融合多特征圖及實體影響力的領域實體消歧
2023-03-13 10:05:40單曉歡齊鑫傲宋寶燕張浩林
計算機工程與應用 2023年5期
單曉歡,齊鑫傲,宋寶燕,張浩林
遼寧大學 信息學院,沈陽 110036
隨著信息技術的飛速發展以及互聯網的普及應用,網絡數據正以指數級的速度增長,網絡已經成為最大的數據倉庫之一,且大量數據在網絡上以自然語言的形式呈現[1]。但是自然語言本身具有高度的歧義性和多樣性,歧義性體現在相同的實體指稱在不同上下文中可以指不同的實體,例如阿里巴巴可以表示阿里巴巴集團、阿里巴巴(阿拉伯小說人物)、阿里巴巴(歌曲名)、阿里巴巴(書名);而多樣性是指同一實體在文本中會有不同的指稱,如馬爸爸、風清揚、Jack Ma都指阿里巴巴集團創始人馬云。如果能夠消除上述歧義,將網絡數據與知識庫連接起來,將更有助于人們理解網絡數據的語義信息,有效利用網絡數據進行數據分析,同時像Dbpedia、YAGO這樣的實體知識庫也可以不斷擴充,使其知識更豐富,而實現這一步的關鍵便是實體消歧技術。
實體消歧指的是識別文本中的歧義實體指稱(命名實體),并為這些實體指稱在眾多的候選實體中匹配出最終的目標實體[2],其在智能問答[3]、語義搜索[4]以及推薦系統[5]等諸多領域都有廣泛應用。實體消歧可分為基于無監督聚類的實體消歧[6],其把所有實體指稱按其指向的目標實體進行聚類;以及基于實體鏈接的實體消歧[7],此類方法利用知識庫獲取候選實體列表,并將實體指稱鏈接到與之最相似的實體上。近年來,隨著知識圖譜的廣泛應用,基于實體鏈接的消歧方法成為解決消歧任務的主流方法,因此本文采用此類方法實現實體消歧。
本文針對現有方法進行研究發現,普遍存在的問題包括:僅考慮單一實體指稱與其候選之間的語義關系,而忽略了同一文本中不同實體指稱候選之間的聯系,因此只能實現局部消歧(單實體指稱消歧);利用候選實體構建圖時,忽略了實體影響力及候選實體間的相似度對實體消歧的影響;將無歧義實體指稱及其候選實體亦作為圖節點,增加了后續圖計算的復雜性,進而對消歧的效率產生影響。
針對上述問題,本文提出一種融合多特征圖及實體影響力的實體消歧方法(entity disambiguation method combining multi-feature graph and entity influence,ED_MG&EI),該方法綜合局部消歧與協同消歧的優勢,有效實現同一文本多實體指稱的整體消歧,本文主要內容如下:
(1)基于候選實體的多特征圖構建。本文以金融領域為特定領域,對現有知識庫進行預處理,提取金融類別相關關鍵詞三元組,構建金融領域知識庫;針對金融活動類文本,提取待消歧實體指稱,融合多種特征提取語義信息并通過相似度計算,篩選候選實體作為頂點集合,利用知識庫三元組信息獲取候選實體間2-hop內的關系作為邊集合,同時計算候選實體間的相似度作為邊權值,進而將多特征信息充分融合到圖模型中,完成多特征圖構建。
