自然場景文本檢測與端到端識別:深度學習方法
2023-03-10 00:10:32韋勤彬廖俊瑋曾凡智馮文婕劉翔宇周月霞
計算機與生活 2023年3期
周 燕,韋勤彬,廖俊瑋,曾凡智,馮文婕,劉翔宇,周月霞
佛山科學技術學院 計算機系,廣東 佛山528000
文本作為人類智慧的結晶,在文化的傳承中起著不可或缺的作用。文本的出現打破了有聲語言在時間和空間上的局限性,為人類文明的傳播提供了更有力的載體。隨著信息技術的飛速發展,文本的呈現方式早已不局限于紙質資料,大量的文本以文檔、圖像或視頻數據的方式被保存下來。因此,如何利用計算機技術對圖像或視頻中的文本進行檢測與端到端識別變得尤為重要。自然場景文本的檢測與端到端識別具有廣泛的應用,一方面能夠提高各類應用場景的效率,如車牌識別與定位[1]、文本類驗證碼識別[2]或手寫體識別[3]等;另一方面在智能交通系統[4-6]、圖像與視頻檢索[7]、視障人導盲[8-9]以及便攜式視覺系統[10-12]等計算機視覺的實際應用場景提供額外信息。因此,自然場景文本的檢測與端到端識別逐漸成為計算機視覺的研究熱點之一,引起了研究者們的廣泛關注。
目前,用于文本文檔的光學字符識別(optical character recognition,OCR)系統已經非常成熟。不同于傳統的、規則的圖像文本,自然場景文本通常會由于表現形式豐富、圖像背景復雜、文本發生透視或彎曲、圖像失真等干擾因素的影響,使其檢測與端到端識別的難度遠遠大于傳統的、規則的圖像文本,主要體現在以下方面:
(1)自然場景的文本檢測。其任務是準確定位自然場景圖像中的文本,該方面面臨三大挑戰:①如何在現有傳統的圖像文本檢測技術基礎上再進一步擴展,以檢測不同形狀的文本;②如何有效地解決長文本、密集文本與大間距文本的問題;③如何提升準確率與召回率等性能指標。
(2)自然場景的端到端識別。這方面的任務是將檢測與識別組合成一個完整的過程,即在檢測出圖像中的文本區域后并識別其文本內容,其面臨的挑戰主要體現在:①如何高效地連接檢測與識別兩個分支,提高模型效率;②如何平衡文本檢測與識別兩者在學習難度和收斂速度上的顯著差異。
隨著深度學習技術的快速發展,針對上述各類任務所面臨的問題,許多研究者陸續提出了相應的解決方案,推動了自然場景文本相關技術領域的發展。雖然已有相關綜述對自然場景文本檢測的方法做了較為系統的闡述和總結,但多數未對該領域涉及的端到端識別方向進行討論分析,總體上對未來發展趨勢的展望也不夠全面,如文獻[13-15],因此本文的后續內容是對近年來基于深度學習的自然場景文本檢測及端到端識別算法進行了總結歸納;整理了一些常用的數據集,同時對各類算法的性能進行對比和分析;最后討論了自然場景文本檢測與端到端識別的主流研究方向,并對未來發展趨勢進行了展望。
1 自然場景文本檢測方法
近年來,在基于深度學習的自然場景文本檢測方法中,主要的思路是從回歸區域候選框和分類圖像像素點的角度出發來檢測自然場景文本。在文獻[13-15]中,大體上也是從這兩方面來進行自然場景文本檢測方法的分類,主要分為基于回歸的方法和基于分割的方法。而在這些參考文獻中,文獻[15]對于自然場景文本檢測方法的分類更為細致、合理,能夠更好地分析和總結現有的自然場景文本檢測方法。因此,本文主要參考文獻[15],將自然場景文本檢測方法的分類思路劃分為基于區域候選的自然場景文本檢測方法和基于語義分割的自然場景文本檢測方法。
1.1 基于區域候選的自然場景文本檢測方法
該類算法一般基于二維目標檢測原理,把文本檢測作為特殊目標進行。首先,將圖像輸入到卷積神經網絡(convolutional neural network,CNN)后,進行特征提取得到各類特征圖。其次,在特征圖上應用經典的二維目標檢測算法生成候選框,計算候選框與真實標簽框的交并比(intersection of union,IOU)來濾除冗余框。最后,經過其他后處理步驟,如非極大值抑制(non-maximum suppression,NMS)、邊框回歸等,來得到文本目標框。經典的二維目標檢測候選框生成算法主要包括:基于區域的卷積神經網絡(region-based convolutional neural network,RCNN)[16]的選擇性搜索(selective search,SS)算法、快速基于區域的卷積神經網絡(faster region based convolutional neural network,Faster R-CNN)[17]的區域候選網絡(region proposal network,RPN)或者其他自設多種不同尺寸的候選框生成方式等。根據文本檢測過程中區域候選框所回歸的區域對象不同,參考文獻[15]將該類算法分為基于文本區域候選的方法和基于文本組件候選的方法。
1.1.1 基于文本區域候選的方法
基于文本區域候選的方法主要是指在特征圖上應用二維目標檢測算法直接生成候選框后,接著引入感興趣區域(region of interest,RoI)層將生成的候選框進行統一表示,再將固定尺寸大小的特征輸入到CNN 中進行文本候選區域的篩選。在本小節中,首先介紹了改進的二維目標檢測算法在自然場景圖像中規則文本的應用;其次介紹了具有極端橫縱比特點的文本的檢測難點;最后列舉了針對該檢測難點而展開的相關研究工作。
