基于Dlib和變種Transformer的哈欠檢測方法
2023-03-25 02:07:46廖冬杰
汽車技術 2023年3期
廖冬杰
(1.華東交通大學,南昌 330013;2.江西省先進控制與優化重點實驗室,南昌 330013)
主題詞:哈欠檢測 Dlib 哈欠特征矩陣 變種Transformer YawDD
1 前言
疲勞駕駛是造成交通事故的主要原因之一[1],而打哈欠是駕駛員疲勞初期的主要表現形式之一[2]。因此,研究駕駛員疲勞初期的哈欠特征,從而進行準確檢測,對保障道路交通安全具有重要意義。
國內外研究人員針對哈欠檢測已進行了大量的研究。馬素剛等[3]充分關注人臉的各種特征,以駕駛員面部圖片作為輸入,通過卷積核進行特征提取,并利用Softmax 分類器判斷駕駛員是否打哈欠,但只關注了單幀圖像的分類,沒有充分利用多幀圖像在時間維度上的關聯性,可能把講話、唱歌、大笑等張嘴行為誤檢測為打哈欠。Mateusz Knapik 等[4]對熱成像視頻進行人臉區域檢測,提出眼角檢測算法,實現了人臉對齊,通過檢測嘴部區域的快速溫度變化判斷駕駛員的打哈欠行為,但未考慮大幅度張嘴呼吸以及咳嗽等特殊情況。史瑞鵬等人[5]提出了一種基于多任務卷積神經網絡(Multi-Task Convolutional Neural Network,MTCNN)的加速優化算法,對圖像中駕駛員是否存在張嘴行為進行分類,以嘴部持續張開時間作為評判駕駛員是否打哈欠的標準,但此類方法分類標準無法準確度量,無法確定嘴部持續張開時間閾值,只能根據經驗給出,無法達到最優效果。王超等[6]提出只關注嘴部圖像,利用卷積神經網絡(Convolutional Neural Network,CNN)和長短期記憶(Long Short-Term Memory,LSTM)網絡對視頻進行空間和時間的特征提取,從而實現哈欠檢測,但是這類方法哈欠檢測特征單一,未考慮眼部等特征與哈欠行為的關聯,缺乏全面性。
本文基于Dlib 和變種Transformer[7]模型,針對哈欠檢測特征單一的問題,同時關注左右眼部、嘴部的特征變化,構建包含直接哈欠特征和隱含哈欠特征的哈欠特征矩陣,有效避免駕駛員嘴部呼吸、咳嗽等嘴部特殊情況的誤檢;針對無法度量閾值的問題,采用深度學習的方法,利用變種Transformer 模型進行隱含哈欠特征提取,并實現哈欠分類,提高算法的準確性;針對幀與幀之間缺乏聯系的問題,引進多頭注意力機制和序列編碼,以降低檢測中大笑、說話等情況的誤檢可能性。