(2)提出基于實體影響力的消歧方法,該方法既考慮不同指稱候選之間的關聯性,又將局部消歧的消歧信息轉化為實體影響力,作為消歧計算的衡量指標之一。在消歧過程中,采用動態決策策略,利用PageRank算法,并結合實體影響力計算多特征圖中候選實體的綜合評分,進而獲得可信度較高的消歧結果。
1 相關工作
目前,基于實體鏈接的消歧方法主要有局部實體消歧和協同實體消歧兩類。局部實體消歧通常只利用實體指稱與候選實體的上下文信息的特征表示,計算兩者之間的相似度,進而選出目標實體。由于傳統特征方法[8]多為啟發式算法,需手工設計有效特征,且難以調整,進而無法獲取更深層次的語義和結構信息。近年來,采用神經網絡進行局部消歧的思想逐漸興起,Sun等人[9]提出了一種基于記憶網絡的實體消歧方法,該方法通過注意機制從周圍的語境中自動找到重要線索,并利用這些線索進行實體消歧,不依賴任何手動設計的特性。為了有效地學習模型參數,其需要大量的訓練數據。Deeptype[10]是一種將符號信息集成到帶有類型系統的神經網絡推理過程中以實現實體消歧的方法,其能夠將結構化數據和非結構數據進行整合,在英語、法語、德語以及西班牙語上具有較理想的消歧效果。Alokaili等人[11]提出了一種基于長短時記憶循環神經網絡的神經網絡結構,用于編碼目標地理實體的上下文,進而實現地理實體消歧,其在英語和西班牙語兩個注釋語料庫上對方法進行了評估。
協同實體消歧認為同一文本中不同實體指稱存在語義關聯性,進而推斷其候選實體之間也具有依賴關系,在局部消歧基礎上增加協同策略,結合這種關系進行綜合計算,以提升實體消歧性能。文獻[12]提出了一種結合語義表示學習的基于圖的實體鏈接模型,基于RDF數據訓練的語義向量構造了一個實體相關圖,并在圖上利用PageRank算法計算實體指稱的正確候選實體。近年來,也有相關算法[13-14]將深度學習與圖方法結合,將構建的實體圖輸入到圖神經網絡中學習,此類方法消歧效率較高,但文檔較多訓練起來工程很大。文獻[15]為解決短文本稀疏性造成概念化困難的問題,通過度量術語之間的相關性、選擇信息術語并對信息術語進行優先排序,以突出其辨別能力,減少噪聲干擾。Jia等人[16]提出了一種層次語義相似模型,該模型基于實體指稱上下文、實體描述和類別等多個信息源來尋找實體指稱與目標實體的語義匹配。實體鏈接標注系統ABACO[17]假定標注的實體與文檔的主題一致,以解決名稱歧義問題。根據候選實體在知識圖中的中心性和與文檔主題的文本相似度對其進行評分,進而剔除最差的候選實體。
2 基于候選實體的多特征圖構建
