圖神經網絡會話推薦系統綜述
2023-03-13 10:04:16朱志國李偉玥周沛瑤
計算機工程與應用 2023年5期
朱志國,李偉玥,姜 盼,周沛瑤
東北財經大學 管理科學與工程學院,遼寧 大連 116025
推薦系統旨在幫助用戶從紛繁復雜的數據中提取出感興趣的信息,在提高效率的同時,也有助于提升用戶滿意度與平臺效益。近十年來推薦系統技術得到了長足發展,不僅成為學術界的研究熱點之一,也已經成功地運用在電商、新聞和音樂推薦等多個場景中[1]。其中,會話推薦(包括基于會話的推薦與會話感知推薦,但不包括普通序列推薦)旨在以用戶當前的項目交互序列為主,以歷史會話數據、場景、知識圖譜等信息為輔,重在通過各種方式捕捉用戶的當前興趣,如圖1所示。
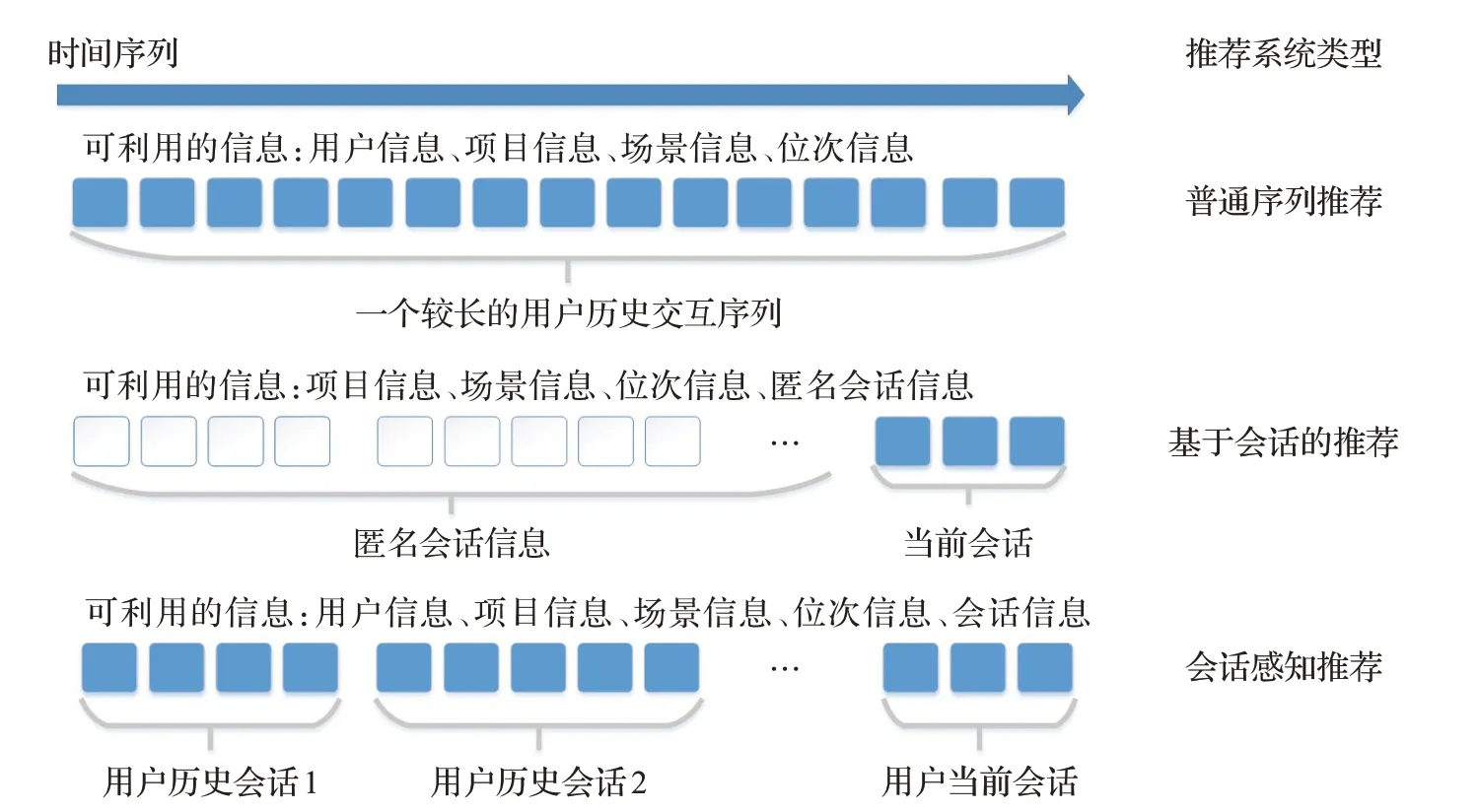
圖1 普通序列、基于會話和會話感知推薦的概念區分Fig.1 Concept distinction of recommendation among sequence-based,session-based and session-aware
此前,會話推薦領域的相關工作大多基于多種循環神經網絡(recurrent neural network,RNN),或采用RNN結合多種注意力機制,亦或是基于純注意力機制和復雜結構的多層感知機(multi-layer perceptron,MLP),同時結合豐富的輔助信息來捕獲項目間的依賴關系。雖然這些會話推薦系統能夠捕捉到項目間的順次轉換關系,但是在當前會話中捕捉項目間遠距離的非嚴格時序轉換關系,或在全局會話環境中捕捉項目間多對多的復雜關聯關系時,其性能有待提升[2]。
圖神經網絡(graph neural network,GNN)是可從非歐式數據的圖結構數據中,根據目標節點的鄰域信息學習特征的神經網絡結構。近些年來GNN的發展十分迅速,并已在生物醫學工程[3]、自然語言處理[4]、社交定位[5]、計算機視覺[6]、金融預測[7]等領域得到了一定研究。由于用戶社交關系、用戶或項目知識圖譜等信息可直接表示為圖,并且用戶-項目交互關系和原始會話序列等信息可以轉換為圖,同時GNN提供了可融合多種信息的統一框架,學者們提出了基于多種圖神經網絡的會話推薦系統[8-10],旨在根據多種信息源學習,得到融合了豐富特征的目標節點向量,實現基于用戶特征的個性化精準推薦。
目前,已經有學者以不同的分類標準,對基于GNN的推薦系統進行了對比分析[1,11],但是其中鮮有對會話推薦相關工作的最新工作進展評述。因此,本文將從問題定義和會話推薦中需要考慮的因素出發,然后根據模型的不同算法原理,將諸多基于GNN的會話推薦系統進一步細分為:基于圖卷積網絡(graph convolutional network,GCN)、門控圖神經網絡(gated graph neural network,GGNN)和圖注意力網絡(graph attention networks,GAT)及其他結構的會話推薦系統共四大類進行評述。隨后根據各工作的實驗部分展開綜合對比討論,力圖展現出GNN在會話推薦系統中的應用與研究前沿進展概貌。最后,提出了對該領域未來研究的一些思考和展望。
1 會話推薦中的考慮因素
總結起來,如圖2所示,會話推薦任務中需要考慮的因素大體可分為如下三類:用戶因素、項目因素和情景因素。
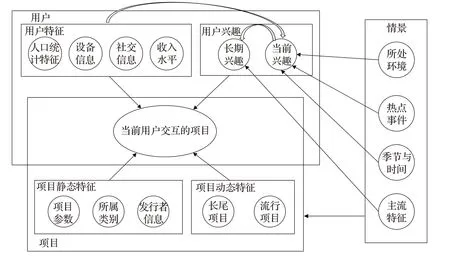
圖2 會話推薦任務中的因素Fig.2 Factors in session recommendation task
(1)用戶因素:如果能獲取到用戶的信息,則可以根據其人口統計學特征、設備、社交關系和收入水平等信息來推斷出該用戶的興趣偏好。
(2)項目因素:主要包括相對穩定的靜態特征和隨時間變動較為明顯的動態特征。靜態特征主要包括項目參數(如尺碼、價格等)、所屬類別(即項目對應的分類信息)、發行者信息(如商品對應的生產商、新聞對應的記者等);動態特征主要指該項目的熱度高低,比如近期熱門新聞或爆火的網紅商品可認為是流行項目。
(3)情景因素:主要包括用戶所處環境、近期熱點事件、季節與時間、當前流行項目特征(如當季流行配色與款式等)。這些情景因素可能會對項目因素產生較大影響,并且場景因素也會在一定程度上影響到用戶的長短期興趣[12-13]。
2 基于GNN的會話推薦系統構圖分析
對于基于GNN的會話推薦系統而言,如何將原始的會話序列高效地轉換為相應的會話圖,是首要且重要的問題。如圖3所示,SR-GNN模型[8]首次提出將會話序列轉換為會話圖進行處理,即以會話中的項目為節點、以項目間的鄰接順次轉換關系為邊、以歸一化鄰接矩陣中的值為邊權重構圖。
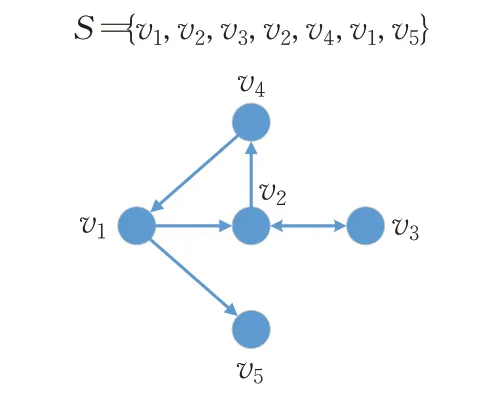