2 基于Dlib 和變種Transformer 的哈欠檢測方法原理
Dlib是一個包含眾多機器學習算法、圖像處理和數值計算等豐富功能的開源工具箱,廣泛應用于人臉識別、分類等領域。Transformer模型是一種自然語言處理模型,由編碼器(Encoder)和解碼器(Decoder)組成[7],可以完成特征提取,同時捕獲遠距離的依賴關系,實現分類和生成等功能。本文旨在實現駕駛員哈欠檢測,故提出基于Dlib和變種Transformer的哈欠檢測方法,其原理如圖1所示。
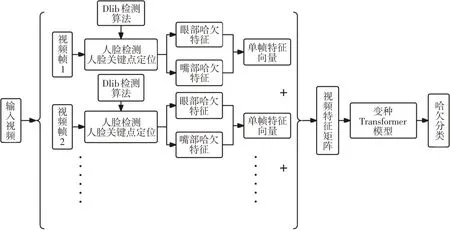
圖1 哈欠檢測原理
本文提出的哈欠檢測方法主要包含3個部分:
a.人臉檢測和關鍵點定位。通過基于集成回歸樹(Ensemble of Regression Trees,ERT)的Dlib 算法進行人臉檢測以及68點關鍵點定位。
b.哈欠特征矩陣構建。根據定位關鍵點坐標提取眼部、嘴部直接哈欠特征,得到每幀的哈欠特征向量,在時間維度進行堆積,構建包含直接哈欠特征和隱含哈欠特征的視頻哈欠特征矩陣。
c.哈欠檢測。在得到視頻哈欠特征矩陣的基礎上,利用變種Transformer 模型進行特征提取和視頻分類,完成對視頻中是否有打哈欠行為的檢測。
3 基于Dlib的哈欠特征矩陣構建
3.1 Dlib人臉關鍵點定位
Dlib 人臉關鍵點定位使用了Vahid Kazemi 等人提出的ERT級聯回歸算法[8],該算法構建了級聯的梯度提升決策樹(Gradient Boosting Decision Tree,GBDT),使得預測的人臉形狀即關鍵點不斷回歸到真實位置[9],其基本思想是:每一個GBDT 的每個葉子節點均儲存著殘差回歸量,當輸入經過某一葉子節點時,將當前輸入和葉子節點儲存的殘差回歸量相加,起到回歸作用,所有殘差回歸量相加后,即可獲得預測的人臉形狀。與傳統算法相比,ERT 算法具有較出色的準確率和檢測速度,同時還能夠處理數據缺失的問題[8]。ERT 算法核心表達式為:
式中,S為由p個關鍵點坐標組成的人臉真實形狀;∈R2(i=1,2,…,p)為面部圖像I的第i個關鍵點的坐標;為第t次的人臉估計形狀;為第t次計算得到的殘差回歸量。