本文針對特定領域,從財經網、南方財富網、搜狐財經等網站爬取金融領域相關語料,獲得經過人工標注、數據清洗、事件抽取而最終生成的待消歧實體指稱集,并在此基礎上進行研究,實現參與金融活動要素的實體消歧。因為金融相關文本表達的信息主要是金融交易或投資之間的關系,所以命名實體識別后的實體指稱項(待消歧實體)為參與金融活動要素的企業及與企業相關的個人實體。
2.1 領域知識庫構建
CN-DBpedia[18]是由復旦大學知識工場實驗室研發并維護的大規模通用領域結構化百科,是國內最早推出的也是目前最大規模的開放百科中文知識圖譜,涵蓋數千萬實體和數億級的關系。CN-DBpedia主要從中文百科類網站(如百度百科、互動百科、中文維基百科等)的純文本頁面中提取信息,經過濾、融合、推斷等操作后,最終形成高質量的結構化數據,即Dump數據集。
Dump數據集中有mention2entity信息110萬+、摘要信息400萬+、標簽信息1 980萬+、infobox信息4 100萬+。Dump數據中的摘要信息、標簽信息以及涵蓋大量三元組關系、語義信息的infobox信息,適用于圖節點及關系的挖掘;而mention2entity數據包含的信息則更注重表示實體對應的不同含義,即可能是具有相同字面表示的所有可能含義或者是現實中存在同一實體的不同別名的情況,因此這種數據對于候選實體生成具有一定的過濾作用。
由于本文只針對金融領域的實體消歧進行研究,因此從P2P(網絡借貸)、小額貸款、互聯網支付等金融新業態角度研究,通過人工定義關鍵詞知識體系,從CN-DBpedia數據中提取金融類別相關關鍵詞三元組,構建金融特定領域知識庫,分別生成mention2entity_finance數據和Dump_finance數據,并將抽取的三元組關系批量導入到Neo4j圖數據庫中進行存儲及管理。同時,為了有效提高候選實體的挖掘效率,本文將mention2entity_finance數據進行預處理,遍歷該數據集,將具有唯一含義的實體對三元組提取并生成mention2entity_finance_one-to-one數據集,用于驗證實體指稱是否只具有唯一候選實體;將剩余的三元組繼續存儲在mention2entity_finance數據集中,即該數據集中實體指稱具有多個候選實體。
2.2 多特征圖構建
研究發現,同一文本下不同實體指稱的高相關性,導致對應的不同候選集合之間也具有一定的語義聯系,且這種語義聯系對消除實體歧義具有一定的作用[2],為此本文將候選實體及其之間的聯系構建為有向加權圖G=(V,E,LV,W)表示,其中V為節點集合,表示不同實體指稱的候選實體及候選實體的1-hop鄰居實體;E表示邊集合,由不同實體指稱的候選實體之間的語義關系組成;LV則為節點標簽屬性集合;W表示邊權值集合,候選實體之間的關聯度通過邊權值表示,權值越大,則表明兩候選實體之間越相似。
2.2.1 候選實體篩選
