結合來計算專利文本相似性, 采用譜聚類與Scikit-learn 算法劃分手機芯片行業子技術領域, 再綜合多維指標體系與專利量年度變化來判別新興技術。Choi S 等[105] 采用NLP 與語義信息鏈接方法從專利全文中提取SAO 結構, 將Subject、Object 轉換為名詞、動詞的形式, 基于名詞—謂語矩陣構建SAO 網絡, 最后結合度數、中心性等指標, 以及行動者網絡理論來識別新興技術。
SAO 可以在有效地表達詞間語義關系的基礎上, 清晰地反映技術的關鍵概念、屬性、結構、功能、制備工藝等, 揭示技術是如何被使用或使用技術的目的, 以及如何與其他技術相互作用。但由于SAO 結構的復雜性, 很難準確地從文本信息中定位并提煉相應的S、A、O 部分, 且由于技術的復雜性, 即使在專家的輔助下, 有時也很難解讀各部分間的語義關系。
3.3機器學習方法
為了提高新興技術識別準確度, 機器學習方法被眾多學者使用, 其核心是將新興技術識別問題轉化為分類問題。如Liang Z 等[106]首先采用深度神經網絡中的LSTM 和NNAR, 結合9 種計量指標來對技術主題的熱度分值進行預測, 該指標以時間序列的方式反映候選技術主題的影響力和增長性; 其次, 從高熱度候選技術主題中篩選出新穎性高的新興技術主題, 此外, Liang Z 等綜合對比了分別在全局策略和局部策略下LSTM、NNAR、LightGBM、線性回歸、多項式回歸、EScore、Naive Method 7種方法在指標值預測準確性和最優排序方面的表現, 發現兩種神經網絡模型在大多數指標上表現均優于其他5 種模型, LSTM 的表現還要優于NNAR。Huang L 等[35] 提出了一種基于動態共詞網絡的新興主題分析方法, 該方法首先構建多時間切片下的動態加權共詞網絡, 再引入鏈路預測方法來揭示共詞網絡的動態變化, 同時, 采用機器學習算法擬合3 種鏈路預測指標, 充分評估局部結構、路徑和隨機游走信息, 提高了鏈路預測方法的準確性, 最后結合新穎性、增長性、連續性和影響性4 種測量指標進行新興技術主題識別, 并經專家驗證確認了本文方法的可行性和可靠性。Xu S 等[50] 利用動態影響模型(DIM)識別技術主題, 并計算技術主題的增長性、連續性和影響力, 通過引文影響力模型(CIM)計算新穎性, 采用多任務最小二乘支持向量模型(MTLS-SVM)對未來兩年的指標值進行預測, 并以基因編輯領域為例, 識別到了3 個新興技術主題。孔德婧等[107] 使用BERT 預訓練模型將專利文本向量化, 基于語義相似度構建專利相似度網絡,識別離群專利, 然后基于DNN 模型構建離群專利指標與技術影響力之間的關系, 實現從海量離群專利中快速、準確地預測新興技術, 識別出網絡中的離群點作為備選新興技術。
采用機器學習算法可以自動化、高通量地處理領域全量數據, 挖掘文獻的語義信息, 從而提高技術識別的全面性和準確性。但基于監督的機器學習方法需要大量的人工標記訓練樣本, 且實驗結果的可解釋性差, 而無監督機器學習雖不需要人工標記訓練集, 但準確性和可控性稍差。此外, 機器學習方法的學習門檻較高, 不利于方法的普及。
3.4新趨勢與結果驗證