考慮到Dlib 在人臉檢測和人臉關鍵點檢測上的出色能力,本文利用Dlib提供的人臉關鍵點模型[10]對車內駕駛員的68個人臉關鍵點進行檢測,結果如圖2所示,試驗證明,Dlib人臉關鍵點檢測算法在車內環境中有著優秀的關鍵點定位能力。因此,利用Dlib人臉關鍵點模型分析駕駛員疲勞時的眼部和嘴部哈欠特征是可行的。

圖2 車內環境人臉檢測關鍵點
3.2 哈欠特征構建
眼睛和嘴是駕駛員在打哈欠時表現最為突出的部分。本文利用Dlib人臉關鍵點模型得到人臉關鍵點,提取眼部的12個關鍵點坐標信息、嘴部的6個關鍵點坐標信息,如圖3、圖4所示,以眼部和嘴部張度作為直接哈欠特征,得到視頻幀哈欠特征向量,再按照時間維度堆積,構建包含嘴部持續張開時間、眼睛閉合時間比例(Percentage Eyelid Closure over the Pupil over Time,PERCLOS)等隱含哈欠特征的視頻哈欠特征矩陣,從而進行哈欠行為檢測。

圖3 眼部關鍵點
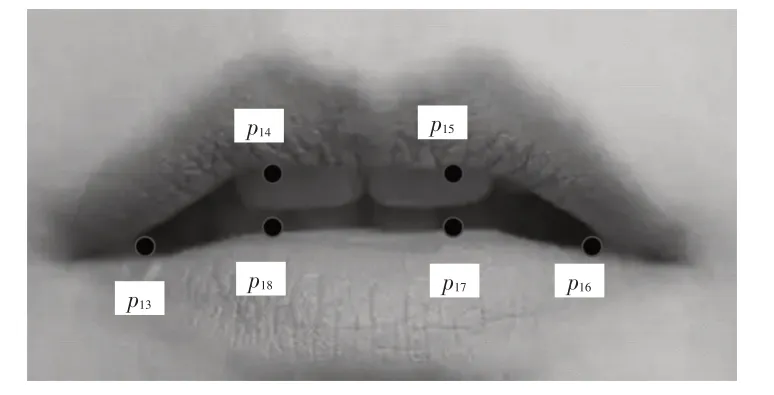
圖4 嘴部關鍵點
3.2.1 眼部哈欠特征
根據Soukupová等人[11]提出的觀點,駕駛員眼部開合程度的改變可以通過眼部縱橫比(Eye Aspect Ratio,EAR)的變化來表征。用pi表示圖3、圖4 中編號為i的點,左、右眼眼部縱橫比Real和Rear的計算公式為:
John Sofia Jennifer 提出,為了定位角度更為寬廣的朝向角,不必同時考慮2 只眼睛,僅使用單眼檢測即可達到出色效果[12],但本文考慮到駕駛員可能存在揉眼、扭頭等行為造成實際僅能檢測到1 只眼睛的情況,將左、右眼部縱橫比均作為哈欠特征。
3.2.2 嘴部哈欠特征
鑒于人在打哈欠時,嘴部的張合程度會發生明顯改變,因此類比于Soukupová提出的眼部縱橫比,本文引入一種評估嘴部開合程度的新指標——嘴部縱橫比(Mouth Aspect Ratio,MAR)。考慮到不同駕駛員嘴部的厚度差別,根據嘴唇的相關關鍵點進行特征提取:
式中,RMA為嘴部縱橫比。
至此,已經根據人臉關鍵點模型提取出眼部和嘴部的哈欠特征,將這些特征組合在一起,形成視頻幀哈欠特征向量。
3.2.3 特征矩陣構建
基于駕駛員駕駛狀態的視頻采集圖像,提取每個視頻幀Real、Rear、RMA特征值,獲得單幀的哈欠特征向量Vec:
式中,Reali、Reari、RMAi分別為第i個視頻幀的左、右眼眼部縱橫比和嘴部縱橫比;n為視頻所含視頻幀數量。
若將特征向量按照時間維度進行堆積,得到視頻特征矩陣HQ:
由于存在時間信息,HQ除了包含視頻每幀的左、右眼部縱橫比和嘴部縱橫比等直接哈欠特征以外,還包含嘴部持續張開時間、短時間內是否存在嘴部張度大幅度改變、單位時間眨眼次數、PERCLOS 等隱含哈欠特征,為后續分辨駕駛員是否存在哈欠行為奠定了基礎。
4 變種Transformer模型
4.1 Transformer模型
李小平等[13]通過LSTM 對得到的駕駛員疲勞特征矩陣進行分類,從而判斷駕駛員是否處于疲勞狀態。盧喜東等人[14]通過深度森林方法對方向梯度直方圖(Histogram of Oriented Gradient,HOG)特征矩陣進行惡意代碼分類。本文選擇變種Transformer模型提取HQ的隱含哈欠特征,從而完成對視頻中駕駛員是否打哈欠的分類,因為Transformer通過注意力機制可以捕獲遠距離依賴關系,并可實現循環神經網絡(Recurrent Neural Network,RNN)不能實現的并行訓練功能,結構如圖5所示。
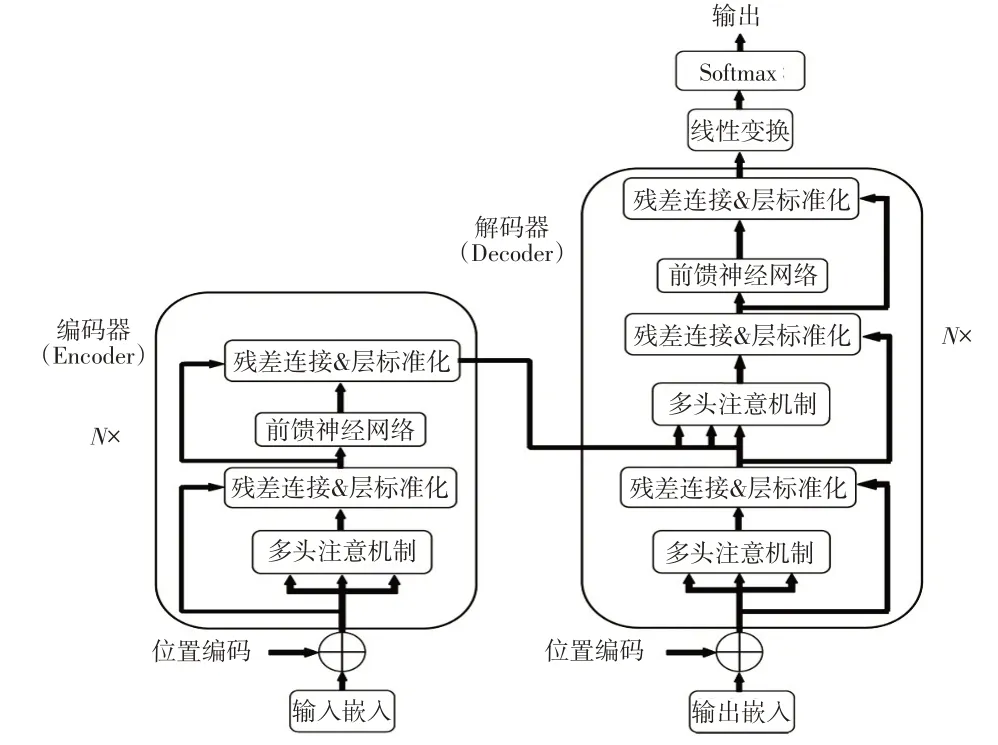
圖5 Transformer模型結構
圖5 中,編碼器部分的輸入為詞向量矩陣,考慮到單詞間的順序,為每個詞向量添加了位置編碼,計算公式分別為:
式中,P(s,2i)、P(s,2i+1)分別為句子中第s個單詞偶數維度/奇數維度的位置編碼;dmodel為位置編碼的維度。
將經過位置編碼的詞向量矩陣作為自注意力(Self-Attention)層的輸入,得到查詢矩陣、鍵矩陣和值矩陣,如圖6所示。
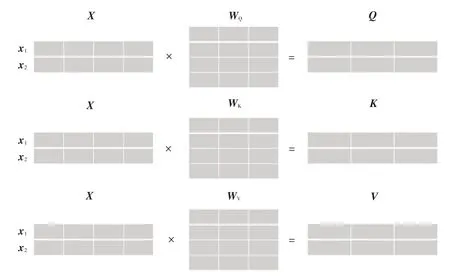
圖6 矩陣實現自注意力機制示意
圖6 中,X為位置編碼后的詞向量矩陣;x1、x2分別為經過位置編碼第1個和第2個單詞的詞向量;WQ、WK、WV為訓練好權重的線性變換矩陣;Q、K、V分別為X的查詢矩陣、鍵矩陣和值矩陣。
Q與KT相乘,得到詞向量與其他詞向量之間的關聯性,為了維護梯度的穩定性,除以,通過Softmax 函數得到該詞向量與其他詞向量關聯性的權重,再與詞向量包含的信息V相乘,可得:
式中,A(Q,K,V)為自注意力層輸出;dK為鍵矩陣K的維度。