對于候選實體的生成,首先將文本中所有識別出的實體指稱項組成集合M={m1,m2,…,mn},其中n表示文本中實體指稱項的個數。然后針對每個實體指稱項mi,在預處理的知識庫三元組數據中搜索與之同名的頭實體,將對應的尾實體集合作為該實體指稱的候選集Ei={ei1,ei2,…},同理獲得全部實體指稱的候選集合H={E1,E2,…,Es},其中每個候選實體即為多特征圖的節點。
如果知識庫(mention2entity_finance_one-to-one及mention2entity_finance)中沒有同名實體,則把相應的實體指稱項歸為空實體。如果從mention2entity_finance_one-to-one獲得實體指稱的候選實體,則表明該候選實體為唯一的無歧義候選,將這類候選實體直接作為實體消歧結果,不再構建于圖中,進而降低了圖的規模并簡化了后續圖計算的復雜度。其余實體則具有多個候選實體,為避免過多候選實體對實體消歧效率產生的影響,本文選取top-k個候選實體作為構建多特征圖的節點,當候選實體個數小于等于k時,選取指稱項所有的候選實體作為它最終的候選實體;當候選實體個數大于k時,定義指稱項與候選實體的相似度為指稱相似度,選取相似度最大的k個候選實體作為最終的候選實體。本文指稱相似度由衡量字符串特征的編輯距離語法相似度以及表示語義特征的上下文語義相似度構成。
(1)表示字符串特征的編輯距離語法相似度
編輯距離(edit distance,ED)是兩個字符串之間,由一個字符串通過替換、插入和刪除等一系列操作轉換成另一個字符串所需的最少編輯操作代價。用EDm,ei(x,y)來表示字符串m和ei之間的編輯距離,其中x和y分別表示m和ei的長度。為統一量綱,本文對編輯距離進行歸一化處理,如式(1)所示。當m和ei完全相同時,NED=0;反之,當m和ei完全不同時,NED=1,即NED(m,ei)∈[0,1]。
本文利用編輯距離對兩字符串間的接近或相似程度進行衡量,將歸一化的編輯距離轉換為詞語間的語法相似度,如式(2)所示,其值越大,表明兩字符串的編輯距離越小,則越相似。
(2)表示語義特征的上下文語義相似度
編輯距離只反映了m和ei之間的字符串特征,未考慮任何語義特征,然而考慮到同一個實體所處的上下文環境相似,本文利用實體指稱的上下文和候選實體在知識庫中的上下文之間的文本特征計算實體指稱與候選實體的相似性。對于m和ei之間的文本特征,采用經典的向量空間模型(vector space model,VSM)進行計算,通過空間上的相似性直觀易懂地表達語義的相似度。
首先對實體指稱和候選實體的上下文進行分詞、停用詞去除等預處理,再利用詞袋模型將2個文本表示為向量,并計算2個向量之間的余弦值作為實體指稱與候選實體的文本語義相似度,計算公式如式(3):
其中,X表示實體指稱m上下文的詞向量,Y表示候選實體ei的詞向量,X·Y表示向量內積,||X||表示向量長度。