圖3 SR-GNN模型的經典構圖方式示例Fig.3 Traditional graph constructing method in SR-GNN
這種經典的構圖方式實現了序列式數據到圖數據的轉換,使得全局項目間的依賴關系更為直觀和易于捕捉。此后,一些學者將用戶節點、項目所屬類別、用戶行為類別(如點擊、購買、分享)等多種類型的節點加入圖中或單獨構圖,同時引入了豐富類型的邊,使模型可以直接學習到多元節點間的豐富交互關系,隨后可將各類信息與項目特征相融合,以獲得更為豐富的項目表示。如圖4(a)所示,SE-Frame模型[14]在構造會話圖時,考慮到了用戶節點,從而在圖學習時可直接捕捉到用戶與項目的豐富交互信息;SR-HetGNN模型[15]則進一步將會話作為節點加入異構圖中,使模型能夠從全新角度學習整個會話的特征表示。圖4(b)所示的GNNH模型[16]異構圖將用戶的不同交互行為視為邊特征,并分別應用于項目圖和類別圖,使得模型能夠學習到包含多種用戶交互行為特征的項目及其所屬類別的表示向量。
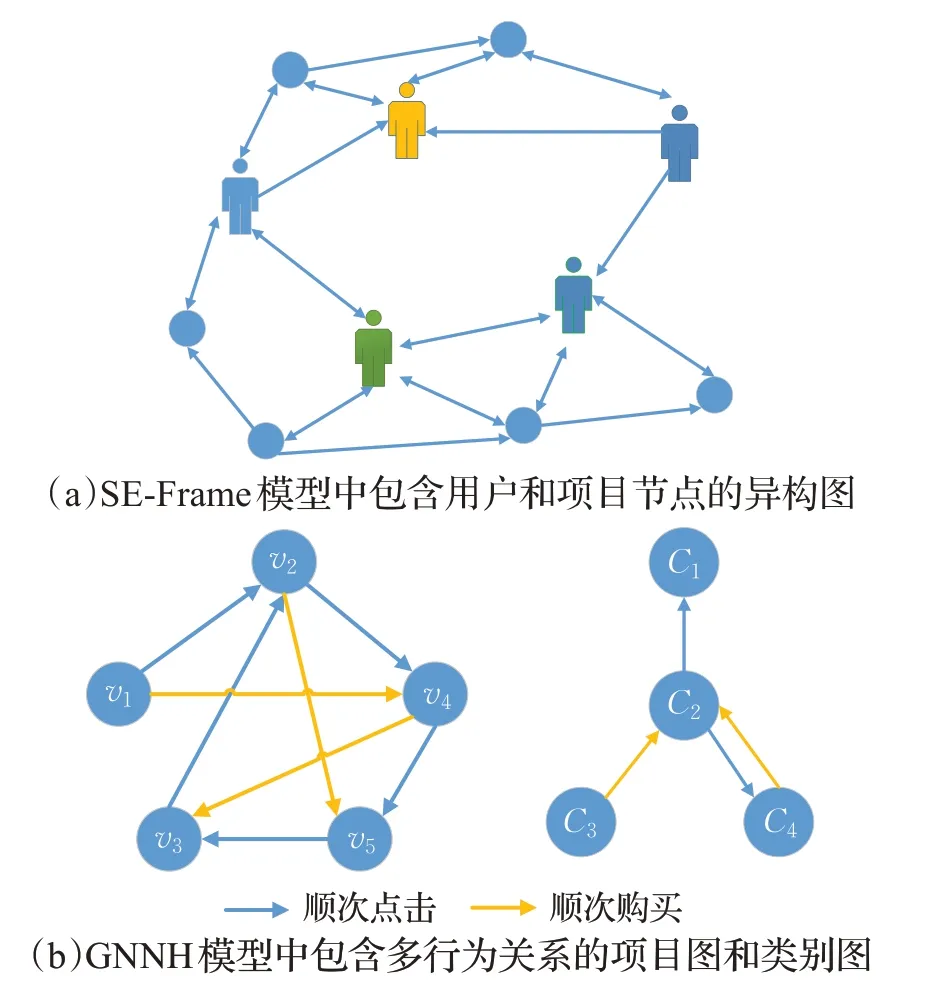
圖4 包含多種節點與邊的復雜異構圖Fig.4 Complex heterogeneous graph with diverse nodes and edges
一些學者為了更加充分地挖掘項目間的上下文關系而去除了邊的方向信息,提出了DSGNN模型[17]、TAGNN模型[18]中的無向加權項目圖,此類會話圖可以將全局項目間轉換關系更加明晰地顯示出來。
還有一些學者提出了更加具有創意的會話圖構造方式,例如SGNN-HN模型[19]中的星型圖、DHCN模型[20]中的超圖及其對應線圖等,如圖5(a)和(b)所示。星型圖中的不相鄰節點可通過中心節點以兩跳的方式相連,使得模型更易捕捉到遠程項目的關聯關系;而超圖則直接忽略了項目間的順次連接關系,從會話的層面探索項目間的相關關系,線圖則映了超圖的連通性,可直接越過項目級,從更高層面上探索會話間的關系。
針對部分基于GNN的會話推薦模型中存在的有損會話編碼和難以捕捉項目間遠距離依賴關系的問題,LESSR模型[21]在將會話序列轉換為會話圖的過程中,加入了邊順序信息,從而避免了時序信息丟失問題;并在原始會話圖的基礎上提出了快速連接圖,其中新加入遠距離項目間的邊使模型得以更加全面地捕獲項目間的遠距離依賴關系,如圖5(c)所示。而SR-LSG模型[22]也提出了一種類似于LESSR模型中保持邊順序的會話圖,如圖5(d)所示。兩者的區別在于LESSR模型圖中的邊編號由指向目標節點不同邊的順序確定,而SR-LSG模型圖中的邊編號由會話項目順序確定。
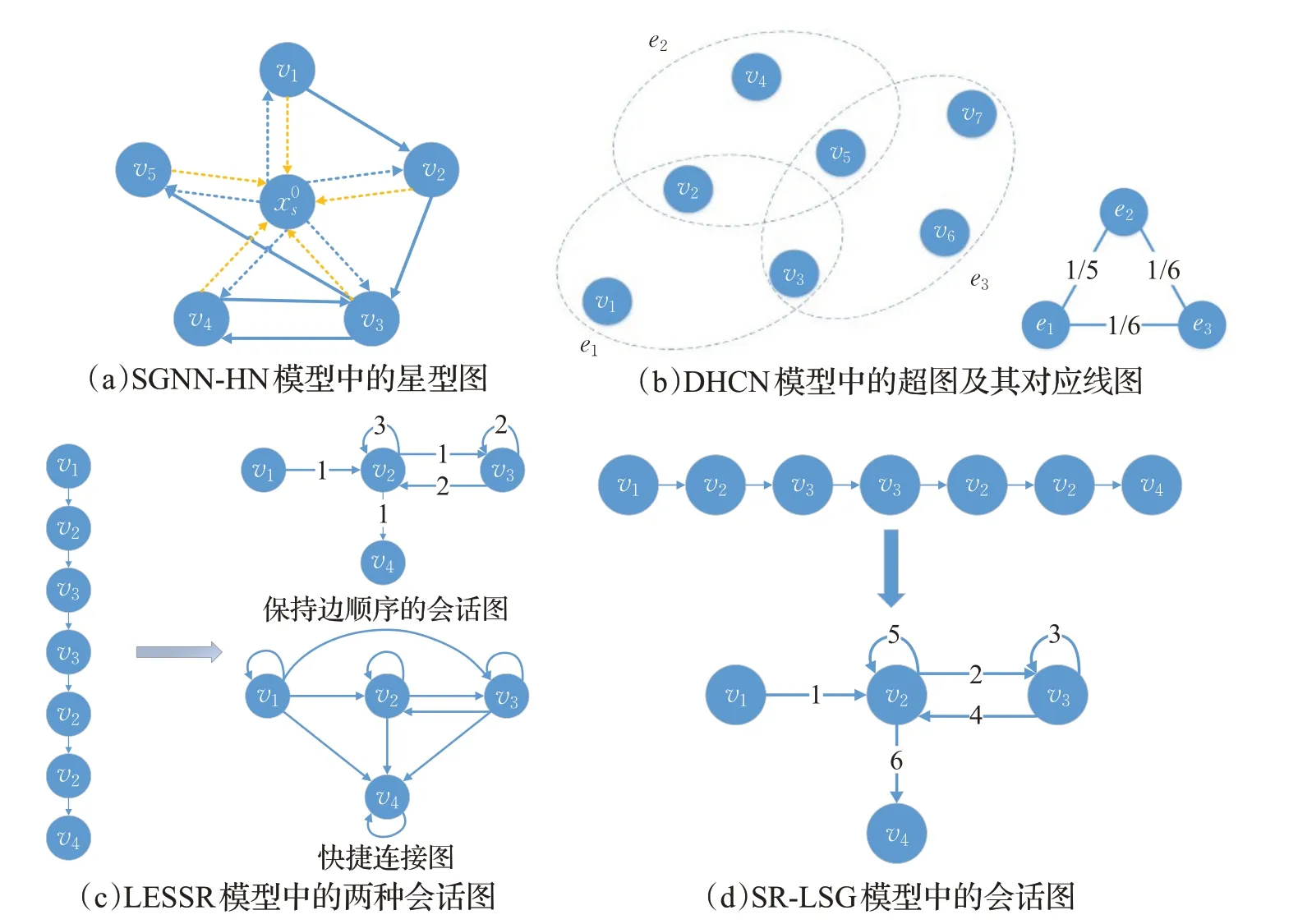
圖5 部分新型的會話圖結構Fig.5 Some creative session graph structure
在優化邊權重的相關工作中,除了根據近鄰矩陣或進一步將數值歸一化后設置邊權重的經典方法外,SR-HGNN模型[23]通過累乘原始未加權的近鄰矩陣來構造不同階數的高階近鄰矩陣,以直接捕捉項目間的高階關系;Disen-GNN模型[24]將項目分解為因子級表示,并由此提出了因子級相似性矩陣。另外,一些基于GAT或注意力增強的GGNN的會話推薦系統也可通過動態更新邊權重捕捉用戶不斷變化的興趣。
總的來說,SR-GNN式的會話圖構造方式使得GNN能夠間接處理序列式的會話數據。隨后,各學者受此啟發,從節點類型、鏈接屬性等方面基于經典會話圖進行優化。在此過程中,豐富的用戶側和項目側邊信息(side-information)以及多種圖結構變換極大地豐富了原始會話圖中的數據,使得GNN有機會學習到包含更多信息的項目特征表示,從而提升了推薦結果的精準性。然而,優化會話圖的方式可能會帶來更多噪聲信息。因此,可以嘗試采用多種形式的注意力機制對特征提取結果進行去噪,以減輕非關鍵信息對特征提取的負面影響。
3 不同GNN架構下的會話推薦系統研究進展
基于GNN的會話推薦系統大多首先將會話序列轉換為會話圖,并將多個會話圖合并為全局會話圖;然后通過圖神經網絡中的多種架構形式(如:GCN、GGNN、GAT等)聚合目標節點的近鄰節點信息,從而精準捕獲到n跳(n∈Z+)的鄰域信息。隨后,結合項目本身的信息、項目間的復雜轉換關系和用戶與項目的交互信息生成包含多種豐富信息的項目表示,進而基于注意力機制、循環神經網絡等模塊生成較為精確的會話表示。最后綜合用戶表示、會話表示和項目表示等特征計算各候選項目的推薦得分,實現精準推薦。
與完全基于循環神經網絡、卷積神經網絡等結構的會話推薦系統不同,圖數據結構具有良好的可擴展性,能將多種性質的節點與邊融入會話圖中,這極大地豐富了會話圖中的信息。因此,本章將基于GNN的會話推薦系統進一步劃分為基于GCN、GAT、GGNN及其他GNN架構的四類模型,并分別對各算法原理下的相關工作展開梳理、評述與總結。