得益于Faster R-CNN[17]中關于RPN 生成候選框方式的啟發,Zhong等[18]提出一個基于感知模塊的區域候選網絡來代替傳統的候選框提取算法,大幅度減少了候選框數量,提升了檢測效率。而這種方法的局限性在于只能處理水平方向的規則文本,難以檢測具有角度信息的傾斜文本。為此,Jiang等[19]在Faster R-CNN[17]的基礎上提出了R2CNN網絡,該網絡在分類優化后的區域候選框上預測具有不同池化尺寸的傾斜面積邊界框,接著采用傾斜非最大值抑制法對候選檢測結果進行后處理,從而能夠檢測傾斜文本。Liu等[20]提出了深度匹配先驗網絡(deep matching prior network,DMPNet),通過引入坐標順序協議來確定框點順序,以此解決文本在不同傾斜程度時框點坐標變化的問題,從而達到檢測傾斜文本的效果。但其缺點在于框點的后處理計算復雜,成本較高。而針對檢測傾斜文本后處理步驟繁瑣、計算成本高的問題,2018 年Ma等[21]則從網絡生成候選框入手,提出了旋轉區域候選網絡(rotation region proposal network,RRPN),并以此生成具有角度信息的傾斜候選框,有效地降低了模型計算復雜度,且取得了不錯的性能。
文本檢測的難點之一在于文本具有極端橫縱比的特點,因此網絡最終提取的特征圖通常會存在感受野不足的情況,從而導致文本檢測不全。為此,2017 年Liao等[22]提出了TextBoxes 網絡,該網絡主要是對二維目標檢測SSD(single shot multibox detector)[23]算法進行改進,將其網絡中的全連接層替換為卷積層,并且采用長條形卷積核代替方形卷積核,使感受野更符合文本的形狀,同時預設了6 種不同橫縱比的候選框來檢測不同尺寸的文本,對水平文本的檢測取得了不錯的性能。作者后續在原有基礎上進行改進,提出了TextBoxes++[24]網絡,該網絡主要是增加對角度的學習,使其能夠檢測多方向文本。Lin等[25]則將預測不全的文本框概括為因感受野不足而產生子文本的問題,因此提出了一個協同控制(contrastive relation,CORE)模塊。首先,建模多個文本實例的全文本和子文本之間的關系;其次,采用實例級的子文本區分的對比方式進一步增強關系推理,有力地解決了這一難點。
1.1.2 基于文本組件候選的方法
基于文本組件候選的方法主要是將文本區域看作由字符或文本行部分區域所構成的多個組件進行拼接而成,而邊框回歸的對象也將是這些組件,最后經過頂點線性擬合、文本行構建等方法得到文本檢測框。在本小節中,針對回歸完整文本行的檢測方法所存在的不足,首先介紹了回歸文本組件序列的相關研究工作;其次介紹了回歸文本組件序列的檢測方法的不足;最后列舉了從字符角度出發的相關研究工作。
2016 年,Tian等[26]首次采用回歸文本組件序列的方式來構建文本區域,同時引入循環神經網絡(recurrent neural network,RNN)來更好地學習序列之間的關系,但其缺點在于網絡收斂速度慢,且只能檢測水平文本。為了能夠檢測多方向文本,Shi等[27]在二維目標檢測SSD[23]算法的基礎上提出了SegLink 模型。如圖1 所示,該模型通過利用層內連接檢測模塊判斷區域鄰居像素點是否需要相連來解決文本字符的高度問題,利用跨層連接檢測模塊來解決同一文本在不同層會被檢測到所產生的冗余問題,從而能有效地檢測多方向文本。然而在檢測密集或間距很大的文本行時,該模型的性能效果不佳。Tang等[28]則在Seg-Link[27]的基礎上提出了SegLink++模型,該模型對文本組件的預測方式進行改進,通過學習文本片段之間的吸引與互斥系數來防止相鄰文本之間的粘連問題,一定程度上提升檢測密集文本的性能。然而,上述方法還未能更有效地獲取文本組件之間豐富的關聯關系,因此Zhang等[29]提出了一個統一的深度關系推理圖網絡。首先,采用文本候選網絡得到文本組件的幾何屬性;其次,利用圖網絡對其進行分組;最后,根據局部圖來生成文本檢測框,在很大程度上增強了以文本組件回歸文本區域的能力。
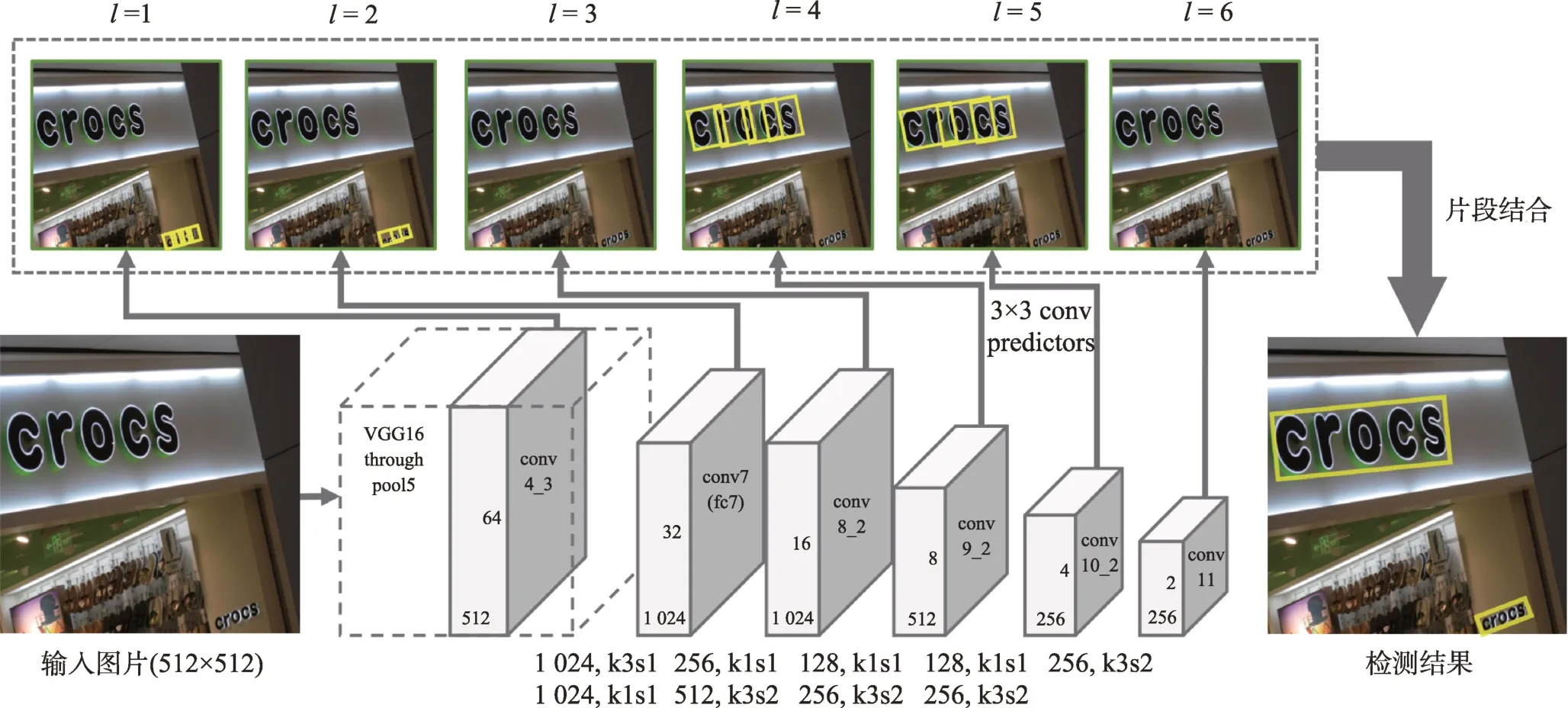
圖1 SegLink 模型Fig.1 Model of SegLink
然而,利用回歸文本組件序列的方式來構建文本區域的操作可擴展性較差,檢測速度上也有待提高。不少研究者便從字符的角度出發來檢測文本。Li等[30]提出了CENet 網絡,該網絡利用嵌入向量來學習字符間的關系,并將復雜的后處理過程轉化為嵌入字符空間中簡單的距離閾值步驟,從而更容易實現對字符的分組、合并,但其局限性在于單個字符級注釋的缺乏會導致網絡難以收斂而性能不佳。為此,Baek等[31]開始使用弱監督學習框架來擴增字符訓練數據,從而提升網絡泛化能力,借此提出了一個CRAFT 框架來預測字符區域和字符之間的關聯。相較之前的方法而言,CRAFT 框架的性能效果和檢測效率得到明顯提升。
1.2 基于語義分割的自然場景文本檢測方法
基于語義分割的自然場景文本檢測方法思維是從經典語義分割算法而來,通過全卷積神經網絡(fully convolution networks,FCN)[32]預測圖像中的每個像素點是否屬于文本區域,再決定是否將對應的像素點聚合到同一文本實例中,進而生成目標檢測框。根據采用像素點預測生成文本框方式的不同,參考文獻[15]將該類算法分為3 種:基于直接邊框回歸的方法、基于分類預測的方法與基于邊界特征檢測的方法。
1.2.1 基于直接邊框回歸的方法
傳統的圖像語義分割是通過多層CNN 對圖像進行特征提取,然后根據特征圖來預測目標分割結果。基于直接邊框回歸的方法思路與此類似,但其直接回歸的是所屬框的參數信息,如文本框各點坐標、方向角度或其他表征參數。在本小節中,首先簡要介紹了較為經典的檢測方法;其次針對文本具有極端橫縱比的特點來展開相關工作的敘述;最后闡明了迭代優化文本框特征的檢測方法的優勢。