本文將上述兩種相似度的線性組合作為實體指稱與候選實體之間的指稱相似度,如式(4)所示:
2.2.2 候選實體關系挖掘
實體關系屬性是候選實體的重要屬性之一,這種屬性可以直接通過多特征圖中的邊表示。本文構建的領域知識庫的Dump_finance數據中含有豐富的關系屬性,本文通過檢索頭、尾實體為候選實體的三元組,獲得候選實體間的關系屬性,從而使候選實體相互連通形成網絡圖。具體過程為對每個實體指稱的候選實體集合中的每個元素分別與其他候選實體集合中的所有元素進行關系查找,如果兩者之間存在直接三元組或者具有2-hop的路徑,則認為兩候選實體之間存在關系,對應多特征圖中兩節點之間生成連接的邊。為豐富消歧信息,提高實體消歧的準確性,在多特征圖的構建過程中,既考慮了候選實體間的直接關系,又將2-hop內的間接關系體現在圖中。
2.2.3 基于上下文語義相似度的權值計算
因為候選實體本身帶有一定的描述信息,利用該語義信息可以計算不同實體指稱的候選實體間的相似度,從而生成節點之間的邊權值。本文將候選實體的描述文本表示為其上下文的文本向量,通過文本向量間的距離衡量不同指稱的候選間的相似程度,其值由式(3)的余弦相似度計算所得。
綜上,本文將構建的具有節點標簽且能表示候選實體間語義關系及相似程度的有向加權圖稱之為多特征圖。考慮某些實體指稱只有唯一候選實體,這類無歧義候選實體即為消歧結果,無需構建于圖中,簡化了圖的大小和后續圖計算的復雜度。如圖1所示,多特征圖中節點由候選實體及候選實體之間的2-hop間接關系組成,邊由不同實體指稱的候選實體間的語義關系組成。圖1中方形節點為實體指稱,虛線表示實體指稱與候選實體的對應關系,其上的權值為指稱相似度,將作為候選實體節點的權值,因此本文構建的多特征圖中不包含實體指稱。
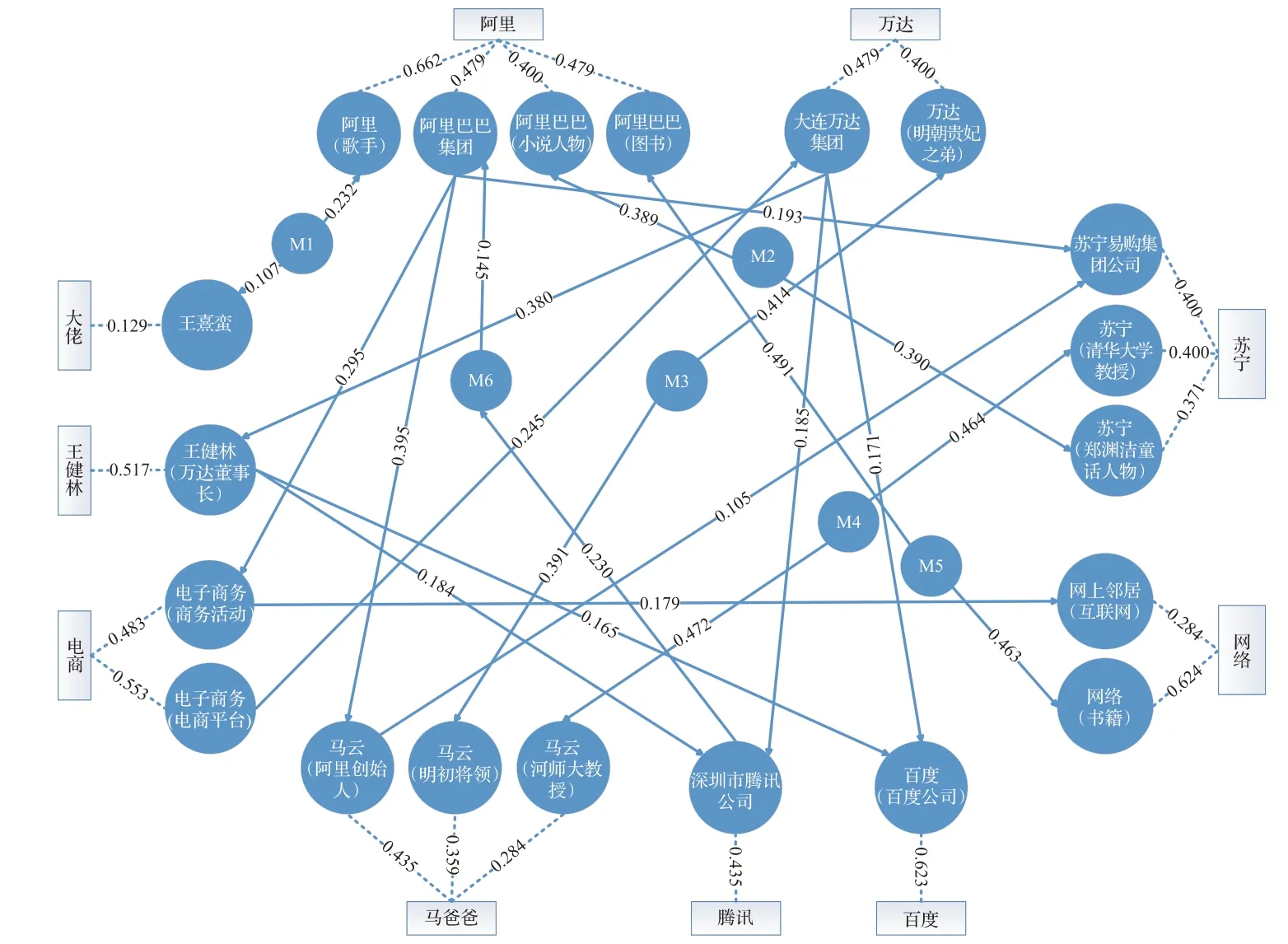
圖1 多特征圖示例Fig.1 Example of multi-feature graph
3 領域實體消歧
3.1 候選實體影響力計算
本文利用協同消歧的思想,即同一段文本的實體指稱語義相近,推斷知識庫中的候選實體語義也相近[12]。同時在眾多實體指稱的候選實體中,唯一候選實體作為無歧義候選,其與其他實體指稱的候選實體的關聯性對確定目標實體具有一定的影響,因此本文將唯一候選實體與其他候選實體的關聯性作為節點的影響特征。
對無歧義候選實體集合Ei′中的元素分別與圖中其他候選實體集合Ei中的每個元素進行關系查找,通過檢索特定金融領域知識庫的Dump_finance數據中的三元組,如果E′i中的元素與Ei中的元素之間存在直接三元組,說明該候選實體與唯一候選實體之間有關聯,則增加圖中相應候選實體的影響特征,每出現一個三元組則影響特征值加θ,其中θ∈(0,1)。
與此同時,實體指稱與候選實體之間的指稱相似度也作為衡量該候選實體影響力的因素之一,因此實體影響力的具體定義如下。