為了學習到更多獨立信息,充分關注不同子空間,引進多頭注意力機制[7],設hi為第i個子空間的自注意力層輸出,將m個子空間的hi進行橫向拼接得到多頭拼接矩陣,通過線性變換矩陣Wo將多頭拼接矩陣變換成與X相同形狀:
考慮到網絡中可能出現的退化問題,將X與M進行連接,再進行層標準化,得到前饋神經網絡輸入Of:
式中,LayerNorm為層標準化函數。
將Of通過由線性層、線性整流函數(Rectified Linear Unit,ReLU)層和線性層構成的前饋神經網絡進行殘差連接和層標準化,結束模型的編碼器部分,公式為:
式中,Os為前饋神經網絡的輸出;Ot為編碼器部分的輸出;W1、b1分別為第1層線性層的參數矩陣和偏置;W2、b2分別為第2層線性層的參數矩陣和偏置。
Ot經過模型的解碼器部分,連接一個線性層,通過Softmax進行分類,完成整個Transformer模型的構建。
4.2 Transformer模型的改進
由于Transformer 的解碼器部分主要完成生成類功能,而疲勞駕駛哈欠檢測只需要實現哈欠特征的分類任務即可,故本文提出一種只使用編碼器部分的變種Transformer模型。其基本思想是:在繼承Transformer模型編碼器部分的基礎上,對輸入嵌入、位置編碼以及輸出層進行了改進,整體結構如圖7所示。
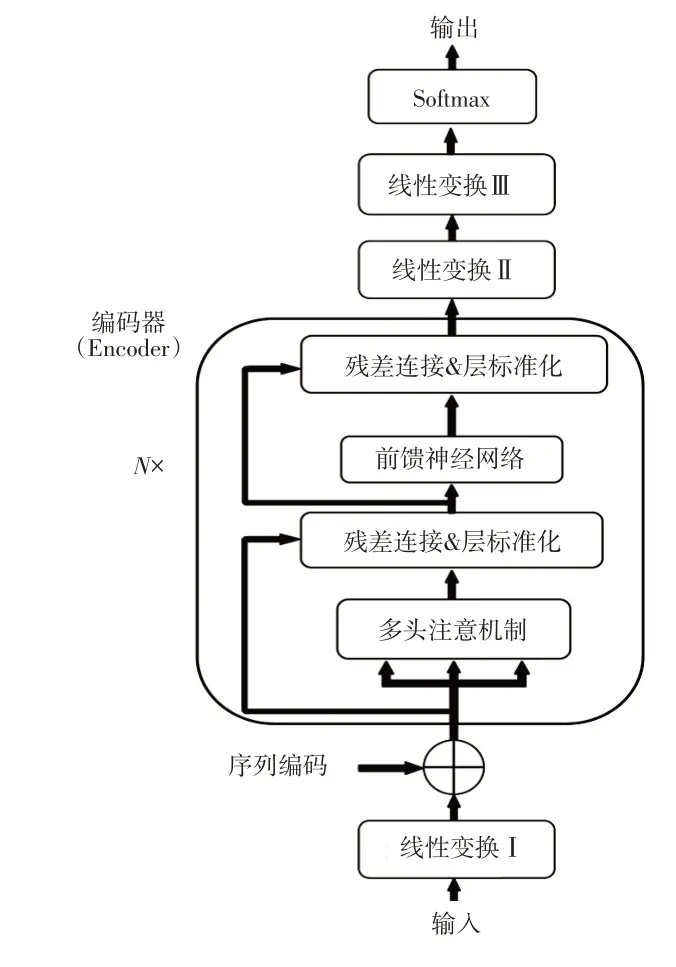
圖7 變種Transformer模型結構
圖7 中,模型的輸入不再是詞向量矩陣,而是經過Dlib 檢測算法構建的如式(7)所示的疲勞特征矩陣HQ,如圖8所示,設為序列編碼的維度,利用維的矩陣W*,得到線性變換Ⅰ的輸出:
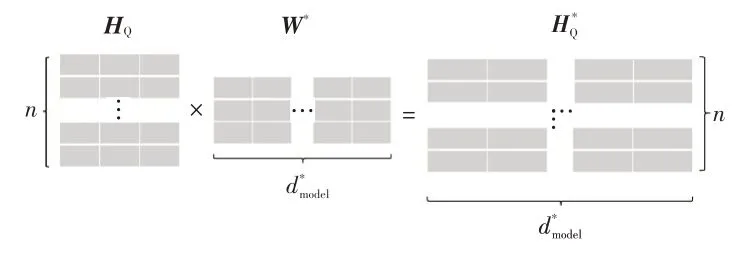
圖8 HQ變換示意
為了充分考慮各視頻幀之間的時間先后順序,將進行序列編碼:
式中,S(q,2j)、S(q,2j+1)為視頻中第q幀視頻幀偶數維度、奇數維度的序列編碼。
根據式(10),得到其他視頻幀包含的該視頻幀信息,通過式(11)和式(12),多個子空間充分挖掘學習視頻幀相關信息,之后根據式(13)~式(15),得到變種Transformer模型編碼器部分的輸出,通過圖9所示的變換,利用維的線性變換矩陣Wα得到線性變換Ⅱ的輸出O:
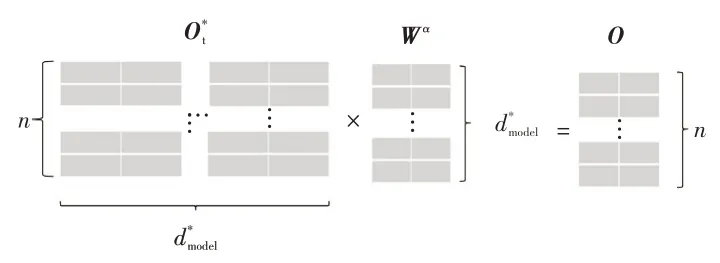
圖9 變換示意