2017 年,Zhou等[33]提出了一個兩階段文本檢測模型EAST(efficient and accurate scene text detector),該模型主要是采用FCN[32]來直接預測每個像素點屬于前景或后景,并預測其對應文本實例的得分圖和邊界坐標,進而生成文本框。He等[34]驗證了間接回歸方法的缺陷和直接回歸方法的潛在優越性,因而設計網絡直接學習文本框頂點相對于中心點的偏移量,取得了較高的準確率和召回率。對于任意形狀文本的檢測問題,Long等[35]提出了TextSnake 方法,該方法的主要思想是采用一連串具有圓心、半徑和角度等幾何信息的圓環來表達文本區域,再結合特征圖得到其骨架線,最后得到文本檢測框。
在文本檢測中,如何檢測具有極端橫縱比特點的文本是一個難以解決的問題,主要取決于預設框的尺寸以及現有文本框回歸方法的局限性,通常會出現文本檢測不全、碎片化等問題。為此,2019 年Wang等[36]提出了SAST(single shot arbitrarily-shaped text detector)方法,該方法主要是結合高層級與低層級的語義信息,以此將具有相同特征的、破碎分離的像素點歸為相同文本實例,經過文本邊框重構后得到最終文本框,但由于小文本中像素點較密集,該方法對于小文本的檢測效果較差,主要依賴復雜的后處理算法進行像素點歸類。而其他研究者則認為后處理算法過于復雜容易對網絡計算造成負擔,因而期望從其他角度著手解決如何檢測長文本的問題。Zhong等[37]認為是預設框感受野受限的問題,進而舍棄了錨框的方式,提出了一個無錨框區域候選網絡(anchor-free region proposal network,AF-RPN),該網絡直接預測特定特征圖上像素點映射回原始圖中點到對應框頂點的偏移量,從而實現以無錨框方式直接生成高質量的候選框。然而,舍棄錨框的方式固然比較容易,也不受感受野的限制,但網絡的召回率會相對較低。為此,Zhang等[38]提出了LOMO(look more than once)框架,該框架采用一個迭代優化模塊(iterative refinement module,IRM)來對直接回歸器(direct regressor,DR)產生的檢測框內的特征進行迭代優化,逐漸感知到整個長文本,進而重建出更加精準的文本框,同時網絡的召回率也有所提高。而在迭代優化文本框特征的思想上,He等[39]提出了一個文本特征對齊模塊(text feature alignment module,TFAM)來動態調整預測層的特征感受野,并引入一個位置感知非極大抑制(position-aware non-maximum suppression,PA-NMS)模塊來有選擇性地定位可靠檢測框。該方法不僅能夠提高文本的檢測精度,還能保證較快的檢測速度。
1.2.2 基于分類預測的方法
基于分類預測的方法主要是把文本檢測任務看作像素分類任務,利用圖像的全局特征來預測像素分類圖,相較于利用邊框回歸任務更加容易學習。在本小節中,首先介紹了純分割檢測方法的思路及不足;其次主要圍繞自然場景圖像中緊密相鄰文本的檢測難點及后續的相關研究工作;最后介紹了較為經典且有效的方法及其改進工作。
受到SegLink[27]模型中將同層點鄰域與跨層點連接正負性方式的啟發,Deng等[40]首次將回歸任務轉化為分類任務,并提出了PixelLink 模型。該模型以純分割的思路來對多層特征圖上的像素點標定正負,有效地降低網絡訓練難度,提升了檢測速度。但這種方法對于緊密相鄰文本的檢測則像素點分類效果不佳,文本預測框通常會出現其他文本實例的情況。針對這種現象,Li等[41]鑒于高維度特征圖中不同文本實例邊緣像素能夠明顯區分的思路,提出了漸進式尺度擴展算法來根據網絡深度依次擴展文本核,然而其網絡結構繁瑣。因此,Wang等[42]提出了可學習的像素聚合(pixel aggregation network,PAN)方法,通過計算同一文本實例中像素與核之間的距離,使用預測出的相似度向量來引導文本像素去糾正核參數,以此將文本區域中的像素合并到核中,從而重建出完整的文本實例。然而,這類方法中復雜的聚合過程計算量較大,同時對于密集相鄰文本或不明確文本邊界的魯棒性也相對較差。為此,Zhang等[43]首次引入了動態核卷積策略,進而提出了一個核候選網絡(kernel proposal network,KPN),該網絡根據嵌入特征圖的關鍵位置信息,利用預測的高斯中心圖來提取多個核候選框,并且設計了一種正交學習損失(orthogonal learning loss,OLL)來加強核候選框之間的獨立性,從而有效地解決密集相鄰文本實例的粘連問題。
采用分割網絡來進行文本檢測任務,通常需要將預測的概率圖轉化為二值圖,以此更有效地進行網絡訓練,節約計算成本。然而這個操作是不可微的,需要人為地進行相應的后處理操作,這嚴重影響了模型的收斂效率和網絡的性能。為此,Liao等[44]引入了一個閾值圖分支,并提出了一個可微二值化(differentiable binarization,DB)模塊,將概率圖與閾值圖兩個分支結合,通過DB 模塊生成近似二值圖,網絡結構如圖2 所示。DB 模塊的引入使網絡能夠進行端到端的訓練,提升檢測速度。作者后續又在原有模型基礎上提出了DBNet++[45]模型,該模型添加了自適應尺度融合(adaptive scale fusion,ASF)模塊,利用通道與空間注意力機制來增強多尺度特征,顯著地提高了網絡性能,但兩者的不足之處都在于難以檢測重疊文本。