隨著對新興技術識別研究的深入, 學者們開始關注新興技術的內核, 即基于新興技術的屬性特征構建指標體系, 對基于上述各類識別方法所得的技術主題進行篩選與甄別, 從而識別出新興技術主題, 并按照指標表現進行新興技術類別劃分。這一新趨勢表明了新興技術識別在不斷減少結果的主觀偏見性, 增加客觀及可驗證性。如Porter A L 等[108]提出了基于Escore(Emergence Score)的新興技術主題探測方法, 該方法通過VantagePoint 提取文摘信息中的術語詞, 基于新穎性、連續性、增長性和群體性的屬性特征設置術語篩選標準, 再結合術語的Escore 值識別新興技術主題詞, 此外, 還以Escore指標為基礎, 設計出多個二級指標, 分別用于探測前沿機構、國家和作者。Jang W 等[49] 以是否會在未來集中增長, 并會影響社會和技術發展作為新興技術的篩選標準; Zhou Y 等[38] 通過新穎性、技術影響、社會影響特征來篩選新興技術; Liu X 等[37]構建一個三維評估框架系統來反映新興技術的持續性、區域性和增長性; Zhang Y Y 等[73] 認為新興科學技術以巨大的不確定性和極高的潛力為最主要的特征; Zhang B 等[110] 認為新興技術的典型特征包括爆發性、持續性、突破性和競爭優勢。
該類方法的研究深度和識別精細度雖有提升,但仍存在著如下問題: ①部分研究的屬性特征與測量指標之間缺乏聯系, 指標選取的科學性和合理性存在質疑; ②指標權重確定、表征力判斷與閾值選取, 以及模型構建等沒有統一的標準, 難以界定;③指標計算的普適性、可解釋性、可操作性難以協調與兼備。
對新興技術識別有兩種切入角度: 一種是對既定的新興技術進行描述性分析[111] ; 另一種是對選定的領域進行新興技術探測[15,112-113] , 目前多采用第二類研究的切入視角, 但出于嚴謹性考慮, 需要對識別結果進行驗證。目前, 常用的驗證方法有3種: 資料驗證法、專家評估法、指標驗證法。
1)資料驗證法, 指通過已發表的學術成果或各類在業界具備影響力的獎勵、項目等來對新興技術識別結果的客觀性、可靠性進行驗證, 這是目前應用最多的驗證方法。該方法的優勢在于便捷、操作成本低且可靠性高, 但缺陷在于通過已經出版的資料進行結果驗證, 在一定程度上降低了識別結果的時效性和價值性。如Small H 等[15] 通過諾貝爾獎和領域權威獎項進行結果驗證; Kajikawa Y 等[61] 通過與日本機構繪制的領域專家路線圖進行比對, 實現結果驗證; Wang Q[16] 通過與現有領域相關出版成果中提及的新興技術進行比對, 實現結果驗證。
2) 專家評估法, 指通過專家對領域多年的知識與經驗積累對識別結果進行評估, 優點是經過專家認可的識別結果權威性、可靠性都得到了保證,缺點是主觀性強、時效性差。如Mu?oz -?cija T等[114] 通過專家訪談法、Chen C M[25] 通過調查問卷法, 周源等[115] 結合郵件、會議、問卷多種形式進行結果驗證, 此外, Jang W 等[49] 、Cozzens S 等[116] 、Choi Y 等[117] 、Arora S K 等[118] 、Ma T 等[119] 、HuangL 等[35] 、Li X 等[120] 均借助了專家智慧進行結果驗證。
3) 指標驗證法, 指通過各類指標對實證分析所構建模型的有效性進行驗證。該方法屬于一種間接的驗證方法, 即通過驗證模型的可靠性來對識別結果的可靠性進行一定程度的保證, 不足之處在于只能證明識別的結果符合預設的各種標準, 但符合標準的是否一定就是新興技術并不能得到證明。如Liang Z 等[106] 通過MAE、RMSE、NDCG@ k 3 種指標, 對LSTM、NNAR、LightGBM、LR、Na?ve 5 種模型進行效果評估。
4研究問題與展望
4.1概念不明確, 標準不統一