定義1(實體影響力)無歧義候選的影響特征值與指稱相似度之和。
3.2 基于改進PageRank和影響力的實體消歧
本文利用多特征圖的多屬性特征,確定圖中候選實體選擇的兩種因素,一種是候選實體影響力,包括無歧義候選的影響特征和指稱相似度,反映候選實體在圖中的影響力大小;另一種是利用PageRank算法計算節點的重要程度。
PageRank算法是基于實現網頁重要性排序的一種算法。本文將圖中的節點對應為實體概念,然后通過PageRank算法捕捉圖模型中各個節點的重要程度。常規的PageRank算法只考慮了出入度的平均分配,即某個節點的PageRank值為它入度節點集中每個入度節點的PageRank值除以它們的出度邊數之和。本文將PageRank計算公式進行修改,以適應本文的有向加權圖,每個入度節點給出的值大小不再是平均分配,而是引入多特征圖中代表候選實體間相似度的邊權值,按權值占比大小分配,具體公式如下:
其中,N為節點數,M(ei)表示鏈入ei節點的集合,N(ej)表示鏈出ej節點的集合,W(ej,ei)是節點ej、ei之間邊權值,d為阻尼因子,一般取0.85。達到平穩狀態時的PR值表示了各節點的重要程度。
本文綜合考慮實體影響力及節點的重要程度進行消歧。在消歧過程中,采用動態決策策略依次對每個實體指稱進行消歧,計算所有節點的PageRank值,將各節點的影響力與PageRank值相加,作為候選實體的綜合評分,分數越高的候選實體越優先消歧;若出現不同指稱中多個候選的綜合評分相同,則選擇候選個數最多的實體指稱優先消歧。每確定一個實體指稱的目標實體,則對多特征圖中節點進行修剪,將該實體指稱的其他候選實體從多特征圖中移除,以減少后續的計算量,具體算法如算法1所示。圖1最終的消歧結果如圖2所示。
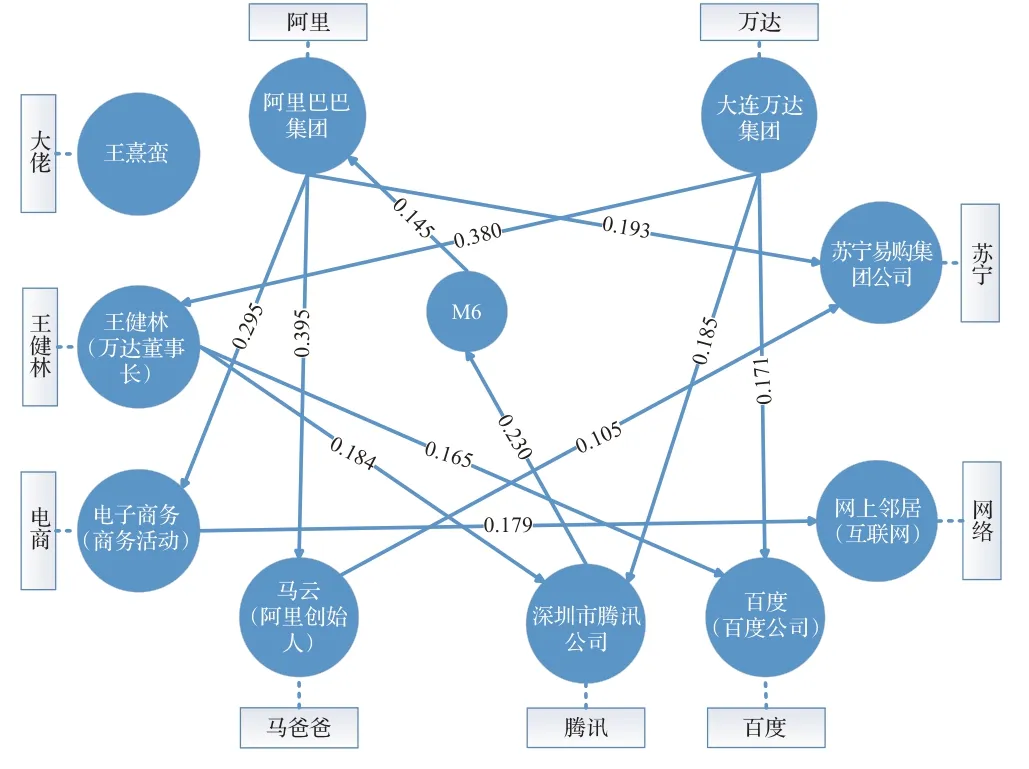
圖2 消歧結果Fig.2 Disambiguation results
算法1ED_MG&EI Algorithm
Input:G,每個節點的影響力
Output:mention_entity_Dic(實體指稱對應的目標實體)
Begin
1.對圖G計算PageRank;
2.將每個節點的影響力加到其PageRank值上;
3.獲取PageRank值+影響力最高的候選實體entity;
4.將entity對應實體指稱mention的其他候選實體以及相關邊從G中移除并在mention_entity_Dic中添加mention_entity_Dic[MENTION]=entity;
5.若mention_entity_Dic中的實體指稱沒有完全確定,返回1;
6.返回mention_entity_Dic;
End
4 實驗與分析
4.1 實驗設置