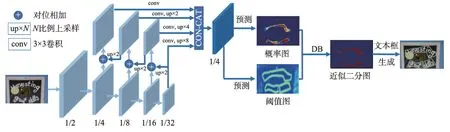
圖2 DBNet網絡Fig.2 Network of DBNet
1.2.3 基于邊界特征檢測的方法
基于邊界特征檢測的方法不僅可以利用圖像中不同文本實例的中心區域與邊界的關系特征來區分不同的文本實例,也可以對文本邊框四個角點進行劃分,接著采用重采樣等策略得到輪廓區域,再根據輪廓中點的關系進行文本檢測模型的訓練。在本小節中,首先列舉了較為經典的檢測方法;其次針對圖像空間域中文本與背景之間的關系而展開相關的研究工作;最后介紹了在傅里葉域和頻域上擬合高度彎曲文本的相關研究工作。
2019 年,Xu等[46]提出了二維向量場的概念,以其長度表達像素點屬于文本的概率,以其方向表達像素點在文本實例中的位置,在自然場景文本檢測任務上取得了不錯的效果。Zhu等[47]則提出了TextMountain 模型,該模型主要是將文本中心到邊界的區域看作概率圖,并且概率從中心向邊界逐漸遞減,概率上升方向指向文本實例,使文本分組和文本框形成更加容易。然而,上述方法在檢測彎曲文本或任意形狀文本時,常常出現文本框定位錯誤的問題。因此,Xue等[48]提出了一個多尺度形狀回歸網絡(multi-scale shape regression network,MSR),通過網絡能夠預測出文本的中心區域及其到最近邊界的橫向和縱向距離,結合這些信息后得到一組密集邊框點,連接后得到文本邊框,有效地避免了文本框錯誤定位。
利用像素點級別的預測方式來進行文本檢測任務時,通常會對圖像的背景噪聲相當敏感,后處理相對復雜且成本高。基于此,不少研究者便采用文本框層級的預測代替像素點層級的預測,以減少網絡計算負擔和背景噪聲的影響。Dai等[49]提出了漸進式輪廓回歸(progressive contour regression,PCR)方法,該方法以初始水平框經過多次演變后生成任意形狀的文本框,同時建立了一種可靠的輪廓定位機制來重新定位文本輪廓,在保證檢測效率的同時加強文本定位的準確性。Zhang等[50]提出了一個新型自適應邊界候選網絡,該網絡分為兩個階段:第一階段,采用邊界候選模型,利用共享特征分類文本像素,生成分類圖、距離場和方向場,進而產生粗邊界候選框;第二階段,采用自適應邊界變形模型,其在先驗信息指導下對邊界進行迭代變形,以此獲得更精確的文本邊界,進而提升了檢測效果。作者后續又對原有的自適應邊界變形模型進行改進,轉而采用邊界Transformer 模塊[51]來學習特征,使采樣邊界點序列和上下文信息進一步被充分利用和挖掘,從而大幅度地提升了網絡的準確率和召回率。然而,上述方法中單純地預測文本框的計算成本也相對較高,因此Tang等[52]濾除了預測文本框中過多的背景像素點,只在多尺度特征圖上分別選取與前景文本高度相關的特征點序列,并利用Transformer 模塊來建模序列之間的關系,以此有效地將其劃分為多個特征組,進而重建出文本框。該方法有效地降低了計算成本,且在常用數據集上取得了不錯的性能指標。
采樣文本邊界控制點的思路在圖像空間域上進行文本檢測任務,往往難以捕捉高度彎曲的文本細節,而回歸文本區域掩膜的方法一般也比較復雜,計算成本較高。因此,不少學者從其他域上展開研究。Zhu等[53]在傅里葉域上做研究,提出了傅里葉空間嵌入(Fourier contour embedding,FCE)方法,模型結構如圖3 所示,該網絡預測了分類圖和文本邊框點的傅里葉特征向量,然后在高于閾值的區域上對向量進行傅里葉逆變換(inverse Fourier transformation,IFT)操作,從而在圖像空間域中重建出文本輪廓點序列,在彎曲文本數據集的檢測任務上效果顯著。Su等[54]則首先提出了離散余弦變換(discrete cosine transform,DCT)方法,在頻域上將文本實例編碼為緊湊向量,接著設計了一個特征感知模塊(feature awareness module,FAM)來實現空間和尺度上的感知,有效地學習幾何編碼,最后還提出了分段非最大值抑制方法來有效地抑制不明確樣本,進一步提升了網絡性能。

圖3 FCENet模型Fig.3 Model of FCENet
2 自然場景端到端識別方法
自然場景文本相比傳統的規則文本,其識別難度主要表現為背景及形狀復雜,且場景文本通常會存在透視失真、文本彎曲失真和各種類型的扭曲等情況。現有的場景文本識別方法主要是將場景文本識別任務視為視覺識別任務,并且取得了非常好的性能效果。Fang等[55]提出了一種具有自主性、雙向性與迭代性的場景文本識別網絡。首先,引入了視覺模型和語言模型,并在兩者之間阻斷梯度流,以實現語言的顯式建模;其次,提出了一種基于雙向特征表示的雙向填充網絡語言模型來對兩者進行融合;最后,提出了一種迭代修正的執行方式來有效地緩解噪聲輸入的影響。He等[56]認為大多數方法忽略了全局文本表示,進而設計了一個圖卷積網絡的文本推理模型GTR(graph convolutional network for textual reasoning),來細化空間上下文的粗文本序列預測,同時采用了一種動態融合策略來產生一致的語言視覺表征和高質量的聯合預測,最后放在一個統一的分割基線框架S-GTR(segmentation baseline with GTR)中,為場景文本的識別任務提供了新的技術。Chu等[57]首先提出了一個迭代視覺建模模塊IterVM,從輸入的場景文本圖像中反復提取視覺特征,以增強多層次特征;其次將其與迭代語言建模模塊結合,提出了場景文本識別器IterNet,顯著地提高了低質量場景文本圖像的識別精度。受到視覺Transformer 技術的啟發,Du等[58]則提出了一個在補丁式圖像標記化框架內進行場景文本識別的單一視覺模型SVTR(scene text recognition with a single visual model),采用補丁式圖像標記化和自注意法來捕獲二維補丁之間的識別線索。該模型構建了四種具有不同容量的架構變體,并在英漢場景文本識別任務中取得了非常優秀的性能,運行速度快,模型也較小。
