基于機(jī)器學(xué)習(xí)的分子動(dòng)力軌跡預(yù)測(cè)
2023-03-13 15:24:10焦嘉
信息記錄材料 2023年1期
關(guān)鍵詞:結(jié)構(gòu)模型
焦 嘉
(湖南信息職業(yè)技術(shù)學(xué)院 湖南 長(zhǎng)沙 410203)
0 引言
分子動(dòng)力模擬是一種計(jì)算分子和原子在相空間模擬運(yùn)動(dòng)的軌跡的計(jì)算機(jī)模擬方法。該方法主要利用計(jì)算機(jī)來(lái)計(jì)算模擬分子和原子在某段時(shí)間內(nèi)運(yùn)動(dòng)結(jié)構(gòu)變化[1],目前分子動(dòng)力模擬發(fā)展已經(jīng)比較成熟,能研究具有不同內(nèi)部自由度的多原子分子、單原子分子,現(xiàn)在也已經(jīng)成功運(yùn)用在研究蛋白質(zhì)、DNA等生物大分子的研究中[2-3]。當(dāng)在各種條件下發(fā)生構(gòu)象變化時(shí),蛋白質(zhì)構(gòu)象在影響其功能中起著重要作用。分子動(dòng)力學(xué)(molecular dynamics,MD)軌跡模擬可以提供蛋白質(zhì)運(yùn)動(dòng)的結(jié)構(gòu)數(shù)據(jù),這在蛋白質(zhì)功能中起著非常重要的作用。
現(xiàn)在比較流行的研究分子動(dòng)力結(jié)構(gòu)預(yù)測(cè)的方法是主成分分析(principal component analysis,PCA),在預(yù)測(cè)蛋白質(zhì)結(jié)構(gòu)中的用途,從而將前兩個(gè)(最高)主成分(PC)的線性組合用于生成新結(jié)構(gòu)。與自動(dòng)編碼器相比,對(duì)于更剛性的蛋白質(zhì),它的性能很好,但對(duì)于更柔性的蛋白質(zhì),效果不佳[4-6]。本文提出的方法主要就是解決對(duì)于柔性蛋白質(zhì)的預(yù)測(cè)問(wèn)題。
1 分子動(dòng)力模擬結(jié)構(gòu)的分類
本次實(shí)驗(yàn)采用可視化分子動(dòng)力學(xué)(visual molecular dynamics,VMD)軟件[7],該軟件能可視化呈現(xiàn)蛋白質(zhì)的結(jié)構(gòu)以及對(duì)不同軌跡的模擬分析。VMD顯示兩個(gè)軌跡圖像的總體視圖(見(jiàn)圖1),為了顯示構(gòu)象差異,還繪制了兩個(gè)獨(dú)立軌跡的RMSD圖。
在圖1可視化了3D空間中的所有原子點(diǎn)后,根據(jù)繪制數(shù)據(jù)集在空間中的分布大致了解目標(biāo)數(shù)據(jù)集的分布情況,確定數(shù)據(jù)集的分布,并根據(jù)數(shù)據(jù)的特征選擇合適的SVM分類器模型。
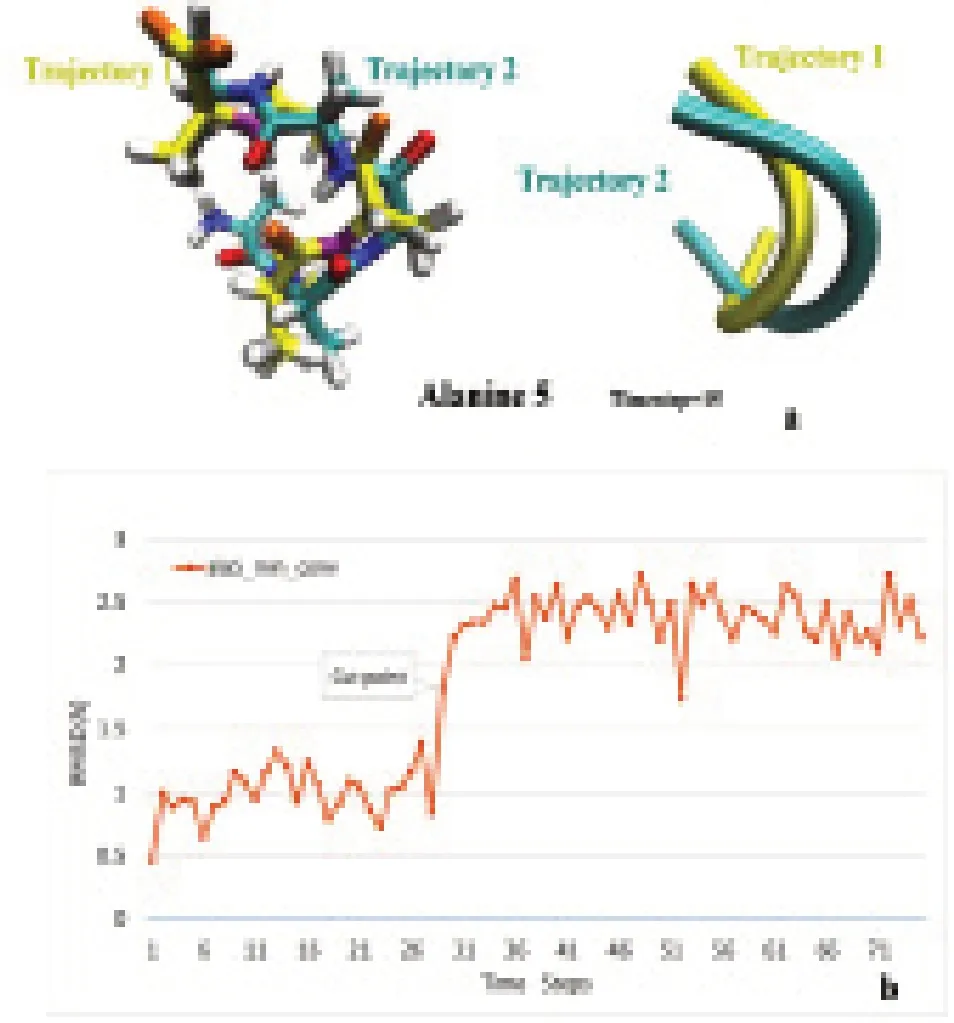
圖1 丙氨酸5的不同結(jié)構(gòu)可視化示意圖和RMSD示意圖
2 分子動(dòng)力模擬結(jié)構(gòu)的異常檢測(cè)
2.1 一類支持向量機(jī)