3.1 基于GCN架構的會話推薦系統
GCN將傳統卷積神經網絡對二維網格型數據的卷積運算推廣至圖數據,其基本思想是通過對基于圖的拉普拉斯矩陣進行一階特征分解,聚合目標節點自身和近鄰節點的特征,從而得到目標節點表示。圖6(a)表示二維卷積網絡對網格型數據的處理,即通過一定算法聚合目標節點及其周圍八個相鄰節點的特征。以生成節點表示。由于過濾器的大小固定不變,因此近鄰節點的個數也是固定不變的。而圖6(b)展示的GCN雖然也是根據一定方法聚合目標節點的近鄰節點特征以生成節點表示,但由于不依賴于固定尺寸的過濾器,即不要求近鄰節點的個數恒定,因此該算法更為靈活。
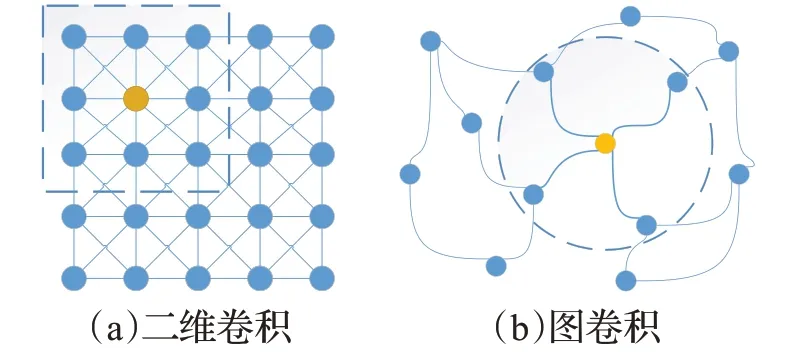
圖6 傳統二維卷積與圖卷積的區別Fig.6 Difference between traditional 2D convolution and graph convolution
基于GCN的會話推薦系統大多基于線性變換和非線性變換結合的消息傳遞機制,根據目標節點的鄰域信息學習其特征表示,如公式(1)所示:
其中,H(l)為第l層的節點隱狀態矩陣,ψ(·)為復雜的非線性函數,例如MLP、加性注意力機制等。A為鄰接矩陣,為了在信息傳播和聚合過程中考慮到節點自身信息,因此令對應的度矩陣,且有
從多關系項目圖中學習項目特征表示時,MGNNSPred模型[25]和GNNH模型[16]首先根據目標行為和輔助行為及前后項目的兩兩組合得到四類節點集合,并分別使用均值池化方式聚合每個集合中的節點,最后采用加和池化的方式進行聚合。其中,MGNN-SPred模型通過正則累加和門控聚合的方式通過目標行為序列和輔助行為序列直接得到了會話表示向量;而GNNH模型還在多關系特征圖上進行了類似的GCN操作,并獲得了在會話中用戶對不同特征的興趣。
DGTN模型[26]在更新會話圖節點信息時,去除了非線性激活函數,并將權重矩陣進行折疊,僅根據規范化后的近鄰節點向量對會話內和會話間的項目節點信息進行特征學習。而DHCN模型[20]使用新穎的超圖及其線圖對會話序列進行建模,并基于超圖卷積對項目節點特征進行學習。COTREC框架[27]采用了與DHCN模型類似的聚合算法,兩者區別在于該框架使用項目視圖和會話視圖的概念取代了DHCN模型中的超圖概念。
GCN作為一種有效的局部特征提取算法,可對目標節點的數個K階近鄰節點的信息進行聚合來獲得目標節點的最終表示。現根據GCN在會話推薦系統中的作用,將部分代表工作進行分類,如表1所示。
從表1中可以看出,GCN的主要作用是學習會話圖中各項目節點的特征表示,并根據后續模型任務,通過多種讀出函數生成局部或全局會話表示。由于GCN難以捕捉項目間的時序依賴關系,因此在學習用戶長短期興趣時,還會引入GRU[28-29]和多種注意力機制[9,16,20,27,29,31,33]。為了更好地學習項目間的遠距離近鄰上下文特征,大多數模型采用了堆疊GNN的方式,然而這會帶來非常嚴重的過度平滑問題。一些模型[29-31]通過修改GCN的消息傳遞算法,有效地解決了此類問題。此外,由于經典的監督任務欠缺實踐價值,不少相關工作引入對比學習[20]、多任務學習[33]等自監督訓練方式,通過挖掘不同角度下的自監督信號,實現對特征的自適應學習;還有部分工作[32]從提升模型實時學習能力的角度進行優化。
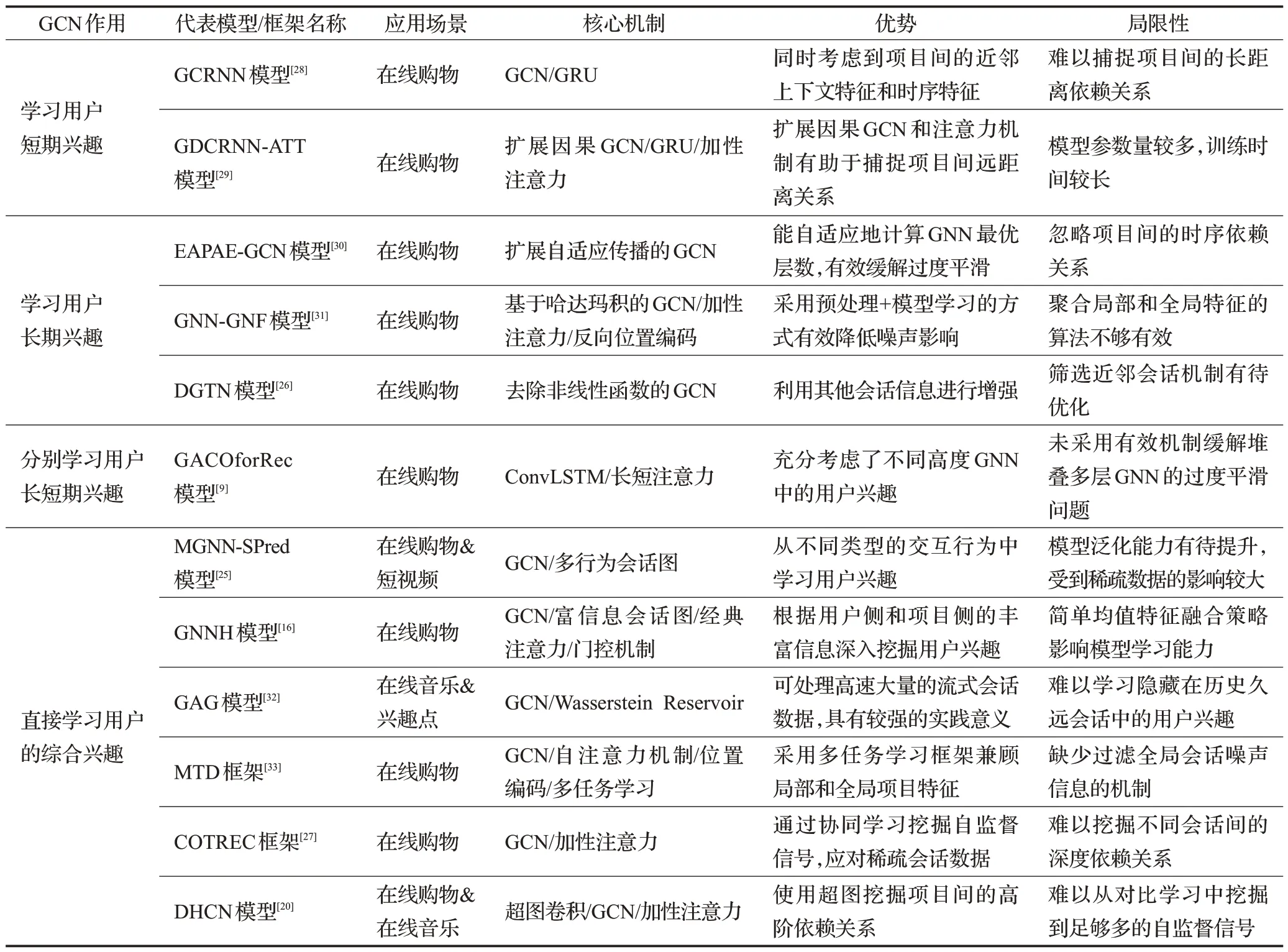
表1 GCN架構在各會話推薦系統中的作用Table 1 Role of GCN among session recommendation system
當從短會話中推斷用戶的興趣偏好時,基于GCN的會話推薦系統性能尚可,但是當會話序列較長時,此類模型的性能往往有待提升。其主要原因是在長會話中學習各項目的特征表示時,需要更多的鄰域信息,因此在堆疊GNN的過程中帶來了嚴重的過度平滑問題。此外,每當會話圖中添加新的節點時都需要重新進行圖推理,而不是采用增量方式計算,因此部分基于GCN的會話推薦系統的可擴展性還有待提升。
總體上,基于GCN的會話推薦系統立足于會話圖結構,通過多種圖卷積算法學習各節點的特征表示。相關工作主要以在線購物場景為主,向在線音樂、短視頻、興趣點等場景進行延伸,在多個場景下保持著較高的推薦精準度。根據相關工作的實驗報告,GNN-GNF模型[31]在電商數據集Yoochoose 1/64上的點擊率Top-20預測任務中,精準度高達70.59%,DGTN模型[26]的召回率更是高達71.18%,充分地體現了此類會話推薦系統的優越性。
3.2 基于GGNN架構的會話推薦系統