然而,在自然場景文本檢測與識別領域中,如何深入挖掘文本檢測與識別任務之間的內在聯系,是研究者們所重點關注的問題。目前大部分研究人員將自然場景文本檢測與識別分割為兩個獨立的任務,即首先利用檢測網絡得到圖像中的文本框,再將根據文本框得到剪裁的文本實例圖像輸入到文本識別網絡識別文本內容,但很少有方法探討這兩個任務之間的互補性。因此,將這些獨立的方法組合成一個場景文本檢測與識別系統會增加計算量,而端到端識別算法可以在一個算法中完成文本檢測和文本識別,其基本思想是設計一個同時具有檢測和識別模塊的模型,共享其中兩者的CNN 特征,并聯合訓練。由于一個算法即可完成文字識別,端到端模型更小,速度更快。本章首先介紹了由傳統自然場景文本檢測方法改進的端到端識別方法;其次介紹了目標檢測和實例分割技術在端到端識別方法中的應用;然后介紹了一些旨在提高檢測與識別速度的實時端到端識別方法;最后列舉了一些針對如何解決檢測與識別之間存在嚴重依賴的端到端識別方法。
2018 年,He等[59]在EAST[33]模型基礎上提出了一個端到端的文本識別模型,該模型在文本識別模塊中增加了注意力對齊學習,通過引入額外的聚焦損失來監督學習,得到更準確的編碼字符空間信息,以此提高文本識別準確率。但該方法只能識別水平方向的規則文本,對自然場景文本中存在的彎曲、旋轉等不規則文本識別效果較差。為此,Feng等[60]在Text-Snake[35]方法基礎上提出了一種新穎的文本識別框架TextDragon,其原理是先檢測文本的任意四邊形組件,然后通過感興趣區域滑動操作與CTC(connectionist temporal classification)算法結合進行文本識別。該框架僅使用單詞/行級注釋進行訓練即可以端到端的方式來檢測和識別任意形狀的文本,且對不規則文本的識別效果也有了一定的提高。Baek等[61]則以CRAFT[31]文本檢測框架為基礎提出了CRAFTS方法,在檢測到不規則文本后對區域特征做薄板樣條變換得到矯正后的文本特征,與單字檢測結果結合并將其送入識別器進行文本識別,同樣取得了較好的識別性能。
也有學者將目標檢測和實例分割中常用的算法,如Faster R-CNN[17]和Mask R-CNN[62]運用于端到端識別中,以識別自然場景中的任意形狀文本。2018 年,Lyu等[63]開創性地提出了一種能夠檢測和識別任意形狀文本實例的模型Mask TextSpotter,該模型以獨特的文本識別方式在不同的數據集上取得了較好的性能,但訓練的時候需要依賴于字符級別的標注,因此只能識別英文和數字文本,對于中文這種字符數量很大的文本識別并不合適。作者后續在該工作的基礎上提出了Mask TextSpotter V2[64],在其識別網絡中加入了基于注意力機制的序列識別分支,提高了識別性能。2020 年該作者繼續沿用Mask TextSpotter V2[64]中檢測和識別分支的設計思路,提出了Mask TextSpotter V3[65],網絡結構如圖4所示。通過設計一個無錨框的分割區域提取網絡(segmentation proposal network,SPN)替代RPN 預測任意形狀文本的顯著圖,進一步提高了網絡的性能。得益于Mask TextSpotter V3[65]在端到端識別任務中優越的性能,有學者在此基礎上進行了拓展。Huang等[66]在Mask TextSpotter V3[65]基礎上加入了語種識別網絡,該網絡對文本區域所屬語種進行識別,并選擇對應語種的識別頭,從而實現了多語種的檢測與識別,其另一改進之處在于能夠單獨訓練網絡中的模塊,使網絡訓練更具靈活性。

圖4 Mask TextSpotter V3 網絡Fig.4 Network of Mask TextSpotter V3
雖然Mask TextSpotter[63-66]系列方法取得了優秀的性能表現,但由于感興趣區域操作,網絡檢測速度較慢。而針對如何提高端到端識別速度的問題,Qiao等[67]提出了一個基于掩碼注意力引導的端到端識別框架(mask attention guided one-stage scene text spotter,MANGO),通過包含實例級掩碼和字符級掩碼的位置感知注意力模塊,對每個文本實例及其特征生成注意力權重,將圖像中的不同文本分配到不同的特征映射通道上,最后使用一個輕量級的序列解碼器來生成字符序列。由于該方法不需要RoI 提取操作,網絡預測速度更快,且取得了優秀的性能。Wang等[68]提出了一種快速端到端的自然場景文本識別方法(point gathering network,PGNet),其通過字符點聚合的改進CTC 方法來避免RoI和非極大值抑制操作,有效地提高了預測速度,同時提出了基于圖的修正模塊來進一步提高模型識別性能,識別精度更高。與CRAFTS[61]相比,該方法不需要字符級別的標注,適用性更強。Wang等[69]提出了一種基于文本內核(即中心區域)的任意形狀文本的表示方法,可以較好地區分密集相鄰文本,且對實時的應用場景非常友好。在此基礎上,作者加入了無編碼器的輕量級注意力識別頭,建立了一個高效的端到端識別框架PAN++[69]。