在異常檢測(cè)的任務(wù)中,比較常用的就是一類支持向量機(jī)(one class support vector machine)[8-9],這個(gè)算法的原理就是把所有的訓(xùn)練數(shù)據(jù)訓(xùn)練出一個(gè)最小的超球面,這個(gè)超球面就盡量把所有訓(xùn)練數(shù)據(jù)都“包”起來(lái),當(dāng)識(shí)別新的點(diǎn)的時(shí)候,如果落在超球面上,那么就是屬于這個(gè)類,反之則不是屬于這個(gè)類別。選擇One Class SVM(sklearn中的函數(shù))的默認(rèn)值RBF內(nèi)核,以及gamma和nu超參數(shù)的默認(rèn)值。另外,在這個(gè)實(shí)驗(yàn)中,使用了Grid Search[10]來(lái)找到該模型的最佳參數(shù)對(duì),并通過(guò)使用最佳組合超參數(shù)執(zhí)行一類支持向量機(jī)的算法。圖2是一類支持向量機(jī)的原理圖,圖中黑點(diǎn)表示數(shù)據(jù)集,可以看到a、b兩個(gè)點(diǎn)離超球面的距離非常遠(yuǎn),所以這個(gè)算法把這兩個(gè)點(diǎn)視為異常點(diǎn)。

圖2 一類支持向量機(jī)原理示意圖
2.2 孤立森林
我們使用了另一種異常檢測(cè)方法來(lái)區(qū)分構(gòu)象采樣中的差異——使用網(wǎng)格搜索通過(guò)準(zhǔn)確性分?jǐn)?shù)來(lái)搜索孤立森林(isolation forest)[11]的最佳組合。為了通過(guò)操縱isolation forest找出對(duì)性能的不同影響,還對(duì)每個(gè)超參數(shù)使用所有默認(rèn)值對(duì)其進(jìn)行訓(xùn)練,并獲得在RMSD圖中顯示負(fù)點(diǎn)的結(jié)果。值得注意的是,將自動(dòng)設(shè)置為污染時(shí),參數(shù)行為不能“過(guò)時(shí)”。因此,將行為從“舊”更改為“新”。最重要的超參數(shù)是基本估計(jì)量、樣本數(shù)量和從該數(shù)據(jù)集中提取的特征,以及訓(xùn)練模型中的估計(jì)量。就最大樣本數(shù)而言,為估計(jì)量和特征數(shù)設(shè)置了默認(rèn)值,并從50、100、300到500中選擇了最大樣本數(shù)的值來(lái)訓(xùn)練該模型。
2.3 離群點(diǎn)檢測(cè)法
離群點(diǎn)檢測(cè)法(local outlier factor, LOF)是一種基于距離的異常點(diǎn)檢測(cè)的算法,這個(gè)算法的主要思想是通過(guò)目標(biāo)點(diǎn)T和其每個(gè)領(lǐng)域的點(diǎn)的密度來(lái)判斷被檢測(cè)點(diǎn)是否屬于異常,點(diǎn)T的密度越低就越可能被檢測(cè)成是異常點(diǎn)。這里的密度,指的是通過(guò)點(diǎn)之間的距離來(lái)計(jì)算的數(shù)值,樣本中點(diǎn)之間距離越遠(yuǎn),密度越低,距離越近,密度越高。同時(shí)因?yàn)長(zhǎng)OF對(duì)密度的計(jì)算是通過(guò)點(diǎn)的第k鄰域來(lái)計(jì)算,而不是需要通過(guò)全局掃描式的計(jì)算,避免了時(shí)間復(fù)雜度很高的情況,這也是為什么叫“局部”異常因子算法的原因。下面是局部可達(dá)密度(local reachability density)的公式:
在公式(1)中,比值越接近1,說(shuō)明p和周圍的點(diǎn)密度差不多,所以p可能是和周圍的點(diǎn)是同類。另外,如果比值小于1,則說(shuō)明p是密集點(diǎn),p大于1的話,說(shuō)明p就是異常點(diǎn)。在異常檢測(cè)中,直接利用集成好的離群點(diǎn)檢測(cè)法算法在訓(xùn)練集上,來(lái)對(duì)比前兩種算法的效果,最后得出對(duì)于該實(shí)驗(yàn)最優(yōu)的異常檢測(cè)算法。
3 分子動(dòng)力模擬結(jié)構(gòu)預(yù)測(cè)
3.1 改編的自編碼模型
這次實(shí)驗(yàn)中,為了預(yù)測(cè)僅給出二維點(diǎn)的高維結(jié)構(gòu),我們提出了一種符合當(dāng)前數(shù)據(jù)情況的編碼器模型,該編碼器模型通過(guò)輸入高維的坐標(biāo)變量({x1,x2,x3…,xn}),轉(zhuǎn)化成二維的隱變量Z(恰好和輸入數(shù)據(jù)一樣的維度),然后再利用產(chǎn)生的二維擴(kuò)展為高維的結(jié)構(gòu)坐標(biāo)作為解碼器(1,2,3。可以計(jì)算x和之間的誤差,通過(guò)控制兩編碼器和解碼器輸出的結(jié)果之間的誤差來(lái)訓(xùn)練數(shù)據(jù)模型:
通過(guò)優(yōu)化公式(2),最初訓(xùn)練了一種具有較小誤差(損失)的改進(jìn)型自動(dòng)編碼器。完善的自動(dòng)編碼器的損失函數(shù)的設(shè)計(jì)如圖3所示。其中x是輸入向量,x︿是輸出向量,盡量地使其與x非常相似,而z是隱向量,z'是新的隱向量對(duì),這些參數(shù)通過(guò)最小化神經(jīng)網(wǎng)絡(luò)中的值來(lái)訓(xùn)練。

圖3 改編的自編碼器結(jié)構(gòu)示意圖
改編的自動(dòng)編碼器的思想來(lái)自另一個(gè)改編的自動(dòng)編碼器,它是變分自動(dòng)編碼器(VAE)[12-13],這是基于自動(dòng)編碼器開(kāi)發(fā)的神經(jīng)網(wǎng)絡(luò)的另一種結(jié)構(gòu)。它們之間的主要區(qū)別是損失函數(shù),VAE使用Kullback-Leibler散度訓(xùn)練了模型,從而最大限度地減少了編碼器分布和解碼器分布之間的損失。總的來(lái)說(shuō),這是一種有效的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),該結(jié)構(gòu)以自我監(jiān)督的方式進(jìn)行訓(xùn)練,可通過(guò)輸入大量結(jié)構(gòu)坐標(biāo)來(lái)近似重建幾何結(jié)構(gòu)。另外,解碼器部分參考給定新的PC向量組(主要成分)的情況下產(chǎn)生新的預(yù)測(cè)結(jié)構(gòu)的預(yù)測(cè)模型。通過(guò)查閱文獻(xiàn),沒(méi)有論文研究過(guò)這種類型的自動(dòng)編碼器,因此這是一種在傳統(tǒng)自動(dòng)編碼器的基礎(chǔ)上進(jìn)行修改的全新自動(dòng)編碼器。