門控圖神經網絡是一種以循環神經網絡作為消息傳遞算法的GNN。在會話推薦領域,GGNN采用均值池化算法聚合會話序列中的項目節點信息,并采用門控遞歸單元(gated recurrent unit,GRU)作為遞歸函數來集成近鄰節點和目標節點的信息。相比于GCN不做區分地聚集目標節點及其近鄰節點的信息,GGNN中的門控機制可幫助模型判斷應當保留和丟棄哪些信息;同時GGNN對節點的出邊與入邊進行了區分,即其鄰接矩陣并非GCN中的對稱陣,而是由出度矩陣與入度矩陣拼接得到,如圖7所示。理論上,GGNN還可通過拼接節點間不同類型邊對應鄰接矩陣的方式融合節點間的多元關系。
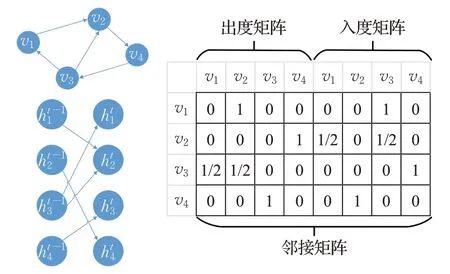
圖7 GGNN示例Fig.7 Example of GGNN
Wu等人[8]提出SR-GNN模型首次將GGNN用于會話推薦系統,該模型在將會話序列轉換為會話圖的同時,對各項目進行了嵌入編碼,并將相應的向量矩陣作為GGNN的初始輸入,然后基于GRU實現節點間的消息傳遞,如公式(2)、(3)所示:
其中,As表示有向圖的節點連接信息,可由經過歸一化處理后的出度矩陣Aosut與入度矩陣Aisn拼接得到;W和b均為可學習參數;k為GGNN的堆疊層數。雖然不難發現GGNN和GRU的公式除了輸入數據不同之外,其余部分基本相同,但是要明確兩種算法的目的和意義存在差別。GGNN是以會話圖的鄰接矩陣作為輸入,處理的信息實質上是節點之間的連接關系,其目的在于學習包含近鄰上下文信息的節點表示;而GRU是以會話序列的項目表示向量為輸入,實質上是在學習項目間的順序依賴關系。為了便于評述,在接下來的章節中稱這種形式的GGNN為經典GGNN結構。
SR-GNN是第一個將GNN引入會話推薦系統的模型,具有開創性價值和里程碑意義,然而該模型存在著一定的局限之處。該模型僅學習了項目間的上下文依賴關系,忽略了項目間的時序特征。同時,由于該模型未能考慮到用戶的個人信息,因此它并非個性化的推薦系統。此后,學者們大多圍繞SR-GNN模型中的經典會話圖構造方法和GGNN架構進行優化。
GC-SAN模型[34]與SR-GNN模型較為相似,但是在對通過GGNN學習到的各項目表示進行處理時,相比于后者的加性注意力算法,GC-SAN模型堆疊由自注意力層、MLP層和殘差學習層組成的自注意力塊提取用戶的長期興趣,并從不同高度的塊中捕捉不同層次的特征。此外,相比于SR-GNN模型采用拼接用戶長短期興趣并進行線性投影的方式獲得會話表示,GC-SAN模型采用了線性插值的方式處理用戶的長短期興趣。
CIE-GNN模型[35]借鑒了GC-SAN模型的部分結構,但是該模型將位置信息加入項目表示中,并將其作為經典GGNN的初始輸出以捕捉項目間的時序關系。相比于GC-SAN模型簡單定義局部會話興趣,CIE-GNN模型使用多頭自注意力層建模局部會話向量表示,從而自適應地捕獲用戶的動態當前興趣。
不同于CIE-GNN模型將項目表示向量輸入經典GGNN進行處理之前就將位置向量與項目向量相加的操作,AMGNN模型[36]先將項目向量通過經典GGNN處理后,再采用拼接的方式將學習到的項目向量與位置向量聚合,并采用多頭注意力與加性注意力相結合的方式學習會話的全局表示向量。
項目間的時序相關關系不僅能根據順次轉換記錄學習,TAGNN模型[37]在為用戶進行推薦時,更注重從用戶歷史交互記錄中提取其對同類商品的喜好。具體來說,該模型采用注意力機制計算指定目標項目下的會話表示向量,并且會話向量可在用戶對新的目標項目感興趣時動態變化,從而有效應對了用戶興趣漂移的問題。
總的來說,各學者主要從表2所示的五個方向對SR-GNN進行優化。例如學者們已嘗試通過堆疊的注意力機制從融入豐富輔助信息的項目表示中,提取用戶的長短期興趣,通過將用戶、類別等信息融入經典GGNN的初始輸入,或是直接改變模型架構。此外,也有學者采用多路并行、優化會話圖和修改整體機制的方法增強模型的性能。然而,相關研究工作均存在不同程度的局限性,其中不少工作僅考慮到了項目間的上下文依賴關系,而忽略了重要的時序相關關系。同時,部分工作簡單地將用戶的最后一個交互項目視為短期興趣,使模型很容易受到用戶興趣漂移的影響。
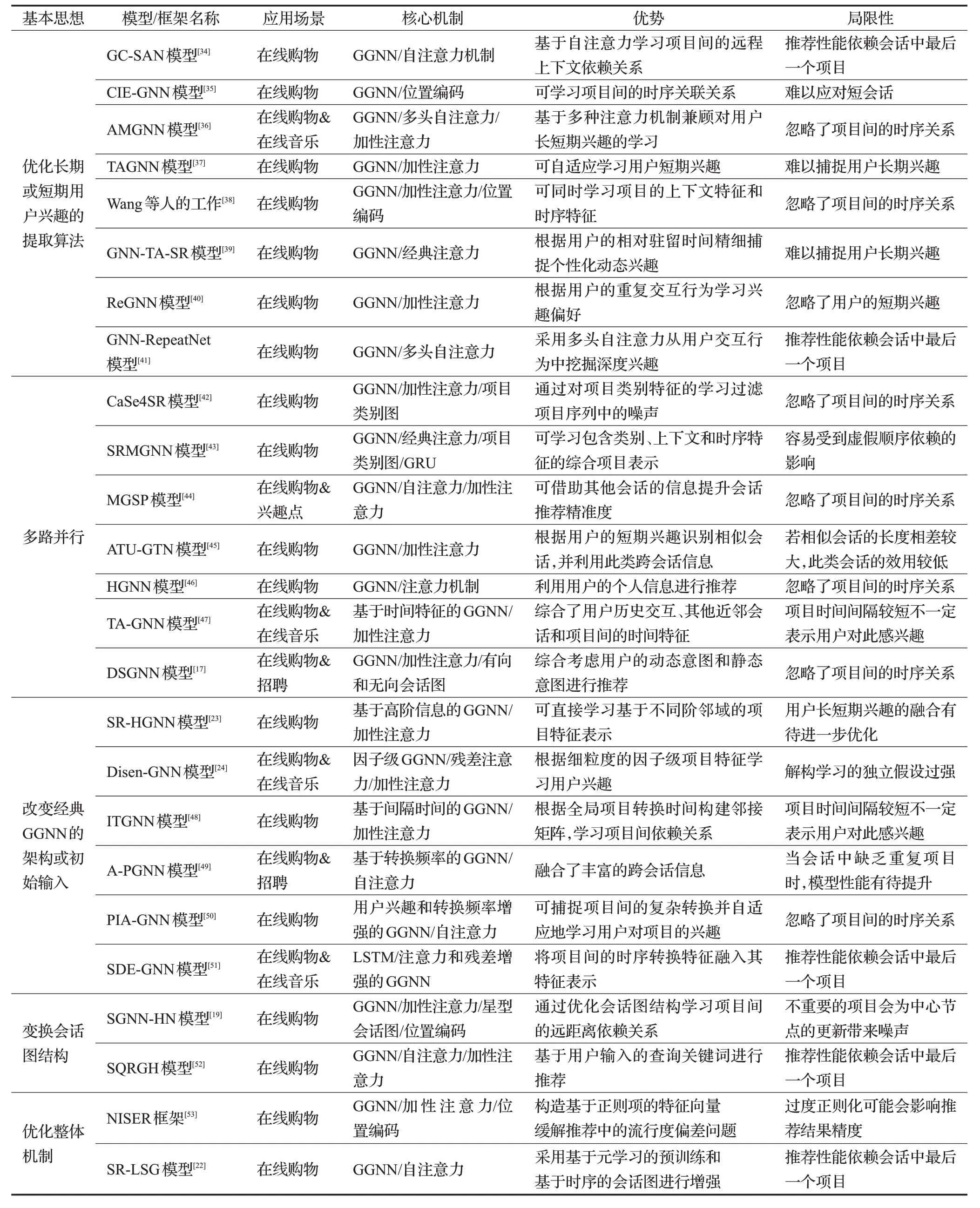
表2 基于SR-GNN的優化方式及代表模型Table 2 Each optimization mode with corresponding representative models based on SR-GNN
由于GGNN需要在所有節點上多次計算遞歸函數,即需要存儲所有節點的隱狀態,故該方法對內存的需求較大,因此將GGNN應用于多個節點和多條邊的大型圖上時,可能會導致性能變差。其次,經典的GGNN在節點間進行消息傳遞的過程中,僅使用不同時間步下的狀態隱向量,這有可能會導致梯度消失和底層信息丟失的問題;并且它沒有對目標節點的各近鄰節點進行權重分配,因此可能會在更新節點表示的過程中受到噪聲數據的干擾。雖然部分學者提出了相應的方法進行優化[22,53],但是從實驗結果來看,模型性能仍然有待提高。