如圖5 所示,其可以有效地檢測和識別自然場景中任意形狀的文本,顯著地提升了推理的速度和識別的精度。Liu等[70]則提出了一種基于貝塞爾曲線的實時端到端的自然場景文本識別方法(adaptive Bezier-curve network,ABCNet),該方法用三階貝塞爾曲線對不規則文本進行建模,設計貝塞爾對齊層來精確提取任意形狀文本實例的卷積特征,通過貝塞爾曲線檢測方法可以大大減小計算開銷,在效率和精度上都具有優勢。作者后續在該工作基礎上進一步提出了ABCNet V2[71],設計了一種新的貝塞爾對齊層,考慮了雙向多尺度金字塔整體文本特征,對多尺度文本實例的處理更具有通用性,并且識別頭采用基于注意力機制的解碼器替代ABCNet[70]中基于CTC 損失函數的解碼器,在保持高效率的同時實現先進的性能。

圖5 PAN++模型Fig.5 Model of PAN++
針對端到端識別網絡的訓練需要昂貴的空間注釋的問題,Kittenplon等[72]提出了TTS(TextTranSpotter)框架。該框架采用完全監督和弱監督相結合的方式訓練網絡,使模型性能和注釋成本之間能夠進行權衡。然而,檢測與識別兩個任務共享相同的CNN 特征會存在兩個問題:第一,文本識別的性能高度依賴于文本檢測的精度;第二,連接檢測和識別的RoI 裁剪會帶來背景噪聲,導致信息丟失。因此,不少學者對此展開研究。2022 年,Wu等[73]提出了一個單鏡頭自依賴的場景文本定位器(single shot self-reliant scene text spotter,SRSTS),其通過采樣共享特征圖上的正錨點來橋接并行的檢測和識別兩個分支,使識別不再著眼于精確的文本邊界,進而減少兩者的依賴,有效地降低了檢測網絡所需的注釋成本。Huang等[74]以SwinTransformer 為特征提取網絡,提出了一個端到端的場景文本定位框架SwinTextSpotter,利用以動態頭為檢測器的Transformer 編碼器,將檢測與識別之間的橋梁統一為一種新的識別轉換機制,并通過識別損失來明確地引導文本定位。其不需要字符級的注釋及識別修正模塊,因此網絡的訓練比較容易,但由于識別器難以匹配較大的注意力圖,對長且形狀任意的文本檢測效果不佳。Zhang等[75]則提出了一個文本定位轉換器(text spotting transformer,TESTR),采用單編碼器和雙解碼器的方式來聯合文本框控制點回歸和字符識別,同時設計了一個邊界框到多邊形框的引導方法,能夠有效地處理貝塞爾和多邊形注釋,但缺點在于無法自適應不同形狀文本所需的控制點個數。
3 場景文本檢測與端到端識別性能對比
3.1 常用公開數據集
在自然場景文本檢測與端到端識別領域,常用公開數據集的詳細信息如表1 所示。其中ICDAR-2013 和ICDAR2015 是目前用于四邊形文本檢測與識別的主流數據集,Total-Text 和CTW-1500 則是用于任意形狀及曲線文本檢測與識別的主流數據集。
3.2 文本檢測性能評估
由表1 可知,自然場景文本檢測的數據集很多,本節主要在ICDAR2013、ICDAR2015、Total-Text 和CTW-1500 數據集上從召回率(recall)、準確率(precision)和調和平均(F-measure)三方面進行基于深度學習的自然場景文本檢測算法的性能評估。其中,ICDAR2013 和ICDAR2015 通常用來做水平方向文本或四邊形文本的檢測,各類算法的性能評估如表2所示。Total-Text 和CTW-1500 則通常用于任意形狀文本和曲線文本的檢測,各類算法的性能評估如表3所示。總體來說,基于文本區域候選的方法如CORETEXT[25]在水平與傾斜文本檢測上效果較好,可見優化迭代文本框的方法非常有效;基于文本組件候選的方法如CRAFT[31]、DRR(deep relational reasoning graph network)[29]在水平和彎曲文本上性能表現更優,但其檢測速度慢且拓展難度大;而基于語義分割的方法如KPN(kernel proposal network)[43]、Text-BPN(boundary proposal network for arbitrary shape text detection)[50]、FSG(feature sampling and grouping)[52]在這兩類文本上的檢測性能較好,并且隨著分割技術的發展,具有更廣闊的前景,也是目前文本檢測的主流方式。
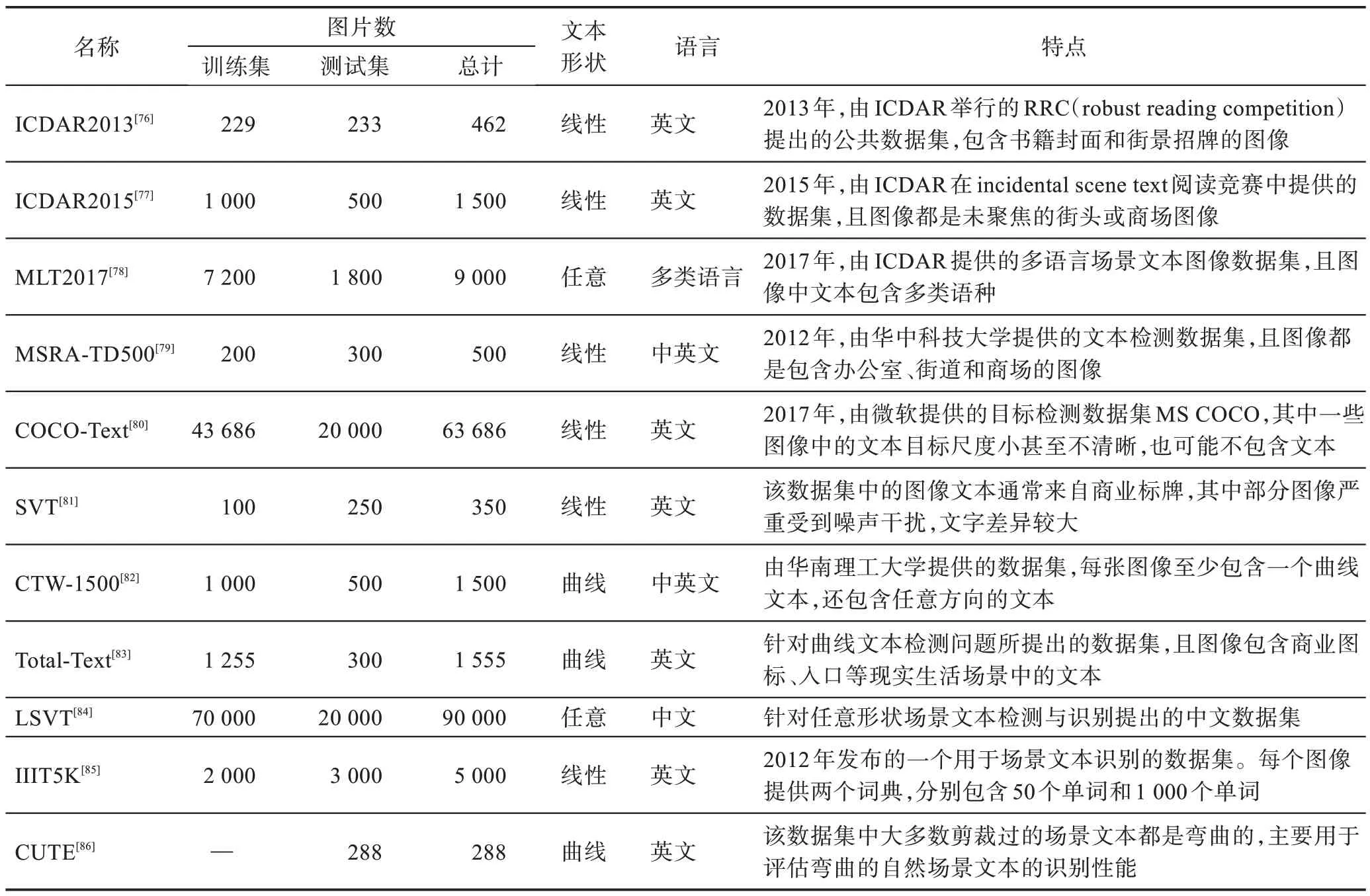
表1 常用數據集Table 1 Common datasets
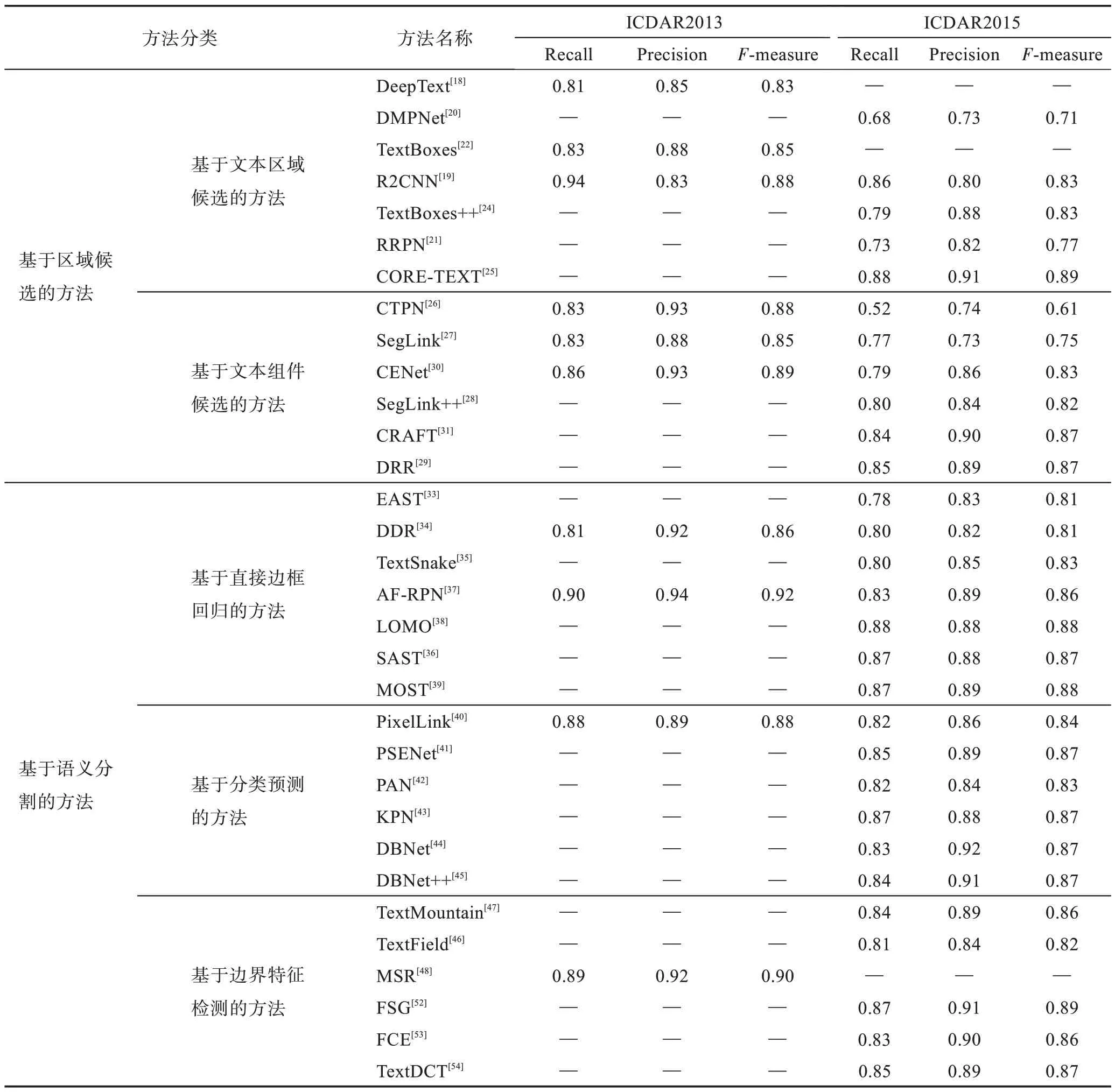
表2 文本檢測方法在ICDAR2013 和ICDAR2015 上的性能對比Table 2 Performance comparison of text detection methods on ICDAR2013 and ICDAR2015
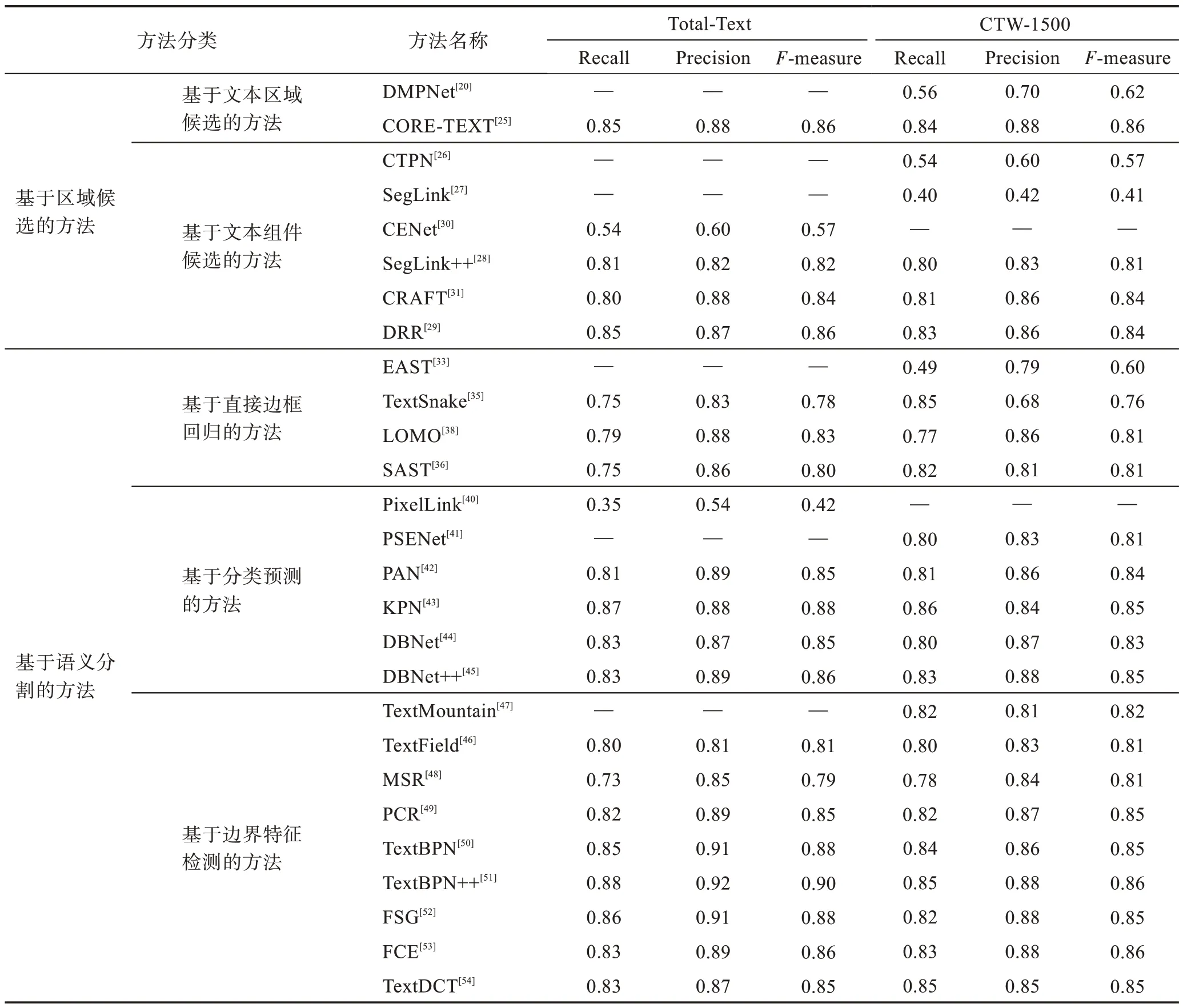
表3 文本檢測方法在Total-Text和CTW-1500 上的性能對比Table 3 Performance comparison of text detection methods on Total-Text and CTW-1500
3.3 端到端識別性能評估