本文基于pycharm在Windows10環境下實現。實驗采用從財經網、南方財富網、搜狐財經、新浪微博等網站爬取的金融活動文本為數據集。人工選取包含歧義實體較多的500篇文本,其中200篇作為訓練數據,訓練指稱相似度中編輯距離語法相似度與上下文語義相似度的最優權值參數,300篇作為測試數據分析實驗方法性能。語料預處理過程采用分詞工具完成,包括分詞、去停用詞等過程。人工標記出與金融活動相關的公司實體和個人實體,通過命名實體識別可從文本中識別出共1 230個實體指稱,通過人工方式標注了所有實體指稱對應的正確實體(含NIL實體)。
本文采用準確率(Precision)、召回率(Recall)、F值三種評價指標,對提出方法的有效性進行驗證。
4.2 實驗分析
實驗1特征參數的設置分析
將200篇文本構成的訓練數據用于訓練生成權值參數的最優解,在指稱相似度中包含語法特征和語義特征兩種,分別分配給兩特征參數α和β,令α和β相加得1。測試實驗使得兩個特征同時發揮最大作用,通過對準確率Precise的分析,確定式(4)中α和β的最優值,如圖3所示,當α=0.40、β=0.60時,準確率達到最大值。
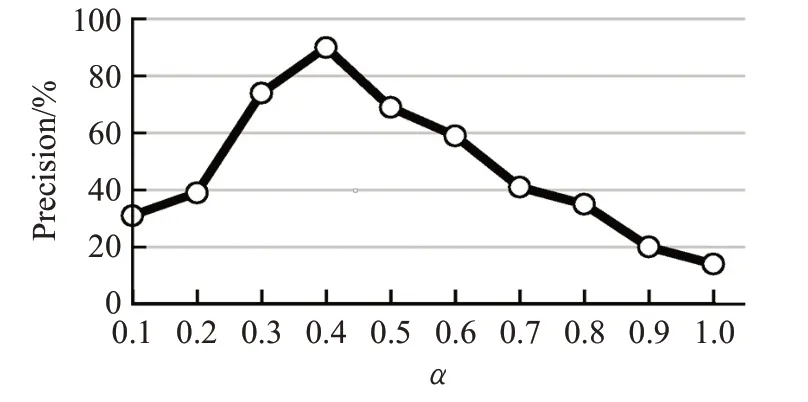
圖3 參數設置Fig.3 Parameter setting
實驗2利用不分類候選生成圖和去除無歧義候選的多特征圖消歧的實驗結果對比
實驗2將所有實體指稱生成的候選集都作為圖節點,構建不分類候選生成圖;按候選實體分類將包含多個候選實體的實體指稱對應的候選集作為圖節點,構建多特征圖。表1為利用不分類候選生成圖和去除無歧義候選的多特征圖進行消歧的結果,由于本文多特征圖中去除了無歧義候選,有效降低了圖的規模,同時將節點影響力及節點的重要程度作為節點的綜合評分,有效提高了消歧的準確性。

表1 不分類候選生成圖和多特征圖的實驗結果對比Table 1 Comparison of results between unclassified candidate generating graph and multi-feature graph單位:%
實驗3局部消歧、協同消歧和本文的集成消歧實驗結果對比
為分析多種特征的有效性,本實驗在基線系統的基礎上分別疊加局部消歧、協同消歧和本文結合兩種策略產生的集成實體消歧方法,三種方法與基線系統進行對比,實驗結果如表2所示。
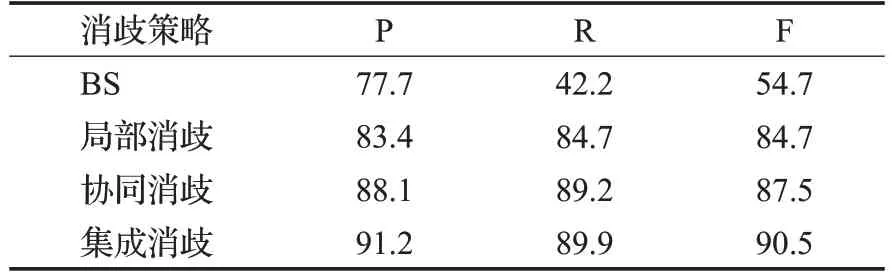
表2 消歧策略實驗結果對比Table 2 Comparison of experimental results of disambiguation strategies 單位:%
實驗4無向無權圖與本文有向加權圖方法實驗結果對比