在實踐方面,基于GGNN的會話推薦系統可有效完成不同場景下的精準推薦任務,相關工作涵蓋了在線購物、在線音樂、招聘求職等多個場景。在電商購物推薦任務中,TAGNN模型[37]在電商數據集Yoochoose 1/64上的點擊率Top-20預測任務中,精準度高達71.02%;在音樂推薦任務中,TA-GNN模型[47]和SDE-GNN模型[51]分別在Nowplaying數據集的Top-20推薦任務中取得了15.74%和19.01%的召回率和精準率;在招聘求職推薦任務中,A-PGNN模型[49]和DSGNN模型[17]分別在Xing數據集的Top-10推薦任務中取得了17.06%和24.48%的召回率和命中率。彰顯了GGNN在會話推薦中的強大特征提取能力。
3.3 基于GAT架構的會話推薦系統
GAT認為不同近鄰節點對目標節點的影響不同,因此基于多種注意力機制為各近鄰節點分配權重,以衡量其對目標節點的不同影響程度,并通過聚合函數動態更新每個節點的表示向量。值得注意的是,GCN為目標節點的近鄰節點分配的權重是根據圖結構預先確定的;而GAT為目標節點的近鄰節點分配的權重,是根據消息傳播算法計算不同時間步下的節點隱狀態,并由此動態更新得到的,如圖8所示。因此,相比于GCN靜態的參數化權重,GAT動態的可學習權重更為靈活,也更能精準捕獲到會話圖中的復雜交互信息。
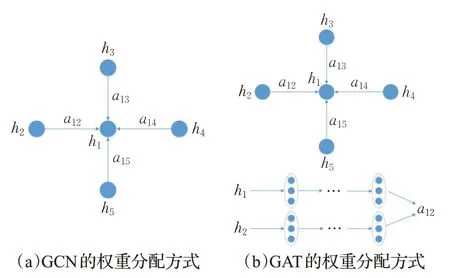
圖8 GCN與GAT的權重分配方式區別Fig.8 Difference in weighting between GCN and GAT
基于GAT的會話推薦系統通過計算目標節點和各近鄰節點間的注意力權重區分不同近鄰節點的重要程度,并通過多種加權聚合方式更新目標節點向量,如公式(4)、(5)所示:
其中,αij為目標節點i與其近鄰節點j的注意力權重,f(·)可為多種注意力得分計算函數,如點積、加性注意力等。N(i)為目標節點i的近鄰節點集合,為目標節點i在第l層的特征向量。ξ(·)和δ(·)為提高模型擬合能力的線性或非線性變換函數。
考慮到RNN有助于學習項目間的時序關聯關系,部分學者采用長短期記憶網絡(long-short term networks,LSTM)對模型進行增強。Song等人[10]提出的DGRec模型首先使用LSTM捕捉目標用戶及其朋友在各自會話中的動態興趣,然后結合用戶的社交網絡探索其朋友的喜好對該用戶的影響。DYAGNN模型[54]首先構造以項目為節點的有向加權圖,然后通過堆疊多層的GAT計算各邊權重和節點向量,并通過LSTM進一步捕捉項目間的時序關系。
多路并行的模型架構有助于從多個角度聯合捕捉用戶興趣,其中MSGIFSR模型[55]以不同長度的子會話為節點、以子會話間的聯系為邊建立有向加權的多粒度異構會話圖,并使用基于多頭注意力的雙向GAT學習各粒度下不同子會話單元的表示。SHARE模型[56]也采用了類似于MSGIFSR模型的并行GAT思想,其不同之處在于該模型基于超圖分別學習節點到超邊和超邊到節點的信息傳播,并通過疊加多層GAT學習包含豐富上下文信息的項目表示來精確反映會話中的用戶意圖。
為了更加直觀地對相關模型框架進行比較,表3整理了部分具有代表性的GAT會話推薦系統。經分析,大多數相關工作在計算節點間的注意力時,主要采用加性注意力機制計算注意力分數,然后基于Soft max函數進行歸一化處理,部分工作[10,56]使用基于內積的算法計算注意力分數。在聚合近鄰節點特征時,部分工作采用普通加權和的方式[10,59],一些工作[55,57]引入了可學習參數矩陣增強模型的學習能力,還有不少工作[54,58,60-62]在此基礎上引入了激活函數,以提高模型的非線性擬合能力。總的來說,基于GAT的會話推薦系統相關工作相對較少,還存在著較大的研究空間。
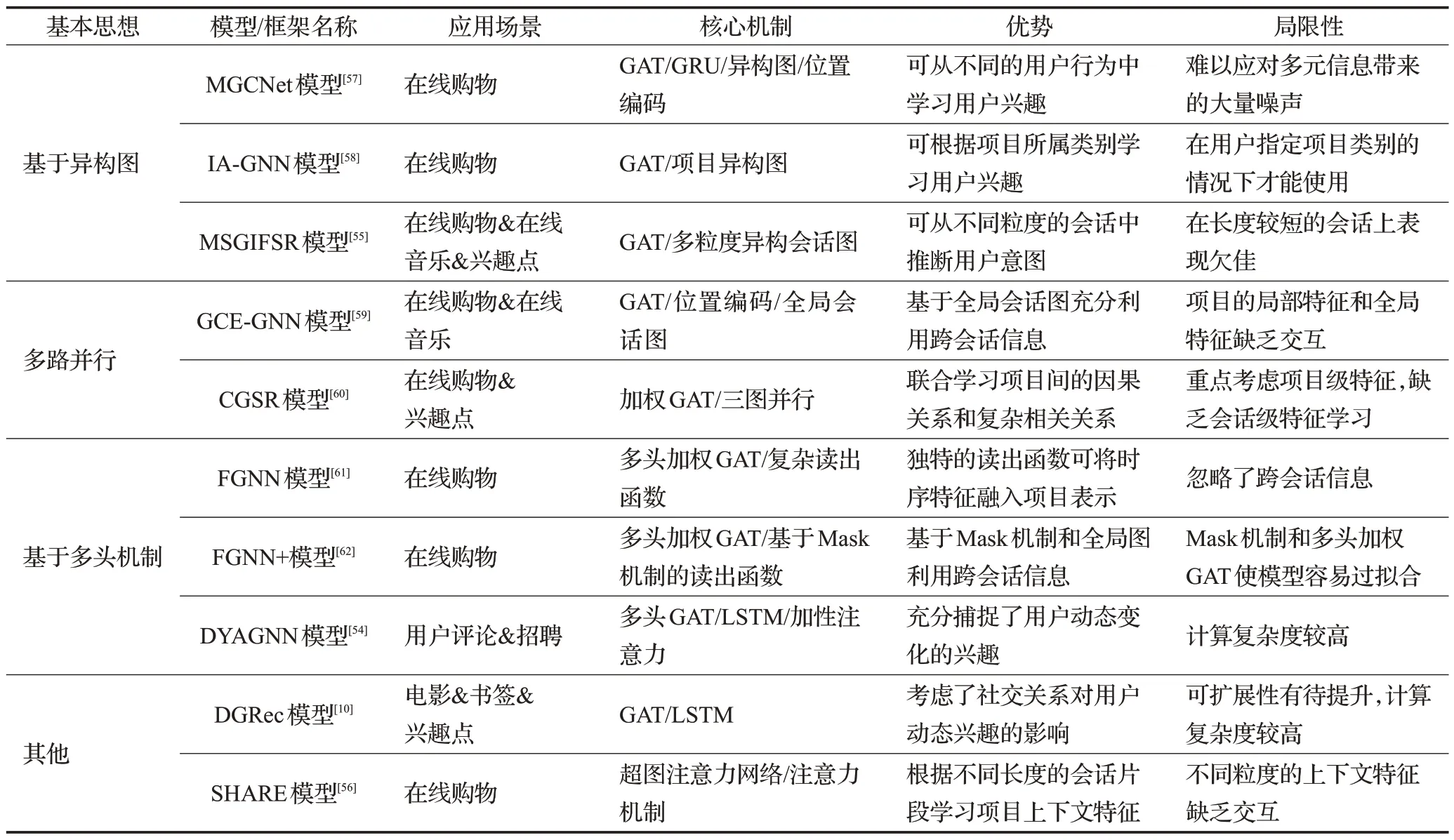
表3 基于GAT架構的會話推薦系統分類Table 3 Classification of session recommendation system based on GAT architecture
注意力機制的強大去噪能力使得基于GAT的會話推薦系統得以從包含多元信息的異構圖中挖掘用戶興趣,多頭機制更是提升了此類推薦系統的特征提取能力,從而使模型能夠更為精準地推斷用戶偏好。GAT雖然能通過分配注意力權重的方式,區分鄰域節點的相對重要性,但是由于忽略了圖中的結構信息,其在聚合多跳范圍內的鄰域信息時,很容易出現嚴重的過度平滑問題[63]。此外,GAT對參數的初始化策略十分敏感,模型的性能波動較大[64]。因此,在使用GAT時仍然需要結合一些相應措施來緩解可能出現的性能問題,例如應用更加穩健的參數初始化策略,或嘗試NISER框架[53]和SRLSG模型[22]中的優化策略。