端到端識別方法主要在ICDAR2015、Total-Text和CTW-1500 數據集上進行性能評估。性能評估方式主要分為:end-to-end、word spotting、None 和Full。其中,None 和Full 分別代表無詞典和全詞典下的識別準確率,end-to-end 表示檢測并準確識別圖像中的文本,word spotting 則表示檢測并準確識別詞匯表中的單詞,詞匯表由S、W、G 三類不同的詞匯表構成。其中,S(strong)表示由每幅圖像包含的所有單詞以及從數據集選取的部分單詞組成的詞匯表(總共100個);W(weakly)表示由訓練集和測試集所有單詞組成的詞匯表;G(generic)表示通用詞匯表,其來源于文獻[87]的數據集,大約9 萬個單詞的通用詞匯表。對于四邊形文本端到端算法主要基于ICDAR2015 數據集進行評估,性能對比如表4 所示。對于不規則文本端到端算法主要在Total-Text 和CTW-1500 數據集進行評估,性能對比如表5 所示。總體來說,目前CRAFTS[61]這類有字符級別監督的端到端識別算法在規則文本與不規則文本上性能表現更佳,但是在大規模數據集進行字符級別的標注工作量是巨大的,這也是該類算法的局限性。雖然近年來端到端識別算法的性能得到了顯著提升,但該類算法識別準確性仍遠落后于先檢測后識別的拼接方式,距離真正應用于實際場景仍存在很大提升空間。
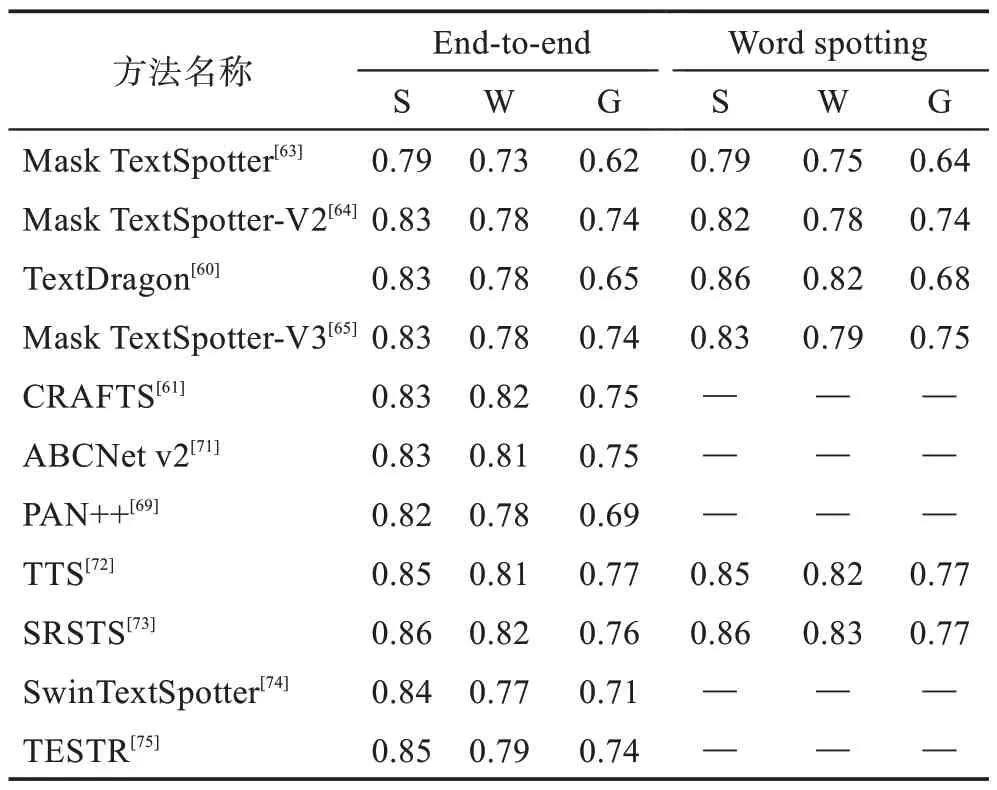
表4 端到端識別方法在ICDAR2015 上的性能對比Table 4 Performance comparison of end-to-end recognition methods on ICDAR2015

表5 端到端識別方法在Total-Text和CTW-1500 上的性能對比Table 5 Performance comparison of end-to-end recognition methods on Total-Text and CTW-1500
4 討論
4.1 基于區域候選的文本檢測方法
基于區域候選的方法主要分為基于文本區域候選的方法和基于文本組件候選的方法,前者幾乎依賴于二維目標檢測算法,但是解決不了文本具有極端橫縱比的特點,后續的改進是在二維目標檢測算法基礎上進行擴展,將回歸目標物體區域轉化為回歸文本區域,同時預設了多類不同尺寸的邊框來解決文本具有極端橫縱比的問題,然而在這階段只是直接回歸出整個文本區域邊界框。此外,國內外學者和研究機構也將目光放在后者,如將回歸的對象區域放在了單個字符或文本行的部分區域,或者充分挖掘字符之間的關系等。為了檢測傾斜文本,以往的方法在生成區域候選框時會引入多余的背景噪聲造成干擾,導致檢測與識別的性能受到很大的影響。為此,還需要加入網絡對文本框角度的學習來更好地擬合傾斜文本框。
然而基于區域候選的方法對網絡的設計需要足夠精巧,對預設框的大小和比例有一定的挑戰,主要的因素如下:(1)若網絡輸出的最后一層特征圖的感受野或預設框的尺寸小于文本行的尺寸,將會導致部分文本信息檢測不到;(2)使用RPN 生成的區域候選框在處理密集文本時會引入相鄰文本的特征信息;(3)框的數量過多時會導致文本的檢測速度受到影響,數量過少時會導致準確度降低。雖然3.2 節中針對上述問題提出了很多觀點,并進行了一系列的實驗,但由于文本極端橫縱比特點的存在,使得超過預設閾值的檢測框數量少,這嚴重影響了召回率和準確率等性能指標的評估。此外,對于彎曲文本或任意形狀文本,預設框數量巨大,模型過于復雜,即單純的基于區域候選的文本檢測方法很難檢測這類文本。
4.2 基于語義分割的文本檢測方法
隨著圖像語義分割技術的興起,憑借其能夠準確分割任意形狀的物體輪廓的特點,國內外學者和研究機構開始將這類方法引入到文本檢測領域。其中利用直接邊框回歸的方式,區別于區域候選的方法,它不再回歸出真實框與預設框的中心點坐標或四個頂點坐標的偏移量,而是回歸每個像素點坐標相對于真實框表征參數的偏移量,解決了預設文本框難以選擇尺寸大小的問題。雖然這類方法的性能較之前的方法在整體上有所提升,但其需要回歸的參數數量過于龐大,導致網絡檢測的速度較慢。
而對于彎曲或任意形狀文本的檢測而言,特別是緊密相鄰文本的區域檢測問題,上述方法仍然不能夠解決。為此,基于分類預測的方法被提出:一類方法是先對像素點進行分類,再利用高維特征能夠分割出很近的文本的特點,根據之前生成的標簽,依次對網絡輸出進行逐層的像素點合并,生成最終的文本框區域;另一類方法則是利用像素聚類的方式,通過縮短同一文本實例中文本像素與核之間的距離,使用預測出的相似度向量來引導文本像素去糾正核參數,以此將文本區域中的像素合并到核中,從而重建出完整的文本實例。這類方法解決了之前很多的問題,同時檢測速度也很快,是目前的主流方法。當然,還有基于邊界特征檢測的方法,可以利用中心區域與邊界的關系特征來區分不同的文本實例,也可以對文本邊框角點進行劃分,采樣后得到輪廓區域,再根據輪廓中點的關系進行訓練。但這類方法的性能主要取決于預處理步驟,對數據集進行處理后,利用網絡進行高效、準確的訓練,同樣取得了不錯的性能。
近年來,Transformer 技術在視覺領域有了突破性的進展,憑借其具有快速有效地對文本特征之間的關系進行建模等特點,不少研究者將其與CNN 結合,并應用到自然場景文本檢測與端到端識別領域中,如作為特征提取網絡主干或分類回歸分支,迭代細化文本框,文本特征點關系建模等,取得了非常好的效果,但因其需要訓練的網絡參數量巨大,所以對設備具有較高的要求,同時落地也相對困難。但可以肯定的是,如何將Transformer 與CNN 之間更好地結合到一起,并應用到該領域中,是廣大研究者比較關注的,也是未來的發展趨勢。