對(duì)于預(yù)測(cè),我們就可以只利用經(jīng)過(guò)訓(xùn)練的自動(dòng)編碼器中的解碼器部分,可以通過(guò)訓(xùn)練相似的分布數(shù)據(jù)集(稱為生成模型)來(lái)泛化該模型,因此解碼器的輸出是針對(duì)不同數(shù)據(jù)的預(yù)測(cè)結(jié)果,但是這些數(shù)據(jù)都具有類似的分布和格式。對(duì)于任何潛在分布的采樣(PC對(duì)),預(yù)期此解碼器模型可以準(zhǔn)確地重建原始輸入結(jié)構(gòu)。在實(shí)際的實(shí)驗(yàn)中,使用Keras在Python 3.8中構(gòu)建改編的自動(dòng)編碼器,Keras是具有Tensorflow的開(kāi)源深度學(xué)習(xí)庫(kù)。本研究測(cè)試了具有3個(gè)編碼層和3個(gè)解碼層的網(wǎng)絡(luò)。在計(jì)算機(jī)科學(xué)方面,模型的損失反映了神經(jīng)網(wǎng)絡(luò)的性能。 因此,比較了不同網(wǎng)絡(luò)產(chǎn)生的損耗結(jié)果,以評(píng)估結(jié)構(gòu)的性能。圖4是整個(gè)模型的總體思路。
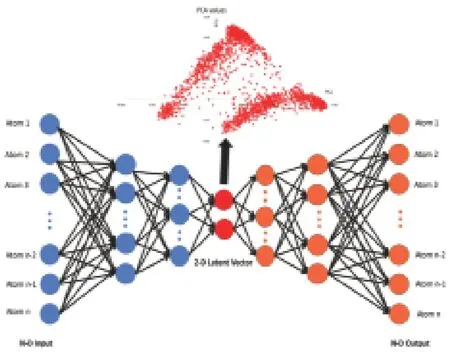
圖4 深度學(xué)習(xí)網(wǎng)絡(luò)訓(xùn)練結(jié)構(gòu)示意圖
3.2 改編的自編碼模型結(jié)果
本文選擇了訓(xùn)練數(shù)據(jù)之外的12個(gè)點(diǎn)作為預(yù)測(cè)數(shù)據(jù),以測(cè)試預(yù)測(cè)的準(zhǔn)確性,為了測(cè)試改進(jìn)的自動(dòng)編碼器的性能和穩(wěn)定性,在預(yù)測(cè)點(diǎn)周圍刪除了類似的結(jié)構(gòu)(x的+/-0.002和y的+/-0.003之內(nèi)的點(diǎn),y與數(shù)據(jù)集中的x相比方差略大)。預(yù)測(cè)12點(diǎn)的每個(gè)點(diǎn)時(shí)的訓(xùn)練數(shù)據(jù)集。例如,排除了正方形區(qū)域內(nèi)的點(diǎn)。當(dāng)預(yù)測(cè)(0,0.02)的結(jié)構(gòu)時(shí),訓(xùn)練數(shù)據(jù)中的{(-0.002,0.02),(0.002,0.02),(0,0.017),(0,0.023)}。在劃分2 000條軌跡時(shí),仍然采用相同的比率(訓(xùn)練數(shù)據(jù)為80%,測(cè)試數(shù)據(jù)為20%),并對(duì)它們進(jìn)行了相同的MinMax歸一化處理。實(shí)驗(yàn)結(jié)果如圖5所示。
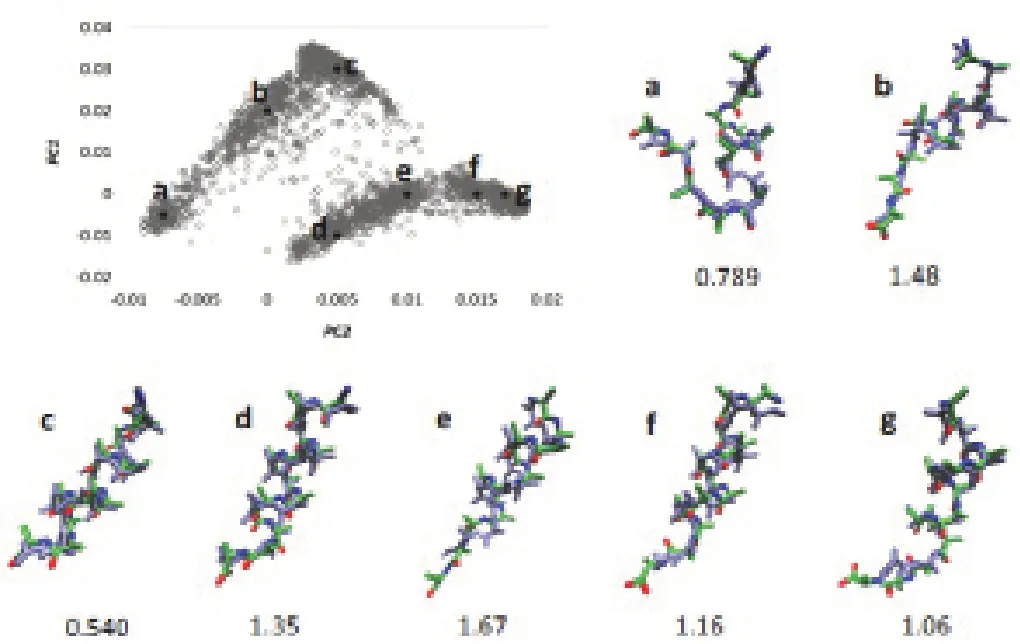
圖5 預(yù)測(cè)結(jié)構(gòu)和真實(shí)結(jié)構(gòu)對(duì)比圖