在實踐方面,基于GAT的會話推薦系統仍以在線購物為主,同時涉足更為廣泛,除了音樂、興趣點和招聘推薦之外,還涵蓋電影、書簽等娛樂場景下的推薦。由于GAT本身可基于注意力機制對鄰域信息分配權重,因此具有更為強大的去噪能力和特征提取能力。例如MGCNet模型[57]在電商數據集Yoochoose 1/64上的購買率Top-20預測任務中,召回率達到了驚人的92.38%;在音樂推薦任務中,GCE-GNN模型[59]在Nowplaying數據集的Top-20推薦任務中取得22.37%的精準率。刷新了基于GCN和GGNN的會話推薦系統的相應最高記錄。
3.4 基于其他GNN架構的會話推薦系統
正如前文所述,雖然GCN、GGNN和GAT的性能強大,但是也各有不足之處。因此,部分學者提出了基于混合機制的GNN會話推薦系統,并結合多種注意力機制、位置編碼或殘差學習等技術進行更為精準的推薦。此外,不少學者通過在原有結構的基礎上融入新元素或替換的方式進行優化,也在一定程度上提升了模型性能。
根據各工作的實驗結論,將注意力機制與GGNN相結合有助于增強模型對噪聲數據的過濾能力,從而更加精準地學習項目特征表示。PA-GGAN模型[65]、TPA-GNN模型[18]、NA-GNN模型[66]和LESSR模型[21]均將注意力機制與GGNN相結合,其區別在于NA-GNN模型先通過GGNN獲得項目節點的初步表示,再通過自注意力機制進一步更新節點向量;TPA-GNN模型先通過多頭注意力機制更新邊權重,再通過GGNN更新項目表示向量;而PA-GGAN模型先通過注意力機制為各項目分配向量,然后通過GGNN獲得節點向量初步表示,再通過多頭機制增強注意力機制,并使用殘差學習和MLP防止模型在學習過程中丟失底層信息和增強模型的非線性擬合能力;LESSR模型使用GGNN與GAT形成交叉堆疊的結構交替進行節點信息和邊權重的更新。然而,相關工作大多僅對項目的上下文近鄰特征進行了較為充分的學習,不同程度上地忽略了項目間重要的時序特征關系。
引入豐富的邊信息開可有效提升會話推薦系統的推薦精度,將這些邊信息融入異構圖更是有助于學習到多種交互下的項目特征。SE-Frame框架[14]將用戶的社交關系加入會話推薦任務中,并以簡單線性方式分別根據用戶間的聯系與用戶和項目間的交互計算用戶節點的社會影響和用戶偏好,然后使用注意力機制分別融合兩種信息。而HG-GNN模型[67]則采用均值池化與MLP結合的方式從基于包含用戶節點與項目節點的異構全局會話圖中學習多種類型的邊權重,然后使用門控機制聚合經過加性注意力機制分別學習到的用戶長短期偏好。然而,邊信息的引入也帶來了更多的噪聲,如何設計有效的去噪機制,是此類會話推薦系統面臨的重大挑戰之一。此外,多樣化的信息來源也導致推薦結果的可解釋性更差。目前,元學習和基于邊信息的注意力機制是應對此類挑戰的有效方式,通過學習元路徑和為不同的項目屬性分配權重,可更加精準地推斷用戶意圖,同時具備了良好的可解釋性。
受到變分推理的啟發,一些學者將該思想與會話推薦相融合,將用戶興趣視為復雜的分布函數,并采用自動編碼器進行學習。例如HybridGNN-SR模型[68]將變分推理的思想融入GNN,并結合無監督和有監督的圖學習來學習會話中的項目轉換關系。該工作所采用的方式在一定程度上解決了有監督學習方法忽略圖結構信息和無監督方法忽略用戶偏好的問題,使得推薦結果更為精準全面。然而,用戶的真實興趣不僅復雜,而且多變,變分推理難以在無法獲取足夠多用戶交互歷史的情況下,捕捉到動態變化的用戶興趣。因此,此類思想更適合于根據用戶的長期行為推斷其意圖的推薦場景。
雖然GRU4Rec模型奠定了GRU在會話推薦領域的地位,不少學者仍然嘗試基于LSTM進行會話推薦。SR-MNN模型[69]在聚合項目節點向量的過程中,首次采用基于LSTM的GNN學習目標節點及其近鄰的信息,隨后使用GRU捕捉會話中的項目時序關系。此外,該模型還將目標會話中首個交互項目加入會話向量表示中,以捕捉用戶初始興趣對整個會話興趣的影響。SR-HetGNN模型[15]則更進一步根據用戶節點、會話節點與項目節點形成了復雜的異質圖,然后采用DeepWalk算法[70]和Word2Vec算法[71]學習各類型節點的初始化向量,并通過基于重啟的隨機游走與雙向LSTM獲得包含多元信息的項目表示。雖然根據相關工作的實驗報告,此類會話推薦系統取得了較高的推薦精度。然而,模型的復雜度會隨著數據體量的增加而快速提升,此類模型的可擴展性還有待優化。