4.3 端到端識別方法
端到端識別算法的基本思想是設計一個同時具有檢測單元和識別模塊的模型,共享文本檢測與文本識別的特征并聯合訓練。相對于先檢測后識別的兩階段算法,端到端識別算法整體模型更小,速度更快,適用于實時性要求較高的領域。
目前大多數應用研究都是采用文本檢測和文本識別級聯的方式,在這過程中上一級產生的錯誤會因為級聯而傳遞積累,這可能導致文本識別產生大量錯誤預測。而端到端的方式可以防止錯誤在訓練過程中積累,實現特征共享和協同優化,其困難在于如何搭建文本檢測與識別之間特征信息共享的橋梁,在訓練過程中有效地共享兩者特征信息。并且,由于文本檢測與識別兩者方法的不同,平衡文本檢測和識別兩者在學習難度和收斂速度上的顯著差異對模型性能有重要作用。另一方面,維護一個具有數據和模型依賴關系的文本檢測與識別級聯管道需要大量的工程工作,而端到端的模型更容易維護和適應新的領域,具有重要的工程價值。
5 亟待解決的問題和發展趨勢
文字作為人類文明的瑰寶,在生活中起著不可或缺的作用,因此自然場景文本檢測與端到端識別作為計算機視覺與人工智能領域中一個重要且具有挑戰性的問題而受到廣泛關注。隨著深度學習技術的深入發展,自然場景文本檢測與端到端識別領域取得了突破性的進展,但目前的文本檢測與端到端識別性能仍存在巨大提升空間。根據已有的研究方法和最新的研究思路,本文對基于深度學習的自然場景文本檢測與端到端識別方法存在的待解決的問題與未來研究方向進行展望。
(1)如何提高文本檢測與端到端識別模型的泛化能力,適應現實世界復雜多變的場景文本。雖然由當前流行的數據集訓練的文本檢測與端到端識別算法在幾個真實的評估數據集上取得了良好的性能,但它們在一些特殊情況仍存在問題,如文本較長、尺寸較小、字體樣式多變和字符背景復雜的文本實例。此外,大多數文本識別算法對環境干擾敏感,難以處理現實世界的復雜性,泛化能力不夠。例如,相較于其他數據集,在COCO-Text 這一難度較大的數據集上各類方法測試取得的性能較差,性能存在較大差異。相比之下,人類善于在復雜場景下識別不同風格的文本,這表明目前各類算法的識別水平和泛化能力與人類水平的表現相比還有很大提升空間。因此,除了簡單地使用豐富多樣的數據作為訓練樣本外,如何探索文本獨特和本質的特征表示,結合視覺級和語義級的特征將是提高文本檢測與端到端識別模型泛化能力的關鍵。
(2)如何提高端到端識別模型的性能。目前,由于端到端識別算法在一個模型里需要同時完成文本檢測和識別兩大關鍵任務,網絡設計更加復雜,模型訓練和優化也更加困難,其準確率仍未達到應用領域的要求,存在巨大的提升空間。因此,如何設計更有效的方法來銜接文本檢測和識別之間的特征信息,從而平衡文本檢測和識別兩者在學習難度和收斂速度上的顯著差異,將是提高端到端識別模型的性能的關鍵。
(3)如何解決訓練數據不足的問題。深度學習算法的性能與訓練數據密切相關,特別是文本識別算法。目前大多數自然場景文本數據集只包含數千張數據樣本,而這對于訓練一個準確的文本識別模型來說是遠遠不夠的。而且,手工收集和注釋大量的真實數據將涉及巨大的人工和資源開銷。目前的解決方案大致分為以下兩類:①合成真實有效的數據,與真實數據集相比,在數據合成過程中可以輕松獲得詞級、字符級和像素級等多級標注信息,用于訓練文本識別算法;②開發有效的文本數據增強方法,擴充數據集規模。此外,采用自監督學習的方法引入大量真實世界采集的無標注數據也是一個很有潛力的發展方向。
(4)如何使文本識別算法適應多種語言。隨著日益密切的國際交流,能夠適應多語言的文本識別模型是促進各國人民交流和智慧城市發展的關鍵。目前大多數文本識別模型只能識別一個語言的文本,若場景圖片中存在多種語言將難以識別。此外,當前許多文本識別算法只針對拉丁文本,非拉丁語文本的識別還沒有得到廣泛的研究,例如中文場景文本,中文字符類別更多,與拉丁語文本相比具有獨特性。并且,現有的文本識別算法不能很好地推廣到不同的語言,因此為特定語言開發與該語言相關的文本識別算法,結合語種識別分類器,自適應地選擇對應語種的文本識別模型可能是一個可行的解決方案。
(5)如何提高自然場景文本檢測與端到端識別算法在落地應用場景的適應性。雖然當前自然場景文本檢測與端到端識別的相關研究取得了巨大進步,在相應數據集取得了較好的性能,但在應用時還需結合其他因素進行適配才能更好地落地。例如,對于日常生活中常見的較為隱私和重要的場景,如身份證和銀行卡識別,不僅要保證識別的性能,識別方法的安全性也尤為重要。現實應用場景中的挑戰可能會為未來的研究提供新的研究機會,如多語言文本識別、隱私場景的高精度識別、移動設備的快速文本識別等。因此,研究者不應當局限于當前的評價基準,而是更應該考慮應用場景的特點,有針對性地進行優化改進,從而能夠更好地實現算法在各個應用領域的落地。
6 結束語
自然場景的文本檢測與端到端識別作為近年來計算機視覺的研究熱點,在生活中有著廣泛的應用,幫助人們更好地感受和理解世界。本文主要歸納總結了近年來基于深度學習技術的自然場景文本檢測與端到端識別方法的技術發展路線,對研究者們所提出的思想、方法進行分類,對比了這些方法在主流數據集上的性能,最后針對自然場景文本檢測與端到端識別的主流研究方向進行了討論,并闡述了其待解決問題和發展趨勢。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
小學教學參考(2015年20期)2016-01-15 08:44:38
電測與儀表(2015年5期)2015-04-09 11:30:52