圖5左上方:代表了2D RMSD矩陣(灰色圓圈)的PC1與PC2圖,點(diǎn)a~g(黑點(diǎn))用于測(cè)試算法。對(duì)于每個(gè)預(yù)測(cè),將(PC1,PC2)值在(+/-0.002,+/-0.003)以內(nèi)的點(diǎn)從訓(xùn)練集中排除。對(duì)于每個(gè)點(diǎn)(a~g),都顯示了具有預(yù)測(cè)結(jié)構(gòu)的原始結(jié)構(gòu)的疊加圖,下面的數(shù)值代表了其RMSD值。
4 結(jié)語(yǔ)
本文通過(guò)計(jì)算機(jī)領(lǐng)域的機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的使用,在分子動(dòng)力模擬領(lǐng)域的一系列探究實(shí)驗(yàn),充分證明了機(jī)器學(xué)習(xí)和深度學(xué)習(xí)在該領(lǐng)域的可行性和可探究性。由于之前很少有人在這個(gè)領(lǐng)域用機(jī)器學(xué)習(xí)的方法來(lái)對(duì)分子運(yùn)動(dòng)軌跡進(jìn)行研究或者預(yù)測(cè),之前的一些研究主要是利用類似于PCA的降維方法來(lái)觀察分子動(dòng)力模擬軌跡的分布,但是并不能很準(zhǔn)確地預(yù)測(cè)出分子結(jié)構(gòu),這些問(wèn)題其實(shí)一直困擾著這個(gè)領(lǐng)域,所以現(xiàn)在用機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的方法來(lái)進(jìn)行這些探究實(shí)驗(yàn)的意義非常重大,為該領(lǐng)域開(kāi)辟了一個(gè)全新的研究視角。本文提出了運(yùn)用機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的方法來(lái)對(duì)分子動(dòng)力模擬領(lǐng)域的原子坐標(biāo)進(jìn)行探究,成功驗(yàn)證了機(jī)器學(xué)習(xí)算法在蛋白質(zhì)軌跡分類的實(shí)驗(yàn)上的有效性,用三種異常檢測(cè)算法對(duì)不同狀態(tài)的蛋白質(zhì)大分子結(jié)構(gòu)進(jìn)行檢測(cè),通過(guò)對(duì)比不同RMSD值的變化,來(lái)判斷具體時(shí)刻的分子結(jié)構(gòu)變化的程度,從而得到“異常”的蛋白質(zhì)分子結(jié)構(gòu),最后提出了一種全新的基于自編碼的神經(jīng)網(wǎng)絡(luò)模型,通過(guò)修改損失函數(shù)的組成來(lái)構(gòu)建適合低維輸入和高維輸出情況的模型。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學(xué)評(píng)論(2021年2期)2021-08-22 01:53:34
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中華詩(shī)詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評(píng)論(2016年0期)2016-11-23 05:26:01
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
現(xiàn)代企業(yè)(2015年9期)2015-02-28 18:56:50