如圖10所示,利用(n×1)維的矩陣Wβ對O的轉置矩陣OT進行線性變換,得到線性變換Ⅲ的輸出Oμ:
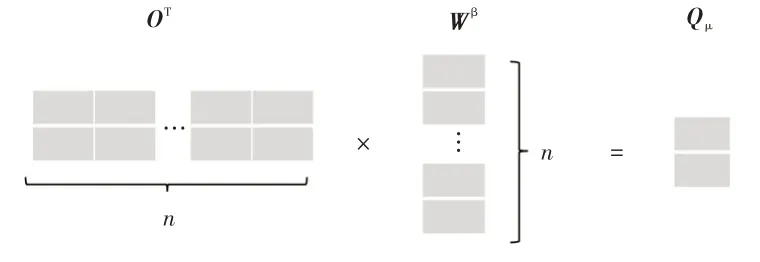
圖10 Oε 變換示意
最終分類結果為:
式中,Ans為視頻分類結果;為Oμ的轉置矩陣。
本文提出的變種Transformer 模型充分考慮視頻幀之間的關聯性,且引入序列編碼使得視頻幀時間維度得以關聯,通過多頭注意力機制和多層線性變換,可以實現對哈欠特征矩陣的分類。
5 試驗驗證與分析
為了驗證所提出方法的有效性,本文基于YawDD數據集[15]進行訓練和測試,與其他方法進行準確率的對比:
式中,Ac為準確率;TP、FP分別為被模型預測為哈欠的哈欠視頻、其他視頻數量;FN、TN分別為被模型預測為其他的哈欠視頻、其他視頻數量。
5.1 數據集構建
YawDD 數據集是一個公開的視頻數據集,視頻分辨率均為680×480,幀率為30 幀/s,包含2 個子數據集,分別由固定在后視鏡下方的攝像頭拍攝的視頻和由固定在組合儀表上方的攝像頭拍攝的視頻組成[15]。考慮到角度問題以及人臉關鍵點定位精準度,本文主要以第2 個子數據集為研究對象。該子數據集中的每個視頻包含不同的駕駛員,且駕駛員在同一個視頻里面包含講話、大笑、唱歌、打哈欠等行為,不能直接用來進行駕駛員哈欠檢測,因此本文采用人工重構數據集的方法對數據集進行處理,得到新的數據集DX-YawDD:即將每個視頻中出現的打哈欠視頻片段單獨裁剪出來,作為哈欠數據集,將每個視頻的其他視頻片段按照每段視頻3~10 s 進行隨機切割,得到新的視頻集,作為其他數據集。經過處理后,DX-YawDD 數據集中共包含71 個哈欠數據集視頻,344個其他數據集視頻。
5.2 試驗環境
本文試驗環境配置如下:服務器處理器為Intel Core i7-9750H CPU @ 2.60 GHz,安裝內存為8 GB,在Windows10環境下,在Pytorch深度學習框架下搭建了基于Dlib 和變種Transformer 哈欠檢測模型,使用數據集DX-YawDD 進行模型訓練和性能測試。其中,模型測試集共有125個視頻,包括隨機選取的22個打哈欠視頻和103個其他視頻,剩下的49個哈欠視頻和241個其他視頻組成模型訓練集。
5.3 試驗結果