本文在現有圖方法的基礎上進行改進,將圖變換成精度更高、信息更豐富的有向加權圖,知識庫三元組的頭節點及尾節點提供有向邊,圖節點之間的相似性及語義關系為邊提供權值,有向加權圖使PageRank的計算結果更準確,實驗進行有向加權圖和無向無權圖方法對比,實驗結果如表3所示。

表3 無向無權圖和本文有向加權圖方法實驗結果對比Table 3 Comparison of experimental results between undirected unweighted graph method and proposed directed weighted graph method 單位:%
實驗5不同領域數據集對比
本文針對特定領域,在金融活動相關文本中提取實體,分析非法金融活動,在金融新業態角度研究非法金融活動的界定,構建金融領域知識庫輔助消歧,因此相較于其他領域,金融領域文本的實體消歧效果更理想,實驗結果如表4所示。
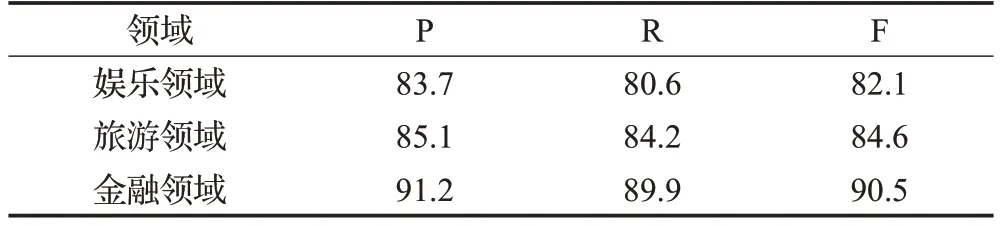
表4 不同領域實驗結果對比Table 4 Comparison of experimental results in different fields單位:%
實驗6不同方法實驗結果對比
實驗在金融領域數據集上復現了張濤等人[19]和高艷紅等人[20]的方法,張濤等人[19]提出了一種基于圖模型的維基概念相似度計算方法,有效地捕捉實體指稱項文本與候選實體間的語義相似度。但圖構建沒有充分利用特征的表達,影響相似度計算。高艷紅等人[20]提出了一種融合多特征的解決方案,將語義相似度融合到圖模型中,但由于其構建的實體指稱-候選實體圖僅能對單一實體指稱進行消歧,不適用于文本中多實體指稱的集成消歧。本文針對上述問題,將無歧義候選實體去除,以降低圖規模,同時綜合考慮字符串特征、語義特征、實體影響力以及節點的重要程度等特征因素,以獲得可信度較高的消歧結果,實驗結果對比如表5所示。
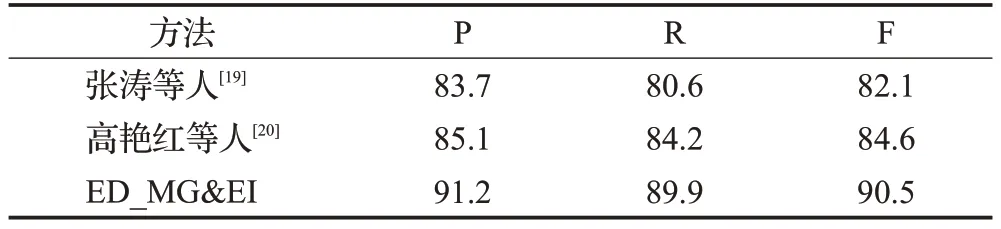
表5 本文方法與其他方法實驗結果對比Table 5 Experimental results of this method compared with other methods 單位:%
5 結束語
本文對特定領域的實體消歧問題進行了研究,提出了一種融合多特征圖及實體影響力的領域實體消歧方法。以金融領域為例,首先構建金融領域知識庫,然后針對金融活動類文本,提取待消歧實體指稱,利用構建的金融知識庫,融合字符串及語義的相似特征,實體影響力及節點重要程度等特征屬性構建多特征圖;最后采用動態決策策略,利用PageRank算法,并結合實體影響力計算多特征圖中候選實體的綜合評分,進而獲得可信度較高的消歧結果。實驗結果驗證了提出方法在特定領域實體消歧的精確度。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