由于對新興技術尚未形成統一的定義, 學者對屬性特征的理解也各有不同, 因此, 新興技術識別的方法流程、指標設計、驗證標準均存在差異, 尤其是在特征指標設立方面存在許多問題, 如屬性特征與測量指標之間缺乏聯系, 指標選取的科學性和合理性存在質疑; 指標權重確定、表征力判斷與閾值選取等沒有統一的標準; 指標計算的普適性、可解釋性、可操作性難以協調與兼備等。此外, 現有研究缺乏對新興技術內涵、外延、本質特征及發展機制的探索, 多聚焦于引進新的技術與方法, 以期不斷改進技術識別效果, 但由于缺乏統一的理論根基支撐, 方法多樣性越來越強, 不同的方法得到的識別結果不同, 使得方法的選擇與評價越來越困難。
4.2數據源類型選擇不均衡, 偏向性明顯
目前, 有關新興技術識別研究的數據源類型選擇偏向性明顯, 主要存在以下3 種情況:
1) 多單一數據, 少多源數據。現有研究大多聚焦于論文或專利的單一數據, 較少采用多源數據進行新興技術識別。部分研究引入了學位論文[121] 、會議論文[122] 、專著、Web 網絡數據[123] 、社交媒體數據[120] 、基金項目[124] 等不同的數據源類型,但綜合多種數據源類型進行新興技術識別的研究仍然較少。如張維沖等[125] 、唐恒等[51] 嘗試綜合多源數據進行新興技術識別, 二者的研究共同之處在于, 基于多種文獻類型的文摘數據, 分別進行主題抽取與新興技術主題識別, 然后再對不同文獻類型的識別結果作主題關聯分析, 若相似度高則合并為同一主題。但這種做法存在一個問題, 技術主題在不同文獻類型中的表達方式會有差異, 若僅基于主題相似度計算進行同類主題合并, 會存在很大的誤差, 且相似度算法的選擇、閾值的設置均沒有統一標準, 存在很強的主觀差異性。
2) 多文摘數據, 少全文數據。現有研究絕大部分均是基于文獻的文摘數據進行主題抽取, 很少有基于全文數據進行分析的。尤其是采用多種數據源進行分析時, 基于文本過載與處理效率的考慮,也是采用文摘數據進行分析。隨著機器學習、文本挖掘技術應用程度的不斷加深, 基于全文數據進行新興技術識別將成為一種研究方向。
3) 多精選數據, 少全量數據。很多研究基于領域內特定期刊、高被引文獻等精選數據集進行分析, 這樣做主要是為了去除噪聲影響, 提高識別精度與效率, 簡化數據處理過程中的復雜度; 但根據“長尾理論”[126] , 這樣做明顯會遺漏許多重要信息。
4.3“漸進式” 回溯研究成主流, “躍進式” 預測研究仍待發展
現有關于新興技術識別的研究大多基于“漸進式發展” 的理論, 采用回溯性方式進行研究, 即基于歷史數據, 應用預定義的規則來識別已出現的技術主題, 并回顧其技術發展歷程, 這類研究的通用方法流程為: 目標領域數據集構建、技術主題抽取、多維指標體系構建、新興技術主題篩選、方法驗證。這類研究加強了對新興技術的理解, 并為后續的技術預測工作提供了有價值的參考, 但回溯性研究的成果是面向過去的未來, 因此, 無法滿足決策者和科學家對技術未來發展及技術預見方面的需求。基于“躍進式發展” 理論技術演化研究及前瞻預測性的技術識別研究較少, 這類研究嘗試將新興技術主題預測轉變為統計學問題, 將給定歷史特征作為輸入, 未來指標作為目標輸出, 通過訓練預測模型來預測新出現的技術主題[50,127,106] 。
針對新興技術識別與演化研究中出現的問題,未來應從以下幾個方面加強研究:
1) 加強對新興技術內涵、屬性特征、發生機制等的研究, 以求加強對新興技術概念、屬性特征的學術共識, 構建更加完善、可解釋性強的特征指標體系, 增加新興技術識別的客觀性與可靠性。
2) 充分發揮多種數據源的特性, 加強多種文獻類型在新興技術識別中的應用, 以提高識別結果的全面性與準確性。此外, 加強多源信息融合的理論與方法研究, 以及全文數據和全量數據的應用,拓寬新興技術識別乃至技術預測領域的切入視角。
3) 加強新興技術從回溯性描述到預測性探索研究的轉變, 以從未知的學科和領域中識別出未來極具價值和影響力的技術主題, 為未來的決策制定和戰略布局提供數據支撐。