基于訓練數據集,選擇變種Transformer模型的損失函數為交叉熵損失函數,采用隨機梯度下降優化器,學習率為0.001,動量為0.99,得到圖11所示的損失函數曲線。
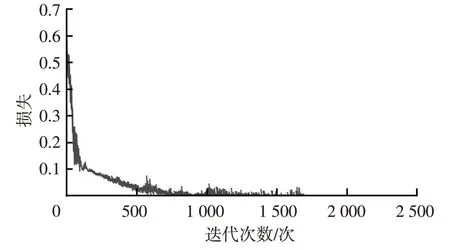
圖11 訓練損失函數曲線
由圖11可知,當訓練1 700次時,損失函數收斂,此時模型訓練的準確率為100%。模型在測試數據集上的哈欠檢測結果如表1所示,準確率達到96.8%,召回率為95.5%,表明本方法哈欠漏檢率較低。
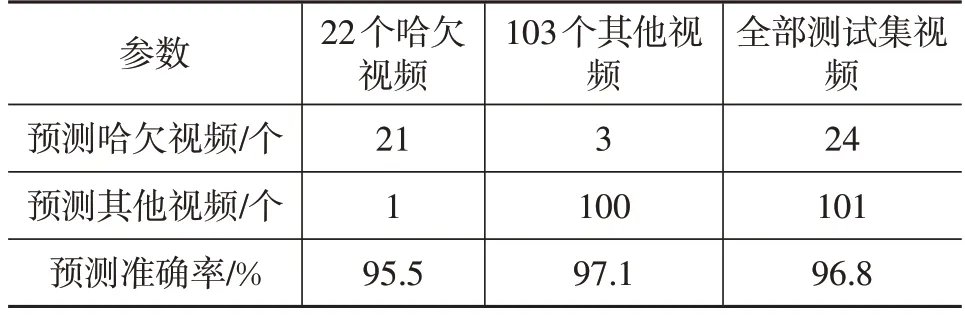
表1 測試集哈欠檢測結果
將本文方法與其他哈欠檢測算法基于DX-YawDD數據集進行對比驗證,不同算法的哈欠檢測準確率如表2所示。
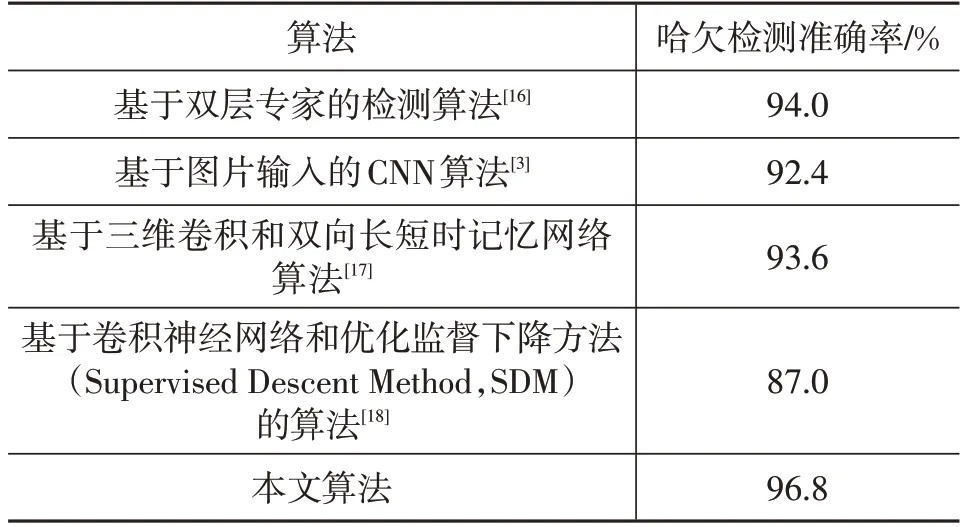
表2 不同算法哈欠檢測準確率
由表2可知,本文算法的檢測準確率為96.8%,高于其他檢測算法。這是因為本文算法綜合考慮了眼部、嘴部的哈欠特征,構建了包含有直接、隱含哈欠特征的視頻特征矩陣,利用變種Transformer模型進行特征提取和分類,關注了各視頻幀之間的聯系,捕捉到遠距離視頻幀之間的依賴特性,提高算法的準確性。
6 結束語
針對現有駕駛員哈欠檢測時,哈欠特征單一、分類閾值無法度量、視頻圖像中幀與幀之間缺乏聯系等問題,本文提出了基于Dlib 和變種Transformer 算法,通過公開數據集YawDD 進行測試,本文算法的哈欠檢測準確率高達96.8%,可以應用于駕駛員疲勞駕駛初期哈欠檢測任務,對避免駕駛員疲勞駕駛,保障人員和道路安全具有積極作用。
同時,利用本文算法進行哈欠檢測時,雖然多方面考慮了人臉特征點對于哈欠檢測的作用,但還存在面部特征挖掘不充分等缺陷,下一步可以通過3D 卷積等方法進行挖掘,避免顯式的哈欠特征提取,進一步簡化算法,提高準確率與魯棒性。
猜你喜歡
汽車實用技術(2022年14期)2022-07-30 06:13:42
汽車實用技術(2022年4期)2022-03-07 06:07:20
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
公民與法治(2016年4期)2016-05-17 04:09:26
中國衛生(2014年2期)2014-11-12 13:00:16
語文知識(2014年7期)2014-02-28 22:00:26