綜上所述,基于混合架構GNN的會話推薦系統大多仍圍繞GGNN展開。值得注意的是,GGNN和GRU的公式除了輸入信息有所差異,其他部分基本一致。因此,基于GGNN的會話推薦系統也可以仿照此前基于RNN的會話推薦系統的相關工作,將不同類型的注意力加入門控機制中,形成門控注意力圖神經網絡。在實踐方面,相關工作仍然可以有效應對不同場景下的精準推薦任務,同樣以在線購物推薦為主,以音樂推薦、興趣點推薦為輔,此外還有其他娛樂場景下的推薦應用。部分工作在興趣點推薦任務上的表現較為出色,例如,LESSR模型[21]在Gowalla數據集的Top-20推薦任務中,取得了51.34%的召回率;基于SE-Frame框架[14]實例化的SE-Rec模型,在FourSquare數據集的Top-20推薦任務中,取得了70.05%的召回率。
由于混合模型引入了多種神經網絡,如何設計整體模型框架,實現各模塊間良好的統籌協調,成為此類模型需要應對的重大挑戰。此外,模型整體深度和寬度的增加也會導致待訓練參數量快速增長,如何在控制參數量的同時,提升推薦的準確度,值得未來進一步研究。
4 現有工作中的實驗設計綜述
本章將依據各基于GNN的會話推薦工作的實驗部分進行分析,由于損失函數、數據集和性能評估指標的選取對模型性能影響較大,因此重點關注了各工作中的相應信息。為了更加直觀地展示出損失函數、所選取的數據集和模型性能指標的使用情況,現將統計結果進行展示,如表4所示。
根據表4(a)的統計結果,大多數基于GNN的會話推薦系統使用了帶交叉熵的損失函數,即模型的學習目標是最小化模型學習到的數據分布與真實數據分布的差異。相比于復雜形式的損失函數,交叉熵損失函數可以大幅提升模型在訓練過程中的權重矩陣更新速度,使損失值快速收斂,有助于縮短訓練時長。然而,當面臨帶有噪聲標簽的樣本時,即用戶并非對會話中的每個項目都感興趣時,使用交叉熵損失函數進行訓練很可能會帶來嚴重的過擬合問題。此外,在點擊率預測或購買預測任務中(即多分類問題),大多數基于GNN的會話推薦模型會使用Softmax函數進行處理,然而這種處理方式會使模型重點關注預測的準確度,而忽略了其他非正確預測結果間的差異。因此,如何通過優化正則項、提高數據質量等方式緩解訓練過程中的過擬合,或是通過修改非線性函數的方式提升軟分類精度,亦或是通過對比學習、蒸餾學習、強化學習等方式提升模型訓練的效率,仍然值得進一步探索。
根據表4(b)的統計結果,大多數基于GNN的會話推薦系統在實驗部分使用了電商類數據集,其中使用次數最高的Yoochoose數據集和Diginetica數據集均為會話推薦領域的基準數據集。雖然兩個數據集提供了會話標注字段,避免了人為切分會話降低數據質量,但是并未提供更為豐富的用戶信息和交互信息。此前的文獻綜述已經表明,合理引入豐富多元的邊信息,有利于提升推薦結果質量。因此,未來的研究可以嘗試在包含多樣化信息的數據集上進行實驗。
根據表4(c)的統計結果,大多數基于GNN的會話推薦系統使用了平均倒數排序(mean reciprocal rank,MRR)和準確度(precision)指標,命中率(hit rate,HR)、召回率(recall)和標準化折現累積增益(normalized discounted cumulative gain,NDCG)也均反映了推薦結果的精準度。雖然精準度是衡量推薦結果質量的重要指標,但并非唯一指標,未來的研究還應適當關注推薦結果的新穎度、驚喜度等,可引入DIV@K[72]、POP@K、EILD-RR@K[13]、ESI-RR@K[13]等指標對模型性能進行評測。
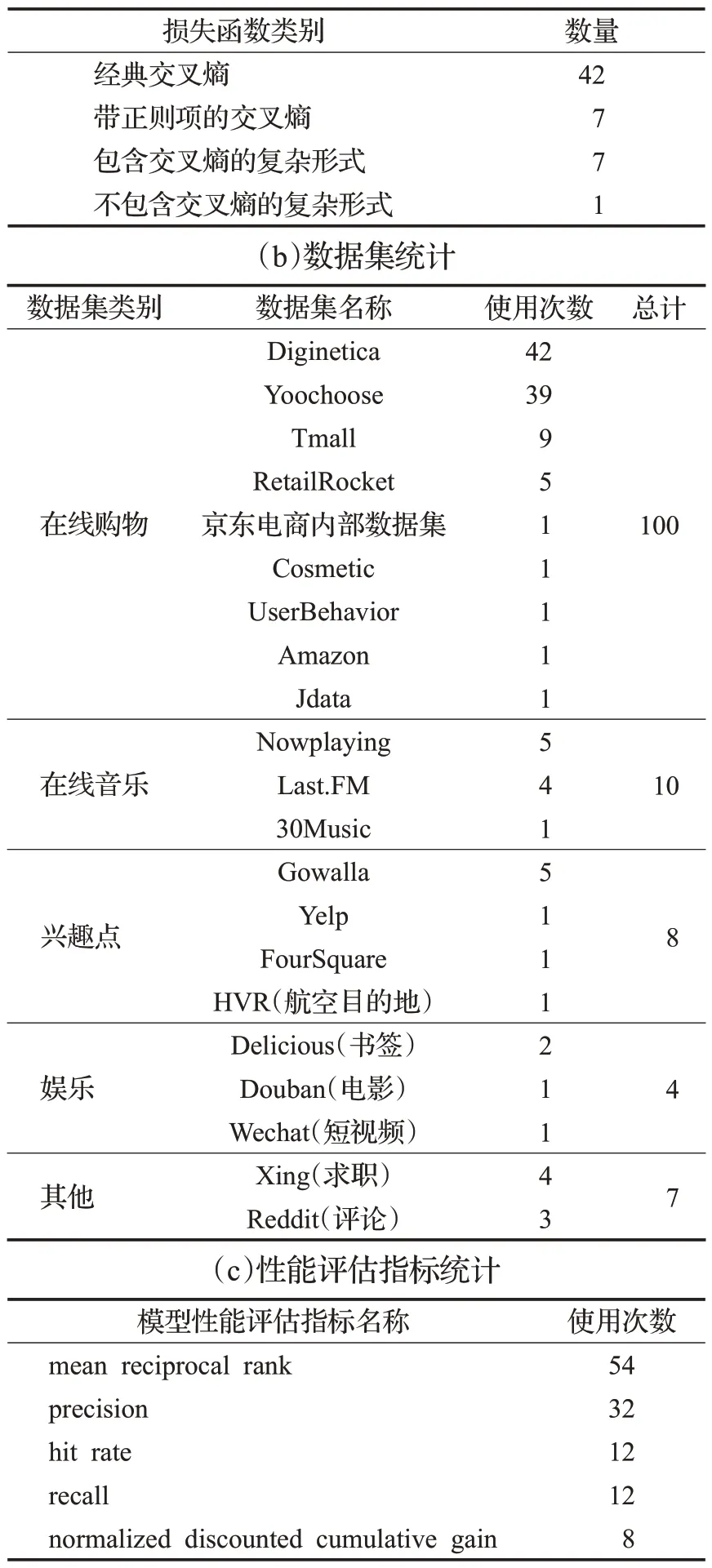
表4 損失函數、數據集和評估指標統計Table 4 Statistics of loss functions,datasets and metrics(a)損失函數類別統計
總的來說,大部分基于GNN的會話推薦工作面向電商購物場景,并將推薦任務視為多分類任務,更關注推薦結果的精準性。
5 討論與未來工作展望
5.1 討論
根據前文對基于GNN的會話推薦系統相關工作的評述,為了應對精準會話推薦的挑戰,各工作主要從學習項目間的時序特征、引入豐富多元的邊信息、創新GNN算法、優化模型訓練方式四個角度進行了突破,如表5所示。下面將對不同角度下的相關工作進行綜合討論分析。

表5 應對精準會話推薦的策略分析Table 5 Analysis of strategies to deal with accurate session recommendation
5.1.1 學習項目間的時序特征
具有開創性的SR-GNN式經典構圖提供了一種樸素的數據結構轉換思路,使GNN能間接處理序列式的原始會話信息。然而,這種構圖方法存在一定局限,例如丟失了項目間的順序轉換信息和忽略鏈接屬性。
雖然部分研究工作[20,27-28,51,56]意識到了時序特征的重要性,并從多個角度出發進行創新,但各方法仍存在不足之處。將時序信息作為鏈接屬性加入會話圖可以在一定程度上保留原始時序信息,然而此類信息難以隨模型訓練而優化。因為項目間的原始順次轉換信息是客觀信息,不應當隨模型的訓練而更改。此外,現有的研究工作大多采用單路串行的方式設計模型,其本質是偏重時序信息或上下文信息,難以做到兩種信息的動態平衡。
5.1.2 引入多元的邊信息
經典的會話推薦任務僅基于匿名用戶和項目的交互記錄進行推薦,然而此類數據的信息量有限,推薦性能的理論上限較低。受到知識圖譜相關研究的啟發,不少學者嘗試將更加多元的邊信息作為補充數據引入會話推薦任務中,大幅提升了會話推薦系統的精準推薦能力。總的來說,相關工作可根據信息來源渠道,分為基于用戶側邊信息的會話推薦系統[25,40,57]和基于項目側邊信息的會話推薦系統[42,58,73]。一些工作同時考慮到了用戶側和項目側的豐富的邊信息[16]。這些邊信息增強的會話推薦系統極大地提升了推薦精準度,是相關領域具有較大研究潛力的方向之一。值得注意的是,引入更多信息的同時也會帶來更多的噪聲。因此,可以采用多種形式的注意力機制進行去噪處理,以緩解噪聲信息對推薦性能的影響。
5.1.3 優化模型結構或輸入
優化模型結構最為明顯的特征是嘗試使用不同種類的神經網絡,或基于相應經典結構進行優化,提高模型的推薦精準度。由于GCN和GGNN模型難以處理隱藏在各種圖中的噪聲信息,因此部分學者嘗試在GNN前后引入注意力機制進行去噪[9,34]。一些工作還采取多路并行的方式,從不同角度推斷用戶意圖[59-60]。
采用多路并行的架構雖然有效,但是很容易導致模型的參數量增大,導致模型的訓練時間大幅延長。因此,一些學者從提高模型輸入質量的角度入手,將多種信息與項目的初始嵌入編碼相結合,從源頭提升特征編碼的質量[23,49]。提高模型輸入質量的另一個角度是對原始會話圖進行優化[19,24]。優化模型輸入有助于GNN從不同角度學習隱藏在會話中的用戶興趣,但是這種方式的擴展性較差,當需要從多個角度聯合推斷用戶偏好時,容易由于噪聲過多而難以提升推薦結果的精準度。
5.1.4 優化模型訓練方式
大多數基于GNN的會話推薦系統將推薦視為有監督的學習,其本質是假設訓練集包含了所有項目。然而在實際應用場景中,新項目會源源不斷地加入,導致基于監督學習的GNN會話推薦系統性能不佳。為此,一些學者試圖基于自監督學習訓練模型[20]。大多此類模型假設用戶在會話中具有直接單一的興趣,因此不同角度下學習到的用戶特征應當相同。然而,部分工作[74]證實用戶在會話中的偏好可能復雜多變,因此僅基于無監督學習的相關模型在短會話上具有較好的性能,而難以從長會話中挖掘出用戶的真實興趣。
無論是有監督學習還是自監督學習,都存在一定缺陷。基于有監督學習的相關模型難以有效應對真實應用場景下不斷涌現的新項目,而基于自監督學習的相關模型往往無法收集到足夠多的自監督信號。HybridGNN-SR模型[68]提供了一種應對方式,即將無監督和有監督的圖學習相結合。此類方法在一定程度上解決了有監督學習忽略圖結構信息和無監督學習忽略用戶復雜偏好的問題,使得推薦結果更為精準全面。
5.2 未來工作展望
基于前文從多個角度對GNN會話推薦系統相關工作的評述與分析,對該領域未來的工作進行展望。
5.2.1 注重模型的可解釋性
基于GNN的會話推薦系統的可解釋性仍然欠佳,這可能是由于隱式反饋難以收集并高度抽象。然而,良好的解釋有助于增強用戶對推薦系統的信任,這樣用戶更有可能接受來自系統的推薦。目前,已經有學者通過一些方式提升模型的可解釋性[60],相信這也是研究潛力較大的一個方向。
5.2.2 發掘用戶的個性化交互行為
由于基于GNN的推薦系統可有效學習項目間的近鄰上下文特征,因此理論上應當在捕捉用戶的重復交互、周期性交互等特殊信息方面有更為明顯的優勢。基于RNN和注意力機制的RepeatNet模型[75]與基于異構超圖注意網絡的MSGIFSR模型[55]已經證明,捕捉用戶的重復交互行為有助于提升會話推薦的精準度。因此,從用戶的特殊交互行為中學習其興趣偏好是值得探索的方向之一。
5.2.3 重視會話數據的質量
由于目前的數據集大多沒有明確劃分會話,因此只能根據時間戳信息,并基于硬性規則進行會話劃分。然而,都是人為設定的會話切分方式難免有所偏差。在未來的研究工作中,可以嘗試聯合多種方式切分會話,或根據用戶個人信息和歷史交互數據分布,使用自適應的方式以獲得更為精準的會話序列。同時,應當鼓勵研究人員在考慮豐富項目屬性和用戶信息的基礎上,收集攜帶會話標識的數據集,以支撐相關領域的后續研究。
6 結束語
目前GNN已經成為各領域的研究熱點之一,在過去的五年里,會話推薦領域涌現出不少重要的相關工作。因此,本文從推薦因素分析出發,重點從算法原理與性能分析兩方面對數十篇基于GNN的會話推薦相關工作展開評述,旨在總結學者們在各方面所做出的貢獻。最后,根據前文對相關工作的分類評述對比,提出了對未來研究的展望。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
